Apa yang dimaksud dengan AI Hypercomputer?
Apa yang dimaksud dengan AI Hypercomputer?
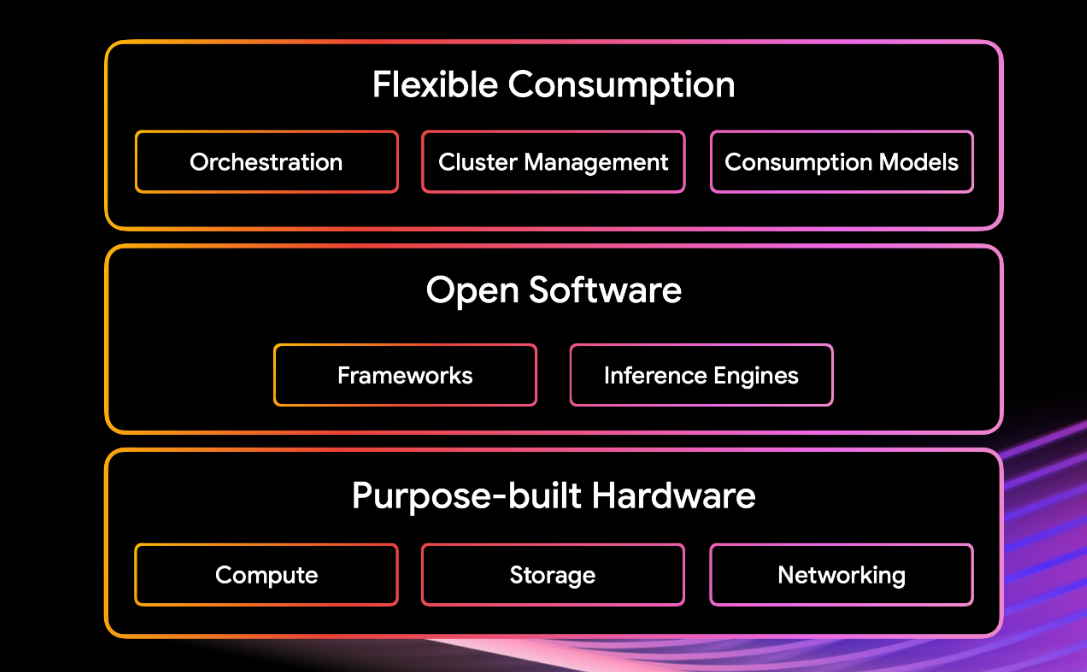
Arsitektur yang menggabungkan hardware khusus, software terbuka, dan konsumsi yang fleksibel. Setiap komponen diintegrasikan dengan cermat agar dapat bekerja sama dengan baik, sehingga meningkatkan performa, biaya, dan produktivitas developer Anda.
Lihat pengumuman terbaru (April 2026): Inovasi infrastruktur AI Google berikutnya: Penskalaan untuk era agentic
Pelatihan yang lebih cerdas dan cepat
Pelatihan yang lebih cerdas dan cepat
Bangun model dalam hitungan minggu, bukan bulan. Gunakan stack pelatihan Google untuk mempercepat pengembangan dan pengujian tanpa mengorbankan performa.

Melatih dan menyesuaikan LLM dengan lebih cepat
Kembangkan LLM 36% lebih cepat dan tingkatkan produktivitas hingga 97% (Goodput) dari setiap akselerator menggunakan TPU 8t dengan software yang dirancang bersama Google DeepMind dan diintegrasikan dengan framework open source - dari Pathways hingga Pallas (pelatihan), Ray hingga Agent Sandbox (penyesuaian). Kami juga memahami bahwa satu solusi tidak cocok untuk semua, jadi kami menjalin kerja sama secara erat dengan NVIDIA untuk menghadirkan GPU terbaru. Google Cloud akan menjadi salah satu yang pertama menghadirkan instance berdasarkan NVIDIA Vera Rubin NVL72 generasi berikutnya saat tersedia akhir tahun ini.
Latih model ringan dengan lebih cerdas menggunakan data eksklusif
Gunakan Platform Agen Gemini Enterprise dengan BigQuery untuk melatih model pada data eksklusif 16 kali lebih cepat dengan menggabungkan data estate, pengembangan ML, dan akselerator Anda di satu tempat. Keduanya didukung oleh AI Hypercomputer, baik Anda menggunakan VM G4 maupun TPU Ironwood.
Membangun agen fisik adaptif dengan MuJoCo-Warp
Jalankan simulasi berbasis GPU di MuJoCo-Warp DeepMind, hingga 100 kali lebih cepat daripada MuJoCo standar. Kemudian, simulasikan kasus ekstrem yang mustahil, berisiko, atau mahal menggunakan media sintetis dari Veo, Genie, dan Nano Banana, atau serap data sensor dunia nyata berukuran petabyte di BigQuery. Pelajari lebih lanjut cara membangun agen fisik di Google Cloud di sini.
Inferensi yang responsif dan efisien
Inferensi yang responsif dan efisien
Dapatkan profil model yang divalidasi serta software terbuka dan Google yang terintegrasi sepenuhnya untuk meningkatkan responsivitas aplikasi dengan lebih sedikit kompleksitas dan pemborosan.
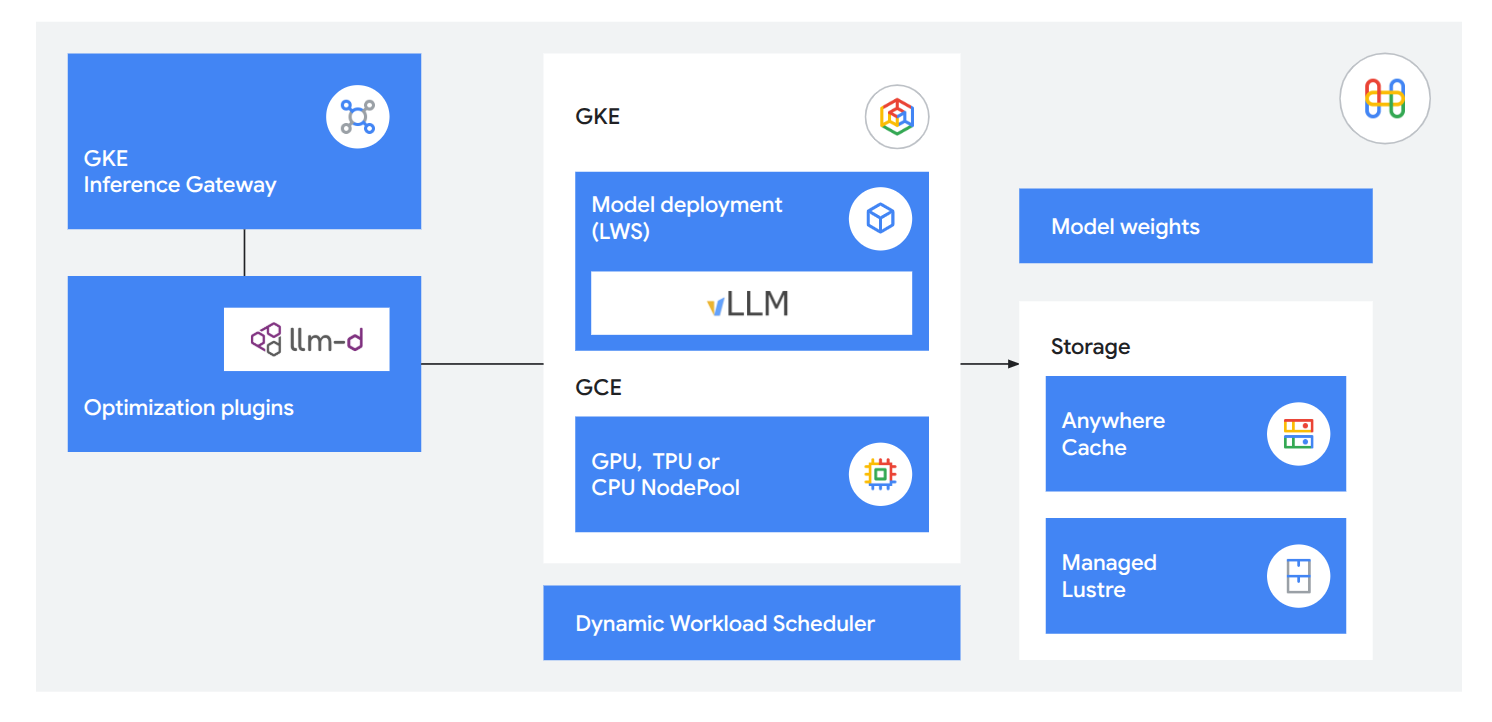
Menyajikan LLM dengan latensi hampir nol
Gunakan teknologi inferensi terintegrasi untuk memberikan layanan yang berguna dan responsif kepada pelanggan. Kurangi waktu ke token pertama sebesar 71% dengan GKE Inference Gateway, sajikan hingga 120 ribu token per detik menggunakan llm-d untuk penyajian terpisah, dan muat model 5 kali lebih cepat menggunakan Anywhere Cache dan TPU 8i untuk menyimpan memori kerja Anda tepat di tempat yang diperlukan.
Menyajikan model visual, persepsi, dan media bawaan
Deploy model ML klasik 70% lebih cepat menggunakan salah satu dari 200+ model yang tersedia di Platform Agen Gemini Enterprise, menggunakan TPU atau GPU pilihan Anda, termasuk VM A5X (NVIDIA Vera Rubin) dan TPU 8i saat tersedia akhir tahun ini.
Menyediakan agen dengan aman dan hemat biaya
Sajikan banyak agen dengan aman di GKE Agent Sandbox, yang menyediakan hingga 300 sandbox per detik sekaligus langsung menjeda dan melanjutkan sesuai kebutuhan, sehingga Anda tidak perlu membayar agen yang tidak digunakan.
Operasi yang fleksibel, terbuka, dan andal
Operasi yang fleksibel, terbuka, dan andal
Gunakan framework atau akselerator apa pun di seluruh lingkungan hybrid dan multicloud dengan pemeliharaan dan pengelolaan cluster otomatis yang dirancang untuk exascale.

Beralih antara TPU dan GPU tanpa menulis ulang kode
TorchTPU menghilangkan kurva pembelajaran TPU bagi developer dengan menyediakan dukungan PyTorch native, sehingga Anda dapat menggunakan akselerator terbaik yang tersedia tanpa perlu menulis ulang kode yang kompleks.
Men-deploy AI di lingkungan apa pun pada skala apa pun
Berdasarkan Kubernetes open source, GKE memberi Anda portabilitas multicloud dengan skala tingkat perusahaan, mendukung hingga 130.000 node sekaligus terintegrasi secara native dengan Platform Agen dan Google Distributed Cloud untuk deployment hybrid.
Mengotomatiskan pemeliharaan cluster dengan alat kemampuan observasi dan diagnostik cluster canggih
Setiap akselerator di AI Hypercomputer didukung oleh kemampuan cluster director, termasuk bill of health pra-deployment, dasbor kemampuan observasi 360 derajat, dan health check yang selalu aktif.
Menghubungkan workload multicloud dalam hitungan menit, bukan minggu
Hubungkan layanan di seluruh cloud tanpa koneksi yang lambat menggunakan Cross-Cloud Network, backbone jaringan yang dipercaya oleh lebih dari 65% perusahaan Fortune 100 yang memindahkan lebih dari 27 exabyte data per bulan.
Dapatkan kapasitas akselerator, sesuai keinginan Anda
Model pemakaian yang fleksibel kami memberi Anda beberapa cara untuk menjadwalkan dan mengurangi biaya akselerator. Hemat hingga 91% untuk tugas batch atau fault-tolerant dengan Spot VM, hingga 50% untuk tugas dengan tanggal mulai yang fleksibel menggunakan Dynamic Workload Scheduler, dan hingga 50% diskon saat Anda mendaftar diskon abonemen.
Sistem yang siap agen
Sistem yang siap agen
Dorong batas performa dan gunakan energi secara bertanggung jawab saat Anda melakukan penskalaan di fondasi infrastruktur yang dipercaya oleh Google dan Frontier AI Labs
Kurangi risiko roadmap AI Anda dengan fondasi tepercaya
Google Cloud mendukung 9 dari 10 lab AI teratas dan 70 persen startup AI yang didanai. Dengan men-deploy di AI Hypercomputer, Anda menggunakan pusat data yang memproses lebih dari 100 miliar token dengan andal di hampir 350 pelanggan hanya pada bulan Desember 2025.
Mencapai efisiensi energi terbaik di industri
Pusat data Google Cloud, termasuk AI Hypercomputer, memberikan efisiensi energi terdepan di industri, dengan daya komputasi enam kali lebih besar per unit listrik dibandingkan lima tahun lalu. Hal ini memungkinkan TPU generasi ke-8 kami memberikan rasio harga-performa 80% lebih baik dan efisiensi energi 20% lebih tinggi dibandingkan generasi sebelumnya.
Kurangi dampak Anda terhadap jaringan energi dan komunitas
Google berkomitmen untuk menanggung 100% daya yang digunakan pusat data kami dan biaya infrastruktur baru yang secara langsung dipicu oleh pertumbuhan kami. Bermitra dengan kami untuk memastikan bahwa seiring dengan meningkatnya ambisi AI Anda, rumah tangga dan bisnis lokal tidak menanggung biayanya. Dalam beberapa tahun mendatang, kami akan mendanai infrastruktur dan sumber daya baru untuk mendukung model kami, serta terus berinvestasi dalam sumber energi alternatif seperti nuklir canggih, geotermal, dan penyimpanan energi jangka panjang.
Melindungi IP Anda yang paling berharga dari silikon hingga edge
Chip Titan kustom dalam arsitektur Titanium kami memberikan root of trust hardware yang dapat diverifikasi dan keamanan zero-trust. Analisis independen dari cloudvulndb.org menunjukkan bahwa sistem kami mengalami kerentanan kritis hingga 70% lebih sedikit dibandingkan cloud terkemuka lainnya.
Mendukung para inovator terkemuka di dunia










Pelajari AI Hypercomputer lebih lanjut
- IDC: Nilai Bisnis AI HypercomputerLaporan IDC ini mengeksplorasi dampak nyata AI Hypercomputer bagi pelanggan untuk workload AI. Baca laporan lengkapnya untuk melihat data pelanggan yang menunjukkan peningkatan ROI sebesar 353%, tim IT yang 55% lebih efisien, dan 67% lebih sedikit waktu non-operasional aplikasi/workload yang tidak direncanakan.
Waktu baca: 5 menit
Baca laporannya - Google dinobatkan sebagai Pemimpin dalam Gartner® Magic Quadrant for Strategic Cloud Platform ServicesUntuk kedelapan kalinya secara berturut-turut, Gartner® menobatkan Google sebagai Pemimpin dalam Gartner Magic Quadrant™ for Strategic Cloud Platform Services. Namun, tahun ini menandai pencapaian besar: Google kini menempati posisi terdepan untuk kelengkapan visi.
Waktu baca: 5 menit
Lihat hasilnya - Google dinobatkan sebagai Pemimpin dalam The Forrester Wave™: AI Infrastructure Solutions, Q4 2025Google menerima skor tertinggi di antara semua vendor dalam kategori Current Offering dan menerima skor tertinggi yang memungkinkan dalam 16 dari 19 kriteria evaluasi, termasuk, tetapi tidak terbatas pada: Visi, Arsitektur, Pelatihan, Inferensi, Efisiensi, dan Keamanan.
Waktu baca: 5 menit
Lihat hasilnya
- Mendesain dan men-deploy stack inferensi pertama AndaPelajari komponen penting yang membentuk solusi inferensi di Google Cloud, mulai dari GKE, Cloud TPU, TensorFlow, PyTorch, JAX, dan Keras.
Kursus 2 jam
Ikuti kursus - Menggunakan vLLM di GKE untuk menyajikan inferensi Gemma 3 27BTutorial ini menunjukkan cara men-deploy dan menyajikan model bahasa besar (LLM) Gemma 3 27B dengan framework penyajian vLLM. Anda men-deploy Gemma 3 pada satu instance virtual machine (VM) A4 di Google Kubernetes Engine (GKE).
Panduan 15 menit
Ikuti tutorial - Menyesuaikan Gemma 3 di cluster GKE A4Tutorial ini menunjukkan cara menyesuaikan model bahasa besar (LLM) Gemma 3 pada cluster GKE multi-node dan multi-GPU di Google Cloud. Cluster ini menggunakan instance virtual machine (VM) A4 yang memiliki 8 GPU NVIDIA B200.
Panduan 15 menit
Ikuti tutorial
- Melatih Qwen2 di cluster Slurm A4Tutorial ini menunjukkan cara melatih model bahasa besar (LLM) pada cluster Slurm multi-node dan multi-GPU di Google Cloud. Model yang Anda gunakan dalam tutorial ini didasarkan pada model parameter Qwen2 1,5 miliar. Cluster Slurm menggunakan dua virtual machine (VM) a4-highgpu-8g, yang masing-masing memiliki 8 GPU NVIDIA B200.
Panduan 15 menit
Ikuti tutorial - Menyajikan Qwen2-7B-Instruct dengan vLLM di TPUTutorial ini menyajikan model Qwen/Qwen2-7B-Instruct menggunakan framework penyajian TPU vLLM pada VM TPU v6e.
Panduan 15 menit
Ikuti tutorial
- Mulai di siniLihat semua dokumentasi AI Hypercomputer yang tersedia, termasuk arsitektur, deployment, pengelolaan, pengujian, dan panduan pengoptimalan.Baca semua dokumentasi
- Rekomendasi pelatihanPelajari opsi akselerator, model konsumsi yang direkomendasikan, dan layanan penyimpanan yang dapat digunakan saat melakukan pra-pelatihan model.
Waktu baca: 15 menit
Baca dokumentasi - Rekomendasi inferensiPelajari opsi akselerator, model konsumsi yang direkomendasikan, dan layanan penyimpanan yang digunakan untuk inferensi.
Waktu baca: 15 menit
Baca dokumentasi
Insight analis
- IDC: Nilai Bisnis AI HypercomputerLaporan IDC ini mengeksplorasi dampak nyata AI Hypercomputer bagi pelanggan untuk workload AI. Baca laporan lengkapnya untuk melihat data pelanggan yang menunjukkan peningkatan ROI sebesar 353%, tim IT yang 55% lebih efisien, dan 67% lebih sedikit waktu non-operasional aplikasi/workload yang tidak direncanakan.
Waktu baca: 5 menit
Baca laporannya - Google dinobatkan sebagai Pemimpin dalam Gartner® Magic Quadrant for Strategic Cloud Platform ServicesUntuk kedelapan kalinya secara berturut-turut, Gartner® menobatkan Google sebagai Pemimpin dalam Gartner Magic Quadrant™ for Strategic Cloud Platform Services. Namun, tahun ini menandai pencapaian besar: Google kini menempati posisi terdepan untuk kelengkapan visi.
Waktu baca: 5 menit
Lihat hasilnya - Google dinobatkan sebagai Pemimpin dalam The Forrester Wave™: AI Infrastructure Solutions, Q4 2025Google menerima skor tertinggi di antara semua vendor dalam kategori Current Offering dan menerima skor tertinggi yang memungkinkan dalam 16 dari 19 kriteria evaluasi, termasuk, tetapi tidak terbatas pada: Visi, Arsitektur, Pelatihan, Inferensi, Efisiensi, dan Keamanan.
Waktu baca: 5 menit
Lihat hasilnya
Tutorial
- Mendesain dan men-deploy stack inferensi pertama AndaPelajari komponen penting yang membentuk solusi inferensi di Google Cloud, mulai dari GKE, Cloud TPU, TensorFlow, PyTorch, JAX, dan Keras.
Kursus 2 jam
Ikuti kursus - Menggunakan vLLM di GKE untuk menyajikan inferensi Gemma 3 27BTutorial ini menunjukkan cara men-deploy dan menyajikan model bahasa besar (LLM) Gemma 3 27B dengan framework penyajian vLLM. Anda men-deploy Gemma 3 pada satu instance virtual machine (VM) A4 di Google Kubernetes Engine (GKE).
Panduan 15 menit
Ikuti tutorial - Menyesuaikan Gemma 3 di cluster GKE A4Tutorial ini menunjukkan cara menyesuaikan model bahasa besar (LLM) Gemma 3 pada cluster GKE multi-node dan multi-GPU di Google Cloud. Cluster ini menggunakan instance virtual machine (VM) A4 yang memiliki 8 GPU NVIDIA B200.
Panduan 15 menit
Ikuti tutorial
- Melatih Qwen2 di cluster Slurm A4Tutorial ini menunjukkan cara melatih model bahasa besar (LLM) pada cluster Slurm multi-node dan multi-GPU di Google Cloud. Model yang Anda gunakan dalam tutorial ini didasarkan pada model parameter Qwen2 1,5 miliar. Cluster Slurm menggunakan dua virtual machine (VM) a4-highgpu-8g, yang masing-masing memiliki 8 GPU NVIDIA B200.
Panduan 15 menit
Ikuti tutorial - Menyajikan Qwen2-7B-Instruct dengan vLLM di TPUTutorial ini menyajikan model Qwen/Qwen2-7B-Instruct menggunakan framework penyajian TPU vLLM pada VM TPU v6e.
Panduan 15 menit
Ikuti tutorial
Dokumentasi
- Mulai di siniLihat semua dokumentasi AI Hypercomputer yang tersedia, termasuk arsitektur, deployment, pengelolaan, pengujian, dan panduan pengoptimalan.Baca semua dokumentasi
- Rekomendasi pelatihanPelajari opsi akselerator, model konsumsi yang direkomendasikan, dan layanan penyimpanan yang dapat digunakan saat melakukan pra-pelatihan model.
Waktu baca: 15 menit
Baca dokumentasi - Rekomendasi inferensiPelajari opsi akselerator, model konsumsi yang direkomendasikan, dan layanan penyimpanan yang digunakan untuk inferensi.
Waktu baca: 15 menit
Baca dokumentasi












