
45–55% reduction in model training costs
Cold starts improved by 99%, from 20 minutes to a few seconds
5–6× increase in AI team output
Rapid deployment of multi-model 80 GB containers with no re-architecting
Google Cloud's GPU-rich platform helped Rembrand cut training costs in half and bring new video capabilities to market faster than ever.
Google Cloud's GPU-rich platform helped Rembrand cut training costs in half and bring new video capabilities to market faster than ever.
Why Rembrand made GKE the foundation
of its AI platform
For a long time, running across multiple clouds felt unavoidable. Access to high-end GPUs was unpredictable, and we had to take capacity wherever we could. DWS on GKE gave us reliable, cost-efficient access to the accelerators we needed, so consolidating our core AI workloads on Google Cloud made sense.
Ahmed Saad
Chief Technology Officer, Rembrand
Rembrand creates AI-powered product placement, inserting brands into finished video so naturally that viewers assume the items were always there. Their technology has to operate at a level of film-level realism most AI companies never touch. "Even a tiny mismatch can break the illusion: a strand of hair, a shadow, the way a product sits behind someone," said Ahmed Saad, Chief Technology Officer and Co-founder of Rembrand. Delivering a seamless experience requires a deep stack of AI systems working together. This includes diffusion models for video editing, segmentation and tracking, depth and lighting estimators, and synthetic data generation.
In the early days, Rembrand relied on a costly patchwork of cloud providers and neocloud GPU platforms that slowed the team down. AWS supported much of their production layer, and GPU-heavy experiments bounced between Google Kubernetes Engine (GKE) and other providers when capacity aligned.
This meant data had to be duplicated across systems, GPU performance varied, and the overhead of maintaining different Kubernetes environments became a drag on engineering time. Experimentation lagged because every new model checkpoint meant spinning up infrastructure, waiting for large containers to load, and hoping the environment behaved consistently.
"For a long time, running across multiple clouds felt unavoidable. Access to high-end GPUs was unpredictable, and we had to take capacity wherever we could," said Saad. But when the team found Google Cloud's Dynamic Workload Scheduler (DWS), it immediately changed the economics of training. DWS gave them flexible, cost-efficient access to single A100 and H100 GPUs instead of expensive multi-GPU machines, while GKE took care of the operational overhead. "DWS on GKE gave us reliable, cost-efficient access to the accelerators we needed, so consolidating our core AI workloads on Google Cloud made sense."
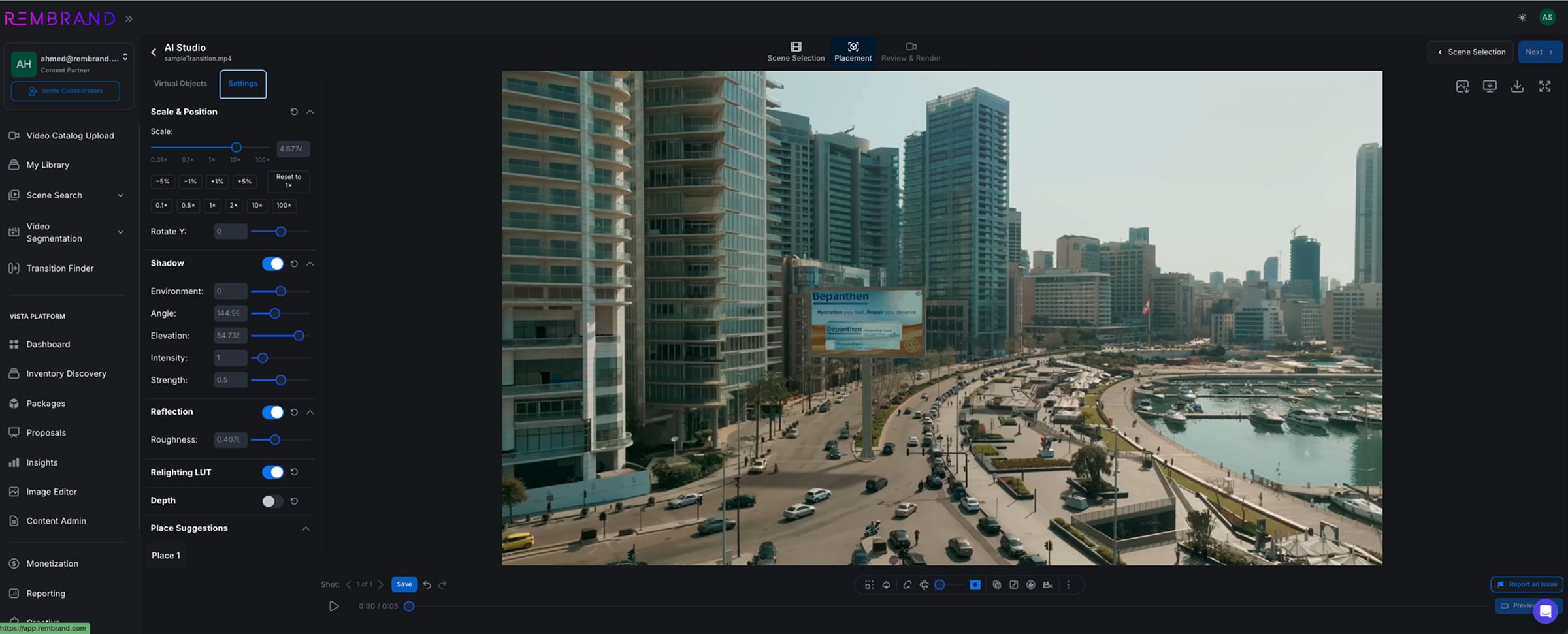

The infrastructure behind the movie magic
Once Rembrand consolidated on Google Cloud, GKE became the backbone of their machine learning pipeline. On other platforms, standing up Kubernetes demanded manual tuning and a heap of add-ons just to achieve basic stability. On GKE, those foundational capabilities were built in from the start. "In our new setup, GKE immediately felt different," said Saad. "The basics weren't something we had to fight anymore. Logging, monitoring, scaling, node management—it all just worked."
GKE became even more powerful when paired with Dynamic Workload Scheduler (DWS), which sits under GKE to provision GPU capacity for training jobs.
Accessing high-end GPUs in single-unit slices meant we could experiment constantly without overprovisioning or waiting weeks for capacity.
Ahmed Saad
Chief Technology Officer, Rembrand
Instead of reserving entire eight-GPU machines just to run a single experiment, DWS allocates the exact number of GPUs needed and queues jobs efficiently. For Rembrand, this immediately cut training costs by 45–55% while giving them consistent access to high-end accelerators. "Accessing high-end GPUs in single-unit slices meant we could experiment constantly without overprovisioning or waiting weeks for capacity," Khamis said.
Layering Kubeflow and its PyTorchJob training operator on GKE then gave the team full control over distributed training by orchestrating pipelines and keeping experiments reproducible. "We could suddenly run 32- or 48-GPU jobs without engineering gymnastics," said Khamis. "The cluster just understood how to place workloads and recover from failures. And our smaller models ran right alongside them on T4s or L4s without maintaining separate systems."
By bringing training, experimentation, data preprocessing, and synthetic data generation onto GKE and co-locating storage on Cloud Storage, Rembrand eliminated the drag of shuffling workloads across clouds. "Our output grew five to six times not because we hired more people, but because the platform stopped fighting us," said Khamis.
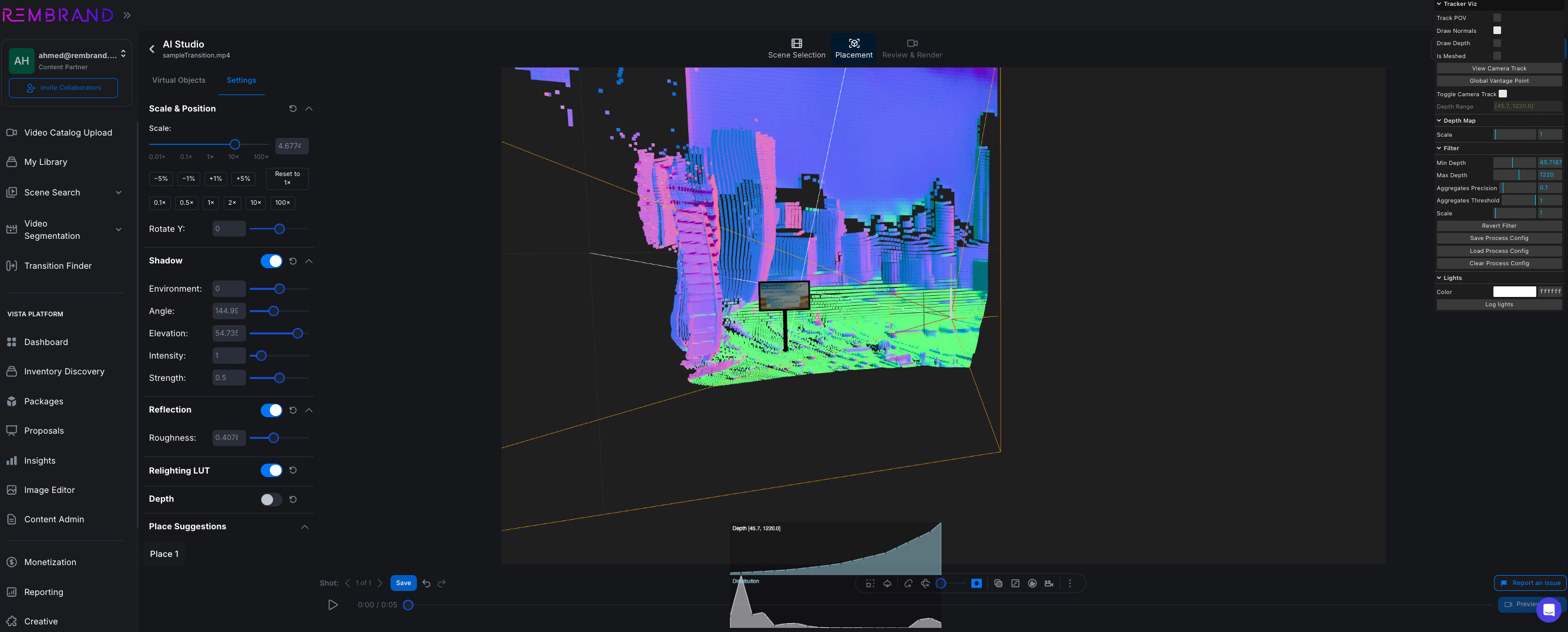
Bringing real-time inference to Rembrand's pipeline
Cloud Run was the moment everything clicked for inference. We went from double-digit-minute cold starts to models loading in a few seconds. It opened the door for real-time experiences we simply couldn't deliver before.
Ahmed Saad
Chief Technology Officer, Rembrand
While training had become smooth on GKE, inference still lagged behind because Rembrand's production stack on AWS couldn't support GPUs in a serverless environment. Every model update meant spinning up dedicated GPU instances and loading 80 GB containers before anything could run. Cold starts routinely stretch to fifteen or twenty minutes. For a team that constantly tests new checkpoints and model variations, that delay throttled experimentation and slowed down customer demos.
Cloud Run changed that dynamic almost immediately. With serverless GPU support, Rembrand no longer had to keep long-lived GPU machines running just to serve inference. Cloud Run provisions GPU-backed containers on demand, scales them down to zero when idle, and uses container image streaming to begin execution before the full image downloads.
"Cloud Run was the moment everything clicked for inference," said Saad. "We went from double-digit-minute cold starts to models loading in a few seconds. It opened the door for real-time experiences we simply couldn't deliver before." Now, customers could interactively preview product placements directly in their browser, complete with accurate occlusion, lighting, and motion tracking. Additionally, Rembrand could ship new capabilities far earlier in their development cycle.
Together, GKE and Cloud Run give Rembrand a unified, high-performance foundation for both training and inference. Rembrand sees Google Cloud as more than a provider. "Google Cloud finally gave us an environment that matches the ambition of our product," said Saad. "It's the first platform that keeps up with the kind of AI we're trying to build."
Rembrand is an AI-powered platform that uses generative models to place brands seamlessly into video content, creating context-aware media experiences for creators and advertisers.
Industry: Technology
Location: United States
Products: Google Kubernetes Engine (GKE), Dynamic Workload Scheduler (DWS), Cloud Run, Cloud Storage


















