Novità ed eventi
Novità ed eventi
- Scopri perché Google è stata nominata Leader nel Gartner® Magic Quadrant™ per l'infrastruttura AILeggi il report per scoprire perché AI Hypercomputer è posizionato più lontano per esecuzione e vision.
- Ricevi le ultime notizie su TPUIscriviti alla nostra mailing list per essere il primo a conoscere i nuovi lanci e gli eventi TPU.
- Metti in contatto i tuoi sviluppatori con una community globaleAbbiamo appena superato i 100.000 membri nella nostra community Google Cloud x NVIDIA, il posto migliore per gli sviluppatori per entrare in contatto, condividere e imparare dai propri colleghi.
Il futuro dell'infrastruttura AI
Il futuro dell'infrastruttura AI
AI Hypercomputer è un'architettura che combina hardware appositamente progettato, software open e modelli di consumo flessibili. Ogni componente è integrato con cura per funzionare bene insieme, migliorando le prestazioni, i costi e la produttività degli sviluppatori.

Addestramento più intelligente e veloce
Addestramento più intelligente e veloce
Crea modelli in settimane, non in mesi. Utilizza lo stack di addestramento di Google per accelerare lo sviluppo e i test senza sacrificare le prestazioni.

Addestra e ottimizza gli LLM più velocemente
Sviluppa LLM più velocemente del 36% e ottieni fino al 97% di produttività (Goodput) da ogni acceleratore utilizzando TPU 8t insieme a software progettato in collaborazione con Google DeepMind e integrato con framework open source, da Pathways a Pallas (addestramento) e da Ray a Agent Sandbox (ottimizzazione). Sappiamo anche che non esiste una soluzione unica per tutti, quindi collaboriamo a stretto contatto con NVIDIA per fornire le GPU più recenti. Google Cloud sarà tra i primi a fornire istanze basate sulla NVIDIA Vera Rubin NVL72 di nuova generazione quando sarà disponibile entro la fine dell'anno.
Addestra modelli leggeri in modo più intelligente utilizzando dati proprietari
Utilizza Gemini Enterprise Agent Platform con BigQuery per addestrare i modelli sui dati proprietari 16 volte più velocemente combinando il tuo patrimonio di dati, lo sviluppo ML e gli acceleratori in un unico luogo. Entrambi sono basati su AI Hypercomputer, sia che utilizziate VM G4 o TPU Ironwood.
Crea agenti fisici adattivi con MuJoCo-Warp
Esegui simulazioni basate su GPU su MuJoCo-Warp di DeepMind, fino a 100 volte più velocemente rispetto a MuJoCo standard. Quindi simula casi limite impossibili, rischiosi o costosi utilizzando i media sintetici di Veo, Genie e Nano Banana oppure importa petabyte di dati di sensori reali in BigQuery. Scopri di più sulla creazione di agenti fisici su Google Cloud qui.
Inferenza efficiente e reattiva
Inferenza efficiente e reattiva
Ottieni profili di modello convalidati, oltre a software Google e open completamente integrati per aumentare la reattività delle applicazioni con meno complessità e sprechi.
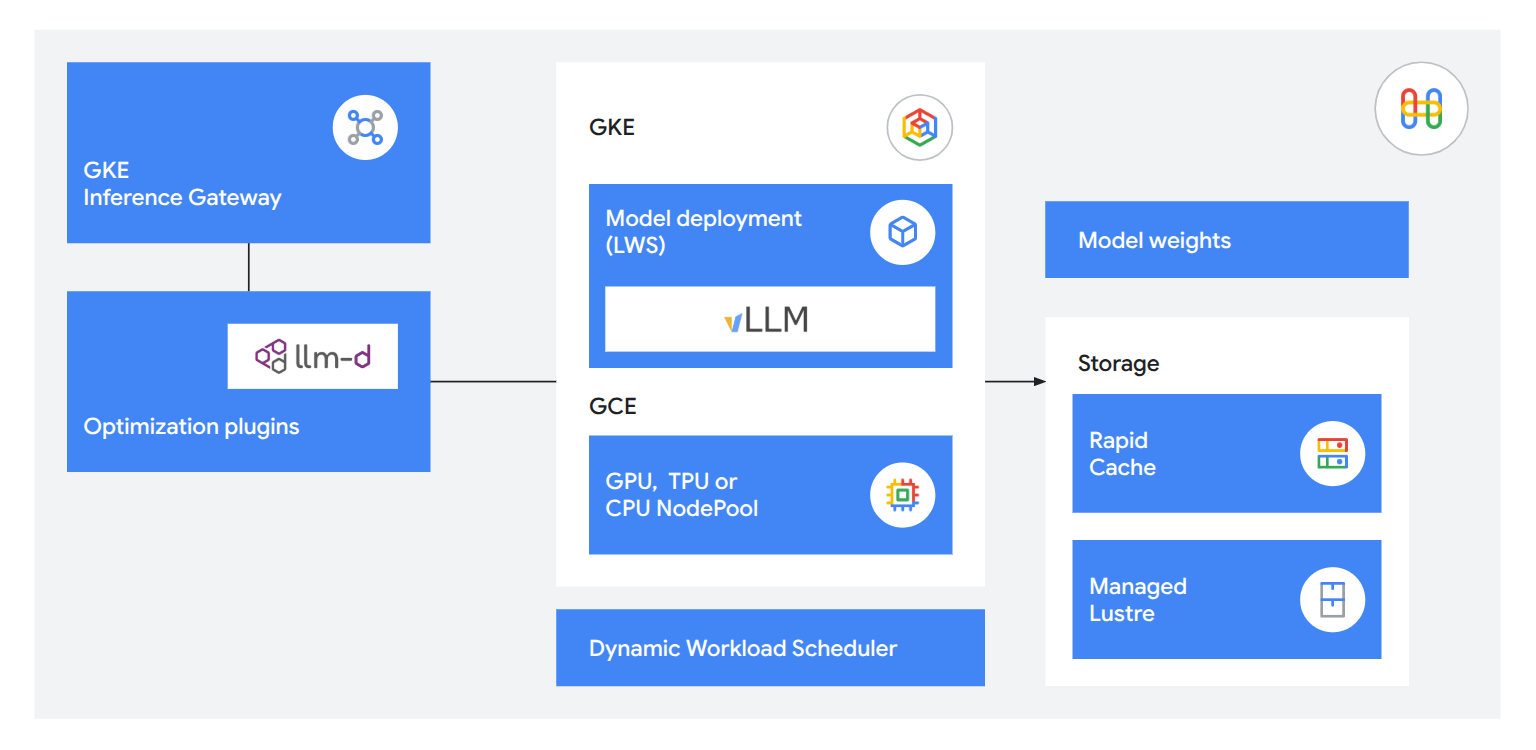
Distribuisci LLM con una latenza quasi nulla
Utilizza tecnologie di inferenza integrate per fornire servizi utili e reattivi ai clienti. Riduci il time-to-first-token del 71% con GKE Inference Gateway, distribuisci fino a 120.000 token al secondo utilizzando llm-d per la distribuzione disaggregata e carica i modelli 5 volte più velocemente utilizzando Rapid Cache e TPU 8i per mantenere la memoria di lavoro esattamente dove serve.
Pubblica modelli visivi, di percezione e multimediali predefiniti
Esegui il deployment di modelli ML classici il 70% più velocemente utilizzando uno degli oltre 200 modelli disponibili su Gemini Enterprise Agent Platform, utilizzando la TPU o la GPU che preferisci, incluse le VM A5X (NVIDIA Vera Rubin) e TPU 8i quando saranno disponibili nel corso di quest'anno.
Servi gli agenti in modo sicuro ed economico
Servi sciami di agenti in modo sicuro in GKE Agent Sandbox, eseguendo il provisioning fino a 300 sandbox al secondo e mettendo in pausa e riprendendo immediatamente secondo necessità, in modo da non pagare mai per gli agenti inattivi.
Operazioni flessibili, aperte e affidabili
Operazioni flessibili, aperte e affidabili
Utilizza qualsiasi framework o acceleratore in ambienti ibridi e multi-cloud con manutenzione e gestione automatizzate dei cluster adatte alla scala exascale.

Passa da TPU a GPU senza riscrivere il codice
TorchTPU elimina la curva di apprendimento delle TPU per gli sviluppatori fornendo supporto PyTorch nativo, in modo che tu possa utilizzare l'acceleratore migliore disponibile senza complesse riscritture di codice.
Esegui il deployment dell'AI in qualsiasi ambiente praticamente su qualsiasi scala
Basato su Kubernetes open source, GKE offre portabilità multi-cloud con scalabilità aziendale, supportando fino a 130.000 nodi e integrandosi in modo nativo con Agent Platform e Google Distributed Cloud per i deployment ibridi.
Automatizza la manutenzione dei cluster con strumenti avanzati di diagnostica e osservabilità dei cluster
Ogni acceleratore su AI Hypercomputer è supportato dalle funzionalità di Cluster Director, tra cui un bill of health pre-deployment, dashboard di osservabilità a 360 gradi e controlli di integrità sempre attivi.
Connetti carichi di lavoro multicloud in pochi minuti anziché in settimane
Collega i servizi tra cloud senza connessioni lente utilizzando Cross-Cloud Network, un backbone di rete di cui si fida oltre il 65% delle aziende Fortune 100 che sposta oltre 27 exabyte di dati al mese.
Ottieni la capacità dell'acceleratore a modo tuo
I nostri modelli di consumo flessibili ti offrono diversi modi per pianificare e ridurre il costo degli acceleratori. Risparmia fino al 91% sui job batch o a tolleranza di errore con le VM spot, fino al 50% sui job con una data di inizio flessibile utilizzando Dynamic Workload Scheduler e fino al 50% di sconto quando ti registri per gli sconti per impegno di utilizzo.
Sistemi pronti per l'agente
Sistemi pronti per l'agente
Supera i limiti delle prestazioni e usa l'energia in modo responsabile mentre esegui la scalabilità sulla base dell'infrastruttura di cui si fidano Google e i laboratori di AI all'avanguardia
Riduci i rischi della tua roadmap per l'AI su una base affidabile
Google Cloud supporta 9 dei 10 migliori laboratori di AI e il 70% delle startup di AI finanziate. Con il deployment su AI Hypercomputer, utilizzi data center che hanno elaborato in modo affidabile oltre 100 miliardi di token per quasi 350 clienti solo nel dicembre 2025.
Ottieni un'efficienza energetica leader del settore
I data center di Google Cloud, incluso AI Hypercomputer, offrono un'efficienza energetica leader del settore, con una potenza di calcolo sei volte superiore per unità di elettricità rispetto a cinque anni fa. Ciò consente alla nostra TPU di ottava generazione di offrire un rapporto prezzo/prestazioni migliore dell'80% e un'efficienza energetica superiore del 20% rispetto alla generazione precedente.
Riduci il tuo impatto sulla rete e sulle comunità
Ci impegniamo a pagare il 100% dell'energia utilizzata dai nostri data center e tutti i nuovi costi infrastrutturali direttamente determinati dalla nostra crescita. Collabora con noi per garantire che, man mano che le tue ambizioni in materia di AI crescono, le famiglie e le aziende locali non debbano pagare il conto. Nei prossimi anni, finanzieremo nuove infrastrutture e fonti di energia per i nostri modelli e continueremo a investire in fonti di energia alternative come il nucleare avanzato, la geotermia e l'accumulo a lunga durata.
Proteggi la tua PI più preziosa dai microchip fino ai dispositivi di edge computing
L'architettura Titanium con chip Titan personalizzati offre una radice di attendibilità hardware verificabile e sicurezza Zero Trust. Un'analisi indipendente di cloudvulndb.org mostra che i nostri sistemi presentano fino al 70% in meno di vulnerabilità critiche rispetto ad altri cloud leader.
Supportiamo i principali innovatori del mondo










Scopri di più su AI Hypercomputer
- IDC: il valore aziendale di AI HypercomputerQuesto report IDC esplora l'impatto reale di AI Hypercomputer sui clienti per i workload di AI. Leggi il report completo per vedere i dati dei clienti che illustrano un miglioramento del ROI del 353%, team IT più efficienti del 55% e tempi di inattività non pianificati di applicazioni/workload inferiori del 67%.
Lettura di 5 minuti
Leggi il report - Google ha ricevuto il titolo di Leader nel Gartner® Magic Quadrant™ per la categoria Strategic Cloud Platform ServicesPer l'ottavo anno consecutivo, Gartner® ha assegnato a Google il titolo di Leader nel Gartner Magic Quadrant™ per la categoria Strategic Cloud Platform Services. Quest'anno, tuttavia, segna una pietra miliare importante: Google si posiziona ora più in alto per completezza della vision.
Lettura di 5 minuti
Guarda i risultati - Google ha ricevuto il titolo di Leader nel report The Forrester Wave™: AI Infrastructure Solutions, Q1 2025Google ha ricevuto il punteggio più alto tra tutti i fornitori nella categoria Current Offering e il punteggio più alto possibile in 16 su 19 criteri di valutazione, tra cui, a titolo esemplificativo, Vision, Architecture, Training, Inferencing, Efficiency e Security.
Lettura di 5 minuti
Guarda i risultati
- Progetta ed esegui il deployment del tuo primo stack di inferenzaScopri i componenti essenziali che formano una soluzione di inferenza su Google Cloud, da GKE, Cloud TPU, TensorFlow, PyTorch, JAX e Keras.
Corso di 2 ore
Svolgi il corso - Utilizza vLLM su GKE per gestire l'inferenza di Gemma 3 27BQuesto tutorial mostra come eseguire il deployment e pubblicare un modello linguistico di grandi dimensioni (LLM) Gemma 3 27B con il framework di pubblicazione vLLM. Esegui il deployment di Gemma 3 su una singola istanza di macchina virtuale (VM) A4 su Google Kubernetes Engine (GKE).
Guida di 15 minuti
Guarda il tutorial - Ottimizza Gemma 3 su un cluster GKE A4Questo tutorial mostra come ottimizzare un modello linguistico di grandi dimensioni (LLM) Gemma 3 su un cluster GKE multi-nodo e multi-GPU su Google Cloud. Questo cluster utilizza un'istanza di macchina virtuale (VM) A4 con 8 GPU NVIDIA B200.
Guida di 15 minuti
Guarda il tutorial
- Addestra Qwen2 su un cluster Slurm A4Questo tutorial mostra come addestrare un modello linguistico di grandi dimensioni (LLM) su un cluster Slurm multi-nodo e multi-GPU su Google Cloud. Il modello che utilizzi in questo tutorial si basa su un modello Qwen2 con 1,5 miliardi di parametri. Il cluster Slurm utilizza due macchine virtuali (VM) a4-highgpu-8g, ognuna delle quali dispone di 8 GPU NVIDIA B200.
Guida di 15 minuti
Guarda il tutorial - Gestisci Qwen2-7B-Instruct con vLLM su TPUQuesto tutorial eroga il modello Qwen/Qwen2-7B-Instruct utilizzando il framework di erogazione vLLM TPU su una VM TPU v6e.
Guida di 15 minuti
Guarda il tutorial
- Inizia da quiConsulta tutta la documentazione disponibile su AI Hypercomputer, tra cui le guide su architettura, deployment, gestione, test e ottimizzazione.Leggi tutta la documentazione
- Suggerimenti di addestramentoScopri le opzioni di acceleratore, i modelli di consumo consigliati e i servizi di archiviazione da utilizzare durante il pre-addestramento dei modelli.
Lettura di 15 minuti
Leggi la documentazione - Consigli per l'inferenzaScopri le opzioni di acceleratore, i modelli di consumo consigliati e il servizio di archiviazione da utilizzare per l'inferenza.
Lettura di 15 minuti
Leggi la documentazione
Approfondimenti degli analisti
- IDC: il valore aziendale di AI HypercomputerQuesto report IDC esplora l'impatto reale di AI Hypercomputer sui clienti per i workload di AI. Leggi il report completo per vedere i dati dei clienti che illustrano un miglioramento del ROI del 353%, team IT più efficienti del 55% e tempi di inattività non pianificati di applicazioni/workload inferiori del 67%.
Lettura di 5 minuti
Leggi il report - Google ha ricevuto il titolo di Leader nel Gartner® Magic Quadrant™ per la categoria Strategic Cloud Platform ServicesPer l'ottavo anno consecutivo, Gartner® ha assegnato a Google il titolo di Leader nel Gartner Magic Quadrant™ per la categoria Strategic Cloud Platform Services. Quest'anno, tuttavia, segna una pietra miliare importante: Google si posiziona ora più in alto per completezza della vision.
Lettura di 5 minuti
Guarda i risultati - Google ha ricevuto il titolo di Leader nel report The Forrester Wave™: AI Infrastructure Solutions, Q1 2025Google ha ricevuto il punteggio più alto tra tutti i fornitori nella categoria Current Offering e il punteggio più alto possibile in 16 su 19 criteri di valutazione, tra cui, a titolo esemplificativo, Vision, Architecture, Training, Inferencing, Efficiency e Security.
Lettura di 5 minuti
Guarda i risultati
Tutorial
- Progetta ed esegui il deployment del tuo primo stack di inferenzaScopri i componenti essenziali che formano una soluzione di inferenza su Google Cloud, da GKE, Cloud TPU, TensorFlow, PyTorch, JAX e Keras.
Corso di 2 ore
Svolgi il corso - Utilizza vLLM su GKE per gestire l'inferenza di Gemma 3 27BQuesto tutorial mostra come eseguire il deployment e pubblicare un modello linguistico di grandi dimensioni (LLM) Gemma 3 27B con il framework di pubblicazione vLLM. Esegui il deployment di Gemma 3 su una singola istanza di macchina virtuale (VM) A4 su Google Kubernetes Engine (GKE).
Guida di 15 minuti
Guarda il tutorial - Ottimizza Gemma 3 su un cluster GKE A4Questo tutorial mostra come ottimizzare un modello linguistico di grandi dimensioni (LLM) Gemma 3 su un cluster GKE multi-nodo e multi-GPU su Google Cloud. Questo cluster utilizza un'istanza di macchina virtuale (VM) A4 con 8 GPU NVIDIA B200.
Guida di 15 minuti
Guarda il tutorial
- Addestra Qwen2 su un cluster Slurm A4Questo tutorial mostra come addestrare un modello linguistico di grandi dimensioni (LLM) su un cluster Slurm multi-nodo e multi-GPU su Google Cloud. Il modello che utilizzi in questo tutorial si basa su un modello Qwen2 con 1,5 miliardi di parametri. Il cluster Slurm utilizza due macchine virtuali (VM) a4-highgpu-8g, ognuna delle quali dispone di 8 GPU NVIDIA B200.
Guida di 15 minuti
Guarda il tutorial - Gestisci Qwen2-7B-Instruct con vLLM su TPUQuesto tutorial eroga il modello Qwen/Qwen2-7B-Instruct utilizzando il framework di erogazione vLLM TPU su una VM TPU v6e.
Guida di 15 minuti
Guarda il tutorial
Documentazione
- Inizia da quiConsulta tutta la documentazione disponibile su AI Hypercomputer, tra cui le guide su architettura, deployment, gestione, test e ottimizzazione.Leggi tutta la documentazione
- Suggerimenti di addestramentoScopri le opzioni di acceleratore, i modelli di consumo consigliati e i servizi di archiviazione da utilizzare durante il pre-addestramento dei modelli.
Lettura di 15 minuti
Leggi la documentazione - Consigli per l'inferenzaScopri le opzioni di acceleratore, i modelli di consumo consigliati e il servizio di archiviazione da utilizzare per l'inferenza.
Lettura di 15 minuti
Leggi la documentazione



















