Cloud TPU-Multisegment – Übersicht
Cloud TPU Multislice ist eine Technologie zur Leistungssteigerung, mit der ein Trainingsjob mehrere TPU-Slices in einem einzelnen Slice oder auf Slices in mehreren Pods mit standardmäßiger Datenparallelität verwenden kann. Mit TPU v4-Chips können für Trainingsjobs in einem einzelnen Lauf mehr als 4.096 Chips verwendet werden. Für Trainingsjobs, für die weniger als 4.096 Chips erforderlich sind, kann ein einzelner Slice die beste Leistung bieten. Mehrere kleinere Scheiben sind jedoch leichter verfügbar, was zu einer schnelleren Startzeit führt, wenn Multislice mit kleineren Scheiben verwendet wird.
Bei der Bereitstellung in Multislice-Konfigurationen kommunizieren TPU-Chips in jedem Slice über Inter-Chip-Interconnect (ICI). TPU-Chips in verschiedenen Slices kommunizieren, indem sie Daten an CPUs (Hosts) übertragen, die die Daten wiederum über das Rechenzentrumsnetzwerk (Data Center Network, DCN) übertragen. Weitere Informationen zur Skalierung mit Multislice finden Sie unter Wie Sie KI-Training mit Multislice auf bis zu Zehntausende Cloud TPU-Chips skalieren.
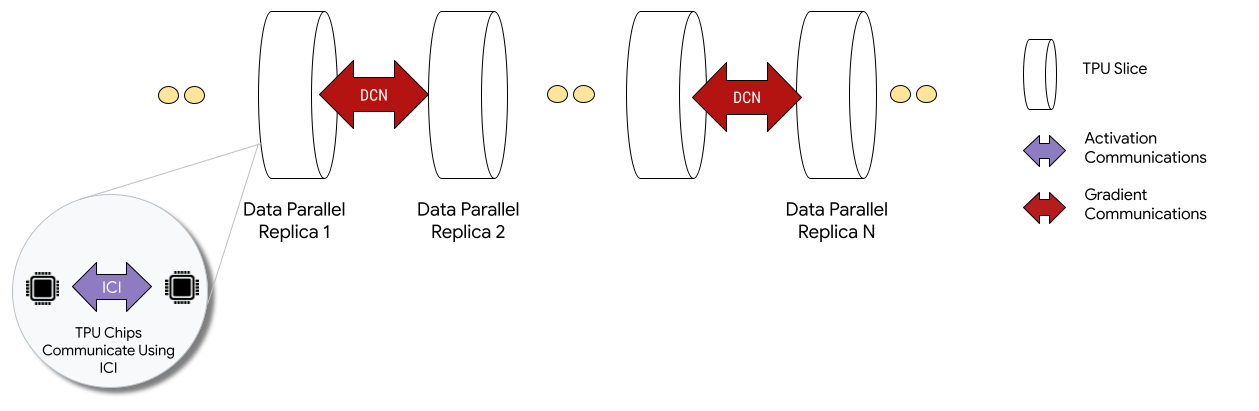
Entwickler müssen keinen Code schreiben, um die DCN-Kommunikation zwischen Slices zu implementieren. Der XLA-Compiler generiert diesen Code für Sie und überlappt die Kommunikation mit der Berechnung, um die Leistung zu maximieren.
Konzepte
- Beschleunigertyp
- Die Form jedes TPU-Slices, aus dem ein Multislice besteht. Jeder Slice in einer Anfrage mit mehreren Slices hat denselben Beschleunigertyp. Ein Beschleunigertyp besteht aus einem TPU-Typ (v4 oder höher) gefolgt von der Anzahl der Tensor-Cores.
Beispiel:
v5litepod-128gibt eine TPU v5e mit 128 TensorCores an. - Automatische Reparatur
- Wenn bei einem Slice ein Wartungsereignis, ein vorzeitiges Beenden oder ein Hardwarefehler auftritt, wird von Cloud TPU ein neuer Slice erstellt. Wenn nicht genügend Ressourcen zum Erstellen eines neuen Slice vorhanden sind, wird die Erstellung erst abgeschlossen, wenn Hardware verfügbar ist. Nachdem der neue Slice erstellt wurde, werden alle anderen Slices in der Multislice-Umgebung neu gestartet, damit das Training fortgesetzt werden kann. Mit einem richtig konfigurierten Startskript kann das Trainingsskript automatisch ohne Nutzereingriff neu gestartet werden. Dabei wird der letzte Checkpoint geladen und das Training wird fortgesetzt.
- Data Center Networking (DCN)
- Ein Netzwerk mit höherer Latenz und geringerem Durchsatz (im Vergleich zu ICI), das TPU-Slices in einer Multislice-Konfiguration verbindet.
- Gang-Planung
- Wenn alle TPU-Slices gleichzeitig bereitgestellt werden, wird garantiert, dass entweder alle oder keine der Slices erfolgreich bereitgestellt werden.
- Interchip Interconnect (ICI)
- Interne Links mit hoher Geschwindigkeit und geringer Latenz, die TPUs in einem TPU-Pod verbinden.
- Multislice
- Zwei oder mehr TPU-Chip-Slices, die über das DCN kommunizieren können.
- Knoten
- Im Kontext von Multislice bezieht sich der Begriff „Knoten“ auf ein einzelnes TPU-Slice. Jedem TPU-Slice in einem Multislice wird eine Knoten-ID zugewiesen.
- Startskript
- Ein standardmäßiges Compute Engine-Startskript, das jedes Mal ausgeführt wird, wenn eine VM gestartet oder neu gestartet wird. Bei Multislice wird sie in der Anfrage zur QR-Code-Erstellung angegeben. Weitere Informationen zu Cloud TPU-Startskripts finden Sie unter TPU-Ressourcen verwalten.
- Tensor
- Eine Datenstruktur, die verwendet wird, um mehrdimensionale Daten in einem Modell für maschinelles Lernen darzustellen.
- Arten von Cloud TPU-Kapazität
TPUs können mit verschiedenen Kapazitätstypen erstellt werden (siehe „Nutzungsoptionen“ unter So funktionieren TPU-Preise):
Reservierung: Um eine Reservierung nutzen zu können, benötigen Sie eine Reservierungsvereinbarung mit Google. Verwenden Sie beim Erstellen der Ressourcen das Flag
--reserved.Spot: Richtet sich mit Spot-VMs auf Kontingente auf Abruf. Ihre Ressourcen werden möglicherweise unterbrochen, um Platz für Anfragen für einen Job mit höherer Priorität zu schaffen. Verwenden Sie beim Erstellen von Ressourcen das Flag
--spot.On-Demand: Richtet sich an das On-Demand-Kontingent, für das keine Reservierung erforderlich ist und das nicht unterbrochen wird. Die TPU-Anfrage wird in eine On-Demand-Kontingentwarteschlange von Cloud TPU eingereiht. Die Verfügbarkeit von Ressourcen wird nicht garantiert. Standardmäßig ausgewählt, keine Flags erforderlich.
Jetzt starten
-
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelismUmgebung einrichten:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
Variablenbeschreibungen
Eingabe Beschreibung QR_ID Die vom Nutzer zugewiesene ID der in die Warteschlange eingereihten Ressource. TPU_NAME Der vom Nutzer zugewiesene Name Ihrer TPU. PROJEKT Google Cloud Projektname ZONE Gibt die Zone an, in der die Ressourcen erstellt werden sollen. NETWORK_NAME Name der VPC-Netzwerke. SUBNETWORK_NAME Name des Subnetzes in VPC-Netzwerken RUNTIME_VERSION Die Cloud TPU-Softwareversion. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … Tags, die verwendet werden, um gültige Quellen oder Ziele für Netzwerkfirewalls zu identifizieren SLICE_COUNT Anzahl der Scheiben. Die Anzahl ist auf maximal 256 Slices beschränkt. STARTUP_SCRIPT Wenn Sie ein Startskript angeben, wird es ausgeführt, wenn der TPU-Slice bereitgestellt oder neu gestartet wird. Erstellen Sie SSH-Schlüssel für
gcloud. Wir empfehlen, kein Passwort einzugeben (drücken Sie nach dem Ausführen des folgenden Befehls zweimal die Eingabetaste). Wenn Sie aufgefordert werden, die Dateigoogle_compute_enginezu ersetzen, tun Sie dies.$ ssh-keygen -f ~/.ssh/google_compute_engine
Stellen Sie Ihre TPUs bereit:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Die Google Cloud CLI unterstützt nicht alle Optionen zum Erstellen von QR-Codes, z. B. Tags. Weitere Informationen finden Sie unter QR-Codes erstellen.
Console
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf TPU erstellen.
Geben Sie im Feld Name einen Namen für Ihre TPU ein.
Wählen Sie im Feld Zone die Zone aus, in der Sie die TPU erstellen möchten.
Wählen Sie im Feld TPU-Typ einen Beschleunigertyp aus. Der Beschleunigertyp gibt die Version und Größe der Cloud TPU an, die Sie erstellen möchten. Weitere Informationen zu den unterstützten Beschleunigertypen für die einzelnen TPU-Versionen finden Sie unter TPU-Versionen.
Wählen Sie im Feld TPU-Softwareversion eine Softwareversion aus. Beim Erstellen einer Cloud TPU-VM gibt die TPU-Softwareversion die Version der zu installierenden TPU-Laufzeit an. Weitere Informationen finden Sie unter TPU-Softwareversionen.
Klicken Sie auf den Schalter Warteschlangen aktivieren.
Geben Sie im Feld Name der Ressource in der Warteschlange einen Namen für die Anfrage für die Ressource in der Warteschlange ein.
Klicken Sie auf Erstellen, um Ihre in die Warteschlange eingereihte Ressourcenanfrage zu erstellen.
Warten Sie, bis sich die Ressource in der Warteschlange im Status
ACTIVEbefindet. Das bedeutet, dass sich die Worker-Knoten im StatusREADYbefinden. Sobald die Bereitstellung der Ressource in der Warteschlange beginnt, kann es je nach Größe der Ressource ein bis fünf Minuten dauern, bis sie abgeschlossen ist. Sie können den Status einer in die Warteschlange eingereihten Ressourcenanfrage mit der gcloud CLI oder der Google Cloud -Konsole prüfen:gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
Console
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf den Tab In die Warteschlange gestellte Ressourcen.
Klicken Sie auf den Namen Ihrer in die Warteschlange eingereihten Ressourcenanfrage.
Stellen Sie eine SSH-Verbindung zur TPU-VM her:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
Klonen Sie MaxText (einschließlich
shardings.py) auf Ihre TPU-VM:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Installieren Sie Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
Erstellen und aktivieren Sie eine virtuelle Umgebung:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
Führen Sie im MaxText-Repository-Verzeichnis das Einrichtungsskript aus, um JAX und andere Abhängigkeiten auf Ihrem TPU-Slice zu installieren. Die Ausführung des Einrichtungsskripts dauert einige Minuten.
$ bash setup.sh
Führen Sie den folgenden Befehl aus, um
shardings.pyauf Ihrem TPU-Slice auszuführen.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Die Ergebnisse werden in den Logs angezeigt. Ihre TPUs sollten etwa 260 TFLOP pro Sekunde oder eine beeindruckende FLOP-Auslastung von über 90%erreichen. In diesem Fall haben wir ungefähr den maximalen Batch ausgewählt, der in den HBM (High Bandwidth Memory) der TPU passt.
Sie können auch andere Sharding-Strategien über ICI ausprobieren, z. B. die folgende Kombination:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Löschen Sie die in die Warteschlange gestellte Ressource und den TPU-Slice, wenn Sie fertig sind. Sie sollten diese Bereinigungsschritte in der Umgebung ausführen, in der Sie den Slice eingerichtet haben. Führen Sie zuerst
exitaus, um die SSH-Sitzung zu beenden. Das Löschen dauert zwei bis fünf Minuten. Wenn Sie die gcloud CLI verwenden, können Sie diesen Befehl mit dem optionalen Flag--asyncim Hintergrund ausführen.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
Console
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf den Tab In die Warteschlange gestellte Ressourcen.
Klicken Sie das Kästchen neben Ihrem in der Warteschlange befindlichen Ressourcenantrag an.
Klicken Sie auf Löschen.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
Klonen Sie MaxText auf Ihrem Runner-Computer:
$ git clone https://github.com/AI-Hypercomputer/maxtext
Wechseln Sie in das Repository-Verzeichnis.
$ cd maxtext
Erstellen Sie SSH-Schlüssel für
gcloud. Wir empfehlen, das Passwortfeld leer zu lassen (drücken Sie nach dem Ausführen des folgenden Befehls zweimal die Eingabetaste). Wenn Sie aufgefordert werden, die Dateigoogle_compute_enginezu ändern, wählen Sie aus, dass Sie die vorhandene Version nicht beibehalten möchten.$ ssh-keygen -f ~/.ssh/google_compute_engine
Fügen Sie eine Umgebungsvariable hinzu, um die Anzahl der TPU-Slices auf
2festzulegen.$ export SLICE_COUNT=2
Erstellen Sie eine Multislice-Umgebung mit dem
queued-resources create-Befehl oder der Google Cloud Console.gcloud
Der folgende Befehl zeigt, wie Sie eine Multislice-TPU vom Typ v5e erstellen. Wenn Sie eine andere TPU-Version verwenden möchten, geben Sie eine andere
accelerator-typeundruntime-versionan.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
Console
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf TPU erstellen.
Geben Sie im Feld Name einen Namen für Ihre TPU ein.
Wählen Sie im Feld Zone die Zone aus, in der Sie die TPU erstellen möchten.
Wählen Sie im Feld TPU-Typ einen Beschleunigertyp aus. Der Beschleunigertyp gibt die Version und Größe der Cloud TPU an, die Sie erstellen möchten. Multi-Slice wird nur für Cloud TPU v4 und höhere TPU-Versionen unterstützt. Weitere Informationen zu TPU-Versionen finden Sie unter TPU-Versionen.
Wählen Sie im Feld TPU-Softwareversion eine Softwareversion aus. Beim Erstellen einer Cloud TPU-VM gibt die TPU-Softwareversion die Version der TPU-Laufzeit an, die auf den TPU-VMs installiert werden soll. Weitere Informationen finden Sie unter TPU-Softwareversionen.
Klicken Sie auf den Schalter Warteschlangen aktivieren.
Geben Sie im Feld Name der Ressource in der Warteschlange einen Namen für die Anfrage für die Ressource in der Warteschlange ein.
Klicken Sie das Kästchen Multislice-TPU erstellen an.
Geben Sie im Feld Anzahl der Segmentierungen die Anzahl der Segmentierungen ein, die Sie erstellen möchten.
Klicken Sie auf Erstellen, um Ihre in die Warteschlange eingereihte Ressourcenanfrage zu erstellen.
Wenn die Bereitstellung der Ressource in der Warteschlange beginnt, kann es je nach Größe der Ressource bis zu fünf Minuten dauern, bis sie abgeschlossen ist. Warten Sie, bis sich die in die Warteschlange eingereihte Ressource im Status
ACTIVEbefindet. Sie können den Status einer in die Warteschlange eingereihten Ressourcenanfrage mit der gcloud CLI oder der Google Cloud -Konsole prüfen:gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
Die Ausgabe sollte in etwa so aussehen:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
Console
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf den Tab In die Warteschlange gestellte Ressourcen.
Klicken Sie auf den Namen Ihrer in die Warteschlange eingereihten Ressourcenanfrage.
Wenden Sie sich an Ihren Google Cloud Kundenbetreuer, wenn der QR-Status länger als 15 Minuten den Status
WAITING_FOR_RESOURCESoderPROVISIONINGhat.Installieren Sie die Abhängigkeiten:
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
Führen Sie
shardings.pyauf jedem Worker mitmultihost_runner.pyaus.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
In den Logdateien werden etwa 230 TFLOPs pro Sekunde angezeigt.
Weitere Informationen zum Konfigurieren der Parallelität finden Sie unter Multislice-Sharding mit DCN-Parallelität und
shardings.py.Bereinigen Sie die TPUs und die in die Warteschlange gestellte Ressource, wenn Sie fertig sind. Das Löschen dauert zwei bis fünf Minuten. Wenn Sie die gcloud CLI verwenden, können Sie diesen Befehl mit dem optionalen Flag
--asyncim Hintergrund ausführen.- Verwenden Sie beim Erstellen des Mesh jax.experimental.mesh_utils.create_hybrid_device_mesh anstelle von jax.experimental.mesh_utils.create_device_mesh.
- Mit dem Testlauf-Skript
multihost_runner.py - Mit dem Produktionsrunner-Skript
multihost_job.py - Manueller Ansatz
Erstellen Sie mit dem folgenden Befehl eine Anfrage für eine Ressource in der Warteschlange:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
Erstellen Sie eine Datei mit dem Namen
queued-resource-req.jsonund kopieren Sie den folgenden JSON-Code hinein.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
Ersetzen Sie die folgenden Werte:
- your-project-number – Ihre Google Cloud Projektnummer
- your-zone: Die Zone, in der Sie die in die Warteschlange eingereihte Ressource erstellen möchten.
- accelerator-type: Die Version und Größe eines einzelnen Slices. Multi-Slice wird nur auf Cloud TPU v4 und späteren TPU-Versionen unterstützt.
- tpu-vm-runtime-version: Die TPU VM-Laufzeitversion, die Sie verwenden möchten.
- your-network-name – Optional: ein Netzwerk, an das die in die Warteschlange gestellte Ressource angehängt wird
- your-subnetwork-name – Optional: Ein Subnetzwerk, an das die in die Warteschlange gestellte Ressource angehängt wird
- example-tag-1 – Optional, ein beliebiger Tag-String
- your-startup-script: Ein Startskript, das ausgeführt wird, wenn die in die Warteschlange eingestellte Ressource zugewiesen wird.
- slice-count: Die Anzahl der TPU-Slices in Ihrer Multislice-Umgebung.
- your-queued-resource-id: Die vom Nutzer bereitgestellte ID für die in die Warteschlange gestellte Ressource
Weitere Informationen zu allen verfügbaren Optionen finden Sie in der Dokumentation zur REST Queued Resource API.
Wenn Sie Spot-Kapazität verwenden möchten, ersetzen Sie:
"guaranteed": { "reserved": true }mit"spot": {}Entfernen Sie die Zeile, um die standardmäßige On-Demand-Kapazität zu verwenden.
Senden Sie die in die Warteschlange eingereihte Anfrage zum Erstellen der Ressource mit der JSON-Nutzlast:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
Ersetzen Sie die folgenden Werte:
- your-project-id: Ihre Google Cloud -Projekt-ID
- your-zone: Die Zone, in der Sie die in die Warteschlange eingereihte Ressource erstellen möchten.
- your-queued-resource-id: Die vom Nutzer bereitgestellte ID für die in die Warteschlange gestellte Ressource
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf TPU erstellen.
Geben Sie im Feld Name einen Namen für Ihre TPU ein.
Wählen Sie im Feld Zone die Zone aus, in der Sie die TPU erstellen möchten.
Wählen Sie im Feld TPU-Typ einen Beschleunigertyp aus. Der Beschleunigertyp gibt die Version und Größe der Cloud TPU an, die Sie erstellen möchten. Multi-Slice wird nur auf Cloud TPU v4 und höheren TPU-Versionen unterstützt. Weitere Informationen zu den unterstützten Beschleunigertypen für die einzelnen TPU-Versionen finden Sie unter TPU-Versionen.
Wählen Sie im Feld TPU-Softwareversion eine Softwareversion aus. Beim Erstellen einer Cloud TPU-VM gibt die TPU-Softwareversion die Version der zu installierenden TPU-Laufzeit an. Weitere Informationen finden Sie unter TPU-Softwareversionen.
Klicken Sie auf den Schalter Warteschlangen aktivieren.
Geben Sie im Feld Name der Ressource in der Warteschlange einen Namen für die Anfrage für die Ressource in der Warteschlange ein.
Klicken Sie das Kästchen Multislice-TPU erstellen an.
Geben Sie im Feld Anzahl der Segmentierungen die Anzahl der Segmentierungen ein, die Sie erstellen möchten.
Klicken Sie auf Erstellen, um Ihre in die Warteschlange eingereihte Ressourcenanfrage zu erstellen.
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf den Tab In die Warteschlange gestellte Ressourcen.
Klicken Sie auf den Namen Ihrer in die Warteschlange eingereihten Ressourcenanfrage.
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf den Tab In die Warteschlange gestellte Ressourcen.
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf den Tab In die Warteschlange gestellte Ressourcen.
Klicken Sie das Kästchen neben Ihrem in der Warteschlange befindlichen Ressourcenantrag an.
Klicken Sie auf Löschen.
- B ist die Batchgröße in Tokens.
- P ist die Anzahl der Parameter.
- Es kommt zur „Pipeline-Blase“, bei der Chips inaktiv sind, weil sie auf Daten warten.
- Dazu ist Micro-Batching erforderlich, wodurch die effektive Batch-Größe, die arithmetische Intensität und letztendlich die FLOP-Auslastung des Modells verringert werden.
Wenn Sie Multislice verwenden möchten, müssen Ihre TPU-Ressourcen als Ressourcen in der Warteschlange verwaltet werden.
Einführungsbeispiel
In dieser Anleitung wird Code aus dem MaxText-GitHub-Repository verwendet. MaxText ist ein leistungsstarkes, beliebig skalierbares, Open-Source- und gut getestetes grundlegendes LLM, das in Python und Jax geschrieben wurde. MaxText wurde für effizientes Training auf Cloud TPU entwickelt.
Der Code in shardings.py
soll Ihnen den Einstieg in die verschiedenen Parallelitätsoptionen erleichtern. Dazu gehören beispielsweise Datenparallelität, vollständig fragmentierte Datenparallelität (Fully Sharded Data Parallelism, FSDP) und Tensorparallelität. Der Code lässt sich von Single-Slice- auf Multislice-Umgebungen skalieren.
ICI-Parallelität
ICI bezieht sich auf die Hochgeschwindigkeitsverbindung, die die TPUs in einem einzelnen Slice verbindet. ICI-Sharding entspricht dem Sharding innerhalb eines Segments. shardings.py bietet drei Parameter für die Parallelität von Inkrementalität und Konversion:
Die Werte, die Sie für diese Parameter angeben, bestimmen die Anzahl der Shards für jede Parallelisierungsmethode.
Diese Eingaben müssen so eingeschränkt werden, dass ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism der Anzahl der Chips im Segment entspricht.
In der folgenden Tabelle finden Sie Beispiele für Nutzereingaben für die ICI-Parallelität für die vier in v4-8 verfügbaren Chips:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| 4-Wege-FSDP | 1 | 4 | 1 |
| 4-Wege-Tensor-Parallelität | 1 | 1 | 4 |
| 2-way FSDP + 2-way Tensor-Parallelität | 1 | 2 | 2 |
Hinweis: ici_data_parallelism sollte in den meisten Fällen auf 1 belassen werden, da das ICI-Netzwerk schnell genug ist, um FSDP fast immer der Datenparallelität vorzuziehen.
In diesem Beispiel wird davon ausgegangen, dass Sie mit dem Ausführen von Code auf einem einzelnen TPU-Slice vertraut sind, wie in Berechnung auf einer Cloud TPU-VM mit JAX ausführen beschrieben.
In diesem Beispiel wird gezeigt, wie Sie shardings.py für einen einzelnen Slice ausführen.
Multislice-Sharding mit DCN-Parallelität
Das Skript shardings.py verwendet drei Parameter, die die DCN-Parallelität angeben und der Anzahl der Shards der einzelnen Arten von Datenparallelität entsprechen:
Die Werte dieser Parameter müssen so eingeschränkt werden, dass dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism der Anzahl der Slices entspricht.
Verwenden Sie als Beispiel für zwei Slices --dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | Anzahl der Slices | |
| Bidirektionale Datenparallelität | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism sollte immer auf 1 festgelegt werden, da das DCN für ein solches Sharding nicht geeignet ist. Bei typischen LLM-Arbeitslasten auf v4-Chips sollte dcn_fsdp_parallelism auch auf 1 gesetzt werden. Daher sollte dcn_data_parallelism auf die Anzahl der Slices gesetzt werden. Dies ist jedoch anwendungsabhängig.
Wenn Sie die Anzahl der Slices erhöhen (vorausgesetzt, Sie behalten die Slice-Größe und den Batch pro Slice konstant), erhöhen Sie den Grad des Datenparallelismus.
shardings.py in einer Multislice-Umgebung ausführen
Sie können shardings.py in einer Multislice-Umgebung mit multihost_runner.py oder durch Ausführen von shardings.py auf jeder TPU-VM ausführen. Hier verwenden wir multihost_runner.py. Die folgenden Schritte ähneln sehr denen in Getting Started: Quick Experiments on Multiple slices aus dem MaxText-Repository. Hier führen wir jedoch shardings.py anstelle des komplexeren LLM in train.py aus.
Das multihost_runner.py-Tool ist für schnelle Tests optimiert, bei denen dieselben TPUs wiederholt verwendet werden. Da das multihost_runner.py-Script von langlebigen SSH-Verbindungen abhängt, empfehlen wir es nicht für Jobs mit langer Ausführungszeit.
Wenn Sie einen längeren Job ausführen möchten (z. B. über Stunden oder Tage), empfehlen wir Ihnen, multihost_job.py zu verwenden.
In dieser Anleitung verwenden wir den Begriff Runner für den Computer, auf dem Sie das multihost_runner.py-Skript ausführen. Wir verwenden den Begriff Worker für die TPU-VMs, aus denen Ihre Slices bestehen. Sie können multihost_runner.py auf einem lokalen Computer oder einer beliebigen Compute Engine-VM im selben Projekt wie Ihre Slices ausführen. Die Ausführung von multihost_runner.py auf einem Worker wird nicht unterstützt.
multihost_runner.py stellt automatisch eine SSH-Verbindung zu TPU-Workern her.
In diesem Beispiel führen Sie shardings.py für zwei v5e-16-Segmente aus, also insgesamt vier VMs und 16 TPU-Chips. Sie können das Beispiel so ändern, dass es auf mehr TPUs ausgeführt wird.
Umgebung einrichten
Arbeitslast auf Multislice skalieren
Bevor Sie Ihr Modell in einer Multislice-Umgebung ausführen, nehmen Sie die folgenden Codeänderungen vor:
Das sollten die einzigen erforderlichen Codeänderungen bei der Umstellung auf Multislice sein. Um eine hohe Leistung zu erzielen, muss DCN auf datenparallele, vollständig shard-parallele oder pipelineparallele Achsen abgebildet werden. Überlegungen zur Leistung und Sharding-Strategien werden ausführlicher unter Sharding mit Multislice für maximale Leistung beschrieben.
Um zu prüfen, ob Ihr Code auf alle Geräte zugreifen kann, können Sie bestätigen, dass len(jax.devices()) der Anzahl der Chips in Ihrer Multislice-Umgebung entspricht. Wenn Sie beispielsweise vier Slices von v4-16 verwenden, haben Sie acht Chips pro Slice × 4 Slices. len(jax.devices()) sollte also 32 zurückgeben.
Slice-Größen für Multislice-Umgebungen auswählen
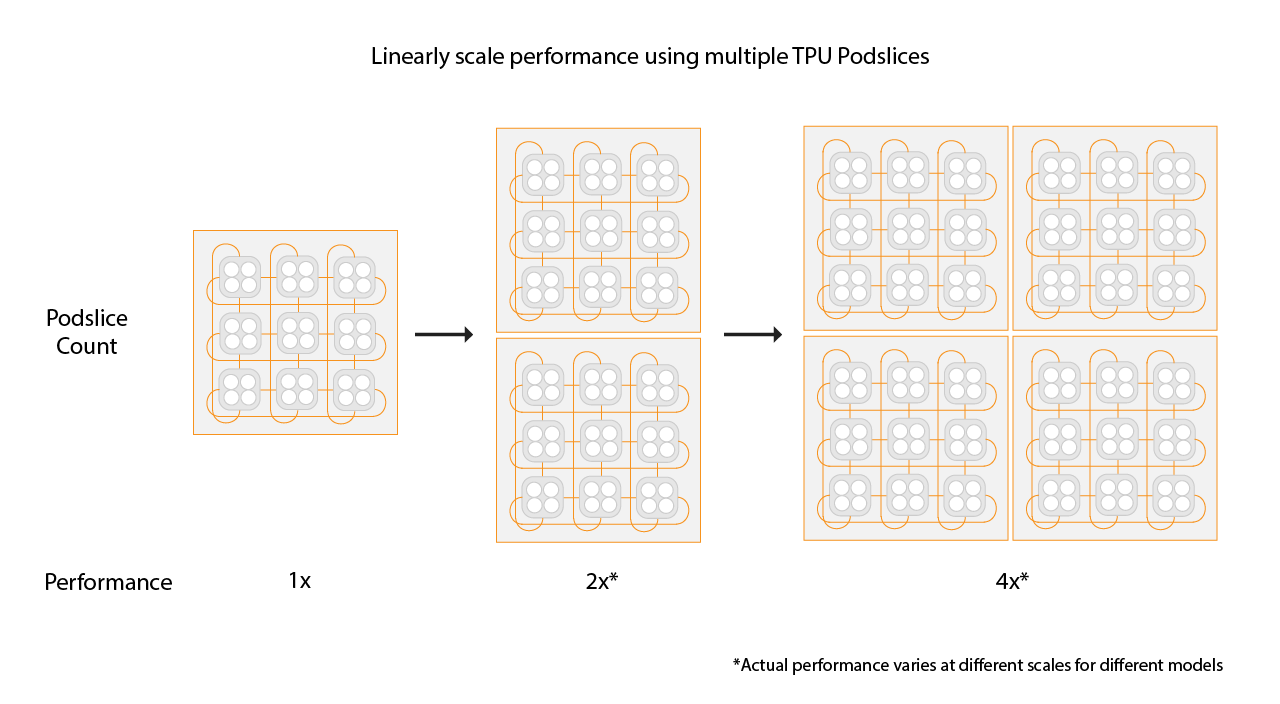
Wenn Sie eine lineare Steigerung erzielen möchten, fügen Sie neue Slices mit derselben Größe wie Ihr vorhandener Slice hinzu. Wenn Sie beispielsweise einen v4-512-Slice verwenden, wird durch Hinzufügen eines zweiten v4-512-Slice und Verdoppeln der globalen Batchgröße mit Multislice etwa die doppelte Leistung erzielt. Weitere Informationen finden Sie unter Sharding mit Multislice für maximale Leistung.
Job auf mehreren Slices ausführen
Es gibt drei verschiedene Ansätze, um Ihre benutzerdefinierte Arbeitslast in einer Multislice-Umgebung auszuführen:
Script für die Testausführung
Das multihost_runner.py-Script verteilt Code an eine vorhandene Multislice-Umgebung, führt Ihren Befehl auf jedem Host aus, kopiert Ihre Logs zurück und verfolgt den Fehlerstatus jedes Befehls. Das multihost_runner.py-Skript wird in der README-Datei für MaxText dokumentiert.
Da multihost_runner.py persistente SSH-Verbindungen aufrechterhält, eignet es sich nur für Experimente mit geringem Umfang und relativ kurzer Laufzeit. Sie können die Schritte im multihost_runner.py-Tutorial an Ihre Arbeitslast und Hardwarekonfiguration anpassen.
Produktions-Runner-Script
Für Produktionsjobs, die gegen Hardwarefehler und andere Unterbrechungen geschützt werden müssen, ist es am besten, die Create Queued Resource API direkt zu verwenden. Verwenden Sie multihost_job.py als Arbeitsbeispiel, das den API-Aufruf „Created Queued Resource“ mit dem entsprechenden Startskript auslöst, um das Training auszuführen und nach einer Unterbrechung fortzusetzen. Das multihost_job.py-Script ist in der README-Datei für MaxText dokumentiert.
Da multihost_job.py für jeden Lauf Ressourcen bereitstellen muss, ist der Iterationszyklus nicht so schnell wie bei multihost_runner.py.
Manueller Ansatz
Wir empfehlen, multihost_runner.py oder multihost_job.py zu verwenden oder anzupassen, um Ihre benutzerdefinierte Arbeitslast in Ihrer Multislice-Konfiguration auszuführen. Wenn Sie Ihre Umgebung lieber direkt mit QR-Befehlen bereitstellen und verwalten möchten, lesen Sie den Abschnitt Multislice-Umgebung verwalten.
Multislice-Umgebung verwalten
Wenn Sie QRs manuell bereitstellen und verwalten möchten, ohne die Tools im MaxText-Repository zu verwenden, lesen Sie die folgenden Abschnitte.
In die Warteschlange gestellte Ressourcen erstellen
gcloud
Achten Sie darauf, dass Sie das entsprechende Kontingent haben, bevor Sie --reserved, --spot oder das standardmäßige On-Demand-Kontingent auswählen. Informationen zu Kontingenttypen finden Sie unter Kontingentrichtlinie.
curl
Die Antwort sollte in etwa so aussehen:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
Verwenden Sie den GUID-Wert am Ende des Stringwerts für das Attribut name, um Informationen zur in die Warteschlange eingereihten Ressourcenanfrage zu erhalten.
Console
Status einer in die Warteschlange gestellten Ressource abrufen
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
Für eine in die Warteschlange eingereihte Ressource im Status ACTIVE sieht die Ausgabe so aus:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
Für eine in die Warteschlange eingereihte Ressource im Status ACTIVE sieht die Ausgabe so aus:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
Console
Nachdem Ihre TPU bereitgestellt wurde, können Sie auch Details zu Ihrer in die Warteschlange gestellten Ressourcenanfrage auf der Seite TPUs aufrufen. Suchen Sie dazu nach Ihrer TPU und klicken Sie auf den Namen der entsprechenden in die Warteschlange gestellten Ressourcenanfrage.
In seltenen Fällen kann es vorkommen, dass sich Ihre in die Warteschlange gestellte Ressource im Status FAILED befindet, während einige Slices den Status ACTIVE haben. Löschen Sie in diesem Fall die erstellten Ressourcen und versuchen Sie es in einigen Minuten noch einmal oder wenden Sie sich an den Google Cloud Support.
SSH und Abhängigkeiten installieren
Unter JAX-Code auf TPU-Slices ausführen wird beschrieben, wie Sie in einem einzelnen Slice eine SSH-Verbindung zu Ihren TPU-VMs herstellen. Wenn Sie über SSH eine Verbindung zu allen TPU-VMs in Ihrer Multislice-Umgebung herstellen und Abhängigkeiten installieren möchten, verwenden Sie den folgenden gcloud-Befehl:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
Mit diesem gcloud-Befehl wird der angegebene Befehl über SSH an alle Worker und Knoten in QR gesendet. Der Befehl wird in Gruppen von vier Befehlen zusammengefasst und gleichzeitig gesendet. Der nächste Batch von Befehlen wird gesendet, wenn der aktuelle Batch ausgeführt wurde. Wenn bei einem der Befehle ein Fehler auftritt, wird die Verarbeitung beendet und es werden keine weiteren Batches gesendet. Weitere Informationen finden Sie in der API-Referenz für Ressourcen in der Warteschlange.
Wenn die Anzahl der verwendeten Slices das Threading-Limit (auch Batching-Limit genannt) Ihres lokalen Computers überschreitet, kommt es zu einem Deadlock. Angenommen, das Batching-Limit auf Ihrem lokalen Computer ist 64. Wenn Sie versuchen, ein Trainingsskript für mehr als 64 Slices auszuführen, z. B. für 100, werden die Slices mit dem SSH-Befehl in Batches aufgeteilt. Das Trainingsskript wird für den ersten Batch mit 64 Slices ausgeführt. Das System wartet, bis die Skriptausführung abgeschlossen ist, bevor das Skript für den verbleibenden Batch mit 36 Slices ausgeführt wird. Die ersten 64 Slices können jedoch erst abgeschlossen werden, wenn die verbleibenden 36 Slices das Skript ausführen, was zu einem Deadlock führt.
Um dieses Szenario zu vermeiden, können Sie das Trainingsskript auf jeder VM im Hintergrund ausführen. Hängen Sie dazu ein kaufmännisches Und-Zeichen (&) an den Skriptbefehl an, den Sie mit dem Flag --command angeben. Wenn Sie das tun, wird die Steuerung nach dem Start des Trainingsskripts für den ersten Batch von Slices sofort an den SSH-Befehl zurückgegeben. Mit dem SSH-Befehl kann dann das Trainingsskript für die verbleibenden 36 Slices ausgeführt werden. Sie müssen Ihre stdout- und stderr-Streams entsprechend weiterleiten, wenn Sie die Befehle im Hintergrund ausführen. Um die Parallelität innerhalb desselben QR zu erhöhen, können Sie mit dem Parameter --node bestimmte Slices auswählen.
Netzwerkeinrichtung
Führen Sie die folgenden Schritte aus, um sicherzustellen, dass TPU-Slices miteinander kommunizieren können.
Installieren Sie JAX auf jedem der Slices. Weitere Informationen finden Sie unter JAX-Code auf TPU-Slices ausführen. Prüfen Sie, ob len(jax.devices()) der Anzahl der Chips in Ihrer Multislice-Umgebung entspricht. Führen Sie dazu für jeden Slice Folgendes aus:
$ python3 -c 'import jax; print(jax.devices())'
Wenn Sie diesen Code auf vier Scheiben von v4-16 ausführen, gibt es acht Chips pro Scheibe und vier Scheiben. Insgesamt sollten also 32 Chips (Geräte) von jax.devices() zurückgegeben werden.
In die Warteschlange gestellte Ressourcen auflisten
gcloud
Mit dem Befehl queued-resources list können Sie den Status Ihrer in die Warteschlange eingereihten Ressourcen aufrufen:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
Die Ausgabe sieht dann ungefähr so aus:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
Console
Job in einer bereitgestellten Umgebung starten
Sie können Arbeitslasten manuell ausführen, indem Sie über SSH eine Verbindung zu allen Hosts in jedem Slice herstellen und den folgenden Befehl auf allen Hosts ausführen.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
Kurzantworten zurücksetzen
Mit der ResetQueuedResource API können Sie alle VMs in einem ACTIVE QR zurücksetzen. Durch das Zurücksetzen der VMs wird der Arbeitsspeicher der Maschine gelöscht und die VM auf ihren Ausgangszustand zurückgesetzt. Alle lokal gespeicherten Daten bleiben intakt und das Startskript wird nach dem Zurücksetzen aufgerufen. Die ResetQueuedResource API kann nützlich sein, wenn Sie alle TPUs neu starten möchten. Das kann beispielsweise der Fall sein, wenn das Training nicht mehr weiterläuft und das Zurücksetzen aller VMs einfacher ist als das Debuggen.
Das Zurücksetzen aller VMs erfolgt parallel und ein ResetQueuedResource-Vorgang dauert ein bis zwei Minuten. Verwenden Sie den folgenden Befehl, um die API aufzurufen:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
In die Warteschlange gestellte Ressourcen löschen
Wenn Sie Ressourcen am Ende des Trainings freigeben möchten, löschen Sie die in der Warteschlange befindliche Ressource. Das Löschen dauert zwei bis fünf Minuten. Wenn Sie die gcloud CLI verwenden, können Sie diesen Befehl mit dem optionalen Flag --async im Hintergrund ausführen.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
Console
Automatische Wiederherstellung nach Fehlern
Im Falle einer Unterbrechung bietet Multislice eine automatische Reparatur des betroffenen Slice und ein anschließendes Zurücksetzen aller Slices. Der betroffene Slice wird durch einen neuen ersetzt und die verbleibenden, ansonsten fehlerfreien Slices werden zurückgesetzt. Wenn keine Kapazität für die Zuweisung eines Ersatzsegments verfügbar ist, wird das Training beendet.
Wenn das Training nach einer Unterbrechung automatisch fortgesetzt werden soll, müssen Sie ein Startscript angeben, das nach den zuletzt gespeicherten Checkpoints sucht und diese lädt. Ihr Startskript wird automatisch jedes Mal ausgeführt, wenn ein Slice neu zugewiesen oder eine VM zurückgesetzt wird. Sie geben ein Startskript in der JSON-Nutzlast an, die Sie an die API zum Erstellen von QR-Codes senden.
Mit dem folgenden Startskript (das in QRs erstellen verwendet wird) können Sie während des MaxText-Trainings automatisch Fehler beheben und das Training anhand von Checkpoints fortsetzen, die in einem Cloud Storage-Bucket gespeichert sind:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
Klonen Sie das MaxText-Repository, bevor Sie es ausprobieren.
Profiling und Debugging
Das Profiling ist in Umgebungen mit einem und mehreren Slices gleich. Weitere Informationen finden Sie unter Profilerstellung für JAX-Programme.
Optimierte Schulungen
In den folgenden Abschnitten wird beschrieben, wie Sie das Multislice-Training optimieren können.
Sharding mit Multislice für maximale Leistung
Um in Multislicing-Umgebungen die maximale Leistung zu erzielen, müssen Sie berücksichtigen, wie Sie die Daten auf die verschiedenen Slices aufteilen. Normalerweise gibt es drei Möglichkeiten: Datenparallelität, vollständig shardierte Datenparallelität und Pipeline-Parallelität. Wir empfehlen nicht, Aktivierungen über die Modelldimensionen hinweg zu sharden (manchmal auch als Tensorparallelität bezeichnet), da dies zu viel Bandbreite zwischen den Slices erfordert. Bei allen diesen Strategien können Sie die Sharding-Strategie innerhalb eines Slice beibehalten, die in der Vergangenheit für Sie funktioniert hat.
Wir empfehlen, mit reiner Datenparallelität zu beginnen. Die Verwendung von Fully Sharded Data Parallelism ist hilfreich, um die Speichernutzung zu reduzieren. Der Nachteil ist, dass die Kommunikation zwischen den Segmenten das DCN-Netzwerk verwendet und Ihre Arbeitslast verlangsamt. Verwenden Sie Pipeline-Parallelität nur, wenn es aufgrund der Batchgröße erforderlich ist (siehe Analyse unten).
Wann sollte Datenparallelität verwendet werden?
Reine Datenparallelität eignet sich gut für Arbeitslasten, die bereits gut ausgeführt werden, deren Leistung aber durch Skalierung über mehrere Slices hinweg verbessert werden soll.
Um eine starke Skalierung über mehrere Slices hinweg zu erreichen, muss die Zeit, die für die All-Reduce-Operation über DCN erforderlich ist, kürzer sein als die Zeit, die für einen Backward-Pass benötigt wird. DCN wird für die Kommunikation zwischen Segmenten verwendet und ist ein begrenzender Faktor für den Arbeitslastdurchsatz.
Jeder v4-TPU-Chip erreicht eine Spitzenleistung von 275 * 1012 FLOPS pro Sekunde.
Es gibt vier Chips pro TPU-Host und jeder Host hat eine maximale Netzwerkbandbreite von 50 Gbit/s.
Die arithmetische Intensität beträgt also 4 * 275 * 1012 FLOPS / 50 Gbit/s = 22.000 FLOPS / Bit.
Ihr Modell verwendet pro Schritt 32 bis 64 Bit DCN-Bandbreite für jeden Parameter. Wenn Sie zwei Slices verwenden, nutzt Ihr Modell 32 Bit der DCN-Bandbreite. Wenn Sie mehr als zwei Slices verwenden, führt der Compiler eine vollständige Shuffle-All-Reduce-Operation aus und Sie verbrauchen pro Schritt bis zu 64 Bit DCN-Bandbreite für jeden Parameter. Die Anzahl der FLOPS, die für jeden Parameter erforderlich sind, hängt von Ihrem Modell ab. Insbesondere für Transformer-basierte Sprachmodelle ist die Anzahl der FLOPS, die für einen Forward- und einen Backward-Pass erforderlich sind, ungefähr 6 * B * P, wobei:
Die Anzahl der FLOPS pro Parameter beträgt 6 * B und die Anzahl der FLOPS pro Parameter während des Rückwärts-Passes beträgt 4 * B.
Damit die starke Skalierung über mehrere Slices hinweg funktioniert, muss die operative Intensität die arithmetische Intensität der TPU-Hardware übersteigen. Um die operative Intensität zu berechnen, teilen Sie die Anzahl der FLOPS pro Parameter während des Backward-Pass durch die Netzwerkbandbreite (in Bit) pro Parameter pro Schritt:
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
Wenn Sie für ein Transformer-basiertes Sprachmodell zwei Slices verwenden, gilt Folgendes:
Operational intensity = 4 * B / 32
Wenn Sie mehr als zwei Slices verwenden: Operational intensity = 4 * B/64
Dies deutet auf eine Mindestbatchgröße zwischen 176.000 und 352.000 für Transformer-basierte Sprachmodelle hin. Da im DCN-Netzwerk kurzzeitig Pakete verloren gehen können, ist es am besten, einen großen Fehlermargen zu berücksichtigen und Datenparallelität nur zu verwenden, wenn die Batchgröße pro Pod mindestens 350.000 (zwei Pods) bis 700.000 (viele Pods) beträgt.
Bei anderen Modellarchitekturen müssen Sie die Laufzeit des Backward-Passes pro Slice schätzen (entweder durch Messen mit einem Profiler oder durch Zählen von FLOPS). Anschließend können Sie diese mit der erwarteten Laufzeit vergleichen, um die DCN-Kosten zu senken und eine gute Schätzung zu erhalten, ob sich Datenparallelität für Sie lohnt.
Wann sollte FSDP (Fully Sharded Data Parallelism) verwendet werden?
Bei der vollständig fragmentierten Datenparallelität (Fully Sharded Data Parallelism, FSDP) wird die Datenparallelität (Fragmentierung der Daten über Knoten hinweg) mit der Fragmentierung der Gewichte über Knoten hinweg kombiniert. Für jeden Vorgang im Vorwärts- und Rückwärtsdurchlauf werden die Gewichte gesammelt, sodass jede Scheibe die benötigten Gewichte hat. Anstatt die Gradienten mit „all-reduce“ zu synchronisieren, werden sie nach der Erstellung mit „reduce-scatter“ verteilt. So erhält jeder Slice nur die Gradienten für die Gewichte, für die er verantwortlich ist.
Ähnlich wie bei der Datenparallelität muss die globale Batchgröße bei FSDP linear mit der Anzahl der Slices skaliert werden. Durch FSDP wird der Speicherdruck verringert, wenn Sie die Anzahl der Slices erhöhen. Das liegt daran, dass die Anzahl der Gewichte und des Optimierungsstatus pro Slice abnimmt, aber auf Kosten von erhöhtem Netzwerkverkehr und der größeren Möglichkeit für Blockierungen aufgrund eines verzögerten Kollektivs.
In der Praxis ist FSDP über Slices hinweg am besten, wenn Sie den Batch pro Slice erhöhen, mehr Aktivierungen speichern, um die Re-Materialisierung während des Backward-Pass zu minimieren, oder die Anzahl der Parameter in Ihrem neuronalen Netzwerk erhöhen.
Die Vorgänge „all-gather“ und „all-reduce“ in FSDP funktionieren ähnlich wie in DP. Sie können also auf dieselbe Weise wie im vorherigen Abschnitt beschrieben feststellen, ob Ihre FSDP-Arbeitslast durch die DCN-Leistung begrenzt wird.
Wann sollte Pipeline-Parallelität verwendet werden?
Die Pipeline-Parallelität wird relevant, wenn Sie mit anderen Parallelitätsstrategien, die eine globale Batchgröße erfordern, die größer als Ihre bevorzugte maximale Batchgröße ist, eine hohe Leistung erzielen möchten. Durch die Parallelität von Pipelines können sich die Slices einer Pipeline einen Batch „teilen“. Die Pipeline-Parallelität hat jedoch zwei erhebliche Nachteile:
Die Pipeline-Parallelität sollte nur verwendet werden, wenn die anderen Parallelitätsstrategien eine zu große globale Batchgröße erfordern. Bevor Sie die Pipeline-Parallelität ausprobieren, sollten Sie empirisch testen, ob sich die Konvergenz pro Stichprobe bei der Batchgröße verlangsamt, die für eine leistungsstarke FSDP erforderlich ist. Mit FSDP wird in der Regel eine höhere FLOP-Auslastung des Modells erreicht. Wenn sich die Konvergenz pro Stichprobe jedoch mit zunehmender Batchgröße verlangsamt, ist Pipeline-Parallelität möglicherweise die bessere Wahl. Die meisten Arbeitslasten können ausreichend große Batchgrößen tolerieren, sodass sie nicht von Pipeline-Parallelität profitieren. Ihre Arbeitslast kann jedoch anders sein.
Wenn eine parallele Ausführung von Pipelines erforderlich ist, empfehlen wir, sie mit Datenparallelität oder FSDP zu kombinieren. So können Sie die Tiefe der Pipeline minimieren und gleichzeitig die Batchgröße pro Pipeline erhöhen, bis die DCN-Latenz weniger Einfluss auf den Durchsatz hat. Wenn Sie beispielsweise N Slices haben, sollten Sie Pipelines mit Tiefe 2 und N/2 Replikaten für Datenparallelität in Betracht ziehen, dann Pipelines mit Tiefe 4 und N/4 Replikaten für Datenparallelität usw., bis der Batch pro Pipeline so groß wird, dass die DCN-Collectives hinter der Arithmetik im Rückwärtsdurchlauf verborgen werden können. Dadurch wird die durch Pipeline-Parallelität verursachte Verlangsamung minimiert und Sie können über das globale Limit für die Batchgröße hinaus skalieren.
Best Practices für mehrere Scheiben
In den folgenden Abschnitten werden Best Practices für das Multislice-Training beschrieben.
Laden der Daten
Während des Trainings werden wiederholt Batches aus einem Dataset geladen, um sie in das Modell einzuspeisen. Ein effizienter, asynchroner Datenloader, der den Batch auf Hosts aufteilt, ist wichtig, um zu vermeiden, dass die TPUs nicht ausgelastet sind. Der aktuelle Daten-Loader in MaxText weist jedem Host eine gleiche Teilmenge der Beispiele zu. Diese Lösung ist für Text geeignet, erfordert jedoch eine erneute Shardierung im Modell. Außerdem bietet MaxText noch kein deterministisches Snapshotting, mit dem der Dateniterator vor und nach der Unterbrechung dieselben Daten laden könnte.
Prüfpunktausführung
Die Orbax-Checkpointing-Bibliothek bietet Primitiven zum Speichern von JAX-PyTrees in lokalen Speichern oder Google Cloud -Speichern.
Wir stellen eine Referenzintegration mit synchroner Prüfpunktsetzung in MaxText in checkpointing.py zur Verfügung.
Unterstützte Konfigurationen
In den folgenden Abschnitten werden die unterstützten Slice-Formen, Orchestrierung, Frameworks und Parallelität für Multislice beschrieben.
Formen
Alle Slices müssen dieselbe Form haben (z. B. denselben AcceleratorType). Heterogene Slice-Formen werden nicht unterstützt.
Orchestrierung
Die Orchestrierung wird mit GKE unterstützt. Weitere Informationen finden Sie unter TPUs in GKE.
Frameworks
Multislice unterstützt nur JAX- und PyTorch-Arbeitslasten.
Parallelität
Wir empfehlen Nutzern, Multislice mit Datenparallelität zu testen. Weitere Informationen zur Implementierung von Pipeline-Parallelität mit Multislice erhalten Sie von IhremGoogle Cloud -Kundenbetreuer.
Support und Feedback
Wir freuen uns über jedes Feedback. Wenn Sie Feedback geben oder Support anfordern möchten, wenden Sie sich an uns.