このページでは、Cloud SQL のシステム分析情報ダッシュボードの使用方法について説明します。システム分析情報ダッシュボードには、インスタンスで使用するリソースの指標が表示されるため、システム パフォーマンスの問題の検出と分析に役立ちます。
Gemini in Databases アシスタントを使用すると、Cloud SQL for PostgreSQL リソースのモニタリングとトラブルシューティングを行うことができます。詳細については、Gemini アシスタンスによる観測とトラブルシューティングをご覧ください。システム分析情報ダッシュボードを表示する
システム分析情報ダッシュボードを確認する手順は次のとおりです。
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- インスタンスの名前をクリックします。
左側の SQL ナビゲーション パネルから [システム分析情報] タブを選択します。
システム分析情報ダッシュボードが開きます。
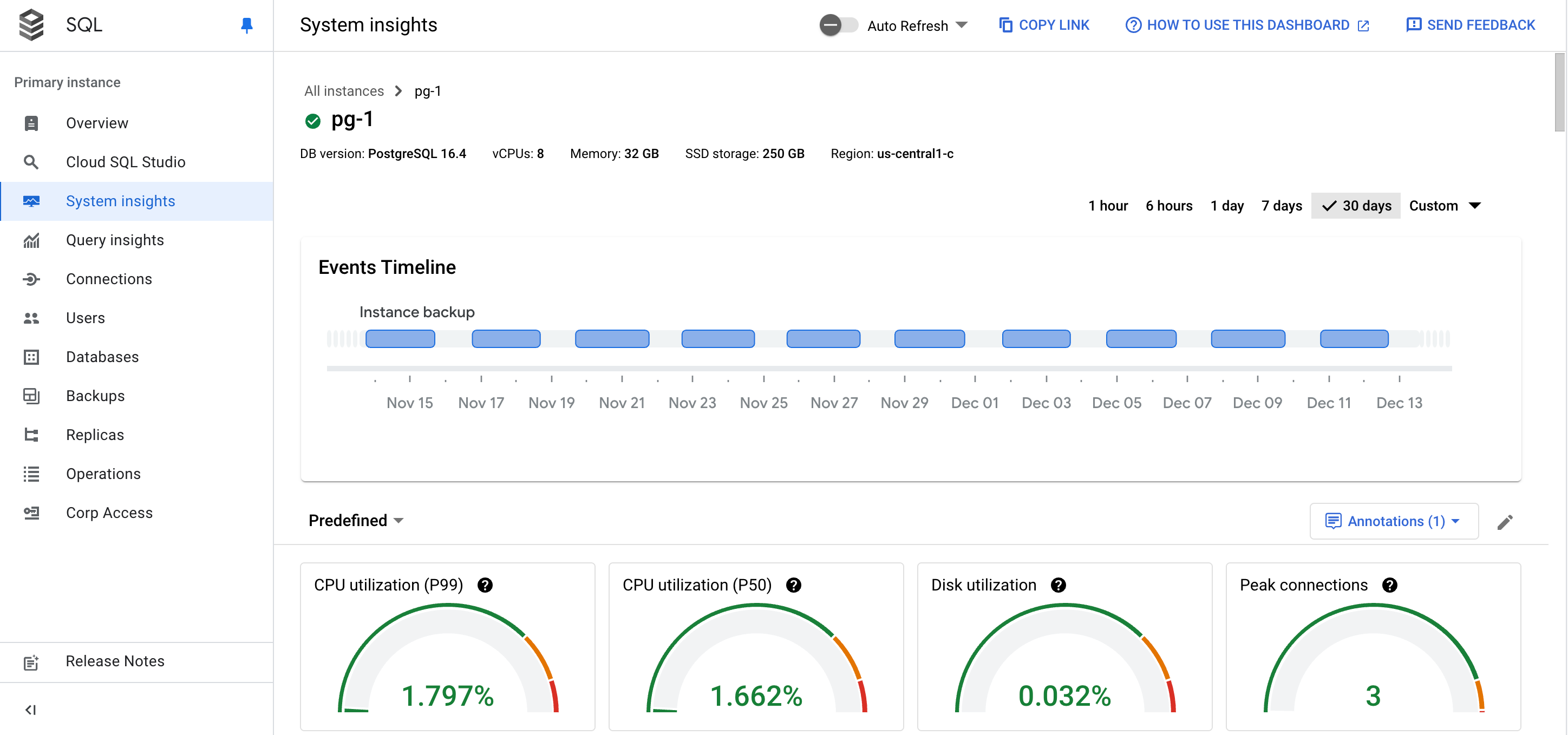
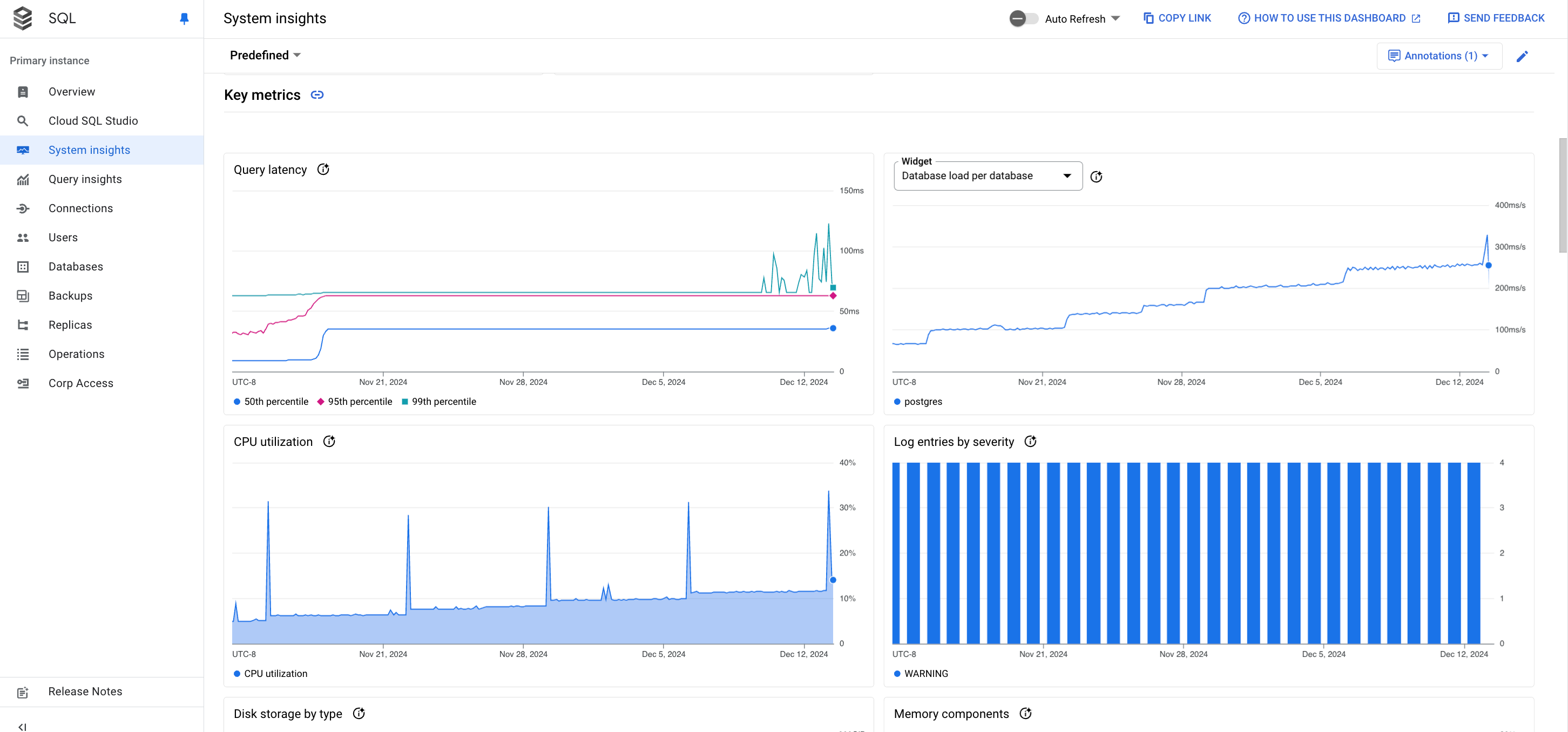
システム分析情報ダッシュボードには、次の情報が表示されます。
インスタンスの詳細
イベントのタイムライン: システム イベントが時系列で表示されます。この情報は、システム イベントがインスタンスの正常性とパフォーマンスに及ぼす影響を評価するのに役立ちます。
概要カード: CPU 使用率、ディスク使用率、ログエラーの指標の最新の値と集計値を表示して、インスタンスの健全性とパフォーマンスの概要を確認できます。
指標グラフ: オペレーティング システムとデータベースの指標に関する情報を示します。スループット、レイテンシ、費用など、いくつかの問題に関する分析情報を得ることができます。
ダッシュボードには、大きく分けて次のオプションがあります。
- 1 行に 1 つまたは 2 つのグラフを表示します。[ビューをカスタマイズ] をクリックして、これらのグラフの表示方法を選択します。このオプションでは、ダッシュボードに表示する指標を選択することもできます。
ダッシュボードを最新の状態に保つには、[
 自動更新] オプションを有効にします。[自動更新] を有効にすると、ダッシュボード データが 1 分ごとに更新されます。この機能は、カスタマイズした期間には対応していません。
自動更新] オプションを有効にします。[自動更新] を有効にすると、ダッシュボード データが 1 分ごとに更新されます。この機能は、カスタマイズした期間には対応していません。タイムセレクタでは、デフォルトで
1 dayが選択されています。期間を変更するには、事前に定義されている他の期間を選択するか、[カスタム] をクリックして開始時刻と終了時刻を定義します。過去 30 日分のデータを利用できます。ダッシュボードの絶対リンクを作成するには、[リンクをコピー] ボタンをクリックします。このリンクは、同じ権限を持つ他の Cloud SQL ユーザーと共有できます。
特定のイベントにアラートを作成するには、 [通知] をクリックします。
特定のアラートを表示するには、[アノテーション] をクリックします。
概要カード
次の表は、システム分析情報ダッシュボードの上部に表示される概要カードを示しています。これらのカードには、選択した期間のインスタンスの正常性とパフォーマンスの概要が表示されます。
| 概要カード | 説明 |
|---|---|
| CPU 使用率 - P99 | P50 | 選択した期間の P99 および P50 の CPU 使用率の値。 |
| ピーク接続数 | 選択した期間の最大接続数に対するピーク接続数の割合。ピーク接続数は、インスタンスのスケーリングや max_connections 設定の手動変更などにより最大数が最近変更された場合、その最大数より大きくなる場合があります。 |
| トランザクション ID の使用率 | 選択した期間のトランザクション ID 使用率の最新値。 |
| ディスク使用率 | 最新のディスク使用率の値。 |
| ログのエラー | ユーザーがログに記録するエラーの数。 |
指標グラフ
サンプルの指標のグラフカードは次のようになります。
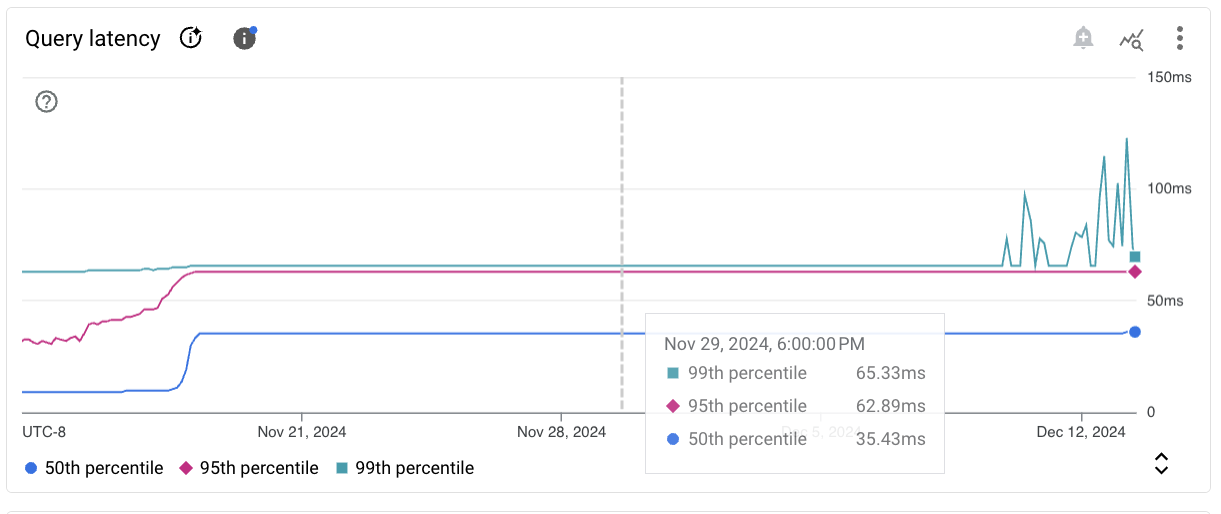
各グラフカードのツールバーには、次の標準オプションのセットがあります。
選択した期間の特定の時点の指標値を表示するには、グラフの上にカーソルを移動します。
グラフをズームするには、グラフをクリックし、X 軸に沿って水平方向または Y 軸に沿って垂直方向にドラッグします。ズーム操作を元に戻すには、[ズームをリセット] をクリックします。または、ダッシュボードの上部にある事前定義された期間のいずれかをクリックします。ズーム操作は、ダッシュボード上のすべてのグラフに同時に適用されます。
その他のオプションを表示するには、[more_vert その他のグラフ オプション] をクリックします。多くのグラフには、次のオプションがあります。
グラフを全画面モードで表示するには、[全画面で表示] をクリックします。全画面モードを終了するには、[キャンセル] をクリックします。
凡例を非表示または閉じます。
グラフの PNG ファイルまたは CSV ファイルをダウンロードします。
Metrics Explorer で表示する。Metrics Explorer で指標を表示します。Cloud SQL Database リソースタイプを選択すると、Metrics Explorer で他の Cloud SQL 指標を確認できます。
カスタム ダッシュボードを作成するには、[edit ダッシュボードをカスタマイズ] をクリックして名前を付けます。または、[事前定義] メニューを開いて、既存のカスタム ダッシュボードを選択します。
指標グラフのデータを詳細に表示するには、query_stats [データを探索] をクリックします。ここで、特定の指標をフィルタし、グラフの表示方法を選択できます。
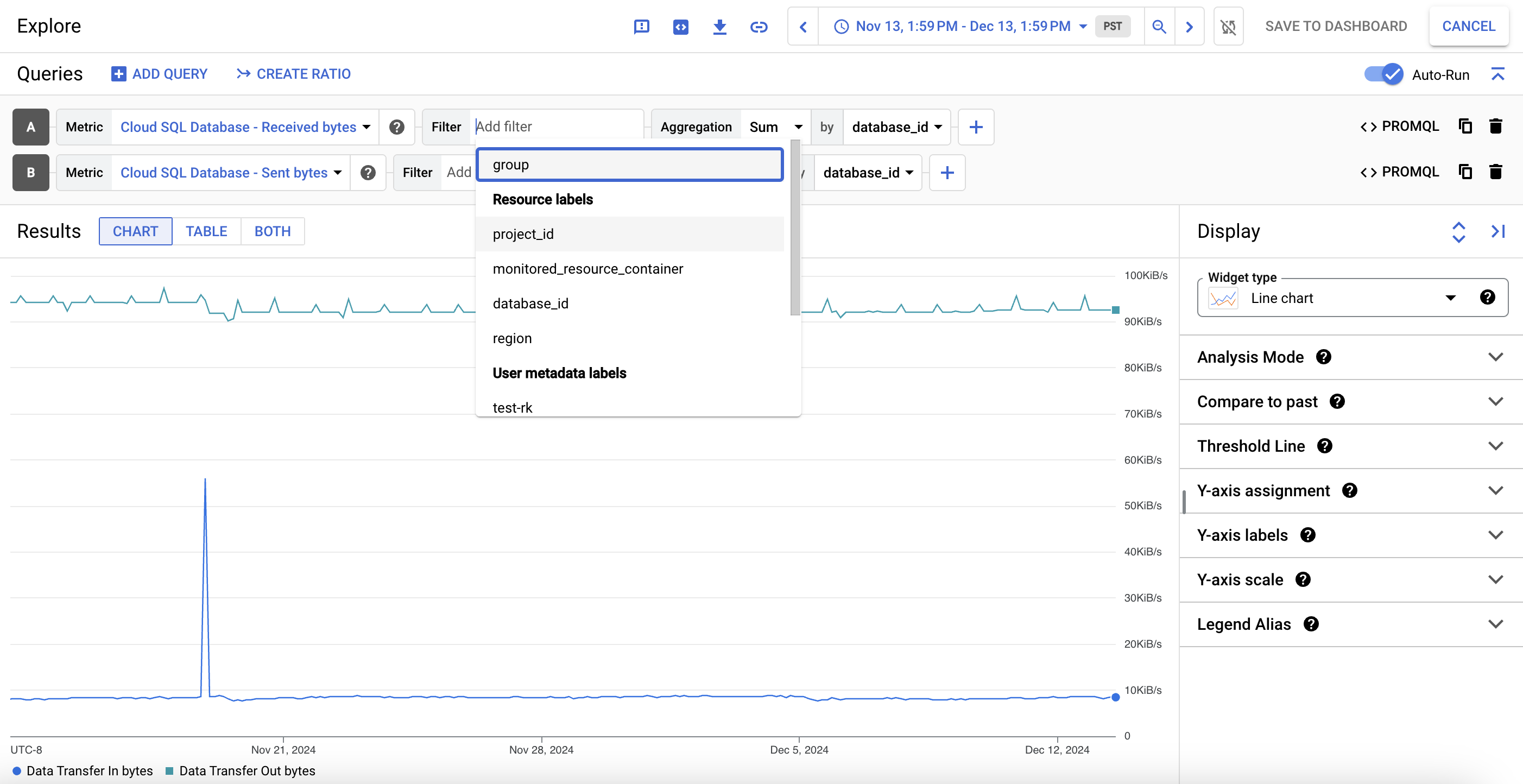
このカスタマイズしたビューを指標グラフとして保存するには、[ダッシュボードに保存] をクリックします。
デフォルトの指標
次の表は、Cloud SQL のシステム情報分析ダッシュボードにデフォルトで表示される Cloud SQL の指標を示したものです。
指標タイプの文字列は、接頭辞 cloudsql.googleapis.com/database/ の後ろに続きます。
次の指標の最新のリリース ステージの可用性については、Google Cloud 指標をご覧ください。
| 指標名とタイプ | 説明 |
|---|---|
1 秒あたりの新しい接続数postgresql/new_connection_count
|
Cloud SQL for PostgreSQL インスタンスに作成する 1 秒あたりの新しい接続数の割合Cloud SQL は、この指標をデータベースごとに計算して表示します。 この指標は、PostgreSQL バージョン 14 以降で使用できます。 |
待機イベントのタイプ
postgresql/backends_in_wait
|
Cloud SQL for PostgreSQL インスタンスの各待機イベントタイプで待機状態にある接続数。 |
待機イベントpostgresql/backends_in_wait
|
Cloud SQL for PostgreSQL インスタンスの待機イベントの数。ダッシュボードには、この指標が「待機イベント名: 待機イベントタイプ」の形式で表示されます。 |
トランザクション数postgresql/transaction_count
|
Cloud SQL for PostgreSQL インスタンスの |
メモリ コンポーネントmemory/components
|
データベースで使用可能なメモリ コンポーネント。各メモリ コンポーネントの値は、データベースで使用可能な合計メモリの割合として計算されます。 |
最大レプリカのバイトラグpostgresql/external_sync/max_replica_byte_lag
|
外部サーバー(ES)レプリカ上のすべてのデータベース間の最大レプリケーション ラグ(バイト単位)。 |
クエリのレイテンシpostgresql/insights/aggregate/latencies |
ユーザーとデータベースごとの P99、P95、P50 別の集計クエリ レイテンシ分布。 クエリ分析情報が有効になっているインスタンスでのみ使用できます。 |
データベース、ユーザー、クライアント アドレスごとのデータベース負荷postgresql/insights/aggregate/execution_time |
データベース、ユーザー、またはクライアント アドレスごとのクエリ実行の累積時間。クエリ実行に関連するすべてのプロセスの CPU 時間、I/O 待機時間、ロック待機時間、プロセス コンテキスト切り替え、スケジューリングの合計です。 クエリ分析情報が有効になっているインスタンスでのみ使用できます。 |
CPU 使用率cpu/utilization |
現在の CPU 使用率は、現在使用されている予約済みの CPU の割合として表されます。 |
ディスク ストレージ(タイプ別)disk/bytes_used_by_data_type |
データ型( この指標は、ストレージ費用の把握に役立ちます。ストレージの使用料金の詳細については、ストレージとネットワークの料金をご覧ください。 ポイントインタイム リカバリ(PITR)は、ログ先行書き込み(WAL)のアーカイブを使用します。これらのログは定期的に更新され、保存容量を使用します。ログ先行書き込みは、関連する自動バックアップによって自動的に削除されます。これは通常、約 7 日後に発生します。 ログ先行書き込みログのサイズが原因でインスタンスに問題が発生している場合、ストレージ サイズを大きくすることができます。ただし、ディスク使用量のログ先行書き込みのサイズが大きくなるのはあくまで一時的です。予期しないストレージの問題を回避するため、PITR の使用時にストレージの自動増量を有効にすることをおすすめします。 ログを削除してストレージを復元するには、ポイントインタイム リカバリを無効にします。ただし、使用されたストレージを減らしても、インスタンスにプロビジョニングされたストレージのサイズは縮小されません。 一時データはストレージ使用量指標に含まれます。一時データはメンテナンスの一環として削除され、ディスクフル イベントを回避するために、無料でユーザー定義の容量制限を超えて増加することが可能です。 新しく作成されたデータベースは、システム テーブルとファイル用に約 100 MB を使用します。 |
ディスク ストレージ(タイプ別)disk/bytes_used_by_data_type |
データ型( この指標は、ストレージ費用の把握に役立ちます。ストレージの使用料金の詳細については、ストレージとネットワークの料金をご覧ください。 ポイントインタイム リカバリでは、write-ahead log 書き込み(WAL)のアーカイブを使用します。ポイントインタイム リカバリが有効になっている新しい Cloud SQL インスタンス、または Cloud Storage で WAL ログを保存するためにこの機能が使用可能になった後、ポイントインタイム リカバリを有効にする既存のインスタンスの場合、ログはディスクに保存されなくなります。代わりに、インスタンスと同じリージョンの Cloud Storage に保存されるようになります。 インスタンスのログが Cloud Storage に保存されているかどうかを確認するには、インスタンスの bytes_used_by_data_type 指標を確認します。 ポイントインタイム リカバリが有効になっている他のすべての既存のインスタンスでは、引き続きログがディスクに保存されます。Cloud Storage にログを保存するようにする変更は、のちほど利用可能になります。 ポイントインタイム リカバリで使用される write-ahead log は、関連する自動バックアップによって自動的に削除されます。これは通常、transactionLogRetentionDays に設定された値に達すると行われます。これは、Cloud SQL がポイントインタイム リカバリのために保持するトランザクション ログの日数(1~7)です。 write-ahead log が Cloud Storage に保存されているインスタンスの場合、ログはプライマリ インスタンスと同じリージョンに保存されます。このログストレージ(ポイントインタイム リカバリの最大時間である 7 日間まで)では、インスタンスごとの追加費用は発生しません。 インスタンスでポイントインタイム リカバリが有効になっていて、ディスク上の write-ahead log のサイズが原因でインスタンスに問題が発生している場合は、ポイントインタイム リカバリを無効にして、再度有効にすることで、新しいログがインスタンスと同じリージョンの Cloud Storage に保存されるようになります。これにより、既存の write-ahead log が削除されるため、ポイントインタイム リカバリを再度有効にした時点よりも前のポイントインタイム リカバリを行うことはできません。ただし、既存のログは削除されますが、ディスクサイズは変わりません。 予期しないストレージの問題を回避するには、ポイントインタイム リカバリを使用するときに、すべてのインスタンスでストレージの自動増量を有効にすることをおすすめします。この推奨事項は、インスタンスでポイントインタイム リカバリが有効になっていて、かつログがディスクに保存されている場合にのみ適用されます。 ログを削除してストレージを復元するには、ポイントインタイム リカバリを無効にします。ただし、使用するログ先行書き込みを減らしても、インスタンスにプロビジョニングされたディスクのサイズは縮小されません。 一時データはストレージ使用量指標に含まれます。一時データはメンテナンスの一環として削除され、ディスクフル イベントを回避するために、無料でユーザー定義の容量制限を超えて増加することが可能です。 新しく作成されたデータベースは、システム テーブルとファイル用に約 100 MB を使用します。 |
ディスク読み取り / 書き込みオペレーションdisk/read_ops_count、disk/write_ops_count |
読み取り回数の指標は、キャッシュではなくディスクからの読み取りオペレーションの回数を示します。この指標を使用すると、インスタンスが環境に適したサイズかどうかを判断できます。必要な場合はさらに大きいマシンタイプを使用して、キャッシュから提供されるリクエストを増やし、レイテンシを短縮できます。 書き込み回数は、ディスクへの書き込みオペレーションの回数です。書き込みアクティビティは、アプリケーションがアクティブではない場合でも生成されます。これは、Cloud SQL インスタンス(レプリカを除く)によって約 1 秒間に 1 回システム テーブルに書き込まれているためです。 |
ステータス別の接続数postgresql/num_backends_by_state |
ステータス別( これらのステータスについては、 |
データベースあたりの接続数postgresql/num_backends |
データベース インスタンスが保持する接続数。 |
上り / 下り(内向き / 外向き)のバイト数network/received_bytes_count、network/sent_bytes_count |
インスタンスとの間の上り(内向き)バイト数(受信バイト数)と下り(外向き)バイト数(送信バイト数)それぞれで示したネットワーク トラフィック。 |
タイプ別の I/O 待機の内訳postgresql/insights/aggregate/io_time |
読み取り / 書き込みタイプ別の SQL ステートメントの I/O 待機時間の内訳。 クエリ分析情報が有効になっているインスタンスでのみ使用できます。 |
デッドロック数(データベース別)postgresql/deadlock_count |
データベースあたりのデッドロックの数。 |
ブロック読み取り数postgresql/blocks_read_count |
ディスクとバッファ キャッシュから 1 秒あたりに読み取られたブロックの数。 |
オペレーション別の処理行数postgresql/tuples_processed_count |
オペレーション別の 1 秒あたりの処理行数。 |
データベース内の行(状態別)postgresql/tuple_size |
各データベースの状態の行数。インスタンス内のデータベース数が 50 未満の場合、Cloud SQL はこの指標を報告します。 |
最も古いトランザクション(経過時間別)postgresql/vacuum/oldest_transaction_age |
バキューム オペレーションをブロックしている最も古いトランザクションの経過時間。 |
WAL のアーカイブreplication/log_archive_success_count、replication/log_archive_failure_count |
アーカイブに成功または失敗した 1 分あたりの先行書き込みログファイルの数。 |
トランザクション ID の使用率postgresql/transaction_id_utilization |
インスタンスで使用されているトランザクション ID の割合。 |
アプリケーション名ごとの接続数postgresql/num_backends_by_application |
Cloud SQL インスタンスへの接続数。アプリケーションごとにグループ化されています。 |
取得された行数、返された行数、書き込まれた行数の対比
|
返された行数と取得された行数の差が非常に大きく、値が同じスケールで表示されない場合は、取得された行の値は 0 と表示されます。これは、返された行の値と比べたら無視できる程度のためです。 |
一時データのサイズpostgresql/temp_bytes_written_count |
クエリの実行とアルゴリズム(結合や並べ替えなど)の実行に使用されたデータの合計量(バイト単位)。 |
一時ファイルpostgresql/temp_files_written_count |
クエリの実行とアルゴリズム(結合や並べ替えなど)の実行に使用された一時ファイルの数。 |
また、Cloud Logging の指標である重大度別のログエントリ(logging.googleapis.com/log_entry_count)には、エラーと警告のログエントリの合計数が表示されます。
これらは、データベース ログである postgres.log と、データアクセス情報を含む pgaudit.log から抽出されます。
詳細については、Cloud SQL の指標をご覧ください。
イベントのタイムライン
ダッシュボードには、次のイベントの詳細が表示されます。
| イベント名 | 説明 | オペレーションのタイプ |
|---|---|---|
Instance restart |
Cloud SQL インスタンスの再起動 | RESTART |
Instance failover |
高可用性(HA)プライマリ インスタンスから、プライマリ インスタンスになるスタンバイ インスタンスへの手動フェイルオーバーを開始します。 | FAILOVER |
Instance maintenance |
インスタンスが現在メンテナンス中であることを示します。通常、メンテナンスを行うとインスタンスは 1~3 分間使用できなくなります。 | MAINTENANCE |
Instance backup |
インスタンスのバックアップを実行します。 | BACKUP_VOLUME |
Instance update |
Cloud SQL インスタンスの設定を更新します。 | UPDATE |
Promote replica |
Cloud SQL レプリカ インスタンスを昇格させます。 | PROMOTE_REPLICA |
Start replica |
Cloud SQL 読み取りレプリカ インスタンスでレプリケーションを開始します。 | START_REPLICA |
Stop replica |
Cloud SQL 読み取りレプリカ インスタンスでレプリケーションを停止します。 | STOP_REPLICA |
Recreate replica |
Cloud SQL レプリカ インスタンスのリソースを再作成します。 | RECREATE_REPLICA |
Create replica |
Cloud SQL レプリカ インスタンスを作成します。 | CREATE_REPLICA |
Data import |
Cloud SQL インスタンスにデータをインポートします。 | IMPORT |
Instance export |
データを Cloud SQL インスタンスから Cloud Storage バケットにエクスポートします。 | EXPORT |
Restore backup |
Cloud SQL インスタンスのバックアップを復元します。このオペレーションにより、インスタンスが再起動する可能性があります。 | RESTORE_VOLUME |