第一原則に基づいてデータ サイエンス ドリブン組織を構築する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
このブログシリーズでは、論文に関連して、さまざまなタイプのデータドリブンの組織について紹介します。前回のブログでは、データ エンジニアリング ドリブン組織を構築するための大原則について説明しました。このシリーズの第 2 部では、データ サイエンス ドリブン組織を構築する方法に焦点を当てます。
ビッグデータの出現、機械学習の進歩、クラウド サービスの台頭は、この 10 年間で技術的な状況を劇的に変化させており、小売業、化学、あるいはヘルスケアなどの業界の限界を押し広げています。このパラダイム シフトから持続可能な競争優位性を生み出すためには、企業は「データ サイエンス ドリブン組織」になる必要があります。1この記事では、企業が直面している社会技術的な課題について議論し、その道のりを支援するために、第一原則に基づいた概念的なフレームワークを提供します。最後に、これらの原則が Google Cloud 上でどのように実装できるかを紹介します。
データ サイエンス ドリブン組織の課題
データ サイエンス ドリブン組織とは、機械学習やアナリティクスを活用しながら、利用可能なデータから得られる価値を最大化し、持続可能な競争優位性を生み出している企業と表現できます。このような組織になることは、純粋に技術的な課題というよりも、社会技術的な課題です。その中で、4 つの主要な課題を特定しました。
柔軟性に欠ける: 多くの企業は、急速に変化する技術的な状況に迅速に対応できるだけの柔軟なインフラストラクチャを構築していません。このような柔軟性に欠けた状態は、ロックイン効果、時代遅れの技術スタック、潜在的な候補への悪いシグナリングなどのコストを伴います。データ ウェアハウスのような成熟した分野では影響は少ないかもしれませんが、データ サイエンスや機械学習では最重要課題になります。
秩序に欠ける: ほとんどの組織はオーガニックな方法で成長します。その結果、標準化されていない技術インフラストラクチャになることが多くなります。標準化と柔軟性は正反対と思われがちですが、組織全体で技術的な「共通語」を確立するためには、ある程度の標準化が必要です。同じものがないと、チーム間の共同作業や知識の共有に支障をきたし、従来のソフトウェア工学に見られるようなモジュール化されたアプローチが妨害されます。
透明性に欠ける: データ サイエンスや機械学習は、基本的にはデータドリブン(エンジニアリング)の規範です。データは常に流動的であるため、データ サイエンス ドリブン組織にとって、説明責任と説明可能性は極めて重要です。2そのため、データ サイエンスと機械学習のワークフローは、従来のソフトウェア工学と同じように厳密に定義する必要があります。そうしないと、このようなワークフローは予測不可能なブラック ボックスになってしまいます。
データ文化(またはその欠如): ほとんどの組織では、データがチームによって管理され、そのチームがリクエストに応じてスケールできないため、迅速なアクセスを提供するうえでボトルネックとなる権限文化になっています。しかし、データ文化を重視する組織では、ガバナンスを維持しながらデータにアクセスする明確な方法があります。その結果、機械学習の実践者は、政治や官僚主義に振り回されることなく、テストを実行できます。
データ サイエンス ドリブン組織におけるペルソナ
データ サイエンス ドリブン組織は、異質なものです。とはいえ、ほとんどの組織が、データ エンジニア、機械学習エンジニア、データ サイエンティスト、アナリストという 4 つのコアペルソナを活用しています。これらの役割は固定されたものではなく、ある程度重複していることに留意する必要があります。すべてのペルソナのコラボレーションと可能性を最大限に発揮できるような組織構造にする必要があります。
データ エンジニアは、データ パイプラインを作成し、利用可能なデータが衛生的なニーズを満たすことを確認します。たとえば、複数のデータソースをクレンジング、結合、拡充して、データをダウンストリーム インテリジェンスのベースとなる情報に変えます。
機械学習エンジニアは、完全な機械学習モデルを開発し、保守します。機械学習エンジニアは 4 つのペルソナの中で最も希少な存在ですが、組織がビジネス クリティカルなワークフローを本番環境で実行することを計画した場合、彼らは不可欠な存在となります。
データ サイエンティストは、データ エンジニアと機械学習エンジニアの結節点としての役割を担っています。ビジネス ステークホルダーとともに、ビジネス上のニーズを検証可能な仮説に変換し、機械学習ワークロードから価値が得られることを確認し、データからの価値を示すレポートを作成します。
データ アナリストは、ビジネスに分析情報をもたらし、ビジネスが求めているデータドリブンのソリューションを確実に実行します。データ アナリストはアドホックな質問に答え、過去のデータだけでなく、最近起こったことを分析した定期的なレポートを提供します。
企業がデータ サイエンス チームを集中的に構築すべきか、分散的に構築すべきかについては、さまざまな議論があります。いずれの場合も、先に述べたような課題に直面します。また、中央の組織からデータ サイエンティストが組み込まれた連携型の組織など、ハイブリッドなモデルもあります。だからこそ、第一原則を使用してにこれらの課題に取り組む方法に注力することがより一層重要になります。以下のセクションでは、これらの原則について説明し、それらの目標を促進するためにデータ サイエンスと機械学習のプラットフォームをどのように設計する必要があるかを示します。
データ サイエンス ドリブン組織を構築するための第一原則
適応性: プラットフォームには、あらゆる種類のペルソナを可能にする柔軟性が求められます。たとえば、データ サイエンティスト / アナリストの中には、自分でカスタムモデルを開発することを好む人もいれば、AutoML のようなノーコードのソリューションを使ったり、SQL で分析を行ったりすることを好む人もいるでしょう。また、TensorFlow、R、Pytorch、Beam、Spark など、さまざまな機械学習やデータ サイエンスのツールが利用できることも含まれます。同時に、プラットフォームは、ロックイン効果を防ぐために可能な限りオープンソース技術をサポートしながら、マルチクラウドやオンプレミス環境で動作するようなオープンなものである必要があります。最後に、組織のニーズに合わせてプラットフォームを迅速にスケールする必要があるため、リソースがボトルネックになってはいけません。
有効化: エンドユーザーが使用するツールに分析を組み込むことでモデルを運用する機能が、幅広いユーザーへのサービス提供におけるスケーリングを実現するための鍵となります。少量のデータをサービスに送信すると、レスポンスで予測を返してくれる機能があるため、データ サイエンスに関する専門知識が少ないデベロッパーでもモデルを利用できます。また、エッジ推論や自動化されたプロセスを、柔軟な API を用いてシームレスにデプロイし、モニタリングすることも重要です。これにより、プライベートおよびパブリック クラウドのインフラストラクチャ、オンプレミスのデータセンター、エッジデバイスに AI を分散させることができます。
標準化: 高度に標準化されていることは、プラットフォーム全体の効率化につながります。コードや技術的なアーティファクトを共有する標準化された方法をサポートするプラットフォームは、社内のコミュニケーションを向上させます。このようなプラットフォームには、リポジトリ、Feature Store、メタデータ ストアが組み込まれていることが期待されます。さらに、それらのリソースをクエリ可能にし、アクセス可能にすることで、チームのパフォーマンスとクリエイティビティを高めることができます。このようなコミュニケーションが可能になって初めて、データ サイエンスや機械学習のチームは、従来のソフトウェア技術と同じように、モジュール方式で作業できるようになります。標準化の重要な側面は、ソースシステムとターゲット システムにすばやく接続できるように、標準的なコネクタを使用することで有効になります。Datastream やData Fusion などのプロダクトがそのような機能を提供します。さらに、 高度な標準化によって、機械学習やデータ サイエンスのワークフローの大半に見られる「技術的負債」(グルーコード)を回避できます。3
説明責任: データ サイエンスや機械学習のユースケースでは、不正検知、医療画像、リスク計算など、デリケートなテーマを扱うことが多いです。そのため、データ サイエンスと機械学習のプラットフォームは、これらのワークフローを可能な限り透明化し、説明可能にし、安全にすることが最も重要です。オープン性は卓越した運用につながります。データ サイエンスや機械学習のワークフローのすべての段階でメタデータを収集して、モニタリングすることは、次のような質問をすることができる「紙の記録」を作成するために重要です。
モデルのトレーニングにはどのデータを使用しましたか?
どのハイパーパラメータを使用しましたか?
本番環境でのモデルの挙動はどうですか?
直近の期間で、データのブレやモデルスキューが発生しましたか?
さらに、データ サイエンス ドリブン組織では、自分たちのモデルを明確に理解する必要があります。従来の統計手法ではあまり問題になりませんが、ディープ ニューラル ネットワークのような機械学習モデルでは、より不透明な部分があります。プラットフォームは、自信を持って使用するために、そのようなモデルを分析するためのシンプルなツールを提供する必要があります。最後に、成熟したデータ サイエンス プラットフォームは、データとアーティファクトを保護するためのあらゆるセキュリティ対策を提供するとともに、リソースの使用状況をきめ細かく管理する必要があります。ビジネスへの影響: McKinsey によると、多くのデータ サイエンス プロジェクトは、試験運用や概念実証の段階を超えることができません。4したがって、新たな取り組みのビジネスへの影響を予測し、測定する能力や、最新のクールなソリューションではなく ROI を選択することがより重要になります。そのため、ML モデルの購入、構築、カスタマイズのタイミングを見極め、それらを統一された統合スタックに接続することが重要です。たとえば、何か月もかけて開発したモデルを構築するのではなく、API を呼び出すだけで利用できるソリューションがあれば、より高い ROI を実現し、価値を示すことができます。
最後に、第一原則のまとめをして本編を終了します。次のセクションでは、それらの原則が Google Cloud の統合 ML プラットフォーム Vertex AI でどのように適用できるかを紹介します。
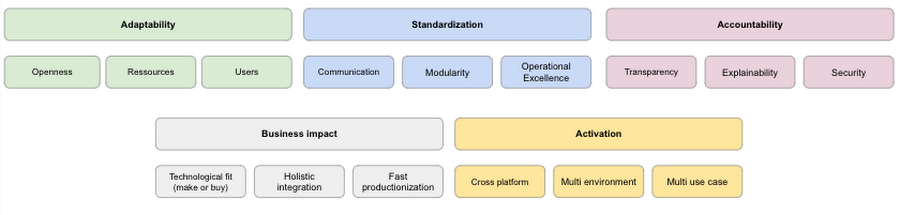
第一原則を用いて Google Cloud 上にデータ サイエンス プラットフォームを構築する
適応性
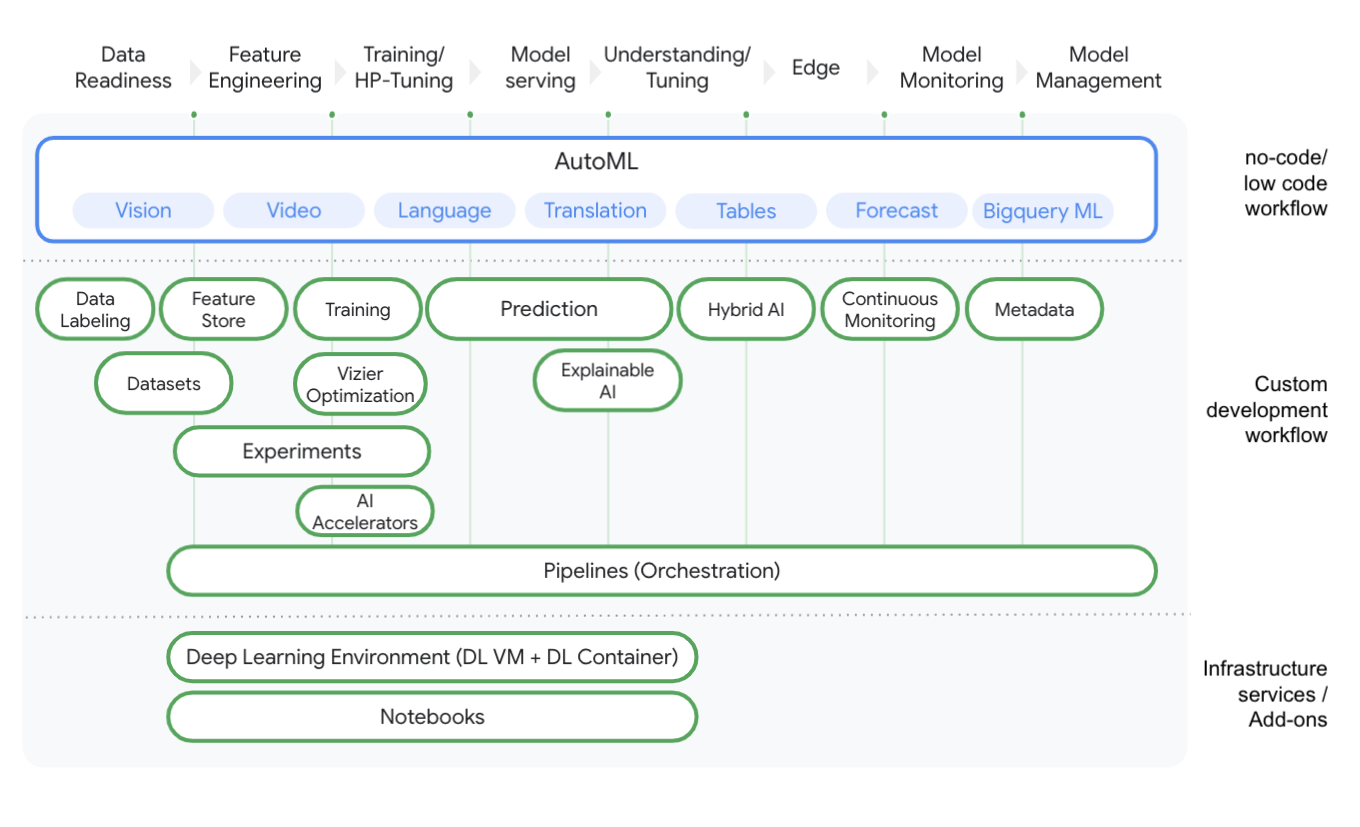
Vertex AI では、第一原則に基づいて構築された、データの準備からモデルの管理まで、データ サイエンスと機械学習のジャーニー全体をカバーするプラットフォームを提供しています。Vertex AI は、データ サイエンスと機械学習のワークフローに対して、ノーコード、ローコード、カスタムコードの手順を提供することで、データ サイエンスと機械学習の利用方法を開放します。たとえば、データ サイエンティストが分類モデルを構築したい場合、AutoML Tables を使用して数分でエンドツーエンドのモデルを構築できます。また、Vertex AI 上で独自のノートブックを立ち上げ、好みのフレームワーク(たとえば、TensorFlow、Pytorch、R)でカスタムコードを開発することもできます。完全なソリューションを構築するための参入障壁を減らすことは、デベロッパーの時間を節約するだけでなく、より幅広いペルソナ(データ アナリストやビジネス アナリストなど)を可能にします。このように障壁が減ることで、組織全体がより一層データ サイエンス駆動型 / 機械学習駆動型になることを可能にするツールを活用できるようになります。
私たちは、柔軟性が高く、人材をひきつけ、ロックインを減らすことができるオープンソース技術を強く信じています。Vertex Pipelines では、データ サイエンスと機械学習のワークフローのオーケストレーションに関するオープンソースの世界の業界標準を反映しています。その結果、データ サイエンティストや機械学習エンジニアが、自分のワークフローをコンテナ化してオーケストレートできるようになりました。Vertex AI により、リソース プロビジョニングのためのエンジニアリング オーバーヘッドを削減し、必要に応じてスケールアップやスケールダウンができる柔軟でコスト効率の高い方法を提供しました。データ サイエンティストや機械学習の実務担当者は、たとえば、Vertex AI 上のノートブックに数行の Python コードを記述するだけで、分散型のトレーニングや予測ジョブを実行できます。
有効化
エンドユーザーが使用するツールにアナリティクスを組み込むことで、モデルを運用化することが重要です。これにより、従来のデータ サイエンスのユーザーを超えて、他のユーザーをデータ サイエンスのアプリケーションに取り込むことができます。たとえば、BigQuery ML のモデルをトレーニングし、Vertex AI の予測を使ってスケールできます。たとえば、SQL クエリを実行するビジネス アナリストが、選択した ML モデルの能力をテストし、何が最適なソリューションであるかを実験できるとします。これにより、ビジネスへの影響がより早く確認できるため、起動までの時間が短縮されます。一方、Vertex Edge Manager は、Vertex AI を搭載したエッジデバイスに ML モデルをデプロイ、管理、実行できます。
標準化
すべての AI サービスを Vertex AI の下に置くことで、データ サイエンスと機械学習のワークフローを標準化しました。Vertex Pipelines と組み合わせることで、Vertex のすべてのコンポーネントをオーケストレーションすることができ、あらゆる形態のグルーコードが不要になり、卓越した運用の向上につながります。 Vertex Pipelines はコンポーネント(コンテナ化されたステップ)に基づいているため、パイプラインの一部を他のチームと共有できます。たとえば、データ サイエンティストがデータベースからデータを抽出するための ETL パイプラインを書いたとします。この ETL パイプラインは、ダウンストリームのデータ サイエンスや機械学習のタスクのための特長を作成するために使用されます。データ サイエンティストは、このコンポーネントをパッケージ化し、GitHub や Cloud Source Repositories のレポジトリを使って共有し、他のチームが自分のワークフローにシームレスに統合できます。これにより、チームはよりモジュール化された方法で作業を行うことができ、全体的なチーム コラボレーションが促進されます。このような標準化された環境を持つことで、データ サイエンティストや機械学習エンジニアがチーム間でローテーションし、ワークフロー間の互換性の問題を回避することが容易になります。Vertex Feature Store のような新しいコンポーネントは、組織全体で機能を共有することでコラボレーションをさらに向上させます。
説明責任
データ サイエンスや機械学習のプロジェクトは、複雑でダイナミックであるため、高度な説明責任が求められます。そのためには、データ サイエンスや機械学習のプロジェクトでは、プロセス全体のニュアンスを捉えた「紙の記録」を作る必要があります。Vertex ML Metadata は、トレーニングされたモデルや実行中のワークフローのメタデータを自動的に追跡します。ワークフローの履歴(モデルがどのようにトレーニングされたか、どのデータが使用されたか、モデルがどのようにデプロイされたかなど)を把握するためのメタデータ ストアを提供します。新しいモデル リポジトリでは、プロジェクトの下でトレーニングされたすべてのモデルの概要をすばやく確認できます。Vertex Explainable AI のような追加サービスは、機械学習モデルがある予測をした理由を理解するのに役立ちます。さらに、予測のブレやトレーニング / サービング スキューの検出を含む継続的なモニタリングなどの機能により、本番稼働モデルをコントロールできます。
ビジネスへの影響: 先に述べたように、ML モデルを購入、構築、またはカスタマイズするタイミングを見極め、それらを統一された統合スタックに接続することが重要です。たとえば、自社のサービスやプロダクトを翻訳によって世界中のお客様に提供したいと考え、サイトやユーザーのコメントを翻訳する場合、Cloud Translation API を利用できます。それがまさにトレーニングされたものであり、ML モデルをトレーニングするためのインターネット サイズのデータセットはおそらく存在しません。一方で、お客様自身でカスタム ソリューションを構築することも可能です。Google Cloud には同じ入力(写真)とラベルでトレーニングされた Vision API があります。しかし、組織にはそのようなイメージのはるかに大きなデータセットがあり、特定のユースケースでより良い結果が得られる可能性があります。もちろん、いつでも完成したモデルと既製のソリューションを比較して、その判断が正しかったかどうかを確認できます。実現可能性の確認は重要なので、モデル構築の話の際には、正しい判断をしているかどうかを確認するための簡単な方法をいつも紹介しています。
まとめ
データ サイエンス ドリブン組織の構築には、いくつかの社会技術的な課題が伴います。多くの場合、組織のインフラストラクチャは、急速に変化する技術的状況に対応できるだけの柔軟性を備えていません。また、プラットフォームには、チーム間のコミュニケーションを促進し、技術的な「共通語」を確立するのに十分な標準化が必要です。これは、チーム間でモジュール化されたワークフローを可能にし、卓越した運用を確立するための鍵となります。さらに、複雑なデータ サイエンスや機械学習のワークフローを安全にモニタリングするには、不透明すぎることが多いです。私たちは、データ サイエンス ドリブン組織は、技術的なオープン性という点で適応性の高い技術プラットフォームの上に構築されるべきだと主張します。そのため、幅広いペルソナを実現し、技術的なリソースを柔軟にサーバーレスで提供します。ソリューションを購入するか構築するかは、組織の費用対効果を実現するための重要なドライバーの一つであり、これによって AI ソリューションがもたらすビジネスへの影響が決まります。同時に、多くのユーザーが利用できることで、より多くのユースケースを実現できます。最後に、最大限の説明責任を果たすためには、データ サイエンスや機械学習のワークフローをオープン、説明可能、かつ安全にするためのツールやリソースをプラットフォームが提供する必要があります。Vertex AI は、これらの要素に基づいて構築されており、お客様の組織がデータ サイエンス ドリブン組織になることを支援します。詳細については、Vertex AI ページにアクセスしてください。
1. データ サイエンスは、ビッグデータ、分析、機械学習の相互作用の包括的な用語として使用されています。
2. Covid のパンデミックはその典型的な例で、私たちの環境に大きな影響を与え、データ サイエンスや機械学習のワークフローのベースとなるデータにも影響を与えました。
3. Sculley et al. (2015)。機械学習システムの隠れた技術的負債.
4. https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2020
- 機械学習シニア スペシャリスト Dr. Sören Petersen
- データ アナリティクス プラクティス リード Firat Tekiner



