Google Cloud でのデータ サイエンスに関する概要
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
データ サイエンスがデータを有効活用するための手法であることは知られていますが、機械学習を使用して課題に取り組む際にデータ サイエンスのワークフローの各ステージで役立つツールについて、明確かつ詳細に理解されている方は少ないかもしれません。
そこで、データを有効に活用できるようにするためのプロセスに不可欠な 6 つの大きな分野と、その分野に対応する Google Cloud のプロダクトおよびサービスについてご説明したいと思います。

データ エンジニアリング
データ サイエンスにおける最大の機会損失は、存在することはわかっていても、アクセスできる状態にないデータに起因すると考えられます。これらのデータが使用できないために、さらに詳細な分析を行うことができないことは多々あります。ダウンストリームのシステムの重要な基盤を築くデータ エンジニアリングは、データを利用可能およびアクセス可能にするために、データの転送、形成、充実化を実行します。
Google Cloud でのデータの取り込みとデータの前処理
Google Cloud では、データの取り込みをある場所から別の場所へのデータの移動と考え、データの前処理を消費前の変換、拡張、または拡充のプロセスと考えます。グローバルなスケーラビリティ、高スループット、リアルタイムなアクセス、堅牢性がこのステージでの一般的な課題です。スケーラブルでリアルタイムなバッチデータ処理を実現するためには、マネージド型の Apache Beam サービスである Dataflow を使用してデータの取り込みと前処理のパイプラインを構築することを検討するのがよいでしょう。Dataflow が Google Cloud のアナリティクスのバックボーンであると言われるのには理由があります。
データの取り込みを支援するスケーラブルなメッセージング システムをお求めなら、水平スケーリングが可能なグローバル メッセージング インフラストラクチャである Cloud Pub/Sub をご検討ください。Cloud Pub/Sub は、Google 広告、Google 検索、Gmail などの Google サービスが 1 秒間に億単位のイベント処理を実現するために使用するのと同じインフラストラクチャ コンポーネントを使用してビルドされています。
Google Cloud 上のサーバーレスなデータ ウェアハウスである BigQuery へのデータ移動を自動化する簡単な方法をお求めの場合は、BigQuery Data Transfer Service をご検討ください。データを Cloud Storage に移動する場合は、Storage Transfer Service をご利用いただけます。また、コード不要のデータ取り込みおよび変換ツールをお求めの場合は、Data Fusion をご検討ください。150 を超える構成済みコネクタと変換をご利用いただけます。データ準備のための Dataflow と Data Fusion に加えて、Spark ユーザーは Spark on Google Cloud の関連プロダクトや機能をご利用いただけます。
Google Cloud でのデータ ストレージとデータのカタログ化
構造化データの場合、BigQuery のようなデータ ウェアハウスをご検討ください。また、クラウド データベースであれば Cloud SQL のようなリレーショナル データベース、Cloud BigTable や Cloud Firestore のような NoSQL データベースもお考えいただけます。非構造化データの場合は、いつでも Cloud Storage を使用できます。また、データレイクも検討できます。データの検出、カタログ化、メタデータ管理には、Data Catalog をご検討ください。統合ソリューションには、Dataplex をお考えください。Dataplex は、統合データ管理ソリューションと統合された分析エクスペリエンスを組み合わせたサービスです。
Google Cloud でのデータ エンジニアリングについての詳細
データ エンジニアリング向け学習プログラムを詳しく見る
リファレンス パターンを確認する
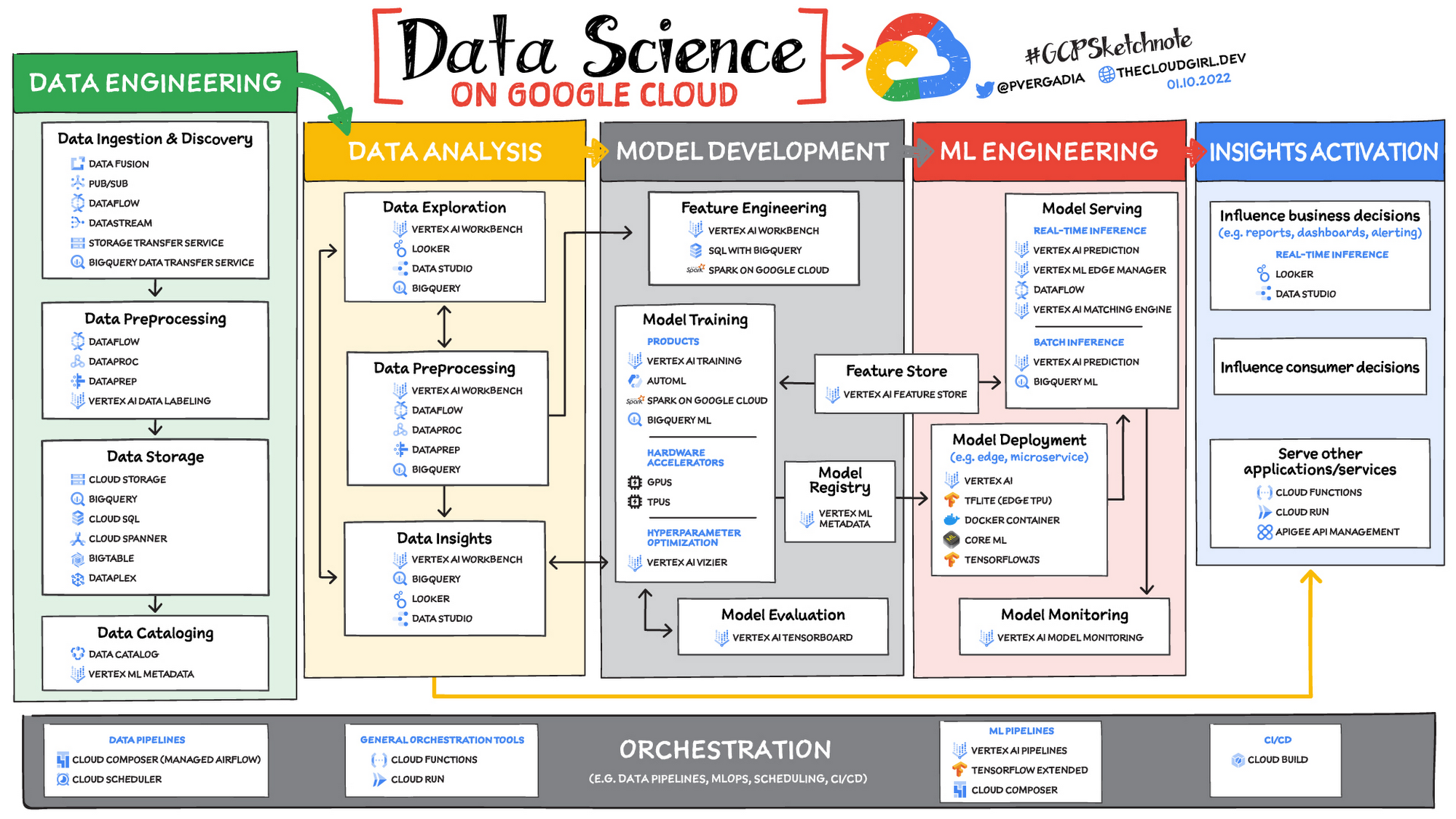
データ分析
記述統計から可視化に至るまで、データ分析はデータの価値が現れ始める段階です。
データ探索、データの前処理、データ分析情報
データ探索は非常に反復的な処理を行います。具体的には、データの前処理によってデータのスライシングとダイシングを行います。これにより、データ分析で、可視化または簡単な group-by や order-by オペレーションを介してマニフェストを開始できるようになります。このフェーズの特徴の一つは、データ サイエンティストがこのデータでどのような疑問を解決しようとしているのかまだわかっていない可能性があることです。この一時的なフェーズでは、データ アナリストまたはデータ サイエンティストがすでに何かを見出しているかもしれませんが、まだ共有していません。分析情報が共有されると、フローは「分析情報の有効化」のステージに入り、これらの分析情報はビジネス上の意思決定の指針となったり、消費者の選択に影響を与えたり、他のアプリケーションやサービスに組み込まれたりして使用されるようになります。
Google Cloud では、データを探索、前処理して分析情報を引き出すたくさんの方法があります。ノートブックベースのエンドツーエンドのデータ サイエンス環境をお求めの場合は、Vertex AI Workbench をご検討ください。BigQuery による SQL でのペタバイト規模の構造化データから、Spark on Google Cloud とそのサーバーレス、自動スケーリング、GPU 高速化機能を使用したデータ処理まで、データ資産全体のアクセス、分析、可視化を可能にします。統合されたデータ サイエンス環境として、Vertex AI Workbench も組み込みの MLOps 機能を使用して、TensorFlow、PyTorch、Spark による機械学習を簡単にします。
最後に、データ ウェアハウスからの構造化データの分析やビジネス インテリジェンスの分析情報の有効化に重点を置く場合、インタラクティブな分析、可視化、ダッシュボード ツールを豊富に利用できる Looker をおすすめします。また、短時間で分析情報を取得できる Looker Blocks もご検討ください。
Google Cloud でのデータ分析についての詳細
Jupyter ベースのフルマネージド ノートブック環境に最適な Vertex AI Workbench について確認する
Spark on Google Cloud の詳細を確認する
データ アナリスト向け学習プログラムについて確認する
一般的な分析ユースケースのリファレンス パターンの詳細を確認する
モデル開発
線形回帰から XGBoost、TensorFlow から PyTorch まで、モデル開発のステージは、機械学習がデータから価値を引き出すための新しい方法を提供し始める段階です。このステージではテストが重要なテーマです。データ サイエンティストはインフラストラクチャ オーバーヘッドや、データ分析のツールや MLOps によりモデルを製品化するためのツール間のコンテキスト切り替えを気に掛けることなく、モデル間のイテレーションを高速化することを目指すことができます。
これらの課題を解決するには、繰り返しになりますが、Jupyter ベースのフルマネージド、スケーラブルかつエンタープライズ向けの環境である Vertex AI Workbench を使用できます。Vertex AI はデータ サイエンスのワンストップ ショップとして、分析と Vertex AI などの機械学習を組み合わせて、課題の解決を簡単にします。Apache Spark、XGBoost、TensorFlow、PyTorch は、Vertex AI Workbench でサポートされているフレームワークの一部にすぎません。Vertex AI Workbench を使用すると、水平方向および垂直方向のスケーリング機能と不要な費用を軽減するアイドル タイムアウト機能と自動シャットダウン機能によりモデル トレーニングに必要な基盤のコンピューティング インフラストラクチャを簡単に管理できます。ノートブック自体は、分散トレーニングやハイパーパラメータの最適化に利用できます。また、ノートブックには、バージョン管理のための Git インテグレーションも含まれています。Vertex AI Workbench を使用することで、データ サイエンティストは必要なコンテキスト切り替えを大幅に削減することができ、従来のノートブックと比べて 5 倍速くモデルを構築してトレーニングできます。
Vertex AI では、コンテナを使用してカスタムモデルのトレーニングとデプロイを実行できます。モデルのトレーニングとデプロイを行うために、ビルド済みコンテナまたはカスタム コンテナを利用できます。
ローコード モデルの開発の場合、データ アナリストとデータ サイエンティストは SQL を BigQuery ML と組み合わせて、BigQuery に組み込まれているサーバーレスな自動スケーリング機能を直接使用することで、モデル(XGBoost、ディープ ニューラル ネットワーク、PCA など)のトレーニングとデプロイを行います。バックグラウンドでは、BigQuery ML が Vertex AI を活用してハイパーパラメータの自動チューニングや Explainable AI を実現します。コード不要なモデル開発の場合、Vertex AI Training を使用することで、マウス操作だけのインターフェースで AutoML を使用して強力なモデルのトレーニングを行えます。AutoML には、AutoML Tables、AutoML Image、AutoML Text、AutoML Video、AutoML Translation が搭載されています。
Google Cloud でのモデル開発についての詳細
Jupyter ベースのフルマネージド ノートブック環境に最適な Vertex AI Workbench について確認する
Vertex AI の詳細について確認する
ML エンジニアリング
満足のいくモデルが開発できたら、次のステップではテスト、デプロイ、モニタリングなど、最適に設計されたアプリケーション ライフサイクルの全アクティビティを取り入れます。そして、それらのアクティビティはすべて、可能な限り自動化され、堅牢である必要があります。
マネージド データセットと Vertex AI の Feature Store は、それぞれデータセットと設計済み特徴の共有リポジトリを提供します。これらは、データにおける信頼できる単一の情報源を提供し、チーム内およびチーム間の再利用とコラボレーションを促進します。Vertex AI のモデル提供機能を使用すると、複数バージョンのモデルのデプロイ、自動容量スケーリング、ユーザー指定のロード バランシングを行うことができます。最後に、Vertex AI の Model Monitoring は、デプロイされたモデルに流れ込む予測リクエストをモニタリングし、本番環境トラフィックがユーザー定義のしきい値や過去の予測リクエストから逸脱した場合に、モデル所有者に自動的に警告する機能を提供します。
MLOps は、今やアプリケーションの分野では当たり前となったスケーラビリティ、モニタリング、信頼性、自動化した CI / CD、その他多くの特徴や機能を備え、技術的にも優れた最新 ML サービスを指す業界用語です。Vertex AI が提供する ML エンジニアリング機能は、社内 ML サービスのデプロイと運用を行ってきた Google の豊富な経験に基づくものです。Google が Vertex AI で目指すのは、誰もが MLOps に不可欠なサービスやベスト プラクティスに簡単にアクセスできるようにすることです。
Google Cloud での ML エンジニアリングと MLOps の詳細
Vertex AI のガイド、チュートリアル、およびドキュメントをフォローする
動画で Vertex AI の詳細を確認する
分析情報の有効化
分析情報の有効化のステージは、データを他のチームやプロセスにとって有用なものにする段階です。Looker とデータポータルを使用することで、チャート、レポート、アラートを使ってビジネスの意思決定に影響を与えるユースケースを実現できます。
また、データはお客様の意思決定にも影響を与え、その結果、たとえば使用量の増加や離脱率の軽減が可能になります。最後に、その他のサービスを使用してデータから分析情報を引き出すこともできます。それらのサービスは Google Cloud の外部、Google Cloud 内部の Cloud Run または Cloud Functions で実行でき、インターフェースとして Apigee API 管理も使用できます。
Google Cloud での分析情報の有効化に関する詳細
動画で Looker と Vertex AI を使ったインタラクティブな ML アプリの構築について確認する
Looker について、または e コマースやデジタル メディアなどでの Looker ソリューションの活用方法について確認する
動画で Cloud Run と Cloud Functions の違いを理解する
オーケストレーション
上述したすべての機能は、最新のデータ サイエンス ソリューションの主要な構成要素を提供しますが、これらの機能を実用化するには、あるサービスから別のサービスへのデータのフローを自動的に管理するオーケストレーションが必要です。そこで、データ パイプライン、ML パイプライン、MLOps の組み合わせが重要になります。効果的なオーケストレーションにより、データの取り込みから本番環境へのモデルのデプロイまでの時間を確実に短縮し、ML システムのモニタリングと把握を可能にします。
データ パイプラインのオーケストレーションでは、Cloud Composer と Cloud Scheduler の両方をパイプラインのキックオフと維持に使用できます。
ML パイプラインのオーケストレーションでは、マネージド機械学習サービスである Vertex AI Pipelines を使用できます。このサービスを使用することで、機械学習モデルのテストおよび開発や、機械学習モデルの本番環境への移行をすばやく行うことができるようになります。Vertex Pipelines はサーバーレスであるため、基盤となる GKE クラスタやインフラストラクチャを管理する必要はありません。必要なときにスケールアップでき、ご利用いただいた分だけお支払いいただきます。つまり、データ サイエンスのパイプラインの構築に専念できます。
Google Cloud でのオーケストレーションの詳細
Airflow をベースとしたパイプライン向けの Cloud Composer の詳細を読む
Vertex AI Pipelines を使用した GitHub でのノートブックのサンプルを試す
MLOps の実践ガイド: 機械学習における継続的デリバリーと自動化のフレームワークのホワイトペーパーを読む
まとめ
Google Cloud は、データから分析情報を生成する包括的なデータ管理、分析、機械学習ツールの統合スイートを提供します。詳しくは、次のリソースをご覧ください。
このブログ投稿にご協力いただいた Alok Pattani、Brad Miro、Saeed Aghabozorgi、Diptiman Raichaudhuri、Reza Rokni に感謝します。
-デベロッパー アドボケイト Polong Lin
-デベロッパー アドボケイト Marc Cohen




