Dataflow, the backbone of data analytics
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
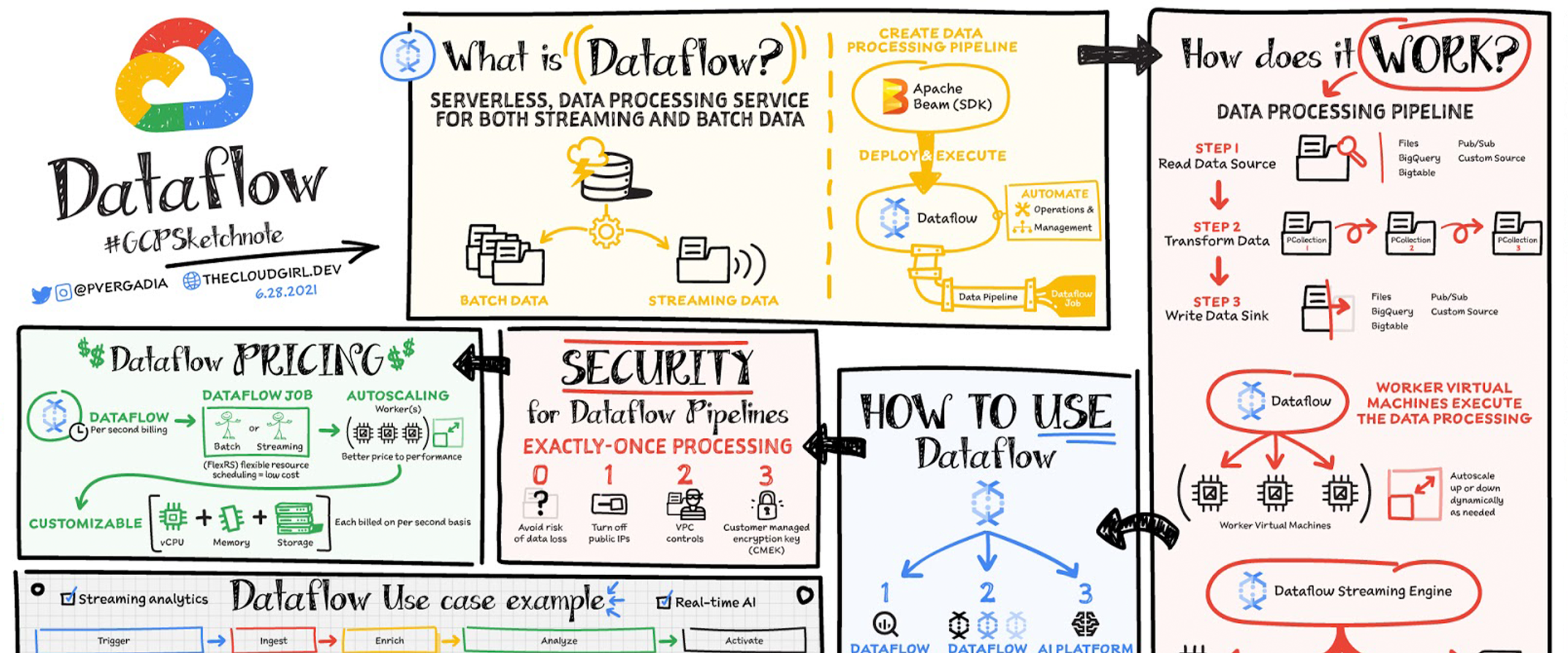
Data is generated in real-time from websites, mobile apps, IoT devices,and other workloads. Capturing, processing and analyzing this data is a priority for all businesses. But, data from these systems is not often in the format that is conducive for analysis or for effective use, by downstream systems. That’s where Dataflow comes in! Dataflow is used for processing & enriching batch or stream data for use cases such as analysis, machine learning or data warehousing.
Dataflow is a serverless, fast and cost-effective service that supports both stream and batch processing. It provides portability with processing jobs written using the open source Apache Beam libraries and removes operational overhead from your data engineering teams by automating the infrastructure provisioning and cluster management.
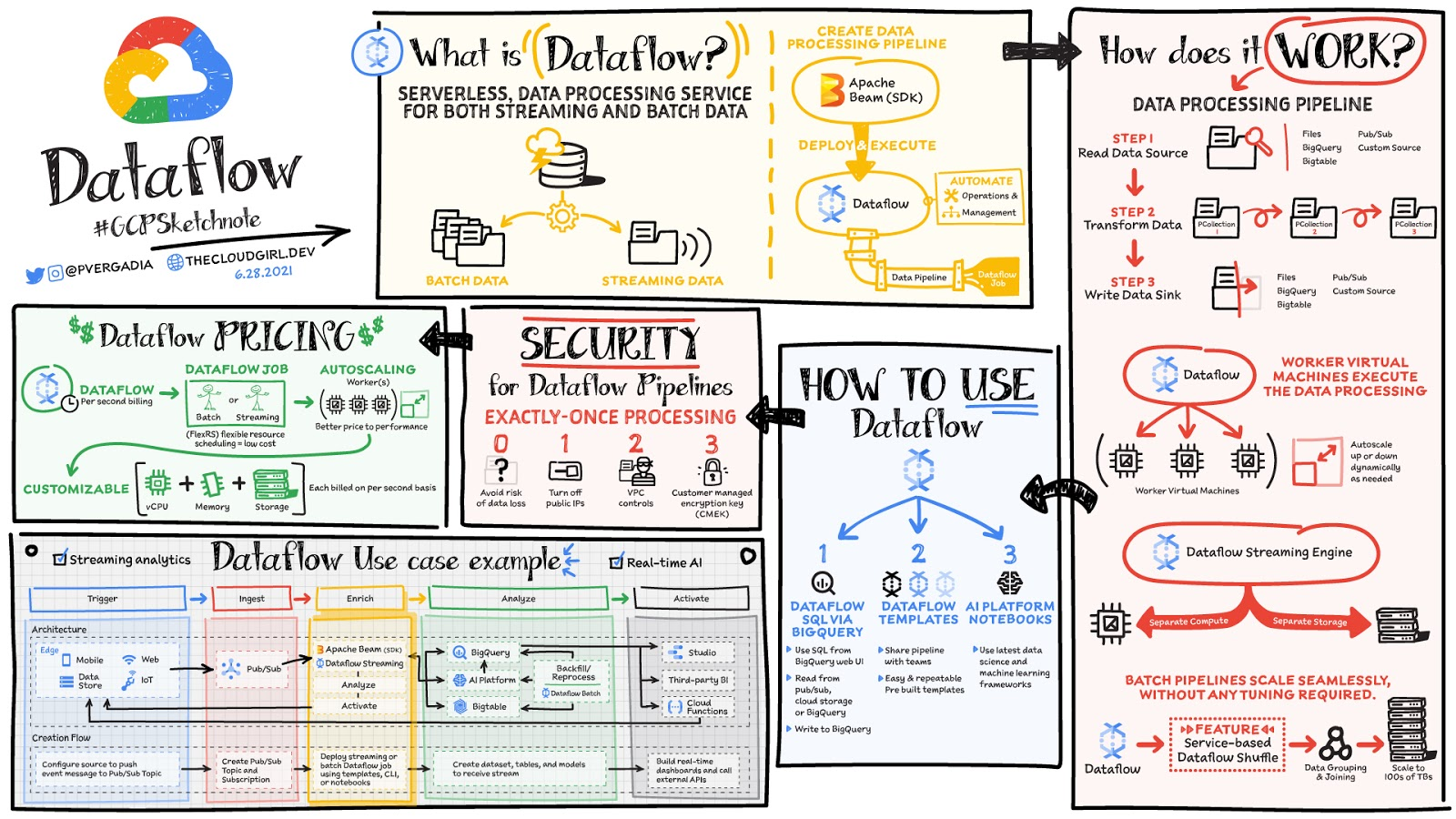
How does data processing work?
In general a data processing pipeline involves three steps: You read the data from a source, transform it and write the data back into a sink.
- The data is read from the source into a PCollection. The ‘P’ stands for “parallel” because a PCollection is designed to be distributed across multiple machines.
- Then it performs one or more operations on the PCollection, which are called transforms. Each time it runs a transform, a new PCollection is created. That’s because PCollections are immutable.
- After all of the transforms are executed, the pipeline writes the final PCollection to an external sink
Once you have created your pipeline using Apache beam SDK in the language of your choice - Java or Python. You can use Dataflow to deploy and execute that pipeline which is called a Dataflow job. Dataflow then assigns the worker virtual machines to execute the data processing, you can customize the shape and size of these machines. And, if your traffic pattern is spiky, Dataflow autoscaling automatically increases or decreases the number of worker instances required to run your job. Dataflow streaming engine separates compute from storage and moves parts of pipeline execution out of the worker VMs and into the Dataflow service backend. This improves autoscaling and data latency!
How to use Dataflow
You can create dataflow jobs using the cloud console UI, gcloud CLI or the API. There are multiple options to create a job.
- Dataflow templates offer a collection of pre-built templates with an option to create your own custom ones! You can then easily share them with others in your organization.
- Dataflow SQL lets you use your SQL skills to develop streaming pipelines right from the BigQuery web UI. You can join streaming data from Pub/Sub with files in Cloud Storage or tables in BigQuery, write results into BigQuery, and build real-time dashboards for visualization.
- Using Vertex AI notebooks from the Dataflow interface, you can build and deploy data pipelines using the latest data science and machine learning frameworks.
Dataflow inline monitoring lets you directly access job metrics to help with troubleshooting pipelines at both the step and the worker level.
Dataflow governance
When using Dataflow, all the data is encrypted at rest and in transit. To further secure data processing environment you can:
- Turn off public IPs to restrict access to internal systems.
- Leverage VPC Service Controls that help mitigate the risk of data exfiltration
- Use your own custom encryption keys customer-managed encryption key (CMEK)
Conclusion
Dataflow is a great choice for batch or stream data that needs processing and enrichment for the downstream systems such as analysis, machine learning or data warehousing. For example: Dataflow brings streaming events to Google Cloud’s Vertex AI and TensorFlow Extended (TFX) to enable predictive analytics, fraud detection, real-time personalization, and other advanced analytics use cases. For a more in-depth look into Dataflow check out the documentation. Want to explore further? Take Dataflow specialization on Coursera & Pluralsight.
For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.




