Cloud Bigtable のパフォーマンスと費用の最適化に関するベスト プラクティス ガイド
Google Cloud Japan Team
※この投稿は米国時間 2021 年 3 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud は、さまざまなアプリケーション ワークロードに対応するために、複数のマネージド データベース オプションを提供しています。リレーショナル ユースケース用の Cloud SQL や Cloud Spanner、ドキュメント データ用の Firestore や Firebase、インメモリ データ管理用の Memorystore、NoSQL のワイドカラム型 Key-Value データベースの Cloud Bigtable などです。
Google が設計した Bigtable は、ペタバイトのデータを保存、分析、管理するだけでなく、水平方向にスケールして低レイテンシで毎秒数百万件のリクエストをサポートできます。Cloud Bigtable は、Google が 10 年以上にわたって社内でテストを繰り返して構築した、従来のセルフマネージド データベースのような運用上のオーバーヘッドのないデータベースを Google Cloud のお客様にもご利用いただけるプロダクトです。総所有コストを考えると、多くの場合、フルマネージド クラウド データベースはセルフマネージド データベースよりも運用費用がはるかに低くなります。とはいっても、拡大するアプリケーションをお使いのデータベースがサポートし続ける上で、費用を最適化する機会が訪れることもあります。
このブログでは、Cloud Bigtable のデプロイを最適化して費用を抑えるためのベスト プラクティスを紹介しながら、さまざまな選択肢と考慮すべきトレードオフについてご説明します。
はじめに
このブログは、現在 Cloud Bigtable を使用している、または使用を検討しているデベロッパー、データベース管理者、システム アーキテクトを対象にしています。パフォーマンスと費用の適切なバランスを取るうえで参考になれば幸いです。
このブログシリーズの最初の記事「Cloud Bigtable の費用最適化の基礎」では、Cloud Bigtable の各有料コンポーネントを確認し、さまざまなリソースの変更が費用に与える影響について説明するとともに、この記事で詳しく説明するベスト プラクティスを取り上げています。
注: このブログは、Cloud Bigtable 公開ドキュメントに代わるものではありません。ここで紹介するガイドを読む前に、公開ドキュメントをご一読ください。また、この記事の目的は、特定のワークロードを最適化してビジネス目標の達成を支援する方法を掘り下げることではなく、費用とパフォーマンスのバランスを取るために活用できる一般的なベスト プラクティスについてご説明することです。
現在のデータベースの動作を理解する
データベースを変更する前に、クラスタの現在の動作を観察して文書化します。
Cloud Bigtable Monitoring を使用し、次の主要な指標の現行の値と傾向を文書化して把握します。
1 秒あたりの読み取り / 書き込み数
CPU 使用率
リクエストのレイテンシ
読み取り / 書き込みスループット
ディスク使用量
1 日のさまざまな時点での指標値と、長期的な傾向を確認する必要があります。まず、現在と前の週を調べて、値が 1 日を通して一定であるか、日単位のサイクルがあるか、その他に周期的なパターンがあるかを確認します。月ごとや季節ごとのパターンがある可能性があるため、より長い期間を評価することでも、貴重な分析情報が得られます。
時間をかけて、ワークロード要件、ユースケース、アクセス パターンを確認します。たとえば、読み取りと書き込みのどちらが多いか、スループットまたはレイテンシの影響を受けているか、などです。こうした制約を知っておくと、パフォーマンスと費用のバランスを考える際に役立ちます。
パフォーマンスの最小許容しきい値を定義する
Cloud Bigtable クラスタに変更を加える前に、この最適化の演習で潜在的なトレードオフを確認します。演習の目標は、クラスタ リソースの削減、インスタンス構成の変更、ストレージ要件の軽減などを行って、パフォーマンス要件に応じてワークロードを処理するために必要なリソースを最小レベルにまで下げることにより、運用コストを削減することです。アプリケーションのパフォーマンスに影響を与えずに最適化できるリソースもあるかもしれませんが、費用削減のための変更によってアプリケーションのパフォーマンス指標値に影響が出る可能性のほうが高いと考えられます。アプリケーション パフォーマンスの最小許容しきい値を知ることは、費用とパフォーマンスの最適なバランスが取れた点を知るために重要です。
まず、指標のバジェットを作成します。アプリケーションのパフォーマンス要件を使用してデータベースのパフォーマンス目標を推進するので、アプリケーションのユースケースごとにレイテンシとスループットで許容される最小の指標値を定量化しておきます。この値は、各ユースケースの指標の総バジェットを表します。特定のユースケースでは、Cloud Bigtable とやり取りを行う多数のバックエンド サービスを使用してアプリケーションをサポートする場合があります。それぞれのバックエンド サービスとその動作に関する知識に基づいて、各バックエンド サービスに総バジェットの一部を割り当てます。それぞれのユースケースは複数のバックエンド サービスでサポートされることが推測されますが、Cloud Bigtable が唯一のバックエンド サービスである場合は、指標バジェット全体を Cloud Bigtable に割り当てることができます。
次に、測定した Cloud Bigtable の指標を利用可能な指標バジェットと比較します。観察した指標よりもバジェットが大きい場合は、他の変更を加えることなく、Cloud Bigtable 用にプロビジョニングされたリソースを削減する余地があります。2 つを比較して余裕がなければ、多くの場合、プロビジョニングされたリソースを削減する前に、アーキテクチャまたはアプリケーション ロジックを変更する必要があります。
次の図は、アプリケーションのレイテンシに割り当てられた指標バジェットの例を示しています。これには 2 つのユースケースがあります。それぞれのユースケースではバックエンド サービスを呼び出し、次にバックエンド サービスが別のバックエンド サービスと Cloud Bigtable を使用します。
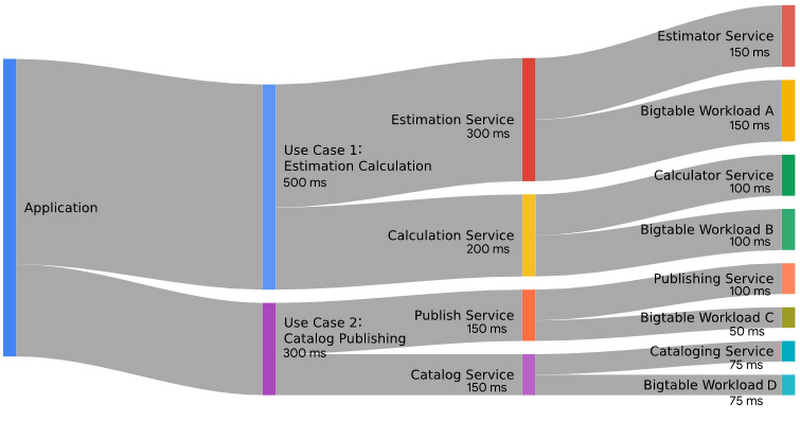
上の図に示した例では、Cloud Bigtable のオペレーションに利用できるバジェットは、サービス呼び出しの総バジェットの一部にすぎないことに注意してください。たとえば、Estimation Service(見積もりサービス)の総バジェットは 300 ミリ秒で、Cloud Bigtable Workload A へのコンポーネント呼び出しには、パフォーマンスの最小許容しきい値である 150 ミリ秒が割り当てられています。このデータベース オペレーションが 150 ミリ秒以内に完了する限り、バジェットは使い果たされません。実際のデータベース指標を確認して Cloud Bigtable Workload A がこれより早く完了していることがわかった場合は、バジェット内で調整する余裕があり、コンピューティング費用を削減できる可能性があります。
パフォーマンスと費用のバランスを取る 4 つの方法
データベースの動作とワークロードのリソース要件について理解を深めたら、費用を最適化できる箇所を検討します。
ここでは、以下の 4 つを実現するために活用できる可能性のある、補足的な方法について説明します。
クラスタを最適なサイズにする
データベースのパフォーマンスを最適化する
データ ストレージの使用状況を評価する
アーキテクチャの代替案を検討する
方法 1: クラスタのサイズを最適なクラスタノード数に設定する
アプリケーションやデータを支えているアーキテクチャへの変更を検討する前に、現在のワークロード用クラスタにプロビジョニングされるノードの数を最適化していることを確認してください。
オーバープロビジョニングについて観察された指標を評価する
単一クラスタ、または単一クラスタ ルーティングを使用するマルチクラスタ インスタンスの場合、推奨される最大平均 CPU 使用率は、クラスタで 70%、最もホットなノードで 90% です。マルチクラスタ ルーティングを使用するマルチクラスタ インスタンスの場合、推奨される最大平均 CPU 使用率は、クラスタで 35%、最もホットなノードで 45% です。
CPU 使用率の適切な推奨最大値を、既存のクラスタで観察される指標の傾向と比較します。平均使用率が推奨値よりも大幅に低いクラスタを見つけた場合、そのクラスタは十分に活用されていない可能性があり、サイズ縮小の候補として検討できます。インスタンス クラスタのノード数は対称でなくてよい点に注意してください。使用率に応じて、インスタンス内の各クラスタのサイズを設定できます。
観測値を推奨値と比較するときは、クラスタ指標を評価するときに観測したさまざまな期間の最大値を考慮に入れてください。たとえば、クラスタの平日ピーク時 CPU 使用率が平均 55% であるものの、週末には最大平均値が 65% に達している場合は、後者の指標値を使用してクラスタの CPU のヘッドルームを決定する必要があります。
ノード数を手動で最適化する
この戦略に従ってクラスタのサイズを適切に設定するには、ノード数を徐々に減らし、クラスタが定常状態に達した期間中の動作の変化を観察します。一般的に、クラスタノード数を 10~20 分ごとに 5~10% 以下で減らしていくことをおすすめします。こうすることで、処理を担うノード数が減るにつれてクラスタがスムーズに分割を再調整できます。
インスタンスへの変更を計画するときは、アプリケーションのトラフィック パターンを考慮に入れてください。たとえば、業務時間外にモニタリングして得られたデータは、最適なノード数を決定するうえで適切なシグナルとは言えません。変更期間中のトラフィックは、アプリケーションの典型的な負荷を表しているものである必要があります。たとえば、業務時間外にサイズを落としてモニタリングして得られたデータは、最適なノード数を決定するうえで適切なシグナルとは言えません。
データベース インスタンスへの変更は、アプリケーションの動作をアクティブにモニタリングすることで補完する必要があることに注意してください。ノード数が減少すると、それに対応して CPU の平均使用率が高まります。目的のレベルに達したら、それ以上ノード数を減らす必要はありません。このプロセス中に CPU 値が目標値よりも高くなった場合は、負荷を処理するためにクラスタ内のノード数を増やす必要があります。
自動スケーリングを使用してノード数を長期にわたって最適なレベルに維持する
指標の傾向を評価するときに、毎日、毎週、季節ごとに定期的なパターンを観察した場合は、指標またはスケジュールに基づいた自動スケーリングが有益な可能性があります。適切に策定された自動スケーリング戦略によって、追加の処理能力が必要になったときにクラスタが拡張され、必要がなくなれば縮小されます。平均すると、アプリケーションのパフォーマンス目標を満たす、よりコスト効率の高いデプロイが可能になります。
現在のところ Cloud Bigtable にはネイティブの自動スケーリング ソリューションは備わっていませんが、Cloud Bigtable Admin API を使用してプログラムでクラスタのサイズを変更できます。これまでも、Google Cloud のお客様がこの API を使用して独自のオートスケーラーが構築された例がありました。こういった Cloud Bigtable 自動スケーリング用のオープンソース ソリューションの一つは GitHub で入手可能で、多くのお客様に繰り返し利用されています。
自動スケーリング ロジックを実装する際に役立つヒントをいくつか紹介します。
測定された戦略に従ってスケールアップ / スケールダウンします。スケールアップするときは費用を考慮します。スケールアップが速すぎると費用の増加につながります。スケールダウンするときは、最適なパフォーマンスを得るために徐々にスケールダウンします。
短期間でクラスタノード数を頻繁に増減すると、費用対効果が下がります。1 時間ごとにその時間内に存在するノードの最大数に対して課金されるため、1 時間以内に細かくアップ スケーリングとダウン スケーリングを行うと費用対効果が低下します。
自動スケーリングは、適切なワークロードに対して使用することではじめて効果が出ます。ノードをクラスタに追加した後、ノードがトラフィックを効率的に処理できるようになるまで、数分程度の時間差があります。つまり、自動スケーリングは短期間のトラフィック バーストに対処するためには理想的なソリューションではないということです。
周期的なパターンに合ったトラフィックの自動スケーリングを選択します。自動スケーリングは、スケジュールされたバッチ ワークロードのような通常の日周トラフィック パターンを持つソリューションや、トラフィック パターンが通常の営業時間に沿ったアプリケーションに適しています。
自動スケーリングは、急増するワークロードにも効果的です。スケジュールされたバッチ ワークロードが見込まれるワークロードの場合、バッチ トラフィックを見越してスケールアップするスケジューリング機能を備えた自動スケーリング ソリューションが適しています。
方法 2: データベースのパフォーマンスを最適化して費用を削減する
アプリケーションのパフォーマンスを改善するか、データスキーマを最適化することで、データベースの CPU 負荷を減らすことができれば、クラスタノードの数を削減できる可能性があります。ここまで説明したように、これによりデータベースの運用コストが削減されます。
ホットスポットを回避するために行キーの設計にベスト プラクティスを適用する
繰り返しになりますが、Cloud Bigtable で最も頻繁に発生するパフォーマンスの問題は行キーの設計に関連しており、そのうち最も一般的な問題はデータアクセスのホットスポットに起因します。ホットスポットは、不均衡な割合のデータベース オペレーションが、隣接する行キー範囲内のデータを操作する場合に発生することに注意してください。多くの場合、連続する数値識別子やタイムスタンプ値など、単調に増加する値で構成される行キーの設計によって発生します。その他の原因には、行の頻繁な更新や、特定のバッチジョブに起因するアクセス パターンなどがあります。
Key Visualizer を使用して Cloud Bigtable クラスタ内のホットスポットとホットキーを特定できます。この高度なモニタリング ツールを利用してテーブルごとにビジュアル レポートを生成し、アクセスされた行キーに基づいて使用状況を示せます。ヒートマップを活用すると、テーブル アクセスを視覚的に確認して、周期的な使用量の急増、特定のホットキー範囲の読み取りまたは書き込みの負荷、連続した読み取りと書き込みの明らかな兆候などの一般的なパターンを迅速に特定できます。
データ アクセス パターンでホットスポットを特定する場合、考慮すべき戦略がいくつかあります。
行キーのスペースが適切に分散されていることを確認する。
同じ行を新しい値で繰り返し更新することは避ける。新しい行を作成する方がはるかに効率的です。
十分に分散されたパターンでデータにアクセスするバッチジョブを設計する。
類似スキーマがあり同時アクセスされるデータセットを統合する
複数のテーブルにデータを手動で分割したり、リレーショナル スキーマを正規化してより効率的なストレージ構造を作成したりすることが有益なデータベース システムに慣れておられるかもしれません。しかし多くの場合、Cloud Bigtable では、すべてのデータを 1 つの大きなテーブルに格納する方が適しています。
データセットに類似したスキーマがある場合、または同時にアクセスされる列または隣接する行のデータで構成されている場合は、データセットをより大きなテーブルに統合するようにテーブルを設計することをおすすめします。
この戦略にはいくつかの理由があります。
Cloud Bigtable には、インスタンスあたり 1,000 個のテーブルという上限がある。
大きなテーブルへの単一のリクエストは、多くの小さなテーブルへの同時リクエストよりも効率的である。
テーブルが大きいほど、Cloud Bigtable が高い性能を発揮する負荷分散機能をより有効に活用できる。
さらに、Key Visualizer は 30 GB 以上のデータを持つテーブルにのみ使用できるため、テーブルを統合することでオブザーバビリティが高まる可能性があります。
一緒にアクセスされることがないデータセットを区分けする
たとえば、2 つのデータセットがあり、一方のデータセットのアクセス頻度がもう一方のデータセットよりも低い場合、この 2 つのデータセットをディスク上で分離するスキーマを設計した方がよい場合があります。これが特に当てはまるのは、アクセス頻度の低いデータセットが他のデータセットよりもはるかに大きい場合、または 2 つのデータセットの行キーがインターリーブされている場合です。
データセット ストレージの区分けに利用できる設計戦略がいくつかあります。
最小単位の行レベルの更新が不要で、データが一緒にアクセスされることがめったにない場合は、次の 2 つのオプションを検討できます。
データを別々のテーブルに保存する。両方のデータセットが同じ行キーのスペースを共有している場合でも、データセットを 2 つの別々のテーブルに分けることができます。
データを 1 つのテーブルに保持しつつ、別々の行キー プレフィックスを使用して、関連データを連続する行に格納し、異なるデータセット行を分離する。
行キーのスペースを共有するデータセット間で最小単位の更新が必要な場合は、そのデータセットを同じテーブルに保持する必要がありますが、各データセットは異なる列ファミリーに配置できます。これは、ワークロードがキースペースを共有する別々のデータセットを同時に取り込み、そのデータセットを個別に読み取る場合に特に効果的です。
クエリで Cloud Bigtable フィルタを使用して 1 つのファミリーの列のみをリクエストした場合、Cloud Bigtable は、その列ファミリーの最後のセルに到達すると、次の行を効率的に検索します。それとは対照的に、個別にリクエストされた列セットが単一の列ファミリー内でインターリーブされた場合、Cloud Bigtable は目的のセルを連続して読み取ることができません。ディスク上のデータのレイアウトによっては、リクエストされたセルを一度に 1 つずつ取得するために、より多くのリソースを消費する一連のフィルタリング オペレーションが発生します。
推奨されるこれらのスキーマ設計は同じ結果につながります。それは、ディスク上で 2 つのデータセットのアドレス指定が改善することで、小さいデータセットへの頻繁なアクセスがはるかに効率的になるということです。さらに、一緒に書き込んだが一緒には読み取らないデータを分離することで、Cloud Bigtable は、SSTable の関連ブロックをより効率的に検索し、関連のないブロックをスキップできます。一般に、相対的な並べ替え順序を制御するためにスキーマ設計を変更すると、パフォーマンスの向上につながる可能性があります。結果として、必要なコンピューティング ノードの数が減り、費用を軽減できます。
シリアル化されたデータ構造に多くの列値を格納する
読み取りによって走査される各セルにはわずかな追加のオーバーヘッドが発生し、返される各セルには、スタックの各レベルでさらにオーバーヘッドが発生します。列ごとに 1 つの値を設定して行全体に構造化データを分散するのではなく、blob として単一の列に格納すると、パフォーマンスが向上する場合があります。
この推奨事項には 2 つの例外があります。
1 つめは、blob が大きく、その一部のみが必要になることが多い場合、データを分割することでデータ スループットが向上する可能性があります。クエリがばらばらのデータ サブセットを対象とすることが多い場合は、それぞれの小さな blob ごとに列を作成します。重複がある場合は、階層型システムを試してください。たとえば、blob A だけが必要な場合、blob A と B または blob B と C をリクエストする場合はあるが、3 つすべてが必要になることはめったにないクエリをサポートするためには列 A、B、C を作成します。
2 つめは、データの一部で Cloud Bigtable フィルタを使用する場合(上記の警告を参照)、そのセクションを独自の列に配置する必要があります。
この方法がデータとユースケースに適合する場合は、プロトコル バッファ(Protobuf)バイナリ形式の使用を検討してください。ストレージのオーバーヘッドが軽減され、パフォーマンスが向上する可能性があります。この場合のトレードオフは、protobuf をデコードしてデータ値を抽出するという追加の処理が、クライアント側で必要になることです(詳細については、このトレードオフの 2 つの面と潜在的な費用の最適化に関する投稿をお読みください)。
行キーの一部としてのタイムスタンプの使用を検討する
データの複数のバージョンを保持している場合は、列の複数のタイムスタンプ付きセルを 1 つの行に保持するのではなく、行キーの最後にタイムスタンプを追加することを検討してください。
これにより、ディスクの並べ替え順序が(行、列、タイムスタンプ)から(行、タイムスタンプ、列)に変更されます。前者の場合、セルのタイムスタンプは行のミューテーションの一部として割り当てられ、セル識別子の最後に追加されます。後者の場合、データのタイムスタンプは明示的に行キーに追加されます。この後者の行キー設計は、行ごとに多くの列を取得したいが、タイムスタンプは単一または限られた範囲にしたいという場合に、はるかに効率的です。
このアプローチは、シリアル化構造に対する以前の推奨事項を補完するものです。列ごとに複数のタイムスタンプ付きセルを収集する場合、シリアル化データ構造の同等の設計では、タイムスタンプを行キーにプロモートする必要があります。すべての列をまとめてシリアル化構造に格納できない場合でも、このパターンに適した方法で列を読み取れば、個々の列に値を格納することでもメリットが得られます。
時系列を維持するために新しいタイムスタンプ付きデータをエンティティに頻繁に追加する場合は、この設計が最も効果的です。ただし、履歴の目的で少数のバージョンのみを保持する場合は、組み込みの Cloud Bigtable タイムスタンプ付きセルが推奨されます。このタイムスタンプは自動的に取得されてデータに適用されるため、パフォーマンスに悪影響を与えることはありません。列が 1 つしかない場合、2 つの並べ替え順序は同等であることに注意してください。
複雑なクエリフィルタ述語ではなくクライアントのフィルタリング ロジックを検討する
Cloud Bigtable API には、連鎖可能で豊富なフィルタリング メカニズムが用意されており、小さなサブセットの結果を求めて大きなデータセットを検索するときに特に有効です。ただし、リクエストされた行キーの範囲に対してあまり選択的なクエリがない場合は、すべてのデータをできるだけ速く返し、アプリケーションでフィルタリングする方が効率が上がる可能性があります。処理コストの増加を正当化するには、選択的な結果セットが得られるクエリのみをサーバー側のフィルタリングで作成する必要があります。
ガベージ コレクション ポリシーを利用して行サイズを自動的に最小化する
Cloud Bigtable は最大 256 MB のデータを含む行をサポートできますが、1 行あたり 100 MB を超えるデータを保存すると、パフォーマンスに影響が出る可能性があります。大きな行はパフォーマンスに悪影響を与えるため、無制限に行が増えるのを防ぐ必要があります。不要なセル、列ファミリー、行を削除することでデータを明示的に削除できますが、このプロセスは手動で実行するか、自動化、管理、モニタリングが必要になります。
または、ガベージ コレクション ポリシーを設定して、次のコンパクション時に削除するようセルに自動的にマークを付けることができます。これには、通常は数日ほど、最長で 1 週間かかることがあります。列ファミリーごとにポリシーを設定して、指定したバージョン数、または一般に有効期間(TTL)として知られるエージベースの有効期限を超えたセルを削除できます。各ポリシータイプを 1 つずつ適用し、ルールの共通(両方)または結合(いずれか)の組み合わせの適用メカニズムを定義することもできます。
クエリ結果からデータが削除される正確なタイミングには、微妙な点がいくつかあり、確認しておく価値があります。たとえば、Cloud Bigtable Data API の DeleteFromRow Mutation によって実行されるものはすぐに省略される一方で、ガベージ コレクションされたセルが除外される特定の瞬間は保証されません。
データ保持の要件を評価し、さまざまなデータセットの増加パターンを理解したら、行サイズが推奨される最大サイズを超えてパフォーマンスに悪影響を及ぼさないようにするガベージ コレクション戦略を開発できます。
方法 3: コスト削減の機会についてデータ ストレージを評価する
Cloud Bigtable ノードが 1 か月の費用の大部分を占める可能性は高くなりますが、費用軽減の見通しについてストレージも評価する必要があります。個別の項目として課金対象となるのは、Cloud Bigtable のディスク上での内部表現に使用されるストレージと、テーブルのアクティブ バックアップを保持するために必要な圧縮ストレージです。
データ ストレージの費用管理には、アクティブな方法とパッシブな方法があります。
ガベージ コレクション ポリシーを利用してデータを自動的に削除する
先に説明したように、ガベージ コレクション ポリシーを使用すると、データセットのプルーニングを簡素化できます。適切なパフォーマンスを確保するために行サイズの制御を選択するのと同じ方法で、データを削除するポリシーを設定して、データ ストレージの費用を制御することもできます。
ガベージ コレクションを使用すると、不要になったデータや使わなくなったデータを削除することで、費用を節約できます。これは特に、SSD ストレージ タイプを使用している場合に有効です。
この目的と前述の目的の両方を実現するためにガベージ コレクション ポリシーを適用する場合、複数の基準に基づくポリシー(結合ポリシー、または共通と結合の両方を備えたネスト化ポリシーのいずれか)を使用できます。
極端な例として、約 10 MB の値を格納する列があると想像してください。この場合、行サイズを 100 MB 未満に保つには、保持するバージョン数を 10 個以下にしなければなりません。短期的には 10 個のバージョンを保持することにはビジネス上の価値がありますが、長期的に見ると、データ ストレージの量を制御するためには数個のバージョンを保持すれば十分です。
この場合、ポリシーを (maxage=7d and maxversions=2) or maxversions=10 と設定できます。
このガベージ コレクション ポリシーは、次のいずれかの条件を満たす列ファミリーのセルを削除します。
直近 10 個のセルより古い
7 日以上経過していて、最新の 2 つのセルよりも古い
ガベージ コレクション ポリシーに関する最後の注意: コンパクションが発生し(ガベージ コレクションが発生したとき)、データが物理的に削除されるまで、期限切れまたは古くなったデータの保存にも引き続き課金されることを考慮に入れてください。このプロセスは通常、数日以内に発生しますが、最長で 1 週間かかることがあります。
コストを意識したバックアップ プランを選択する
データベースのバックアップは、バックアップと復元戦略の重要な要素です。Cloud Bigtable のマネージド テーブル バックアップを使用すると、オペレーターのエラーやアプリケーション データの破損などのシナリオからデータを保護できます。Cloud Bigtable のバックアップはすべて Cloud Bigtable サービスによって処理され、保持期間中のストレージに対してのみ課金されます。バックアップを作成または復元するための処理費用がかからないため、個別にプロビジョニングされたサービスを使用してデータをエクスポートとインポートする外部バックアップよりも費用を抑えられます。
テーブルのバックアップは、バックアップが開始されたクラスタに保存され、バックアップの作成時にテーブルにあったすべてのデータが含まれますが、いくつかの注意点があります。バックアップが作成されると、ユーザー定義の有効期限が定義されます。この日付はバックアップが作成されてから最大 30 日まで設定できますが、必要以上に長く保持しないように、保持期間は慎重に検討してください。バックアップの冗長性とテーブルのバックアップ頻度の要件に応じて、保持期間を設定できます。後者には、許容可能なデータの損失量、つまりバックアップ戦略の目標復旧時点(RPO)を反映する必要があります。
たとえば、RPO が 1 時間のテーブルがある場合、1 時間ごとに新しいテーブル バックアップを作成するようにスケジュールを構成できます。バックアップの有効期限は最大 30 日に設定できますが、この設定ではテーブルのサイズによってはかなりの費用が発生し、ビジネス要件によっては見合った価値が得られない場合があります。バックアップ保持ポリシーに基づいて、かなり短いバックアップ有効期限(たとえば、4 時間)を設定することもできます。この例では、1 時間未満の必要な RPO 内でテーブルを復旧できますが、その期間のどの時点をとってもテーブル バックアップは 4~5 個しか保持されません。これに対し、バックアップの有効期限を 30 日に設定した場合のバックアップ数は 720 個です。
HDD ストレージでプロビジョニングする
Cloud Bigtable インスタンスを作成するときは、SSD または HDD ストレージのいずれかを選択する必要があります。SSD ノードは非常に高速でパフォーマンスの予測可能性にも優れていますが、コストが高く、ノードあたりのストレージ容量は少なくなります。一般的に、判断に迷った場合は SSD ストレージを選択することをおすすめします。ただし、HDD ストレージが設定されたインスタンスは、適切なユースケースのワークロードの場合、費用を大幅に削減できます。
次のような特徴のあるユースケースは、HDD インスタンス ストレージが適しています。
特に予測される読み取りスループットに比べて、ストレージ要件が大きい(10 TB を超える)。たとえば、アーカイブ データなど、読み取り頻度の低いデータクラスの時系列データベースを使うユースケースです。
データ アクセス トラフィックが主に書き込みで、大部分がスキャンの読み取りである。HDD ストレージでは、順次読み取りと書き込みには妥当なパフォーマンスが得られますが、SSD ストレージによる 1 秒あたりのランダム読み取り行数のごく一部しかサポートされていません。
レイテンシの影響を受けにくい。たとえば、内部分析ワークフローにつながるバッチ ワークロードがあるユースケースです。
そうは言っても、この選択は慎重に行う必要があります。ストレージ メディアの特性が異なるためにクラスタがディスク I/O の制約を受ける場合は、HDD インスタンスが SSD インスタンスよりも高価になることがあります。こうした状況では、SSD インスタンスは、HDD インスタンスよりも少ないノードで同じ量のトラフィックを処理できます。さらに、インスタンス ストア タイプは作成後に変更できません。SSD と HDD のストレージ タイプを切り替えるには、新しいインスタンスを作成してデータを移行する必要があります。SSD と HDD のストレージ タイプにおけるトレードオフの詳細については、Cloud Bigtable のドキュメントをご確認ください。
方法 4: データベースの負荷を下げるためにアーキテクチャの変更を検討する
ワークロードによっては、アーキテクチャを変更してデータベースの負荷を軽減できる場合があります。これにより、クラスタ内のノード数を減らすことができます。ノードが少ないほど、クラスタの費用が軽減されます。
容量キャッシュを追加する
Cloud Bigtable が選択される理由として、読み取りリクエストを処理する際のレイテンシが低いことが挙げられます。こうしたタイプのワークロードに適している理由の一つは、Cloud Bigtable が、基盤となる分散ファイル システムである Colossus から読み取られた SSTable ブロックをキャッシュするブロック キャッシュを備えていることです。それでも、小さな値が含まれる列の読み取り頻度が高く、大きな値が含まれる列の読み取り頻度が低い行など、特定のデータ アクセス パターンでは、アーキテクチャに容量キャッシュを導入することで、費用とパフォーマンスをさらに最適化できます。
このようなアーキテクチャでは、読み取りオペレーションが Cloud Bigtable に送信される前に、アプリケーションによってクエリされるキャッシング インフラストラクチャをプロビジョニングします。目的の結果がキャッシュ レイヤ(キャッシュ ヒットとも呼ばれる)に存在する場合、Cloud Bigtable を検討する必要はありません。このキャッシュ レイヤの使用は、キャッシュアサイド パターンとして知られています。
Cloud Memorystore は、マネージド キャッシュ サービスとして Redis と Memcached の両方を提供します。通常、Cloud Bigtable のワークロードには分散アーキテクチャに優れた Memcached が選択されます。アプリケーション ロジックを変更して Cloud Bigtable の前に Memcached キャッシュ レイヤを追加する方法の例については、こちらのチュートリアルをご覧ください。高いキャッシュ ヒット率を維持できる場合、このタイプのアーキテクチャの 2 つの最適化オプションに注目してください。
まず、Cloud Bigtable クラスタノード数を削減できる可能性があります。キャッシュが読み取りトラフィックのかなりの部分を処理できる場合は、Cloud Bigtable クラスタをより低い読み取り容量でプロビジョニングできます。これが特に当てはまるのは、リクエスト プロファイルがべき乗則の確率分布に従う場合、つまり、少数の行キーがリクエストのかなりの割合を表す場合です。
次に、前述したように、データセットが非常に大きい場合は、SSD ではなく HDD を使用して Cloud Bigtable インスタンスをプロビジョニングすることを検討できます。データ量が大きい場合、Cloud Bigtable の HDD ストレージ タイプは SSD ストレージ タイプよりも大幅に費用を抑えられる可能性があります。SSD を使用する Cloud Bigtable クラスタは、HDD を使用する同等のクラスタよりもはるかに大きいポイント読み取り容量を備えていますが、書き込み容量は同じです。容量キャッシュのために必要な読み取り容量が小さい場合は、同じ書き込みスループットを維持しながら HDD インスタンスを利用できます。
クエリ分布の変更によって高いキャッシュ ヒット率を維持できない、またはキャッシュ レイヤにダウンタイムがある場合、この最適化にはリスクが伴います。その場合は、増加した量のトラフィックが Cloud Bigtable に渡されます。Cloud Bigtable に必要な読み取り容量がないと、リクエストのレイテンシが増加してリクエストのスループットが制限されるなど、アプリケーションのパフォーマンスが低下する可能性があります。このような状況では、自動スケーリング ソリューションを導入することである程度の安全策を講じることができますが、障害状態のリスク評価を実施するまでは、このアーキテクチャを選択すべきではありません。
次のステップ
Cloud Bigtable は、低レイテンシのオペレーションをサポートし、ペタバイトのデータ ストレージとコンピューティング リソースに線形のスケーラビリティを提供する、高度なフルマネージド クラウド データベースです。このシリーズの最初の投稿で説明したように、Cloud Bigtable インスタンスの運用コストは、予約済みのリソースと消費されたリソースに関連しています。オーバープロビジョニングされた Cloud Bigtable インスタンスには、ワークロードの特定の要件に合わせて調整されたインスタンスよりも高いコストが発生します。しかし、データベースを観察して適切な指標目標値を決定するには時間がかかります。プロビジョニングされたコンピューティング リソースを最大限に活用するように Cloud Bigtable インスタンスを調整すれば、費用を最適化できます。
このシリーズの次の投稿では、さまざまな最適化が費用削減と直接的な相関関係にある理由を明らかにするために、Cloud Bigtable の特定の内部的な側面について詳しく説明します。
その前に、以下についてもぜひご確認ください。
Cloud Bigtable のパフォーマンスの詳細を確認する。
Cloud Bigtable ガベージ コレクションの詳細を理解する。
Cloud Bigtable ホワイトペーパーの公開以降、設計に多くの改善と最適化が施されていますが、現在でもホワイトペーパーは有用なリソースです。
-ソリューション アーキテクト Drew Stevens
-カスタマー エンジニア Matt Geerling