Trainingsfortschritt mit Autocheckpoint beibehalten
Wenn für eine TPU-VM Wartungsarbeiten erforderlich sind, wird das Verfahren sofort eingeleitet, ohne dass Nutzer Zeit haben, Aktionen auszuführen, die den Fortschritt bewahren, z. B. einen Prüfpunkt zu speichern. Dies ist in Abbildung 1(a) dargestellt.
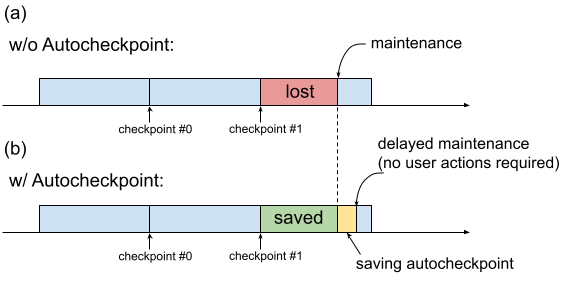
Abbildung 1. Abbildung der Autocheckpoint-Funktion: (a) Ohne Autocheckpoint geht der Trainingsfortschritt seit dem letzten Prüfpunkt verloren, wenn ein Wartungsereignis ansteht. (b) Mit Autocheckpoint kann der Trainingsfortschritt seit dem letzten Checkpoint beibehalten werden, wenn ein Wartungsereignis ansteht.
Mit Autocheckpoint (Abbildung 1(b)) können Sie den Trainingsfortschritt beibehalten, indem Sie Ihren Code so konfigurieren, dass ein nicht geplanter Prüfpunkt gespeichert wird, wenn ein Wartungsereignis eintritt. Wenn ein Wartungsereignis eintritt, wird der Fortschritt seit dem letzten Checkpoint automatisch gespeichert. Die Funktion ist sowohl für einzelne Slices als auch für Multislice verfügbar.
Die Funktion für automatische Checkpoints funktioniert mit Frameworks, die SIGTERM-Signale erfassen und anschließend einen Checkpoint speichern können. Folgende Frameworks werden unterstützt:
Autoprüfpunkt verwenden
Die Funktion „Automatische Checkpoints“ ist standardmäßig deaktiviert. Wenn Sie eine TPU erstellen oder eine in die Warteschlange gestellte Ressource anfordern, können Sie Autocheckpoint aktivieren, indem Sie beim Bereitstellen der TPU das Flag --autocheckpoint-enabled hinzufügen.
Wenn die Funktion aktiviert ist, führt Cloud TPU die folgenden Schritte aus, sobald eine Benachrichtigung über ein Wartungsereignis eingeht:
- SIGTERM-Signal erfassen, das mit dem TPU-Gerät an den Prozess gesendet wird
- Warten Sie, bis der Prozess beendet wird oder 5 Minuten vergangen sind, je nachdem, was zuerst eintritt.
- Wartung für die betroffenen Slices durchführen
Die von Autocheckpoint verwendete Infrastruktur ist unabhängig vom ML-Framework. Jedes ML-Framework kann Autocheckpoint unterstützen, wenn es das SIGTERM-Signal erfassen und einen Prüfpunktprozess initiieren kann.
Im Anwendungscode müssen Sie die vom ML-Framework bereitgestellten Autocheckpoint-Funktionen aktivieren. In Pax bedeutet das beispielsweise, beim Starten des Trainings Befehlszeilen-Flags zu aktivieren. Weitere Informationen finden Sie in der Autocheckpoint-Kurzanleitung mit Pax. Im Hintergrund speichern die Frameworks einen nicht geplanten Prüfpunkt, wenn ein SIGTERM-Signal empfangen wird. Die betroffene TPU-VM wird gewartet, wenn die TPU nicht mehr verwendet wird.
Kurzanleitung: Autoprüfpunkt mit MaxText
MaxText ist ein leistungsstarkes, beliebig skalierbares, Open-Source-LLM, das in reinem Python/JAX für Cloud TPUs geschrieben wurde und gut getestet ist. MaxText enthält alle erforderlichen Einstellungen für die Verwendung der Funktion „Automatische Checkpoints“.
In der MaxText-Datei README
werden zwei Möglichkeiten beschrieben, MaxText im großen Maßstab auszuführen:
multihost_runner.pyverwenden (für Tests empfohlen)multihost_job.pyverwenden (für die Produktion empfohlen)
Wenn Sie multihost_runner.py verwenden, aktivieren Sie Autocheckpoint, indem Sie das Flag autocheckpoint-enabled beim Bereitstellen der in die Warteschlange gestellten Ressource festlegen.
Wenn Sie multihost_job.py verwenden, aktivieren Sie Autocheckpoint, indem Sie das Befehlszeilenflag ENABLE_AUTOCHECKPOINT=true beim Starten des Jobs angeben.
Kurzanleitung: Automatische Prüfpunkte mit Pax auf einem einzelnen Slice
In diesem Abschnitt finden Sie ein Beispiel dafür, wie Sie Autocheckpoint mit Pax auf einem einzelnen Slice einrichten und verwenden. Bei entsprechender Einrichtung:
- Ein Prüfpunkt wird gespeichert, wenn ein Wartungsereignis eintritt.
- Cloud TPU führt die Wartung der betroffenen TPU-VM(s) durch, nachdem der Prüfpunkt gespeichert wurde.
- Wenn die Wartung der Cloud TPU abgeschlossen ist, können Sie die TPU-VM wie gewohnt verwenden.
Verwenden Sie das Flag
autocheckpoint-enabled, wenn Sie die TPU-VM erstellen oder eine in die Warteschlange eingereihte Ressource anfordern.Beispiel:
Legen Sie Umgebungsvariablen fest:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Beschreibungen von Umgebungsvariablen
Variable Beschreibung PROJECT_IDIhre Google Cloud Projekt-ID. Verwenden Sie ein vorhandenes Projekt oder erstellen Sie ein neues. TPU_NAMEDer Name der TPU. ZONEDie Zone, in der die TPU-VM erstellt werden soll. Weitere Informationen zu unterstützten Zonen finden Sie unter TPU-Regionen und ‑Zonen. ACCELERATOR_TYPEDer Beschleunigertyp gibt die Version und Größe der Cloud TPU an, die Sie erstellen möchten. Weitere Informationen zu den unterstützten Beschleunigertypen für die einzelnen TPU-Versionen finden Sie unter TPU-Versionen. RUNTIME_VERSIONDie Softwareversion der Cloud TPU. Legen Sie Ihre Projekt-ID und Zone in Ihrer aktiven Konfiguration fest:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
TPU erstellen:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Stellen Sie eine SSH-Verbindung zur TPU her:
gcloud compute tpus tpu-vm ssh $TPU_NAMEPax auf einem einzelnen Slice installieren
Die Funktion „Automatische Prüfpunkte“ ist in Pax-Versionen 1.1.0 und höher verfügbar. Installieren Sie auf der TPU-VM
jax[tpu]und die aktuelle Version vonpaxml:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Konfigurieren Sie das Modell
LmCloudSpmd2B. Ändern Sie vor dem Ausführen des TrainingsskriptsICI_MESH_SHAPEin[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Starten Sie das Training mit der entsprechenden Konfiguration.
Im folgenden Beispiel wird gezeigt, wie Sie das
LmCloudSpmd2B-Modell so konfigurieren, dass durch Autocheckpoint ausgelöste Checkpoints in einem Cloud Storage-Bucket gespeichert werden. Ersetzen Sie your-storage-bucket durch den Namen eines vorhandenen Buckets oder erstellen Sie einen neuen Bucket.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Beachten Sie die beiden Flags, die an den Befehl übergeben werden:
jax_fully_async_checkpoint: Wenn dieses Flag aktiviert ist, wirdorbax.checkpoint.AsyncCheckpointerverwendet. Die KlasseAsyncCheckpointerspeichert automatisch einen Prüfpunkt, wenn das Trainingsskript ein SIGTERM-Signal empfängt.exit_after_ondemand_checkpoint: Wenn dieses Flag aktiviert ist, wird der TPU-Prozess beendet, nachdem der Autoprüfpunkt erfolgreich gespeichert wurde. Dadurch wird die Wartung sofort ausgeführt. Wenn Sie dieses Flag nicht verwenden, wird das Training nach dem Speichern des Prüfpunkts fortgesetzt und die Cloud TPU wartet auf ein Zeitlimit (5 Minuten), bevor die erforderliche Wartung durchgeführt wird.
Automatische Prüfpunkte mit Orbax
Die Funktion „Automatische Checkpoints“ ist nicht auf MaxText oder Pax beschränkt. Jedes Framework, das das SIGTERM-Signal erfassen und einen Checkpointing-Prozess starten kann, funktioniert mit der von Autocheckpoint bereitgestellten Infrastruktur. Orbax, ein Namespace mit allgemeinen Dienstprogrammbibliotheken für JAX-Nutzer, bietet diese Funktionen.
Wie in der Orbax-Dokumentation erläutert, sind diese Funktionen standardmäßig für Nutzer von orbax.checkpoint.CheckpointManager aktiviert. Die save-Methode, die nach jedem Schritt aufgerufen wird, prüft automatisch, ob ein Wartungsereignis bevorsteht. Wenn dies der Fall ist, wird ein Prüfpunkt gespeichert, auch wenn die Schrittnummer kein Vielfaches von save_interval_steps ist.
In der GitHub-Dokumentation wird auch veranschaulicht, wie Sie das Training nach dem Speichern eines automatischen Checkpoints mit einer Änderung im Nutzercode beenden.