이 튜토리얼에서는 Google Cloud 콘솔을 사용하여 PostgreSQL용 AlloyDB에서 벡터 검색을 설정하고 수행하는 방법을 설명합니다. 벡터 검색 기능을 보여주는 예가 포함되어 있으며, 데모용으로만 사용해야 합니다.
필터링된 벡터 검색을 사용하여 유사성 검색을 개선하는 방법을 알아보려면 PostgreSQL용 AlloyDB의 필터링된 벡터 검색을 참고하세요.
Vertex AI 임베딩으로 벡터 검색을 수행하는 방법을 알아보려면 AlloyDB AI로 벡터 임베딩 시작하기를 참고하세요.
목표
- AlloyDB 클러스터 및 기본 인스턴스를 만듭니다.
- 데이터베이스에 연결하고 필수 확장 프로그램을 설치합니다.
product및product inventory테이블을 만듭니다.product및product inventory테이블에 데이터를 삽입하고 기본 벡터 검색을 실행합니다.- 제품 테이블에 ScaNN 색인을 만듭니다.
- 간단한 벡터 검색을 실행합니다.
- 필터와 조인을 사용하여 복잡한 벡터 검색을 실행합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
결제 및 필수 API 사용 설정
Google Cloud 콘솔에서 클러스터 페이지로 이동합니다.
PostgreSQL용 AlloyDB를 만들고 연결하는 데 필요한 Cloud API를 사용 설정합니다.
- 프로젝트 확인 단계에서 다음을 클릭하여 변경할 프로젝트의 이름을 확인합니다.
API 사용 설정 단계에서 사용 설정을 클릭하여 다음을 사용 설정합니다.
- AlloyDB API
- Compute Engine API
- Service Networking API
- Vertex AI API
AlloyDB 클러스터 및 기본 인스턴스 만들기
Google Cloud 콘솔에서 클러스터 페이지로 이동합니다.
클러스터 만들기를 클릭합니다.
클러스터 ID에
my-cluster를 입력합니다.비밀번호를 입력합니다. 이 튜토리얼에서 사용되므로 이 비밀번호를 기록해 둡니다.
리전을 선택합니다(예:
us-central1 (Iowa)).기본 네트워크를 선택합니다.
비공개 액세스 연결이 있는 경우 다음 단계로 계속 진행합니다. 그렇지 않은 경우 연결 설정을 클릭하고 다음 단계를 따르세요.
- IP 범위 할당에서 자동 할당된 IP 범위 사용을 클릭합니다.
- 계속을 클릭한 다음 연결 만들기를 클릭합니다.
영역 가용성에서 단일 영역을 선택합니다.
2 vCPU,16 GB머신 유형을 선택합니다.연결에서 공개 IP 사용 설정을 선택합니다.
클러스터 만들기를 클릭합니다. AlloyDB에서 클러스터를 생성하고 기본 클러스터 개요 페이지에 표시하는 데 몇 분 정도 걸릴 수 있습니다.
클러스터의 인스턴스에서 연결 창을 펼칩니다. 이 튜토리얼에서 사용되므로 연결 URI를 기록해 둡니다.
연결 URI는
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary형식입니다.
AlloyDB 서비스 에이전트에 Vertex AI 사용자 권한 부여
AlloyDB가 Vertex AI 텍스트 임베딩 모델을 사용하도록 설정하려면 클러스터와 인스턴스가 있는 프로젝트의 AlloyDB 서비스 에이전트에 Vertex AI 사용자 권한을 추가해야 합니다.
권한을 추가하는 방법에 대한 자세한 내용은 AlloyDB 서비스 에이전트에 Vertex AI 사용자 권한 부여를 참고하세요.
웹브라우저를 사용하여 데이터베이스에 연결
Google Cloud 콘솔에서 클러스터 페이지로 이동합니다.
리소스 이름 열에서 클러스터 이름
my-cluster을 클릭합니다.탐색창에서 AlloyDB Studio를 클릭합니다.
AlloyDB Studio에 로그인 페이지에서 다음 단계를 따르세요.
postgres데이터베이스를 선택합니다.postgres사용자를 선택합니다.- 클러스터 및 클러스터의 기본 인스턴스 만들기에서 만든 비밀번호를 입력합니다.
- 인증을 클릭합니다. 탐색기 창에
postgres데이터베이스의 객체 목록이 표시됩니다.
+ 새 SQL 편집기 탭 또는 + 새 탭을 클릭하여 새 탭을 엽니다.
필수 확장 프로그램 설치
다음 쿼리를 실행하여 vector 및 alloydb_scann 확장 프로그램을 설치합니다.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
제품 및 제품 인벤토리 데이터를 삽입하고 기본 벡터 검색 실행
다음 문을 실행하여 다음 작업을 실행하는
product테이블을 만듭니다.- 기본 제품 정보를 저장합니다.
- 각 제품의 제품 설명에 대한 임베딩 벡터를 계산하고 저장하는
embedding벡터 열이 포함됩니다.
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );필요한 경우 로그 탐색기를 사용하여 로그를 확인하고 오류를 해결할 수 있습니다.
다음 쿼리를 실행하여 사용 가능한 인벤토리와 해당 가격에 관한 정보를 저장하는
product_inventory테이블을 만듭니다. 이 튜토리얼에서는product_inventory및product테이블을 사용하여 복잡한 벡터 검색 쿼리를 실행합니다.CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );다음 쿼리를 실행하여 제품 데이터를
product테이블에 삽입합니다.INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');선택사항: 다음 쿼리를 실행하여 데이터가
product테이블에 삽입되었는지 확인합니다.SELECT * FROM product;다음 쿼리를 실행하여
product_inventory테이블에 인벤토리 데이터를 삽입합니다.INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);music이라는 단어와 유사한 제품을 찾으려고 시도하는 다음 벡터 검색 쿼리를 실행합니다. 즉, 제품 설명에music라는 단어가 명시적으로 언급되지 않더라도 검색어와 관련된 제품이 결과에 표시됩니다.SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;쿼리 결과는 다음과 같습니다.
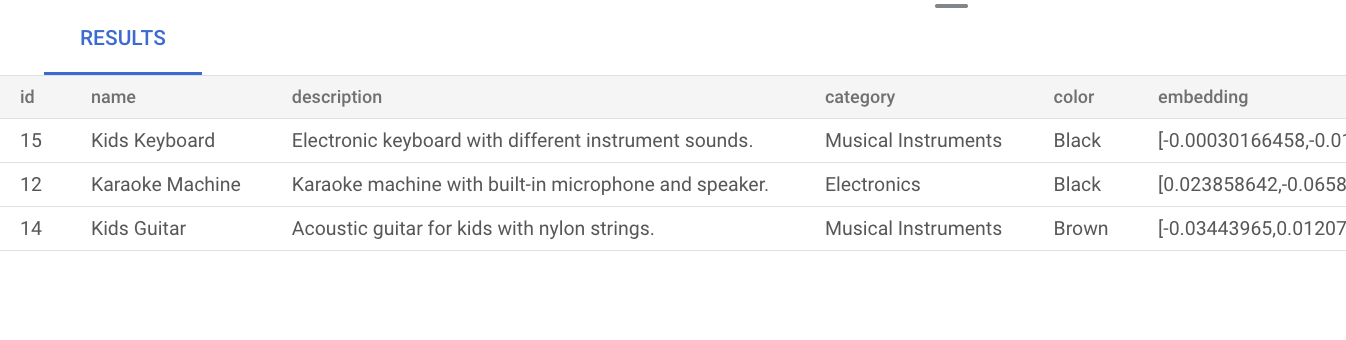
색인을 만들지 않고 기본 벡터 검색을 수행하면 정확한 최근접 이웃 검색 (KNN)이 사용되어 효율적인 검색을 제공합니다. 대규모로 KNN을 사용하면 성능에 영향을 줄 수 있습니다. 더 나은 쿼리 성능을 위해 근사 최근접 이웃 (ANN) 검색에 ScaNN 색인을 사용하는 것이 좋습니다. ScaNN 색인은 지연 시간이 짧고 재현율이 높습니다.
색인을 만들지 않으면 AlloyDB는 기본적으로 정확한 근접 이웃 검색 (KNN)을 사용합니다.
대규모로 ScaNN을 사용하는 방법을 자세히 알아보려면 AlloyDB AI로 벡터 임베딩 시작하기를 참고하세요.
제품 테이블에 ScaNN 색인 만들기
다음 쿼리를 실행하여 product 테이블에 product_index ScaNN 색인을 만듭니다.
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (num_leaves=5);
num_leaves 매개변수는 트리 기반 색인이 색인을 빌드하는 리프 노드 수를 나타냅니다. 이 매개변수를 조정하는 방법에 관한 자세한 내용은 벡터 쿼리 성능 조정을 참고하세요.
벡터 검색 수행
자연어 쿼리 music와 유사한 제품을 찾으려고 시도하는 다음 벡터 검색 쿼리를 실행합니다. music라는 단어가 제품 설명에 포함되어 있지 않더라도 검색어와 관련된 제품이 결과에 표시됩니다.
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
쿼리 결과는 다음과 같습니다.

scann.num_leaves_to_search 쿼리 매개변수는 유사성 검색 중에 검색되는 리프 노드 수를 제어합니다. num_leaves 및 scann.num_leaves_to_search 매개변수 값은 성능과 재현율의 균형을 맞추는 데 도움이 됩니다.
필터와 조인을 사용하는 벡터 검색 실행
ScaNN 색인을 사용하는 경우에도 필터링된 벡터 검색 쿼리를 효율적으로 실행할 수 있습니다. 다음과 같은 복잡한 벡터 검색 쿼리를 실행합니다. 이 쿼리는 필터가 있더라도 쿼리 조건을 충족하는 관련 결과를 반환합니다.
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
필터링된 벡터 검색 가속화
데이터베이스에서 LIKE를 사용하는 등 선택성이 높은 술어 필터링과 결합할 때 열 형식 엔진을 사용하여 벡터 유사성 검색, 특히 K-최근접 이웃 (KNN) 검색의 성능을 개선할 수 있습니다. 이 섹션에서는 vector 확장 프로그램과 AlloyDB google_columnar_engine 확장 프로그램을 사용합니다.
성능 개선은 열 형식 엔진이 대규모 데이터 세트를 스캔하고 LIKE 술어와 같은 필터를 적용하는 내장된 효율성과 벡터 지원을 사용하여 행을 사전 필터링하는 기능에서 비롯됩니다.
이 기능은 후속 KNN 벡터 거리 계산에 필요한 데이터 하위 집합의 수를 줄여주며 표준 필터링 및 벡터 검색과 관련된 복잡한 분석 쿼리를 최적화하는 데 도움이 됩니다.
열 형식 엔진을 사용 설정하기 전후에 LIKE 조건자로 필터링된 KNN 벡터 검색의 실행 시간을 비교하려면 다음 단계를 따르세요.
벡터 데이터 유형과 연산을 지원하도록
vector확장 프로그램을 사용 설정합니다. 다음 문을 실행하여 ID, 텍스트 설명, 512차원 벡터 임베딩 열이 있는 예시 테이블 (items)을 만듭니다.CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );다음 문을 실행하여 예시
items테이블에 100만 개의 행을 삽입하여 데이터를 채웁니다.-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;열 기반 엔진 없이 벡터 유사성 검색의 기준 성능을 측정합니다.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Google Cloud CLI에서 다음 명령어를 실행하여 열 형식 엔진과 벡터 지원을 사용 설정합니다. gcloud CLI를 사용하려면 gcloud CLI를 설치하고 초기화합니다.
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=onitems테이블을 열 형식 엔진에 추가합니다.SELECT google_columnar_engine_add('items');열 형식 엔진을 사용하여 벡터 유사성 검색의 성능을 측정합니다. 이전에 실행한 쿼리를 다시 실행하여 기준 성능을 측정합니다.
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;쿼리가 열 형식 엔진으로 실행되었는지 확인하려면 다음 명령어를 실행합니다.
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
삭제
Google Cloud 콘솔에서 클러스터 페이지로 이동합니다.
리소스 이름 열에서 클러스터 이름(
my-cluster)을 클릭합니다.delete 클러스터 삭제를 클릭합니다.
Delete cluster my-cluster에서
my-cluster를 입력하여 클러스터를 삭제할 것인지 확인합니다.삭제를 클릭합니다.
클러스터를 만들 때 비공개 연결을 만든 경우 Google Cloud 콘솔의 네트워킹 페이지로 이동하여 VPC 네트워크 삭제를 클릭합니다.
다음 단계
- 벡터 검색의 실제 사용 사례를 알아봅니다.
- AlloyDB AI를 사용하여 벡터 임베딩 시작하기
- AlloyDB AI를 사용하여 생성형 AI 애플리케이션을 빌드하는 방법을 알아보세요.
- ScaNN 색인 만들기
- ScaNN 색인 조정
- AlloyDB, pgvector, 모델 엔드포인트 관리로 스마트 쇼핑 어시스턴트를 빌드하는 방법 알아보기
- 로그 탐색기를 사용하여 오류를 해결합니다.