什么是 AI Hypercomputer?
什么是 AI Hypercomputer?
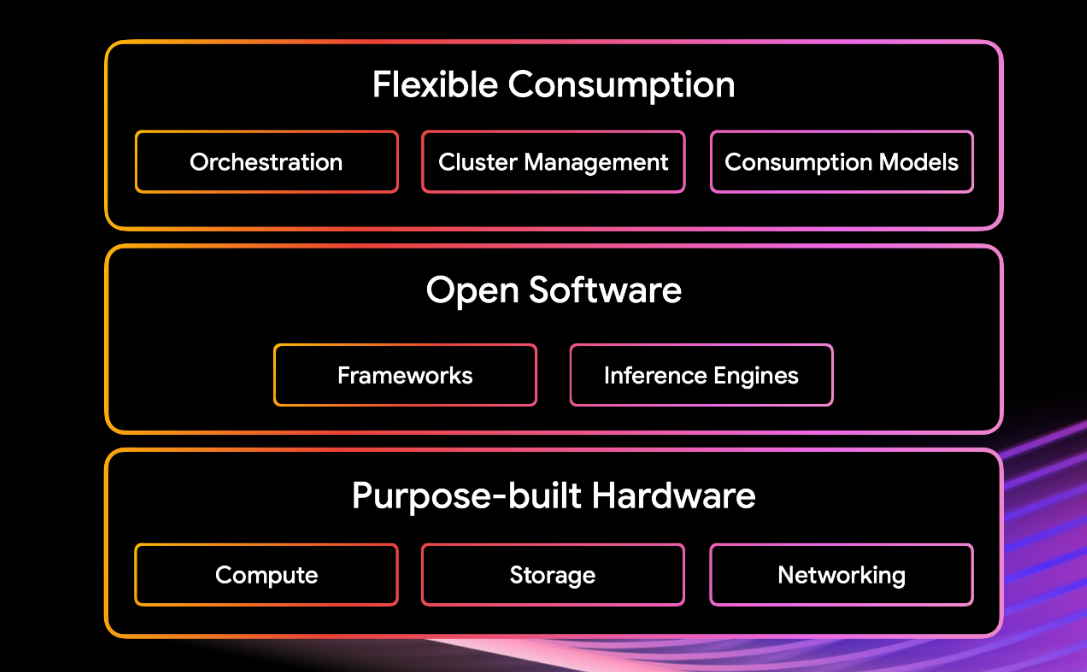
一种结合了专用硬件、开源软件和灵活使用模式的架构。每个组件都经过精心集成,可协同工作,从而提升性能、降低成本并提高开发者工作效率。
查看最新公告(2026 年 4 月):Google AI 基础设施新动向:为智能体时代提供规模化支撑
更智能、更快速的训练
更智能、更快速的训练
在数周(而非数月)内构建模型。使用 Google 的训练栈可加快开发和测试速度,同时不影响性能。

更快地训练和调优 LLM
使用专有数据更智能地训练轻量级模型
将 Gemini Enterprise Agent Platform 与 BigQuery 搭配使用,将数据资产、机器学习开发和加速器整合到一处,以快 16 倍的速度基于专有数据训练模型。无论您使用 G4 虚拟机还是 Ironwood TPU,都由 AI Hypercomputer 提供支持。
使用 MuJoCo-Warp 构建自适应物理智能体
在 DeepMind 的 MuJoCo-Warp 上运行基于 GPU 的模拟,速度比标准 MuJoCo 快 100 倍。然后,使用 Veo、Genie 和 Nano Banana 的合成媒体模拟不可能、有风险或成本高昂的极端情况,或者在 BigQuery 中注入 PB 级的真实传感器数据。如需详细了解如何在 Google Cloud 上构建物理智能体,请点击此处。
响应迅速、高效的推理
响应迅速、高效的推理
获取经过验证的模型配置文件,以及完全集成的 Google 软件和开源软件,以更低的复杂性和浪费提高应用响应能力。
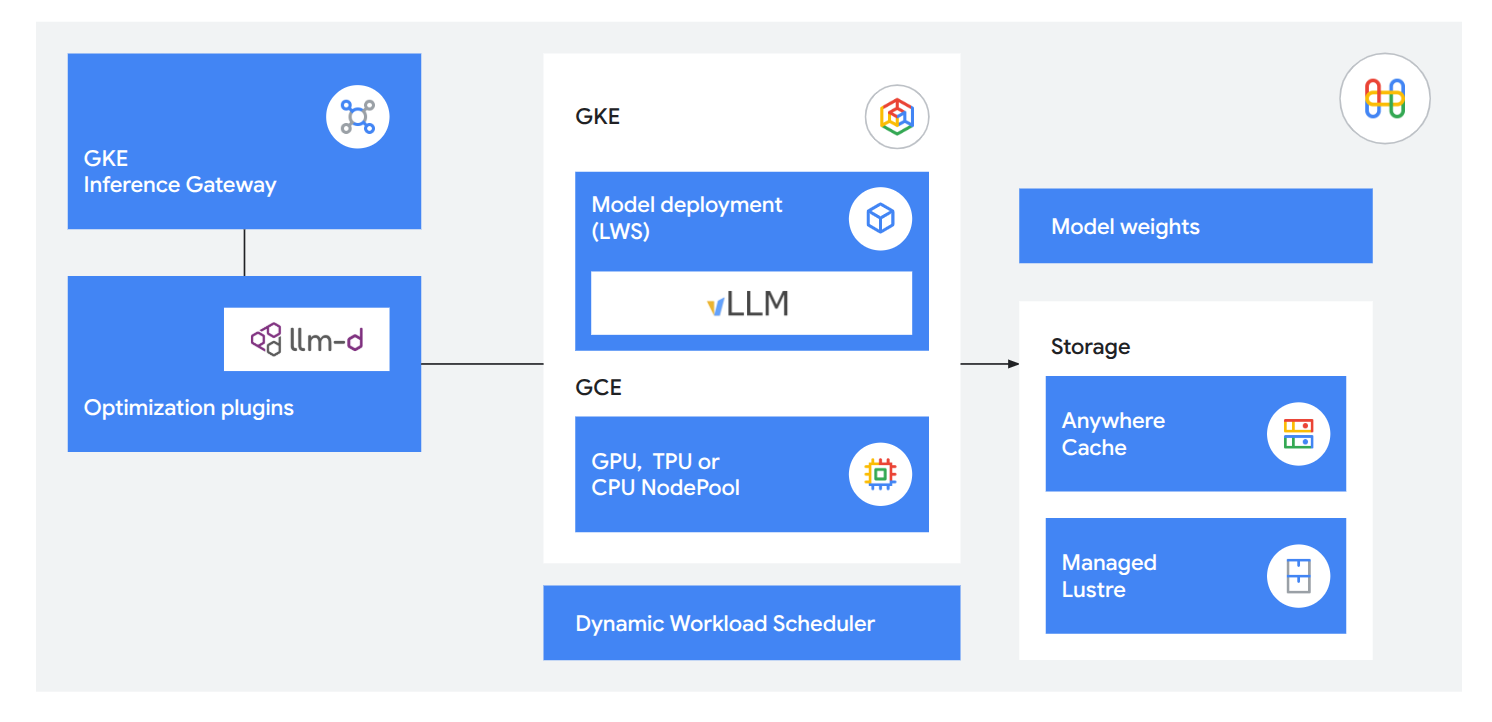
以近乎为零的延迟时间部署 LLM
使用集成式推理技术为客户提供实用、响应迅速的服务。利用 GKE Inference Gateway 将首 token 延迟时间缩短 71%,使用 llm-d 进行分离式服务每秒可提供多达 12 万个 token,并使用 Anywhere Cache 和 TPU 8i 将模型加载速度提升到原来的 5 倍,从而将工作内存保持在需要的位置。
提供预构建的视觉、感知和媒体模型
使用 Gemini Enterprise Agent Platform 提供的 200 多个模型之一,以 70% 更快的速度部署传统机器学习模型,并使用您选择的 TPU 或 GPU,包括 A5X 虚拟机 (NVIDIA Vera Rubin) 和 TPU 8i(将于今年晚些时候推出)。
安全且经济高效地为智能体提供服务
在 GKE Agent Sandbox 中安全地部署大量智能体,每秒预配多达 300 个沙盒,并根据需要即时暂停和恢复,因此您永远不会为闲置的智能体付费。
灵活、开放、可靠的运营
灵活、开放、可靠的运营
在混合云和多云环境中,使用任何框架或加速器,并利用适合 E 级规模的自动集群维护和管理功能。

无需重写代码,即可在 TPU 和 GPU 之间切换
TorchTPU 通过提供原生 PyTorch 支持,消除了开发者的 TPU 学习曲线,让您无需重写复杂的代码即可使用最佳可用的加速器。
在任何环境中以几乎任何规模部署 AI
GKE 基于开源 Kubernetes,可提供企业级规模的多云可移植性,支持多达 13 万个节点,同时与 Agent Platform 和 Google Distributed Cloud 原生集成,实现混合部署。
利用高级集群诊断和可观测性工具自动执行集群维护
AI Hypercomputer 上的每个加速器都由 Cluster Director 功能提供支持,包括部署前健康状况清单、360 度可观测性信息中心和始终开启的健康状况检查。
在几分钟(而不是几周)内连接多云工作负载
使用跨云网络(一个深受《财富》100 强中超过 65% 的公司信赖的网络主干,每月传输超过 27 EB 的数据),在不同云之间连接服务,而不会出现连接延迟。
按需获取加速器容量
我们灵活的使用模式为您提供了多种调度和降低加速器成本的方法。使用 Spot 虚拟机,批量作业或容错作业可节省高达 91% 的费用;使用动态工作负载调度器,开始日期灵活的作业可节省高达 50% 的费用;注册承诺使用折扣,可节省高达 50% 的费用。
可供智能体使用的系统
可供智能体使用的系统
在 Google 和前沿 AI 实验室信赖的基础设施基础上进行扩缩时,突破性能极限,以负责任的方式使用能源
在值得信赖的基础之上降低 AI 路线图的风险
Google Cloud 为排名前 10 的 AI 实验室中的 9 家以及 70% 获得融资的 AI 初创公司提供支持。通过在 AI Hypercomputer 上部署,您将使用数据中心,这些数据中心仅在 2025 年 12 月就为近 350 家客户可靠地处理了超过 1, 000 亿个 token。
实现行业领先的能效
Google Cloud 的数据中心(包括 AI Hypercomputer)提供业界领先的能源效率,每单位电量的计算能力是五年前的六倍。这使得我们的第 8 代 TPU 的性价比比上一代高 80%,能效高 20%。
减少对电网和社区的影响
从芯片到边缘,保护您最有价值的 IP
我们的 Titanium 架构采用定制的 Titan 芯片,可提供可验证的硬件信任根和零信任安全性。cloudvulndb.org 的独立分析表明,与其他领先的云服务相比,我们的系统遇到的严重漏洞最多可减少 70%。
为全球领先的创新者提供助力










详细了解 AI Hypercomputer
- IDC:AI Hypercomputer 的商业价值这份 IDC 报告探讨了 AI Hypercomputer 对 AI 工作负载的实际客户影响。阅读完整报告,查看客户数据,了解投资回报率提升 353%、IT 团队效率提升 55% 以及应用/工作负载计划外停机时间减少 67% 的情况。
阅读用时:5 分钟
阅读报告 - 在 Gartner®《战略云平台服务魔力象限》报告中,Google 被评为业界领导者Gartner® 连续第八年在《战略云平台服务 Gartner 魔力象限™》报告中将 Google 评为业界领导者。然而,今年却是一个主要里程碑:Google 在“愿景完整性”指标上名列前茅。
阅读用时:5 分钟
查看结果 - 在 2025 年第 4 季度的《Forrester Wave™:AI 基础设施解决方案》报告中,Google 被评为业界领导者Google 在“当前产品”类别中得分最高,并在 19 项评估标准中的 16 项中获得了最高分,包括但不限于:愿景、架构、训练、推理、效率和安全性。
阅读用时:5 分钟
查看结果
- 设计并部署您的第一个推理堆栈了解在 Google Cloud 上构建推理解决方案的基本组件,包括 GKE、Cloud TPU、TensorFlow、PyTorch、JAX 和 Keras。
2 小时课程
开始课程学习 - 在 GKE 上使用 vLLM 来执行 Gemma 3 27B 推理本教程介绍如何使用 vLLM 部署框架部署和投放 Gemma 3 27B 大语言模型 (LLM)。您可以在 Google Kubernetes Engine (GKE) 上的单个 A4 虚拟机 (VM) 实例上部署 Gemma 3。
15 分钟指南
学习教程 - 在 A4 GKE 集群上微调 Gemma 3本教程介绍如何在 Google Cloud 上的多节点、多 GPU GKE 集群中微调 Gemma 3 大语言模型 (LLM)。此集群使用包含 8 个 NVIDIA B200 GPU 的 A4 虚拟机 (VM) 实例。
15 分钟指南
学习教程
分析师数据洞见
- IDC:AI Hypercomputer 的商业价值这份 IDC 报告探讨了 AI Hypercomputer 对 AI 工作负载的实际客户影响。阅读完整报告,查看客户数据,了解投资回报率提升 353%、IT 团队效率提升 55% 以及应用/工作负载计划外停机时间减少 67% 的情况。
阅读用时:5 分钟
阅读报告 - 在 Gartner®《战略云平台服务魔力象限》报告中,Google 被评为业界领导者Gartner® 连续第八年在《战略云平台服务 Gartner 魔力象限™》报告中将 Google 评为业界领导者。然而,今年却是一个主要里程碑:Google 在“愿景完整性”指标上名列前茅。
阅读用时:5 分钟
查看结果 - 在 2025 年第 4 季度的《Forrester Wave™:AI 基础设施解决方案》报告中,Google 被评为业界领导者Google 在“当前产品”类别中得分最高,并在 19 项评估标准中的 16 项中获得了最高分,包括但不限于:愿景、架构、训练、推理、效率和安全性。
阅读用时:5 分钟
查看结果
教程
- 设计并部署您的第一个推理堆栈了解在 Google Cloud 上构建推理解决方案的基本组件,包括 GKE、Cloud TPU、TensorFlow、PyTorch、JAX 和 Keras。
2 小时课程
开始课程学习 - 在 GKE 上使用 vLLM 来执行 Gemma 3 27B 推理本教程介绍如何使用 vLLM 部署框架部署和投放 Gemma 3 27B 大语言模型 (LLM)。您可以在 Google Kubernetes Engine (GKE) 上的单个 A4 虚拟机 (VM) 实例上部署 Gemma 3。
15 分钟指南
学习教程 - 在 A4 GKE 集群上微调 Gemma 3本教程介绍如何在 Google Cloud 上的多节点、多 GPU GKE 集群中微调 Gemma 3 大语言模型 (LLM)。此集群使用包含 8 个 NVIDIA B200 GPU 的 A4 虚拟机 (VM) 实例。
15 分钟指南
学习教程












