Cette page explique comment utiliser le tableau de bord Insights sur les requêtes pour détecter et analyser les problèmes de performances. Pour obtenir un aperçu de cette fonctionnalité, consultez Présentation de Query Insights.
Vous pouvez utiliser Gemini Cloud Assist pour vous aider à surveiller et à résoudre les problèmes liés à vos ressources AlloyDB. Pour en savoir plus, consultez Surveiller et résoudre les problèmes avec l'aide de Gemini.
Avant de commencer
Si vous ou d'autres utilisateurs devez afficher le plan de requête ou effectuer un traçage de bout en bout, vous devez disposer d'autorisations IAM (Identity and Access Management) spécifiques. Vous pouvez créer un rôle personnalisé et lui attribuer les autorisations IAM nécessaires. Vous pouvez ensuite ajouter ce rôle à tous les comptes utilisateur qui utilisent Insights sur les requêtes pour résoudre des problèmes. Pour en savoir plus, consultez Créer des rôles d'administrateur personnalisés.
Le rôle personnalisé doit disposer de l'autorisation IAM suivante : cloudtrace.traces.get.
Ouvrir le tableau de bord "Insights sur les requêtes"
Pour ouvrir le tableau de bord Insights sur les requêtes, procédez comme suit :
- Dans la liste des clusters et des instances, cliquez sur une instance.
- Cliquez sur Consulter la page "Insights sur les requêtes" pour obtenir des informations plus détaillées sur les requêtes et les performances sous le graphique des métriques sur la page "Vue d'ensemble" du cluster ou sélectionnez l'onglet Insights sur les requêtes dans le panneau de navigation de gauche.
Sur la page suivante, vous pouvez utiliser les options suivantes pour filtrer les résultats :
- Sélecteur d'instances : Vous permet de sélectionner l'instance principale ou les instances du pool de lecture dans le cluster. Par défaut, l'instance principale est sélectionnée. Les détails affichés sont agrégés pour toutes les instances de pool de lecture connectées et leurs nœuds.
- Base de données : Filtre la charge de requête sur une base de données spécifique ou sur toutes les bases de données.
- Utilisateur : Filtre la charge de requête à partir de comptes utilisateur spécifiques.
- Adresse du client : Filtre la charge de requête à partir d'une adresse IP spécifique.
- Période : Filtre la charge de requête par périodes, mesurées en heures, jours, semaines ou autre plage personnalisée.
Modifier la configuration des insights sur les requêtes
Les insights sur les requêtes sont activés par défaut sur les instances AlloyDB. Vous pouvez modifier la configuration par défaut des insights sur les requêtes.
Pour modifier la configuration des insights sur les requêtes pour une instance AlloyDB, procédez comme suit :
Console
Dans la console Google Cloud , accédez à la page Clusters.
Cliquez sur un cluster dans la colonne Nom de la ressource.
Cliquez sur Insights sur les requêtes dans le panneau de navigation de gauche.
Sélectionnez Principal ou Pool de lecture dans la liste Insights sur les requêtes, puis cliquez sur Modifier.
Modifiez les champs Insights sur les requêtes :
Pour modifier la limite par défaut de 1 024 octets sur la longueur des requêtes qu'AlloyDB peut analyser, saisissez un nombre compris entre 256 et 4 500 dans le champ Longueur des requêtes.
L'instance redémarre après la modification de ce champ.
Remarque : Des limites de longueur de requête plus élevées nécessitent davantage de mémoire.
Pour personnaliser les ensembles de fonctionnalités dédiées aux insights sur les requêtes, ajustez les options suivantes :
Échantillonnage du plan de requête : cochez cette case pour visualiser les opérations utilisées pour effectuer un échantillon d'une requête. Le taux d'échantillonnage détermine le nombre maximal de requêtes qu'AlloyDB peut échantillonner par minute pour l'instance et par nœud.
Dans le champ Taux d'échantillonnage maximal, saisissez un nombre compris entre 1 et 20. Par défaut, le taux d'échantillonnage est défini sur 5. Pour désactiver l'échantillonnage, décochez la case Échantillonnage du plan de requête.
Stocker les adresses IP clientes : cochez cette case pour savoir d'où proviennent vos requêtes et regrouper ces informations pour en extraire des métriques.
Stocker les tags d'application : cochez cette case pour savoir quelles applications taguées émettent des requêtes et pour regrouper ces informations afin d'exécuter des métriques. Pour en savoir plus sur les tags d'application, consultez la spécification.
Cliquez sur Mettre à jour l'instance.
gcloud
Pour activer Insights sur les requêtes pour une instance AlloyDB à l'aide des commandes Google Cloud CLI, procédez comme suit :
- Installez la Google Cloud CLI.
- Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init
Si vous utilisez un shell local, créez des identifiants d'authentification locaux pour votre compte utilisateur :
gcloud auth application-default login
Vous n'avez pas besoin de le faire si vous utilisez Cloud Shell.
Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Exemple :
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-addressRemplacez les éléments suivants :
INSTANCE: ID de l'instance à mettre à jourCLUSTER: ID du cluster de l'instancePROJECT: ID du projet du clusterREGION: région du cluster, par exempleus-central1QUERY_LENGTH: longueur de la requête, comprise entre 256 et 4 500QUERY_PLANS: nombre de plans de requête à configurer par minute.
De plus, utilisez une ou plusieurs des options facultatives suivantes :
--insights-config-query-string-length: définit la limite de longueur par défaut des requêtes de 256 à 4 500 octets. La longueur de requête par défaut est de 1 024 octets. Des longueurs de requête plus élevées sont plus utiles pour les requêtes analytiques, mais elles nécessitent également davantage de mémoire. Pour modifier la longueur de la requête, vous devez redémarrer l'instance. Vous pouvez toujours ajouter des tags aux requêtes qui dépassent la longueur maximale.--insights-config-query-plans-per-minute: par défaut, un maximum de cinq échantillons de plan de requête exécutés sont capturés par minute sur l'ensemble des bases de données de l'instance. Remplacez cette valeur par un nombre compris entre 1 et 20. Pour désactiver l'échantillonnage, saisissez 0. Si vous augmentez le taux d'échantillonnage, vous obtiendrez peut-être plus de points de données, mais cela peut avoir un impact sur les performances.--insights-config-record-client-address: stocke les adresses IP clientes d'où proviennent les requêtes et vous aide à regrouper ces données pour en extraire des métriques. Les requêtes proviennent de plusieurs hôtes. L'examen des graphiques des requêtes à partir d'adresses IP clientes peut aider à identifier la source d'un problème. Si vous ne souhaitez pas stocker les adresses IP des clients, utilisez--no-insights-config-record-client-address.--insights-config-record-application-tags: stocke les tags d'application qui vous aident à déterminer les API et les routes MVC (model-view-controller) qui envoient des requêtes, ainsi qu'à regrouper les données pour en extraire des métriques. Cette option nécessite de commenter des requêtes avec un ensemble de tags spécifique. Si vous ne souhaitez pas stocker les tags d'application, utilisez--no-insights-config-record-application-tags.
Terraform
Pour configurer Insights sur les requêtes à l'aide de Terraform, utilisez la ressource google_alloydb_instance.
Exemple :
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
Remplacez les éléments suivants :
QUERY_STRING_LENGTH_VALUE: longueur de la chaîne de requête. La valeur par défaut est1024. Tout nombre entier compris entre 256 et 4 500 est valide.RECORD_APPLICATION_TAG_VALUE: enregistrez le tag d'application pour une instance. La valeur par défaut esttrue.RECORD_CLIENT_ADDRESS_VALUE: enregistre l'adresse du client pour une instance. La valeur par défaut esttrue.QUERY_PLANS_PER_MINUTE_VALUE: nombre de plans d'exécution de requêtes capturés par Insights par minute pour toutes les requêtes combinées. La valeur par défaut est5. Tout nombre entier compris entre 0 et 20 est valide.Pour savoir comment appliquer ou supprimer une configuration Terraform, consultez Commandes Terraform de base.
La configuration de l'instance exemple avec la configuration des insights sur les requêtes ajoutée doit se présenter comme suit :
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
Cet exemple configure les paramètres d'observabilité sur votre instance AlloyDB. Pour obtenir la liste complète des paramètres de cet appel, consultez Méthode : projects.locations.clusters.instances.patch.
Pour configurer les paramètres des insights sur les requêtes, modifiez les champs facultatifs si nécessaire. Pour obtenir la liste complète des champs de cet appel, consultez QueryInsightsInstanceConfig.
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
CLUSTER_ID: ID du cluster que vous créez. Il doit commencer par une lettre minuscule et peut contenir des lettres minuscules, des chiffres et des traits d'union.PROJECT_ID: ID du projet dans lequel vous souhaitez placer le cluster.LOCATION_ID: ID de la région du cluster.INSTANCE_ID: nom de l'instance principale que vous souhaitez créer.
Pour modifier la configuration de votre instance, utilisez la requête PATCH suivante :
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
Le corps de la requête JSON qui configure tous les champs d'observabilité se présente comme suit :
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
Améliorer les performances des requêtes
Les insights sur les requêtes permettent de résoudre les problèmes liés aux requêtes AlloyDB à la recherche de problèmes de performances. Le tableau de bord d'insights sur les requêtes affiche la charge de la requête en fonction des facteurs que vous sélectionnez. La charge de la requête correspond au calcul du travail total pour toutes les requêtes de l'instance au cours de la période sélectionnée.
Les insights sur les requêtes vous aident à détecter et à analyser les problèmes de performances des requêtes. Pour résoudre les problèmes liés aux requêtes à l'aide des insights sur les requêtes, procédez comme suit :
- Affichez la charge de la base de données pour toutes les requêtes
- Identifiez une requête ou un tag problématique.
- Examinez la requête ou le tag pour identifier les problèmes
- Examinez une trace générée par un exemple de requête.
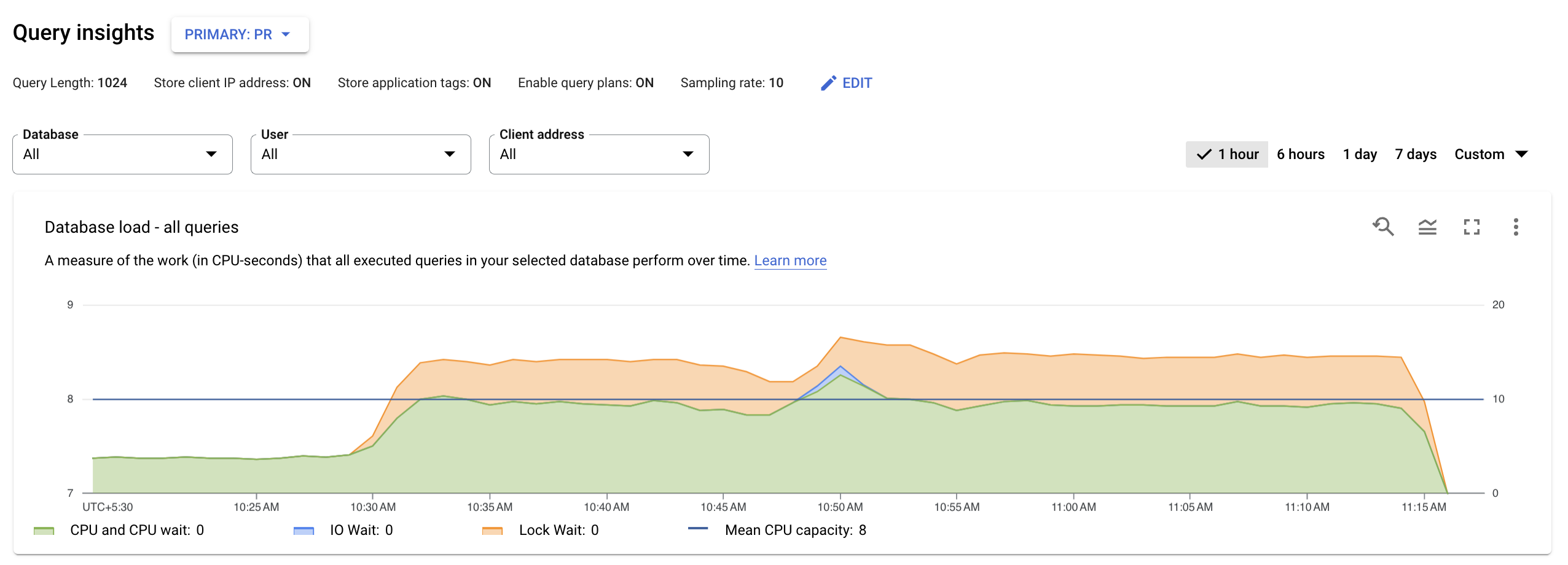
Afficher la charge de la base de données pour toutes les requêtes
Le tableau de bord de premier niveau d'insights sur les requêtes affiche le graphique Charge de la base de données – toutes les principales requêtes à l'aide de données filtrées. La charge de la requête de la base de données est une mesure du travail (en secondes de temps de processeur) effectué au fil du temps par les requêtes exécutées dans la base de données sélectionnée. Chaque requête en cours d'exécution utilise ou attend des ressources du processeur, des ressources d'E/S ou des ressources de verrouillage. La charge de la requête de la base de données correspond au ratio du temps pris par toutes les requêtes effectuées sur une période donnée par rapport à la durée d'exécution.
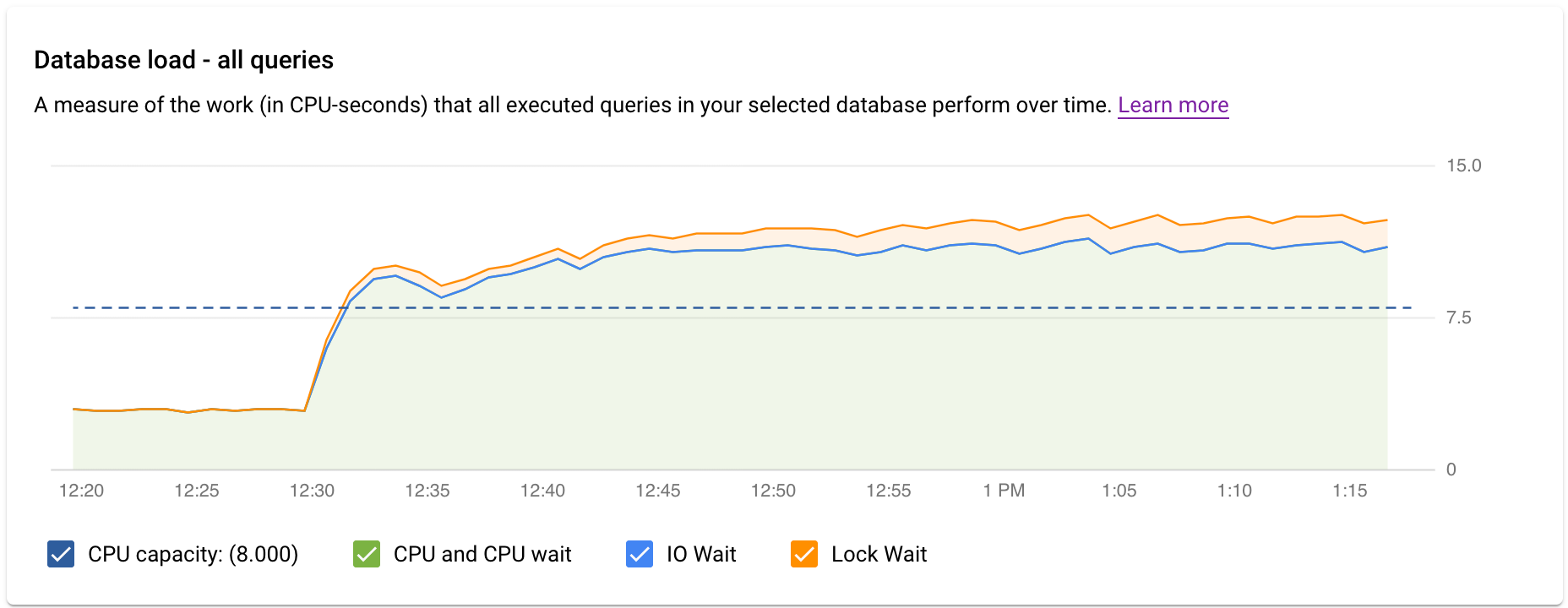
Les lignes colorées dans le graphique indiquent la charge de la requête, divisée en quatre catégories :
- Capacité du processeur : nombre de processeurs disponibles sur l'instance
Processeur et Attente du processeur : ratio entre le temps pris par les requêtes dans un état actif par rapport à la durée d'exécution. Les temps d'attente E/S et de verrouillage ne bloquent pas les requêtes dont l'état est actif. Cette métrique peut indiquer que la requête utilise le processeur ou qu'elle attend que le programmeur Linux planifie le processus du serveur exécutant la requête alors que d'autres processus utilisent le processeur.
Remarque : La charge du processeur tient compte à la fois de l'environnement d'exécution et du temps d'attente du programmeur Linux chargé de planifier le processus du serveur en cours d'exécution. Par conséquent, la charge du processeur peut dépasser la limite maximale de cœur.
Attente E/S : temps pris par les requêtes en attente d'E/S par rapport à la durée d'exécution. L'attente E/S comprend l'attente E/S en lecture et l'attente E/S en écriture. Consultez la table des événements PostgreSQL. Si vous souhaitez une répartition des informations sur les temps de verrouillage, vous pouvez les consulter dans Cloud Monitoring. Pour en savoir plus, consultez Graphiques de métriques.
Attente verrouillage : temps pris par les requêtes en attente de verrous par rapport à la durée d'exécution. Cela inclut les temps d'attente associés aux valeurs Lock, LwLock et BufferPin. Si vous souhaitez une répartition des informations relatives aux temps de verrouillage, vous pouvez les consulter dans Cloud Monitoring. Pour en savoir plus, consultez Graphiques de métriques.
Consultez ensuite le graphique et utilisez les options de filtrage pour répondre aux questions suivantes :
- La charge de la requête est-elle élevée ? Le graphique a-t-il connu un pic ou augmenté au fil du temps ? Si vous ne constatez pas de charge élevée, le problème ne concerne pas vos requêtes.
- Depuis combien de temps la charge est-elle élevée ? Est-elle élevée uniquement maintenant ? Ou est-elle élevée depuis longtemps ? Utilisez la sélection de plages pour sélectionner différentes périodes et déterminer depuis combien de temps le problème persiste. Vous pouvez également faire un zoom avant pour afficher une période dans laquelle des pics de la charge de requête ont été observés. Vous pouvez faire un zoom arrière pour afficher une semaine de la chronologie.
- Qu'est-ce qui provoque la charge élevée ? Vous pouvez sélectionner des options pour examiner la capacité du processeur, l'attente du processeur et le processeur, l'attente de verrouillage ou l'attente E/S. Le graphique de chacune de ces options s'affiche dans une couleur différente, ce qui vous permet d'identifier celle qui présente la charge la plus élevée. La ligne bleu foncé sur le graphique indique la capacité maximale du processeur du système. Il vous permet de comparer la charge de requête avec la capacité maximale de processeur du système. Cette comparaison vous permet de savoir si une instance manque de ressources de processeur.
- Quelle base de données subit la charge ? Sélectionnez différentes bases de données dans le menu déroulant "Bases de données" pour trouver celles avec les charges les plus élevées.
- Des utilisateurs spécifiques ou des adresses IP entraînent-ils des charges plus élevées ? Sélectionnez des utilisateurs et des adresses différents dans les menus déroulants pour comparer ceux qui entraînent des charges plus élevées.
Filtrer la charge de la base de données
Les sections Requêtes et tags vous permettent de filtrer ou de trier la charge des requêtes pour une requête sélectionnée ou pour un tag de requête SQL.
Filtrer par requêtes
La table REQUÊTES fournit un aperçu des requêtes qui provoquent les charges de requête les plus élevées. Le tableau affiche toutes les requêtes normalisées pour la période et les options sélectionnées dans le tableau de bord Insights sur les requêtes.
Par défaut, le tableau trie les requêtes par durée d'exécution totale au cours de la période sélectionnée.
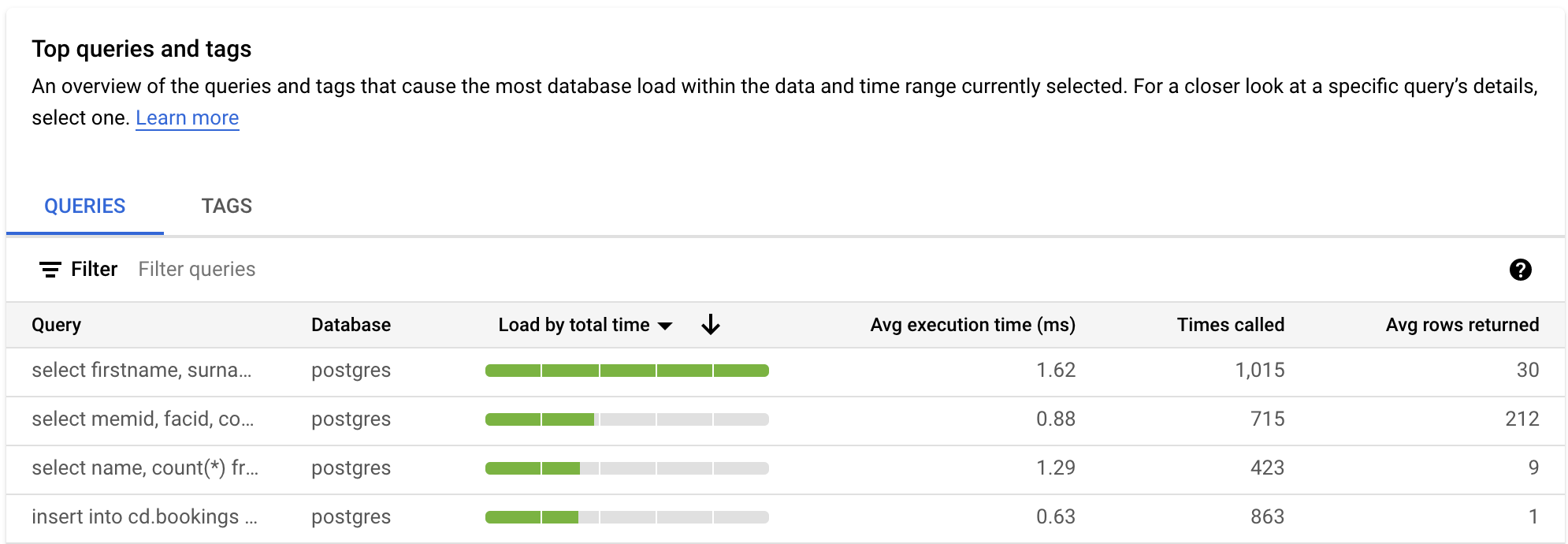
Pour filtrer le tableau, sélectionnez une propriété dans Filtrer les requêtes. Pour trier le tableau, sélectionnez un en-tête de colonne. Le tableau affiche les propriétés suivantes :
Chaîne de requête Chaîne de requête normalisée. Par défaut, Insights sur les requêtes affiche uniquement 1 024 caractères dans la chaîne de requête.
Les requêtes libellées
UTILITY COMMANDincluent généralement les commandesBEGIN,COMMITetEXPLAIN, ou les commandes de wrapper.Base de données : Base de données sur laquelle la requête a été exécutée
Charge par temps total/Charge par processeur/Charge par temps d'attente E/S/Charge par temps d'attente de verrouillage. Ces options vous permettent de filtrer des requêtes spécifiques afin de trouver la charge la plus élevée pour chaque option.
Temps d'exécution moyen (ms) : Temps total nécessaire à toutes les sous-tâches sur l'ensemble des nœuds de calcul parallèles pour exécuter la requête. Pour en savoir plus, consultez Durée et temps d'exécution moyens.
Nombre d'appels : Nombre de fois que la requête a été appelée par l'application
Nombre moyen de lignes récupérées : Nombre moyen de lignes récupérées pour la requête
Les insights sur les requêtes affichent les requêtes normalisées, ce qui signifie que les valeurs constantes littérales sont remplacées par $1, $2, etc. Exemple :
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
La valeur de la constante est ignorée afin que l'outil Insights sur les requêtes puisse agréger des requêtes similaires et supprimer toute information permettant d'identifier personnellement l'utilisateur pouvant être affichée par la constante.
Filtrer par tags de requête
Pour dépanner une application, vous devez d'abord ajouter des tags à vos requêtes SQL.
Les insights sur les requêtes offrent également une surveillance centrée sur les applications afin de diagnostiquer les problèmes de performances des applications créées à l'aide d'ORM.
Si vous êtes responsable de l'ensemble de la pile d'applications, Insights sur les requêtes assure la surveillance des requêtes à partir d'une vue de l'application. L'ajout de tags aux requêtes vous aide à détecter les problèmes liés à des constructions de niveau supérieur, telles que l'utilisation de la logique métier, d'un microservice ou d'une autre construction. Vous pouvez des tags aux requêtes en fonction de la logique métier, par exemple à l'aide des tags de paiement, d'inventaire, d'analyse commerciale ou de livraison. Vous pouvez ensuite trouver la charge de requête créée par les différents types de logique métier. Par exemple, vous pouvez trouver des événements inattendus, tels qu'un pic pour un tag d'analyse commerciale à 13 h. Vous pourriez également constater une croissance inattendue d'un service de paiement au cours de la semaine précédente.
Les tags de charge de requête fournissent la répartition de la charge des requêtes pour le tag sélectionné au fil du temps.
Pour calculer la charge de base de données pour un tag, Insights sur les requêtes utilise le temps nécessaire à chaque requête utilisant le tag sélectionné. Query Insights calcule le délai d'exécution à la minute à l'aide de l'heure d'exécution.
Dans le tableau de bord Insights sur les requêtes, sélectionnez TAGS pour afficher le tableau des tags. Le tableau TAGS trie les tags en fonction de leur charge totale par durée totale.

Vous pouvez trier la table en sélectionnant une propriété dans Filtrer les requêtes ou en cliquant sur un en-tête de colonne. Le tableau affiche les propriétés suivantes :
- Action, contrôleur, framework, route, application, pilote de base de données. Chaque propriété que vous avez ajoutée à vos requêtes s'affiche sous la forme d'une colonne. Vous devez ajouter au moins une de ces propriétés si vous souhaitez effectuer un filtrage par tags.
- Charge par temps total/Charge par processeur/Charge par temps d'attente E/S/Charge par temps d'attente de verrouillage. Ces options vous permettent de filtrer des requêtes spécifiques afin de trouver la charge la plus élevée pour chaque option.
- Temps d'exécution moyen (ms) : Temps total nécessaire à toutes les sous-tâches sur l'ensemble des nœuds de calcul parallèles pour exécuter la requête. Pour en savoir plus, consultez Durée et temps d'exécution moyens.
- Nombre d'appels : Nombre de fois que la requête a été appelée par l'application
- Nombre moyen de lignes récupérées : Nombre moyen de lignes récupérées pour la requête
- Base de données : Base de données sur laquelle la requête a été exécutée
Examiner une requête ou un tag spécifique
Pour déterminer si une requête ou un tag est la cause principale du problème, procédez comme suit à partir de l'onglet Requêtes ou Tags :
- Cliquez sur l'en-tête Load by total time (Charge par temps total) pour trier la liste par ordre décroissant.
- Cliquez sur la requête ou le tag qui semble avoir la charge la plus élevée et dure plus longtemps que les autres.
Un tableau de bord s'ouvre et affiche les détails de la requête ou du tag sélectionné.
Si vous avez sélectionné une requête, un aperçu de celle-ci s'affiche :

Si vous avez sélectionné un tag, un aperçu de celui-ci s'affiche.
Examiner la charge pour une requête ou un tag spécifique
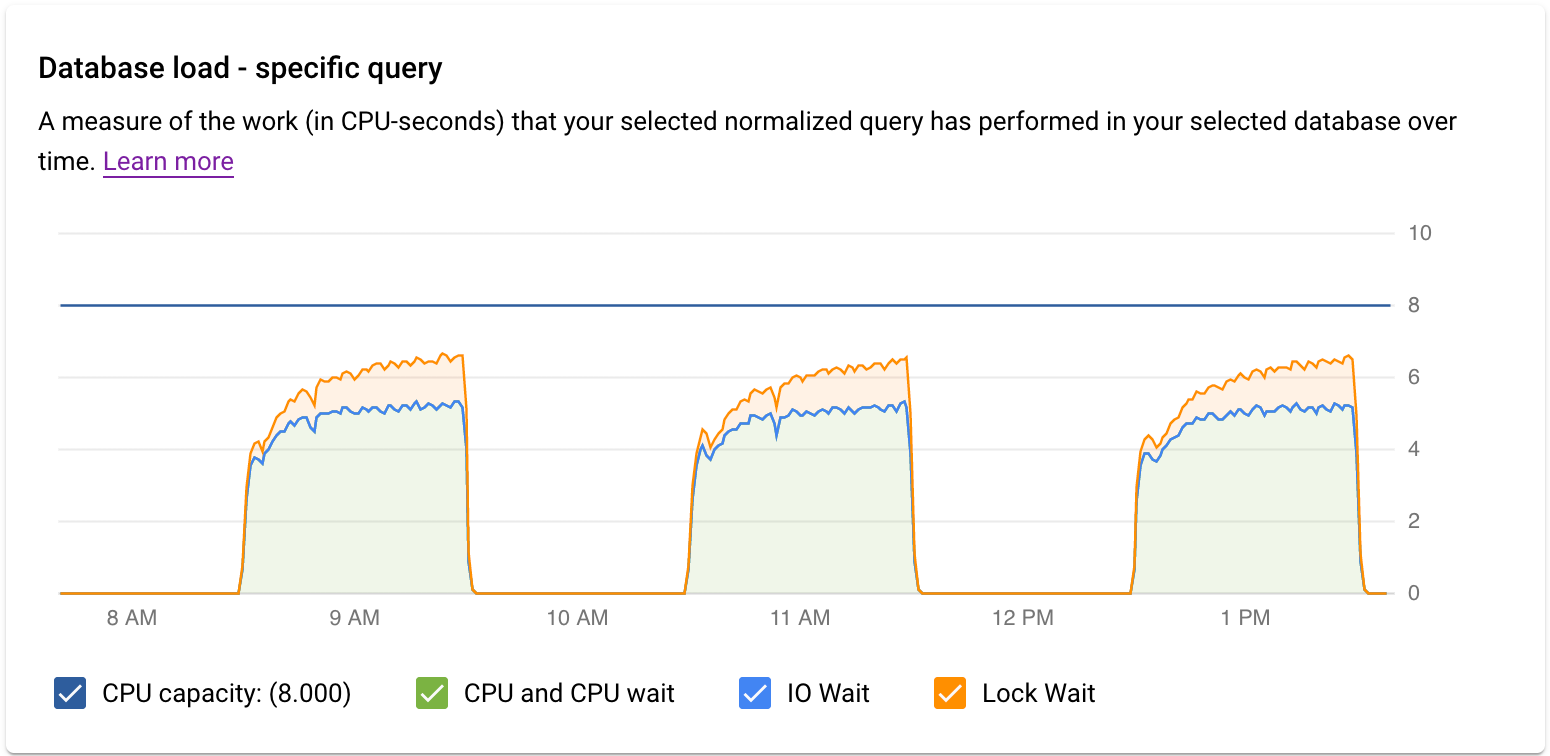
Le graphique Charge de la base de données – requête spécifique montre le travail (en secondes de processeur) effectué au cours du temps par la requête normalisée sélectionnée dans la requête sélectionnée. Pour calculer la charge, elle utilise le temps pris par les requêtes normalisées à la limite de la minute par rapport à la durée d'exécution. En haut du tableau, les 1 024 premiers caractères de la requête normalisée (où les littéraux sont supprimés pour des raisons d'agrégation et d'informations personnelles) s'affichent. Comme pour le graphique des requêtes totales, vous pouvez filtrer la charge d'une requête spécifique par base de données, utilisateur et adresse du client. La charge de la requête est divisée en capacité du processeur, processeur et temps d'attente du processeur, temps d'attente d'E/S et temps d'attente de verrouillage.
Le graphique (Charge de la base de données – tags spécifiques) montre le travail (en secondes de processeur) effectué au cours du temps par les requêtes correspondant aux tags spécifiés, dans la base de données sélectionnée. Comme pour le graphique des requêtes totales, vous pouvez filtrer la charge d'un tag spécifique par base de données, utilisateur et adresse du client.
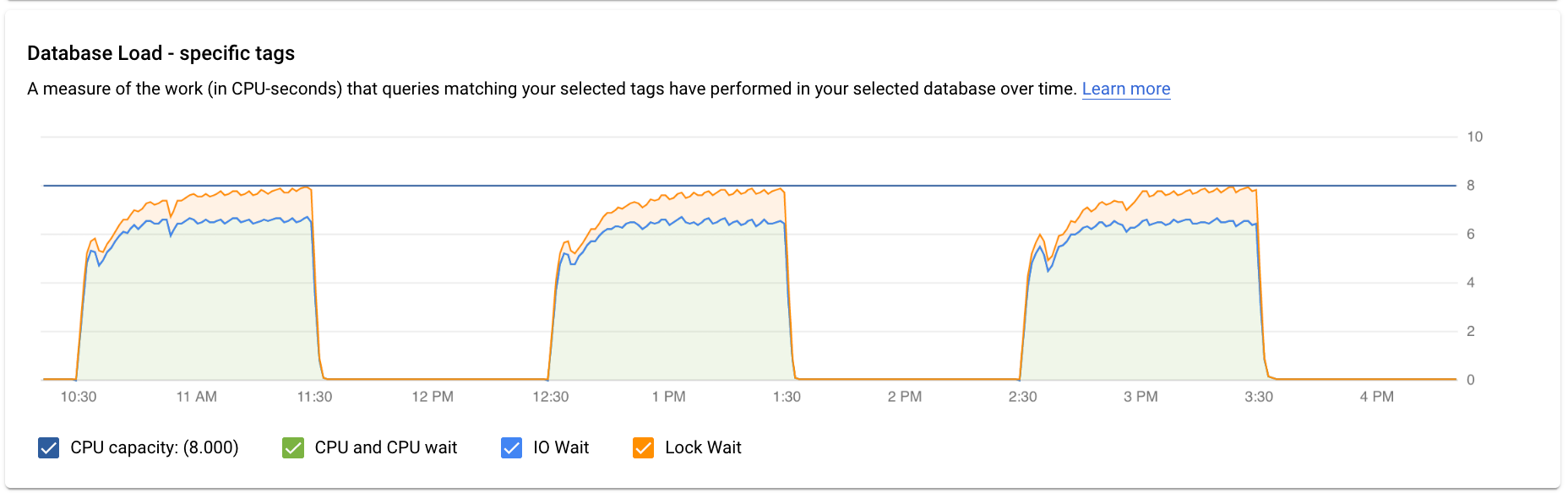
Examiner la latence
Vous utilisez le graphique Latence pour examiner la latence de la requête ou du tag. La latence correspond au temps d'exécution de la requête normalisée en temps réel écoulé. Le tableau de bord de latence montre la latence des 50e, 95e et 99e centiles afin de détecter les comportements présentant des anomalies.
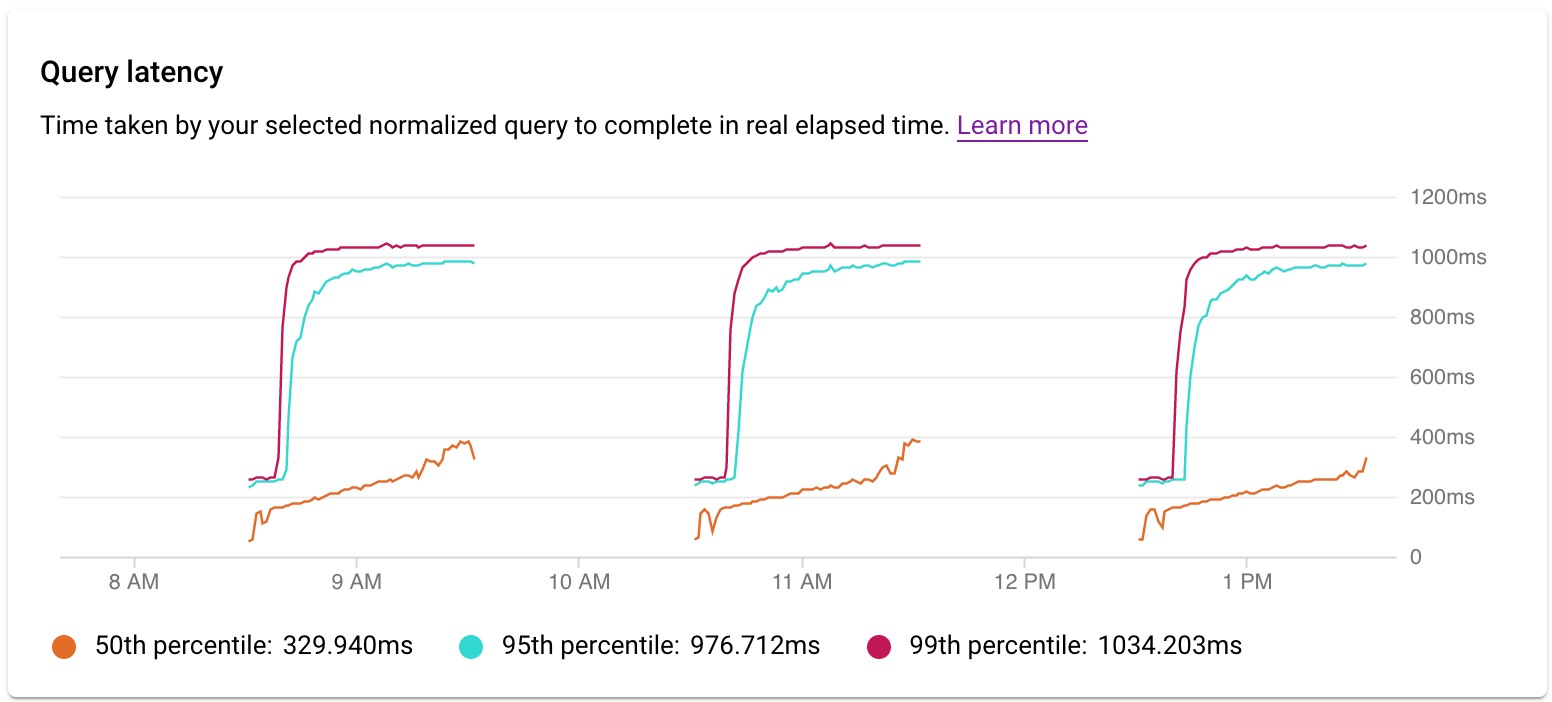
La latence des requêtes parallèles est mesurée en temps d'exécution, même si la charge de la requête peut être plus élevée pour la requête en raison de l'utilisation de plusieurs cœurs pour exécuter une partie de la requête.
Essayez de préciser le problème en examinant les éléments suivants :
- Qu'est-ce qui provoque la charge élevée ? Sélectionnez des options pour examiner la capacité du processeur, le temps d'attente du processeur et le processeur, le temps d'attente de verrouillage ou le temps d'attente d'E/S.
- Depuis combien de temps la charge est-elle élevée ? Est-elle élevée uniquement maintenant ? Ou est-elle élevée depuis longtemps ? Modifiez les périodes pour trouver la date et l'heure auxquelles la charge s'est mal exécutée.
- Y a-t-il eu des pics de latence ? Vous pouvez modifier la période pour étudier la latence historique de la requête normalisée.
Une fois que vous avez trouvé les zones et les heures pour la charge maximale, vous pouvez afficher plus de détails.
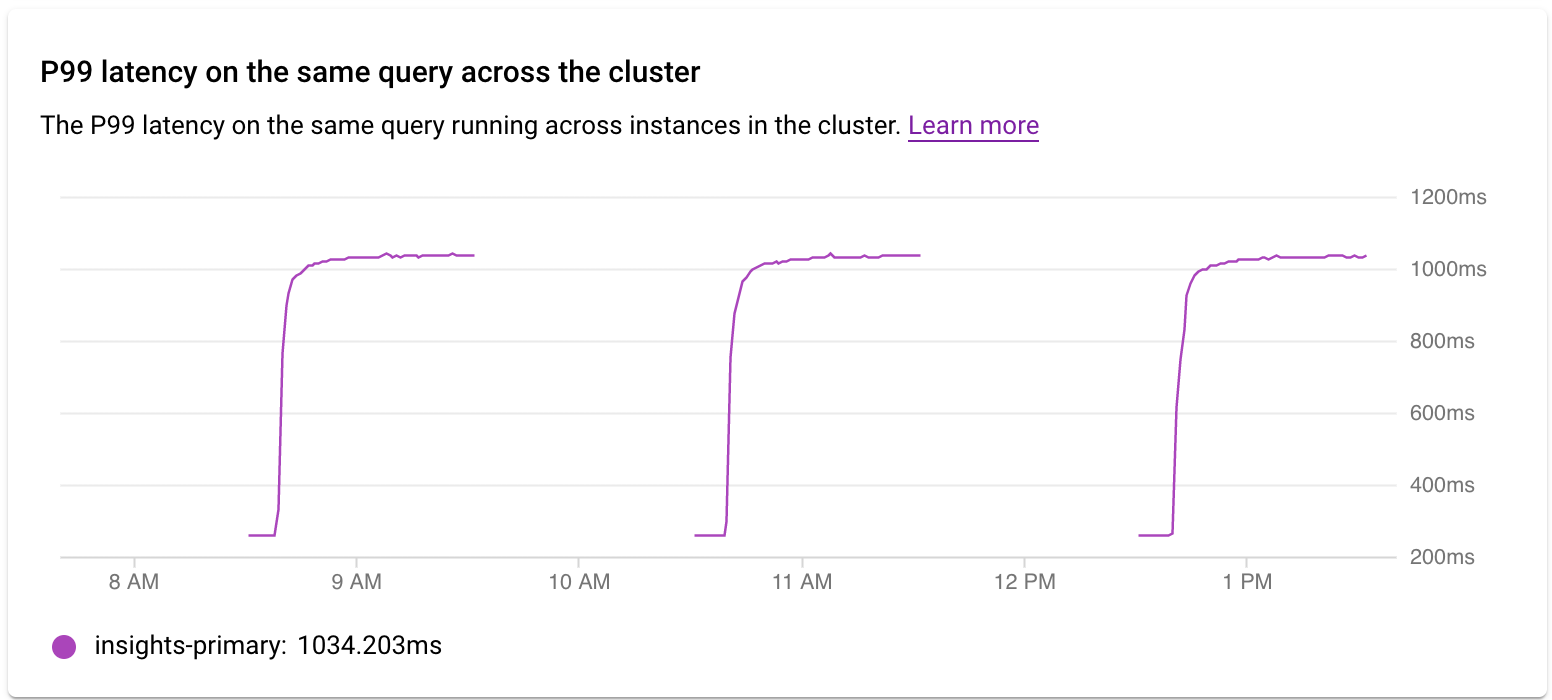
Examiner la latence dans un cluster
Vous utilisez le graphique Latence P99 sur la même requête dans le cluster pour examiner la latence P99 de la requête ou du tag sur les instances du cluster.
Examiner les opérations dans un plan de requête échantillonné
Un plan de requête prend un échantillon de votre requête et le divise en opérations individuelles. Il décrit et analyse chaque opération dans la requête. Le graphique des exemples de plan de requête affiche tous les plans de requête en cours d'exécution à des heures particulières et la durée d'exécution de chaque plan.
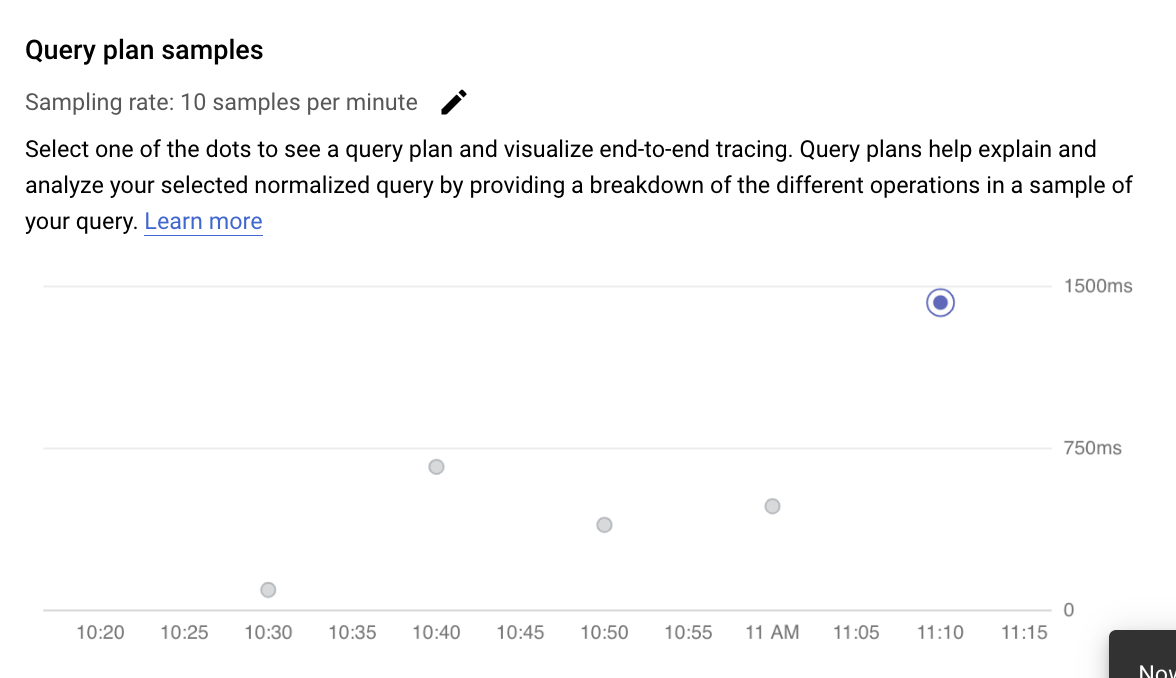
Pour afficher les détails de l'exemple de plan de requête, cliquez sur les points du graphique Exemples de plans de requête. Il existe un aperçu des exemples de plans de requête exécutés pour la plupart des requêtes, mais pas de la totalité. Les détails développés montrent un modèle de toutes les opérations du plan de requête. Chaque opération affiche la latence, les lignes renvoyées et le coût de cette opération. Lorsque vous sélectionnez une opération, vous pouvez afficher plus de détails, tels que des blocs d'appels partagés, le type de schéma, les boucles réelles, des lignes de plan, etc.
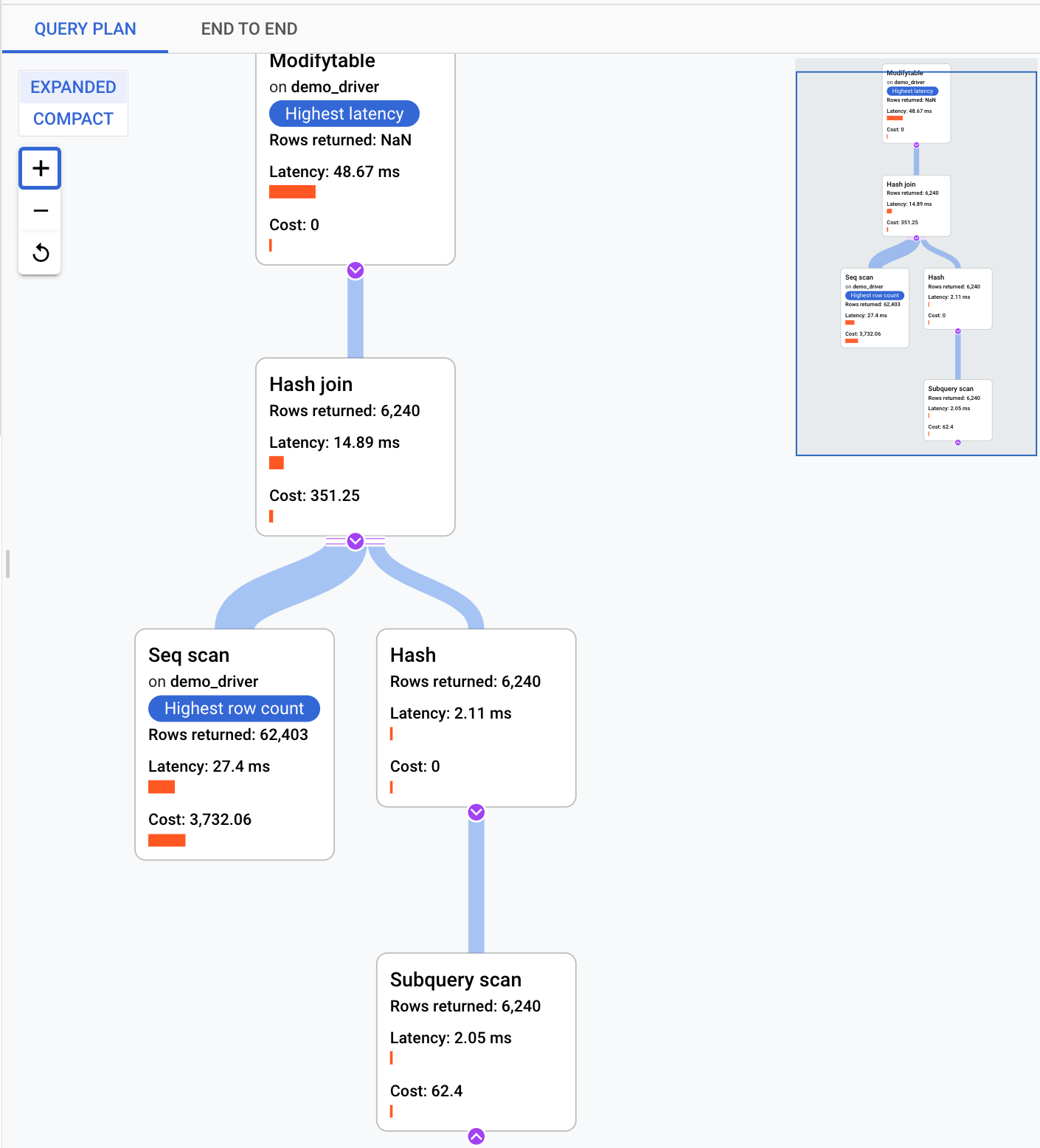
Essayez de préciser le problème en examinant les questions suivantes :
- Quelle est la consommation des ressources ?
- Quel est le rapport avec les autres requêtes ?
- La consommation évolue-t-elle au fil du temps ?
Examiner une trace générée par un exemple de requête
En plus d'afficher l'exemple de plan de requête, vous pouvez utiliser les insights sur les requêtes pour afficher une trace d'application de bout en bout et en contexte pour un exemple de requête. Cette trace peut vous aider à identifier la source d'une requête problématique en affichant l'activité de la base de données pour une requête spécifique. De plus, les entrées de journal que l'application envoie à Cloud Logging pendant la requête sont associées à la trace, ce qui vous aide dans votre investigation.
Pour afficher la trace dans le contexte, procédez comme suit :
Dans le volet Exemple de requête, cliquez sur l'onglet Trace de bout en bout. Cet onglet affiche un graphique de Gantt qui détaille les spans (enregistrements d'opérations individuelles) pour la trace générée par la requête.
Pour afficher plus d'informations sur chaque segment, comme les attributs et les métadonnées, cliquez sur le segment.
Vous pouvez également afficher la trace sur la page Explorateur Trace. Pour ce faire, cliquez sur Afficher dans Cloud Trace. Pour savoir comment utiliser la page Explorateur Trace afin d'explorer vos données de trace, consultez Rechercher et explorer des traces.
Ajouter des tags aux requêtes SQL
L'ajout de tags aux requêtes SQL simplifie le dépannage des applications. Vous pouvez ajouter automatiquement des tags à vos requêtes SQL avec sqlcommenter à l'aide d'un mappage objet-relationnel (ORM, Object-Relational Mapping) ou manuellement.
Utiliser sqlcommenter avec ORM
Lorsque ORM est utilisé au lieu d'écrire directement des requêtes SQL, il est possible que vous ne trouviez pas le code d'application qui engendre le problème de performances. Vous aurez peut-être également des difficultés à analyser l'impact du code de votre application sur les performances des requêtes. Pour résoudre ce problème, Insights sur les requêtes fournit une bibliothèque Open Source appelée sqlcommenter, une bibliothèque d'instrumentation ORM. Cette bibliothèque est utile pour les développeurs qui utilisent ORMs et les administrateurs pour détecter le code d'application qui pose problème.
Si vous utilisez ensemble ORM et sqlcommenter, ces tags sont créés automatiquement sans que vous ayez besoin d'ajouter de code personnalisé à votre application, ni de modifier un code existant.
Vous pouvez installer sqlcommenter sur le serveur d'applications. La bibliothèque d'instrumentation permet de propager des informations liées à l'application en rapport avec votre framework MVC dans la base de données, ainsi que les requêtes en tant que commentaire SQL. La base de données récupère ces tags, puis commence à enregistrer et à agréger les statistiques en fonction de leurs tags, qui sont orthogonaux avec des statistiques agrégées par requêtes normalisées. Insights sur les requêtes affiche les tags afin que vous puissiez savoir quelle application est à l'origine de la charge de la requête. Ces informations vous aident à identifier le code d'application qui pose problème.
Lorsque vous examinez les résultats dans les journaux de la base de données SQL, ils se présentent comme suit :
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
Les tags acceptées incluent le nom du contrôleur, la route, le framework et l'action.
L'ensemble des ORM dans sqlcommenter est compatible avec différents langages de programmation :
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
Pour plus d'informations sur sqlcommenter et sur son utilisation dans votre framework ORM, consultez la documentation de sqlcommenter dans GitHub.
Ajouter des tags manuellement à l'aide de sqlcommenter
Si vous n'utilisez pas ORM, vous devez ajouter manuellement des tags sqlcommenter à vos requêtes SQL. Dans votre requête, vous devez améliorer chaque instruction SQL à l'aide d'un commentaire contenant une paire clé/valeur sérialisée. Utilisez au moins l'une des clés suivantes :
action=''controller=''framework=''route=''application=''db driver=''
Insights sur les requêtes supprime toutes les autres clés. Consultez la documentation sqlcommenter pour connaître le format approprié pour les commentaires SQL.
Heure et durée d'exécution
Les insights sur les requêtes fournissent une métrique Durée d'exécution moyenne (ms), qui indique le temps total nécessaire à toutes les sous-tâches sur tous les nœuds de calcul parallèles pour exécuter la requête. Cette métrique peut vous aider à optimiser l'utilisation globale des ressources des bases de données en identifiant et en optimisant les requêtes qui génèrent la plus grande surcharge du processeur.
Pour afficher le temps écoulé, vous pouvez mesurer la durée d'une requête en exécutant la commande \timing sur le client psql. Elle mesure le temps écoulé entre la réception de la requête et l'envoi d'une réponse par le serveur PostgreSQL. Cette métrique peut vous aider à analyser pourquoi une requête donnée prend trop de temps et à décider de l'optimiser ou non pour qu'elle s'exécute plus rapidement.
Si une requête est exécutée en mode monothread par une seule tâche, la durée et le temps d'exécution moyen restent les mêmes.
Activer les fonctionnalités avancées d'insights sur les requêtes pour AlloyDB
Le tableau de bord des fonctionnalités avancées d'insights sur les requêtes pour AlloyDB est intégré au tableau de bord standard des insights sur les requêtes. Pour savoir comment activer les fonctionnalités avancées d'insights sur les requêtes, consultez Améliorer les performances des requêtes à l'aide des fonctionnalités avancées d'insights sur les requêtes.
Étapes suivantes
- Présentation des insights sur les requêtes
- Améliorer les performances des requêtes à l'aide des fonctionnalités avancées d'insights sur les requêtes pour AlloyDB
- Métriques AlloyDB
- Blog sur SQL Commenter : Présentation de Sqlcommenter : bibliothèque d'instrumentation automatique ORM Open Source
- Blog pratique : Activez l'ajout de tags aux requêtes avec Sqlcommenter