Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Auf dieser Seite wird beschrieben, wie Sie mit KubernetesPodOperator Kubernetes-Pods von Cloud Composer in den Google Kubernetes Engine-Cluster Ihrer Cloud Composer-Umgebung bereitstellen.
KubernetesPodOperator startet Kubernetes-Pods im Cluster Ihrer Umgebung. Mit Google Kubernetes Engine-Operatoren werden dagegen Kubernetes-Pods in einem bestimmten Cluster ausgeführt. Dabei kann es sich um einen separaten Cluster handeln, der nicht mit Ihrer Umgebung in Verbindung steht. Sie können Cluster auch mit Google Kubernetes Engine-Operatoren erstellen und löschen.
KubernetesPodOperator ist eine gute Option, wenn Sie Folgendes benötigen:
- Benutzerdefinierte Python-Abhängigkeiten, die nicht über das öffentliche PyPI-Repository verfügbar sind.
- Binäre Abhängigkeiten, die im Cloud Composer-Worker-Image nicht verfügbar sind.
Hinweis
- Wir empfehlen die Verwendung der neuesten Version von Cloud Composer. Diese Version muss mindestens im Rahmen der Einstellungs- und Supportrichtlinie unterstützt werden.
- Es müssen genügend Ressourcen für die Umgebung verfügbar sein. Das Starten von Pods in einer Umgebung mit zu wenigen Ressourcen kann zu Airflow-Worker- und Airflow-Planer-Fehlern führen.
Ressourcen der Cloud Composer-Umgebung einrichten
Wenn Sie eine Cloud Composer-Umgebung erstellen, geben Sie deren Leistungsparameter an, einschließlich der Leistungsparameter für den Cluster der Umgebung. Das Starten von Kubernetes-Pods im Umgebungscluster kann zu Konflikten bei Clusterressourcen wie CPU oder Arbeitsspeicher führen. Da sich der Airflow-Planer und die Airflow-Worker im selben GKE-Cluster befinden, funktionieren Planer und Worker nicht ordnungsgemäß, wenn diese Konkurrenzsituation einen Ressourcenmangel verursacht.
Führen Sie eine oder mehrere der folgenden Aktionen aus, um einen Ressourcenmangel zu verhindern:
- (Empfohlen) Knotenpool erstellen
- Anzahl der Knoten in der Umgebung erhöhen
- Entsprechenden Maschinentyp angeben
Knotenpool erstellen
Die bevorzugte Methode zum Verhindern eines Ressourcenmangels in der Cloud Composer-Umgebung besteht darin, einen neuen Knotenpool zu erstellen und Kubernetes-Pods so zu konfigurieren, dass sie bei der Ausführung nur Ressourcen aus diesem Pool verwenden.
Console
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Klicken Sie auf den Namen Ihrer Umgebung.
Wechseln Sie auf der Seite Umgebungsdetails zum Tab Umgebungskonfiguration.
Klicken Sie im Bereich Ressourcen > GKE-Cluster auf den Link Clusterdetails aufrufen.
Erstellen Sie einen Knotenpool, wie unter Knotenpool hinzufügen beschrieben.
gcloud
Bestimmen Sie den Namen des Umgebungsclusters:
gcloud composer environments describe ENVIRONMENT_NAME \ --location LOCATION \ --format="value(config.gkeCluster)"Ersetzen Sie:
ENVIRONMENT_NAMEdurch den Namen der Umgebung.LOCATIONdurch die Region, in der sich die Umgebung befindet.
Die Ausgabe enthält den Namen des Clusters Ihrer Umgebung. Dies kann beispielsweise
europe-west3-example-enviro-af810e25-gkesein.Erstellen Sie einen Knotenpool, wie unter Knotenpool hinzufügen beschrieben.
Anzahl der Knoten in der Umgebung erhöhen
Wenn Sie die Anzahl der Knoten in der Cloud Composer-Umgebung erhöhen, steht den Arbeitslasten mehr Rechenleistung zur Verfügung. Durch diese Erhöhung werden keine zusätzlichen Ressourcen für Aufgaben bereitgestellt, die mehr CPU oder RAM benötigen, als der angegebene Maschinentyp bietet.
Zum Erhöhen der Knotenanzahl aktualisieren Sie die Umgebung.
Geeigneten Maschinentyp angeben
Wenn Sie die Cloud Composer-Umgebung erstellen, können Sie einen Maschinentyp angeben. Damit immer genug Ressourcen verfügbar sind, sollten Sie einen Maschinentyp für die Art von Computing angeben, das in Ihrer Cloud Composer-Umgebung ausgeführt wird.
Minimalkonfiguration
Zum Erstellen eines KubernetesPodOperator sind nur die Pod-Parameter name, image und task_id erforderlich. Die /home/airflow/composer_kube_config enthält Anmeldedaten für die Authentifizierung bei GKE.
Airflow 2
Airflow 1
Pod-Affinitätskonfiguration
Mit der Konfiguration des Parameters affinity in KubernetesPodOperator können Sie steuern, auf welchen Knoten Pods geplant werden sollen, beispielsweise nur auf Knoten in einem bestimmten Knotenpool. In diesem Beispiel wird der Operator nur in Knotenpools namens pool-0 und pool-1 ausgeführt. Da sich Ihre Cloud Composer 1-Umgebungsknoten im default-pool befinden, werden Ihre Pods nicht auf den Knoten in Ihrer Umgebung ausgeführt.
Airflow 2
Airflow 1
Da das Beispiel so konfiguriert ist, schlägt die Aufgabe fehl. Aus den Logs geht hervor, dass die Aufgabe fehlschlägt, weil die Knotenpools pool-0 und pool-1 nicht vorhanden sind.
Damit die Knotenpools in values zu finden sind, nehmen Sie eine der folgenden Konfigurationsänderungen vor:
Wenn Sie einen Knotenpool zuvor erstellt haben, ersetzen Sie
pool-0undpool-1durch die Namen Ihrer Knotenpools. Laden Sie dann Ihren DAG noch einmal hoch.Erstellen Sie einen Knotenpool namens
pool-0oderpool-1. Sie können beide erstellen, zur erfolgreichen Ausführung der Aufgabe ist aber nur einer erforderlich.Ersetzen Sie
pool-0undpool-1durchdefault-pool. Dies ist der von Airflow verwendete Standardpool. Laden Sie dann Ihren DAG noch einmal hoch.
Warten Sie nach den Änderungen einige Minuten, bis die Umgebung aktualisiert wurde.
Führen Sie dann die Aufgabe ex-pod-affinity noch einmal aus und prüfen Sie, ob die Aufgabe ex-pod-affinity erfolgreich ausgeführt wurde.
Zusätzliche Konfiguration
In diesem Beispiel sind zusätzliche Parameter zu sehen, die Sie im KubernetesPodOperator konfigurieren können.
Weitere Informationen finden Sie in den folgenden Ressourcen:
Informationen zur Verwendung von Kubernetes-Secrets und ConfigMaps finden Sie unter Kubernetes-Secrets und ConfigMaps verwenden.
Informationen zur Verwendung von Jinja-Vorlagen mit KubernetesPodOperator finden Sie unter Jinja-Vorlagen verwenden.
Informationen zu den Parametern von KubernetesPodOperator finden Sie in der Referenz für den Operator in der Airflow-Dokumentation.
Airflow 2
Airflow 1
Jinja-Vorlagen verwenden
Airflow unterstützt Jinja-Vorlagen in DAGs.
Sie müssen die erforderlichen Airflow-Parameter (task_id, name und image) mit dem Operator deklarieren. Wie im folgenden Beispiel gezeigt, können Sie alle anderen Parameter mit Jinja als Vorlage verwenden, einschließlich cmds, arguments, env_vars und config_file.
Der Parameter env_vars wird im Beispiel über eine Airflow-Variable namens my_value festgelegt. Der Beispiel-DAG bezieht seinen Wert aus der Vorlagenvariablen vars in Airflow. Airflow bietet mehr Variablen, die Zugriff auf verschiedene Arten von Informationen bieten. So können Sie beispielsweise mit der Vorlagenvariablen conf auf Werte der Airflow-Konfigurationsoptionen zugreifen. Weitere Informationen und eine Liste der in Airflow verfügbaren Variablen finden Sie in der Airflow-Dokumentation unter Referenz zu Vorlagen.
Ohne den DAG zu ändern oder die Variable env_vars zu erstellen, schlägt die Aufgabe ex-kube-templates im Beispiel fehl, da die Variable nicht vorhanden ist. Erstellen Sie diese Variable in der Airflow-Benutzeroberfläche oder mit der Google Cloud CLI:
Airflow-UI
Rufen Sie die Airflow-UI auf.
Klicken Sie in der Symbolleiste auf Verwaltung > Variablen.
Klicken Sie auf der Seite Listenvariable auf Neuen Eintrag hinzufügen.
Geben Sie auf der Seite Add Variable (Variable hinzufügen) die folgenden Informationen ein:
- Key:
my_value - Val:
example_value
- Key:
Klicken Sie auf Speichern.
Wenn in Ihrer Umgebung Airflow 1 verwendet wird, führen Sie stattdessen den folgenden Befehl aus:
Rufen Sie die Airflow-UI auf.
Klicken Sie in der Symbolleiste auf Admin > Variables.
Klicken Sie auf der Seite Variablen auf den Tab Erstellen.
Geben Sie auf der Seite Variable die folgenden Informationen ein:
- Key:
my_value - Val:
example_value
- Key:
Klicken Sie auf Speichern.
gcloud
Geben Sie den folgenden Befehl ein:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
Wenn in Ihrer Umgebung Airflow 1 verwendet wird, führen Sie stattdessen den folgenden Befehl aus:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables -- \
--set my_value example_value
Ersetzen Sie:
ENVIRONMENTdurch den Namen der Umgebung.LOCATIONdurch die Region, in der sich die Umgebung befindet.
Das folgende Beispiel zeigt, wie Jinja-Vorlagen mit KubernetesPodOperator verwendet werden:
Airflow 2
Airflow 1
Kubernetes-Secrets und ConfigMaps verwenden
Ein Kubernetes-Secret ist ein Objekt, das sensible Daten enthält. Eine Kubernetes-ConfigMap ist ein Objekt, das nicht vertrauliche Daten in Schlüssel/Wert-Paaren enthält.
In Cloud Composer 2 können Sie Secrets und ConfigMaps mit der Google Cloud CLI, der API oder Terraform erstellen und dann über KubernetesPodOperator darauf zugreifen.
YAML-Konfigurationsdateien
Wenn Sie ein Kubernetes-Secret oder ein ConfigMap mit der Google Cloud CLI und API erstellen, müssen Sie eine Datei im YAML-Format angeben. Diese Datei muss demselben Format entsprechen wie bei Kubernetes-Secrets und ConfigMaps. Die Kubernetes-Dokumentation enthält viele Codebeispiele für ConfigMaps und Secrets. Sehen Sie sich als Erstes die Seite Anmeldedaten mit Secrets sicher verteilen und ConfigMaps an.
Wie bei Kubernetes-Secrets sollten Sie die Base64-Darstellung verwenden, wenn Sie Werte in Secrets definieren.
Sie können einen Wert mit dem folgenden Befehl codieren. Dies ist eine von vielen Möglichkeiten, einen base64-codierten Wert zu erhalten:
echo "postgresql+psycopg2://root:example-password@127.0.0.1:3306/example-db" -n | base64
Ausgabe:
cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Die folgenden beiden YAML-Dateibeispiele werden später in diesem Leitfaden in Beispielen verwendet. Beispiel für eine YAML-Konfigurationsdatei für ein Kubernetes-Secret:
apiVersion: v1
kind: Secret
metadata:
name: airflow-secrets
data:
sql_alchemy_conn: cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Ein weiteres Beispiel, das zeigt, wie Dateien eingefügt werden. Wie im vorherigen Beispiel: Codieren Sie zuerst den Inhalt einer Datei (cat ./key.json | base64) und geben Sie diesen Wert dann in der YAML-Datei an:
apiVersion: v1
kind: Secret
metadata:
name: service-account
data:
service-account.json: |
ewogICJ0eXBl...mdzZXJ2aWNlYWNjb3VudC5jb20iCn0K
Beispiel für eine YAML-Konfigurationsdatei für eine ConfigMap. Sie müssen die Base64-Darstellung in ConfigMaps nicht verwenden:
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
example_key: example_value
Kubernetes-Secrets verwalten
In Cloud Composer 2 erstellen Sie Secrets mit der Google Cloud CLI und kubectl:
Informationen zum Cluster Ihrer Umgebung abrufen:
Führen Sie dazu diesen Befehl aus:
gcloud composer environments describe ENVIRONMENT \ --location LOCATION \ --format="value(config.gkeCluster)"Ersetzen Sie:
ENVIRONMENTdurch den Namen Ihrer Umgebung.LOCATIONdurch die Region, in der sich die Cloud Composer-Umgebung befindet.
Die Ausgabe dieses Befehls hat das folgende Format:
projects/<your-project-id>/zones/<zone-of-composer-env>/clusters/<your-cluster-id>.Zum Abrufen der GKE-Cluster-ID kopieren Sie die Ausgabe nach
/clusters/(endet auf-gke).Zum Abrufen der Zone kopieren Sie die Ausgabe nach
/zones/.
Stellen Sie mit folgendem Befehl eine Verbindung zum GKE-Cluster her:
gcloud container clusters get-credentials CLUSTER_ID \ --project PROJECT \ --zone ZONEErsetzen Sie:
CLUSTER_ID: die Cluster-ID der Umgebung.PROJECT_ID: die Projekt-ID.ZONEdurch die Zone, in der sich der Cluster der Umgebung befindet.
Erstellen Sie Kubernetes-Secrets:
Die folgenden Befehle veranschaulichen zwei unterschiedliche Ansätze zum Erstellen von Kubernetes-Secrets. Der Ansatz
--from-literalverwendet Schlüssel/Wert-Paare. Der Ansatz--from-fileverwendet Dateiinhalte.Führen Sie den folgenden Befehl aus, um ein Kubernetes-Secret mithilfe von Schlüssel/Wert-Paaren zu erstellen. In diesem Beispiel wird ein Secret mit dem Namen
airflow-secretserstellt, das einsql_alchemy_conn-Feld mit dem Werttest_valueenthält.kubectl create secret generic airflow-secrets \ --from-literal sql_alchemy_conn=test_valueFühren Sie den folgenden Befehl aus, um ein Kubernetes-Secret mithilfe des Dateiinhalts zu erstellen. In diesem Beispiel wird ein Secret mit dem Namen
service-accounterstellt, das das Feldservice-account.jsonmit dem Wert aus dem Inhalt einer lokalen./key.json-Datei enthält.kubectl create secret generic service-account \ --from-file service-account.json=./key.json
Kubernetes-Secrets in DAGs verwenden
Dieses Beispiel zeigt zwei Möglichkeiten für die Verwendung von Kubernetes Secrets: als Umgebungsvariable und als vom Pod bereitgestelltes Volume.
Das erste Secret, airflow-secrets, ist auf eine Kubernetes-Umgebungsvariable namens SQL_CONN festgelegt (nicht auf eine Airflow- oder Cloud Composer-Umgebungsvariable).
Das zweite Secret, service-account, stellt service-account.json, eine Datei mit einem Dienstkontotoken, in /var/secrets/google bereit.
Die Secret-Objekte sehen so aus:
Airflow 2
Airflow 1
Der Name des ersten Kubernetes-Secrets wird in der Variablen secret_env definiert.
Dieses Secret heißt airflow-secrets. Der Parameter deploy_type gibt an, dass er als Umgebungsvariable verfügbar gemacht werden muss. Der Name der Umgebungsvariablen lautet SQL_CONN, wie im Parameter deploy_target angegeben. Schließlich wird der Wert der Umgebungsvariablen SQL_CONN auf den Wert des Schlüssels sql_alchemy_conn festgelegt.
Der Name des zweiten Kubernetes-Secrets wird in der Variablen secret_volume definiert. Dieses Secret heißt service-account. Es wird als Volume bereitgestellt, wie im Parameter deploy_type angegeben. Der Pfad der bereitzustellenden Datei (deploy_target) lautet /var/secrets/google. Schließlich lautet der key des Secrets, das in deploy_target gespeichert ist, service-account.json.
Die Operatorkonfiguration sieht so aus:
Airflow 2
Airflow 1
Informationen zum CNCF-Kubernetes-Anbieter
KubernetesPodOperator ist im apache-airflow-providers-cncf-kubernetes-Anbieter implementiert.
Ausführliche Versionshinweise für CNCF-Kubernetes-Anbieter finden Sie auf der Website des CNCF-Kubernetes-Anbieters.
Version 6.0.0
In Version 6.0.0 des CNCF Kubernetes-Anbieterpakets wird die kubernetes_default-Verbindung standardmäßig in KubernetesPodOperator verwendet.
Wenn Sie in Version 5.0.0 eine benutzerdefinierte Verbindung angegeben haben, wird diese vom Betreiber weiterhin verwendet. Wenn Sie wieder zur kubernetes_default-Verbindung zurückkehren möchten, sollten Sie Ihre DAGs entsprechend anpassen.
Version 5.0.0
Diese Version führt im Vergleich zu Version 4.4.0 einige nicht abwärtskompatible Änderungen ein. Die wichtigsten betreffen die kubernetes_default-Verbindung, die in Version 5.0.0 nicht verwendet wird.
- Die
kubernetes_default-Verbindung muss geändert werden. Der Kubernetes-Konfigurationspfad muss auf/home/airflow/composer_kube_configfestgelegt sein (wie in der folgenden Abbildung dargestellt). Alternativ mussconfig_fileder KubernetesPodOperator-Konfiguration hinzugefügt werden (siehe folgendes Codebeispiel).
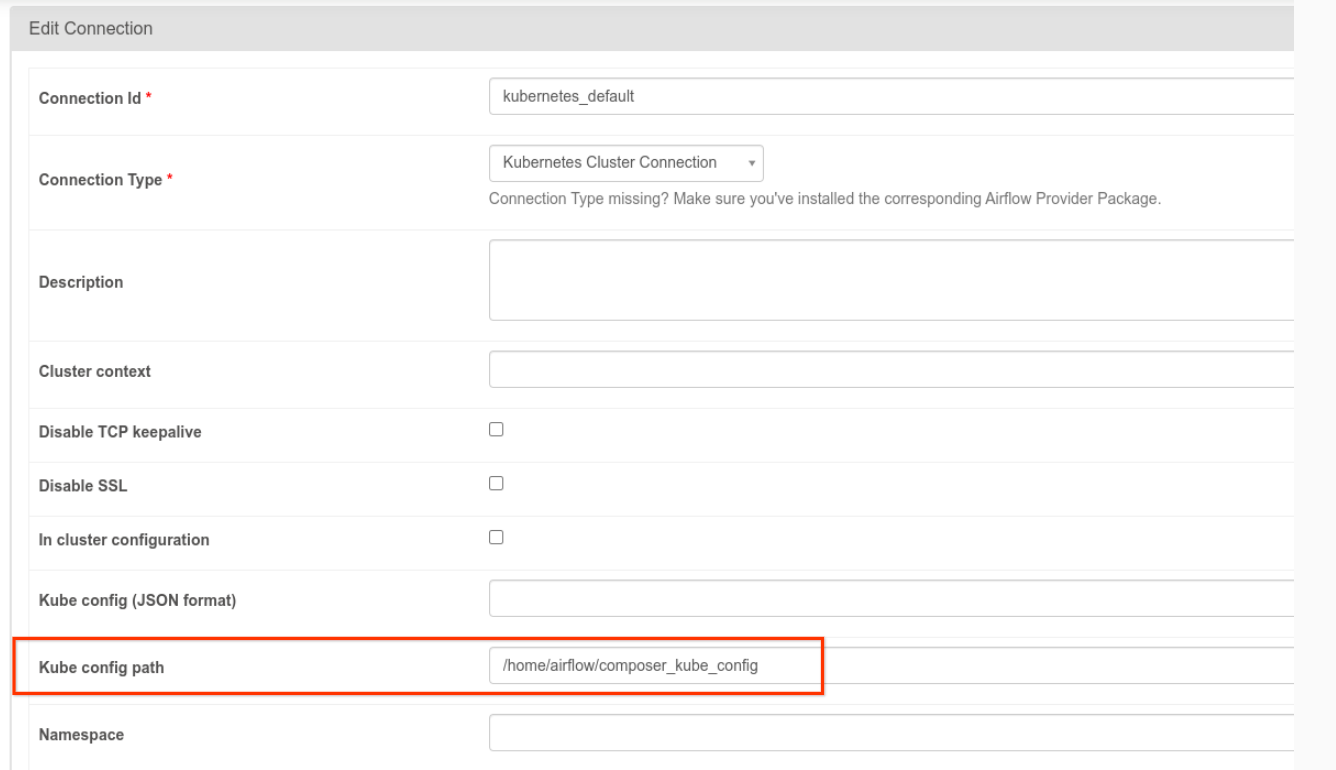
- Ändern Sie den Code einer Aufgabe mit KubernetesPodOperator so:
KubernetesPodOperator(
# config_file parameter - can be skipped if connection contains this setting
config_file="/home/airflow/composer_kube_config",
# definition of connection to be used by the operator
kubernetes_conn_id='kubernetes_default',
...
)
Weitere Informationen zu Version 5.0.0 finden Sie in den Versionshinweisen des CNCF Kubernetes-Anbieters.
Fehlerbehebung
In diesem Abschnitt finden Sie Tipps zur Behebung häufiger Probleme mit KubernetesPodOperator:
Logs ansehen
Prüfen Sie bei der Fehlerbehebung die Protokolle in der folgenden Reihenfolge:
Airflow-Task-Logs:
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Klicken Sie in der Liste der Umgebungen auf den Namen Ihrer Umgebung. Die Seite Umgebungsdetails wird geöffnet.
Rufen Sie den Tab DAGs auf.
Klicken Sie auf den Namen des DAG und dann auf die DAG-Ausführung, um die Details und Protokolle aufzurufen.
Airflow-Planer-Logs:
Rufen Sie die Seite Umgebungsdetails auf.
Rufen Sie den Tab Protokolle auf.
Prüfen Sie die Logs des Airflow-Planers.
Pod-Logs in der Google Cloud Console unter „GKE-Arbeitslasten“. Diese Logs enthalten die YAML-Datei der Pod-Definition, Pod-Ereignisse und Pod-Details.
Rückgabecodes ungleich null
Wenn Sie KubernetesPodOperator (und GKEStartPodOperator) verwenden, bestimmt der Rückgabecode des Einstiegspunkts des Containers, ob die Aufgabe als erfolgreich betrachtet wird oder nicht. Rückgabecodes mit einem Wert ungleich null weisen auf einen Fehler hin.
Ein gängiges Muster besteht darin, ein Shell-Script als Container-Einstiegspunkt auszuführen, um mehrere Vorgänge innerhalb des Containers zusammenzufassen.
Wenn Sie ein solches Skript schreiben, sollten Sie den Befehl set -e oben im Skript einfügen, sodass fehlgeschlagene Befehle im Skript das Skript beenden und den Fehler an die Airflow-Aufgabeninstanz weiterleiten.
Pod-Zeitüberschreitungen
Das Standardzeitlimit für KubernetesPodOperator beträgt 120 Sekunden. Dies kann zu Zeitüberschreitungen führen, bevor größere Images heruntergeladen sind. Sie können das Zeitlimit erhöhen, wenn Sie beim Erstellen des KubernetesPodOperators den Parameter startup_timeout_seconds ändern.
Wenn eine Pod-Zeitüberschreitung auftritt, ist das aufgabenspezifische Log in der Airflow-UI verfügbar. Beispiel:
Executing <Task(KubernetesPodOperator): ex-all-configs> on 2018-07-23 19:06:58.133811
Running: ['bash', '-c', u'airflow run kubernetes-pod-example ex-all-configs 2018-07-23T19:06:58.133811 --job_id 726 --raw -sd DAGS_FOLDER/kubernetes_pod_operator_sample.py']
Event: pod-name-9a8e9d06 had an event of type Pending
...
...
Event: pod-name-9a8e9d06 had an event of type Pending
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 27, in <module>
args.func(args)
File "/usr/local/lib/python2.7/site-packages/airflow/bin/cli.py", line 392, in run
pool=args.pool,
File "/usr/local/lib/python2.7/site-packages/airflow/utils/db.py", line 50, in wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/airflow/models.py", line 1492, in _run_raw_task
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/site-packages/airflow/contrib/operators/kubernetes_pod_operator.py", line 123, in execute
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
airflow.exceptions.AirflowException: Pod Launching failed: Pod took too long to start
Pod-Zeitüberschreitungen können auch auftreten, wenn das Cloud Composer-Dienstkonto nicht die erforderlichen IAM-Berechtigungen zum Ausführen der jeweiligen Aufgabe hat. Das können Sie prüfen, wenn Sie sich in den GKE-Dashboards die Fehler auf Pod-Ebene in den Logs für die jeweilige Arbeitslast ansehen oder Cloud Logging verwenden.
Neue Verbindung konnte nicht hergestellt werden
Automatische Upgrades sind in GKE-Clustern standardmäßig aktiviert. Wenn sich ein Knotenpool in einem Cluster befindet, für den gerade ein Upgrade durchgeführt wird, sehen Sie möglicherweise die folgende Fehlermeldung:
<Task(KubernetesPodOperator): gke-upgrade> Failed to establish a new
connection: [Errno 111] Connection refused
Wenn Sie prüfen möchten, ob der Cluster aktualisiert wird, rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf und suchen nach dem Ladesymbol neben dem Clusternamen Ihrer Umgebung.