Artifact Registry ne surveille pas les registres tiers pour les mises à jour des images que vous copiez dans Artifact Registry. Si vous souhaitez intégrer une version plus récente d'une image dans votre pipeline, vous devez la transférer vers Artifact Registry.
Présentation de la migration
La migration de vos images de conteneurs comprend les étapes suivantes :
- Configurer les prérequis.
- Identifier les images à migrer.
- Rechercher les références à des registres tiers dans vos fichiers Dockerfile et vos fichiers manifestes de déploiement.
- Déterminer la fréquence d'extraction des images depuis des registres tiers à l'aide de Cloud Logging et BigQuery.
- Copier les images identifiées dans Artifact Registry.
- Vérifiez que les autorisations d'accès au registre sont correctement configurées, en particulier si Artifact Registry et votre environnement de déploiement Google Cloudse trouvent dans des projets différents.
- Mettre à jour les fichiers manifestes pour vos déploiements.
- Redéployer vos charges de travail.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
-
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
Create or select a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Artifact Registry API:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable artifactregistry.googleapis.com
- Si vous ne disposez pas de dépôt Artifact Registry, créez-en un et configurez l'authentification pour les clients tiers qui ont besoin d'accéder au dépôt.
- Vérifiez vos autorisations. Vous devez disposer du rôle IAM Propriétaire ou Éditeur dans les projets dans lesquels vous migrez des images vers Artifact Registry.
- Exportez les variables d'environnement suivantes :
export PROJECT=$(gcloud config get-value project)
- Vérifiez que Go version 1.13 ou ultérieure est installé.
go version - Dans le répertoire contenant vos fichiers manifestes GKE ou Cloud Run, exécutez la commande suivante :
grep -inr -H --include \*.yaml "image:" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
./code/deploy/k8s/ubuntu16-04.yaml:63: image: busybox:1.31.1-uclibc ./code/deploy/k8s/master.yaml:26: image: kubernetes/redis:v1 - Pour répertorier les images exécutées sur un cluster, exécutez la commande suivante :
kubectl get all --all-namespaces -o yaml | grep image: | grep -i -v -E 'docker.pkg.dev|gcr.io'
- image: nginx image: nginx:latest - image: nginx - image: nginx -
Dans la console Google Cloud , accédez à la page Explorateur de journaux.
Accéder à l'explorateur de journaux
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Logging.
Sélectionnez un projet Google Cloud .
Dans l'onglet Générateur de requête, saisissez la requête suivante :
resource.type="k8s_pod" jsonPayload.reason="Pulling"Modifiez le filtre d'historique en passant de Dernière heure à 7 derniers jours.
Cliquez sur Exécuter la requête.
Après avoir vérifié que les résultats s'affichent correctement, cliquez sur Actions > Créer un récepteur.
Dans la boîte de dialogue Détails du récepteur, procédez comme suit :
- Dans le champ Nom du récepteur, saisissez
image_pull_logs. - Dans Description du récepteur, saisissez une description du récepteur.
- Dans le champ Nom du récepteur, saisissez
Cliquez sur Suivant.
Dans la boîte de dialogue Destination du récepteur, sélectionnez les valeurs suivantes :
- Dans le champ Sélectionner le service de récepteur, sélectionnez Ensemble de données BigQuery.
- Dans le champ Sélectionner un ensemble de données BigQuery, sélectionnez Créer un ensemble de données BigQuery et saisissez les informations requises dans la boîte de dialogue qui s'affiche. Pour savoir comment créer un ensemble de données BigQuery, consultez Créer des ensembles de données.
- Cliquez sur Créer un ensemble de données.
Cliquez sur Suivant.
Dans la section Sélectionner les journaux à inclure dans le récepteur, la requête correspond à celle que vous avez exécutée dans l'onglet Générateur de requêtes.
Cliquez sur Suivant.
Facultatif : Choisissez les journaux à exclure du récepteur. Pour en savoir plus sur la façon d'interroger et de filtrer les données Cloud Logging, consultez la page Langage de requête Logging.
Cliquez sur Créer un récepteur.
Votre récepteur de journaux est créé.
Exécutez les commandes suivantes dans Cloud Shell :
PROJECTS="PROJECT-LIST" DESTINATION_PROJECT="DATASET-PROJECT" DATASET="DATASET-NAME" for source_project in $PROJECTS do gcloud logging --project="${source_project}" sinks create image_pull_logs bigquery.googleapis.com/projects/${DESTINATION_PROJECT}/datasets/${DATASET} --log-filter='resource.type="k8s_pod" jsonPayload.reason="Pulling"' doneOù :
- PROJECT-LIST est une liste d'ID de projet Google Cloud , séparés par des espaces. Par exemple :
project1 project2 project3. - DATASET-PROJECT est le projet dans lequel vous souhaitez stocker l'ensemble de données.
- DATASET-NAME est le nom de l'ensemble de données, par exemple
image_pull_logs.
- PROJECT-LIST est une liste d'ID de projet Google Cloud , séparés par des espaces. Par exemple :
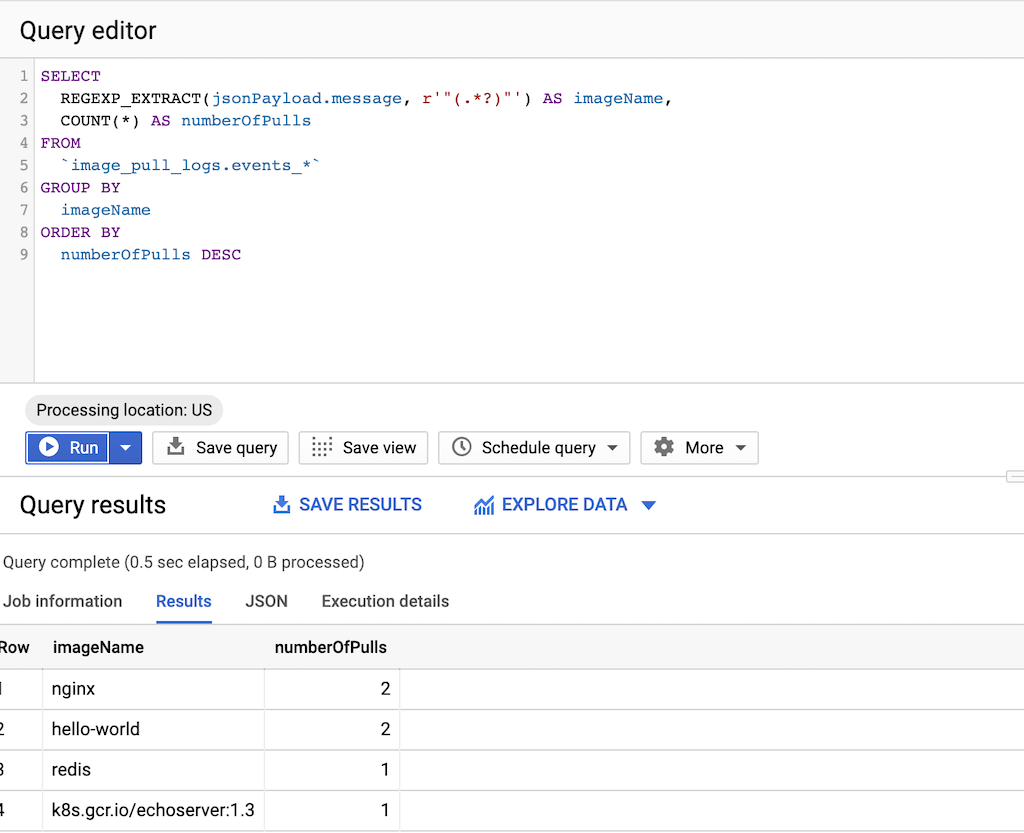
Exécutez la requête suivante :
SELECT REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName, COUNT(*) AS numberOfPulls FROM `DATASET-PROJECT.DATASET-NAME.events_*` GROUP BY imageName ORDER BY numberOfPulls DESCOù :
- DATASET-PROJECT est le projet qui contient votre ensemble de données.
- DATASET-NAME est le nom de l'ensemble de données.
Créez un fichier texte
images.txtavec le nom des images que vous avez identifiées. Exemple :ubuntu:18.04 debian:buster hello-world:latest redis:buster jupyter/tensorflow-notebookTéléchargez gcrane.
GO111MODULE=on go get github.com/google/go-containerregistry/cmd/gcraneCréez un script nommé
copy_images.shpour copier votre liste de fichiers.#!/bin/bash images=$(cat images.txt) if [ -z "${AR_PROJECT}" ] then echo ERROR: AR_PROJECT must be set before running this exit 1 fi for img in ${images} do gcrane cp ${img} LOCATION-docker.pkg.dev/${AR_PROJECT}/${img} doneRemplacez
LOCATIONpar l'emplacement régional ou multirégional du dépôt.Rendez le script exécutable :
chmod +x copy_images.shExécutez le script pour copier les fichiers :
AR_PROJECT=${PROJECT} ./copy_images.sh
Coûts
Ce guide utilise les composants facturables suivants de Google Cloud :
Identifier les images à migrer
Recherchez dans les fichiers que vous utilisez pour créer et déployer vos images de conteneurs des références à des registres tiers, puis vérifiez à quelle fréquence vous extrayez les images.
Identifier les références dans les fichiers Dockerfile
Effectuez cette étape dans un emplacement où sont stockés vos fichiers Dockerfile. Il peut s'agir de l'emplacement où votre code est extrait localement, ou dans Cloud Shell si les fichiers sont disponibles sur une VM.Dans le répertoire contenant vos fichiers Dockerfile, exécutez la commande suivante :
grep -inr -H --include Dockerfile\* "FROM" . | grep -i -v -E 'docker.pkg.dev|gcr.io'
Le résultat ressemble à l'exemple suivant :
./code/build/baseimage/Dockerfile:1:FROM debian:stretch
./code/build/ubuntubase/Dockerfile:1:FROM ubuntu:latest
./code/build/pythonbase/Dockerfile:1:FROM python:3.5-buster
Cette commande recherche tous les fichiers Dockerfile de votre répertoire et identifie la ligne "FROM". Ajustez la commande selon vos besoins pour qu'elle corresponde à la manière dont vous stockez vos fichiers Dockerfile.
Identifier les références dans les fichiers manifestes
Effectuez ces étapes dans un emplacement où sont stockés vos fichiers manifestes GKE ou Cloud Run. Il peut s'agir de l'emplacement où votre code est extrait localement, ou dans Cloud Shell si les fichiers sont disponibles sur une VM.Exécutez les commandes précédentes pour tous les clusters GKE de tous les projetsGoogle Cloud pour une couverture totale.
Identifier la fréquence d'extraction depuis un registre tiers
Dans les projets qui extraient à partir de registres tiers, utilisez les informations sur la fréquence d'extraction d'image pour déterminer si votre utilisation est proche ou supérieure aux limites de débit appliquées par le registre tiers.
Collecter les données des journaux
Créez un récepteur de journaux pour exporter des données vers BigQuery. Un récepteur de journaux inclut une destination, ainsi qu'un filtre qui sélectionne les entrées de journal à exporter. Vous pouvez créer un récepteur en interrogeant des projets individuels, ou utiliser un script pour collecter des données entre différents projets.
Pour créer un récepteur pour un seul projet, procédez comme suit :
Pour créer un récepteur pour plusieurs projets, procédez comme suit :
Après la création d'un récepteur, le transfert des données dans les tables BigQuery prend du temps, en fonction de la fréquence à laquelle les images sont extraites.
Requête pour la fréquence d'extraction
Une fois que vous disposez d'un exemple représentatif d'extractions d'images effectuées par vos builds, exécutez une requête pour la fréquence d'extraction.
Copier des images dans Artifact Registry
Une fois que vous avez identifié des images provenant de registres tiers, vous pouvez les copier dans Artifact Registry. L'outil gcrane vous aide avec le processus de copie.
Vérifier les autorisations
Assurez-vous que les autorisations sont correctement configurées avant de mettre à jour et de redéployer vos charges de travail.
Pour en savoir plus, consultez la documentation sur le contrôle des accès.
Mettre à jour les fichiers manifestes pour référencer Artifact Registry
Mettez à jour vos fichiers Dockerfile et vos fichiers manifestes pour faire référence à Artifact Registry plutôt qu'au registre tiers.
L'exemple suivant illustre un fichier manifeste référençant un registre tiers :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Cette version mise à jour du fichier manifeste pointe vers une image sur us-docker.pkg.dev.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: us-docker.pkg.dev/<AR_PROJECT>/nginx:1.14.2
ports:
- containerPort: 80
Pour un grand nombre de fichiers manifestes, utilisez sed ou un autre outil capable de gérer des mises à jour dans de nombreux fichiers texte.
Redéployer des charges de travail
Redéployez les charges de travail avec vos fichiers manifestes mis à jour.
Effectuez le suivi des nouvelles extractions d'images en exécutant la requête suivante dans la console BigQuery :
SELECT`
FORMAT_TIMESTAMP("%D %R", timestamp) as timeOfImagePull,
REGEXP_EXTRACT(jsonPayload.message, r'"(.*?)"') AS imageName,
COUNT(*) AS numberOfPulls
FROM
`image_pull_logs.events_*`
GROUP BY
timeOfImagePull,
imageName
ORDER BY
timeOfImagePull DESC,
numberOfPulls DESC
Toutes les nouvelles extractions d'images doivent provenir de Artifact Registry et contenir la chaîne docker.pkg.dev.