さあ始めましょう!ML パイプライン実行のトリガー
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
ML パイプラインはエンドツーエンドの ML ワークフローを自動化するのに役立ちます。では、一歩進んで、ご自身のパイプラインの実行を自動化したい場合はどうでしょう。この投稿でその手順を詳しくお伝えします。BigQuery テーブルに追加されたデータに応じて、Vertex Pipelines の実行をトリガーする方法を学びましょう。
今回はゼロからパイプラインを構築するのではなく、パイプラインの実行を自動化する方法にフォーカスします。ML パイプラインの構築について詳しく知りたい場合は、この Codelab か、こちらのブログ投稿をご覧ください。
ML パイプラインの簡単な復習
ML パイプラインという言葉に混乱しているのはあなただけではありません。まずはその意味、またその実装に使用するツールを理解しましょう。ML パイプラインは、MLOps のより大規模な実践の一部であり、再現性と信頼性の高い方法を用いた ML ワークフローの製品化に主眼を置いています。
ML システムを構築する際に、データの収集や前処理、モデルのトレーニング、デプロイ、評価などのステップを確立している場合、これらのステップをアドホックの異なるプロセスとして構築することから始めるかもしれません。こうして作成したワークフローを他のチームと共有し、他のチームがそのステップを行ったときにも同じ結果が得られるようにしたいとお思いかもしれません。接続されていない ML ステップの共有は困難を伴いますが、そんなときに役立つのがパイプラインです。パイプラインを使えば、ML ワークフローを一連のステップまたはコンポーネントとして定義できます。パイプラインの各ステップはコンテナとして体現され、各ステップの出力は次のステップへの入力として供給されます。
パイプラインはどのようにして構築するのでしょう?パイプライン ステップを表現および接続してコンテナに変換するためのツールを提供し、この手間のかかる作業の多くを実行するオープンソース ライブラリが存在します。ここでは、ML パイプラインを構築、モニタリング、実行するためのサーバーレス ツールである Vertex Pipelines を使用します。素晴らしいのは、Kubeflow Pipelines(今回使用します)とTensorflow Extended(TFX)の 2 つの人気オープンソース フレームワークで構築されたパイプラインをサポートしている点です。
Kubeflow Pipelines SDK で Vertex Pipelines をコンパイルする
この投稿では、自動化するパイプラインがすでに定義されていることを前提としています。これを Kubeflow Pipelines SDK を使って行った場合を考えてみましょう。パイプラインを定義したら、次はそれをコンパイルします。これにより、パイプラインを実行する際に使用するパイプライン定義の JSON ファイルが生成されます。
パイプラインがコンパイルされれば、いつでも実行できます。パイプライン定義がどのようなものか知りたい場合は、こちらのチュートリアルをご覧ください。
BigQuery に追加されたデータからパイプライン実行をトリガーする
MLOps では、新しいデータが利用可能になったら、モデルを再トレーニングするのが一般的です。これから、BigQuery のテーブルにさらにデータが追加された場合にパイプライン実行をトリガーする方法を具体的に見ていきます。ここでは、パイプラインが BigQuery からのデータを使用してモデルをトレーニングすることを前提としていますが、以下に示したものと同様のアプローチを用いて、BigQuery を別のデータソースに置き換えることも可能です。構築するものを以下の図に示します。
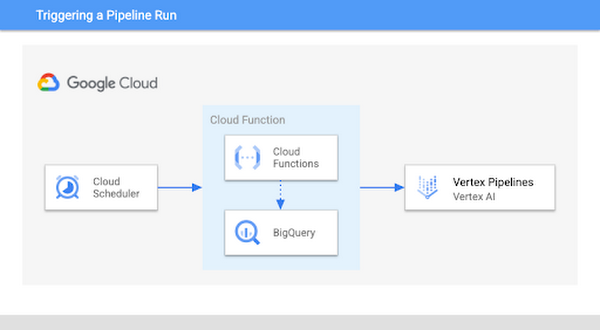
これを実装するには、Cloud Functions の関数を使って新しいデータがあるかどうかチェックし、データがあればパイプラインを実行します。ここでの最初のステップは、モデルの再トレーニングをトリガーする新しいデータ行の数を決定することです。この例では、しきい値を 1,000 としていますが、ユースケースに応じて値をカスタマイズ可能です。Cloud Functions の関数内で、BigQuery テーブルの行数と、モデルのトレーニングに最後に使用したデータの量を比較します。しきい値を超えた場合は、新しいパイプラインの実行を開始してモデルを再トレーニングします。
Cloud Functions にはいくつか種類がありますが、今回は HTTP 関数を使い、Cloud Scheduler でトリガーできるようにします。この関数は、モデルのトレーニング データを保存している BigQuery データセットの名前と、そのデータを含むテーブルの 2 つのパラメータを使用します。この関数はまた、データセットに count というテーブルを作成し、それを使用して、再トレーニング パイプラインを最後に実行したときに使用された行数のスナップショットを保持します。
テーブルの現在の行数が count テーブルの最新の値をあらかじめ設定したしきい値を超えて上回っている場合、パイプラインの実行が開始され、Kubeflow Pipelines SDK メソッド create_run_from_job_spec で count が新しい行数に更新されます。
結果として得られる count テーブルには、この関数がパイプラインの実行を開始するたびに、データテーブルのサイズの実行ログが表示されます。

完全な関数コードはこの gist から確認できます。ここで、check_table_size 関数は Cloud Functions のエントリ ポイントです。なお、パイプラインの実行に失敗した場合を想定して、ユースケースに応じたエラー処理を追加する必要があります。
関数をデプロイする際には、kfp と google-cloud-bigquery の両方のライブラリを含む requirements.txt ファイルを含めます。また、コンパイルしたパイプラインの JSON ファイルも必要になります。関数がデプロイされたら、この関数を定期的に実行する Cloud Scheduler のジョブを作成しましょう。
これは、コンソールの Cloud Scheduler セクションから行えます。最初に [ジョブの作成] をクリックし、ジョブの名前、頻度、タイムゾーンを指定します。頻度は、アプリケーションに新しいデータが追加される頻度に大きく依存します。これを設定しても、必ずしもパイプラインが指定した頻度で実行されるわけではなく、BigQuery の新しいデータがチェックされるのみです [1]。
今回の例では、この関数を毎週月曜日の午前 9 時(米国東部標準時間)に実行することにします。
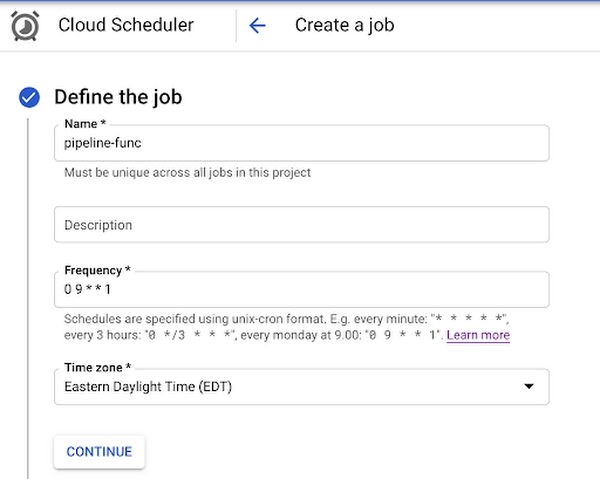
次に、ターゲティング タイプに「HTTP」を設定し、デプロイした Cloud Functions の関数の URL を追加します。本文に、この関数が使用する 2 つのパラメータ(BigQuery データセットとテーブル名)を含む JSON を追加します。
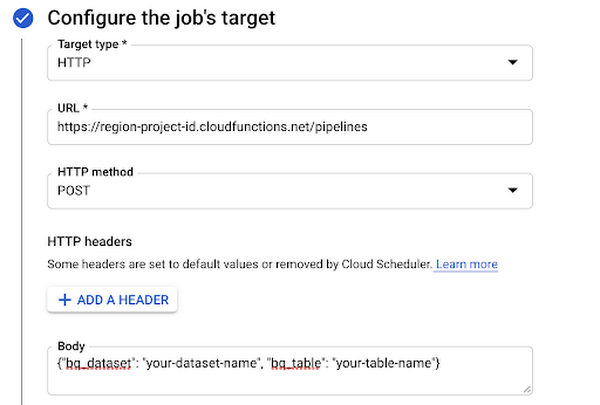
次に、Cloud Functions 起動元のロールを含むサービス アカウントを作成します。Auth header で [OIDC トークンを追加] を選択し、先ほど作成したサービス アカウントを追加します。

これで、十分な新しいデータが利用可能になったときに再トレーニング パイプラインが実行されるので、Scheduler ジョブを作成してしまえばあとはリラックスして待つだけです。進行具合をチェックしたいですか?コンソール内の Cloud Scheduler で、最後にジョブが実行された時刻を確認できます。

次の予定時刻まで待ちたくない場合は、右の [今すぐ実行] ボタンをクリックすることもできます。関数を直接テストするには、コンソールの [Functions] セクションに移動し、関数が要求する 2 つのパラメータを渡してブラウザでテストします。
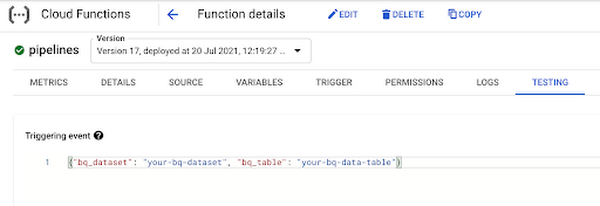
こうして、Vertex AI でパイプラインが実行されているのを確認できます。以下は、完成したパイプライン実行の例です。
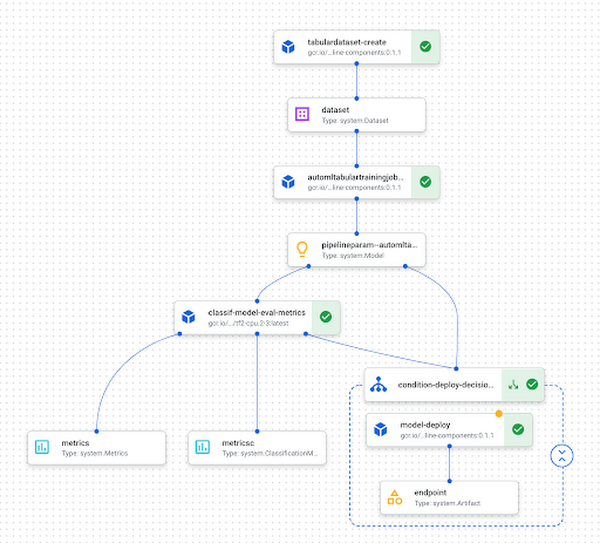
次のステップ
今回の投稿では、BigQuery テーブルに新しいデータが追加された場合にパイプラインをトリガーする方法をご紹介してきました。ここで取り上げたさまざまなプロダクトについての詳細については、以下のリソースをご覧ください。
この投稿に対するコメントや、もっと他の ML に関するコンテンツを見たいというご要望がありましたら、ぜひ Twitter でお知らせください。アカウントは @SRobTweets です。
[1] パイプラインを定期的に実行したい場合は、こちらのドキュメントに記載されている create_schedule_from_job_spec メソッドを使用できます。これにより、Cloud 環境の変化に応じてパイプラインを実行するのではなく、指定した頻度でパイプラインを実行する Cloud Scheduler のジョブが作成されます。
このブログ投稿へのフィードバックを提供した Marc Cohen と Polong Lin に感謝します。
-Google Cloud Platform 担当デベロッパー アドボケイト Sara Robinson




