Google Distributed Cloud (solo software) per bare metal supporta più opzioni per il logging e il monitoraggio dei cluster, tra cui servizi gestiti basati sul cloud, strumenti open source e compatibilità con soluzioni commerciali di terze parti convalidate. Questa pagina spiega queste opzioni e fornisce indicazioni di base per la scelta della soluzione giusta per il tuo ambiente.
Questa pagina è rivolta ad amministratori, architetti e operatori che vogliono monitorare l'integrità di applicazioni o servizi di cui è stato eseguito il deployment, ad esempio per la conformità all'obiettivo del livello di servizio (SLO). Per scoprire di più sui ruoli comuni e sulle attività di esempio a cui viene fatto riferimento nei contenuti di Google Cloud , consulta Ruoli e attività utente GKE comuni.
Opzioni per Google Distributed Cloud
Hai a disposizione diverse opzioni di logging e monitoraggio per il tuo cluster:
- Cloud Logging e Cloud Monitoring, abilitati per impostazione predefinita sui componenti di sistema bare metal.
- Prometheus e Grafana sono disponibili in Cloud Marketplace.
- Configurazioni convalidate con soluzioni di terze parti.
Cloud Logging e Cloud Monitoring
Google Cloud Observability è la soluzione di osservabilità integrata per Google Cloud. Offre una soluzione di logging, raccolta di metriche, monitoraggio, dashboard e avvisi completamente gestita. Cloud Monitoring monitora i cluster Google Distributed Cloud in modo simile ai cluster GKE basati sul cloud.
Cloud Logging e Cloud Monitoring sono abilitati per impostazione predefinita quando crei cluster con i service account e i ruoli Identity and Access Management (IAM) richiesti. Non puoi disattivare Cloud Logging e Cloud Monitoring. Per ulteriori informazioni sui service account e sui ruoli richiesti, vedi Configurare i service account.
Gli agenti possono essere configurati per modificare quanto segue:
- Ambito di logging e monitoraggio, dai soli componenti di sistema (impostazione predefinita) a componenti di sistema e applicazioni.
- Livello di metriche raccolte, da un solo insieme ottimizzato di metriche (il valore predefinito) a tutte le metriche.
Per saperne di più, consulta la sezione Configurazione degli agenti Stackdriver per Google Distributed Cloud in questo documento.
Logging e Monitoring forniscono un'unica soluzione di osservabilità basata su cloud, potente e facile da configurare. Ti consigliamo vivamente Logging e Monitoring quando esegui i workload su Google Distributed Cloud. Per le applicazioni con componenti in esecuzione su Google Distributed Cloud e infrastruttura on-premise standard, potresti prendere in considerazione altre soluzioni per una visualizzazione end-to-end di queste applicazioni.
Per informazioni dettagliate su architettura, configurazione e quali dati vengono replicati nel tuo progetto Google Cloud per impostazione predefinita, consulta Come funziona Logging e Monitoring per Google Distributed Cloud.
Per saperne di più su Logging, consulta la documentazione di Cloud Logging.
Per saperne di più su Monitoring, consulta la documentazione di Cloud Monitoring.
Per scoprire come visualizzare e utilizzare le metriche di utilizzo delle risorse di Cloud Monitoring da Google Distributed Cloud a livello di parco risorse, consulta Utilizzare la panoramica di Google Kubernetes Engine.
Prometheus e Grafana
Prometheus e Grafana sono due prodotti di monitoraggio open source molto diffusi disponibili in Cloud Marketplace:
Prometheus raccoglie metriche di sistema e delle applicazioni.
Alertmanager gestisce l'invio di avvisi con diversi meccanismi di avviso.
Grafana è uno strumento per la creazione di dashboard.
Ti consigliamo di utilizzare Google Cloud Managed Service per Prometheus, che si basa su Cloud Monitoring, per tutte le tue esigenze di monitoraggio. Con Google Cloud Managed Service per Prometheus puoi monitorare i componenti di sistema senza costi. Google Cloud Managed Service per Prometheus è compatibile anche con Grafana. Tuttavia, se preferisci un sistema di monitoraggio locale puro, puoi scegliere di installare Prometheus e Grafana nei tuoi cluster.
Se hai installato Prometheus localmente e vuoi raccogliere metriche dai componenti di sistema, devi concedere all'istanza Prometheus locale l'autorizzazione per accedere agli endpoint delle metriche dei componenti di sistema:
Collega il account di servizio per l'istanza Prometheus al ClusterRole
gke-metrics-agentpredefinito e utilizza il token account di servizio come credenziale per eseguire lo scraping delle metriche dai seguenti componenti di sistema:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
Utilizza la chiave e il certificato del client archiviati nel secret
kube-system/stackdriver-prometheus-etcd-scrapeper autenticare lo scraping delle metriche da etcd.Crea una NetworkPolicy per consentire l'accesso dallo spazio dei nomi a kube-state-metrics.
Soluzioni di terze parti
Google ha collaborato con diversi fornitori di soluzioni di logging e monitoraggio di terze parti per fare in modo che i loro prodotti funzionino bene con Google Distributed Cloud. Questi includono Datadog, Elastic e Splunk. In futuro verranno aggiunte altre terze parti convalidate.
Sono disponibili le seguenti guide alle soluzioni per l'utilizzo di soluzioni di terze parti con Google Distributed Cloud:
- Monitoraggio di Google Distributed Cloud con Elastic Stack
- Raccogli i log su Google Distributed Cloud con Splunk Connect
Come funziona il logging e il monitoraggio per Google Distributed Cloud
Cloud Logging e Cloud Monitoring vengono installati e attivati in ogni cluster quando crei un nuovo cluster amministratore o utente.
Gli agenti Stackdriver includono diversi componenti su ogni cluster:
Stackdriver Operator (
stackdriver-operator-*). Gestisce il ciclo di vita di tutti gli altri agenti Stackdriver di cui è stato eseguito il deployment sul cluster.Risorsa personalizzata Stackdriver. Una risorsa creata automaticamente nell'ambito della procedura di installazione di Google Distributed Cloud.
Agente metriche GKE (
gke-metrics-agent-*). Un DaemonSet basato su OpenTelemetry Collector che recupera le metriche da ogni nodo a Cloud Monitoring. Sono inclusi anche un DaemonSetnode-exportere un deploymentkube-state-metricsper fornire ulteriori metriche sul cluster.Stackdriver Log Forwarder (
stackdriver-log-forwarder-*). Un DaemonSet Fluent Bit che inoltra i log da ogni macchina a Cloud Logging. Log Forwarder memorizza nel buffer le voci di log sul nodo localmente e le invia di nuovo per un massimo di 4 ore. Se il buffer si riempie o se Log Forwarder non riesce a raggiungere l'API Cloud Logging per più di 4 ore, i log vengono eliminati.Agente metadati (
stackdriver-metadata-agent-). Un deployment che invia metadati per risorse Kubernetes come pod, deployment o nodi all'API Config Monitoring for Ops. L'aggiunta di metadati consente di eseguire query sui dati delle metriche in base al nome del deployment, al nome del nodo o persino al nome del servizio Kubernetes.
Puoi visualizzare gli agenti installati da Stackdriver eseguendo questo comando:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
L'output di questo comando è simile al seguente:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Metriche di Cloud Monitoring
Per un elenco delle metriche raccolte da Cloud Monitoring, consulta Visualizzare le metriche di Google Distributed Cloud.
Configurazione degli agenti Stackdriver per Google Distributed Cloud
Gli agenti Stackdriver installati con Google Distributed Cloud raccolgono dati sui componenti di sistema per la manutenzione e la risoluzione dei problemi dei tuoi cluster. Le sezioni seguenti descrivono la configurazione e le modalità operative di Stackdriver.
Solo componenti del sistema (modalità predefinita)
Al momento dell'installazione, gli agent Stackdriver sono configurati per impostazione predefinita per raccogliere log e metriche, inclusi i dettagli sulle prestazioni (ad esempio, utilizzo di CPU e memoria) e metadati simili, per i componenti di sistema forniti da Google. Questi includono tutti i carichi di lavoro nel cluster di amministrazione e, per i cluster utente, i carichi di lavoro negli spazi dei nomi kube-system, gke-system, gke-connect, istio-system e config-management- system.
Componenti e applicazioni di sistema
Per attivare il logging e il monitoraggio delle applicazioni in aggiunta alla modalità predefinita, segui i passaggi descritti in Abilitazione di Logging e Monitoring per le applicazioni.
Metriche ottimizzate (metriche predefinite)
Per impostazione predefinita, i deployment kube-state-metrics in esecuzione nel cluster raccolgono e segnalano un insieme ottimizzato di metriche kube a Google Cloud Observability (in precedenza Stackdriver).
Per raccogliere questo set ottimizzato di metriche sono necessarie meno risorse, il che migliora le prestazioni e la scalabilità complessive.
Per disabilitare le metriche ottimizzate (non consigliato), sostituisci l'impostazione predefinita nella risorsa personalizzata Stackdriver.
Utilizza Google Cloud Managed Service per Prometheus per i componenti di sistema selezionati
Google Cloud Managed Service per Prometheus fa parte di Cloud Monitoring ed è disponibile come opzione per i componenti di sistema. I vantaggi di Google Cloud Managed Service per Prometheus includono quanto segue:
Puoi continuare a utilizzare il monitoraggio esistente basato su Prometheus senza modificare gli avvisi e le dashboard di Grafana.
Se utilizzi sia GKE che Google Distributed Cloud, puoi utilizzare lo stesso Prometheus Query Language (PromQL) per le metriche su tutti i tuoi cluster. Puoi anche utilizzare la scheda PromQL in Esplora metriche nella console Google Cloud .
Abilitare e disabilitare Google Cloud Managed Service per Prometheus
A partire dalla release 1.30.0-gke.1930 di Google Distributed Cloud,
Google Cloud Managed Service per Prometheus è sempre abilitato. Nelle versioni precedenti, puoi modificare la risorsa Stackdriver, stackdriver, per abilitare o disabilitare Google Cloud Managed Service per Prometheus. Per disattivare Google Cloud Managed Service per Prometheus
per le versioni del cluster precedenti alla 1.30.0-gke.1930, imposta
spec.featureGates.enableGMPForSystemMetrics nella risorsa stackdriver su
false.
Visualizzare i dati delle metriche
Quando enableGMPForSystemMetrics è impostato su true, le metriche per i seguenti componenti hanno un formato diverso per la modalità di archiviazione e query in Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet e cadvisor
- kube-state-metrics
- node-exporter
Nel nuovo formato, puoi eseguire query sulle metriche precedenti utilizzando Prometheus Query Language (PromQL).
Query PromQL di esempio:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Configurazione dei dashboard Grafana con Google Cloud Managed Service per Prometheus
Per utilizzare Grafana con i dati delle metriche di Google Cloud Managed Service per Prometheus, devi prima configurare e autenticare l'origine dati Grafana. Per configurare e autenticare l'origine dati, utilizza lo strumento di sincronizzazione dell'origine dati (datasource-syncer) per generare le credenziali OAuth2 e sincronizzarle con Grafana tramite l'API dell'origine dati di Grafana. Il sincronizzatore dell'origine dati imposta l'API Cloud Monitoring come URL del server Prometheus (il valore dell'URL inizia con https://monitoring.googleapis.com) nell'origine dati in Grafana.
Segui i passaggi descritti in Query utilizzando Grafana per autenticare e configurare un'origine dati Grafana per eseguire query sui dati da Google Cloud Managed Service per Prometheus.
Un insieme di dashboard Grafana di esempio è fornito nel repository anthos-samples su GitHub. Per installare le dashboard di esempio:
Scarica i file JSON di esempio:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Se l'origine dati Grafana è stata creata con un nome diverso da
Managed Service for Prometheus, modifica il campodatasourcein tutti i file JSON:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Sostituisci [DATASOURCE_NAME] con il nome dell'origine dati in Grafana che puntava al servizio Prometheus
frontend.Accedi all'interfaccia utente di Grafana dal browser e seleziona + Importa nel menu Dashboard.
Carica il file JSON oppure copia e incolla i contenuti del file e seleziona Carica. Una volta caricato correttamente il contenuto del file, seleziona Importa. Se vuoi, puoi anche modificare il nome e l'UID del dashboard prima dell'importazione.
Il caricamento del dashboard importato dovrebbe avvenire correttamente se Google Distributed Cloud e l'origine dati sono configurati correttamente. Ad esempio, lo screenshot seguente mostra la dashboard configurata da
cluster-capacity.json.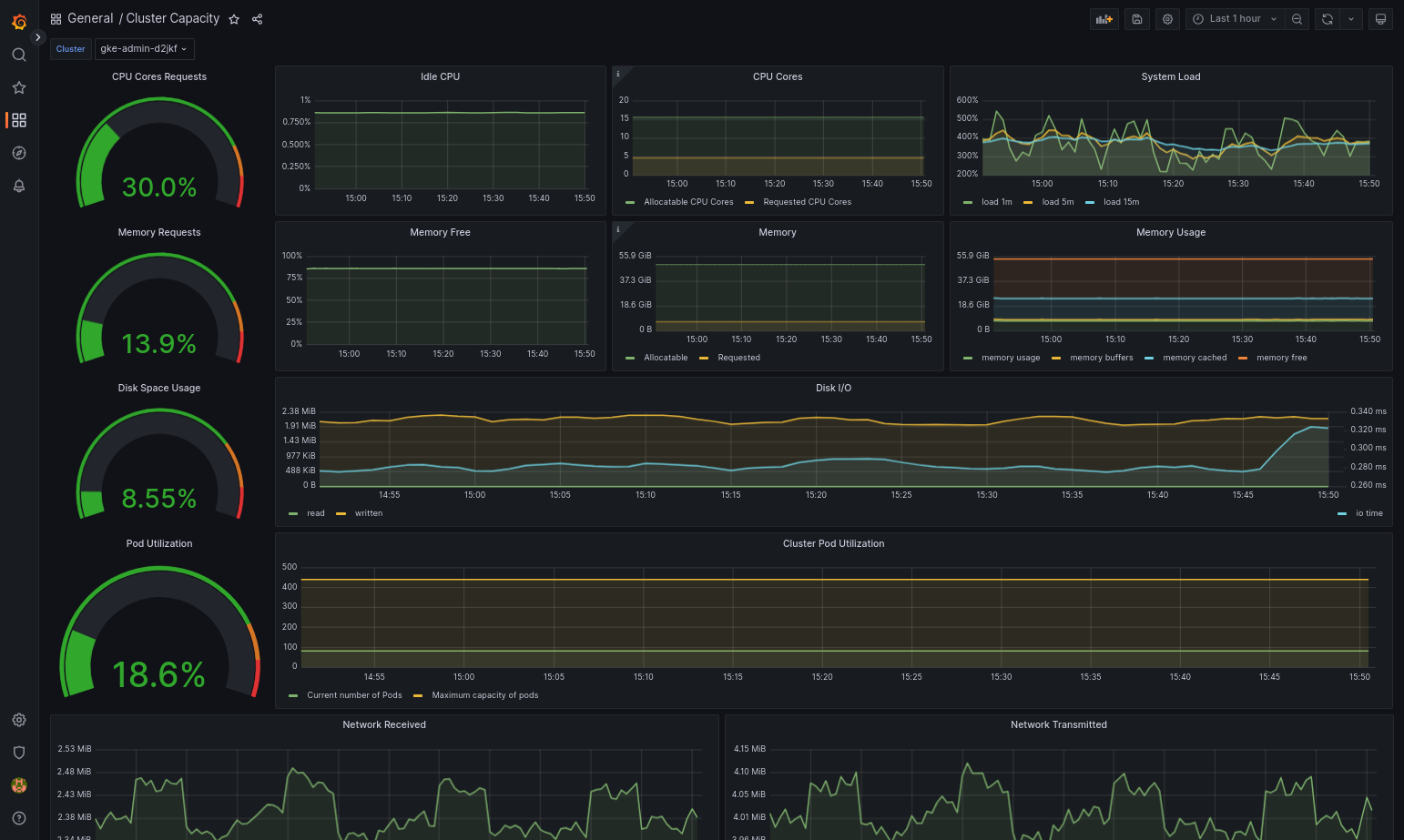
Risorse aggiuntive
Per ulteriori informazioni su Google Cloud Managed Service per Prometheus, consulta le seguenti risorse:
Configurazione delle risorse dei componenti Stackdriver
Quando crei un cluster, Google Distributed Cloud crea automaticamente una risorsa personalizzata Stackdriver. Puoi modificare la specifica nella risorsa personalizzata per eseguire l'override dei valori predefiniti per le richieste e i limiti di CPU e memoria per un componente Stackdriver e puoi eseguire l'override separato dell'impostazione predefinita delle metriche ottimizzate.
Eseguire l'override delle richieste e dei limiti predefiniti di CPU e memoria per un componente Stackdriver
I cluster con un'alta densità di pod introducono un overhead maggiore per logging e monitoraggio. In casi estremi, i componenti di Stackdriver potrebbero segnalare un utilizzo della CPU e della memoria vicino al limite o potrebbero essere soggetti a riavvii costanti a causa dei limiti delle risorse. In questo caso, per sostituire i valori predefiniti per le richieste e i limiti di CPU e memoria per un componente Stackdriver, segui questi passaggi:
Esegui questo comando per aprire la risorsa personalizzata Stackdriver in un editor della riga di comando:
kubectl -n kube-system edit stackdriver stackdriver
Nella risorsa personalizzata Stackdriver, aggiungi la sezione
resourceAttrOverridesotto il campospec:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYTieni presente che la sezione
resourceAttrOverridesostituisce tutti i limiti e le richieste predefiniti esistenti per il componente specificato. I seguenti componenti sono supportati daresourceAttrOverride:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Un file di esempio ha il seguente aspetto:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiPer salvare le modifiche alla risorsa personalizzata Stackdriver, salva e chiudi l'editor della riga di comando.
Controlla lo stato del tuo pod:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Una risposta per un pod integro è simile alla seguente:
gke-metrics-agent-4th8r 1/1 Running 1 40h
Controlla la specifica del pod del componente per assicurarti che le risorse siano impostate correttamente.
kubectl -n kube-system describe pod POD_NAME
Sostituisci
POD_NAMEcon il nome del pod che hai appena modificato. Ad esempio,gke-metrics-agent-4th8r.La risposta è simile alla seguente:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Disattivare le metriche ottimizzate
Per impostazione predefinita, i deployment kube-state-metrics in esecuzione nel cluster raccolgono e segnalano a Stackdriver un insieme ottimizzato di metriche kube. Se hai bisogno di metriche aggiuntive,
ti consigliamo di trovare una sostituzione nell'elenco delle metriche di Google Distributed Cloud.
Ecco alcuni esempi di sostituzioni che potresti utilizzare:
| Metrica disabilitata | Sostituzioni |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Per disattivare l'impostazione predefinita delle metriche ottimizzate (non consigliata):
Apri la risorsa personalizzata Stackdriver in un editor della riga di comando:
kubectl -n kube-system edit stackdriver stackdriver
Imposta il campo
optimizedMetricssufalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Salva le modifiche e chiudi l'editor della riga di comando.
Server delle metriche
Metrics Server è l'origine delle metriche delle risorse dei container per varie pipeline di scalabilità automatica. Metrics Server recupera le metriche dai kubelet e le espone tramite l'API Kubernetes Metrics. HPA e VPA utilizzano queste metriche per determinare quando attivare la scalabilità automatica. Il server delle metriche viene scalato utilizzando addon-resizer.
In casi estremi in cui l'elevata densità di pod crea un sovraccarico eccessivo di logging e monitoraggio, Metrics Server potrebbe essere arrestato e riavviato a causa di limitazioni delle risorse. In questo caso, puoi allocare più risorse al server delle metriche modificando
il configmap metrics-server-config nello spazio dei nomi gke-managed-metrics-server
e modificando il valore di cpuPerNode e memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
I contenuti di esempio di ConfigMap sono:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Dopo aver aggiornato ConfigMap, ricrea i pod metrics-server con il seguente comando:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Routing di log e metriche
Stackdriver log forwarder (stackdriver-log-forwarder) invia i log da ogni
macchina nodo a Cloud Logging. Analogamente, l'agente delle metriche GKE
(gke-metrics-agent) invia le metriche da ogni macchina nodo a
Cloud Monitoring. Prima dell'invio di log e metriche, l'operatore Stackdriver (stackdriver-operator) associa il valore del campo clusterLocation nella risorsa personalizzata stackdriver a ogni voce di log e metrica prima che vengano indirizzate a Google Cloud. Inoltre, i log e le metriche sono
associati al Google Cloud progetto
specificato nella stackdriver specifica della risorsa personalizzata (spec.projectID).
La risorsa stackdriver riceve i valori per i campi clusterLocation e projectID
dai campi
location
e
projectID
nella sezione clusterOperations della risorsa Cluster al momento della creazione del cluster.
Tutte le metriche e le voci di log inviate dagli agenti Stackdriver vengono indirizzate a un endpoint di importazione globale. Da qui, i dati vengono inoltrati all'endpoint Google Cloud regionale raggiungibile più vicino per garantire l'affidabilità del trasporto dei dati.
Una volta che l'endpoint globale riceve la metrica o la voce di log, ciò che accade dopo dipende dal servizio:
Come viene configurato il routing dei log: quando l'endpoint di logging riceve un messaggio di log, Cloud Logging lo passa al router di log. I sink e i filtri nella configurazione del router dei log determinano come instradare il messaggio. Puoi indirizzare le voci di log a destinazioni come i bucket Logging regionali, che archiviano la voce di log, o a Pub/Sub. Per ulteriori informazioni sul funzionamento del routing dei log e su come configurarlo, consulta la panoramica su routing e archiviazione.
Né il campo
clusterLocationnella risorsa personalizzatastackdriverné il campoclusterOperations.locationnella specifica del cluster vengono presi in considerazione in questo processo di routing. Per i log,clusterLocationviene utilizzato solo per etichettare le voci di log, il che può essere utile per il filtraggio in Esplora log.Come viene configurato il routing delle metriche: quando l'endpoint delle metriche riceve una voce di metrica, questa viene indirizzata automaticamente per essere archiviata nella posizione specificata dalla metrica. La località nella metrica proviene dal campo
clusterLocationnella risorsa personalizzatastackdriver.Pianifica la configurazione: quando configuri Cloud Logging e Cloud Monitoring, configura il router dei log e specifica un
clusterOperations.locationappropriato con le località che meglio supportano le tue esigenze. Ad esempio, se vuoi che i log e le metriche vengano inviati alla stessa posizione, impostaclusterOperations.locationsulla stessa Google Cloud regione che Log Router utilizza per il tuo Google Cloud progetto.Aggiorna la configurazione dei log quando necessario: puoi apportare modifiche in qualsiasi momento alle impostazioni di destinazione dei log a causa di requisiti aziendali, ad esempio piani di ripristino di emergenza. Le modifiche alla configurazione di Log Router in Google Cloud hanno effetto rapidamente. I campi
locationeprojectIDnella sezioneclusterOperationsdella risorsa cluster sono immutabili, pertanto non possono essere aggiornati dopo la creazione del cluster. Non ti consigliamo di modificare direttamente i valori nella risorsastackdriver. Questa risorsa viene ripristinata allo stato di creazione del cluster originale ogni volta che un'operazione del cluster, ad esempio un upgrade, attiva una riconciliazione.
Requisiti di configurazione per Logging e Monitoring
Esistono diversi requisiti di configurazione per abilitare Cloud Logging e Cloud Monitoring con Google Distributed Cloud. Questi passaggi sono inclusi nella sezione Configurazione di un account di servizio da utilizzare con Logging e Monitoring nella pagina Attivazione dei servizi Google e nel seguente elenco:
- È necessario creare un workspace Cloud Monitoring all'interno del progettoGoogle Cloud . Per farlo, fai clic su Monitoraggio nella consoleGoogle Cloud e segui il flusso di lavoro.
Devi abilitare le seguenti API Stackdriver:
Devi assegnare i seguenti ruoli IAM al service account utilizzato dagli agenti Stackdriver:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Tag log
Molti log di Google Distributed Cloud hanno un tag F:
logtag: "F"
Questo tag indica che la voce di log è completa o full. Per saperne di più su questo tag, consulta Formato log nelle proposte di progettazione di Kubernetes su GitHub.
Prezzi
In un cluster Google Distributed Cloud, i log e le metriche di sistema includono:
- Log e metriche di tutti i componenti in un cluster di amministrazione.
- Log e metriche dei componenti nei seguenti spazi dei nomi di un cluster utente:
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-system,cnrm-system.
Per ulteriori informazioni, consulta la pagina Prezzi di Google Cloud Observability.
Per informazioni sul credito per le metriche di Cloud Logging, contatta il team di vendita per i prezzi.