Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Auf dieser Seite wird beschrieben, wie Sie den allgemeinen Zustand und die Leistung der Cloud Composer-Umgebung anhand wichtiger Messwerte im Monitoring-Dashboard überwachen.
Einführung
In diesem Tutorial werden die wichtigsten Cloud Composer-Monitoring-Messwerte behandelt, die einen guten Überblick über den Zustand und die Leistung auf Umgebungsebene bieten.
Cloud Composer bietet mehrere Messwerte, die den allgemeinen Zustand der Umgebung beschreiben. Die Monitoring-Richtlinien in dieser Anleitung basieren auf den Messwerten, die im Monitoring-Dashboard Ihrer Cloud Composer-Umgebung verfügbar sind.
In dieser Anleitung erfahren Sie mehr über die wichtigsten Messwerte, die als primäre Indikatoren für Probleme mit der Leistung und dem Zustand Ihrer Umgebung dienen. Außerdem erhalten Sie Richtlinien für die Interpretation der einzelnen Messwerte, um Korrekturmaßnahmen zu ergreifen und die Umgebung in gutem Zustand zu halten. Außerdem richten Sie Benachrichtigungsregeln für jeden Messwert ein, führen den Beispiel-DAG aus und verwenden diese Messwerte und Benachrichtigungen, um die Leistung Ihrer Umgebung zu optimieren.
Lernziele
Kosten
In dieser Anleitung werden die folgenden kostenpflichtigen Komponenten von Google Cloudverwendet:
Nach Abschluss dieser Anleitung können Sie weitere Kosten durch Löschen von erstellten Ressourcen vermeiden. Weitere Informationen finden Sie unter Bereinigen.
Hinweise
In diesem Abschnitt werden die Aktionen beschrieben, die vor Beginn des Tutorials erforderlich sind.
Projekt erstellen und konfigurieren
Für diese Anleitung benötigen Sie ein Google Cloud-Projekt. Konfigurieren Sie das Projekt so:
Wählen Sie in der Google Cloud -Console ein Projekt aus oder erstellen Sie ein Projekt:
Die Abrechnung für Ihr Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Achten Sie darauf, dass der Nutzer Ihres Google Cloud Projekts die folgenden Rollen hat, um die erforderlichen Ressourcen zu erstellen:
- Administrator für Umgebung und Storage-Objekte (
roles/composer.environmentAndStorageObjectAdmin) - Compute-Administrator (
roles/compute.admin) - Monitoring-Editor (
roles/monitoring.editor)
- Administrator für Umgebung und Storage-Objekte (
Die APIs für Ihr Projekt aktivieren
Enable the Cloud Composer API.
Cloud Composer-Umgebung erstellen
Cloud Composer 2-Umgebung erstellen
Im Rahmen dieser Vorgehensweise weisen Sie dem Composer-Dienst-Agent-Konto die Rolle Dienst-Agent-Erweiterung für die Cloud Composer v2 API (roles/composer.ServiceAgentV2Ext) zu. Cloud Composer verwendet dieses Konto, um Vorgänge in Ihrem Google Cloud -Projekt auszuführen.
Wichtige Messwerte für Zustand und Leistung auf Umgebungsebene ansehen
In diesem Tutorial geht es um die wichtigsten Messwerte, die Ihnen einen guten Überblick über den allgemeinen Zustand und die Leistung Ihrer Umgebung geben können.
Das Monitoring-Dashboard in derGoogle Cloud -Konsole enthält eine Vielzahl von Messwerten und Diagrammen, mit denen Sie Trends in Ihrer Umgebung überwachen und Probleme mit Airflow-Komponenten und Cloud Composer-Ressourcen identifizieren können.
Jede Cloud Composer-Umgebung hat ein eigenes Monitoring-Dashboard.
Machen Sie sich mit den folgenden wichtigen Messwerten vertraut und suchen Sie sie im Monitoring-Dashboard:
Rufen Sie in der Google Cloud -Console die Seite Umgebungen auf.
Klicken Sie in der Liste der Umgebungen auf den Namen Ihrer Umgebung. Die Seite Umgebungsdetails wird geöffnet.
Rufen Sie den Tab Monitoring auf.
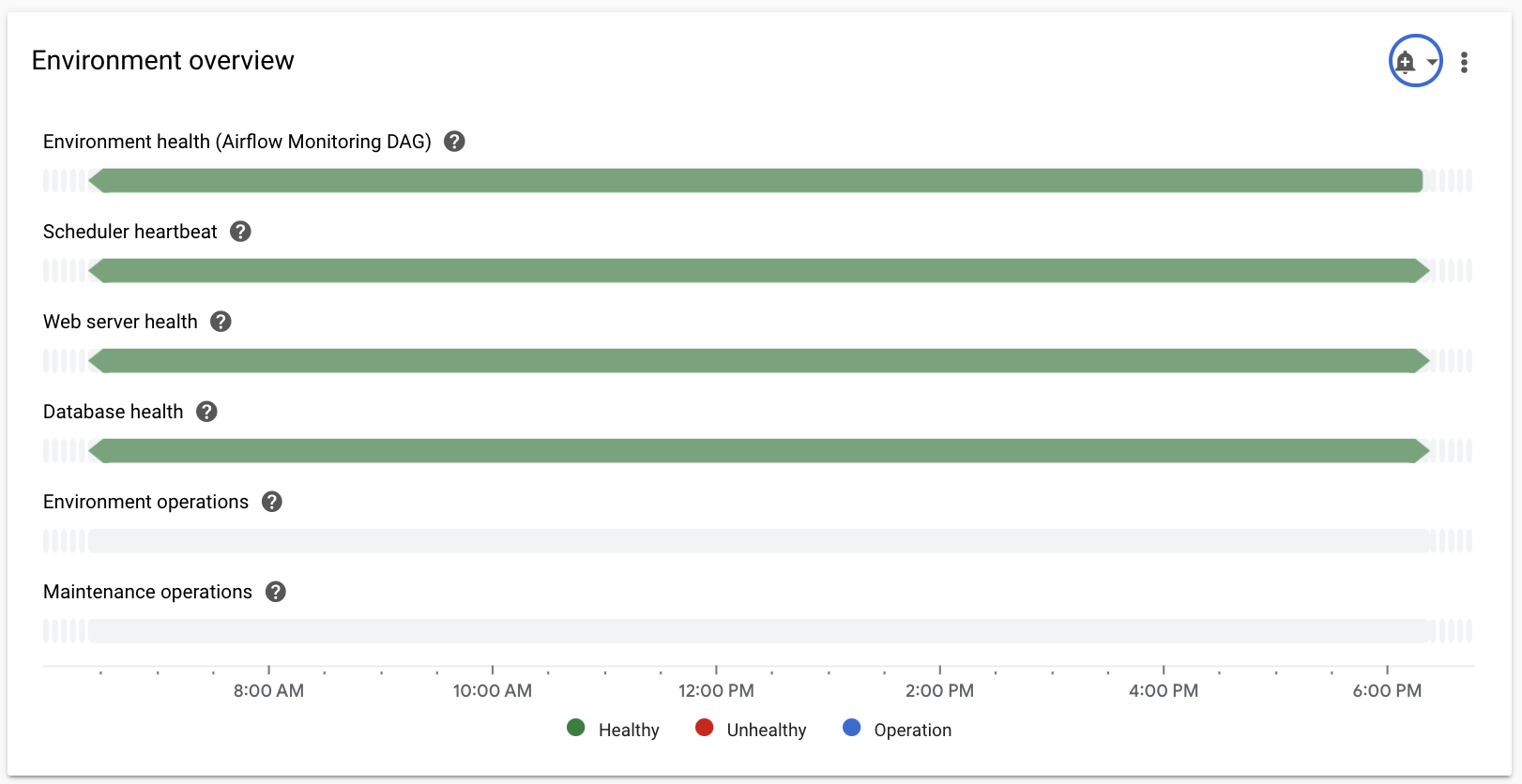
Wählen Sie den Bereich Übersicht aus, suchen Sie im Dashboard nach dem Element Umgebungsübersicht und sehen Sie sich den Messwert Umgebungszustand (Airflow-Monitoring-DAG) an.
Diese Zeitachse zeigt den Zustand der Cloud Composer-Umgebung. Die grüne Farbe der Statusleiste für die Umgebung gibt an, dass die Umgebung fehlerfrei ist. Der Status „Nicht fehlerfrei“ wird durch eine rote Farbe angezeigt.
Cloud Composer führt alle paar Minuten einen Aktivitäts-DAG namens
airflow_monitoringaus. Wenn die Liveness-DAG-Ausführung erfolgreich abgeschlossen wurde, lautet der SystemstatusTrue. Wenn die Ausführung des Aktivitäts-DAG fehlschlägt (z. B. aufgrund von Pod-Entfernung, Beendigung eines externen Prozesses oder Wartung), lautet der SystemstatusFalse.
Wählen Sie den Bereich SQL-Datenbank aus, suchen Sie im Dashboard nach dem Element Datenbankzustand und beobachten Sie den Messwert Datenbankzustand.
Diese Zeitachse zeigt den Status der Verbindung zur Cloud SQL-Instanz Ihrer Umgebung. Die grüne Leiste „Datenbankstatus“ zeigt die Konnektivität an. Fehler bei der Verbindung werden rot dargestellt.
Der Airflow-Monitoring-Pod kontaktiert die Datenbank regelmäßig und meldet den Systemstatus als
True, wenn eine Verbindung hergestellt werden kann. Andernfalls wirdFalseausgegeben.
Sehen Sie sich unter Datenbankstatus die Messwerte CPU-Auslastung der Datenbank und Arbeitsspeichernutzung der Datenbank an.
Das Diagramm zur CPU-Nutzung der Datenbank zeigt die Nutzung von CPU-Kernen durch die Cloud SQL-Datenbankinstanzen Ihrer Umgebung im Vergleich zum insgesamt verfügbaren CPU-Limit für Datenbanken.
Das Diagramm zur Datenbank-Arbeitsspeichernutzung zeigt die Arbeitsspeichernutzung durch die Cloud SQL-Datenbankinstanzen Ihrer Umgebung im Vergleich zum insgesamt verfügbaren Datenbank-Arbeitsspeicherlimit.
Wählen Sie den Abschnitt Planer aus, suchen Sie im Dashboard nach dem Element Scheduler-Heartbeat und beobachten Sie den Messwert Scheduler-Heartbeat.
Diese Zeitachse zeigt den Zustand des Airflow-Planers. Suchen Sie nach roten Bereichen, um Probleme mit Airflow-Planern zu identifizieren. Wenn in Ihrer Umgebung mehrere Planer vorhanden sind, ist der Herzschlagstatus in Ordnung, solange mindestens einer der Planer reagiert.
Der Scheduler gilt als fehlerhaft, wenn der letzte Heartbeat mehr als 30 Sekunden (Standardwert) vor der aktuellen Zeit empfangen wurde.
Wählen Sie den Bereich DAG-Statistiken aus, suchen Sie im Dashboard nach dem Element Zombie-Aufgaben gelöscht und beobachten Sie den Messwert Zombie-Aufgaben gelöscht.
In diesem Diagramm wird die Anzahl der Zombie-Aufgaben angezeigt, die in einem kleinen Zeitfenster beendet wurden. Zombie-Aufgaben werden häufig durch die externe Beendigung von Airflow-Prozessen verursacht, z. B. wenn der Prozess einer Aufgabe beendet wird.
Der Airflow-Planer beendet Zombie-Aufgaben regelmäßig, was in diesem Diagramm angezeigt wird.
Wählen Sie den Abschnitt Worker aus, suchen Sie im Dashboard nach dem Element Neustarts von Worker-Containern und beobachten Sie den Messwert Neustarts von Worker-Containern.
- Ein Diagramm zeigt die Gesamtzahl der Neustarts für einzelne Worker-Container. Zu viele Containerneustarts können sich auf die Verfügbarkeit Ihres Dienstes oder anderer Downstream-Dienste auswirken, die ihn als Abhängigkeit verwenden.
Benchmarks und mögliche Korrekturmaßnahmen für wichtige Messwerte
In der folgenden Liste werden Benchmark-Werte beschrieben, die auf Probleme hinweisen können, sowie Korrekturmaßnahmen, die Sie ergreifen können, um diese Probleme zu beheben.
Umgebungszustand (Airflow-Monitoring-DAG)
Erfolgsquote von weniger als 90% über einen Zeitraum von 4 Stunden
Fehler können zu Pod-Entfernungen oder Worker-Beendigungen führen, weil die Umgebung überlastet ist oder nicht richtig funktioniert. Rote Bereiche auf der Zeitachse für den Zustand der Umgebung korrelieren in der Regel mit roten Bereichen in den anderen Zustandsbalken der einzelnen Umgebungskomponenten. Ermitteln Sie die Ursache, indem Sie andere Messwerte im Monitoring-Dashboard prüfen.
Datenbankstatus
Erfolgsquote von weniger als 95% über einen Zeitraum von 4 Stunden
Fehler bedeuten, dass es Probleme mit der Verbindung zur Airflow-Datenbank gibt. Das kann an einem Datenbankabsturz oder an Ausfallzeiten liegen, weil die Datenbank überlastet ist (z. B. aufgrund einer hohen CPU- oder Arbeitsspeicherauslastung oder einer höheren Latenz beim Herstellen einer Verbindung zur Datenbank). Diese Symptome werden am häufigsten durch suboptimale DAGs verursacht, z. B. wenn in DAGs viele global definierte Airflow- oder Umgebungsvariablen verwendet werden. Ermitteln Sie die Ursache, indem Sie die Messwerte zur Ressourcennutzung der SQL-Datenbank prüfen. Sie können auch die Scheduler-Logs auf Fehler im Zusammenhang mit der Datenbankverbindung prüfen.
CPU- und Arbeitsspeichernutzung der Datenbank
Mehr als 80% durchschnittliche CPU- oder Speichernutzung innerhalb eines 12-stündigen Zeitraums
Die Datenbank ist möglicherweise überlastet. Analysieren Sie die Korrelation zwischen Ihren DAG-Ausführungen und Spitzen bei der CPU- oder Arbeitsspeichernutzung der Datenbank.
Sie können die Datenbanklast durch effizientere DAGs mit optimierten laufenden Abfragen und Verbindungen oder durch eine gleichmäßigere Verteilung der Last über die Zeit reduzieren.
Alternativ können Sie der Datenbank mehr CPU oder Arbeitsspeicher zuweisen. Datenbankressourcen werden durch das Attribut für die Größe Ihrer Umgebung gesteuert. Die Umgebung muss auf eine größere Größe skaliert werden.
Planer-Heartbeat
Erfolgsquote von weniger als 90% über einen Zeitraum von 4 Stunden
Weisen Sie dem Scheduler mehr Ressourcen zu oder erhöhen Sie die Anzahl der Scheduler von 1 auf 2 (empfohlen).
Zombie-Aufgaben gelöscht
Mehr als eine Zombie-Aufgabe pro 24 Stunden
Der häufigste Grund für Zombie-Aufgaben ist der Mangel an CPU- oder Arbeitsspeicherressourcen im Cluster Ihrer Umgebung. Sehen Sie sich die Diagramme zur Ressourcennutzung der Worker an und weisen Sie Ihren Workern mehr Ressourcen zu oder erhöhen Sie das Zeitlimit für Zombie-Aufgaben, damit der Scheduler länger wartet, bevor er eine Aufgabe als Zombie betrachtet.
Neustarts von Worker-Containern
Mehr als ein Neustart pro 24 Stunden
Der häufigste Grund ist ein Mangel an Arbeitsspeicher oder Speicherplatz für den Worker. Sehen Sie sich den Ressourcenverbrauch der Worker an und weisen Sie ihnen mehr Arbeitsspeicher oder Speicherplatz zu. Wenn das nicht der Grund ist, führen Sie eine Fehlerbehebung bei Vorfällen mit Worker-Neustarts durch und verwenden Sie Protokollierungsanfragen, um die Gründe für Worker-Neustarts zu ermitteln.
Benachrichtigungskanäle erstellen
Folgen Sie der Anleitung unter Benachrichtigungskanal erstellen, um einen E-Mail-Benachrichtigungskanal zu erstellen.
Weitere Informationen zu Benachrichtigungskanälen finden Sie unter Benachrichtigungskanäle verwalten.
Benachrichtigungsrichtlinien erstellen
Erstellen Sie Benachrichtigungsrichtlinien basierend auf den Benchmarks in den vorherigen Abschnitten dieses Tutorials, um die Werte von Messwerten kontinuierlich zu überwachen und Benachrichtigungen zu erhalten, wenn diese Messwerte gegen eine Bedingung verstoßen.
Console
Sie können Benachrichtigungen für jeden Messwert im Monitoring-Dashboard einrichten, indem Sie auf das Glockensymbol in der Ecke des entsprechenden Elements klicken:
Suchen Sie im Monitoring-Dashboard nach den Messwerten, die Sie im Blick behalten möchten, und klicken Sie in der Ecke des Messwertelements auf das Glockensymbol. Die Seite Benachrichtigungsrichtlinie erstellen wird geöffnet.
Im Bereich Daten transformieren:
Konfigurieren Sie den Bereich Innerhalb jeder Zeitreihe wie in der Konfiguration von Benachrichtigungsrichtlinien für den Messwert beschrieben.
Klicken Sie auf Weiter und konfigurieren Sie dann den Bereich Benachrichtigungstrigger konfigurieren, wie in der Konfiguration von Benachrichtigungsrichtlinien für den Messwert beschrieben.
Klicken Sie auf Weiter.
Benachrichtigungen konfigurieren Maximieren Sie das Menü Benachrichtigungskanäle und wählen Sie die Benachrichtigungskanäle aus, die Sie im vorherigen Schritt erstellt haben.
Klicken Sie auf OK.
Füllen Sie im Bereich Benachrichtigungsrichtlinie benennen das Feld Name der Benachrichtigungsrichtlinie aus. Verwenden Sie für jeden Messwert einen aussagekräftigen Namen. Verwenden Sie den Wert „Name the alert policy“ (Benachrichtigungsrichtlinie benennen), wie in der Konfiguration der Benachrichtigungsrichtlinien für den Messwert beschrieben.
Klicken Sie auf Weiter.
Prüfen Sie die Benachrichtigungsrichtlinie und klicken Sie auf Richtlinie erstellen.
Messwert „Umgebungszustand“ (Airflow-Monitoring-DAG) – Konfigurationen für Benachrichtigungsrichtlinien
- Messwertname: Cloud Composer Environment - Healthy
- API: composer.googleapis.com/environment/healthy
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: Benutzerdefiniert
- Benutzerdefinierter Wert: 4
- Benutzerdefinierte Einheiten: Stunde(n)
- Funktion für rollierendes Zeitfenster: Anteil „true“
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Unter Grenzwert
- Grenzwert: 90
- Name der Bedingung: Zustand der Umgebung
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Benennen Sie die Benachrichtigungsrichtlinie: Airflow Environment Health
Messwert zum Datenbankzustand – Konfigurationen von Benachrichtigungsrichtlinien
- Messwertname: Cloud Composer Environment - Database Healthy
- API: composer.googleapis.com/environment/database_health
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: Benutzerdefiniert
- Benutzerdefinierter Wert: 4
- Benutzerdefinierte Einheiten: Stunde(n)
- Funktion für rollierendes Zeitfenster: Anteil „true“
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Unter Grenzwert
- Grenzwert: 95
- Name der Bedingung: Datenbankstatus
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Nennen Sie die Benachrichtigungsrichtlinie „Airflow Database Health“.
Messwert zur CPU-Nutzung der Datenbank – Konfigurationen für Benachrichtigungsrichtlinien
- Messwertname: Cloud Composer Environment – Database CPU Utilization
- API: composer.googleapis.com/environment/database/cpu/utilization
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: Benutzerdefiniert
- Benutzerdefinierter Wert: 12
- Benutzerdefinierte Einheiten: Stunde(n)
- Funktion für rollierendes Zeitfenster: Mittelwert
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Über Grenzwert
- Grenzwert: 80
- Name der Bedingung: Bedingung für die CPU-Nutzung der Datenbank
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Nennen Sie die Benachrichtigungsrichtlinie „Airflow Database CPU Usage“.
Messwert für die Arbeitsspeichernutzung der Datenbank – Konfigurationen für Benachrichtigungsrichtlinien
- Messwertname: Cloud Composer Environment – Database Memory Utilization
- API: composer.googleapis.com/environment/database/memory/utilization
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: Benutzerdefiniert
- Benutzerdefinierter Wert: 12
- Benutzerdefinierte Einheiten: Stunde(n)
- Funktion für rollierendes Zeitfenster: Mittelwert
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Über Grenzwert
- Grenzwert: 80
- Bedingungsname: Bedingung für die Arbeitsspeichernutzung der Datenbank
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Benennen Sie die Benachrichtigungsrichtlinie: „Airflow Database Memory Usage“ (Airflow-Datenbank – Speichernutzung).
Messwert „Planer-Heartbeats“ – Konfigurationen von Benachrichtigungsrichtlinien
- Messwertname: Cloud Composer Environment – Scheduler Heartbeats
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: Benutzerdefiniert
- Benutzerdefinierter Wert: 4
- Benutzerdefinierte Einheiten: Stunde(n)
- Funktion für rollierendes Zeitfenster: count
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Unter Grenzwert
Grenzwert: 216
- Sie können diese Zahl abrufen, indem Sie eine Abfrage ausführen, die den Wert
_scheduler_heartbeat_count_meanim Abfrageeditor des Metrics Explorer aggregiert.
- Sie können diese Zahl abrufen, indem Sie eine Abfrage ausführen, die den Wert
Bedingungsname: „Scheduler heartbeat condition“ (Bedingung für Planer-Heartbeat)
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Nennen Sie die Benachrichtigungsrichtlinie „Airflow Scheduler Heartbeat“.
Messwert „Zombie-Aufgaben gelöscht“ – Konfigurationen von Benachrichtigungsrichtlinien
- Messwertname: Cloud Composer Environment – Zombie Tasks Killed
- API: composer.googleapis.com/environment/zombie_task_killed_count
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: 1 Tag
- Funktion für rollierendes Zeitfenster: Summe
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Über Grenzwert
- Grenzwert: 1
- Bedingungsname: Bedingung für Zombie-Aufgaben
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Benennen Sie die Benachrichtigungsrichtlinie: Airflow Zombie Tasks
Messwert „Neustarts von Worker-Containern“ – Konfigurationen von Benachrichtigungsrichtlinien
- Messwertname: Kubernetes Container – Restart Count
- API: kubernetes.io/container/restart_count
Filter:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAMEist der Clusternamen Ihrer Umgebung, den Sie in der Google Cloud -Konsole unter „Umgebungskonfiguration“ > „Ressourcen“ > „GKE-Cluster“ finden.„Daten transformieren“ > „In jeder Zeitachse“:
- Rollierendes Zeitfenster: 1 Tag
- Funktion für rollierendes Zeitfenster: Rate
Benachrichtigungstrigger konfigurieren:
- Bedingungstypen: Schwellenwert
- Benachrichtigungstrigger: Bei jedem Verstoß
- Grenzwertposition: Über Grenzwert
- Grenzwert: 1
- Bedingungsname: Bedingung für Neustarts von Worker-Containern
Konfigurieren Sie Benachrichtigungen und schließen Sie die Benachrichtigung ab:
- Benennen Sie die Benachrichtigungsrichtlinie: Airflow Worker Restarts
Terraform
Führen Sie ein Terraform-Skript aus, das einen E-Mail-Benachrichtigungskanal erstellt und Benachrichtigungsrichtlinien für die in diesem Tutorial bereitgestellten Schlüsselmesswerte basierend auf den jeweiligen Benchmarks hochlädt:
- Speichern Sie die Beispiel-Terraform-Datei auf Ihrem lokalen Computer.
Ersetzen Sie Folgendes:
PROJECT_ID: Die Projekt-ID Ihres Projekts. Beispiel:example-projectEMAIL_ADDRESS: Die E-Mail-Adresse, an die eine Benachrichtigung gesendet werden muss, wenn ein Alert ausgelöst wird.ENVIRONMENT_NAME: Der Name Ihrer Cloud Composer-Umgebung. Beispiel:example-composer-environment.CLUSTER_NAME: Der Name Ihres Umgebungssclusters. Sie finden ihn in der Google Cloud -Konsole unter „Umgebungskonfiguration“ > „Ressourcen“ > „GKE-Cluster“.
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
Benachrichtigungsrichtlinien testen
In diesem Abschnitt wird beschrieben, wie Sie die erstellten Benachrichtigungsrichtlinien testen und die Ergebnisse interpretieren.
Beispiel-DAG hochladen
Der in dieser Anleitung bereitgestellte Beispiel-DAG memory_consumption_dag.py imitiert eine intensive Arbeitsspeichernutzung durch Worker. Der DAG enthält vier Aufgaben. Jede Aufgabe schreibt Daten in einen Beispielstring und belegt dabei 380 MB Arbeitsspeicher. Der Beispiel-DAG wird alle 2 Minuten ausgeführt und startet automatisch, sobald Sie ihn in Ihre Composer-Umgebung hochladen.
Laden Sie den folgenden Beispiel-DAG in die Umgebung hoch, die Sie in den vorherigen Schritten erstellt haben:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Benachrichtigungen und Messwerte in Monitoring interpretieren
Warten Sie etwa 10 Minuten, nachdem der Beispiel-DAG ausgeführt wurde, und werten Sie die Testergebnisse aus:
Prüfen Sie, ob Sie eine Benachrichtigung vonGoogle Cloud Alerting mit einem Betreff erhalten haben, der mit
[ALERT]beginnt. Der Inhalt dieser Nachricht enthält die Vorfalldetails der Benachrichtigungsrichtlinie.Klicken Sie in der E-Mail-Benachrichtigung auf die Schaltfläche Vorfall ansehen. Sie werden zum Metrics Explorer weitergeleitet. Sehen Sie sich die Details des Benachrichtigungsereignisses an:

Abbildung 2. Details zum Benachrichtigungsvorfall (zum Vergrößern klicken) Das Diagramm mit den Vorfallmesswerten zeigt, dass die von Ihnen erstellten Messwerte den Grenzwert von 1 überschritten haben. Das bedeutet, dass in Airflow mehr als eine Zombie-Aufgabe erkannt und beendet wurde.
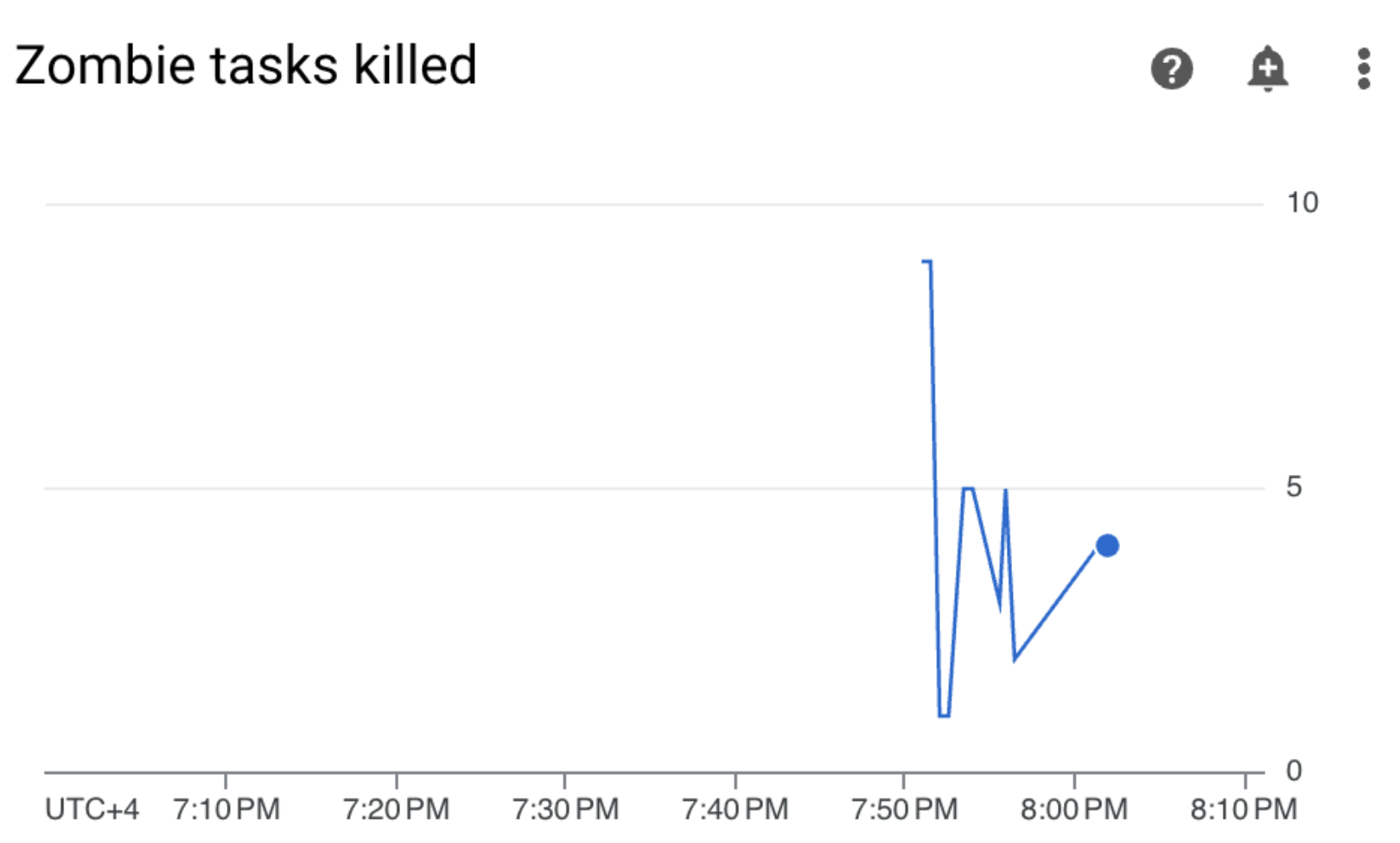
Rufen Sie in Ihrer Cloud Composer-Umgebung den Tab Monitoring auf, öffnen Sie den Bereich DAG-Statistiken und suchen Sie nach dem Diagramm Beendete Zombie-Aufgaben:

Abbildung 3. Diagramm zu Zombie-Aufgaben (zum Vergrößern klicken) Das Diagramm zeigt, dass Airflow innerhalb der ersten 10 Minuten der Ausführung des Beispiel-DAG etwa 20 Zombie-Aufgaben beendet hat.
Laut den Benchmarks und Korrekturmaßnahmen ist der häufigste Grund für Zombie-Aufgaben ein Mangel an Worker-Arbeitsspeicher oder ‑CPU. Ermitteln Sie die Grundursache von Zombie-Aufgaben, indem Sie die Ressourcennutzung Ihrer Worker analysieren.
Öffnen Sie im Monitoring-Dashboard den Abschnitt „Worker“ und sehen Sie sich die Messwerte für die CPU- und Arbeitsspeichernutzung des Workers an:
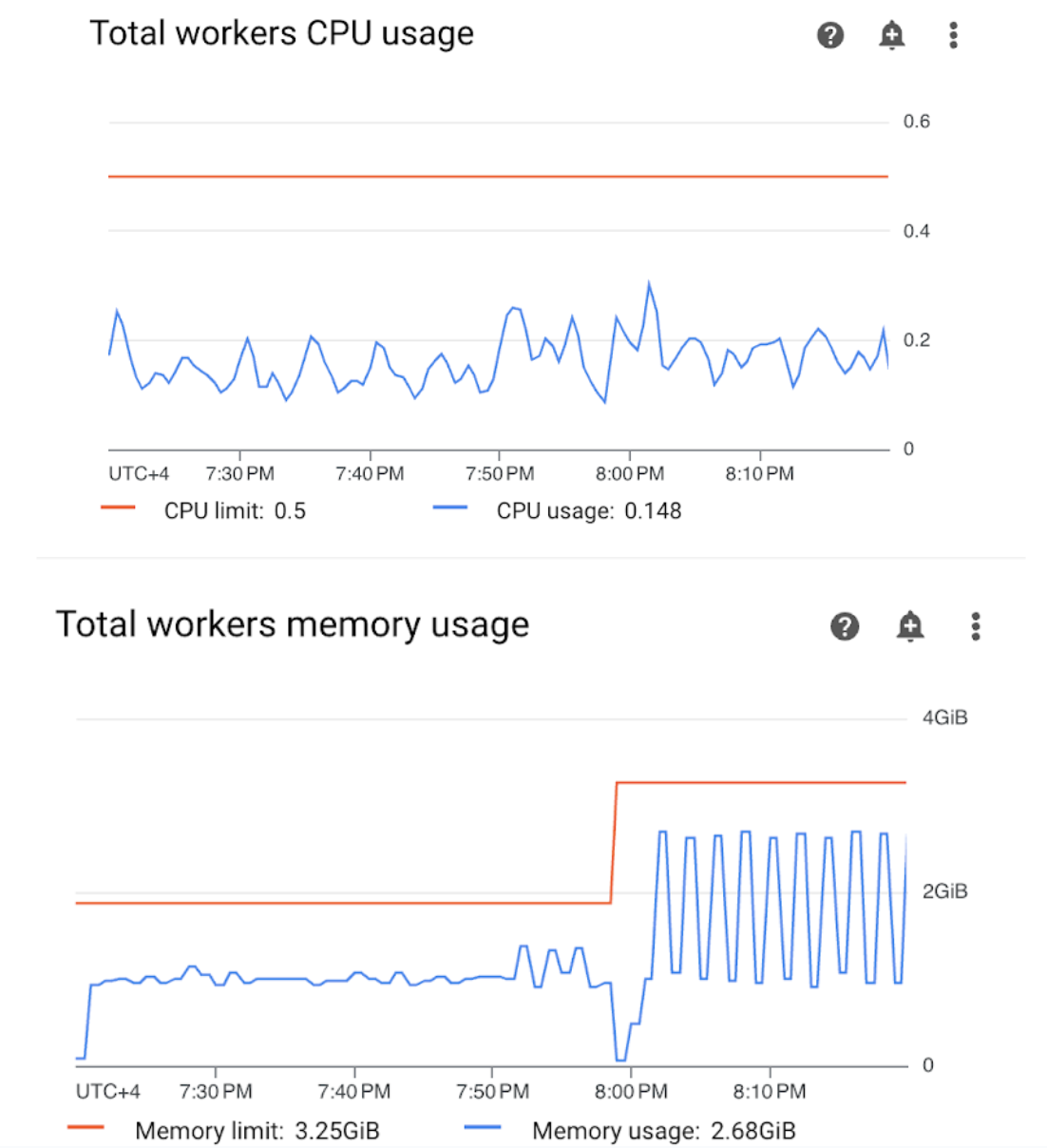
Abbildung 4. Messwerte zur CPU- und Speichernutzung von Worker-Knoten (zum Vergrößern klicken) Das Diagramm „Gesamte CPU-Nutzung der Worker“ zeigt, dass die CPU-Nutzung der Worker zu jedem Zeitpunkt unter 50% des insgesamt verfügbaren Limits lag. Die verfügbare CPU ist also ausreichend. Das Diagramm „Gesamte Arbeitsspeichernutzung der Worker“ zeigt, dass beim Ausführen des Beispiel-DAG das zuweisbare Arbeitsspeicherlimit erreicht wurde, das fast 75% des im Diagramm gezeigten Gesamtarbeitsspeicherlimits entspricht (GKE reserviert 25% der ersten 4 GiB Arbeitsspeicher und zusätzlich 100 MiB Arbeitsspeicher auf jedem Knoten, um die Pod-Bereinigung auszuführen).
Daraus können Sie schließen, dass den Workern die Arbeitsspeicherressourcen fehlen, um den Beispiel-DAG erfolgreich auszuführen.
Umgebung optimieren und Leistung bewerten
Basierend auf der Analyse der Ressourcenauslastung der Worker müssen Sie Ihren Workern mehr Arbeitsspeicher zuweisen, damit alle Aufgaben in Ihrem DAG erfolgreich ausgeführt werden können.
Öffnen Sie in Ihrer Composer-Umgebung den Tab DAGs, klicken Sie auf den Namen des Beispiel-DAG (
memory_consumption_dag) und dann auf DAG pausieren.Zusätzlichen Worker-Arbeitsspeicher zuweisen:
Suchen Sie auf dem Tab „Umgebungskonfiguration“ nach Ressourcen > Arbeitslasten und klicken Sie auf Bearbeiten.
Erhöhen Sie im Element Worker das Arbeitsspeicher-Limit. Verwenden Sie in dieser Anleitung 3,25 GB.
Speichern Sie die Änderungen und warten Sie einige Minuten, bis der Worker neu gestartet wurde.
Öffnen Sie den Tab „DAGs“, klicken Sie auf den Namen des Beispiel-DAG (
memory_consumption_dag) und dann auf DAG fortsetzen.
Rufen Sie Monitoring auf und prüfen Sie, ob nach der Aktualisierung der Worker-Ressourcenlimits neue Zombie-Aufgaben angezeigt werden:
Zusammenfassung
In diesem Lernprogramm haben Sie die wichtigsten Messwerte für den Zustand und die Leistung auf Umgebungsebene kennengelernt. Außerdem haben Sie erfahren, wie Sie Benachrichtigungsrichtlinien für die einzelnen Messwerte einrichten und wie Sie die einzelnen Messwerte interpretieren, um Korrekturmaßnahmen zu ergreifen. Sie haben dann einen Beispiel-DAG ausgeführt, die Ursache von Problemen mit dem Umgebungsstatus mithilfe von Benachrichtigungen und Monitoring-Diagrammen ermittelt und Ihre Umgebung optimiert, indem Sie Ihren Workern mehr Arbeitsspeicher zugewiesen haben. Es wird jedoch empfohlen, Ihre DAGs zu optimieren, um den Ressourcenverbrauch der Worker zu reduzieren, da die Ressourcen nicht über einen bestimmten Schwellenwert hinaus erhöht werden können.
Bereinigen
Damit Ihrem Google Cloud -Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
Projekt löschen
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Einzelne Ressourcen löschen
Wenn Sie mehrere Anleitungen und Kurzanleitungen durcharbeiten möchten, können Sie die Überschreitung von Projektkontingenten verhindern, indem Sie Projekte wiederverwenden.
Console
- Löschen Sie die Cloud Composer-Umgebung. Bei diesem Vorgang löschen Sie auch den Bucket der Umgebung.
- Löschen Sie alle Benachrichtigungsrichtlinien, die Sie in Cloud Monitoring erstellt haben.
Terraform
- Achten Sie darauf, dass Ihr Terraform-Skript keine Einträge für Ressourcen enthält, die für Ihr Projekt noch erforderlich sind. Möglicherweise möchten Sie beispielsweise einige APIs aktiviert und IAM-Berechtigungen weiterhin zugewiesen lassen (wenn Sie solche Definitionen in Ihr Terraform-Skript aufgenommen haben).
- Führen Sie
terraform destroyaus. - Löschen Sie den Bucket der Umgebung manuell. Cloud Composer löscht ihn nicht automatisch. Sie können dies über die Google Cloud Console oder die Google Cloud CLI tun.
Nächste Schritte
- Umgebungen optimieren
- Umgebungen skalieren
- Umgebungslabels verwalten und Umgebungskosten aufschlüsseln