Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
This page describes how to use KubernetesPodOperator to deploy Kubernetes Pods from Cloud Composer into the Google Kubernetes Engine cluster that is part of your Cloud Composer environment.
KubernetesPodOperator launches Kubernetes Pods in your environment's cluster. In comparison, Google Kubernetes Engine operators run Kubernetes Pods in a specified cluster, which can be a separate cluster that is not related to your environment. You can also create and delete clusters using Google Kubernetes Engine operators.
KubernetesPodOperator is a good option if you require:
- Custom Python dependencies that are not available through the public PyPI repository.
- Binary dependencies that are not available in the stock Cloud Composer worker image.
Before you begin
If version 5.0.0 of CNCF Kubernetes Provider is used then follow instructions documented CNCF Kubernetes Provider section.
Pod affinity configuration is not available in Cloud Composer 2. If you want to use Pod affinity, use the GKE operators to launch Pods in a different cluster instead.
About KubernetesPodOperator in Cloud Composer 2
This section describes how KubernetesPodOperator works in Cloud Composer 2.
Resource usage
In Cloud Composer 2, your environment's cluster scales automatically. Extra workloads that you run using KubernetesPodOperator scale independently from your environment.
Your environment is not affected by the increased resource demand, but your environment's cluster scales up and down depending on the resource demand.
The pricing for the extra workloads that you run in your environment's cluster follows the Cloud Composer 2 pricing model and uses Cloud Composer Compute SKUs.
Cloud Composer 2 uses Autopilot clusters which introduce the notion of compute classes:
Cloud Composer supports only the
general-purposecompute class.By default, if no class is selected then the
general-purposeclass is assumed when you create Pods using KubernetesPodOperator.Each class is associated with specific properties and resource limits, You can read about them in Autopilot documentation. For example, Pods that run within the
general-purposeclass can use up to 110 GiB of memory.
Access to project's resources
Cloud Composer 2 uses GKE clusters with
Workload Identity Federation for GKE. Pods that run in the composer-user-workloads
namespace can access Google Cloud resources in your project without
additional configuration. Your environment's service account
is used to access these resources.
If you want to use a custom namespace, then Kubernetes service accounts associated with this namespace must be mapped to Google Cloud service accounts, to enable service identity authorization for requests to Google APIs and other services. If you run Pods in a custom namespace in your environment's cluster, then IAM bindings between Kubernetes and Google Cloud service accounts are not created, and these Pods cannot access resources of your Google Cloud project.
If you use a custom namespace and want your Pods to have access to Google Cloud resources, then follow the guidance in Workload Identity Federation for GKE and set up the bindings for a custom namespace:
- Create a separate namespace in your environment's cluster.
- Create a binding between the custom namespace Kubernetes Service Account and your environment's service account.
- Add your environment's service account annotation to the Kubernetes service account.
- When you use KubernetesPodOperator, specify the namespace and the
Kubernetes service account in the
namespaceandservice_account_nameparameters.
Minimal configuration
To create a KubernetesPodOperator, only Pod's name, image to use, and
task_id parameters are required. The /home/airflow/composer_kube_config
contains credentials to authenticate to GKE.
Additional configuration
This example shows additional parameters that you can configure in the KubernetesPodOperator.
See the following resources for more information:
For information about using Kubernetes Secrets and ConfigMaps, see Use Kubernetes Secrets and ConfigMaps.
For information about using Jinja templates with KubernetesPodOperator, see Use Jinja templates.
For information about KubernetesPodOperator parameters, see the operator's reference in Airflow documentation.
Use Jinja templates
Airflow supports Jinja templates in DAGs.
You must declare the required Airflow parameters (task_id, name, and
image) with the operator. As shown in the following example,
you can template all other parameters with Jinja, including cmds,
arguments, env_vars, and config_file.
The env_vars parameter in the example is set from an
Airflow variable named my_value. The example DAG
gets its value from the vars template variable in Airflow. Airflow has more
variables that provide access to different types of information. For example,
you can use the conf template variable to access values of
Airflow configuration options. For more information and the
list of variables available in Airflow, see
Templates reference in the Airflow
documentation.
Without changing the DAG or creating the env_vars variable, the
ex-kube-templates task in the example fails because the variable does not
exist. Create this variable in the Airflow UI or with Google Cloud CLI:
Airflow UI
Go to the Airflow UI.
In the toolbar, select Admin > Variables.
On the List Variable page, click Add a new record.
On the Add Variable page, enter the following information:
- Key:
my_value - Val:
example_value
- Key:
Click Save.
gcloud
Enter the following command:
gcloud composer environments run ENVIRONMENT \
--location LOCATION \
variables set -- \
my_value example_value
Replace:
ENVIRONMENTwith the name of the environment.LOCATIONwith the region where the environment is located.
The following example demonstrates how to use Jinja templates with KubernetesPodOperator:
Use Kubernetes Secrets and ConfigMaps
A Kubernetes Secret is an object that contains sensitive data. A Kubernetes ConfigMap is an object that contains non-confidential data in key-value pairs.
In Cloud Composer 2, you can create Secrets and ConfigMaps using Google Cloud CLI, API, or Terraform, and then access them from KubernetesPodOperator.
About YAML configuration files
When you create a Kubernetes Secret or a ConfigMap using Google Cloud CLI and API, you provide a file in the YAML format. This file must follow the same format as used by Kubernetes Secrets and ConfigMaps. Kubernetes documentation provides many code samples of ConfigMaps and Secrets. To get started, you can see the Distribute Credentials Securely Using Secrets page and ConfigMaps.
Same as in Kubernetes Secrets, use the base64 representation when you define values in Secrets.
To encode a value, you can use the following command (this is one of many ways to get a base64-encoded value):
echo "postgresql+psycopg2://root:example-password@127.0.0.1:3306/example-db" -n | base64
Output:
cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
The following two YAML file examples are used in samples later in this guide. Example YAML config file for a Kubernetes Secret:
apiVersion: v1
kind: Secret
metadata:
name: airflow-secrets
data:
sql_alchemy_conn: cG9zdGdyZXNxbCtwc3ljb3BnMjovL3Jvb3Q6ZXhhbXBsZS1wYXNzd29yZEAxMjcuMC4wLjE6MzMwNi9leGFtcGxlLWRiIC1uCg==
Another example that demonstrates how to include files. Same as in the previous
example, first encode the contents of a file (cat ./key.json | base64), then
provide this value in the YAML file:
apiVersion: v1
kind: Secret
metadata:
name: service-account
data:
service-account.json: |
ewogICJ0eXBl...mdzZXJ2aWNlYWNjb3VudC5jb20iCn0K
An example YAML config file for a ConfigMap. You don't need to use the base64 representation in ConfigMaps:
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
example_key: example_value
Manage Kubernetes Secrets
In Cloud Composer 2, you create Secrets using Google Cloud CLI and kubectl:
Get information about your environment's cluster:
Run the following command:
gcloud composer environments describe ENVIRONMENT \ --location LOCATION \ --format="value(config.gkeCluster)"Replace:
ENVIRONMENTwith the name of your environment.LOCATIONwith the region where the Cloud Composer environment is located.
The output of this command uses the following format:
projects/<your-project-id>/locations/<location-of-composer-env>/clusters/<your-cluster-id>.To get the GKE cluster ID, copy the output after
/clusters/(ends in-gke).
Connect to your GKE cluster with the following command:
gcloud container clusters get-credentials CLUSTER_ID \ --project PROJECT \ --region LOCATIONReplace the following:
CLUSTER_ID: the environment's cluster ID.PROJECT_ID: the Project ID.LOCATION: the region where the environment is located.
Create Kubernetes Secrets:
The following commands demonstrate two different approaches to creating Kubernetes Secrets. The
--from-literalapproach uses key-value pairs. The--from-fileapproach uses file contents.To create a Kubernetes Secret by providing key-value pairs run the following command. This example creates a Secret named
airflow-secretsthat has asql_alchemy_connfield with the value oftest_value.kubectl create secret generic airflow-secrets \ --from-literal sql_alchemy_conn=test_value -n composer-user-workloadsTo create a Kubernetes Secret by providing file contents, run the following command. This example creates a Secret named
service-accountthat has theservice-account.jsonfield with the value taken from the contents of a local./key.jsonfile.kubectl create secret generic service-account \ --from-file service-account.json=./key.json -n composer-user-workloads
Use Kubernetes Secrets in your DAGs
This example shows two ways of using Kubernetes Secrets: as an environment variable, and as a volume mounted by the Pod.
The first Secret, airflow-secrets, is set
to a Kubernetes environment variable named SQL_CONN (as opposed to an
Airflow or Cloud Composer environment variable).
The second Secret, service-account, mounts service-account.json, a file
with a service account token, to /var/secrets/google.
Here's what the Secret objects look like:
The name of the first Kubernetes Secret is defined in the secret_env variable.
This Secret is named airflow-secrets. The deploy_type parameter specifies
that it must be exposed as an environment variable. The environment variable's
name is SQL_CONN, as specified in the deploy_target parameter. Finally, the
value of the SQL_CONN environment variable is set to the value of the
sql_alchemy_conn key.
The name of the second Kubernetes Secret is defined in the secret_volume
variable. This Secret is named service-account. It is exposed as an
volume, as specified in the deploy_type parameter. The path of the file to
mount, deploy_target, is /var/secrets/google. Finally, the key of the
Secret that is stored in the deploy_target is service-account.json.
Here's what the operator configuration looks like:
Information about CNCF Kubernetes Provider
KubernetesPodOperator is implemented in
apache-airflow-providers-cncf-kubernetes provider.
For detailed release notes for CNCF Kubernetes provider refer to CNCF Kubernetes Provider website.
Version 6.0.0
In version 6.0.0 of the CNCF Kubernetes Provider package,
the kubernetes_default connection is used by default in KubernetesPodOperator.
If you specified a custom connection in version 5.0.0, this custom connection
is still used by the operator. To switch back to using the kubernetes_default
connection, you might want to adjust your DAGs accordingly.
Version 5.0.0
This version introduces a few backward incompatible changes
compared to version 4.4.0. The most important ones are related to
the kubernetes_default connection which is not used in version 5.0.0.
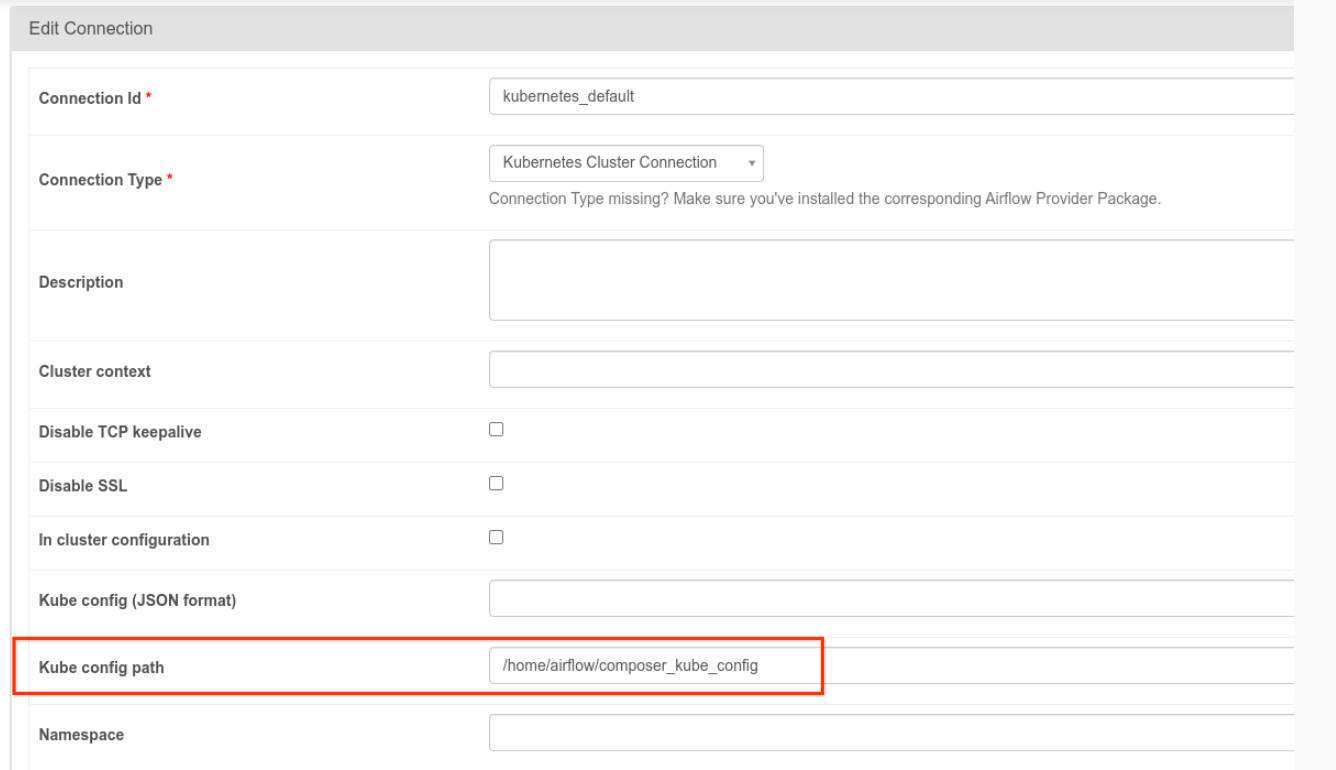
- The
kubernetes_defaultconnection needs to be modified. Kubernetes config path must be set to/home/airflow/composer_kube_config(as shown in the following figure). As an alternative,config_filemust be added to the KubernetesPodOperator configuration (as shown in the following code example).
- Modify the code of a task using KubernetesPodOperator in the following way:
KubernetesPodOperator(
# config_file parameter - can be skipped if connection contains this setting
config_file="/home/airflow/composer_kube_config",
# definition of connection to be used by the operator
kubernetes_conn_id='kubernetes_default',
...
)
For more information about Version 5.0.0 refer to CNCF Kubernetes Provider Release Notes.
Troubleshooting
This section provides advice for troubleshooting common KubernetesPodOperator issues:
View logs
When troubleshooting issues, you can check logs in the following order:
Airflow Task logs:
In the Google Cloud console, go to the Environments page.
In the list of environments, click the name of your environment. The Environment details page opens.
Go to the DAGs tab.
Click the name of the DAG, then click the DAG run to view the details and logs.
Airflow scheduler logs:
Go to the Environment details page.
Go to the Logs tab.
Inspect Airflow scheduler logs.
Pod logs in the Google Cloud console, under GKE workloads. These logs include the Pod definition YAML file, Pod events, and Pod details.
Non-zero return codes
When using KubernetesPodOperator (and GKEStartPodOperator), the return code of the container's entry point determines whether the task is considered successful or not. Non-zero return codes indicate failure.
A common pattern is to execute a shell script as the container entry point to group together multiple operations within the container.
If you are writing such a script, we recommended that you include the
set -e command at the top of the script so that failed commands in the script
terminate the script and propagate the failure to the Airflow task instance.
Pod timeouts
The default timeout for KubernetesPodOperator is 120 seconds, which
can result in timeouts occurring before larger images download. You can
increase the timeout by altering the startup_timeout_seconds parameter when
you create the KubernetesPodOperator.
When a Pod times out, the task specific log is available in the Airflow UI. For example:
Executing <Task(KubernetesPodOperator): ex-all-configs> on 2018-07-23 19:06:58.133811
Running: ['bash', '-c', u'airflow run kubernetes-pod-example ex-all-configs 2018-07-23T19:06:58.133811 --job_id 726 --raw -sd DAGS_FOLDER/kubernetes_pod_operator_sample.py']
Event: pod-name-9a8e9d06 had an event of type Pending
...
...
Event: pod-name-9a8e9d06 had an event of type Pending
Traceback (most recent call last):
File "/usr/local/bin/airflow", line 27, in <module>
args.func(args)
File "/usr/local/lib/python2.7/site-packages/airflow/bin/cli.py", line 392, in run
pool=args.pool,
File "/usr/local/lib/python2.7/site-packages/airflow/utils/db.py", line 50, in wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/airflow/models.py", line 1492, in _run_raw_task
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/site-packages/airflow/contrib/operators/kubernetes_pod_operator.py", line 123, in execute
raise AirflowException('Pod Launching failed: {error}'.format(error=ex))
airflow.exceptions.AirflowException: Pod Launching failed: Pod took too long to start
Pod Timeouts can also occur when the Cloud Composer Service Account lacks the necessary IAM permissions to perform the task at hand. To verify this, look at Pod-level errors using the GKE Dashboards to look at the logs for your particular Workload, or use Cloud Logging.
Failed to establish a new connection
Auto-upgrade is enabled by default in GKE clusters. If a node pool is in a cluster that is upgrading, you might see the following error:
<Task(KubernetesPodOperator): gke-upgrade> Failed to establish a new
connection: [Errno 111] Connection refused
To check if your cluster is upgrading, in Google Cloud console, go to the Kubernetes clusters page and look for the loading icon next to your environment's cluster name.