このチュートリアルでは、Vertex AI に Meta-Llama-3.1-8B モデルをデプロイする方法について説明します。エンドポイントをデプロイし、特定のニーズに合わせて最適化する方法についても説明します。フォールト トレラントなワークロードがある場合は、Spot VM を使用してコストを最適化できます。可用性を確保する場合は、Compute Engine の予約を使用します。次のものを使用するエンドポイントをデプロイする方法を説明します。
- Spot VM: スポット プロビジョニングされたインスタンスを使用して、大幅なコスト削減を実現します。
- 予約: 予測可能なパフォーマンス(特に本番環境のワークロード)のためにリソースの可用性を保証します。このチュートリアルでは、自動(
ANY_RESERVATION)予約と特定(SPECIFIC_RESERVATION)予約の使用方法について説明します。
詳細については、Spot VM または Compute Engine リソースの予約をご覧ください。
前提条件
始める前に、次の前提条件を満たす必要があります。
- 課金が有効になっている Google Cloud プロジェクト。
- Vertex AI API と Compute Engine API が有効になっていること。
- 使用するマシンタイプとアクセラレータ(NVIDIA L4 GPU など)に十分な割り当てがあること。割り当てを確認するには、 Google Cloud コンソールの割り当てとシステム上限をご覧ください。
- Hugging Face アカウントと、読み取りアクセス権を持つユーザー アクセス トークン。
- 共有予約を使用している場合は、プロジェクト間で IAM 権限を付与します。これらの権限はすべてノートブックで説明されています。
Spot VM にデプロイする
以降のセクションでは、 Google Cloud プロジェクトの設定、Hugging Face 認証の構成、Spot VM または予約を使用した Llama-3.1 モデルのデプロイ、デプロイのテストを行うプロセスについて説明します。
1. Google Cloud プロジェクトと共有予約を設定する
Colab Enterprise ノートブックを開きます。
最初のセクションで、Colab ノートブックの PROJECT_ID、SHARED_PROJECT_ID(該当する場合)、BUCKET_URI、REGION の各変数を設定します。
このノートブックは、両方のプロジェクトのサービス アカウントに compute.viewer ロールを付与します。
同じ組織内の別のプロジェクトで作成された予約を使用する場合は、両方のプロジェクトの P4SA(プリンシパル サービス アカウント)に compute.viewer ロールを付与してください。ノートブック コードでこの処理は自動化されますが、SHARED_PROJECT_ID が正しく設定されていることを確認してください。このプロジェクト間の権限により、プライマリ プロジェクトの Vertex AI エンドポイントは、共有プロジェクトの予約容量を確認して使用できます。
2. Hugging Face 認証を設定する
Llama-3.1 モデルをダウンロードするには、Colab ノートブック内の HF_TOKEN 変数に Hugging Face ユーザー アクセス トークンを指定する必要があります。指定しないと、Cannot access gated repository for URL というエラーが表示されます。
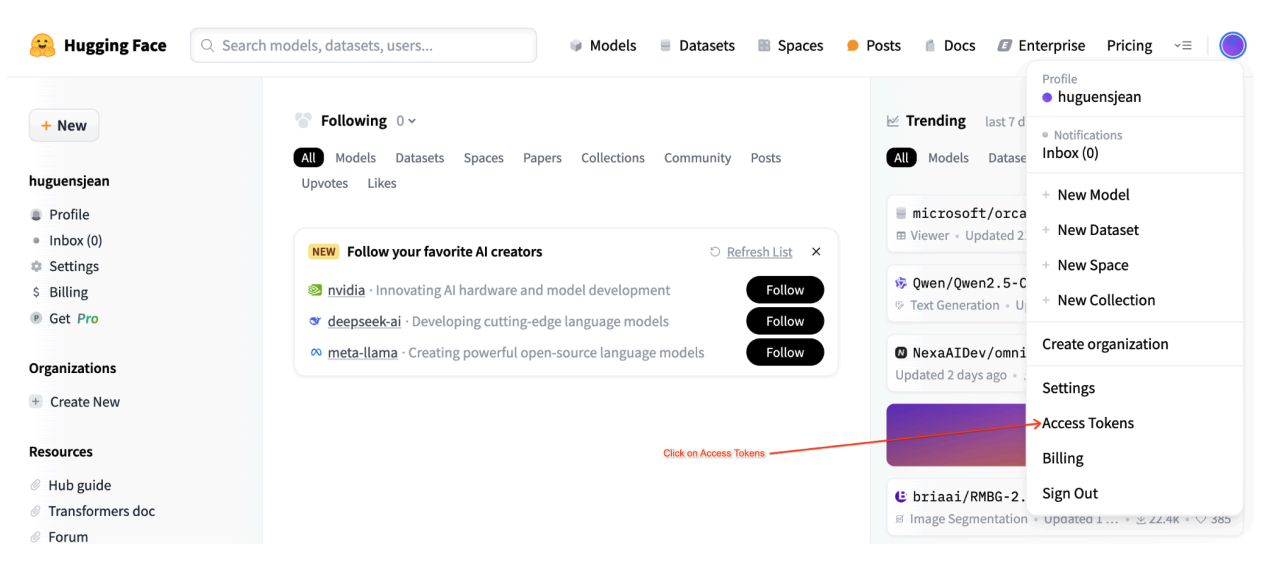 図 1: Hugging Face アクセス トークンの設定
図 1: Hugging Face アクセス トークンの設定3. Spot VM を使用してデプロイする
Llama モデルを Spot VM にデプロイするには、Colab ノートブックの [Spot VM Vertex AI Endpoint Deployment] セクションに移動して is_spot=True を設定します。
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
共有予約インスタンスにデプロイする
以降のセクションでは、共有予約の作成、予約設定の構成、ANY_RESERVATION または SPECIFIC_RESERVATION を使用した Llama-3.1 モデルのデプロイ、デプロイのテストの手順について説明します。
1. 共有予約を作成する
予約を構成するには、ノートブックの「Vertex AI 予測の予約を設定する」セクションに移動します。RES_ZONE、RESERVATION_NAME、RES_MACHINE_TYPE、RES_ACCELERATOR_TYPE、RES_ACCELERATOR_COUNT など、予約に必要な変数を設定します。
RES_ZONE を {REGION}-{availability_zone} に設定する必要があります。
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. 予約を共有する
予約には、単一プロジェクトの予約(デフォルト)と共有予約の 2 種類があります。単一プロジェクトの予約は、予約自体と同じプロジェクト内の VM でのみ使用できます。一方、共有予約は、予約が存在するプロジェクト内の VM と、予約が共有されている他のプロジェクト内の VM で使用できます。共有予約を利用すると、予約済みリソースの使用率が向上し、作成と管理が必要な予約の総数を減らすことができます。このチュートリアルでは、共有予約に焦点を当てています。詳細については、共有予約の仕組みをご覧ください。
続行する前に、図に示すように、 Google Cloud コンソールで [他の Google サービスと共有する] が選択されていることを確認してください。
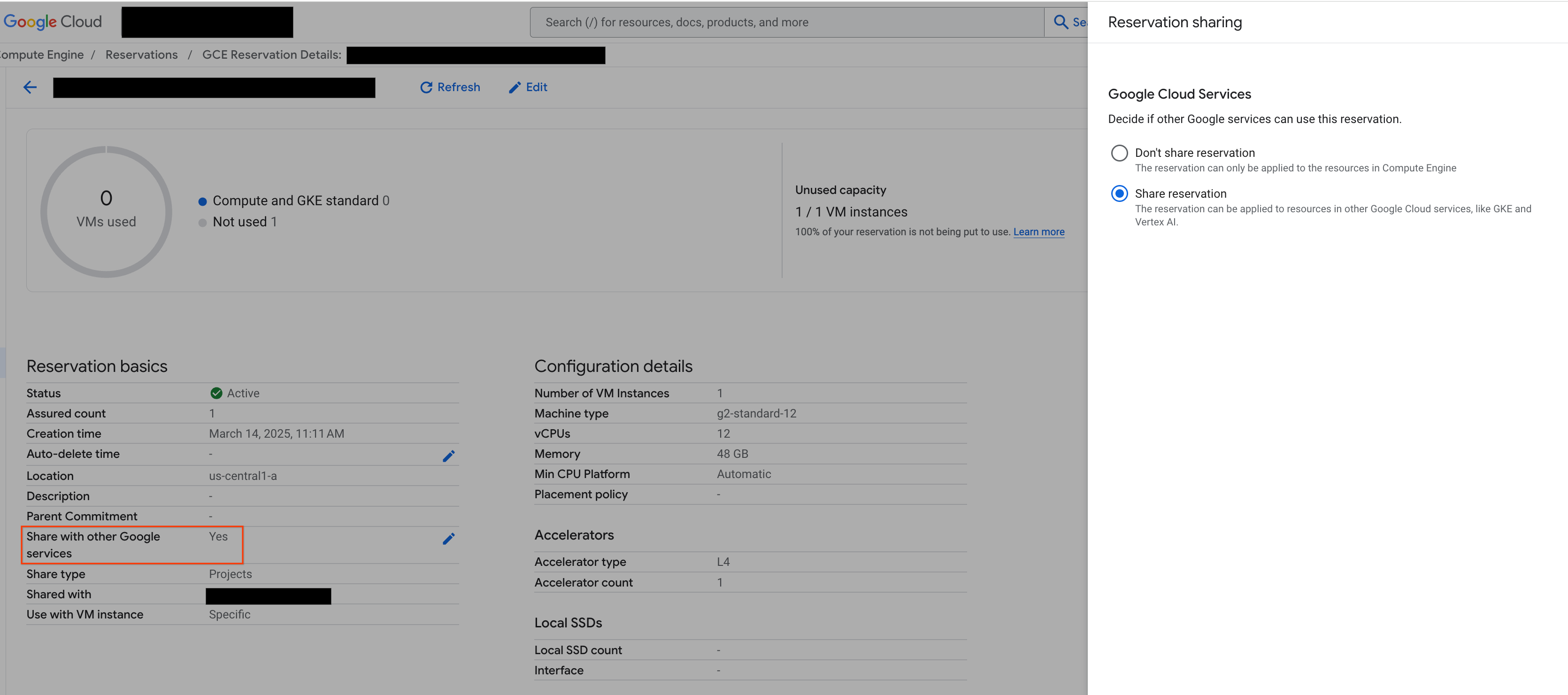 図 2: 他の Google サービスと予約を共有する
図 2: 他の Google サービスと予約を共有する3. ANY_RESERVATION でデプロイする
ANY_RESERVATION を使用してエンドポイントをデプロイするには、ノートブックの「ANY_RESERVATION を使用して Llama-3.1 エンドポイントをデプロイする」セクションに移動します。デプロイ設定を指定し、reservation_affinity_type="ANY_RESERVATION" を設定します。次に、セルを実行してエンドポイントをデプロイします。
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. ANY_RESERVATION エンドポイントをテストする
エンドポイントをデプロイしたら、いくつかのプロンプトをテストして、正しくデプロイされていることを確認します。
5. SPECIFIC_RESERVATION でデプロイする
SPECIFIC_RESERVATION を使用してエンドポイントをデプロイするには、ノートブックの「SPECIFIC_RESERVATION を使用して Llama-3.1 エンドポイントをデプロイする」セクションに移動します。reservation_name、reservation_affinity_type="SPECIFIC_RESERVATION"、reservation_project、reservation_zone の各パラメータを指定します。次に、セルを実行してエンドポイントをデプロイします。
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. SPECIFIC_RESERVATION エンドポイントをテストする
エンドポイントをデプロイしたら、予約が Vertex AI オンライン予測で使用されていることを確認し、いくつかのプロンプトをテストして、正しくデプロイされていることを確認します。
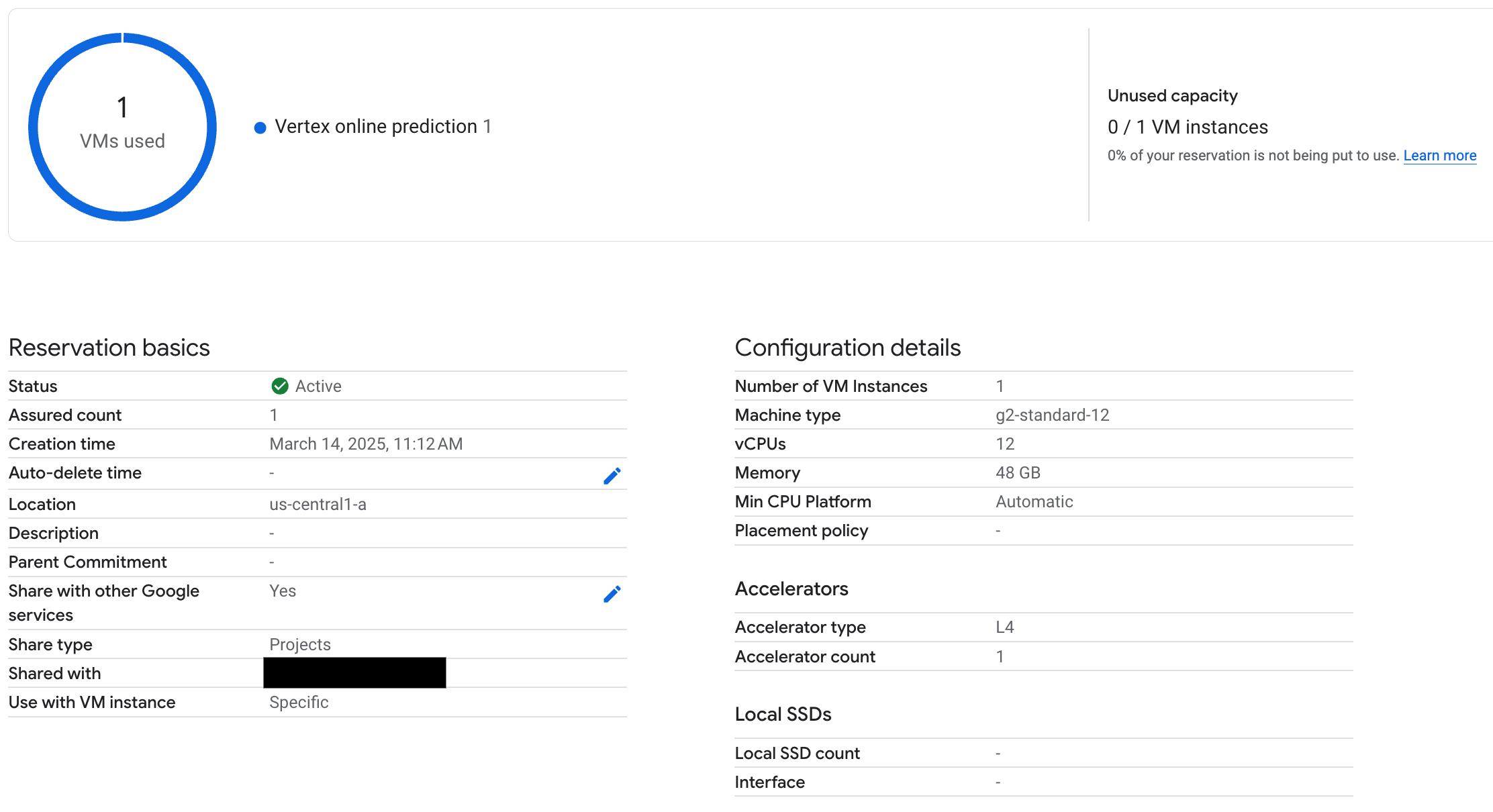 図 3: Vertex オンライン予測で予約が使用されていることを確認する
図 3: Vertex オンライン予測で予約が使用されていることを確認する7. クリーンアップ
継続的な課金が発生しないようにするには、このチュートリアルで作成したモデル、エンドポイント、予約を削除します。Colab ノートブックの [Clean Up] セクションには、このクリーンアップ プロセスを自動化するコードが用意されています。
トラブルシューティング
- Hugging Face トークンエラー: Hugging Face トークンに
read権限があり、ノートブックで正しく設定されていることを再確認します。 - 割り当てエラー: デプロイ先のリージョンに十分な GPU 割り当てがあることを確認します。必要に応じて、割り当ての増加をリクエストします。
- 予約の競合: エンドポイント デプロイのマシンタイプとアクセラレータの構成が、予約の設定と一致していることを確認します。予約が Google サービスと共有できるように有効になっていることを確認する
次のステップ
- さまざまな Llama 3 モデル バリエーションについて確認する。
- 予約の詳細を確認する。Compute Engine の予約の概要をご覧ください。
- Spot VM の詳細を確認する。Spot VM の概要をご覧ください。