Intro to data science on Google Cloud
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
Polong Lin
Developer Advocate
While you likely know that data science is the practice of making data useful, you may not have a clear landscape around the tools that can aid each stage of the data science workflow as you use machine learning to tackle your challenges.
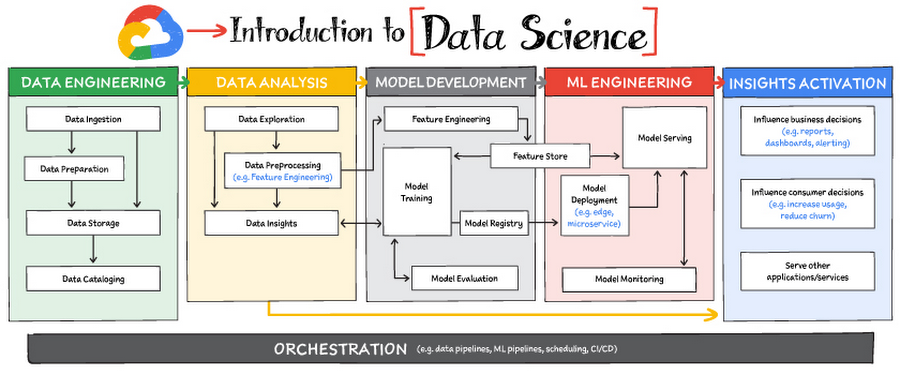
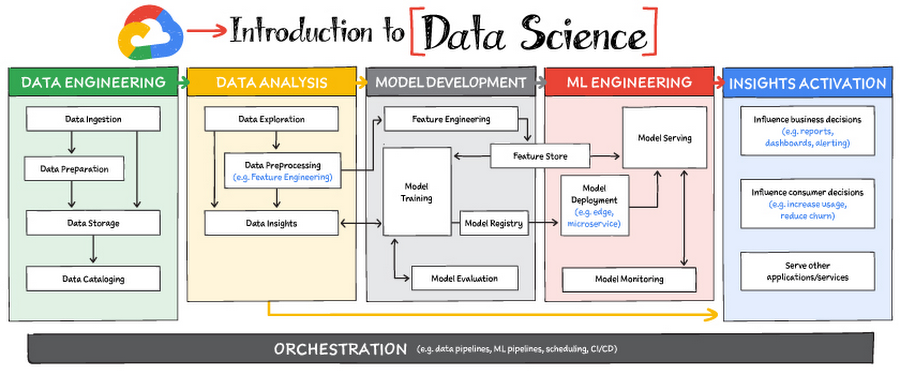
Read on to discover the six broad areas that are critical to the process of making data useful, and some corresponding Google Cloud products and services for those areas.

Data engineering
Perhaps the greatest missed opportunities in data science stem from data that exists somewhere, but hasn't been made accessible for use in further analysis. Laying the critical foundation for downstream systems, data engineering involves the transporting, shaping, and enriching of data for the purposes of making it available and accessible.Data ingestion and data preprocessing on Google Cloud
Here we consider data ingestion as moving data from one place to another, and data preparation the process of transformation, augmentation, or enrichment prior to consumption. Global scalability, high throughput, real-time access, and robustness are common challenges in this stage. For scalable, real-time, and batch data processing, look into building data ingestion and preprocessing pipelines with Dataflow, a managed Apache Beam service. There's a reason why Dataflow is called the backbone of analytics on Google Cloud.If you're looking for a scalable messaging system to help you ingest data, consider Cloud Pub/Sub, a global, horizontally scalable messaging infrastructure. Cloud Pub/Sub was built using the same infrastructure component that enabled Google products, including Ads, Search, and Gmail, to handle hundreds of millions of events per second.
If you want an easy way to automate data movement to BigQuery, a serverless data warehouse on Google Cloud, look into the BigQuery Data Transfer Service. For transferring data to Cloud Storage, take a look at the Storage Transfer Service. Or, for a no-code data ingestion and transformation tool, check out Data Fusion, which has over 150 preconfigured connectors and transformations. In addition to Dataflow and Data Fusion for data preparation, Spark users may want to look at related products and features for Spark on Google Cloud.
Data storage and data cataloging on Google Cloud
For structured data, consider a data warehouse like BigQuery, or any of the Cloud Databases (relational ones like Cloud SQL and NoSQL ones like Cloud BigTable and Cloud Firestore). For unstructured data, you can always use Cloud Storage. You may also want to consider a data lake. For data discovery, cataloging, and metadata management, consider Data Catalog. For a unified solution, take a look at Dataplex, which integrates a unified data management solution with an integrated analytics experience.Learn more about data engineering on Google Cloud
- Explore the data engineering learning path
- Discover reference patterns
- Get certified by Google Cloud as a Professional Data Engineer
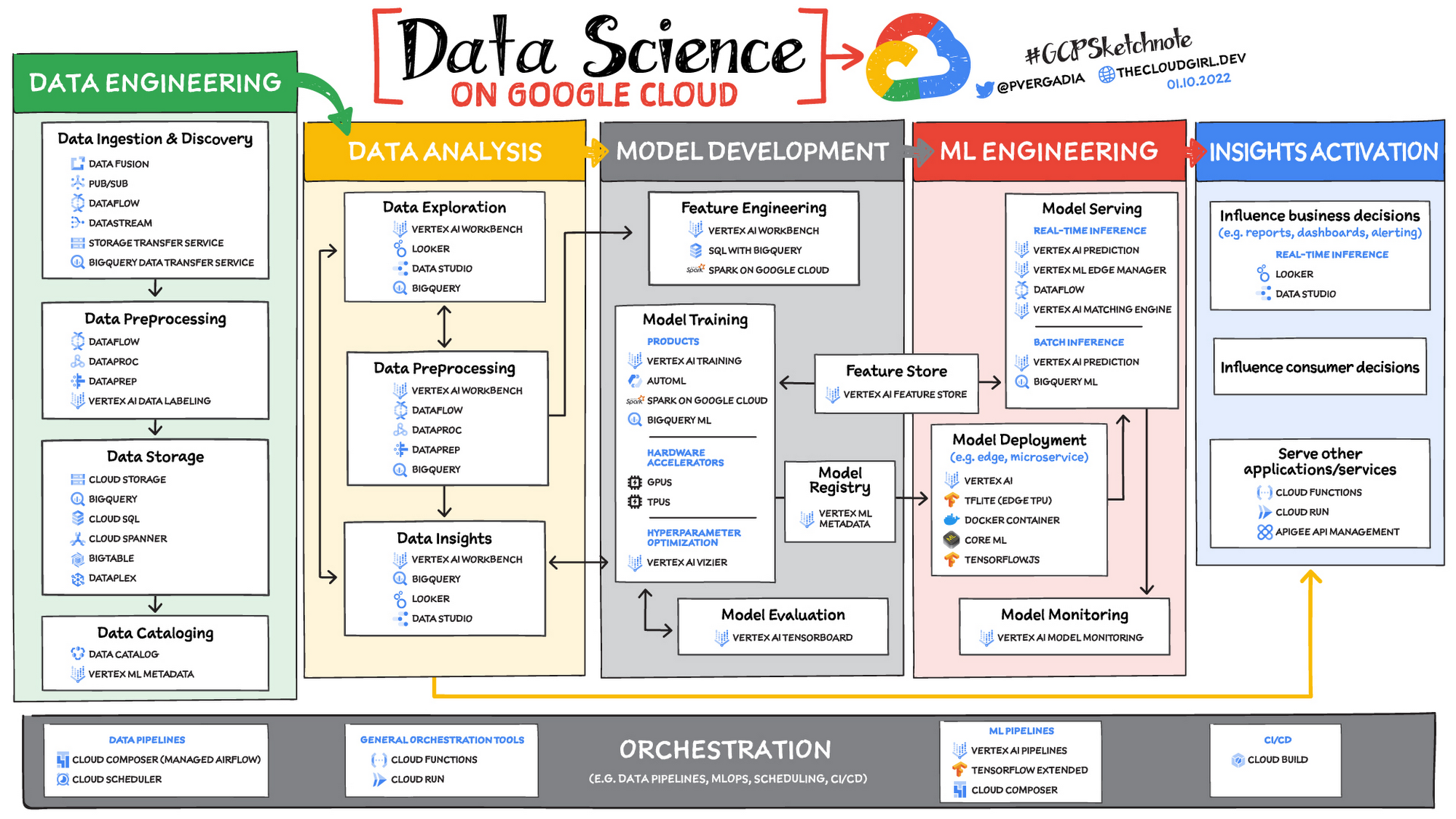
Data Analysis
From descriptive statistics to visualizations, data analysis is where the value of data starts to appear.
Data exploration, data preprocessing, and data insights
Data exploration, a highly iterative process, involves slicing and dicing data via data preprocessing before data insights can start to manifest through visualizations or simply via simple group-by, order-by operations. One hallmark of this phase is that the data scientist may not yet know which questions to ask about the data. In this somewhat ephemeral phase, a data analyst or scientist has likely uncovered some aha-moments, but hasn't shared them yet. Once insights are shared, the flow enters the Insights Activation stage, where those insights become used to guide business decisions, influence consumer choices, or become embedded in other applications or services.
On Google Cloud, there are many ways to explore, preprocess, and uncover insights in your data. If you are looking for a notebook-based end-to-end data science environment, check out Vertex AI Workbench, which enables you to access, analyze, and visualize your entire data estate: from structured data at the petabyte-scale in SQL with BigQuery, to processing data with Spark on Google Cloud and its serverless, auto-scaling, and GPU acceleration capabilities. As a unified data science environment, Vertex AI Workbench also makes it easy to do machine learning with TensorFlow, PyTorch, and Spark, with built-in MLOps capabilities.
Finally, if your focus is on analyzing structured data from data warehouses and insight activation for business intelligence, you may want to also consider using Looker, with its rich interactive analytics, visualizations, dashboarding tools, and Looker Blocks to help you accelerate your time-to-insight.
Learn more about data analysis on Google Cloud
Learn about Vertex AI Workbench for a Jupyter-based fully managed notebook environment
Learn about how you can use BigQuery for petabyte-scale data analysis
Learn about Spark on Google Cloud
Discover the data analyst learning path
Explore reference patterns for common analytics use cases
Model development
From linear regression to XGBoost, from TensorFlow to PyTorch, the model development stage is where machine learning starts to provide new ways of unlocking value from your data. Experimentation is a strong theme here, with data scientists looking to accelerate iteration speed between models without worrying about infrastructure overhead or context-switching between tools for data analysis and tools for productionizing models with MLOps.
To solve these challenges, once again, as a Jupyter-based fully managed, scalable, and enterprise-ready environment, Vertex AI Workbench makes it easy as the one-stop-shop for data science, combining analytics and machine learning, including Vertex AI services. Apache Spark, XGBoost, TensorFlow, and PyTorch are just some of the frameworks supported on Vertex AI Workbench. Vertex AI Workbench makes managing the underlying compute infrastructure needed for model training easy with the ability to scale vertically and horizontally, and with idle timeouts and auto shutdown capabilities to reduce unnecessary costs. Notebooks themselves can be used for distributed training and hyperparameter optimization, and they include Git integration for version control. Due to the significant reduction in context switching required, data scientists can build and train models 5x faster using Vertex AI Workbench than when using traditional notebooks.
With Vertex AI, custom models can be trained and deployed using containers. You can take advantage of pre-built containers or custom containers to train and deploy your models.
For low-code model development, data analysts and data scientists can use SQL with BigQuery ML to train and deploy models (including XGBoost, deep neural networks, and PCA), directly using BigQuery's built-in serverless, autoscaling capabilities. Behind-the-scenes, BigQuery ML leverages Vertex AI to enable automated hyperparameter tuning, and explainable AI. For no-code model development, Vertex AI Training provides a point-and-click interface to train powerful models using AutoML, which comes in multiple flavors: AutoML Tables, AutoML Image, AutoML Text, AutoML Video, and AutoML Translation.
Learn more about model development on Google Cloud
Learn about Vertex AI Workbench for a Jupyter-based fully managed notebook environment
Learn more about Vertex AI
ML engineering
Once a satisfactory model is developed, the next step is to incorporate all the activities of a well-engineered application lifecycle, including testing, deployment, and monitoring. And all of those activities should be as automated and robust as possible.
Managed datasets and Feature Store on Vertex AI provide shared repositories for datasets and engineered features, respectively, which provide a single source of truth for data and promote reuse and collaboration within and across teams. Vertex AI’s model serving capability enables deployment of models with multiple versions, automatic capacity scaling, and user-specified load balancing. Finally, Vertex AI Model Monitoring provides the ability to monitor prediction requests flowing into a deployed model and automatically alert model owners whenever the production traffic deviates beyond user-defined thresholds and previous historical prediction requests.
MLOps is the industry term for modern, well engineered ML services, with scalability, monitoring, reliability, automated CI/CD, and many other characteristics and functions that are now taken for granted in the application domain. The ML engineering features provided by Vertex AI are informed by Google’s extensive experience deploying and operating internal ML services. Our goal with Vertex AI is to provide everyone with easy access to essential MLOps services and best practices.
Learn more about ML engineering and MLOps on Google Cloud
Follow the guides, tutorials and documentation for Vertex AI
Watch this video to learn more about Vertex AI
Discover the data scientist/machine learning engineer learning path
Insights activation
The insights activation stage is where your data has now become useful to other teams and processes. You can use Looker and Data Studio to enable use cases in which data is used to influence business decisions with charts, reports, and alerts.
Data can also influence customer decisions and as a result increase usage or decrease churn, for example. Finally, the data can also be used by other services to drive insights; these services can run outside Google Cloud, inside Google Cloud on Cloud Run or Cloud Functions, and/or using Apigee API Management as an interface.
Learn more about insights activation on Google Cloud
Watch this video to learn about building interactive ML apps using Looker and Vertex AI
Learn about Looker, and Looker solutions for eCommerce, Digital Media and more
Discover a gallery of interactive dashboards created with Data Studio
Watch this video to understand the difference between Cloud Run and Cloud Functions
Orchestration
All of the capabilities discussed above provide the key building blocks to a modern data science solution, but a practical application of those capabilities requires orchestration to automatically manage the flow of data from one service to another. This is where a combination of data pipelines, ML pipelines, and MLOps comes into play. Effective orchestration reduces the amount of time that it takes to reliably go from data ingestion to deploying your model in production, in a way that lets you monitor and understand your ML system.
For data pipeline orchestration, Cloud Composer and Cloud Scheduler are both used to kick off and maintain the pipeline.
For ML pipeline orchestration, Vertex AI Pipelines is a managed machine learning service that enables you to increase the pace at which you experiment with and develop machine learning models and the pace at which you transition those models to production. Vertex Pipelines is serverless, which means that you don’t need to deal with managing an underlying GKE cluster or infrastructure. It scales up when you need it to, and you pay only for what you use. In short, it lets you just focus on building your data science pipelines.
Learn more about orchestration on Google Cloud
Read more about Cloud Composer for Airflow-based pipelines
Try some example notebooks on Github with Vertex AI Pipelines
Read the whitepaper on Practitioners Guide to MLOps: A framework for continuous delivery and automation of machine learning
Summary
Google Cloud offers a complete suite of data management, analytics, and machine learning tools to generate insights from data. Want to learn more? Check out the following resources:
Special thanks to the following contributors to this blogpost: Alok Pattani, Brad Miro, Saeed Aghabozorgi, Diptiman Raichaudhuri, Reza Rokni.




