Vertex Pipelines を使用して AutoML 分類のエンドツーエンド ワークフローを構築
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
この投稿では、Vertex Pipelines を使用してエンドツーエンド ML ワークフローを構築する方法をご説明します。このワークフローでは、AutoML を使用してカスタムモデルをトレーニングして、トレーニング後のモデルについて精度を評価し、十分に正確なモデルは Vertex AI にデプロイして利用できる状態にします。
Vertex AI と Vertex Pipelines
Vertex AI は、新しくリリースされた統合型 ML Ops プラットフォームです。データ サイエンティストと ML エンジニアは、このプラットフォームを使用してテストをスピードアップし、モデルをより短い期間でデプロイして、モデルをより効果的に管理できます。プラットフォームには AutoML と AI Platform が含まれており、ML Ops に特化したいくつかの新プロダクトと併せて統合型 API、クライアント ライブラリ、ユーザー インターフェースに集約されます。
Vertex Pipelines は Vertex AI の一部を構成しており、ML ワークフローのオーケストレーションによる ML システムの自動化、モニタリング、管理が可能です。自動化され、スケーラブル、サーバーレス、かつ優れた費用対効果を持ち、ご利用いただいた分だけお支払いいただきます。Vertex Pipelines は Vertex AI ML Ops のバックボーンであり、ML フレームワークを使用して ML ワークフローの構築および実行を簡略化します。サーバーレスであり GCP と Vertex の AI ツールおよびサービスとシームレスな統合を実現しているため、インフラストラクチャとクラスタのメンテナンスを心配することなくパイプラインの構築と実行に集中できます。
Vertex Pipelines はメタデータを自動で記録してアーティファクト、リネージ、指標、実行を ML ワークフローを通してトラッキングし、ステップ実行のキャッシュ保存をサポートして、Cloud IAM、VPC-SC、CMEK など、エンタープライズ クラスのセキュリティ管理のサポートを提供しています。
Vertex Pipelines では、TFX(TensorFlow Extended)と KFP(Kubeflow Pipelines)という 2 つのオープンソース Python SDK をサポートしています。この投稿でハイライト表示している Vertex Pipelines のサンプルでは KFP SDK を使用しており、Vertex AI サービスへのアクセスを容易にする Google Cloud パイプライン コンポーネントも使用しています。Vertex Pipelines の利用には KFP SDK の v2 が必要です。近日中には KFP v2 の「互換モード」を使用して、OSS KFP のように KFP V2 のサンプルを実行できるようになる予定です。
Vertex Pipelines を使用したエンドツーエンド AutoML ワークフロー
Vertex AI の AutoML 表形式サービスを使用すると、モデル アーキテクチャを構築することなく独自の構造化データを使用してモデルをトレーニング可能です。このサンプルでは、UCI Machine Learning の「乾燥豆」データセットを使用します(出典: KOKLU, M. および OZKAN, I.A.(2020 年)「Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques」、Computers and Electronics in Agriculture、174、105507。DOI)。
豆の特徴に関するいくつかの情報から、その豆の種類を予測する分類作業が課題となります。
Vertex Pipelines を使用すると、このようなモデルの構築、評価、デプロイをサポートするワークフローを非常に簡単に構築できます。以下のように表示されるパイプラインを構築するとします。
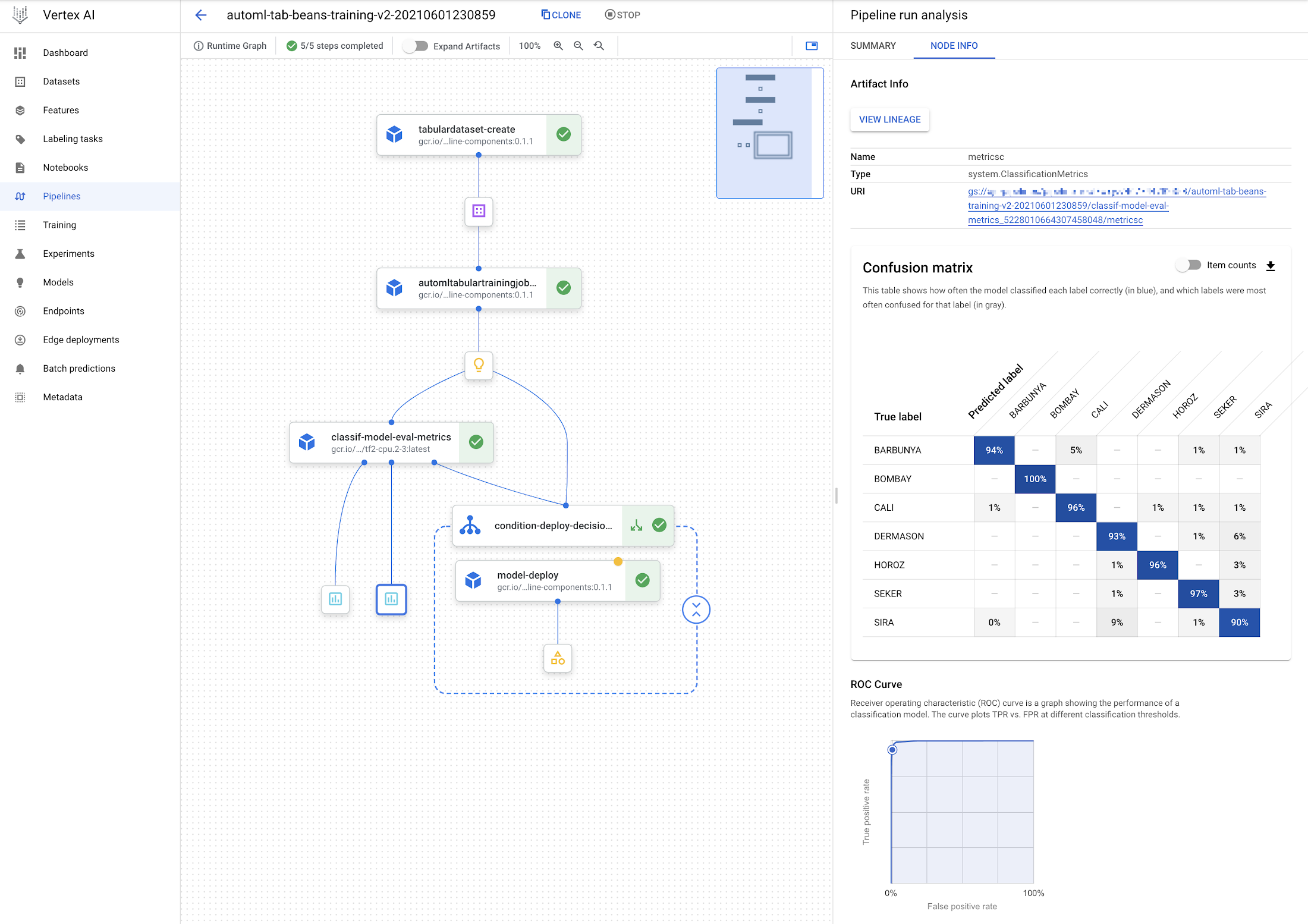
モデルのデプロイ ステップが条件付きで行われることが確認できます。モデルは、評価ステップで十分に正確であると示された場合のみデプロイされます。
このサンプルでは、パイプラインのほぼすべてのコンポーネント(ステップ)が、事前構築された Google Cloud パイプライン コンポーネントです。つまり、これらの構成要素を使用してパイプラインの組み合わせを指定するだけで良いのです。
なお、モデル評価および指標可視化に使用する Python 関数ベースのカスタム コンポーネントを 1 つ追加します。
パイプライン定義は以下のように表示されます(詳細の一部を省略)。
最初に、トレーニング データを保持する BigQuery テーブルからデータセットを作成します。次に、AutoML を使用して表形式の分類モデルをトレーニングします。トレーニング ステップに対するデータセット引数はデータセット ステップの出力から値を取得します(dataset=dataset_create_op.outputs["dataset"])。
モデルのトレーニング後、評価指標を指定の「しきい値」情報と照合して、デプロイするために十分な精度があるかを判断します。
次のセクションでは、このカスタム「評価指標」コンポーネントの定義方法について詳しく見ていきましょう。入力の一つはトレーニング ステップの出力(training_op.outputs["model"])であり、トレーニング後のモデルを示します。
また、KFP 条件では、評価ステップの出力を使用してデプロイの進め方を決定します。
モデルが十分に正確であれば、事前構築されたデプロイ コンポーネントを呼び出します。このステップではエンドポイントを作成し、トレーニング後のモデルをそのエンドポイントにデプロイして利用可能な状態にします。
カスタム コンポーネントを定義する
パイプラインにおける前述したステップの大半は、ML ワークフローの構築を簡単にする構成要素である、事前構築されたコンポーネントから作成されます。今回は、1 つのカスタム コンポーネントを定義してトレーニング後のモデルに関する評価指標を解析し、指標可視化の一部をレンダリングして、指定の「しきい値」情報に基づいて、モデルがデプロイにふさわしいかを判断しています。このカスタム コンポーネントは、@kfp.v2.dsl.component デコレータを持つ Python 関数として定義されています。この関数を評価すると、パイプライン仕様で使用可能なタスク「ファクトリ関数」にコンパイルされます。KFP SDK を使用すると、この方法で新しいパイプライン コンポーネントを非常に簡単に定義できます。
以下はカスタム コンポーネントの定義です(詳細の一部を省略)。@component デコレータは、使用するベースコンテナ イメージ、インストールするパッケージ、およびコンポーネント仕様の書き込み先となる YAML ファイルの 3 つの追加引数を指定します。
コンポーネント関数 classif_model_eval_metrics には、注目すべき入力パラメータがいくつかあります。モデル パラメータは入力 kfp.v2.dsl.Model アーティファクトです。前述のパイプライン仕様にもあるように、この入力はトレーニング ステップの出力によって提供されます。
残りの関数引数は metrics と metricsc の 2 つのコンポーネント出力です(この場合のタイプは、Metrics と ClassificationMetrics)。これらはコンポーネント ステップに対して明示的に入力として渡されることはありませんが、自動的にインスタンス化されてコンポーネントで使用可能となります。たとえば、以下の関数において、metricsc.log_roc_curve() と metricsc.log_confusion_matrix() を呼び出してレンダリングし、Pipelines の UI に可視化しています。これらの出力パラメータは、コンポーネントがコンパイルされたときにコンポーネント出力となり、他のパイプライン ステップで利用されます。
NamedTuple 出力は異なる種類のコンポーネント出力です。ここで、モデルをデプロイするかを示す文字列に戻ります。
この関数を評価する際、前のセクションのように、生成されたファクトリ関数を使用してパイプライン ステップをパイプライン定義の一環として定義できます。
サンプルのノートブックには完全なコンポーネント定義が記述されています。
コンポーネント仕様を共有する
コンポーネントをコンパイルする際、YAML コンポーネント仕様も生成するようにリクエストできます。これは、@component デコレータに渡される追加の output_component_file="tables_eval_component.yaml" 引数を通じて行います。
YAML 形式は、コンポーネント仕様をバージョン管理して他のユーザーと共有可能にします。
また、コンポーネントは、kfp.components.load_component_from_url 関数(および load_component_from_file など他のバリアント)を呼び出して他のパイプラインで使用できます。
Vertex Pipelines でパイプライン ジョブを実行する
パイプラインを定義したら、次はコンパイルするステップに入ります。このステップでは、JSON ジョブ仕様ファイルを生成、送信して、Vertex Pipelines で実行します。パイプライン ジョブを送信する際、パイプライン入力パラメータのデフォルト値に上書きして値を指定できます。
サンプルのノートブックに詳しい指定方法が記載されています。
パイプラインを実行すると Cloud Console に詳細を表示できます。これには、パイプラインの実行と前述したようなリネージグラフ、パイプライン ステップの記録、パイプライン アーティファクトの詳細が含まれます。
また、Cloud Console UI を通じてパイプライン ジョブの仕様を送信して、UI によってパイプラインの実行を簡単に複製できるようにします。JSON パイプライン仕様ファイルは、バージョン管理して他のユーザーと共有する場合もあります。
パイプライン ステップのキャッシュ保存を開発およびデバッグに活用する
Vertex Pipelines ではステップ キャッシュ保存をサポートしており、パイプライン開発で繰り返し処理を行う際に便利です。パイプラインを再実行した際にコンポーネントの入力に変更がなければ、キャッシュ保存された実行結果を再利用できます。このパイプラインを複数回実行する際、この機能が動作しているのに気づくかもしれません。
サンプルを実行する場合、以下の行をコメント解除して、カスタム コンポーネント定義(「Define a metrics eval custom component」(指標評価カスタム コンポーネントを定義する)セクションの classif_model_eval_metrics 関数)を保持するサンプル ノートブック セルに少しの変更を加えてみてください。
その後、コンポーネントを再コンパイルし、DISPLAY_NAME 値を変更せずにパイプラインを再コンパイルしてから再実行します。このように操作する際、Vertex Pipelines がキャッシュ保存された上流ステップに関する実行を(入力が変更されない状態で)活用し、変更されたコンポーネントからの再実行のみを求める点が確認できます。新しい実行に関するパイプライン DAG は以下のように表示され、一部のステップにおける「リサイクル」アイコンはキャッシュ保存された実行が使用されたことを示しています。
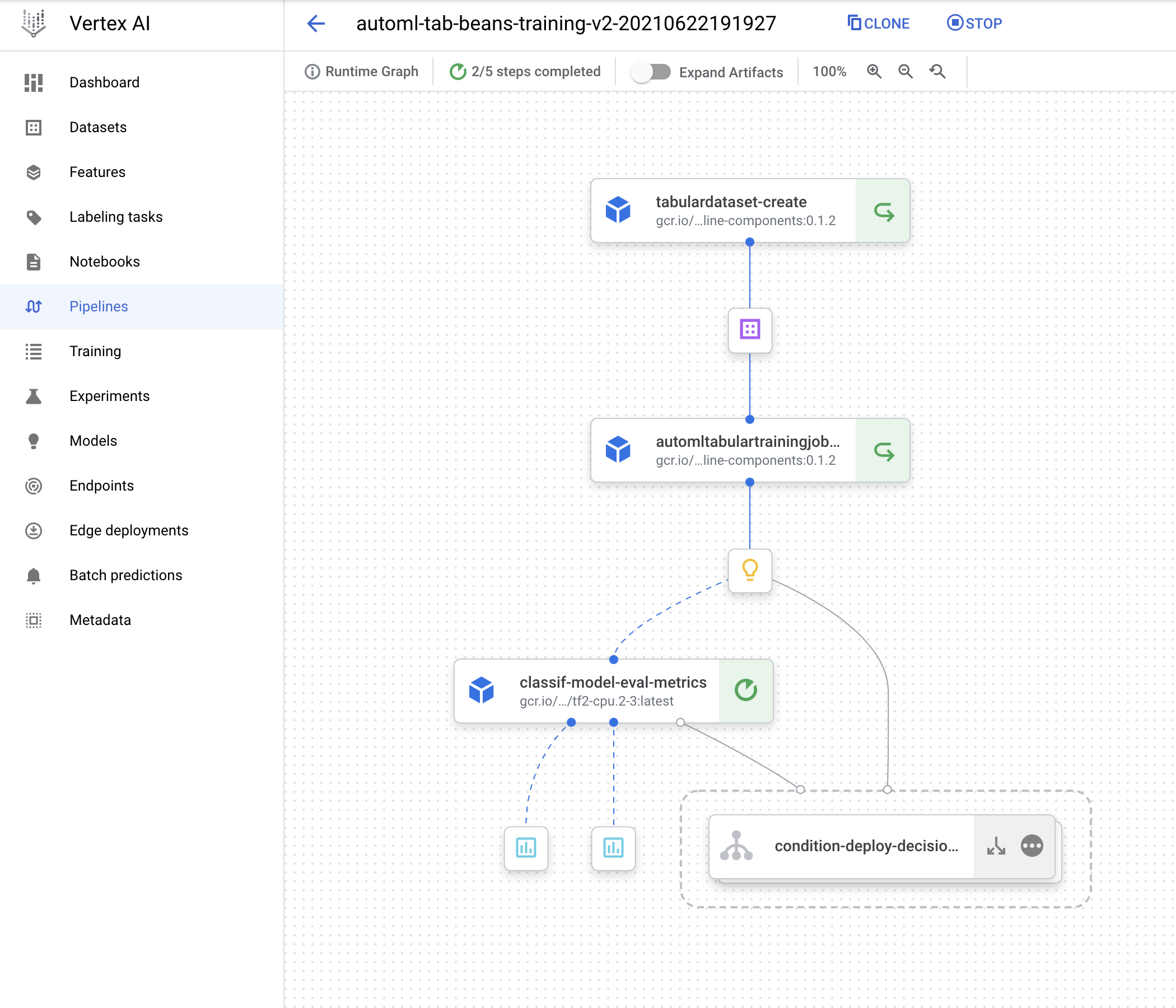
注: ステップ キャッシュ保存はデフォルトで有効ですが、無効化する場合、パイプライン実行を送信する際に enable_caching=False 引数を create_run_from_job_spec 関数に渡します。
リネージのトラッキング
パイプライン グラフのアーティファクトをクリックすると、[リネージを表示] ボタンが表示されます。このボタンを押すと、アーティファクトがステップ実行によってどのように接続されたかをトラッキングできます。これは、パイプライン DAG の逆とも取れ、同じアーティファクトを利用する複数の実行を含めることができます(たとえば、キャッシュ ヒットが発生した際によく起こります)。表示されるトラッキング情報は必ずしも単一のパイプライン実行についての情報ではなく、指定のアーティファクトを使用したあらゆるパイプライン実行についての情報です。
次のステップ
この投稿では、Vertex Pipelines と、Vertex AI へのアクセスを容易にする事前構築された Google Cloud パイプライン コンポーネントをご紹介しました。本投稿の Pipelines サンプルでは、AutoML 表形式サービスを使用して、独自データでモデルを簡単にトレーニングできることを説明しています。データセットの作成、そのデータセットを使用したモデルのトレーニング、モデルに関する評価指標の取得、およびモデルを Vertex AI にデプロイして利用可能にするかどうかの判断を行うパイプラインを説明しました。
次のステップとして、他の Vertex Pipelines サンプル ノートブックと、この投稿のパイプラインに一部関連している Codelab をご参照ください。
また、別の Vertex AI ノートブック サンプルをこちらとこちらでご確認いただけます。
-スタッフ デベロッパー アドボケイト Amy Unruh




