In diesem Dokument werden mehrere Architekturen beschrieben, die Hochverfügbarkeit (High Availability, HA) für PostgreSQL-Bereitstellungen in Google Cloudbieten. HA ist das Maß für die Ausfallsicherheit eines Systems im Fall eines Infrastrukturausfalls. In diesem Dokument bezieht sich HA auf die Verfügbarkeit von PostgreSQL-Clustern innerhalb einer einzelnen Cloud-Region oder innerhalb mehrerer Regionen, abhängig von der HA-Architektur.
Dieses Dokument richtet sich an Datenbankadministratoren, Cloud-Architekten und DevOps-Entwickler, die erfahren möchten, wie sie die Zuverlässigkeit der PostgreSQL-Datenstufe durch Erhöhung der Betriebszeit des Gesamtsystems steigern können. In diesem Dokument werden Konzepte erläutert, die für die Ausführung von PostgreSQL in Compute Engine relevant sind. In diesem Dokument wird die Verwendung verwalteter Datenbanken wie Cloud SQL for PostgreSQL und AlloyDB for PostgreSQL nicht erläutert.
Wenn ein System oder eine Anwendung einen persistenten Status zur Verarbeitung von Anfragen oder Transaktionen benötigt, muss die Datenpersistenzebene (die Datenstufe) verfügbar sein, damit Anfragen für Datenabfragen oder Mutationen erfolgreich verarbeitet werden können. Ausfallzeiten auf der Datenstufe hindern das System oder die Anwendung daran, die erforderlichen Aufgaben auszuführen.
Abhängig von den Service Level Objectives (SLOs) Ihres Systems benötigen Sie möglicherweise eine Architektur, die eine höhere Verfügbarkeit erlaubt. Es gibt mehrere Möglichkeiten, HA zu erreichen, aber im Allgemeinen stellen Sie dafür eine redundante Infrastruktur bereit, die Sie Ihrer Anwendung schnell zur Verfügung stellen können.
In diesem Dokument werden folgende Themen behandelt:
- Definition von Begriffen mit Bezug zu HA-Datenbankkonzepten.
- Optionen für HA-PostgreSQL-Topologien.
- Kontextbezogene Informationen zu den einzelnen Architekturoptionen.
Terminologie
Die folgenden Begriffe und Konzepte sind Branchenstandard, deren Verständnis auch über den Rahmen dieses Dokuments hinaus nützlich ist.
- Replikation
- Der Prozess, durch den Schreibtransaktionen (
INSERT,UPDATEoderDELETE) und Schemaänderungen (Datendefinitionssprache, Data Definition Language (DDL)) zuverlässig erfasst, protokolliert und anschließend auf alle nachgelagerten Datenbank-Replikatknoten in der Architektur angewendet werden. - Primärer Knoten
- Der primäre Knoten ermöglicht einen Lesevorgang mit dem aktuellsten Stand der beibehaltenen Daten. Alle Datenbankschreibvorgänge müssen an einen primären Knoten gerichtet werden.
- Replikatknoten (sekundär)
- Eine Onlinekopie des primären Datenbankknotens. Änderungen werden entweder synchron oder asynchron vom primären Knoten auf Replikatknoten repliziert. Sie können zwar aus Replikatknoten lesen, doch können die Daten aufgrund der Replikationsverzögerung etwas verzögert sein.
- Replikationsverzögerung
- Eine Messung, Logsequenznummer (LSN), Transaktions-ID oder Zeit. Die Replikationsverzögerung gibt die Differenz zwischen dem Zeitpunkt der Anwendung von Änderungsvorgängen auf das Replikat und dem Zeitpunkt an, zu dem sie auf den primären Knoten angewendet werden.
- Kontinuierliche Archivierung
- Eine inkrementelle Sicherung, in der die Datenbank kontinuierlich sequenzielle Transaktionen in einer Datei speichert.
- Write-Ahead-Log (WAL)
- Ein Write-Ahead-Log (WAL) ist eine Logdatei, in der Änderungen an Datendateien aufgezeichnet werden, bevor Änderungen an den Dateien vorgenommen werden. Bei einem Serverabsturz ist das WAL eine Standardmethode, mit der Sie die Datenintegrität und Langlebigkeit Ihrer Schreibvorgänge gewährleisten können.
- WAL-Eintrag
- Eintrag einer Transaktion, die auf die Datenbank angewendet wurde. Ein WAL-Eintrag ist formatiert und als eine Reihe von Einträgen gespeichert, die Änderungen auf der Datendatei auf Seitenebene beschreiben.
- Logsequenznummer (LSN)
- Transaktionen erstellen WAL-Einträge, die an die WAL-Datei angehängt werden. Die Position, an der die Einfügung erfolgt, ist die Logsequenz-Nummer (LSN). Es ist eine 64-Bit-Ganzzahl, die als zwei durch einen Schrägstrich getrennte Hexadezimalzahlen dargestellt wird (XXXXXXXX/YYZZZZZZ). Das "Z" steht für die Offset-Position in der WAL-Datei.
- Segmentdateien
- Dateien mit so vielen WAL-Einträgen wie möglich, je nach der Dateigröße, die Sie konfigurieren. Segmentdateien haben kontinuierlich wachsende Dateinamen und eine Standarddateigröße von 16 MB.
- Synchrone Replikation
- Eine Art der Replikation, bei der der primäre Server darauf wartet, dass die Daten in das Replikat-Transaktionslog geschrieben werden, bevor ein Commit an den Client bestätigt wird. Wenn Sie eine Streamingreplikation ausführen, können Sie die PostgreSQL-Option
synchronous_commitverwenden, um die Konsistenz zwischen Ihrem primären Server und dem Replikat zu gewährleisten. - Asynchrone Replikation
- Eine Art der Replikation, bei der der primäre Server nicht wartet, bis die Replikatdatenbank die Transaktion erhalten hat, bevor ein Commit an den Client bestätigt wird. Die asynchrone Replikation hat im Vergleich zur synchronen Replikation eine geringere Latenz. Wenn jedoch der primäre Server abstürzt und die zugehörigen Commits nicht in das Replikat übertragen werden, kann es zu Datenverlusten kommen. Die asynchrone Replikation ist der Standardmodus der Replikation in PostgreSQL, entweder mit dateibasiertem Logversand oder mit Streamingreplikation.
- Dateibasierter Logversand
- Eine Replikationsmethode in PostgreSQL, die die WAL-Segmentdateien vom primären Datenbankserver an das Replikat überträgt. Der primäre Server arbeitet im kontinuierlichen Archivierungsmodus, während jeder Standby-Dienst im kontinuierlichen Wiederherstellungsmodus ausgeführt wird, um die WAL-Dateien zu lesen. Diese Art der Replikation ist asynchron.
- Streamingreplikation
- Eine Replikationsmethode, bei der das Replikat eine Verbindung zum primären Datenbankserver herstellt und kontinuierlich eine fortlaufende Abfolge von Änderungen empfängt. Da Aktualisierungen über einen Stream eingehen, kann das Replikat bei dieser Methode im Vergleich zur Logversandreplikation besser auf dem Stand des primären Datenbankservers gehalten werden. Die Replikation ist standardmäßig asynchron. Sie können aber auch eine synchrone Replikation konfigurieren.
- Physische Streamingreplikation
- Eine Replikationsmethode, die Änderungen an das Replikat überträgt. Bei dieser Methode werden die WAL-Einträge verwendet, die die physischen Datenänderungen in Form von Blockadressen der Festplatte und Byte-zu-Byte-Änderungen enthalten.
- Logische Streamingreplikation
- Eine Replikationsmethode, die Änderungen basierend auf ihrer Replikationsidentität (Primärschlüssel) erfasst. So können Sie die Replikation der Daten im Vergleich zur physischen Replikation besser steuern. Aufgrund von Einschränkungen bei der logischen PostgreSQL-Replikation erfordert die logische Streamingreplikation eine spezielle Konfiguration für eine HA-Einrichtung. In diesem Leitfaden wird die standardmäßige physische Replikation erläutert und es wird nicht die logische Replikation besprochen.
- uptime
- Der prozentuale Anteil der Zeit, während der eine Ressource einsatzbereit ist und Anfragen beantworten kann.
- Ausfallerkennung
- Der Prozess der Erkennung eines Infrastrukturausfalls.
- failover
- Der Prozess des Hochstufens der Sicherungs- oder Standby-Infrastruktur (in diesem Fall des Replikatknotens) zur primären Infrastruktur. Während des Failovers wird der Replikatknoten zum primären Knoten.
- Switchover
- Die Ausführung eines manuellen Failovers in einem Produktionssystem. Bei einem Switchover wird entweder getestet, ob das System gut funktioniert, oder der aktuelle primäre Knoten wird zu Wartungszwecken aus dem Cluster entfernt.
- Recovery Time Objective (RTO)
- Die verstrichene Echtzeit, die der Failover-Prozess der Datenstufe erfordert. Der RTO-Wert hängt von der Zeitspanne ab, die aus Unternehmenssicht akzeptabel ist.
- Recovery Point Objective (RPO)
- Die Datenverlustmenge (in verstrichener Echtzeit) für die Datenstufe, die infolge eines Failovers beibehalten werden soll. Der RPO-Wert hängt von der Datenverlustmenge ab, die aus geschäftlicher Sicht akzeptabel ist.
- Fallback
- Der Prozess zur Reaktivierung des vorherigen primären Knotens, nachdem die Bedingung, die ein Failover verursachte, behoben wurde.
- Selbstreparatur
- Die Fähigkeit eines Systems, Probleme ohne externen, menschlichen Eingriff zu beheben.
- Netzwerkpartitionierung
- Eine Situation, in der zwei Knoten einer Architektur (z. B. der primäre Knoten und der Replikatknoten) nicht über das Netzwerk miteinander kommunizieren können.
- Split-Brain
- Eine Situation, in der zwei Knoten gleichzeitig "glauben", der primäre Knoten zu sein.
- Knotengruppe
- Eine Reihe von Rechenressourcen, die einen Dienst bereitstellen. In diesem Dokument ist dieser Dienst die Datenpersistenzstufe.
- Witness- oder Quorumknoten
- Eine separate Computing-Ressource, die einer Knotengruppe hilft, zu bestimmen, was in einer Split-Brain-Situation zu tun ist.
- Auswahl des primären Knotens oder Leaders
- Der Prozess, über den eine Gruppe peer-sensitiver Knoten (einschließlich Witness-Knoten) bestimmt, welcher Knoten der primäre Knoten sein soll.
Mögliche Gründe für die Verwendung einer HA-Architektur
HA-Architekturen bieten im Vergleich zu Datenbankkonfigurationen mit nur einem Knoten einen höheren Schutz vor Ausfällen der Datenstufe. Um die beste Option für Ihren Anwendungsfall auszuwählen, müssen Sie Ihre Toleranz bei Ausfallzeiten bestimmen und die entsprechenden Vor- und Nachteile der verschiedenen Architekturen abwägen.
Verwenden Sie eine HA-Architektur, wenn Sie eine erhöhte Verfügbarkeit der Datenstufe erreichen möchten, um die Zuverlässigkeitsanforderungen für Ihre Arbeitslasten und Dienste zu erfüllen. Bei Umgebungen, in denen ein gewisses Maß an Ausfallzeiten tolerierbar ist, führt eine HA-Architektur zu unnötigen Kosten und unnötiger Komplexität. Beispielsweise erfordern Entwicklungs- und Testumgebungen nur selten eine hohe Verfügbarkeit der Datenbankstufe.
HA-Anforderungen berücksichtigen
Anhand der folgenden Fragen lässt sich entscheiden, welche PostgreSQL-HA-Option für Ihr Unternehmen am besten geeignet ist:
- Welches Verfügbarkeitsniveau möchten Sie erreichen? Benötigen Sie eine Option, mit der Ihr Dienst auch dann weiter funktioniert, wenn ein regionaler Ausfall auftritt, oder nur beim Ausfall einer einzelnen Zone? Einige HA-Optionen sind auf eine Region beschränkt, andere hingegen können auf mehrere Regionen verteilt sein.
- Welche Dienste oder Kunden sind auf Ihre Datenstufe angewiesen und wie hoch sind die Kosten für Ihr Unternehmen, wenn Ausfallzeiten in der Datenpersistenzebene auftreten? Wenn ein Dienst nur für interne Kunden bestimmt ist, die eine gelegentliche Nutzung des Systems erfordern, sind die Verfügbarkeitsanforderungen wahrscheinlich niedriger als bei einem endkundenorientierten Dienst, der Kunden kontinuierlich betreut.
- Wie hoch ist Ihr operatives Budget? Die Kosten sind ein wichtiger Aspekt: Zur Bereitstellung von Hochverfügbarkeit werden Ihre Infrastruktur- und Speicherkosten wahrscheinlich steigen.
- Wie automatisiert muss der Prozess sein und wie schnell muss ein Failover erfolgen? Welches RTO haben Sie? HA-Optionen variieren, je nachdem, wie schnell das System ein Failover ausführen und Kunden zur Verfügung stehen kann.
- Können Sie es sich leisten, aufgrund des Failovers Daten zu verlieren? Welches RPO haben Sie? Da HA-Topologien verteilt sind, besteht ein Kompromiss zwischen Commit-Latenz und Risiko des Datenverlusts aufgrund eines Fehlers.
Funktionsweise von HA
In diesem Abschnitt werden Streamingreplikation und synchrone Streamingreplikation beschrieben, die PostgreSQL-HA-Architekturen zugrunde liegen.
Streamingreplikation
Die Streamingreplikation ist ein Replikationsansatz, bei dem das Replikat mit der primären Instanz verbunden und kontinuierlich einen Stream von WAL-Datensätzen erhält. Im Vergleich zur Logversandreplikation kann das Replikat bei der Streamingreplikation besser mit dem primären Server Schritt halten. PostgreSQL bietet ab Version 9 eine integrierte Streamingreplikation. Viele PostgreSQL-HA-Lösungen verwenden die integrierte Streamingreplikation, um den Mechanismus zu ermöglichen, dass mehrere PostgreSQL-Replikatknoten mit dem primären Server synchronisiert werden. Einige dieser Optionen werden weiter unten in diesem Dokument im Abschnitt PostgreSQL-HA-Architekturen erläutert.
Für jeden Replikatknoten sind dedizierte Computing- und Speicherressourcen erforderlich. Die Infrastruktur des Replikatknotens ist unabhängig vom primären Server. Sie können Replikatknoten als Hot-Standbys verwenden, um schreibgeschützte Clientabfragen bereitzustellen. Dieser Ansatz ermöglicht Load-Balancing für schreibgeschützte Abfragen zwischen dem primären Server und einem oder mehreren Replikaten.
Die Streamingreplikation ist standardmäßig asynchron. Der primäre Knoten wartet nicht auf die Bestätigung von einem Replikat, um ein Transaktions-Commit an den Client zu bestätigen. Wenn ein primärer Knoten ausfällt, nachdem die Transaktion bestätigt wurde, aber bevor ein Replikat die Transaktion empfängt, kann es bei der asynchronen Replikation zu Datenverlusten kommen. Wenn das Replikat zu einem neuen primären Knoten hochgestuft wird, ist eine solche Transaktion nicht vorhanden.
Synchrone Streamingreplikation
Sie können die Streamingreplikation als synchron konfigurieren, indem Sie ein oder mehrere Replikate als synchrones Standby auswählen. Wenn Sie die Architektur für die synchrone Replikation konfigurieren, bestätigt der primäre Knoten den Transaktions-Commit erst, nachdem das Replikat die Transaktionspersistenz bestätigt hat. Die synchrone Streamingreplikation bietet eine höhere Langlebigkeit für eine höhere Transaktionslatenz.
Mit der Konfigurationsoption synchronous_commit können Sie auch die folgenden progressiven Langlebigkeitsstufen des Replikats für die Transaktion konfigurieren:
local: Synchrone Standby-Replikate sind nicht an der Commit-Bestätigung beteiligt. Der primäre Knoten bestätigt Transaktions-Commits, nachdem WAL-Einträge auf seine lokale Festplatte geschrieben und geleert wurden. Für Transaktions-Commits auf dem primären Replikat sind keine Standby-Replikate erforderlich. Transaktionen können verloren gehen, wenn auf dem primären Knoten ein Fehler auftritt.on[Standard]: Synchrone Standby-Replikate schreiben Commit-Transaktionen in ihr WAL, bevor sie eine Bestätigung an den primären Knoten senden. Bei deron-Konfiguration kann die Transaktion nur verloren gehen, wenn der primäre Knoten und alle synchronen Standby-Replikate gleichzeitig zu Speicherfehlern führen. Da die Replikate erst eine Bestätigung senden, nachdem sie WAL-Einträge geschrieben haben, können Clients, die das Replikat abfragen, Änderungen erst sehen, nachdem die entsprechenden WAL-Einträge auf die Replikatdatenbank angewendet wurden.remote_write: Synchrone Standby-Replikate bestätigen den Empfang des WAL-Eintrags auf Betriebssystemebene, garantieren jedoch nicht, dass der WAL-Eintrag auf das Laufwerk geschrieben wurde. Daremote_writekeine Garantie dafür ist, dass die WAL geschrieben wurde, kann die Transaktion verloren gehen, wenn sowohl beim primären als auch beim sekundären Server ein Fehler auftritt, bevor die Datensätze geschrieben werden.remote_writehat eine geringere Langlebigkeit hat als die Optionon.remote_apply: Synchrone Standby-Replikate bestätigen den Transaktionseingang und die erfolgreiche Anwendung bei der Datenbank, bevor sie den Commit der Transaktion beim Client bestätigen. Mit der Konfigurationremote_applywird sichergestellt, dass die Transaktion im Replikat beibehalten wird und die Ergebnisse der Clientabfrage sofort die Auswirkungen der Transaktion einschließen.remote_applybietet im Vergleich zuonundremote_writeeine höhere Langlebigkeit und Konsistenz.
Die Konfigurationsoption synchronous_commit funktioniert mit der Konfigurationsoption synchronous_standby_names, die die Liste der Standby-Server angibt, die am synchronen Replikationsprozess beteiligt sind. Wenn keine Namen für synchrone Standby-Instanzen angegeben sind, wird bei Transaktions-Commits nicht auf die Replikation gewartet.
PostgreSQL-HA-Architekturen
Auf der einfachsten Ebene umfasst HA auf der Datenstufe Folgendes:
- Einen Mechanismus zur Ermittlung, ob ein Ausfall des primären Knotens auftritt.
- Einen Vorgang zur Ausführung eines Failovers, bei dem der Replikatknoten zu einem primären Knoten hochgestuft wird.
- Einen Prozess zum Ändern des Abfrageroutings, sodass Anwendungsanfragen den neuen primären Knoten erreichen
- Eine optionale Methode zur Ausführung eines Fallbacks auf die ursprüngliche Architektur. Dabei werden der primäre Knoten und der Replikatknoten mit ihrer ursprünglichen Kapazität vor dem Failover verwendet.
In den folgenden Abschnitten erhalten Sie einen Überblick über die folgenden HA-Architekturen:
- Die Patroni-Vorlage
- pg_auto_failover-Erweiterung und Dienst
- Zustandsorientierte MIGs und regionaler nichtflüchtiger Speicher
Diese HA-Lösungen minimieren die Ausfallzeiten, wenn eine Infrastruktur oder eine Zone ausfällt. Wenn Sie sich zwischen diesen Optionen entscheiden, wägen Sie Commit-Latenz und Langlebigkeit entsprechend Ihren Geschäftsanforderungen ab.
Ein wichtiger Aspekt einer Hochverfügbarkeitsarchitektur ist der Zeit- und manuellen Aufwand, der zur Vorbereitung einer neuen Standby-Umgebung für nachfolgendes Failover oder Fallbacks erforderlich ist. Andernfalls kann das System nur einen Ausfall standhalten und der Dienst ist nicht durch einen SLA-Verstoß geschützt. Wir empfehlen die Auswahl einer HA-Architektur, die manuelle Failovers oder Switchovers mit der Produktionsinfrastruktur ausführen kann.
HA mit der Patroni-Vorlage
Patroni ist eine ausgereifte und aktiv gepflegte Open-Source-Softwarevorlage (MIT-Lizenz), die Ihnen Tools zum Konfigurieren, Bereitstellen und Ausführen einer PostgreSQL-HA-Architektur bietet. Patroni bietet einen gemeinsamen Clusterstatus und eine Architekturkonfiguration, die in einem verteilten Konfigurationsspeicher (DCS) gespeichert werden. Optionen zum Implementieren eines DCS sind: etcd, Consul, Apache ZooKeeper oder Kubernetes. Das folgende Diagramm zeigt die Hauptkomponenten eines Patroni-Clusters.
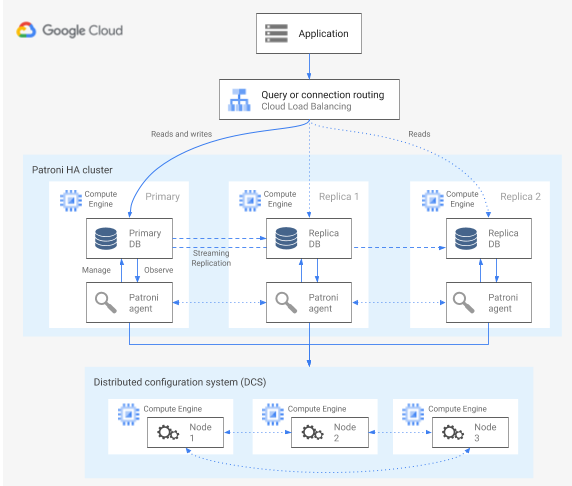
Abbildung 1. Diagramm der Hauptkomponenten eines Patroni-Clusters.
In Abbildung 1 liegen die Load-Balancer den PostgreSQL-Knoten gegenüber und der DCS und die Patroni-Agents werden auf den PostgreSQL-Knoten ausgeführt.
Patroni führt auf jedem PostgreSQL-Knoten einen Agent-Prozess aus. Der Agent-Prozess verwaltet den PostgreSQL-Prozess und die Konfiguration der Datenknoten. Der Patroni-Agent koordiniert die DCS mit anderen Knoten. Für den Patroni-Agent-Prozess wird außerdem eine REST API zur Verfügung gestellt, die Sie abfragen können, um den Zustand des PostgreSQL-Dienstes und die Konfiguration für jeden Knoten zu ermitteln.
Der primäre Knoten aktualisiert den Leader-Schlüssel regelmäßig im DCS, um seine Rolle der Clustermitgliedschaft geltend zu machen. Der Leader-Schlüssel umfasst eine Gültigkeitsdauer (TTL). Wenn die TTL ohne Aktualisierung fehlschlägt, wird der Leader-Schlüssel aus dem DCS entfernt und die Leader-Auswahl wählt einen neuen primären Knoten aus dem Pool der Kandidaten aus.
Das folgende Diagramm zeigt einen intakten Cluster, in dem Knoten A die Leader-Sperre erfolgreich aktualisiert.
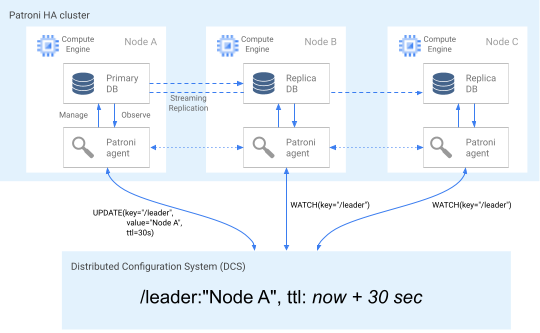
Abbildung 2. Diagramm eines intakten Clusters.
Abbildung 2 zeigt einen intakten Cluster: Knoten B und Knoten-C beobachten, wie Knoten A den Leader-Schlüssel erfolgreich aktualisiert.
Ausfallerkennung
Der Patroni-Agent überträgt seinen Status kontinuierlich durch Aktualisieren seines Schlüssels im DCS. Gleichzeitig validiert der Agent den PostgreSQL-Systemzustand. Wenn der Agent ein Problem erkennt, wird der Knoten entweder durch Herunterfahren abgeschirmt oder auf ein Replikat heruntergestuft. Wenn der beeinträchtigte Knoten der primäre Knoten ist, läuft der zugehörige Leader-Schlüssel im DCS ab und eine neue Auswahl erfolgt. Dies wird im folgenden Diagramm veranschaulicht.
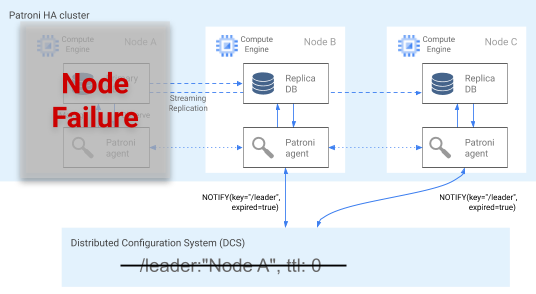
Abbildung 3. Diagramm eines beeinträchtigten Clusters.
Abbildung 3 zeigt einen beeinträchtigten Cluster: Ein inaktiver Knoten hat seinen Leader-Schlüssel in der letzten Zeit nicht aktualisiert und die Nicht-Leader-Replikate werden über den Ablauf des Leader-Schlüssels benachrichtigt.
Auf Linux-Hosts führt Patroni auch einen Watchdog auf Betriebssystemebene auf primären Knoten aus. Dieser Watchdog wartet auf Keep-Alive-Nachrichten vom Patroni-Agent-Prozess. Wenn der Vorgang nicht mehr reagiert und das Keep-Alive nicht gesendet wird, startet der Watchdog den Host neu. Der Watchdog hilft dabei, einen Split-Brain-Zustand zu verhindern, bei dem der PostgreSQL-Knoten weiterhin der primäre Knoten ist, aber der Leader-Schlüssel im DCS aufgrund eines Agentenausfalls abgelaufen ist und ein anderer primärer Knoten (Leader) gewählt wurde.
Failover-Vorgang
Wenn die Leader-Sperre im DCS abläuft, starten die Replikatknoten die Auswahl eines Leaders. Wenn ein Replikat eine fehlende Leader-Sperre erkennt, prüft es die Replikationsposition im Vergleich zu den anderen Replikaten. Jedes Replikat ruft mit der REST API die WAL-Log-Positionen der anderen Replikatknoten ab, wie im folgenden Diagramm dargestellt.
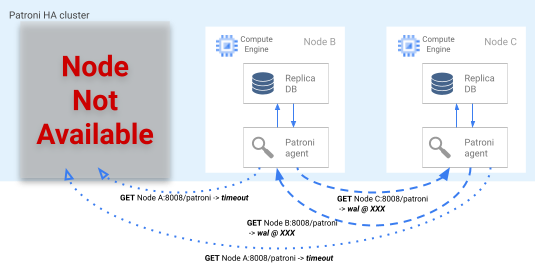
Abbildung 4. Diagramm des Patroni-Failover-Prozesses.
Abbildung 4 zeigt WAL-Log-Positionsabfragen und die zugehörigen Ergebnisse von den aktiven Replikatknoten. Knoten A ist nicht verfügbar und die fehlerfreien Knoten B und C geben sich gegenseitig dieselbe WAL-Position zurück.
Der aktuellste Knoten bzw. die aktuellsten Knoten, sofern sie sich an derselben Position befinden, versuchen gleichzeitig, die Leader-Sperre im DCS zu erhalten. Der Leader-Schlüssel im DCS kann jedoch nur von einem Knoten erstellt werden. Der erste Knoten, der den Leader-Schlüssel erfolgreich erstellt, gewinnt das Leader-Rennen. Dieser Vorgang wird im folgenden Diagramm dargestellt. Alternativ können Sie bevorzugte Failover-Kandidaten festlegen, indem Sie das failover_priority-Tag in den Konfigurationsdateien festlegen.
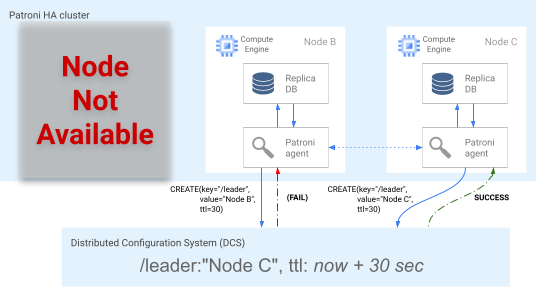
Abbildung 5. Diagramm des Leader-Rennens.
Abbildung 5 zeigt ein Leader-Rennen: Zwei Leader-Kandidaten versuchen, die Leader-Sperre zu erhalten, aber nur einer der beiden Knoten (Knoten C) setzt den Leader-Schlüssel erfolgreich ein und gewinnt das Rennen.
Nachdem es die Leader-Auswahl gewonnen hat, stuft sich das Replikat selbst zum neuen primären Knoten hoch. Ab dem Zeitpunkt, zu dem das Replikat sich selbst hochstuft, aktualisiert der neue primäre Knoten den Leader-Schlüssel im DCS, um die Leader-Sperre beizubehalten. Die anderen Knoten dienen dabei als Replikate.
Außerdem bietet Patroni das patronictl-Steuertool an, mit dem Sie Switchover ausführen können, um den Nodal-Failover-Prozess zu testen.
Dieses Tool hilft Operatoren, ihre HA-Einrichtungen in der Produktion zu testen.
Abfragerouting
Der auf jedem Knoten ausgeführte Patroni-Agent stellt REST API-Endpunkte zur Verfügung, die die aktuelle Knotenrolle preisgeben: primärer Knoten oder Replikatknoten.
| REST-Endpunkt | HTTP-Rückgabecode, wenn primärer Knoten | HTTP-Rückgabecode, wenn Replikatknoten |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
Da die relevanten Systemdiagnosen ihre Antworten ändern, wenn ein bestimmter Knoten seine Rolle ändert, kann eine Systemdiagnose des Load-Balancers diese Endpunkte verwenden, um das Traffic-Routing des primären und Replikatknotens zu kommunizieren. Das Patroni-Projekt stellt Vorlagenkonfigurationen für einen Load-Balancer wie HAProxy bereit. Der interne Passthrough-Network-Load-Balancer kann diese Systemdiagnosen verwenden, um ähnliche Funktionen bereitzustellen.
Fallback-Prozess
Bei einem Knotenausfall bleibt ein Cluster in einem eingeschränkten Zustand. Mit dem Fallback-Prozess von Patroni kann ein HA-Cluster nach einem Failover wieder in einen fehlerfreien Zustand versetzt werden. Der Fallback-Prozess verwaltet die Rückgabe des Clusters in seinen ursprünglichen Zustand, indem der betroffene Knoten automatisch als Clusterreplikat initialisiert wird.
Ein Knoten kann beispielsweise aufgrund eines Fehlers im Betriebssystem oder der zugrunde liegenden Infrastruktur neu gestartet werden. Wenn der Knoten der primäre ist und länger als die TTL des Führungsschlüssels braucht, um neu zu starten, wird eine Leader-Wahl ausgelöst und ein neuer primärer Knoten wird ausgewählt und hochgestuft. Wenn der veraltete primäre Patroni-Prozess startet, erkennt er, dass er nicht die Leader-Sperre hat, stuft sich automatisch zu einem Replikat zurück und tritt dem Cluster als solches bei.
Bei einem nicht wiederherstellbarem Knotenausfall wie einem unwahrscheinlichen Zonenausfall, müssen Sie einen neuen Knoten starten. Ein Datenbankoperator kann manuell einen neuen Knoten starten. Sie können auch eine zustandsorientierte regionale verwaltete Instanzgruppe (Managed Instance Group, MIG) mit einer minimalen Knotenzahl verwenden, um den Prozess zu automatisieren. Nachdem der neue Knoten erstellt wurde, erkennt Patroni, dass der neue Knoten Teil eines vorhandenen Clusters ist und initialisiert den Knoten automatisch als Replikat.
HA mit der Erweiterung und dem Dienst pg_auto_failover
pg_auto_failover ist eine aktiv entwickelte Open-Source-PostgreSQL-Erweiterung (PostgreSQL-Lizenz). pg_auto_failover konfiguriert eine HA-Architektur durch Erweitern der vorhandenen PostgreSQL-Funktionen. pg_auto_failover hat keine anderen Abhängigkeiten als PostgreSQL.
Wenn Sie die Erweiterung pg_auto_failover in einer HA-Architektur verwenden möchten, benötigen Sie mindestens drei Knoten, auf denen jeweils PostgreSQL mit der aktivierten Erweiterung ausgeführt wird. Jeder Knoten kann ausfallen, ohne die Verfügbarkeit der Datenbankgruppe zu beeinträchtigen. Eine Sammlung der von pg_auto_failover verwalteten Knoten wird als Formation bezeichnet. Das folgende Diagramm zeigt eine pg_auto_failover-Architektur.
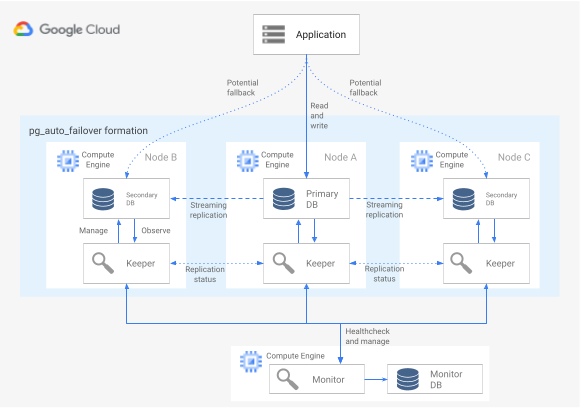
Abbildung 6. Diagramm einer pg_auto_failover-Architektur.
Abbildung 6 zeigt eine pg_auto_failover-Architektur, die aus zwei Hauptkomponenten besteht: dem Monitor-Dienst und dem Keeper-Agent. Sowohl der Keeper-Agent als auch der Monitor-Dienst sind in der Erweiterung pg_auto_failover enthalten.
Monitor-Dienst
Der Monitor-Dienst "pg_auto_failover" ist als PostgreSQL-Erweiterung implementiert. Wenn der Dienst einen Monitor-Knoten erstellt, startet er eine PostgreSQL-Instanz mit aktivierter pg_auto_failover-Erweiterung. Der Monitor-Dienst behält den globalen Zustand für die Formation bei, erhält den Status der Systemdiagnose von den PostgreSQL-Datenknoten des Mitglieds und orchestriert die Gruppe mithilfe der Regeln, die von einer Finite-State-Maschine (FSM) festgelegt wurden. Gemäß den FSM-Regeln für Statusübergänge gibt der Monitor-Dienst den Gruppenknoten Anweisungen für Aktionen wie Hochstufen, Herunterstufen und Konfigurationsänderungen.
Keeper-Agent
Auf jedem pg_auto_failover-Datenknoten startet die Erweiterung einen Keeper-Agent-Prozess. Dieser Keeper-Prozess beobachtet und verwaltet den PostgreSQL-Dienst. Keeper sendet Statusaktualisierungen an den Monitoring-Knoten und empfängt und führt Aktionen aus, die der Monitor als Antwort sendet.
pg_auto_failover richtet standardmäßig alle sekundären Datenknoten einer Gruppe als synchrone Replikate ein. Die Anzahl der für einen Commit erforderlichen synchronen Replikate basiert auf der number_sync_standby-Konfiguration, die Sie auf dem Monitor festlegen.
Ausfallerkennung
Die Keeper-Agents werden regelmäßig mit dem Monitor-Knoten verbunden, um ihren aktuellen Status zu kommunizieren. Prüfen Sie dann, ob Aktionen ausgeführt werden sollen. Der Monitor-Knoten stellt außerdem eine Verbindung zu den Datenknoten her, um einen Gesundheitscheck durchzuführen, indem er die API-Aufrufe des PostgreSQL-Protokolls (libpq) ausführt und dabei die PostgreSQL-Client-Anwendung pg_isready() imitiert. Wenn keine dieser Aktionen nach einem bestimmten Zeitraum (standardmäßig 30 Sekunden) erfolgreich ist, ermittelt der Monitor-Knoten, dass ein Datenknotenfehler aufgetreten ist. Sie können die PostgreSQL-Konfigurationseinstellungen ändern, um das Monitoring-Timing und die Anzahl der Wiederholungsversuche anzupassen. Weitere Informationen finden Sie unter Failover und Fehlertoleranz.
Wenn ein einzelner Knoten ausfällt, trifft eine der folgenden Bedingungen zu:
- Wenn der fehlerhafte Datenknoten ein primärer Knoten ist, startet der Monitor-Dienst ein Failover.
- Wenn der fehlerhafte Datenknoten ein sekundärer Knoten ist, deaktiviert der Monitor-Dienst die synchrone Replikation für den fehlerhaften Knoten.
- Wenn der ausgefallene Knoten der Monitor-Knoten ist, ist kein automatisiertes Failover möglich. Zur Vermeidung dieses Single Point of Failure müssen Sie dafür sorgen, dass die ordnungsgemäße Überwachung und Notfallwiederherstellung eingerichtet ist.
Das folgende Diagramm zeigt die Ausfallszenarien und die in der vorherigen Liste beschriebenen Formationsergebniszustände.
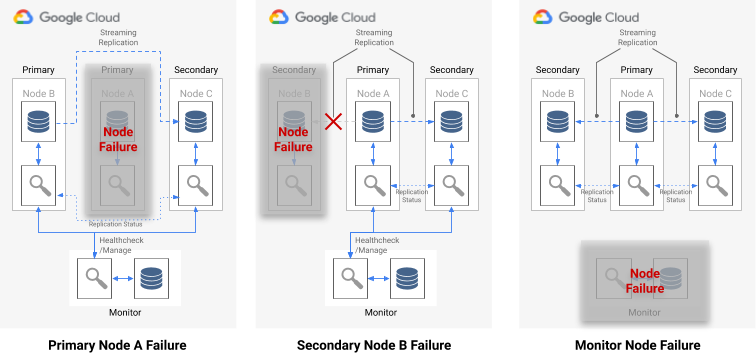
Abbildung 7. Diagramm der pg_auto_failover-Ausfallszenarien.
Failover-Vorgang
Jeder Datenbankknoten in der Gruppe hat die folgenden Konfigurationsoptionen, die den Failover-Prozess bestimmen:
replication_quorum: eine boolesche Option. Wennreplication_quorumauftruegesetzt ist, wird der Knoten als potenzieller Failover-Kandidat betrachtet.candidate_priority: Ganzzahlwert zwischen 0 und 100.candidate_priorityhat den Standardwert 50, den Sie ändern können, um die Failover-Priorität zu beeinflussen. Knoten werden als potenzielles Failover basierend auf dem Wertcandidate_prioritypriorisiert. Knoten mit einem höherencandidate_priority-Wert haben eine höhere Priorität. Für den Failover-Prozess ist es erforderlich, dass mindestens zwei Knoten in jeder Phase von pg_auto_failover eine Priorität von null haben.
Bei einem Ausfall des primären Knotens werden sekundäre Knoten für das Hochstufen berücksichtigt, wenn sie eine aktive synchrone Replikation haben und Mitglieder des replication_quorum sind.
Sekundäre Knoten werden gemäß den folgenden progressiven Kriterien für die Hochstufung berücksichtigt:
- Knoten mit der höchsten Kandidatenpriorität
- Standby mit der vordersten im Monitor-Dienst veröffentlichten WAL-Log-Position
- Zufällige Auswahl eines finalen Gleichstands
Ein Failover-Kandidat ist ein verzögerter Kandidat, wenn es die fortschrittlichste LSN-Position im WAL nicht veröffentlicht hat. In diesem Szenario gibt pg_auto_failover einen Zwischenschritt im Failover-Mechanismus an: das verzögerungsbedingte Kandidat ruft die fehlenden WAL-Byte von einem Standby-Knoten mit der fortschrittlichsten LSN-Position ab. Der Stand-by-Knoten wird dann hochgestuft. Postgres ermöglicht diesen Vorgang, da bei der kaskadierenden Replikation jeder Standby als vorgelagerter Knoten für einen anderen Standby fungieren kann.
Abfragerouting
pg_auto_failure bietet keine serverseitige Funktionen zur Abfrageweiterleitung.
Stattdessen arbeitet pg_auto_failure auf dem clientseitigen Abfragerouting zurück, das den offiziellen PostgreSQL-Clienttreiber libpq verwendet.
Wenn Sie den Verbindungs-URI definieren, kann der Treiber mehrere Hosts im Schlüsselwort host akzeptieren.
Die von Ihrer Anwendung verwendete Clientbibliothek muss entweder "libpq" nutzen oder die Möglichkeit bieten, mehrere Hosts für die Architektur bereitzustellen, um eine vollständig automatisiertes Failover zu unterstützen.
Fallback- und Switchover-Prozesse
Wenn der Keeper-Prozess einen ausgefallenen Knoten neu startet oder einen neuen Ersatzknoten startet, wird der Monitor-Knoten vom Prozess geprüft, um die nächste auszuführende Aktion zu ermitteln. Wenn ein ausgefallener neu gestarteter Knoten zuvor der primäre Knoten war und der Monitor-Dienst bereits einen neuen primären Knoten gemäß dem Failover-Prozess ausgewählt hat, initialisiert Keeper diesen veralteten primären Knoten als sekundäres Replikat neu.
pg_auto_failure stellt das pg_autoctl-Tool bereit, mit dem Sie Switchover zum Testen des Knoten-Failover-Prozesses ausführen können. Neben dem Testen von HA-Konfigurationen in der Produktion können Sie mit dem Tool auch HA-Cluster nach einem Failover wiederherstellen.
HA mit zustandsorientierten MIGs und regionalem nichtflüchtigen Speicher
In diesem Abschnitt wird ein HA-Ansatz mit den folgenden Google Cloud-Komponenten beschrieben:
- Regionaler nichtflüchtiger Speicher. Wenn Sie regionale nichtflüchtige Speicher verwenden, werden die Daten in einer Region synchron zwischen zwei Zonen repliziert, sodass Sie die Streamingreplikation nicht verwenden müssen. HA ist jedoch auf genau zwei Zonen in einer Region beschränkt.
- Zustandsorientierte verwaltete Instanzgruppen. Ein Paar zustandsorientierter MIGs wird als Teil einer Steuerungsebene verwendet, um einen primären PostgreSQL-Knoten auszuführen. Wenn die zustandsorientierte MIG eine neue Instanz startet, kann sie den vorhandenen regionalen nichtflüchtigen Speicher anhängen. Zu einem bestimmten Zeitpunkt wird nur bei einer der beiden MIGs eine Instanz ausgeführt.
- Cloud Storage. Ein Objekt in einem Cloud Storage-Bucket enthält eine Konfiguration, die angibt, welche der beiden MIGs den primären Datenbankknoten ausführt und in welcher MIG eine Failover-Instanz erstellt werden soll.
- MIG-Systemdiagnosen und automatische Reparatur. Die Systemdiagnose überwacht den Zustand der Instanz. Wenn der ausgeführte Knoten fehlerhaft wird, initiiert die Systemdiagnose den automatischen Reparaturvorgang.
- Logging: Wenn die automatische Reparatur den primären Knoten beendet, wird ein Eintrag in Logging aufgezeichnet. Die entsprechenden Logeinträge werden mithilfe eines Filters in ein Pub/Sub-Senkenthema exportiert.
- Ereignisgesteuerte Cloud Run-Funktionen. Die Pub/Sub-Nachricht löst Cloud Run-Funktionen aus. Cloud Run Functions ermittelt anhand der Konfiguration in Cloud Storage, welche Aktionen für jede zustandsorientierte MIG ausgeführt werden sollen.
- Interner Passthrough-Network-Load-Balancer. Der Load-Balancer bietet das Routing an die ausgeführte Instanz in der Gruppe. Dadurch wird sichergestellt, dass die Änderung der Instanz-IP-Adresse durch die Neuerstellung von Instanzen vom Client abstrahiert wird.
Das folgende Diagramm zeigt ein Beispiel für eine HA-Architektur mit zustandsorientierten MIGs und regionalen nichtflüchtigen Speichern:

Abbildung 8. Diagramm einer HA-Architektur mit zustandsorientierten MIGs und regionalen nichtflüchtigen Speichern.
Abbildung 8 zeigt einen fehlerfreien primären Knoten, der Clienttraffic verarbeitet. Clients stellen eine Verbindung zur statischen IP-Adresse des internen Passthrough-Network-Load-Balancers her. Der Load-Balancer leitet Clientanfragen an die VM weiter, die im Rahmen der MIG ausgeführt wird. Datenvolumen wird auf bereitgestellten regionalen nichtflüchtigen Speichern gespeichert.
Um diesen Ansatz zu implementieren, erstellen Sie ein VM-Image mit PostgreSQL, das bei der Initialisierung gestartet wird, um es als Instanzvorlage der MIG zu verwenden. Sie müssen auf dem Knoten auch eine HTTP-basierte Systemdiagnose (wie HAProxy oder pgDoctor) konfigurieren. Eine HTTP-basierte Systemdiagnose stellt sicher, dass sowohl der Load-Balancer als auch die Instanzgruppe den Systemstatus des PostgreSQL-Knotens ermitteln können.
Regionaler nichtflüchtiger Speicher
Wenn Sie ein Blockspeichergerät bereitstellen möchten, das eine synchrone Datenreplikation zwischen zwei Zonen in einer Region bietet, können Sie die regionale nichtflüchtige Speicheroption von Compute Engine verwenden. Regionale nichtflüchtige Speicher können einen grundlegenden Baustein bereitstellen, mit dem Sie eine PostgreSQL-HA-Option implementieren können, die nicht auf die integrierte Streamingreplikation von PostgreSQL angewiesen ist.
Wenn die VM-Instanz des primären Knotens aufgrund eines Infrastruktur- oder Zonenausfalls nicht mehr verfügbar ist, können Sie erzwingen, dass der regionale nichtflüchtige Speicher an eine VM-Instanz in der Sicherungszone derselben Region angehängt wird.
Sie haben zwei Möglichkeiten, den regionalen nichtflüchtigen Speicher an eine VM-Instanz in Ihrer Sicherungszone anzuhängen:
- Eine Cold-Standby-VM-Instanz in der Sicherungszone verwalten. Eine Cold-Standby-VM-Instanz ist eine gestoppte VM-Instanz, auf der kein regionaler nichtflüchtiger Speicher bereitgestellt ist, die aber eine identische VM-Instanz wie die VM-Instanz des Primärknotens ist. Wenn ein Fehler auftritt, wird die Cold-Standby-VM gestartet und der regionale nichtflüchtige Speicher ist darin bereitgestellt. Die Cold-Standby-Instanz und die primäre Knoteninstanz haben dieselben Daten.
- Erstellen Sie ein Paar zustandsorientierter MIGs mit derselben Instanzvorlage. Die MIGs stellen Systemdiagnosen bereit und dienen als Teil der Steuerungsebene. Wenn der primäre Knoten ausfällt, wird in der Ziel-MIG deklarativ eine Failover-Instanz erstellt. Die Ziel-MIG wird im Cloud Storage-Objekt definiert. Die instanzspezifische Konfiguration wird verwendet, um den regionalen nichtflüchtigen Speicher anzuhängen.
Wenn der Datendienstausfall sofort erkannt wird, wird der Vorgang zum erzwungenen Anhängen normalerweise innerhalb einer Minute abgeschlossen. Ein in Minuten gemessener RTO ist daher erreichbar.
Wenn Ihr Unternehmen die für den Ausfall und die erforderliche Ausfallzeit erforderliche zusätzliche Ausfallzeit tolerieren und ein Failover manuell durchführen kann, müssen Sie den Prozess zum erzwungenen Anhängen nicht automatisieren. Wenn Ihre RTO-Toleranz niedriger ist, können Sie den Erkennungs- und Failover-Prozess automatisieren. Alternativ bietet Cloud SQL for PostgreSQL auch eine vollständig verwaltete Implementierung dieses HA-Ansatzes.
Ausfallerkennung und Failover-Prozess
Der HA-Ansatz verwendet die automatischen Reparatur von Instanzgruppen, um den Zustand der Knoten mithilfe einer Systemdiagnose zu überwachen. Wenn die Systemdiagnose fehlschlägt, gilt die vorhandene Instanz als fehlerhaft und die Instanz wird gestoppt. Dadurch wird der Failover-Prozess mit Logging, Pub/Sub und der ausgelösten Cloud Run Functions-Funktion initiiert.
Eine der beiden MIGs wird von Cloud Run Functions so konfiguriert, dass in einer der beiden Zonen, in denen der regionale nichtflüchtige Speicher ausgeführt wird, eine Instanz erstellt werden. So wird erreicht, dass für diese VM immer der regionale Speicher bereitgestellt ist. Bei einem Knotenausfall wird die Ersatzinstanz gemäß dem Status in Cloud Storage in der alternativen Zone gestartet.

Abbildung 9. Diagramm eines Zonenausfalls in einer MIG.
In Abbildung 9 ist der frühere primäre Knoten in Zone A ausgefallen und Cloud Run Functions hat MIG B so konfiguriert, dass eine neue primäre Instanz in Zone B gestartet wird. Der Mechanismus zur Fehlererkennung ist automatisch so konfiguriert, dass er den Status des neuen primären Knotens überwacht.
Abfragerouting
Der interne Passthrough-Network-Load-Balancer leitet Clients an die Instanz weiter, auf der der PostgreSQL-Dienst ausgeführt wird. Der Load-Balancer verwendet die gleiche Systemdiagnose wie die Instanzgruppe, um festzustellen, ob die Instanz für die Verarbeitung von Abfragen verfügbar ist. Wenn der Knoten nicht verfügbar ist, weil er neu erstellt wird, schlagen die Verbindungen fehl. Nachdem die Instanz gesichert wurde, werden Systemdiagnosen weitergeleitet und die neuen Verbindungen werden an den verfügbaren Knoten weitergeleitet. In dieser Konfiguration gibt es keine schreibgeschützten Knoten, da nur ein Knoten ausgeführt wird.
Fallback-Prozess
Wenn eine Systemdiagnose aufgrund eines zugrunde liegenden Hardwareproblems nicht erfolgreich ausgeführt wird, wird der Knoten auf einer anderen zugrunde liegenden Instanz neu erstellt. Dann wird die Architektur ohne zusätzliche Schritte in den ursprünglichen Zustand zurückversetzt. Bei einem Zonenausfall wird die Einrichtung jedoch weiterhin beeinträchtigt, bis die erste Zone wiederhergestellt ist. Obwohl es sehr unwahrscheinlich ist, kann die PostgreSQL-Instanz bei gleichzeitigen Ausfällen in beiden Zonen, die für die regionale nichtflüchtige Speicherreplikation und die zustandsorientierte MIG konfiguriert sind, nicht wiederhergestellt werden. Die Datenbank ist während des Ausfalls nicht verfügbar, um Anfragen zu bedienen.
Vergleich zwischen den HA-Optionen
In den folgenden Tabellen werden die HA-Optionen von Patroni, pg_auto_failover, und zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern verglichen.
Einrichtung und Architektur
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
|
Erfordert eine HA-Architektur, DCS-Einrichtung sowie Monitoring und Benachrichtigungen. Die Einrichtung des Agents auf Datenknoten ist relativ einfach. |
Erfordert keine externen Abhängigkeiten außer PostgreSQL. Erfordert einen Knoten, der als Monitor-Knoten eingerichtet ist. Der Monitor-Knoten erfordert HA und DR, um sicherzustellen, dass es sich nicht um einen Single Point of Failure (SPOF) handelt. | Architektur, die ausschließlich aus Google Cloud-Diensten besteht. Sie können jeweils nur einen aktiven Datenbankknoten ausführen. |
HA-Konfigurierbarkeit
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
| Extrem konfigurierbar: Sie unterstützt sowohl synchrone als auch asynchrone Replikation. Außerdem können Sie angeben, welche Knoten synchron und asynchron sein sollen. Umfasst die automatische Verwaltung synchroner Knoten. Ermöglicht Konfigurationen mit mehreren Zonen und mehreren Regionen. Auf den DCS muss zugegriffen werden können. | Ähnlich wie Patroni: sehr konfigurierbar. Da der Monitoring jedoch nur als eine Instanz verfügbar ist, muss jede Art von Einrichtung den Zugriff auf diesen Knoten berücksichtigen. | Auf zwei Zonen in einer einzelnen Region mit synchroner Replikation beschränkt. |
Fähigkeit zur Verarbeitung der Netzwerkpartition
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
| Die Kombination aus Self-Fencing und Monitoring auf Betriebssystemebene bietet Schutz vor Split-Brain. Jedes Mal, wenn das Herstellen einer Verbindung zu den DCS-Ergebnissen fehlschlägt, stuft sich der primäre Knoten selbst auf ein Replikat herunter und löst ein Failover aus, um Langlebigkeit statt Verfügbarkeit zu gewährleisten. | Verwendet eine Kombination aus Systemdiagnosen vom primären Knoten zum Monitor-Knoten und zum Replikatknoten, um eine Netzwerkpartition zu erkennen und sich selbst herunterzustufen. | Nicht zutreffend: Es ist immer nur ein aktiver PostgreSQL-Knoten vorhanden, also gibt es keine Netzwerkpartition. |
Kosten
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
| Hohe Kosten, da sie vom ausgewählten DCS und der Anzahl der PostgreSQL-Replikate abhängen. Die Patroni-Architektur verursacht keine erheblichen zusätzlichen Kosten. Die Gesamtkosten werden jedoch von der zugrunde liegenden Infrastruktur beeinflusst, die mehrere Compute-Instanzen für PostgreSQL und den DCS verwendet. Da diese Option mehrere Repliken und einen separaten DCS-Cluster verwendet, kann sie am teuersten sein. | Mittlere Kosten, da ein Monitor-Knoten und mindestens drei PostgreSQL-Knoten (ein primärer Knoten und zwei Replikate) ausgeführt werden müssen. | Geringe Kosten, da jeweils nur ein PostgreSQL-Knoten aktiv ausgeführt wird. Sie zahlen nur für eine einzelne Compute-Instanz. |
Clientkonfiguration
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
| Transparent für den Client, da eine Verbindung zu einem Load-Balancer hergestellt wird. | Erfordert eine Clientbibliothek zur Unterstützung mehrerer Hostdefinitionen in der Einrichtung, da sie mit einem Load-Balancer nicht leicht zu erkennen ist. | Transparent für den Client, da eine Verbindung zu einem Load-Balancer hergestellt wird. |
Skalierbarkeit
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
| Hohe Flexibilität bei der Konfiguration von Kompromissen zwischen Skalierbarkeit und Verfügbarkeit. Durch das Hinzufügen weiterer Replikate ist eine Leseskalierung möglich. | Ähnlich wie bei Patroni: Die Leseskalierung ist durch Hinzufügen weiterer Replikate möglich. | Eingeschränkte Skalierbarkeit, da immer nur ein aktiver PostgreSQL-Knoten vorhanden ist. |
PostgreSQL-Knoteninitialisierung und Konfigurationsverwaltung automatisieren
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
Stellt Tools zur Verwaltung der PostgreSQL-Konfiguration (patronictl
edit-config) bereit und initialisiert automatisch neue Knoten oder neu gestartete Knoten im Cluster. Sie können Knoten mit pg_basebackup oder anderen Tools wie Barman initialisieren.
|
Initialisiert automatisch Knoten, ist allerdings bei der Initialisierung eines neuen Replikatknotens auf die Verwendung von pg_basebackup beschränkt.
Die Konfigurationsverwaltung ist auf pg_auto_failover-bezogene Konfigurationen beschränkt.
|
Zustandsorientierte Instanzgruppe mit freigegebenem Laufwerk macht keine PostgreSQL-Knoteninitialisierung erforderlich. Da nur ein Knoten ausgeführt wird, befindet sich die Konfigurationsverwaltung auf einem einzelnen Knoten. |
Anpassungsmöglichkeiten und Features
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
|
Stellt eine Hook-Schnittstelle bereit, über die Nutzer definierbare Aktionen in wichtigen Schritten aufrufen können, wie z. B. Herunter- oder Hochstufung. Umfassende Konfigurationsfeatures wie Unterstützung für verschiedene DCS-Arten, unterschiedliche Methoden zum Initialisieren von Replikaten und verschiedene Möglichkeiten für die Bereitstellung der PostgreSQL-Konfiguration. Ermöglicht die Einrichtung von Standby-Clustern, die eine Kaskadierung von Replikatclustern zulassen und die Migration zwischen Clustern vereinfachen. |
Eingeschränkt, da es sich um ein relativ neues Projekt handelt. | Nicht zutreffend. |
Reife
| Patroni | pg_auto_failover | Zustandsorientierte MIGs mit regionalen nichtflüchtigen Speichern |
|---|---|---|
| Das Projekt steht seit 2015 zur Verfügung und wird in der Produktion von großen Unternehmen wie Zalando und GitLab verwendet. | Relativ neues Projekt wurde Anfang 2019 angekündigt. | Besteht vollständig aus allgemein verfügbaren Google Cloud Produkten. |
Best Practices für Wartung und Monitoring
Die Wartung und Überwachung Ihres PostgreSQL-HA-Clusters ist entscheidend für die Gewährleistung von Hochverfügbarkeit, Datenintegrität und optimaler Leistung. In den folgenden Abschnitten finden Sie einige Best Practices für das Monitoring und die Wartung eines PostgreSQL-HA-Clusters.
Regelmäßige Sicherungen und Wiederherstellungstests durchführen
Sichern Sie Ihre PostgreSQL-Datenbanken regelmäßig und testen Sie den Wiederherstellungsprozess. So wird die Datenintegrität gewährleistet und die Ausfallzeit im Falle eines Ausfalls minimiert. Testen Sie Ihren Wiederherstellungsprozess, um Ihre Sicherungen zu validieren und potenzielle Probleme zu erkennen, bevor es zu einem Ausfall kommt.
PostgreSQL-Server und Replikationsverzögerung überwachen
Überwachen Sie Ihre PostgreSQL-Server, um zu prüfen, ob sie ausgeführt werden. Überwachen Sie die Replikationsverzögerung zwischen dem primären und den Replikatknoten. Eine übermäßige Verzögerung kann bei einem Failover zu Dateninkonsistenzen und erhöhtem Datenverlust führen. Richten Sie Benachrichtigungen für erhebliche Verzögerungssteigerungen ein und untersuchen Sie die Ursache umgehend.
Mit Ansichten wie pg_stat_replication und pg_replication_slots können Sie die Replikationsverzögerung überwachen.
Verbindungs-Pooling implementieren
Mit Connection Pooling können Sie Datenbankverbindungen effizient verwalten. Verbindungs-Pooling trägt dazu bei, den Aufwand für das Herstellen neuer Verbindungen zu reduzieren, was die Anwendungsleistung und die Stabilität des Datenbankservers verbessert. Tools wie PGBouncer und Pgpool-II können Connection Pooling für PostgreSQL bereitstellen.
Umfassendes Monitoring implementieren
Um Einblicke in Ihre PostgreSQL-HA-Cluster zu erhalten, richten Sie robuste Überwachungssysteme ein:
- Wichtige PostgreSQL- und Systemmesswerte wie CPU-Auslastung, Arbeitsspeichernutzung, Festplatten-E/A, Netzwerkaktivität und aktive Verbindungen im Blick behalten.
- Erfassen Sie PostgreSQL-Logs, einschließlich Server-, WAL- und Autovacuum-Logs, für detaillierte Analysen und die Fehlerbehebung.
- Verwenden Sie Monitoring-Tools und Dashboards, um Messwerte und Logs zu visualisieren und Probleme schnell zu erkennen.
- Integrieren Sie Messwerte und Logs in Benachrichtigungssysteme, um proaktiv über potenzielle Probleme informiert zu werden.
Weitere Informationen zum Monitoring einer Compute Engine-Instanz finden Sie in der Cloud Monitoring-Übersicht.
Nächste Schritte
- Mehr über die Cloud SQL-Hochverfügbarkeitskonfiguration erfahren
- Mehr über Hochverfügbarkeitsoptionen mit regionalen nichtflüchtigen Speichern erfahren
- Weitere Informationen zu Patroni.
- Weitere Informationen zu pg_auto_failover.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Beitragende
Autor: Alex Cârciu | Solutions Architect