Carbon Footprint
Cloud-CO₂-Ausstoß messen, melden und reduzieren.
Sowohl standortbasierte als auch marktbasierte CO2-Emissionsdaten in Berichte und Offenlegungen einbeziehen
CO2-Informationen durch Dashboards und Diagramme visualisieren
Emissionen von Cloud-Anwendungen und -Infrastruktur reduzieren
Vorteile
Ihre CO₂-Bilanz genau messen
Ihre CO₂-Bilanz genau messen
Sie können sich die standort- und marktbasierten Emissionen anzeigen lassen, die aus Ihrer Google Cloud-Nutzung entstehen, und so die Emissionen Ihrer Cloud-Anwendungen transparent darstellen.
Detailliertes Emissionsprofil von Cloud-Projekten verfolgen
Detailliertes Emissionsprofil von Cloud-Projekten verfolgen
Überwachen Sie Ihre Cloud-Emissionen im Laufe der Zeit nach Projekt, Produkt und Region. So erhalten IT-Teams und Entwickler Messwerte, mit denen sie ihre CO2-Bilanz verbessern können.
Detaillierte Methodik für Prüfer freigeben
Unsere detaillierte Berechnungsmethode wird veröffentlicht, damit Prüfer und Berichtsteams prüfen können, ob ihre Emissionsdaten das GHG-Protokoll erfüllen.
Wichtige Features
Wichtige Features
[NEU] Doppelte Meldung von standort- und marktbasierten Emissionen
Im Dashboard in der Konsole und in BigQuery Export stellen wir zusätzlich zu Emissionen in Bereich 1 und Bereich 3 sowohl marktbasierte als auch standortbasierte Emissionsdaten in Bereich 2 bereit.
Im Vergleich zu marktbasierten Daten für strombezogene Emissionen (Scope-2-Emissionen) bietet die doppelte Berichterstellung mehr Transparenz und umfassende Informationen für unterschiedliche Anwendungsfälle.
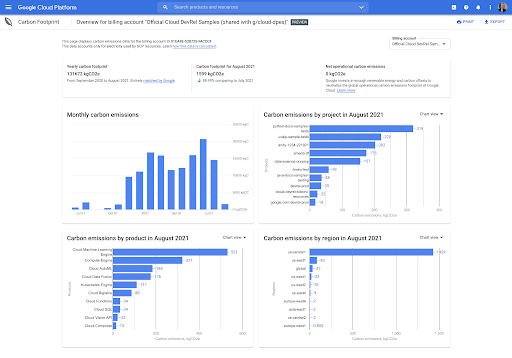
Dashboard in der Konsole
Die Datenübersicht im Dashboard bietet Ihnen einen allgemeinen Überblick über den standort- und den marktbasierten CO2-Ausstoß aus allen drei Bereichen, die mit der Nutzung der abgedeckten Google Cloud-Dienste für Ihr Konto verbunden sind.
Automatisierte und detaillierte Exporte nach BigQuery
Sie können Ihre CO₂-Bilanzdaten nach BigQuery exportieren, um Datenanalysen durchzuführen, benutzerdefinierte Dashboards und Berichte zu erstellen oder die Daten in die Emissionsrechnungstools Ihrer Organisation aufzunehmen.
Sie können Ihre CO2-Emissionen für das ausgewählte Rechnungskonto über alle verfügbaren Monate hinweg nach Google Cloud-Dienst, Projekt, Region und Monat analysieren.
Schätzungen zur standortbasierten Emissionsreduzierung
Carbon Footprint-Daten sind in den unbeaufsichtigten Projekt-Recommender eingebunden, der Ihnen eine Schätzung zu den standortbezogenen Emissionsreduzierungen liefert, die Sie durch die Beseitigung nicht genutzter Projekte erreichen könnten.
Prüfung von CO₂-Bilanz-Methoden durch Dritte
Wir haben eine Auszug von externen Experten für Nachhaltigkeitsberatung, die zu dem Schluss kommt, dass die Methodik von Carbon Footprint eine angemessene und geeignete Methode zum Berechnen und Zuweisen von Emissionen aus Google Cloud-Produkten gemäß dem GHG-Protokoll ist.
Kunden
Wir helfen Kunden, ihre Umweltauswirkungen zu reduzieren
Google Cloud unterstützt unsere Kunden dabei, ihre eigenen Nachhaltigkeitsziele zu erreichen.



Das ist neu
Aktuelle Nachrichten und Veranstaltungen zur CO2-Berichterstattung
Melden Sie sich für die Google Cloud-Newsletter an – so erhalten Sie regelmäßig Produktupdates, Veranstaltungsinformationen, Sonderangebote und mehr.



Dokumentation
Dokumentation
Preise
Preise
Die CO₂-Bilanz wird allen Google Cloud-Kunden kostenlos zur Verfügung gestellt.
Wenn Sie Ihre Daten zu CO2-Emissionen nach BigQuery exportieren, fallen nur geringe Gebühren an. Informationen zu den möglichen Kosten finden Sie unter Speicher- und Abfragekosten schätzen.
Partner
Daten-, Berichts- und Beratungspartner
Sie können Ihre Google Cloud-Emissionsdaten in beliebte Tools zur CO2-Berichterstellung einbinden. Wir arbeiten außerdem mit Organisationen zusammen, die auf Emissionen und Umweltdaten spezialisiert sind.
Emissionsberichte oder Beratung
Diese Partner können Ihnen dabei helfen, unternehmensweite Emissionen zu melden und CO2-Offenlegungen vorzubereiten.




Daten und Visualisierung
Diese Partner stellen Daten und Tools zur Verfügung, mit denen Sie Ihre Auswirkungen auf die Umwelt, Ihre Risiken und Ihre Chancen besser verstehen können.



Gleich loslegen
Profitieren Sie von einem Guthaben über 300 $, um Google Cloud und mehr als 20 „Immer kostenlos“-Produkte kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen











