Cloud Composer 1 Cloud Composer 2
Auf dieser Seite wird beschrieben, wie Sie mit DataflowTemplateOperator Dataflow-Pipelines aus Cloud Composer starten.
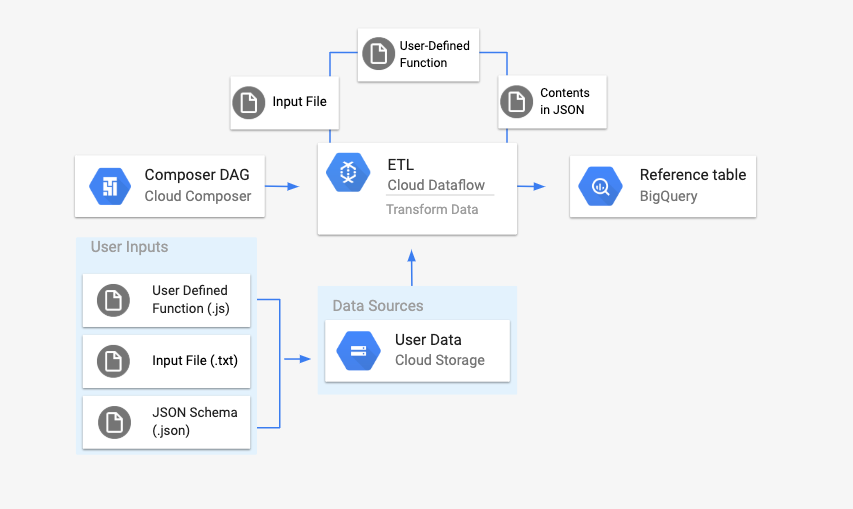
Die Pipeline von Cloud Storage Text für BigQuery ist eine Batchpipeline, mit der Sie in Cloud Storage gespeicherte Textdateien hochladen, sie mit einer von Ihnen bereitgestellten benutzerdefinierten JavaScript-Funktion (User Defined Function, UDF) transformieren und die Ergebnisse in BigQuery ausgeben können.
Überblick
Bevor Sie den Workflow starten, erstellen Sie die folgenden Entitäten:
Eine leere BigQuery-Tabelle aus einem leeren Dataset, die die folgenden Spalten mit Informationen enthält:
location,average_temperature,monthund optionalinches_of_rain,is_currentundlatest_measurement.Eine JSON-Datei, die die Daten aus der Datei
.txtin das richtige Format für das Schema der BigQuery-Tabelle normalisiert. Das JSON-Objekt hat ein Array vonBigQuery Schema, wobei jedes Objekt einen Spaltennamen, einen Eingabetyp und ein Pflichtfeld enthält.Eine
.txt-Eingabedatei mit den Daten, die im Batch in die BigQuery-Tabelle hochgeladen werden.Eine in JavaScript geschriebene benutzerdefinierte Funktion, die jede Zeile der
.txt-Datei in die für unsere Tabelle relevanten Variablen umwandelt.Eine Airflow-DAG-Datei, die auf den Speicherort dieser Dateien verweist.
Als Nächstes laden Sie die Datei
.txt, die UDF-Datei.jsund die Schemadefinition.jsonin einen Cloud Storage-Bucket hoch. Außerdem laden Sie den DAG in Ihre Cloud Composer-Umgebung hoch.Nachdem der DAG hochgeladen wurde, führt Airflow eine Aufgabe daraus aus. In dieser Aufgabe wird eine Dataflow-Pipeline gestartet, die die benutzerdefinierte Funktion auf die Datei
.txtanwendet und gemäß dem JSON-Schema formatiert.Schließlich werden die Daten in die BigQuery-Tabelle hochgeladen, die Sie zuvor erstellt haben.
Hinweise
- Zum Schreiben der benutzerdefinierten Funktion müssen Sie mit JavaScript vertraut sein.
- In diesem Leitfaden wird davon ausgegangen, dass Sie bereits eine Cloud Composer-Umgebung haben. Informationen zum Erstellen einer Umgebung finden Sie unter Umgebung erstellen. Sie können jede Version von Cloud Composer mit dieser Anleitung verwenden.
-
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Leere BigQuery-Tabelle mit einer Schemadefinition erstellen
Erstellen Sie eine BigQuery-Tabelle mit einer Schemadefinition. Sie verwenden diese Schemadefinition später in diesem Leitfaden. Diese BigQuery-Tabelle enthält die Ergebnisse des Batch-Uploads.
So erstellen Sie eine leere Tabelle mit einer Schemadefinition:
Console
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf:
Maximieren Sie im Navigationsbereich im Abschnitt Ressourcen Ihr Projekt.
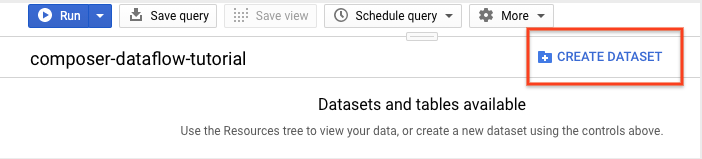
Klicken Sie im Detailbereich auf Dataset erstellen.
Geben Sie dem Dataset auf der Seite „Dataset erstellen“ im Abschnitt Dataset-ID den Namen
average_weather. Belassen Sie alle anderen Felder in ihrem Standardwert.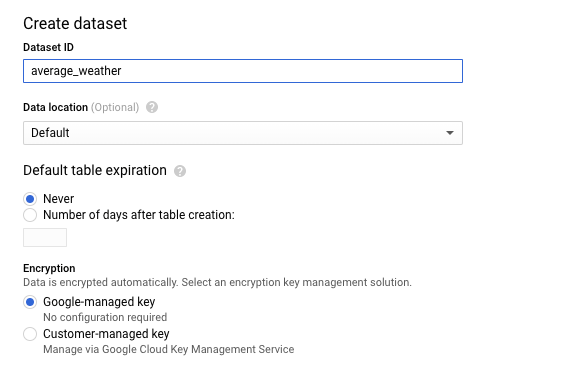
Klicken Sie auf Dataset erstellen.
Kehren Sie zum Navigationsbereich zurück und maximieren Sie im Abschnitt Ressourcen Ihr Projekt. Klicken Sie dann auf das Dataset
average_weather.Klicken Sie im Detailfeld auf Tabelle erstellen.
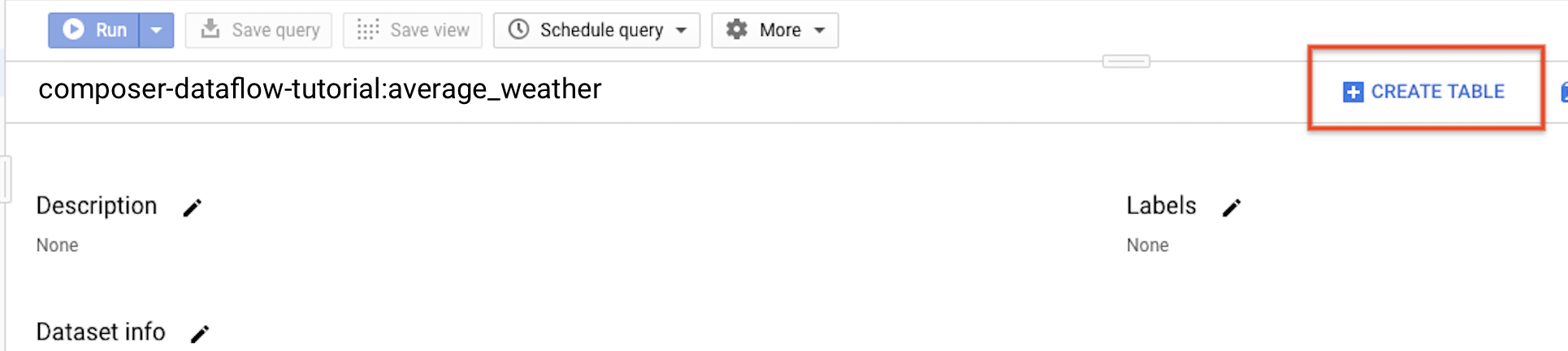
Wählen Sie auf der Seite Tabelle erstellen im Abschnitt Quelle die Option Leere Tabelle aus.
Gehen Sie auf der Seite Tabelle erstellen im Abschnitt Ziel folgendermaßen vor:
Wählen Sie für Dataset-Name das Dataset
average_weatheraus.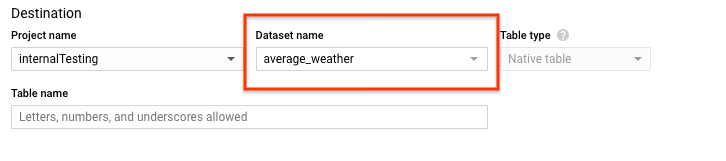
Geben Sie im Feld Tabellenname den Namen
average_weatherein.Achten Sie darauf, dass der Tabellentyp auf Native Tabelle eingestellt ist.
Geben Sie im Abschnitt Schema die Schemadefinition ein. Sie haben folgende Möglichkeiten:
Geben Sie Schemainformationen manuell ein. Aktivieren Sie dazu Als Text bearbeiten und geben Sie das Tabellenschema als JSON-Array ein. Füllen Sie die folgenden Felder aus:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Verwenden Sie Feld hinzufügen, um das Schema manuell einzugeben:
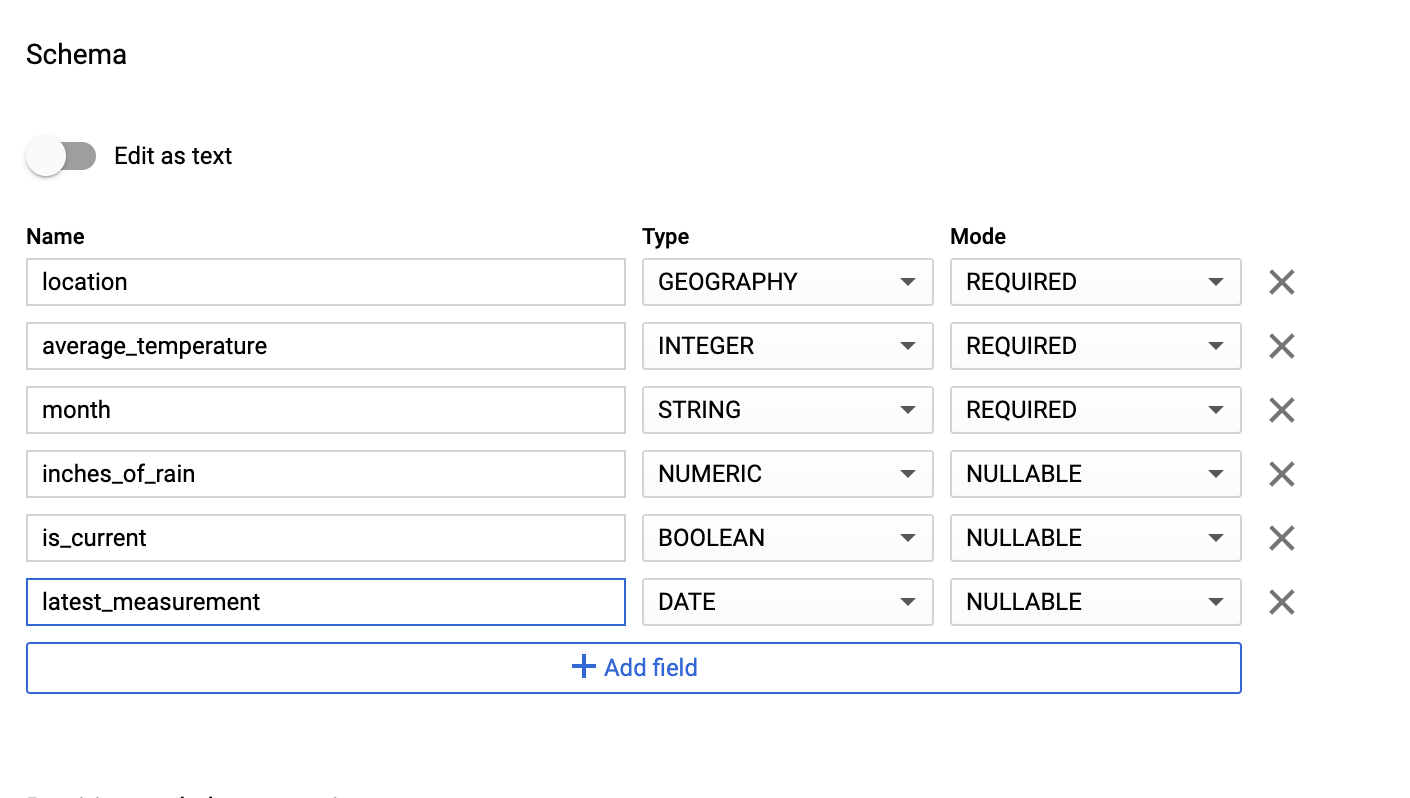
Behalten Sie für Partitions- und Clustereinstellungen den Standardwert
No partitioningbei.Übernehmen Sie im Abschnitt Erweiterte Optionen für Verschlüsselung den Standardwert
Google-managed key.Klicken Sie auf Tabelle erstellen.
bq
Erstellen Sie mit dem Befehl bq mk ein leeres Dataset und eine Tabelle in diesem Dataset.
Führen Sie den folgenden Befehl aus, um ein Dataset mit Informationen zum durchschnittlichen globalen Wetter zu erstellen:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Ersetzen Sie Folgendes:
LOCATION: die Region, in der sich die Umgebung befindet.PROJECT_ID: die Projekt-ID
Führen Sie den folgenden Befehl aus, um eine leere Tabelle in diesem Dataset mit der Schemadefinition zu erstellen:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Nachdem die Tabelle erstellt wurde, können Sie die Ablaufzeit, die Beschreibung und die Labels der Tabelle aktualisieren. Ebenso können Sie die Schemadefinition ändern.
Python
Speichern Sie diesen Code als dataflowtemplateoperator_create_dataset_and_table_helper.py und aktualisieren Sie die darin enthaltenen Variablen entsprechend Ihrem Projekt und Ihrem Speicherort. Führen Sie ihn dann mit dem folgenden Befehl aus:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Cloud Storage-Bucket erstellen
Erstellen Sie einen Bucket, der alle für den Workflow erforderlichen Dateien enthält. Der DAG, den Sie später in diesem Leitfaden erstellen, verweist auf die Dateien, die Sie in diesen Storage-Bucket hochladen. So erstellen Sie einen neuen Storage-Bucket:
Console
Öffnen Sie Cloud Storage in der Google Cloud Console.
Klicken Sie auf Bucket erstellen, um das Formular zum Erstellen eines Buckets zu öffnen.
Geben Sie die Bucket-Informationen ein und klicken Sie zum Ausführen der einzelnen Schritte jeweils auf Weiter:
Geben Sie einen global eindeutigen Namen für den Bucket an. In dieser Anleitung wird
bucketNameals Beispiel verwendet.Wählen Sie Region als Standorttyp aus. Wählen Sie als Nächstes einen Standort aus, an dem die Bucket-Daten gespeichert werden sollen.
Wählen Sie Standard als Standard-Speicherklasse für Ihre Daten aus.
Wählen Sie Einheitliche Zugriffssteuerung für den Zugriff auf Ihre Objekte aus.
Klicken Sie auf Fertig.
gsutil
Führen Sie den Befehl gsutil mb aus:
gsutil mb gs://bucketName/
Ersetzen Sie Folgendes:
bucketName: der Name des Buckets, den Sie zuvor in dieser Anleitung erstellt haben.
Codebeispiele
C#
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Ruby
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
BigQuery-Schema im JSON-Format für Ihre Ausgabetabelle erstellen
Erstellen Sie eine JSON-formatierte BigQuery-Schemadatei, die der zuvor erstellten Ausgabetabelle entspricht. Die Feldnamen, -typen und -modi müssen den zuvor in Ihrem BigQuery-Tabellenschema definierten Namen entsprechen. Diese Datei normalisiert die Daten aus der Datei .txt in ein Format, das mit Ihrem BigQuery-Schema kompatibel ist. Nennen Sie diese Datei jsonSchema.json.
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
JavaScript-Datei zur Datenformatierung erstellen
In dieser Datei definieren Sie Ihre UDF (User Defined Function), die die Logik zum Transformieren der Textzeilen in Ihrer Eingabedatei bereitstellt. Beachten Sie, dass diese Funktion jede Textzeile in Ihrer Eingabedatei als eigenes Argument verwendet. Die Funktion wird also einmal für jede Zeile der Eingabedatei ausgeführt. Nennen Sie diese Datei transformCSVtoJSON.js.
Eingabedatei erstellen
Diese Datei enthält die Informationen, die Sie in Ihre BigQuery-Tabelle hochladen möchten. Kopieren Sie diese Datei lokal und nennen Sie sie inputFile.txt.
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Dateien in den Bucket hochladen
Laden Sie die folgenden Dateien in den Cloud Storage-Bucket hoch, den Sie zuvor erstellt haben:
- JSON-formatiertes BigQuery-Schema (
.json) - Benutzerdefinierte JavaScript-Funktion (
transformCSVtoJSON.js) Die Eingabedatei für den zu verarbeitenden Text (
.txt)
Console
- Wechseln Sie in der Cloud Console zur Seite Cloud Storage-Buckets.
Klicken Sie in der Liste der Buckets auf Ihren Bucket.
Führen Sie auf dem Tab „Objekte“ für den Bucket einen der folgenden Schritte aus:
Fügen Sie die gewünschten Dateien per Drag-and-drop von Ihrem Desktop oder Dateimanager in den Hauptbereich der Google Cloud Console.
Klicken Sie auf die Schaltfläche Dateien hochladen, wählen Sie im angezeigten Dialogfeld die Dateien aus, die Sie hochladen möchten, und klicken Sie auf Öffnen.
gsutil
Führen Sie den Befehl gsutil cp aus:
gsutil cp OBJECT_LOCATION gs://bucketName
Ersetzen Sie Folgendes:
bucketName: der Name des Buckets, den Sie zuvor in dieser Anleitung erstellt haben.OBJECT_LOCATION: der lokale Pfad zu Ihrem Objekt. Beispiel:Desktop/transformCSVtoJSON.js
Codebeispiele
Python
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Ruby
Richten Sie für die Authentifizierung bei Cloud Composer Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
DataflowTemplateOperator konfigurieren
Legen Sie die folgenden Airflow-Variablen fest, bevor Sie den DAG ausführen.
| Airflow-Variable | Wert |
|---|---|
project_id
|
Die Projekt-ID |
gce_zone
|
Compute Engine-Zone, in der der Dataflow-Cluster erstellt werden muss |
bucket_path
|
Der Speicherort des zuvor erstellten Cloud Storage-Bucket. |
Nun verweisen Sie auf die Dateien, die Sie zuvor erstellt haben, um einen DAG zu erstellen, mit dem der Dataflow-Workflow gestartet wird. Kopieren Sie diesen DAG und speichern Sie ihn lokal als composer-dataflow-dag.py.
Airflow 2
Airflow 1
DAG in Cloud Storage hochladen
Laden Sie Ihren DAG in den Ordner /dags im Bucket Ihrer Umgebung hoch. Nachdem der Upload erfolgreich abgeschlossen wurde, können Sie ihn durch Klicken auf den Link DAGs-Ordner auf der Seite „Cloud Composer-Umgebungen“ aufrufen.
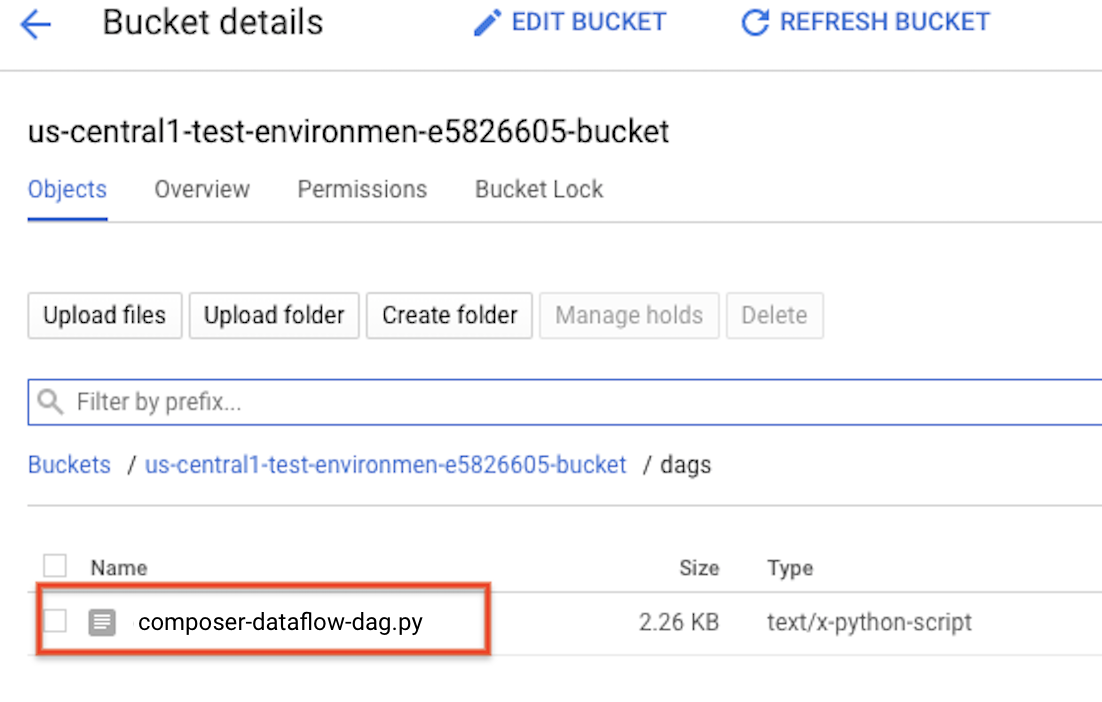
Status der Aufgabe ansehen
- Rufen Sie die Airflow-Weboberfläche auf.
- Klicken Sie auf der Seite "DAGs" auf den DAG-Namen, z. B.
composerDataflowDAG. - Klicken Sie auf der DAGs-Detailseite auf Grafikansicht.
Prüfen Sie den Status:
Failed: Die Aufgabe wird von einem roten Rahmen umgeben. Sie können auch den Mauszeiger über die Aufgabe bewegen und nach Status: Fehlgeschlagen suchen.Success: Die Aufgabe ist von einem grünen Rahmen umgeben. Sie können auch den Mauszeiger über die Aufgabe bewegen und nach Status: Erfolgreich suchen.
Nach einigen Minuten können Sie die Ergebnisse in Dataflow und BigQuery prüfen.
Job in Dataflow ansehen
Rufen Sie in der Google Cloud Console die Seite Dataflow auf.
Der Job heißt
dataflow_operator_transform_csv_to_bqund hat eine eindeutige ID, die am Ende des Namens mit einem Bindestrich angehängt ist. Beispiel:
Klicken Sie auf den Namen, um die Jobdetails aufzurufen.
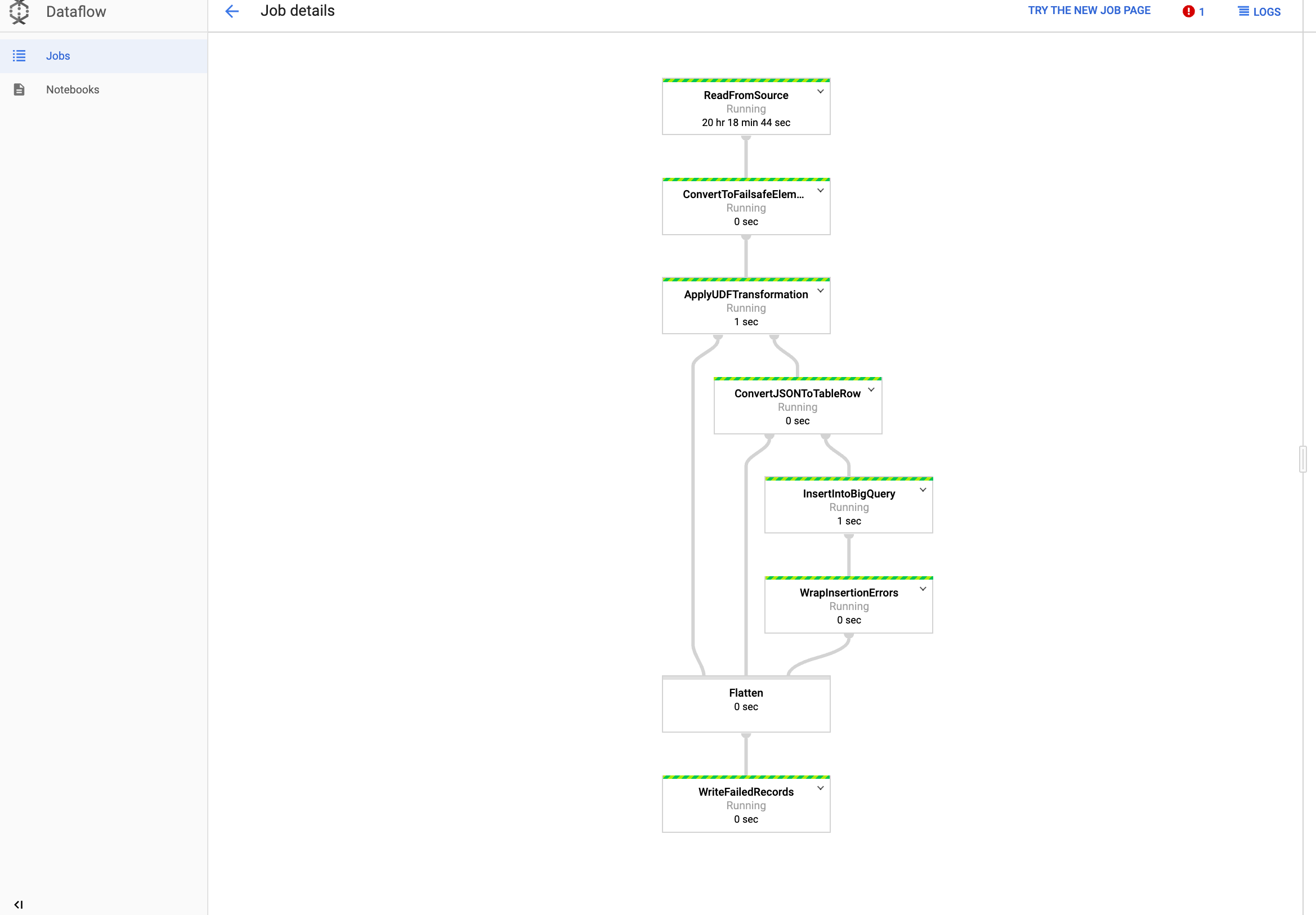
Ergebnisse in BigQuery anzeigen
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Sie können Abfragen mit Standard-SQL senden. Verwenden Sie die folgende Abfrage, um die Zeilen anzuzeigen, die Ihrer Tabelle hinzugefügt wurden:
SELECT * FROM projectId.average_weather.average_weather