データ分析を支える Dataflow
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
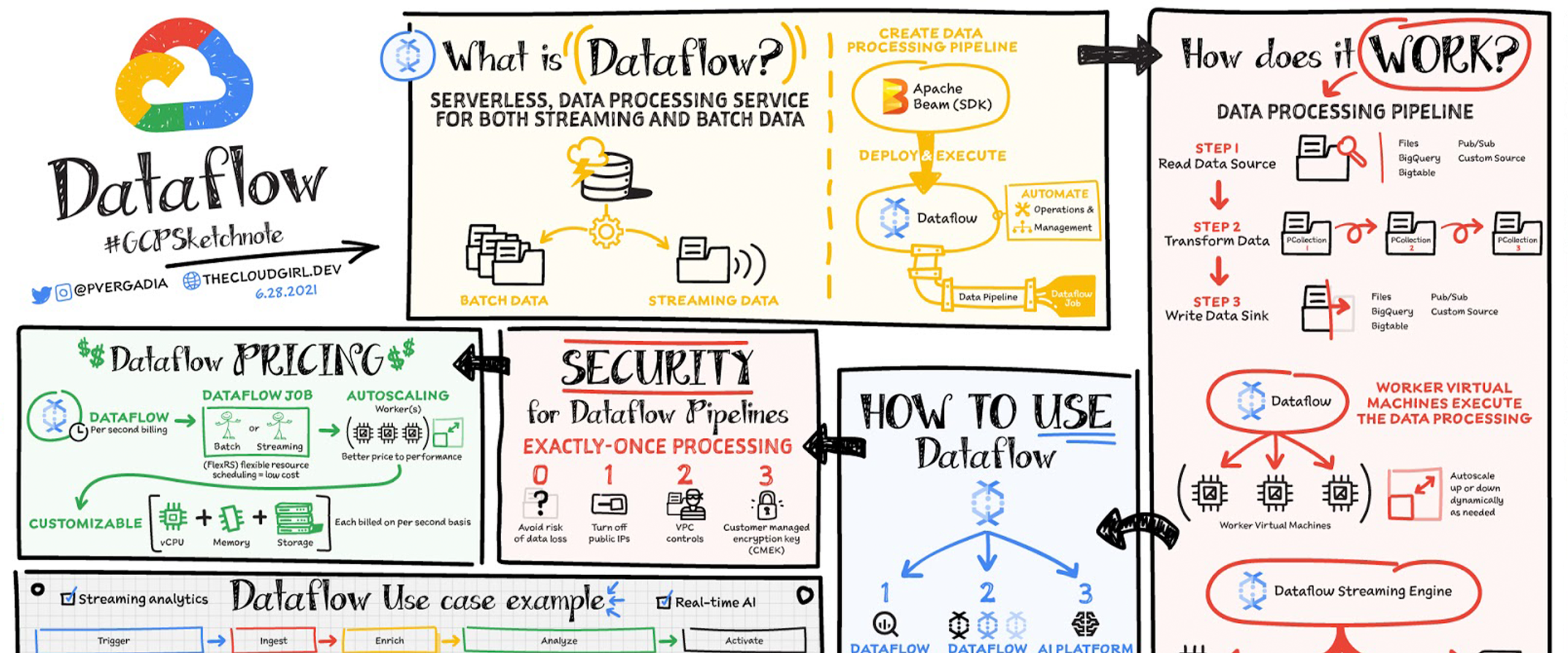
データは、ウェブサイト、モバイルアプリ、IoT デバイス、その他のワークロードからリアルタイムに生成されます。こうしたデータのキャプチャ、処理、分析はあらゆる企業にとっての優先事項です。ただし、このようなシステムから生成されたデータは、ダウンストリームのシステムによる分析や効果的な使用に有効な形式ではないことがほとんどです。そこで Dataflow の出番です。Dataflow は分析、機械学習、データ ウェアハウジングなどのユースケースに合わせて、バッチデータやストリーム データを処理、拡張するために使用されます。
Dataflow は、ストリーミングとバッチ処理をサポートする、サーバーレスで高速かつ費用対効果の高いサービスです。オープンソースの Apache Beam ライブラリを使用して作成された処理ジョブに移植性をもたらすだけでなく、インフラストラクチャのプロビジョニングとクラスタ管理を自動化することによってデータ エンジニアリング チームから運用上のオーバーヘッドを取り除きます。
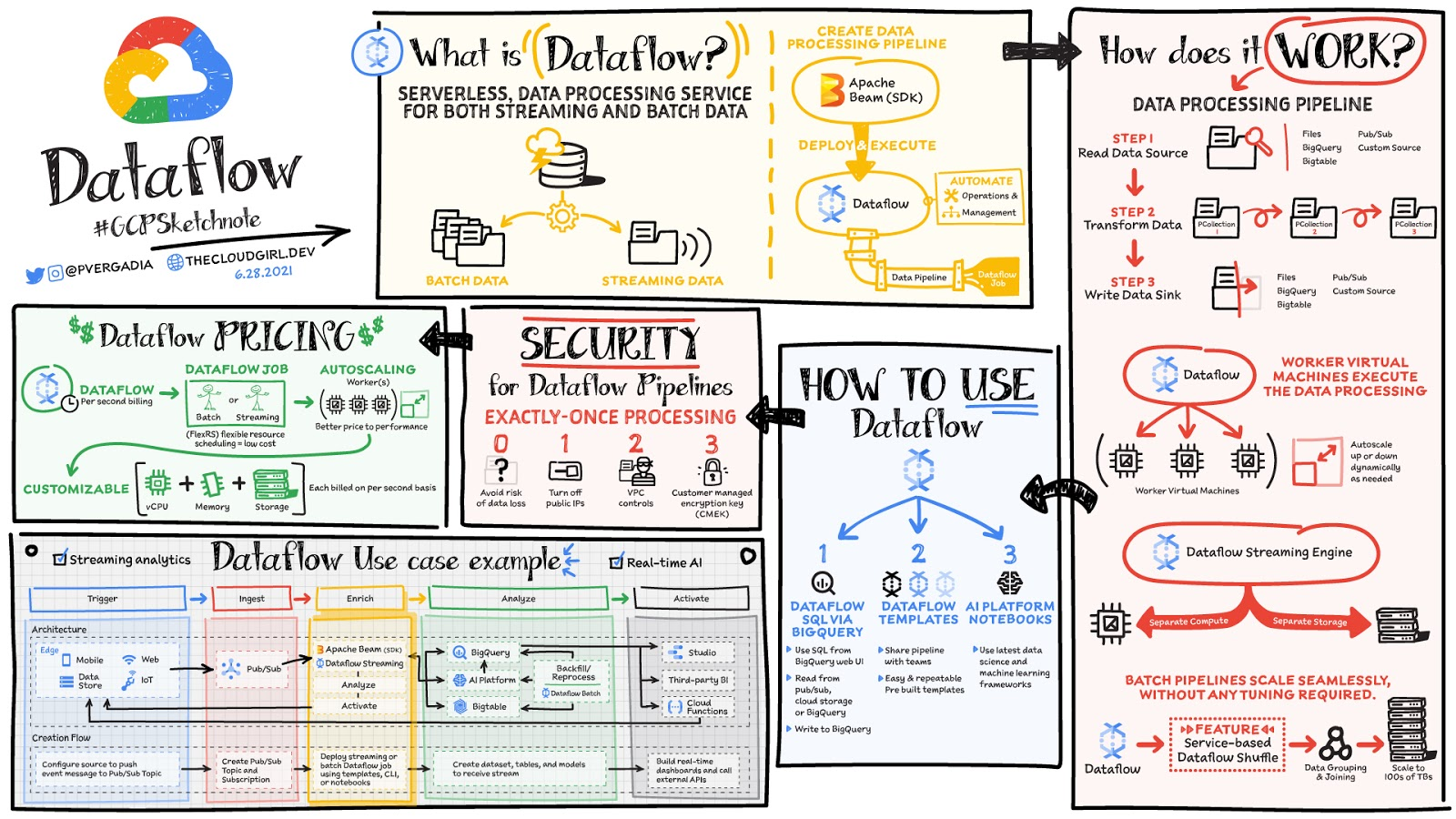
データ処理の仕組み
一般に、データ処理パイプラインには、ソースからのデータの読み取り、変換、シンクへのデータの書き戻しという 3 つのステップが含まれます。
データはソースから PCollection に読み込まれます。「P」は「並列」を表していて、PCollection は複数のマシンに分散するように設計されています。
次に、PCollection に対して、変換と呼ばれる操作が 1 つ以上行われます。変換が行われるたびに、新しい PCollection が作成されます。これは、PCollection が変更不可であるためです。
すべての変換が行われると、パイプラインは最終的な PCollection を外部シンクに書き込みます。
任意の言語(Java または Python)で Apache Beam SDK を使ってパイプラインを作成したら、Dataflow を使用してパイプラインをデプロイ、実行できます(これは Dataflow ジョブと呼ばれます)。次に、Dataflow により、データ処理を行うワーカー仮想マシンが割り当てられ、ワーカー仮想マシンのシェイプとサイズをカスタマイズできます。また、トラフィック パターンの変化が大きい場合は、Dataflow の自動スケーリングによって、ジョブの実行に必要なワーカー インスタンスの数が自動的に増減します。Dataflow ストリーミング エンジンは、コンピューティングとストレージを分離し、パイプライン実行の一部をワーカー VM から Dataflow サービス バックエンドに移動します。そのため、自動スケーリングとデータ レイテンシが向上します。
Dataflow の使用方法
Cloud Console の UI、gcloud CLI、API を使用して Dataflow ジョブを作成できます。ジョブを作成するためのオプションが複数あります。
Dataflow テンプレートは、独自のカスタム テンプレートを作成するオプションを備えた、事前構築済みのテンプレートのコレクションを提供します。カスタム テンプレートは組織内の他のユーザーと簡単に共有できます。
Dataflow SQL では、SQL スキルを使用して、直接 BigQuery ウェブ UI からストリーミング パイプラインを開発できます。Pub/Sub からのストリーミング データを Cloud Storage のファイルや BigQuery のテーブルと結合し、結果を BigQuery に書き込み、リアルタイム ダッシュボードを構築して可視化できます。
Dataflow のインターフェースから Vertex AI Notebooks を使用すると、最新のデータ サイエンスや機械学習フレームワークでデータ パイプラインを構築してデプロイできます。
Dataflow のインライン モニタリングを使用すると、ジョブの指標に直接アクセスして、ステップレベルとワーカーレベルの両方でパイプラインのトラブルシューティングに役立てることができます。
Dataflow のガバナンス
Dataflow を使用すると、すべてのデータが保存時も転送時も暗号化されます。さらに次のことを実施することで、データ処理環境の保護をより強化できます。
パブリック IP をオフにして、内部システムへのアクセスを制限します。
データの引き出しのリスクを軽減するのに役立つ VPC Service Controls を活用します。
独自のカスタム暗号鍵である顧客管理の暗号鍵(CMEK)を使用します。
まとめ
Dataflow は分析、機械学習、データ ウェアハウジングなど、ダウンストリームのシステムの処理と強化が必要なバッチデータやストリーム データに最適です。たとえば、Dataflow により、Google Cloud の Vertex AI と TensorFlow Extended(TFX)にストリーミング イベントを送信できます。これにより、予測分析、不正行為検出、リアルタイム パーソナライズなどの高度な分析ユースケースが可能となります。Dataflow の詳細については、ドキュメントをご参照ください。もっと詳しくお知りになりたい場合は、Coursera や Pluralsight で Dataflow スペシャライゼーションを受講いただけます。

#GCPSketchnote をさらにご覧になるには、GitHub リポジトリをフォローしてください。同様のクラウド コンテンツについては、Twitter で @pvergadia をフォローしてください。thecloudgirl.dev もぜひご覧ください。
-Google デベロッパー アドボケイト Priyanka Vergadia




