BiDiStreamingAnalyzeContent API 是 Conversational Agents 和 Agent Assist 中,新一代音訊和多模態體驗的主要 API。這個 API 可協助串流音訊資料,並傳回轉錄稿或真人服務專員建議。
與先前的 API 不同,簡化的音訊設定已針對人與人之間的對話進行最佳化,並將截止時間延長至 15 分鐘。除了即時翻譯,這個 API 也支援 StreamingAnalyzeContent 支援的所有 Agent Assist 功能。
串流基本概念
下圖說明串流的運作方式。
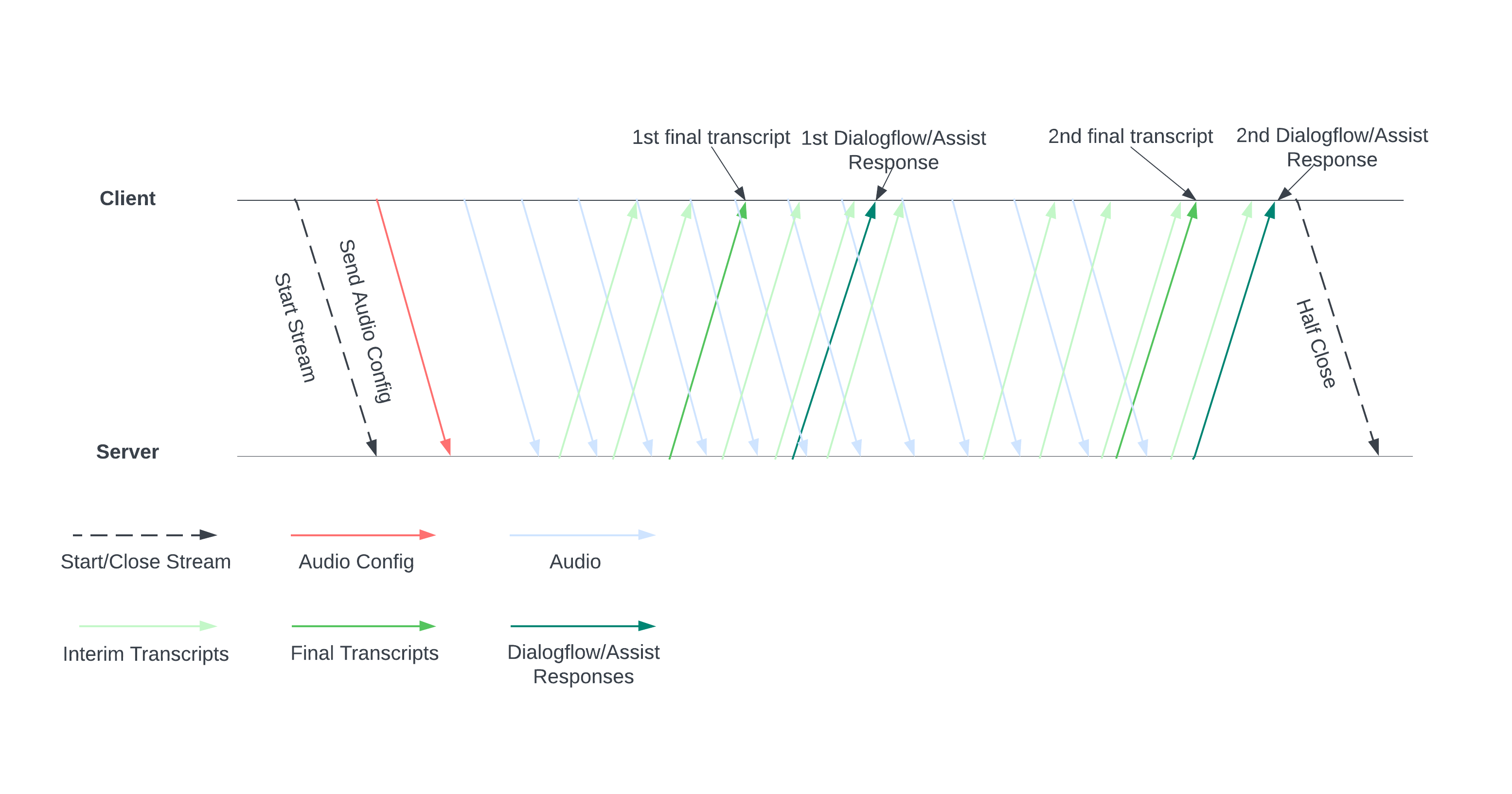
將音訊設定傳送至伺服器,即可開始串流。接著傳送音訊檔案,伺服器就會傳送轉錄稿或人工服務專員的建議。傳送更多音訊資料,即可取得更多轉錄稿和建議。這項交換作業會持續進行,直到您半關閉串流來結束作業為止。
串流指南
如要在對話執行階段使用 BiDiStreamingAnalyzeContent API,請遵循相關規定。
- 呼叫
BiDiStreamingAnalyzeContent方法並設定下列欄位:BiDiStreamingAnalyzeContentRequest.participant- (選用)
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_sample_rate_hertz(如有指定,這會覆寫ConversationProfile.stt_config.sample_rate_hertz中的設定。) - (選用)
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_encoding(如有指定,這會覆寫ConversationProfile.stt_config.audio_encoding中的設定。)
- 準備串流並透過第一個
BiDiStreamingAnalyzeContent要求設定音訊設定。 - 在後續要求中,透過
BiDiStreamingAnalyzeContentRequest.audio將音訊位元組傳送至串流。 - 傳送含有音訊酬載的第二個要求後,您應該會收到串流中的一些
BidiStreamingAnalyzeContentResponses。- 您可以使用下列指令取得中間和最終轉錄結果:
BiDiStreamingAnalyzeContentResponse.recognition_result。 - 您可以透過下列指令存取真人服務專員建議和已處理的對話訊息:
BiDiStreamingAnalyzeContentResponse.analyze_content_response。
- 您可以使用下列指令取得中間和最終轉錄結果:
- 你隨時可以半關閉串流。半關閉串流後,伺服器會傳回包含剩餘辨識結果的回應,以及可能的 Agent Assist 建議。
- 在下列情況下,請開始或重新啟動新的直播:
- 串流中斷。舉例來說,串流在不該停止時停止。
- 對話即將達到 15 分鐘的請求上限。
- 為確保音質,開始串流時,請傳送最後一個
BiDiStreamingAnalyzeContentResponse.recognition_result的is_final=true之後產生的音訊資料至BidiStreamingAnalyzeContent。speech_end_offset
透過 Python 用戶端程式庫使用 API
用戶端程式庫可協助您透過特定程式碼語言存取 Google API。您可以搭配 BidiStreamingAnalyzeContent 使用 Agent Assist 的 Python 用戶端程式庫,如下所示。
from google.cloud import dialogflow_v2beta1
from google.api_core.client_options import ClientOptions
from google.cloud import storage
import time
import google.auth
import participant_management
import conversation_management
PROJECT_ID="your-project-id"
CONVERSATION_PROFILE_ID="your-conversation-profile-id"
BUCKET_NAME="your-audio-bucket-name"
SAMPLE_RATE =48000
# Calculate the bytes with Sample_rate_hertz * bit Depth / 8 -> bytes
# 48000(sample/second) * 16(bits/sample) / 8 = 96000 byte per second,
# 96000 / 10 = 9600 we send 0.1 second to the stream API
POINT_ONE_SECOND_IN_BYTES = 9600
FOLDER_PTAH_FOR_CUSTOMER_AUDIO="your-customer-audios-files-path"
FOLDER_PTAH_FOR_AGENT_AUDIO="your-agent-audios-file-path"
client_options = ClientOptions(api_endpoint="dialogflow.googleapis.com")
credentials, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform",
"https://www.googleapis.com/auth/dialogflow"])
storage_client = storage.Client(credentials = credentials, project=PROJECT_ID)
participant_client = dialogflow_v2beta1.ParticipantsClient(client_options=client_options,
credentials=credentials)
def download_blob(bucket_name, folder_path, audio_array : list):
"""Uploads a file to the bucket."""
bucket = storage_client.bucket(bucket_name, user_project=PROJECT_ID)
blobs = bucket.list_blobs(prefix=folder_path)
for blob in blobs:
if not blob.name.endswith('/'):
audio_array.append(blob.download_as_string())
def request_iterator(participant : dialogflow_v2beta1.Participant, audios):
"""Iterate the request for bidi streaming analyze content
"""
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
"voice_session_config": {
"input_audio_encoding": dialogflow_v2beta1.AudioEncoding.AUDIO_ENCODING_LINEAR_16,
"input_audio_sample_rate_hertz": SAMPLE_RATE,
},
}
)
print(f"participant {participant}")
for i in range(0, len(audios)):
audios_array = audio_request_iterator(audios[i])
for chunk in audios_array:
if not chunk:
break
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
input={
"audio":chunk
},
)
time.sleep(0.1)
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
}
)
time.sleep(0.1)
def participant_bidi_streaming_analyze_content(participant, audios):
"""call bidi streaming analyze content API
"""
bidi_responses = participant_client.bidi_streaming_analyze_content(
requests=request_iterator(participant, audios)
)
for response in bidi_responses:
bidi_streaming_analyze_content_response_handler(response)
def bidi_streaming_analyze_content_response_handler(response: dialogflow_v2beta1.BidiStreamingAnalyzeContentResponse):
"""Call Bidi Streaming Analyze Content
"""
if response.recognition_result:
print(f"Recognition result: { response.recognition_result.transcript}", )
def audio_request_iterator(audio):
"""Iterate the request for bidi streaming analyze content
"""
total_audio_length = len(audio)
print(f"total audio length {total_audio_length}")
array = []
for i in range(0, total_audio_length, POINT_ONE_SECOND_IN_BYTES):
chunk = audio[i : i + POINT_ONE_SECOND_IN_BYTES]
array.append(chunk)
if not chunk:
break
return array
def python_client_handler():
"""Downloads audios from the google cloud storage bucket and stream to
the Bidi streaming AnalyzeContent site.
"""
print("Start streaming")
conversation = conversation_management.create_conversation(
project_id=PROJECT_ID, conversation_profile_id=CONVERSATION_PROFILE_ID_STAGING
)
conversation_id = conversation.name.split("conversations/")[1].rstrip()
human_agent = human_agent = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="HUMAN_AGENT"
)
end_user = end_user = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="END_USER"
)
end_user_requests = []
agent_request= []
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_CUSTOMER_AUDIO, end_user_requests)
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_AGENT_AUDIO, agent_request)
participant_bidi_streaming_analyze_content( human_agent, agent_request)
participant_bidi_streaming_analyze_content( end_user, end_user_requests)
conversation_management.complete_conversation(PROJECT_ID, conversation_id)
啟用電話 SipRec 整合
你可以啟用電話 SipRec 整合功能,透過 BidiStreamingAnalyzeContent 處理音訊。您可以透過 Agent Assist 控制台或直接發出 API 要求,設定音訊處理程序。
控制台
請按照下列步驟設定音訊處理程序,以使用 BidiStreamingAnalyzeContent。
前往 Agent Assist 控制台,然後選取專案。
依序點選「對話設定檔」 > 設定檔名稱。
前往「電話設定」。
按一下以啟用「使用雙向串流 API」>「儲存」。
API
您可以直接呼叫 API,在 ConversationProfile.use_bidi_streaming 設定旗標,藉此建立或更新對話設定檔。
設定範例如下:
{
"name": "projects/PROJECT_ID/locations/global/conversationProfiles/CONVERSATION_PROFILE_ID",f
"displayName": "CONVERSATION_PROFILE_NAME",
"automatedAgentConfig": {
},
"humanAgentAssistantConfig": {
"notificationConfig": {
"topic": "projects/PROJECT_ID/topics/FEATURE_SUGGESTION_TOPIC_ID",
"messageFormat": "JSON"
},
},
"useBidiStreaming": true,
"languageCode": "en-US"
}
配額
並行 BidiStreamingAnalyzeContent 要求數量受限於新的配額 ConcurrentBidiStreamingSessionsPerProjectPerRegion。如要瞭解配額用量,以及如何申請提高配額上限,請參閱 Google Cloud 配額指南。
就配額而言,對全球 Dialogflow 端點發出的 BidiStreamingAnalyzeContent 要求屬於 us-central1 地區。