このチュートリアルでは、 Google Cloud コンソールを使用して AlloyDB for PostgreSQL でベクトル検索を設定して実行する方法について説明します。ベクトル検索機能を示す例は、デモのみを目的としています。
フィルタ付きベクトル検索を使用して類似性検索を絞り込む方法については、AlloyDB for PostgreSQL でのフィルタ付きベクトル検索をご覧ください。
Vertex AI エンベディングでベクトル検索を行う方法については、AlloyDB AI でベクトル エンベディングを使ってみるをご覧ください。
目標
- AlloyDB クラスタとプライマリ インスタンスを作成します。
- データベースに接続し、必要な拡張機能をインストールします。
productテーブルとproduct inventoryテーブルを作成します。productテーブルとproduct inventoryテーブルにデータを挿入し、基本的なベクトル検索を実行します。- products テーブルに ScaNN インデックスを作成します。
- 簡単なベクトル検索を実行します。
- フィルタと結合を使用して複雑なベクトル検索を実行します。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
課金と必要な API を有効にする
Google Cloud コンソールで、[クラスタ] ページに移動します。
AlloyDB for PostgreSQL の作成と接続に必要な Cloud APIs を有効にします。
- [プロジェクトを確認] の手順で、[次へ] をクリックして、変更するプロジェクトの名前を確認します。
[API を有効にする] の手順で、[有効にする] をクリックして、次の機能を有効にします。
- AlloyDB API
- Compute Engine API
- Service Networking API
- Vertex AI API
AlloyDB クラスタとプライマリ インスタンスを作成する
Google Cloud コンソールで、[クラスタ] ページに移動します。
[クラスタを作成] をクリックします。
[クラスタ ID] に「
my-cluster」と入力します。パスワードを入力します。このチュートリアルで使用するため、このパスワードはメモしておきます。
リージョンを選択します。例:
us-central1 (Iowa)デフォルトのネットワークを選択します。
プライベート アクセス接続がある場合は、次のステップに進みます。接続が設定されていない場合は、[接続を設定] をクリックして、次の操作を行います。
- [IP 範囲を割り振る] で、[自動的に割り当てられた IP 範囲を使用する] をクリックします。
- [続行]、[接続を作成] の順にクリックします。
[ゾーンの可用性] で [シングルゾーン] を選択します。
2 vCPU,16 GBマシンタイプを選択します。[接続] で、[パブリック IP を有効にする] を選択します。
[クラスタを作成] をクリックします。AlloyDB がクラスタを作成して、プライマリ クラスタの [概要] ページに表示されるまでに数分かかることがあります。
[クラスタ内のインスタンス] で、[接続] ペインを開きます。このチュートリアルで使用するため、接続 URI をメモしておきます。
接続 URI は
projects/<var>PROJECT_ID</var>/locations/<var>REGION_ID</var>/clusters/my-cluster/instances/my-cluster-primary形式です。
Vertex AI ユーザーに AlloyDB サービス エージェントへの権限を付与する
AlloyDB で Vertex AI テキスト エンベディング モデルを使用できるようにするには、クラスタとインスタンスが配置されているプロジェクトの AlloyDB サービス エージェントに Vertex AI ユーザー権限を追加する必要があります。
権限を追加する方法については、Vertex AI ユーザーに AlloyDB サービス エージェントへの権限を付与するをご覧ください。
ウェブブラウザを使用してデータベースに接続する
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列で、クラスタ名
my-clusterをクリックします。ナビゲーション パネルで [AlloyDB Studio] をクリックします。
[AlloyDB Studio にログインする] ページで、次の操作を行います。
postgresデータベースを選択します。postgresユーザーを選択します。- クラスタとそのプライマリ インスタンスを作成するで作成したパスワードを入力します。
- [認証] をクリックします。[エクスプローラ] ペインに、
postgresデータベースにあるオブジェクトのリストが表示されます。
[+ 新しい SQL エディタタブ] または + [新しいタブ] をクリックし、新しいタブを開きます。
必要な拡張機能をインストールする
次のクエリを実行して、vector と alloydb_scann の拡張機能をインストールします。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
商品データと商品在庫データを挿入して基本的なベクトル検索を実行する
次のステートメントを実行して、次の処理を行う
productテーブルを作成します。- 基本的な商品情報を保存します。
- 各商品の商品説明のエンベディング ベクトルを計算して保存する
embeddingベクトル列が含まれています。
CREATE TABLE product ( id INT PRIMARY KEY, name VARCHAR(255) NOT NULL, description TEXT, category VARCHAR(255), color VARCHAR(255), embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005', description)) STORED );必要に応じて、ログ エクスプローラを使用してログを表示し、エラーのトラブルシューティングを行うことができます。
次のクエリを実行して、利用可能な在庫と対応する価格に関する情報を保存する
product_inventoryテーブルを作成します。このチュートリアルでは、product_inventoryテーブルとproductテーブルを使用して、複雑なベクトル検索クエリを実行します。CREATE TABLE product_inventory ( id INT PRIMARY KEY, product_id INT REFERENCES product(id), inventory INT, price DECIMAL(10,2) );次のクエリを実行して、商品データを
productテーブルに挿入します。INSERT INTO product (id, name, description,category, color) VALUES (1, 'Stuffed Elephant', 'Soft plush elephant with floppy ears.', 'Plush Toys', 'Gray'), (2, 'Remote Control Airplane', 'Easy-to-fly remote control airplane.', 'Vehicles', 'Red'), (3, 'Wooden Train Set', 'Classic wooden train set with tracks and trains.', 'Vehicles', 'Multicolor'), (4, 'Kids Tool Set', 'Toy tool set with realistic tools.', 'Pretend Play', 'Multicolor'), (5, 'Play Food Set', 'Set of realistic play food items.', 'Pretend Play', 'Multicolor'), (6, 'Magnetic Tiles', 'Set of colorful magnetic tiles for building.', 'Construction Toys', 'Multicolor'), (7, 'Kids Microscope', 'Microscope for kids with different magnification levels.', 'Educational Toys', 'White'), (8, 'Telescope for Kids', 'Telescope designed for kids to explore the night sky.', 'Educational Toys', 'Blue'), (9, 'Coding Robot', 'Robot that teaches kids basic coding concepts.', 'Educational Toys', 'White'), (10, 'Kids Camera', 'Durable camera for kids to take pictures and videos.', 'Electronics', 'Pink'), (11, 'Walkie Talkies', 'Set of walkie talkies for kids to communicate.', 'Electronics', 'Blue'), (12, 'Karaoke Machine', 'Karaoke machine with built-in microphone and speaker.', 'Electronics', 'Black'), (13, 'Kids Drum Set', 'Drum set designed for kids with adjustable height.', 'Musical Instruments', 'Blue'), (14, 'Kids Guitar', 'Acoustic guitar for kids with nylon strings.', 'Musical Instruments', 'Brown'), (15, 'Kids Keyboard', 'Electronic keyboard with different instrument sounds.', 'Musical Instruments', 'Black'), (16, 'Art Easel', 'Double-sided art easel with chalkboard and whiteboard.', 'Arts & Crafts', 'White'), (17, 'Finger Paints', 'Set of non-toxic finger paints for kids.', 'Arts & Crafts', 'Multicolor'), (18, 'Modeling Clay', 'Set of colorful modeling clay.', 'Arts & Crafts', 'Multicolor'), (19, 'Watercolor Paint Set', 'Watercolor paint set with brushes and palette.', 'Arts & Crafts', 'Multicolor'), (20, 'Beading Kit', 'Kit for making bracelets and necklaces with beads.', 'Arts & Crafts', 'Multicolor'), (21, '3D Puzzle', '3D puzzle of a famous landmark.', 'Puzzles', 'Multicolor'), (22, 'Race Car Track Set', 'Race car track set with cars and accessories.', 'Vehicles', 'Multicolor'), (23, 'RC Monster Truck', 'Remote control monster truck with oversized tires.', 'Vehicles', 'Green'), (24, 'Train Track Expansion Set', 'Expansion set for wooden train tracks.', 'Vehicles', 'Multicolor');省略可: 次のクエリを実行して、データが
productテーブルに挿入されていることを確認します。SELECT * FROM product;次のクエリを実行して、在庫データを
product_inventoryテーブルに挿入します。INSERT INTO product_inventory (id, product_id, inventory, price) VALUES (1, 1, 9, 13.09), (2, 2, 40, 79.82), (3, 3, 34, 52.49), (4, 4, 9, 12.03), (5, 5, 36, 71.29), (6, 6, 10, 51.49), (7, 7, 7, 37.35), (8, 8, 6, 10.87), (9, 9, 7, 42.47), (10, 10, 3, 24.35), (11, 11, 4, 10.20), (12, 12, 47, 74.57), (13, 13, 5, 28.54), (14, 14, 11, 25.58), (15, 15, 21, 69.84), (16, 16, 6, 47.73), (17, 17, 26, 81.00), (18, 18, 11, 91.60), (19, 19, 8, 78.53), (20, 20, 43, 84.33), (21, 21, 46, 90.01), (22, 22, 6, 49.82), (23, 23, 37, 50.20), (24, 24, 27, 99.27);次のベクトル検索クエリを実行して、
musicという単語に類似する商品を検索します。つまり、商品の説明にmusicという単語が明示的に記載されていなくても、クエリに関連する商品が結果に表示されます。SELECT * FROM product ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector LIMIT 3;クエリの結果は次のとおりです。
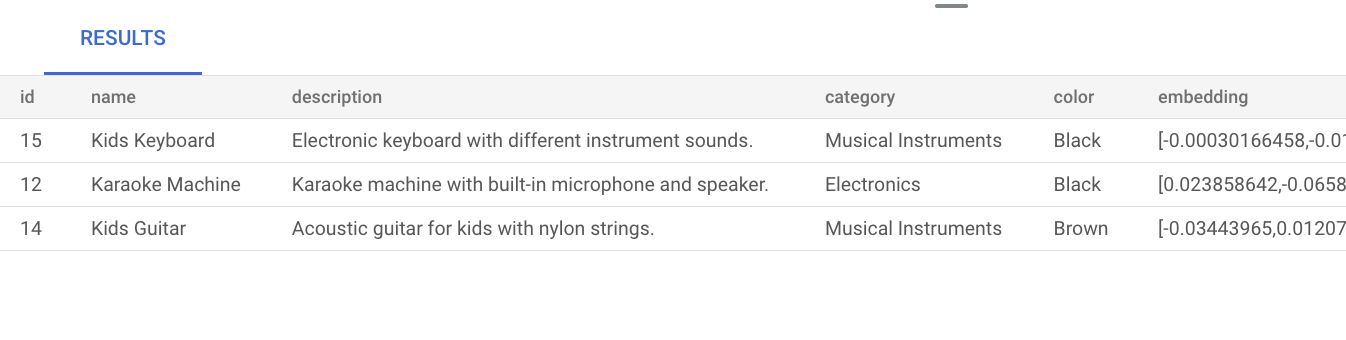
インデックスを作成せずに基本的なベクトル検索を実行すると、正確な最近傍検索(KNN)が使用され、効率的な再現率が得られます。大規模な場合、KNN を使用するとパフォーマンスに影響する可能性があります。クエリのパフォーマンスを向上させるには、近似最近傍検索(ANN)に ScaNN インデックスを使用することをおすすめします。これにより、低レイテンシで高い再現率を実現できます。
インデックスを作成せずに、AlloyDB はデフォルトで正確な最近傍検索(KNN)を使用します。
ScaNN の大規模な使用の詳細については、AlloyDB AI でベクトル エンベディングを使ってみるをご覧ください。
products テーブルに ScaNN インデックスを作成する
次のクエリを実行して、product テーブルに product_index ScaNN インデックスを作成します。
CREATE INDEX product_index ON product
USING scann (embedding cosine)
WITH (num_leaves=5);
num_leaves パラメータは、ツリーベースのインデックスがインデックスの構築に使用するリーフノードの数を示します。このパラメータをチューニングする方法については、ベクトルクエリのパフォーマンスをチューニングするをご覧ください。
ベクトル検索を実行する
次のベクトル検索クエリを実行して、自然言語クエリ music に類似した商品を検索します。商品の説明に music という単語が含まれていなくても、クエリに関連する商品が結果に表示されます。
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
クエリ結果は次のとおりです。

scann.num_leaves_to_search クエリ パラメータは、類似性検索中に検索されるリーフノードの数を制御します。num_leaves パラメータと scann.num_leaves_to_search パラメータの値は、パフォーマンスと再現率のバランスをとるのに役立ちます。
フィルタと結合を使用するベクトル検索を実行する
ScaNN インデックスを使用している場合でも、フィルタ付きベクトル検索クエリを効率的に実行できます。次の複雑なベクトル検索クエリを実行します。フィルタが適用されていても、クエリ条件を満たす関連する結果が返されます。
SET LOCAL scann.num_leaves_to_search = 2;
SELECT * FROM product p
JOIN product_inventory pi ON p.id = pi.product_id
WHERE pi.price < 80.00
ORDER BY embedding <=> embedding('text-embedding-005', 'music')::vector
LIMIT 3;
フィルタ付きベクトル検索を高速化する
カラム型エンジンを使用すると、データベースで選択性の高い述語フィルタリング(LIKE の使用など)と組み合わせた場合に、ベクトル類似性検索(特に K 最近傍(KNN)検索)のパフォーマンスを向上させることができます。このセクションでは、vector 拡張機能と AlloyDB の google_columnar_engine 拡張機能を使用します。
パフォーマンスの向上は、大規模なデータセットのスキャンとフィルタ(LIKE 述語など)の適用におけるカラム型エンジンの組み込みの効率性と、ベクトル サポートを使用して行を事前フィルタリングする機能によって実現されます。この機能により、以降の KNN ベクトル距離計算に必要なデータ サブセットの数が減り、標準フィルタリングとベクトル検索を含む複雑な分析クエリを最適化できます。
カラム型エンジンを有効にする前と後で、LIKE 述語でフィルタされた KNN ベクトル検索の実行時間を比較する手順は次のとおりです。
vector拡張機能を有効にして、ベクトルのデータ型と演算をサポートします。次のステートメントを実行して、ID、テキストの説明、512 次元のベクトル エンベディング列を含むサンプル テーブル(items)を作成します。CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE items ( id SERIAL PRIMARY KEY, description TEXT, embedding VECTOR(512) );データを入力するために、次のステートメントを実行して、サンプル
itemsテーブルに 100 万行を挿入します。-- Simplified example of inserting matching (~0.1%) and non-matching data INSERT INTO items (description, embedding) SELECT CASE WHEN g % 1000 = 0 THEN 'product_' || md5(random()::text) || '_common' -- ~0.1% match ELSE 'generic_item_' || g || '_' || md5(random()::text) -- ~99.9% don't match END, random_vector(512) -- Assumes random_vector function exists FROM generate_series(1, 999999) g;カラム型エンジンを使用しない場合のベクトル類似性検索のベースライン パフォーマンスを測定します。
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;Google Cloud CLI で次のコマンドを実行して、カラム型エンジンとベクトル サポートを有効にします。gcloud CLI を使用するには、gcloud CLI をインストールして初期化します。
gcloud beta alloydb instances update INSTANCE_ID \ --cluster=CLUSTER_ID \ --region=REGION_ID \ --project=PROJECT_ID \ --database-flags=google_columnar_engine.enabled=on,google_columnar_engine.enable_vector_support=onカラム型エンジンに
itemsテーブルを追加します。SELECT google_columnar_engine_add('items');カラム型エンジンを使用して、ベクトル類似性検索のパフォーマンスを測定します。先ほど実行したクエリを再実行して、ベースライン パフォーマンスを測定します。
SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;カラム型エンジンを使用してクエリが実行されたかどうかを確認するには、次のコマンドを実行します。
explain (analyze) SELECT id, description, embedding <-> '[...]' AS distance FROM items WHERE description LIKE '%product_%_common%' ORDER BY embedding <-> '[...]' LIMIT 100;
クリーンアップ
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列でクラスタ名
my-clusterをクリックします。[deleteクラスタを削除] をクリックします。
[Delete cluster my-cluster] で「
my-cluster」と入力して、クラスタの削除を確認します。[削除] をクリックします。
クラスタを作成する際にプライベート接続を作成した場合は、 Google Cloud コンソールの [ネットワーキング] ページに移動し、[VPC ネットワークの削除] をクリックします。
次のステップ
- ベクトル検索の実際のユースケースについて学習する。
- AlloyDB AI を使用してベクトル エンベディングを使ってみる
- AlloyDB AI を使用して生成 AI アプリケーションを構築する方法について学習する。
- ScaNN インデックスを作成する。
- ScaNN インデックスをチューニングする。
- AlloyDB、pgvector、モデル エンドポイント管理を使用してスマート ショッピング アシスタントを構築する方法について学習する。
- ログ エクスプローラを使用してエラーのトラブルシューティングを行う。