BiDiStreamingAnalyzeContent API 是 Conversational Agents 和 Agent Assist 中下一代音频和多模态体验的主要 API。此 API 可实现音频数据的流式传输,并向您返回转写内容或人工客服建议。
与之前的 API 不同,简化的音频配置优化了对人际对话的支持,并将截止期限延长至 15 分钟。除了实时翻译之外,此 API 还支持 StreamingAnalyzeContent 支持的所有 Agent Assist 功能。
流式传输基础知识
下图展示了流的工作方式。
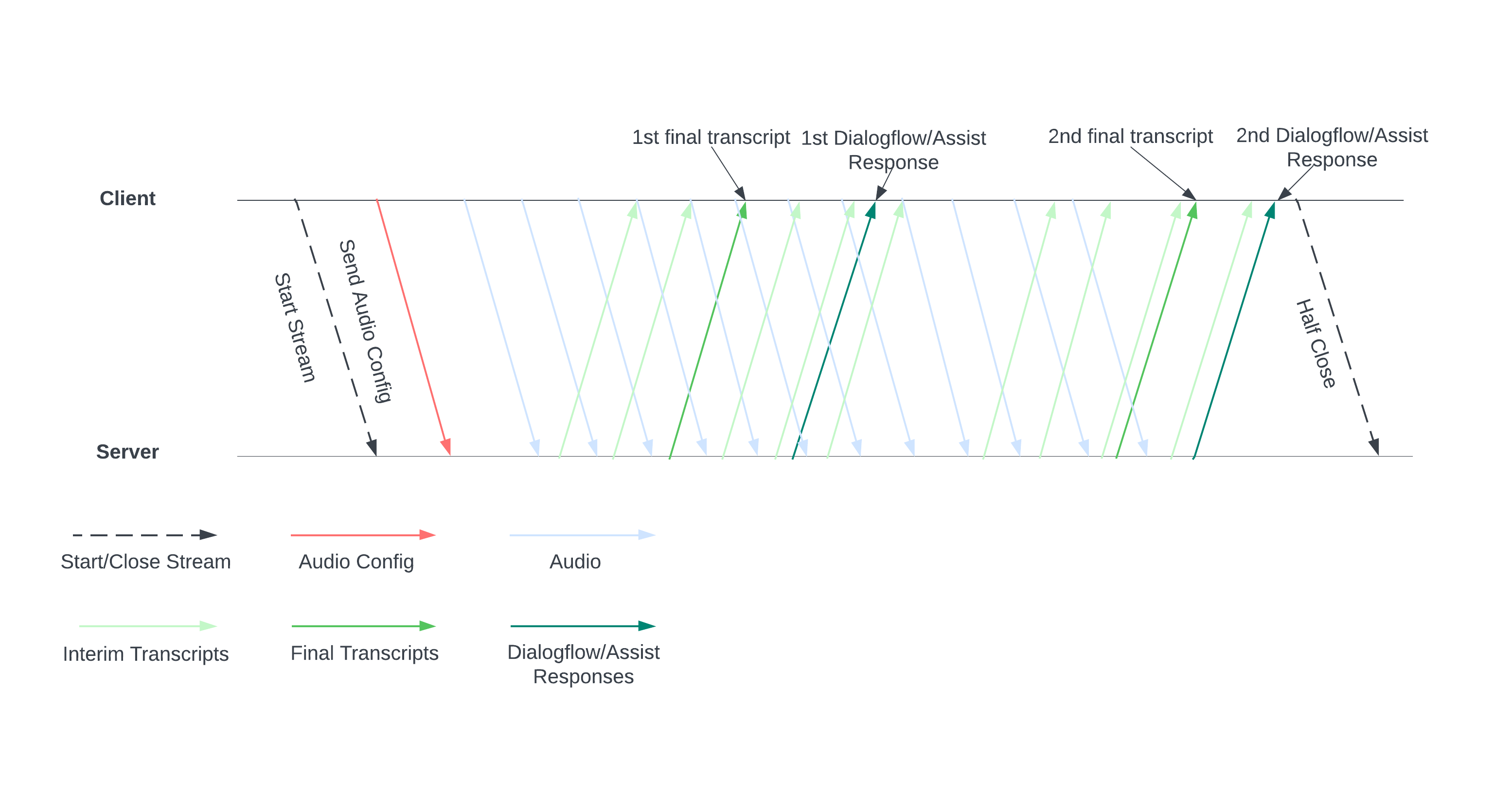
通过向服务器发送音频配置来开始直播。然后,您发送音频文件,服务器会向您发送转写内容或人工客服建议。发送更多音频数据,以获得更多转写内容和建议。此交换会一直持续,直到您通过半关闭流来结束它为止。
影视指南
如需在对话运行时使用 BiDiStreamingAnalyzeContent API,请遵循以下准则。
- 调用
BiDiStreamingAnalyzeContent方法并设置以下字段:BiDiStreamingAnalyzeContentRequest.participant- (可选)
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_sample_rate_hertz(指定后,此值会替换ConversationProfile.stt_config.sample_rate_hertz中的配置。) - (可选)
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_encoding(指定后,此值会替换ConversationProfile.stt_config.audio_encoding中的配置。)
- 通过第一个
BiDiStreamingAnalyzeContent请求准备数据流并设置音频配置。 - 在后续请求中,通过
BiDiStreamingAnalyzeContentRequest.audio将音频字节发送到流。 - 发送包含音频载荷的第二个请求后,您应该会从流中收到一些
BidiStreamingAnalyzeContentResponses。- 您可以使用以下命令获取中间转写结果和最终转写结果:
BiDiStreamingAnalyzeContentResponse.recognition_result。 - 您可以使用以下命令访问人工客服建议和已处理的对话消息:
BiDiStreamingAnalyzeContentResponse.analyze_content_response。
- 您可以使用以下命令获取中间转写结果和最终转写结果:
- 您可以随时半关闭流。在您半关闭流后,服务器会发回包含剩余识别结果以及潜在 Agent Assist 建议的响应。
- 在以下情况下,开始或重启新的直播:
- 视频流中断。例如,音频流在不应停止时停止了。
- 您的对话即将达到 15 分钟的请求时长上限。
- 为获得最佳质量,当您开始直播时,请将
BiDiStreamingAnalyzeContentResponse.recognition_result的最后一个speech_end_offset之后生成的音频数据通过is_final=true发送到BidiStreamingAnalyzeContent。
通过 Python 客户端库使用 API
借助客户端库,您可以使用特定的代码语言访问 Google API。您可以将 Python 客户端库用于 Agent Assist,并搭配 BidiStreamingAnalyzeContent 使用,如下所示。
from google.cloud import dialogflow_v2beta1
from google.api_core.client_options import ClientOptions
from google.cloud import storage
import time
import google.auth
import participant_management
import conversation_management
PROJECT_ID="your-project-id"
CONVERSATION_PROFILE_ID="your-conversation-profile-id"
BUCKET_NAME="your-audio-bucket-name"
SAMPLE_RATE =48000
# Calculate the bytes with Sample_rate_hertz * bit Depth / 8 -> bytes
# 48000(sample/second) * 16(bits/sample) / 8 = 96000 byte per second,
# 96000 / 10 = 9600 we send 0.1 second to the stream API
POINT_ONE_SECOND_IN_BYTES = 9600
FOLDER_PTAH_FOR_CUSTOMER_AUDIO="your-customer-audios-files-path"
FOLDER_PTAH_FOR_AGENT_AUDIO="your-agent-audios-file-path"
client_options = ClientOptions(api_endpoint="dialogflow.googleapis.com")
credentials, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform",
"https://www.googleapis.com/auth/dialogflow"])
storage_client = storage.Client(credentials = credentials, project=PROJECT_ID)
participant_client = dialogflow_v2beta1.ParticipantsClient(client_options=client_options,
credentials=credentials)
def download_blob(bucket_name, folder_path, audio_array : list):
"""Uploads a file to the bucket."""
bucket = storage_client.bucket(bucket_name, user_project=PROJECT_ID)
blobs = bucket.list_blobs(prefix=folder_path)
for blob in blobs:
if not blob.name.endswith('/'):
audio_array.append(blob.download_as_string())
def request_iterator(participant : dialogflow_v2beta1.Participant, audios):
"""Iterate the request for bidi streaming analyze content
"""
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
"voice_session_config": {
"input_audio_encoding": dialogflow_v2beta1.AudioEncoding.AUDIO_ENCODING_LINEAR_16,
"input_audio_sample_rate_hertz": SAMPLE_RATE,
},
}
)
print(f"participant {participant}")
for i in range(0, len(audios)):
audios_array = audio_request_iterator(audios[i])
for chunk in audios_array:
if not chunk:
break
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
input={
"audio":chunk
},
)
time.sleep(0.1)
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
}
)
time.sleep(0.1)
def participant_bidi_streaming_analyze_content(participant, audios):
"""call bidi streaming analyze content API
"""
bidi_responses = participant_client.bidi_streaming_analyze_content(
requests=request_iterator(participant, audios)
)
for response in bidi_responses:
bidi_streaming_analyze_content_response_handler(response)
def bidi_streaming_analyze_content_response_handler(response: dialogflow_v2beta1.BidiStreamingAnalyzeContentResponse):
"""Call Bidi Streaming Analyze Content
"""
if response.recognition_result:
print(f"Recognition result: { response.recognition_result.transcript}", )
def audio_request_iterator(audio):
"""Iterate the request for bidi streaming analyze content
"""
total_audio_length = len(audio)
print(f"total audio length {total_audio_length}")
array = []
for i in range(0, total_audio_length, POINT_ONE_SECOND_IN_BYTES):
chunk = audio[i : i + POINT_ONE_SECOND_IN_BYTES]
array.append(chunk)
if not chunk:
break
return array
def python_client_handler():
"""Downloads audios from the google cloud storage bucket and stream to
the Bidi streaming AnalyzeContent site.
"""
print("Start streaming")
conversation = conversation_management.create_conversation(
project_id=PROJECT_ID, conversation_profile_id=CONVERSATION_PROFILE_ID_STAGING
)
conversation_id = conversation.name.split("conversations/")[1].rstrip()
human_agent = human_agent = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="HUMAN_AGENT"
)
end_user = end_user = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="END_USER"
)
end_user_requests = []
agent_request= []
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_CUSTOMER_AUDIO, end_user_requests)
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_AGENT_AUDIO, agent_request)
participant_bidi_streaming_analyze_content( human_agent, agent_request)
participant_bidi_streaming_analyze_content( end_user, end_user_requests)
conversation_management.complete_conversation(PROJECT_ID, conversation_id)
启用电话 SipRec 集成
您可以启用电话 SipRec 集成,以使用 BidiStreamingAnalyzeContent 进行音频处理。您可以使用 Agent Assist 控制台或直接 API 请求来配置音频处理。
控制台
请按照以下步骤配置音频处理以使用 BidiStreamingAnalyzeContent。
前往 Agent Assist 控制台,然后选择您的项目。
依次点击对话个人资料 > 相应个人资料的名称。
前往电话设置。
点击以启用使用双向流式传输 API> 保存。
API
您可以通过在 ConversationProfile.use_bidi_streaming 中配置标志来直接调用 API,以创建或更新对话配置文件。
配置示例:
{
"name": "projects/PROJECT_ID/locations/global/conversationProfiles/CONVERSATION_PROFILE_ID",f
"displayName": "CONVERSATION_PROFILE_NAME",
"automatedAgentConfig": {
},
"humanAgentAssistantConfig": {
"notificationConfig": {
"topic": "projects/PROJECT_ID/topics/FEATURE_SUGGESTION_TOPIC_ID",
"messageFormat": "JSON"
},
},
"useBidiStreaming": true,
"languageCode": "en-US"
}
配额
并发 BidiStreamingAnalyzeContent 请求的数量受新配额 ConcurrentBidiStreamingSessionsPerProjectPerRegion 的限制。如需了解配额使用情况以及如何申请增加配额限制,请参阅 Google Cloud 配额指南。
对于配额,使用 BidiStreamingAnalyzeContent 请求全球 Dialogflow 端点时,请求位于 us-central1 区域。