
Achieves scalability by matching GPU usage precisely with workload requirements and avoiding over-provisioning
Improves data transfer and instance replication, reducing setup times and speeding up project turnaround
Increases training reliability, improves model quality and prevents disruptions
Saves 8 hours and over $45,000 in pre-training, fine-tuning, and labor costs — resulting in a 30% overall cost reduction
Pints.ai is a Singapore-based AI solutions provider that specializes in creating compact, high-performance Large Language Models (LLMs) for financial institutions. Using Google Cloud GPU instances and Vertex AI, Pints.ai designs a scalable infrastructure that reduces costs and accelerates time-to-market for its clients.
Pints.ai is a Singapore-based AI solutions provider that specializes in creating compact, high-performance Large Language Models (LLMs) for financial institutions. Using Google Cloud GPU instances and Vertex AI, Pints.ai designs a scalable infrastructure that reduces costs and accelerates time-to-market for its clients.
Tackling resource bottlenecks with modular GPU configurations
Privacy is one of the top concerns of financial institutions adopting AI technologies. Pints.ai, a Singapore-based AI startup, was founded to empower financial enterprises with Generative AI (GenAI) platforms with unmatched data privacy, security and operational efficiency.
During the early stages of development, resource limitations were a major issue. "We were trying various options, creating our own machines, but there were limitations in how powerful the GPU could be, which affected our ability to train or fine-tune larger models," explains Calvin Tan, CTO and Co-founder. With lower-cost services, reliability was also an issue: "We spent weeks training models, only for the service to crash, wasting time and money."
Data transfer bottlenecks during model training delayed project timelines. "Given the size of the data sets and models involved, moving data between instances and across regions was time-consuming and prone to errors," says Tan. Their previous infrastructure didn’t allow them to scale resources up or down in real time, which led to underutilisation or overprovisioning, neither of which was cost-effective.
After exploring several options, they chose Google Cloud for its wide range of GPU configurations and flexible infrastructure. "Google Cloud allows us to start with smaller GPUs like the Nvidia T4 or L4 and easily scale up to more powerful options like A100s or H100s, depending on our needs," says Tan. Google Cloud's reliability avoided the system failures they had experienced with other services, helping them to train models without disruptions, which saved time, resources and costs.
Google Cloud allows us to start with smaller GPUs like the Nvidia T4 or L4 and easily scale up to more powerful options like A100s or H100s, depending on our needs.
Calvin Tan
CTO and Co-founder, Pints.ai

Unlocking training, data management and labor savings
"Google Cloud offers a very high degree of flexibility, such as selecting the number of GPUs from 1 all the way up to 8. Previous cloud providers didn’t offer this level of granularity — forcing us to start with a fixed number of GPUs," explains Tan. Being restricted to a few types of instances led to wastage, as some stages of code development didn’t fully use the GPUs that came with the fixed instances. With Google, we can start small and scale up as required.
By modulating the wide array of GPUs available on Google Cloud, the company began generating savings, particularly with the workforce. Calculated on a per-training-run basis, these savings accumulated rapidly, given the multiple runs performed for each project. With Google Cloud’s flexible pricing models, Pints.ai saved $4,600 per run on pre-training and $1,900 on fine-tuning and alignment.
They also reduced the time spent on data preparation and machine setup by 5 hours per run, saving $25,000 in workforce cost. The optimization of the model transfer and evaluation process helped save an extra 3 hours per run, adding up to about $15,000 in labor savings. "In total, we’ve cut over 8 hours and saved more than $45,000 in pre-training, fine-tuning, and labor costs, giving us a 30% overall cost reduction," says Tan.
The data management tools from Google Cloud have been a real turning point for us. They’ve made moving models and data between instances so much easier, cutting down on time that would’ve been wasted on reinstallation and transfers. This has improved our workflow and helped us keep our projects on track.
Calvin Tan
CTO and Co-founder, Pints.ai
Google Cloud’s reliability has been a determining factor for the team — when it comes to training Large Language Models (LLMs), any interruption could wipe out months of work and resources. Google Cloud Storage and Persistent Disk provide the scalability and performance needed to handle the vast amounts of data involved in LLM training, from preparing datasets to managing model outputs. "The data management tools from Google Cloud have been a real turning point for us. They’ve made moving models and data between instances so much easier, cutting down on time that would’ve been wasted on reinstallation and transfers. This has improved our workflow and helped us keep our projects on track," says Tan.
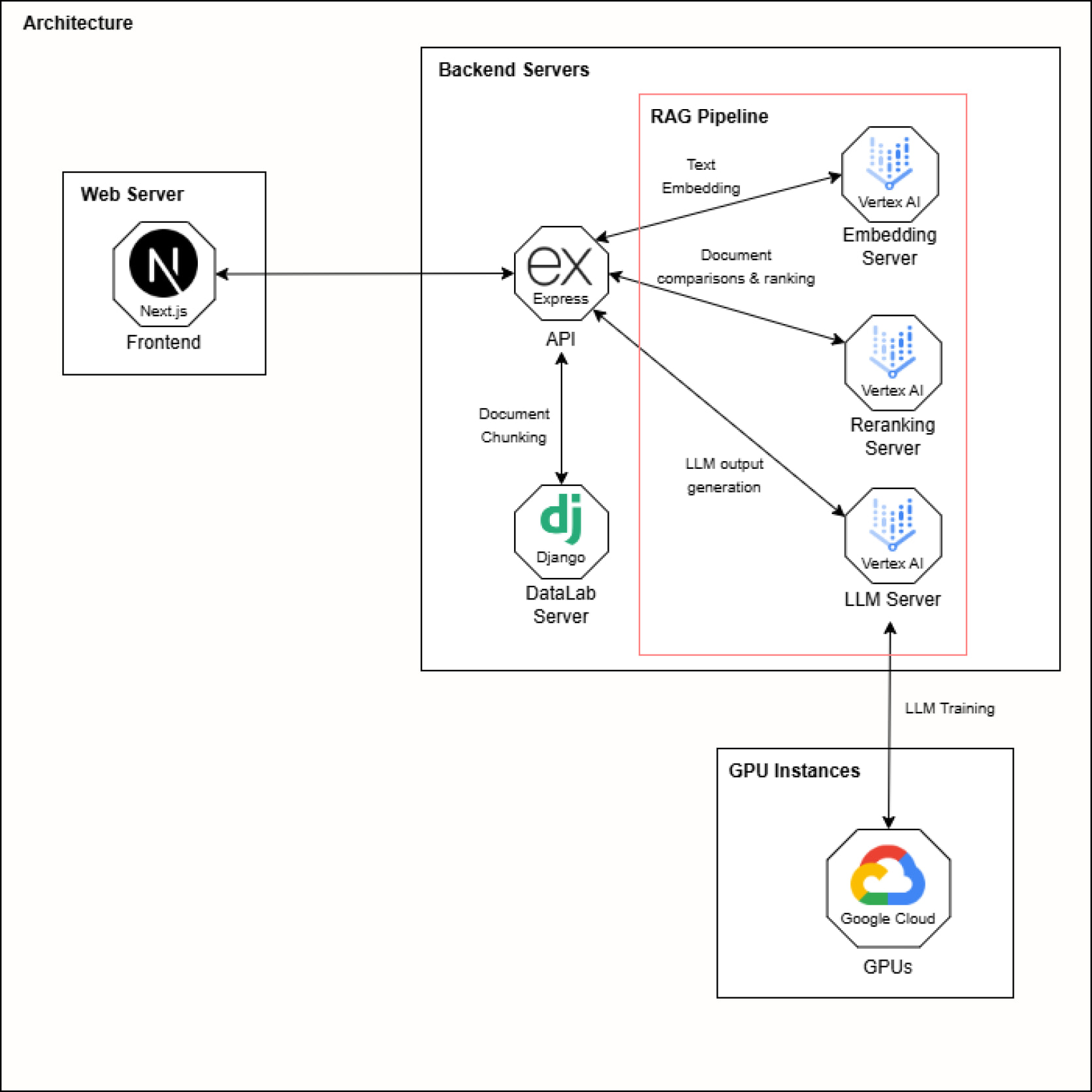
Optimizing workflows with Kubernetes, Vertex AI and Gemma Open Models
Pints.ai containerizes its machine learning models and runs them on Google Kubernetes Engine (GKE) to ensure consistent environments across development and production. Thanks to GKE’s scalability, Pints.ai can handle fluctuating demands without compromising on performance, while reducing the operational burden of managing infrastructure.
By integrating Vertex AI into its end-to-end machine learning pipeline, the company automates essential steps in model development, such as hyperparameter tuning — adjusting model parameters to improve performance — and model evaluation, which ensures the model’s accuracy and effectiveness before deployment. "Vertex AI has been instrumental in helping us deliver faster, more accurate, and tailored solutions that meet the unique needs of financial institutions. We also incorporate Retrieval-Augmented Generation (RAG) to allow financial professionals to query vast datasets and document repositories using natural language," says Tan.
Using Gemma Open Models alongside Google Cloud’s advanced GPUs, Tan’s team can train models faster and with better results. Gemma pre-trained models provide a head start for developing custom AI solutions, so they can focus on fine-tuning models specifically for financial use cases. Pints.ai made their open-source model, one and a half pints, publicly available as part of a research initiative. They provided all the necessary code, along with detailed instructions, so that users could easily train the model on Google Cloud in under 10 minutes. "The idea is not so much about replacing Gemma or Vertex AI, but offering an option for cases where general open-source models don’t satisfy specific needs. This is where our small model comes in, and you can do it too — it’s very easy to do on Google Cloud," says Tan.
Vertex AI has been instrumental in helping us deliver faster, more accurate, and tailored solutions that meet the unique needs of financial institutions. We also incorporate Retrieval-Augmented Generation (RAG) to allow financial professionals to query vast datasets and document repositories using natural language.
Calvin Tan
CTO and Co-founder, Pints.ai

Advancing AI through open knowledge
"Our collaboration with Google has been a key factor in building our generative AI capabilities. This partnership has provided incredible support and access to computational resources, which has become a pillar of our AI initiatives," says Tan. Moving forward, Pints.ai aims to deepen the collaboration with Google Cloud to further scale their AI operations. This includes increasing utilization as well as scaling up to more powerful instances provided by Google Cloud.
They have also made a commitment to actively share their experiences and insights with the broader community, starting with how they’ve used small model templates to empower other companies in building and optimizing their AI models. "Our goal is to contribute to the development of best practices in AI and cloud adoption, drawing on our successful implementation of Google Cloud," says Tan.
Our collaboration with Google has been a key factor in building our generative AI capabilities. This partnership has provided incredible support and access to computational resources, which has become a pillar of our AI initiatives.
Calvin Tan
CTO and Co-founder, Pints.ai

Pints.ai provides an on-prem plug-n-play AI solution tailored for financial institutions, ensuring utmost confidentiality and secure handling of data. Merging the strengths of their proprietary large model, with industry-specific features, its Neuron AI is pre-trained in financial knowledge and seamlessly integrates with clients' sensitive data. They swiftly empower financial entities, from retail banks to fintech startups, enhancing sales and operations for a competitive, secure advantage.
Industry: Financial Services
Location: Singapore
Products: Google Cloud AI Infrastructure, Cloud GPUs, Kubernetes Engine (GKE), Vertex AI, Retrieval-Augmented Generation (RAG), Gemma Open Models, Cloud Storage, Persistent Disks


















