Recommandations pour améliorer la sécurité
Pour les charges de travail qui nécessitent une limite de sécurité ou une isolation stricte, tenez compte des points suivants:
Pour appliquer une isolation stricte, placez les charges de travail sensibles à la sécurité dans un autre projet Google Cloud .
Pour contrôler l'accès à des ressources spécifiques, activez le contrôle des accès basé sur les rôles dans vos instances Cloud Data Fusion.
Pour vous assurer que l'instance n'est pas accessible au public et réduire le risque d'exfiltration de données sensibles, activez les adresses IP internes et VPC Service Controls (VPC-SC) dans vos instances.
Authentification
L'interface utilisateur Web de Cloud Data Fusion prend en charge les mécanismes d'authentification compatibles avec la console Google Cloud , avec un accès contrôlé via Identity and Access Management.
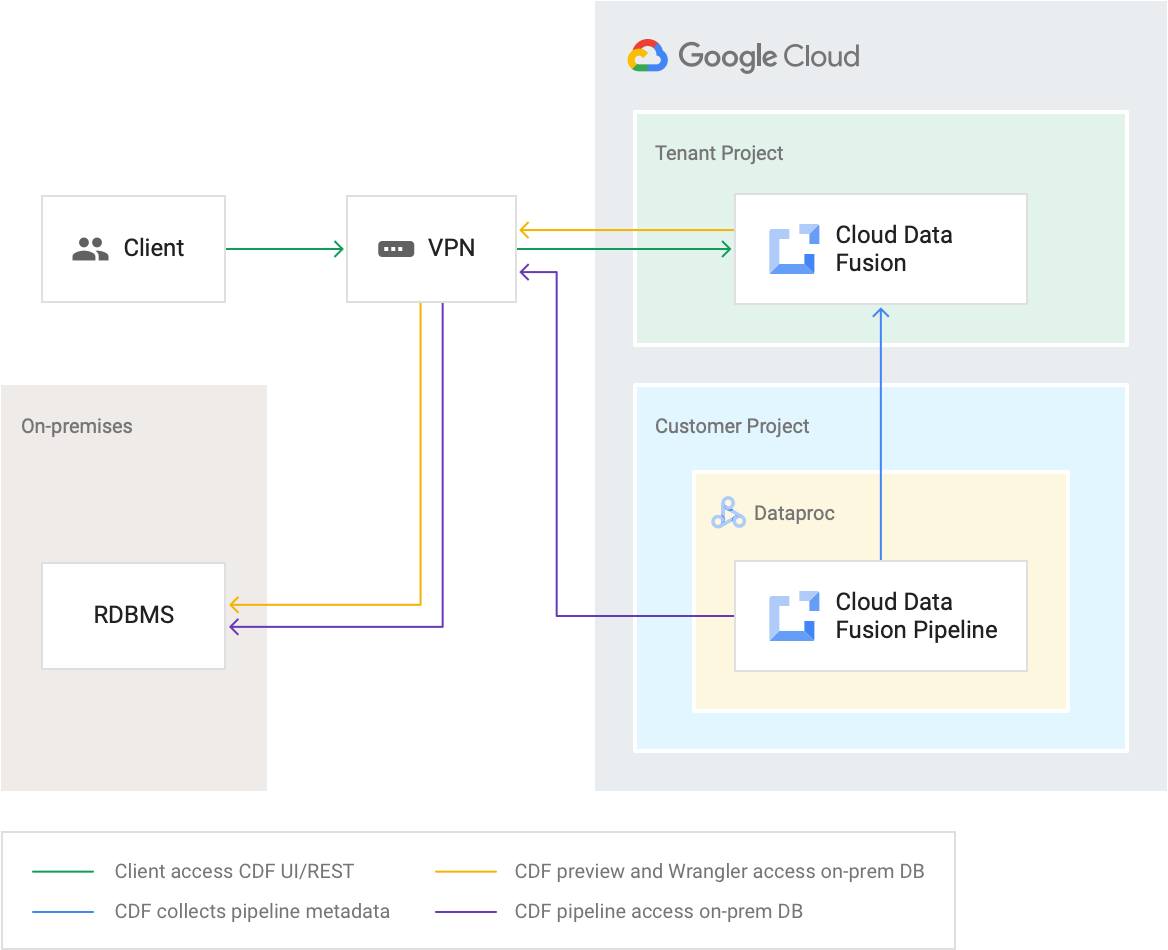
Contrôles de mise en réseau
Vous pouvez créer une instance Cloud Data Fusion privée, qui peut être connectée à votre réseau VPC via l'appairage de réseaux VPC ou Private Service Connect. Les instances Cloud Data Fusion privées possèdent une adresse IP interne et ne sont pas exposées à l'Internet public. Vous pouvez bénéficier d'une sécurité supplémentaire en utilisant VPC Service Controls pour établir un périmètre de sécurité autour d'une instance Cloud Data Fusion privée.
Pour en savoir plus, consultez la présentation de la mise en réseau Cloud Data Fusion.
Exécution du pipeline sur des clusters Dataproc d'adresses IP internes pré-créés
Vous pouvez utiliser une instance Cloud Data Fusion privée avec l'approvisionneur Hadoop distant. Le cluster Dataproc doit se trouver sur le réseau VPC appairé à Cloud Data Fusion. L'approvisionneur Hadoop distant est configuré avec l'adresse IP interne du nœud maître du cluster Dataproc.
Contrôle des accès
Gestion de l'accès à l'instance Cloud Data Fusion : les instances compatibles avec RBAC permettent de gérer l'accès au niveau d'un espace de noms via Identity and Access Management. Les instances avec RBAC désactivé ne permettent de gérer les accès qu'au niveau de l'instance. Si vous avez accès à une instance, vous avez accès à l'ensemble des pipelines et des métadonnées de cette instance.
Accès du pipeline à vos données : l'accès du pipeline aux données est fourni en accordant l'accès au compte de service, qui peut être un compte de service personnalisé que vous spécifiez.
Règles de pare-feu
Pour une exécution de pipeline, vous contrôlez les entrées et sorties en définissant les règles de pare-feu appropriées sur le VPC client sur lequel le pipeline est exécuté.
Pour plus d'informations, consultez la section Règles de pare-feu.
Le stockage des clés
Les mots de passe, les clés et les autres données sont stockés de manière sécurisée dans Cloud Data Fusion et chiffrés à l'aide de clés stockées dans Cloud Key Management Service. Au moment de l'exécution, Cloud Data Fusion appelle Cloud Key Management Service pour récupérer la clé utilisée pour déchiffrer les secrets stockés.
Chiffrement
Par défaut, les données sont chiffrées au repos à l'aide de Google-owned and Google-managed encryption keys et en transit à l'aide de TLS v1.2. Utilisez des clés de chiffrement gérées par le client (CMEK) pour contrôler les données écrites par les pipelines Cloud Data Fusion, y compris les métadonnées de cluster Dataproc et les sources de données et les récepteurs Cloud Storage, BigQuery et Pub/Sub.
Comptes de service
Les pipelines Cloud Data Fusion s'exécutent dans des clusters Dataproc du projet client et peuvent être configurés pour s'exécuter à l'aide d'un compte de service spécifié par le client (personnalisé). Un compte de service personnalisé doit disposer du rôle Utilisateur du compte de service.
Projets
Les services Cloud Data Fusion sont créés dans des projets locataires gérés par Google auxquels les utilisateurs ne peuvent pas accéder. Les pipelines Cloud Data Fusion s'exécutent sur des clusters Dataproc au sein de projets clients. Les clients peuvent accéder à ces clusters tout au long de leur durée de vie.
Journaux d'audit
Les journaux d'audit Cloud Data Fusion sont disponibles dans Logging.
Plug-ins et artefacts
Les opérateurs et les administrateurs doivent éviter d'installer des plug-ins ou des artefacts non approuvés, car ceux-ci peuvent présenter un risque de sécurité.
Fédération d'identité de personnel
Les utilisateurs de la fédération d'identité des employés peuvent effectuer des opérations dans Cloud Data Fusion, telles que la création, la suppression, la mise à niveau et la liste d'instances. Pour en savoir plus sur les limites, consultez la page Fédération des identités des employés: produits compatibles et limites.