查看 Application Integration 支援的連接器。
資料對應工作
資料對應工作可讓您在整合作業中執行變數指派、取得及設定 JSON 物件的屬性,並將巢狀轉換函式套用至值。變數可以是整合變數或工作變數。
舉例來說,您可以將整合變數 X 的值指派給工作變數 Y,或是將工作變數 Y 的值指派給整合變數 X。如要進一步瞭解應用程式整合中的變數,請參閱「 在應用程式整合中使用變數」。
設定資料對應工作
如要設定資料對應工作,請執行下列步驟:
- 前往 Google Cloud 控制台的「Application Integration」頁面。
- 在導覽選單中,按一下「整合」。
系統隨即會顯示「Integrations」頁面,列出 Google Cloud 專案中可用的所有整合功能。
- 選取現有的整合,或按一下「建立整合」來建立新的整合。
如果您要建立新的整合功能:
- 在「Create Integration」窗格中輸入名稱和說明。
- 選取整合作業的區域。
- 選取要用於整合的服務帳戶。您隨時可以透過整合工具列中的 「整合摘要」窗格,變更或更新整合作業的服務帳戶詳細資料。
- 按一下「建立」,新建立的整合服務會在整合服務編輯器中開啟。
- 在整合編輯器的導覽列中,按一下「Tasks」,即可查看可用任務和連接器清單。
- 在整合服務編輯器中按一下並放置「Data Mapping」(資料對應) 元素。
- 按一下設計工具中的「Data Mapping」元素,即可查看「Data Mapping」任務設定窗格。
-
按一下「Open Data Mapping Editor」,即可查看任務的預設值,並新增對應。
如要進一步瞭解如何新增對應項目,請參閱「新增對應項目」。
如要進一步瞭解資料對應編輯器版面配置,請參閱「 資料對應總覽」。
新增對應關係
如要新增對應項目,請執行下列步驟:
- 在「資料對應」工作設定窗格中,按一下「開啟資料對應編輯器」。
- 設定對應的「輸入」:
- 將變數或其子欄位從「變數」清單拖曳到「輸入」列。如要查看變數的可用子欄位,請在「變數」清單中,按一下該變數旁的 「展開」。
- 或者,在「輸入」列中,按一下「變數或值」,然後執行下列操作:
- 選取「變數」,即可搜尋及使用現有變數。 如要建立新變數,請按一下「+ 新增變數」,然後輸入新變數的名稱和資料類型。
- 選取「值」即可輸入
string、integer、double或Boolean類型的值。 - 選取「函式」,即可搜尋及使用基本函式。
在執行整合時,您可以使用基本函式擷取或產生值。例如產生隨機 UUID 或擷取目前的整合區域。如要瞭解支援的基本函式,請參閱「 支援的基本函式」。
- 按一下 [儲存]。
- 在「輸入」列的任何輸入變數、值或基本函式上按一下「+」(新增函式),即可從可用的對應函式清單中新增對應函式。對應函式可以有一或多個參數。每個參數還可以包含值、變數或基本函式,後面接著一連串對應函式。
- 如要新增巢狀函式,請按一下函式參數旁邊的「+ (新增函式)」。同樣地,如要移除或刪除最近新增的函式,請按一下「- (刪除上一個函式)」。
- 如要在對應運算式中新增、移除或變更函式,請按一下函式,然後在下拉式選單中分別選取「Add Function」、「Remove Function」或「Change Function」。
- 如要移除對應運算式中的變數,請按一下變數列旁的 「移除」圖示。
- 如要移除整個「輸入」列,請按一下該列的 「清除」。
如要進一步瞭解對應函式,請參閱「對應函式」。
如要瞭解支援的對應函式,請參閱「 支援的資料類型和對應函式」。
- 設定對應的「輸出」:
- 將「變數」清單中的變數拖曳到「輸出」列。如果變數無法使用,請按一下「建立新變數」,設定新變數的名稱和資料類型。您可以視需要按一下輸出變數,然後選取要將該變數用於整合作業的輸出內容,還是用於其他整合作業的輸入內容。
- 如要移除輸出變數,請按一下 「清除」。
- (選用) 如要刪除對應資料列,請按一下 「(刪除此對應)」。
- 對應完成後,請關閉資料對應編輯器。系統會自動儲存所有變更。
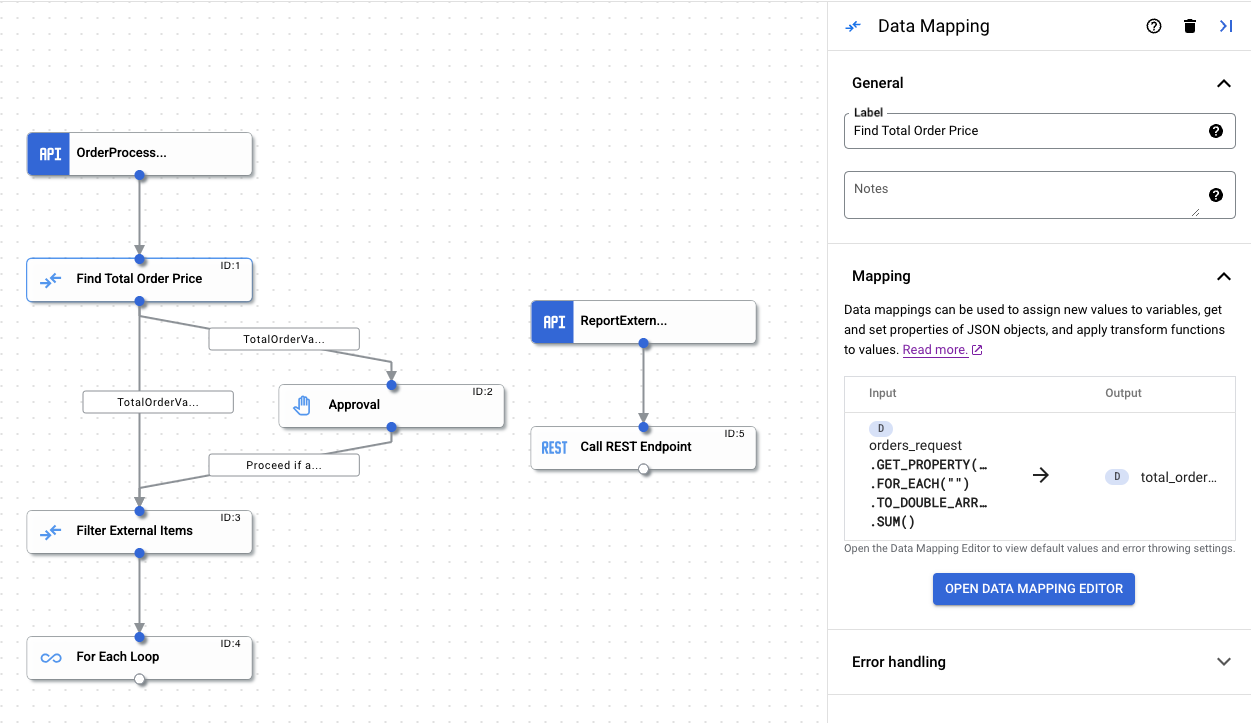
您可以透過「資料對應」任務設定窗格查看完成的資料對應,如下圖所示:
支援的資料類型和對應函式
應用程式整合功能支援下列資料類型,用於資料對應工作中的變數:
- 字串和字串陣列
- 整數和整數陣列
- 雙項與雙項陣列
- 布林值和布林值陣列
- JSON
支援的基本函式
下表列出可用的資料對應基礎函式:| 資料類型 | 支援的基本函式 |
|---|---|
| 整數 | NOW_IN_MILLIS |
| 整數陣列 | INT_LIST |
| 字串 | GENERATE_UUID、GET_EXECUTION_ID、GET_INTEGRATION_NAME、GET_INTEGRATION_REGION、GET_PROJECT_ID |
最佳做法
使用「資料對應」工作是轉換及傳遞整合作業中各項任務的關鍵變數的強大方法。以下是建構整合時應留意的幾個提示:
- 對應項目會依序由上到下執行。也就是說,如果輸入變數
A對應至第一列中的輸出變數B,則變數B可用於後續列的對應。 - 在每個資料列中,輸入資料列的資料類型必須與輸出資料列的資料類型相符。
如要將值轉換為不同類型,請使用轉換函式,例如
TO_STRING和TO_INT。 - 轉換鏈結的長度沒有限制。不過,對大型鏈結轉換進行除錯可能相當困難。建議您讓輸入轉換作業易於閱讀,並將複雜的轉換作業分割成多個對應項目。
- 如果對應項目需要備用值,請為對應項目設定備用值。如果您未提供備用值,當輸入值或轉換作業傳回
null時,對應作業就會傳回錯誤。 - 刪除變數時,請務必刪除其中包含的所有對應項目。
如要瞭解適用於資料對應任務的用量限制,請參閱「 用量限制」一文。
注意事項
針對 JSON 變數,如果是根據 JSON 結構定義,應用程式整合會在下列情況下將變數的子屬性解讀為 JSON 類型:
- 如果子項屬性指定為空值。例如:
{ "properties": { "PersonID": { "type": [ "double", "null" ], "readOnly": false } } }
- 如果子資源的類型指定多個資料類型,例如:
{ "properties": { "PersonID": { "type": [ "integer", "string", "number" ], "readOnly": false } } }
在這些情況下,您必須使用資料對應函式,明確將子變數轉換為所需類型。
以下範例說明各種屬性宣告類型,並說明如何使用資料對應函式取得所需類型:
範例 1
{ "type": "object", "properties": { "dbIntegers": { "type": "array", "items": { "type": [ "integer", "null" ] } }, "dbBooleans": { "type": [ "array" ], "items": { "type": "boolean" } } } }
dbIntegers 解讀為 JSON 類型,將 dbBooleans 解讀為 BOOLEAN_ARRAY 類型。
如要轉換 dbIntegers,請使用:
dbIntegers.TO_INT_ARRAY()
範例 2
{ "type": "object", "properties": { "dbId": { "type": [ "number", "null" ], "readOnly": false }, "dbStatus": { "type": [ "boolean", "null" ], "readOnly": false } } }
dbId 和 dbStatus 都視為 JSON 類型,但 dbId 是可接受單一雙精度值或空值的參數,而 dbStatus 則是可接受單一布林值或空值的參數。
如要轉換 dbId 和 dbStatus 使用方式,請按照下列步驟操作:
dbId.TO_DOUBLE()
dbStatus.TO_BOOLEAN()
範例 3
{ "type": "object", "properties": { "dbString": { "type": [ "string" ], "readOnly": false } } }
dbString 視為字串類型。錯誤處理策略
工作錯誤處理策略會指定在工作因暫時性錯誤而失敗時,應採取的動作。如要瞭解如何使用錯誤處理策略,以及各種錯誤處理策略,請參閱「錯誤處理策略」。
配額與限制
如要進一步瞭解配額和限制,請參閱「配額與限制」。