Application Integration에 지원되는 커넥터를 참조하세요.
데이터 매핑 태스크
데이터 매핑 태스크를 사용하면 통합에서 변수를 할당하고 json 객체의 속성을 가져오고 설정하며 값에 중첩 변환 함수를 적용할 수 있습니다. 변수는 통합 변수나 태스크 변수일 수 있습니다.
예를 들어 통합 변수 X에서 태스크 변수 Y로 또는 태스크 변수 Y에서 통합 변수 X로 값을 할당할 수 있습니다. Application Integration의 변수에 대한 자세한 내용은 Application Integration에서 변수 사용을 참조하세요.
데이터 매핑 태스크 구성
데이터 매핑 태스크를 구성하려면 다음 단계를 수행합니다.
- Google Cloud 콘솔에서 Application Integration 페이지로 이동합니다.
- 탐색 메뉴에서 통합을 클릭합니다.
Google Cloud 프로젝트에서 사용할 수 있는 모든 통합이 나열된 통합 페이지가 나타납니다.
- 기존 통합을 선택하거나 통합 만들기를 클릭하여 새 통합을 만듭니다.
새 통합을 만드는 경우:
- 통합 만들기 창에 이름과 설명을 입력합니다.
- 통합 리전을 선택합니다.
- 통합을 위한 서비스 계정을 선택합니다. 통합 툴바의 통합 요약 창에서 언제든지 통합에 대한 서비스 계정 세부정보를 변경하거나 업데이트할 수 있습니다.
- 만들기를 클릭합니다.
통합 편집기 페이지에서 통합이 열립니다.
- 통합 편집기 탐색 메뉴에서 태스크를 클릭하여 사용 가능한 태스크 및 커넥터 목록을 확인합니다.
- 데이터 매핑 요소를 클릭하고 통합 편집기에 배치합니다.
- 디자이너에서 데이터 매핑 요소를 클릭하여 데이터 매핑 태스크 구성 창을 봅니다.
-
데이터 매핑 편집기 열기를 클릭하여 태스크 기본값을 보고 새 매핑을 추가합니다.
매핑 추가에 대한 자세한 단계는 매핑 추가를 참조하세요.
데이터 매핑 편집기 레이아웃에 대한 자세한 내용은 데이터 매핑 개요를 참조하세요.
매핑 추가
매핑을 추가하려면 다음 단계를 수행합니다.
- 데이터 매핑 태스크 구성 창에서 데이터 매핑 편집기 열기를 클릭합니다.
- 매핑 입력 구성하기:
- 변수 목록에서 입력 행으로 변수 또는 하위 필드를 드래그합니다. 변수의 사용 가능한 하위 필드를 보려면 변수 목록에서 변수 옆의 (확장)을 클릭하세요.
- 또는, 입력 행에서 변수 또는 값을 클릭하도 다음을 수행하세요.
- 기존 변수를 검색하여 사용하려면 변수를 선택합니다. 새 변수를 만들려면 + 새 변수 추가를 클릭하여 새 변수의 이름과 데이터 유형을 입력합니다.
- 값을 선택하여
string,integer,double,Boolean유형의 리터럴 값을 입력합니다. - 기본 함수를 검색하여 사용하려면 함수를 선택합니다.
기본 함수는 통합 실행 중에 값을 검색하거나 생성하는 데 사용됩니다. 무작위 UUID를 생성하거나 현재 통합 리전을 검색하는 경우를 예로 들 수 있습니다. 지원되는 기본 함수에 대한 자세한 내용은 지원되는 기본 함수를 참조하세요.
- 저장을 클릭합니다.
- 입력 필드에서 입력 변수, 값 또는 기본 함수에 대한 + (함수 추가)를 클릭하여 사용 가능한 매핑 함수 목록에서 매핑 함수를 추가합니다. 매핑 함수에는 하나 이상의 매개변수가 있을 수 있습니다. 각 매개변수에는 값, 변수 또는 기본 함수 다음에 매핑 함수 체인이 있을 수 있습니다.
- 중첩 함수를 추가하려면 함수의 매개변수 옆에 있는 +(함수 추가)를 클릭합니다. 마찬가지로, 가장 최근에 추가된 함수를 삭제하려면 -(이전 함수 삭제)를 클릭합니다.
- 매핑 표현식 사이의 함수를 추가, 삭제, 변경하려면 함수를 클릭하고 드롭다운 메뉴에서 각기 함수 추가, 함수 삭제 또는 함수 변경을 선택합니다.
- 매핑 표현식 내에서 변수를 삭제하려면 변수 행 옆에 있는 (삭제)를 클릭합니다.
- 전체 입력 행을 삭제하려면 행에서 (지우기)를 클릭하세요.
매핑 함수에 대한 자세한 내용은 매핑 함수를 참조하세요.
지원되는 매핑 함수에 대한 자세한 내용은 지원되는 데이터 유형 및 매핑 함수를 참조하세요.
- 매핑 출력 구성하기:
- 변수 목록에서 변수를 출력 행으로 변수를 드래그합니다. 변수를 사용할 수 없으면 새 변수 만들기를 클릭하여 새 변수의 이름과 데이터 유형을 구성합니다. 필요에 따라 출력 변수를 클릭하여 해당 변수를 통합 출력으로 또는 다른 통합에 대한 입력으로 사용할지 여부를 선택할 수 있습니다.
- 변수를 삭제하려면 (지우기)를 클릭합니다.
- (선택사항) 매핑 행을 삭제하려면 (이 매핑 삭제)를 클릭합니다.
- 매핑이 완료되면 데이터 매핑 편집기를 닫습니다. 모든 변경사항이 자동 저장됩니다.
다음 이미지와 같이 데이터 매핑 태스크 구성 창에서 완료된 데이터 매핑을 볼 수 있습니다.
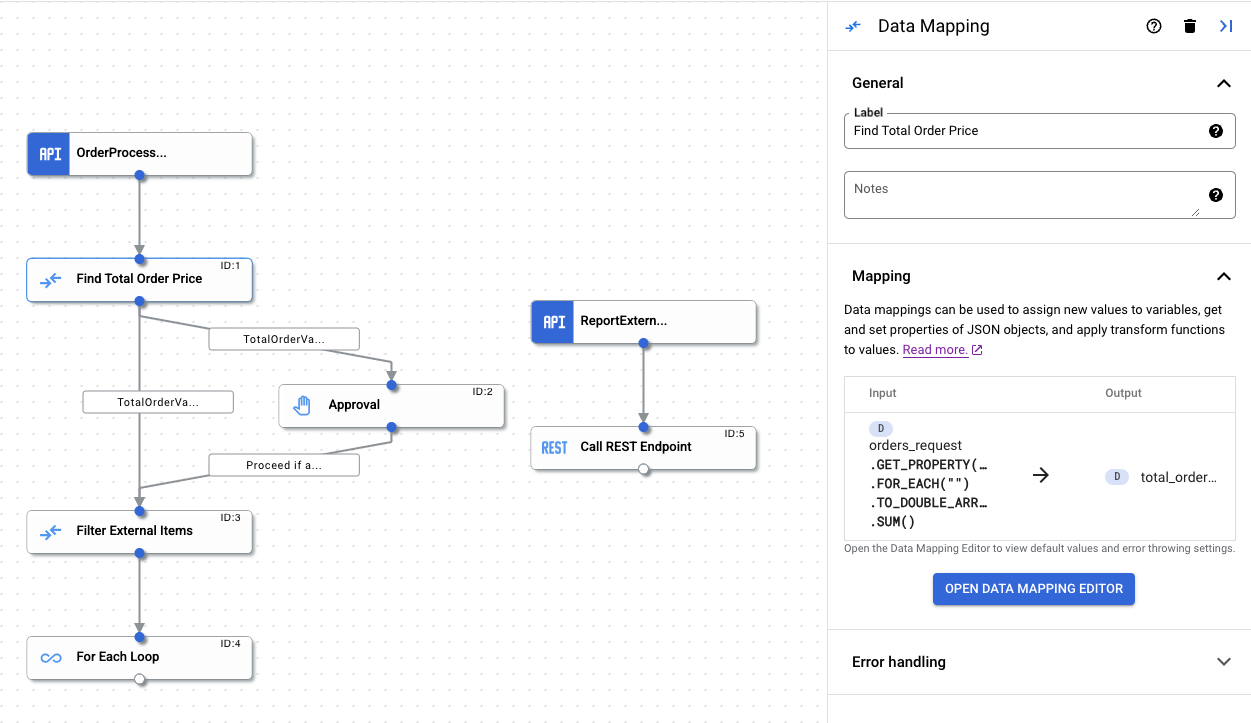
지원되는 데이터 유형 및 매핑 함수
Apigee Integration은 데이터 매핑 태스크의 변수에 다음 데이터 유형을 지원합니다.
- 문자열 및 문자열 배열
- 정수 및 정수 배열
- 실수 및 실수 배열
- 불리언 및 불리언 배열
- JSON
지원되는 기본 함수
다음 표에는 사용 가능한 데이터 매핑 기본 함수가 나와 있습니다.| 데이터 유형 | 지원되는 기본 함수 |
|---|---|
| 정수 | NOW_IN_MILLIS |
| 정수 배열 | INT_LIST |
| 문자열 | GENERATE_UUID, GET_EXECUTION_ID, GET_INTEGRATION_NAME, GET_INTEGRATION_REGION, GET_PROJECT_ID |
권장사항
데이터 매핑 태스크를 사용하면 주요 변수를 변환하여 통합의 다양한 태스크에 전달할 수 있습니다. 다음은 통합을 빌드할 때 몇 가지 유의사항입니다.
- 매핑은 위에서 아래 순서대로 실행됩니다. 즉, 입력 변수
A가 첫 번째 행의 출력 변수B에 매핑되면 후속 행에서 변수B를 매핑에 사용할 수 있습니다. - 각 행에서 입력 행의 데이터 유형은 출력 행의 데이터 유형과 일치해야 합니다.
유형 간에 캐스팅하려면
TO_STRING및TO_INT와 같은 변환 함수를 사용합니다. - 변환 체인 길이에는 제한이 없습니다. 그러나 대규모 체인 변환을 디버깅하기 어려울 수 있습니다. 입력 변환을 읽을 수 있게 유지하고 복잡한 변환을 여러 매핑으로 분할하는 것이 좋습니다.
- 매핑에 대체 값이 필요하면 매핑에 대체 값을 설정합니다. 대체 값을 제공하지 않으면 매핑은 입력 값이나 변환이
null을 반환할 때 오류를 반환합니다. - 변수를 삭제할 때는 변수가 포함된 모든 매핑을 삭제해야 합니다.
데이터 매핑 태스크에 적용되는 사용량 한도에 대한 자세한 내용은 사용량 한도를 참조하세요.
고려사항
JSON 변수의 경우 JSON 스키마를 기준으로 Application Integration은 변수의 하위 속성을 다음 사례의 JSON 유형으로 해석합니다.
- 하위 속성의 유형이 null을 지정하는 경우입니다. 예를 들면 다음과 같습니다.
{ "properties": { "PersonID": { "type": [ "double", "null" ], "readOnly": false } } }
- 하위 속성의 유형이 여러 데이터 유형을 지정하는 경우입니다. 예를 들면 다음과 같습니다.
{ "properties": { "PersonID": { "type": [ "integer", "string", "number" ], "readOnly": false } } }
이러한 경우 데이터 매핑 함수를 사용하여 하위 변수를 원하는 유형으로 명시적으로 변환해야 합니다.
다음 예시는 속성 선언에 대한 여러 유형을 설명하고 데이터 매핑 함수를 사용하여 원하는 유형을 가져오는 방법을 보여줍니다.
예 1
{ "type": "object", "properties": { "dbIntegers": { "type": "array", "items": { "type": [ "integer", "null" ] } }, "dbBooleans": { "type": [ "array" ], "items": { "type": "boolean" } } } }
dbIntegers를 JSON 유형으로 해석하고 dbBooleans을 BOOLEAN_ARRAY 유형으로 해석합니다.
dbIntegers를 변환하려면 다음을 사용합니다.
dbIntegers.TO_INT_ARRAY()
예 2
{ "type": "object", "properties": { "dbId": { "type": [ "number", "null" ], "readOnly": false }, "dbStatus": { "type": [ "boolean", "null" ], "readOnly": false } } }
dbId 및 dbStatus를 둘 다 JSON 유형으로 인식하지만 dbId는 단일 double 값 또는 null 값을 사용할 수 있는 매개변수이고, dbStatus는 단일 불리언 값 또는 null 값을 사용할 수 있는 매개변수입니다.
dbId 및 dbStatus를 변환하려면 다음을 사용합니다.
dbId.TO_DOUBLE()
dbStatus.TO_BOOLEAN()
예시 3
{ "type": "object", "properties": { "dbString": { "type": [ "string" ], "readOnly": false } } }
dbString을 문자열 유형으로 인식합니다.
오류 처리 전략
태스크의 오류 처리 전략은 일시적인 오류로 인해 태스크가 실패할 경우 수행할 태스크를 지정합니다. 오류 처리 전략을 사용하는 방법과 다양한 유형의 오류 처리 전략에 대한 자세한 내용은 오류 처리 전략을 참조하세요.
할당량 및 한도
할당량 및 한도에 대한 자세한 내용은 할당량 및 한도를 참조하세요.
다음 단계
- 모든 태스크 및 트리거 알아보기
- 데이터 매핑 태스크 함수 알아보기
- 통합을 테스트하고 게시하는 방법 알아보기
- 오류 처리 알아보기
- 통합 실행 로그 알아보기