Durch Replikation können Kopien einer Cloud SQL-Instanz oder einer lokalen Datenbank erstellt und die Arbeit auf die Kopien übertragen werden.
Einführung
Der Hauptgrund für die Verwendung der Replikation besteht darin, die Nutzung von Daten in einer Datenbank zu skalieren, ohne dabei die Leistung zu beeinträchtigen.
Weitere Gründe:
- Daten zwischen Regionen migrieren
- Daten zwischen Plattformen migrieren
- Daten aus einer lokalen Datenbank zu Cloud SQL migrieren
Außerdem kann ein Replikat hochgestuft werden, wenn die ursprüngliche Instanz beschädigt wird.
Wenn es sich um eine Cloud SQL-Instanz handelt, werden die replizierte Instanz als primäre Instanz und die Kopien als Lesereplikate bezeichnet. Die primäre Instanz und die Lesereplikate befinden sich in Cloud SQL.
Wenn es sich um eine lokale Datenbank handelt, wird das Replikationsszenario als Replikat von einem externen Server bezeichnet. Dabei ist die replizierte Datenbank der Quelldatenbankserver. Die in Cloud SQL gespeicherten Kopien werden als Cloud SQL-Replikate bezeichnet. Außerdem gibt es eine Instanz, die den Quelldatenbankserver in Cloud SQL darstellt. Sie wird als Quelldarstellungsinstanz bezeichnet.
In einem Notfallwiederherstellungs-Szenario können Sie ein Replikat hochstufen, um es in eine primäre Instanz umzuwandeln. Auf diese Weise können Sie sie anstelle einer Instanz verwenden, die sich in einer Region befindet, in der es zu einem Ausfall gekommen ist. You can also promote a replica to replace an instance that's corrupted.
Cloud SQL unterstützt die folgenden Replikattypen:
Sie können auch den Database Migration Service für die kontinuierliche Replikation von einem Quelldatenbankserver zu Cloud SQL verwenden. Hinweis: Mit Cloud SQL können Nutzer ihre eigene Replikation mithilfe den logischen Replikationsfunktionen von PostgreSQL verwalten.Cloud SQL unterstützt keine Replikation zwischen zwei externen Servern.
Lesereplikate
Lesereplikate werden verwendet, um Cloud SQL-Instanzen zu entlasten. Das Lesereplikat ist eine exakte Kopie der primären Instanz. Daten und andere Änderungen an der primären Instanz werden nahezu in Echtzeit auf dem Lesereplikat aktualisiert.
Lesereplikate gewähren nur Lesezugriff. Schreibvorgänge sind nicht möglich. Das Lesereplikat verarbeitet Abfragen, Leseanfragen und Analysetraffic. Dadurch wird die Last für die primäre Instanz reduziert.
Verbindungen zu Replikaten werden direkt über deren Verbindungsnamen und IP-Adressen hergestellt. Wenn Sie eine Verbindung zu einem Replikat über eine private IP-Adresse herstellen, müssen Sie keine zusätzliche private VPC-Verbindung für das Replikat erstellen, da die Verbindung von der primären Instanz übernommen wird.
Weitere Informationen zum Erstellen eines Lesereplikats finden Sie unter Lesereplikate erstellen. Weitere Informationen zum Verwalten eines Lesereplikats finden Sie unter Lesereplikate verwalten.
Als Best Practice sollten Sie Lesereplikate in einer anderen Zone als die primäre Instanz platzieren, wenn Sie HA auf Ihrer primären Instanz verwenden. Dadurch wird sichergestellt, dass Lesereplikate weiter funktionieren, wenn die Zone mit der primären Instanz ausfällt. Weitere Informationen finden Sie unter Hochverfügbarkeit.
Geeigneten Maschinentyp auswählen
Lesereplikate können einen anderen Maschinentyp haben als der primäre Server. Sie sollten Messwerte auf Ihrer Instanz überwachen, z. B. die CPU- und Arbeitsspeichernutzung, damit die Replikatinstanz für ihre Arbeitslast korrekt dimensioniert wird, insbesondere wenn sie kleiner als die primäre Instanz ist. Eine Replikatinstanz mit geringer Größe ist anfälliger für eine schlechte Leistung, z. B. häufige OOM-Ereignisse (Out-of-Memory).
Auswirkungen auf das Flag max_connections, wenn das Lesereplikat einen Maschinentyp mit weniger Arbeitsspeicher als der primäre Speicher hat
Wenn Sie in einer PostgreSQL-Instanz das Flag max_connections nicht auf einen Wert Ihrer Wahl setzen, wird es von Cloud SQL automatisch anhand des Arbeitsspeichers der Instanz festgelegt. Weitere Informationen finden Sie unter Unterstützte Flags. PostgreSQL erfordert, dass der Wert von max_connections in einem Lesereplikat immer mindestens so groß wie auf seinem primären Replikat ist. Wenn also ein Lesereplikat über weniger Arbeitsspeicher verfügt als das primäre Replikat und Sie das Flag max_connections nicht gesetzt haben, übernimmt es möglicherweise einen größeren Wert für max_connections auf der Grundlage der Größe der primären Instanz. Wenn Sie in dieser Situation die Einstellung max_connections verwenden, um die Anzahl der Verbindungen zur Replikatinstanz zu begrenzen, könnte diese überlastet werden, weil der Wert im Verhältnis zum Maschinentyp der Instanz zu hoch ist Sie können dies jedoch so vermeiden:
- Ändern Sie die Größe der Replikatinstanz in einen größeren Maschinentyp.
- Konfigurieren Sie Ihre Clientanwendung so, dass sie auf eine bestimmte Anzahl von Verbindungen beschränkt ist, die unter dem Wert von
max_connectionsliegt. - Legen Sie für das Flag
max_connectionsauf der primären Instanz und dem Replikat einen geeigneten Wert fest.
Hash-Indexvorgänge mit Lesereplikaten
Hash-Indexvorgänge verwenden kein Write-Ahead-Logging für PostgreSQL 9.6. Cloud SQL hat nur eine verfügbare Version unter PostgreSQL 10. Dies ist im gelben Vorsichtsfeld auf der PostgreSQL-Releaseseite dokumentiert. Dies gilt auch für Cloud SQL-Lesereplikate.
Da Hash-Index-Updates nicht an das Lesereplikat unter PostgreSQL 9.6 weitergegeben werden, können sie nicht vom Replikat verwendet werden. Als Behelfslösung können Sie entweder auf Lesereplikate verzichten oder ein Upgrade auf eine PostgreSQL-Hauptversion (10 oder höher) durchführen.
Regionenübergreifende Lesereplikate
Mit der regionenübergreifenden Replikation können Sie ein Lesereplikat in einer anderen Region als der primären Instanz erstellen. Sie erstellen ein regionsübergreifendes Lesereplikat genauso wie ein Replikat für eine einzige Region.
Regionenübergreifende Replikate:
- verbessern die Leseleistung, da Replikate geografisch näher an Ihrer Anwendung verfügbar gemacht werden,
- stellen eine zusätzliche Notfallwiederherstellungsfunktion bereit, damit Sie vor dem Ausfall einer ganzen Region geschützt sind und
- ermöglichen die Datenmigration von einer Region in eine andere.
Weitere Informationen zu regionenübergreifenden Replikaten finden Sie unter Regionenübergreifende Replikate.
Kaskadierende Lesereplikate
Mit der kaskadierenden Replikation können Sie ein Lesereplikat unter einem anderen Lesereplikat in derselben oder einer anderen Region erstellen. Die folgenden Szenarien sind Anwendungsfälle für die Verwendung kaskadierender Replikate:
- Notfallwiederherstellung: Sie können eine kaskadierende Hierarchie von Lesereplikaten verwenden, um die Topologie Ihrer primären Instanz und der zugehörigen Lesereplikate zu simulieren. Während eines Ausfalls wird das ausgewählte Lesereplikat zur primären Instanz hochgestuft. Die Lesereplikate unter der neuen primären Instanz werden weiterhin repliziert und sind einsatzbereit.
- Leistungsverbesserungen: Um die Belastung der primären Instanz zu reduzieren, können Sie die Replikationsarbeit auf mehrere Lesereplikate verteilen.
- Lesevorgänge skalieren: Sie können weitere Replikate haben, um die Leselast zu teilen.
- Kostenreduzierung: Sie können Netzwerkkosten reduzieren, indem Sie ein einzelnes kaskadierendes Replikat mit regionenübergreifender Replikation in anderen Regionen verwenden.
Terminologie
- Kaskadierendes Replikat: Ein Lesereplikat, das ein eigenes Replikat haben kann.
- Ebenen: Sie können Ebenen von Replikaten in einer kaskadierenden Replikathierarchie erstellen. Beispiel: Wenn Sie einer Instanz vier Replikate hinzufügen, befinden sich diese vier Replikate auf derselben Ebene.
- Gleichgeordnete Instanzen: Mehrere Replikate, die aus derselben primären Instanz repliziert wurden. Gleichgeordnete Elemente befinden sich in der Replikathierarchie auf derselben Ebene. Ein Replikat kann offiziell bis zu acht gleichgeordnete Elemente haben.
- Leaf replica: A read replica that does not have any replicas of its own. In einer mehrstufigen Replikationshierarchie ist das Blatt-Replikat die letzte Ebene.
- Hochstufen: Eine Aktion, bei der ein Replikat auf einer beliebigen Hierarchieebene in eine primäre Instanz umgewandelt wird. Beim Hochstufen wird die kaskadierende Replikathierarchie beibehalten.
Kaskadierende Replikate konfigurieren
Mit kaskadierenden Replikaten können Sie Lesereplikate vorhandenen Replikaten hinzufügen. Sie können bis zu vier Replikatebenen hinzufügen, einschließlich der primären Instanz. Wenn Sie das oberste Replikat einer kaskadierende Hierarchie hochstufen, wird es zu einer primären Instanz, deren kaskadierenden Replikate weiterhin repliziert werden.
Zum Planen der Konfiguration benötigen Sie eine Zielaktion für die Lesereplikate. In den nächsten beiden Abschnitten werden die Konfigurationen für die Notfallwiederherstellung und die Replikation in mehreren Regionen beschrieben.
Notfallwiederherstellung
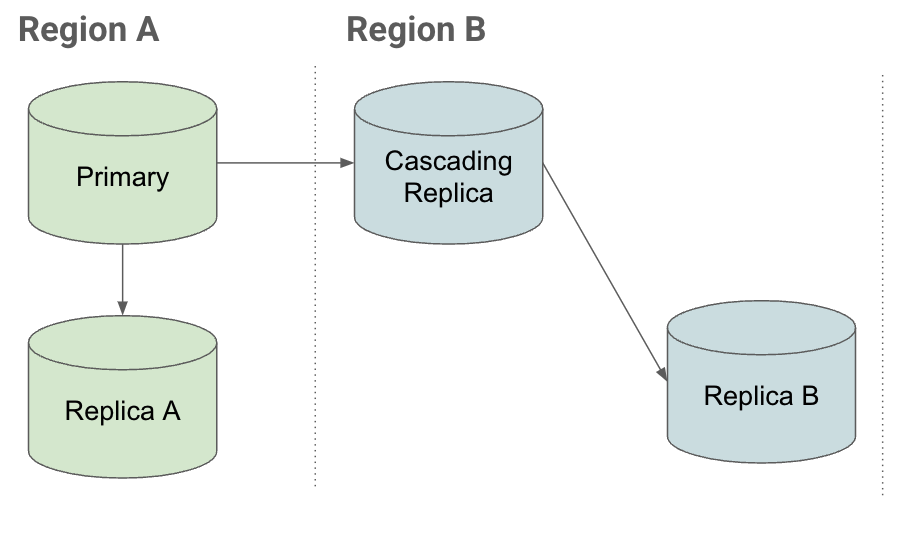
Um zu verstehen, wie kaskadierende Replikate bei einem Ausfall zu einer schnellen Erholung beitragen können, sollten Sie das folgende Replikationsszenario betrachten:
Konfiguration
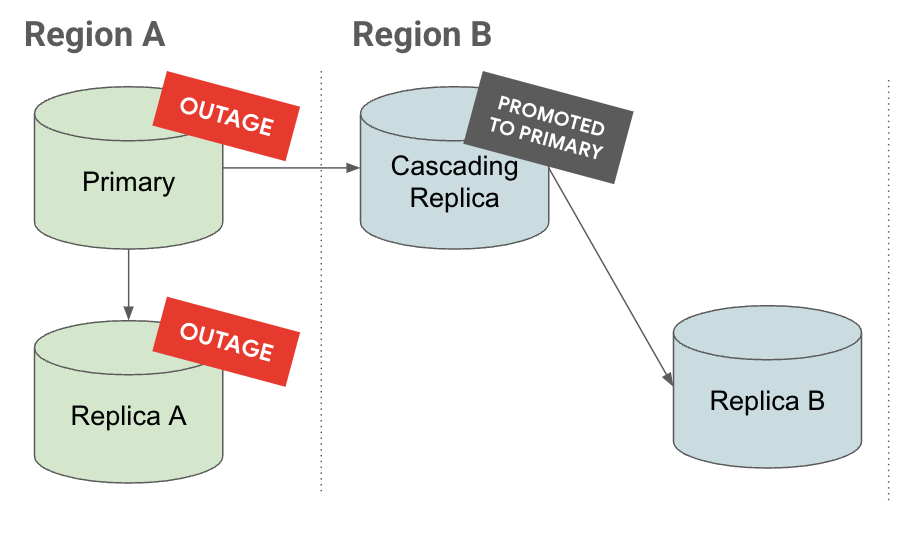
Ausfall
Werbung
Wenn Sie eine Instanz in Region B in einer Konfiguration für die Notfallwiederherstellung verwenden möchten und Folgendes haben:
- Replikate in derselben Region, die der primären Instanz zugeordnet ist (Replikat A)
- Replikate in anderen Regionen (kaskadierendes Replikat), die mit dem primären Element verbunden sind.
Sie können Lesereplikate unter dem kaskadierenden Replikat in Region B erstellen.
Wenn auf dem Tab Ausfall ein Ausfall in Region A auftritt, wird das kaskadierende Replikat zu einer primären Instanz hochgestuft. Es befinden sich bereits Lesereplikate unter ihm, wodurch das RTO (Recovery Time Objective) reduziert wird.
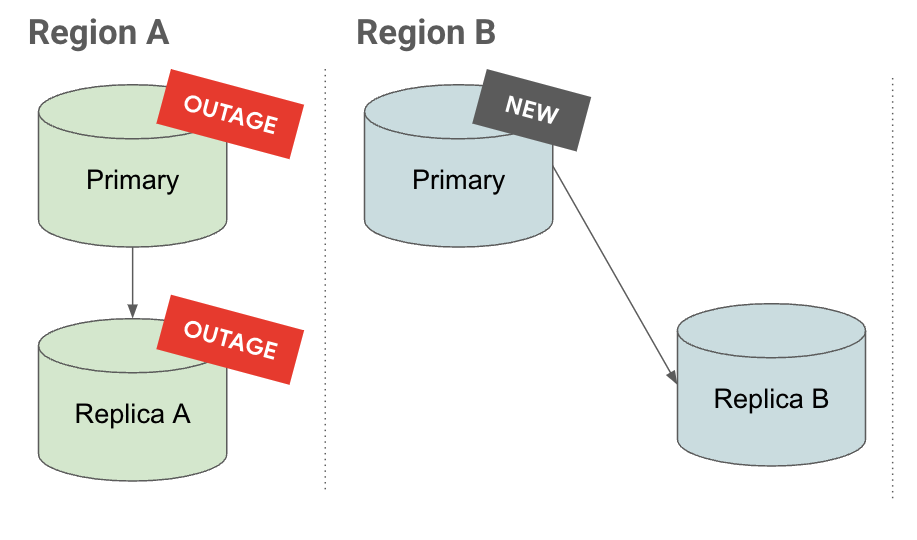
Auf dem Tab Hochstufen sehen Sie, dass beim Hochstufen eines kaskadierenden Replikats unter diesem auch dessen Replikate hochgestuft und repliziert werden.
Replikation für mehrere Regionen
Another use case for cascading replicas is to distribute read capacity to a second region in a cost-efficient manner. Cascading replicas C and D can be created that replicate from Replica B. Clients can distribute read queries across replicas B, C, and D to reduce the load on each replica. The cost of cross-region network traffic is incurred only once, from the primary instance to Replica B. Die Replikation von B nach C und D verwendet die kostenlose Netzwerkübertragung innerhalb der Region.
Sie können eine Hierarchie von bis zu vier Instanzen mit kaskadierenden Replikaten für die Replikation über mehrere Regionen erstellen:
Primär A → Replikat B → Replikat C und Replikat D
Beschränkungen
- Sie können kein Replikat löschen, unter dem Replikate existieren. Um ein solches Replikat zu löschen, müssen Sie mit den Blattreplikaten beginnen und sich durch die Hierarchie nach oben arbeiten.
- Die Abhängigkeit von Zirkelregionen wird nicht unterstützt. Damit das kaskadierende Replikat in derselben Region wie die primäre Instanz vorhanden ist, muss sich auch das kaskadierende Replikat in dieser Region befinden.
Logische Replikation
Mit Cloud SQL können Sie Ihre eigenen Replikationslösungen mit den logischen Replikationsfunktionen von PostgreSQL konfigurieren. Die logische Replikation ist eine flexible Lösung, die Folgendes ermöglicht:
- Standardreplikation von einer primären Instanz zu einem Replikat
- Selektive Replikation nur für bestimmte Tabellen oder Zeilen
- Replikation in PostgreSQL-Hauptversionen
- Replikation in Nicht-PostgreSQL-Datenbanken
- CDC-Workflows (Change Data Capture), bei denen alle Datenbankänderungen an einen Nutzer gestreamt werden
Weitere Informationen finden Sie unter Logische Replikation einrichten. Diese Seite enthält Informationen zu:
- Integrierte logische Replikation
- Die pglogical-Erweiterung
Anwendungsfälle für Replikation
Für jeden Replikationstyp gelten die folgenden Anwendungsfälle:
| Name | Primär | Replikat | Vorteile und Anwendungsfälle | Weitere Informationen |
|---|---|---|---|---|
| Lesereplikat | Cloud SQL-Instanz | Cloud SQL-Instanz |
|
|
| Regionenübergreifendes Lesereplikat | Cloud SQL-Instanz | Cloud SQL-Instanz |
|
|
| Logische Replikation | Beliebige PostgreSQL-Instanz | Eine PostgreSQL-Instanz oder ein externer Nutzer |
|
Abrechnung
- Für ein Lesereplikat wird derselbe Preis berechnet wie für eine Cloud SQL-Standardinstanz. Für die Datenreplikation entstehen keine Gebühren.
- Die Preise für das regionenübergreifende Lesereplikat sind dieselben wie beim Erstellen einer neuen Cloud SQL Instanz in der Region. Unter Cloud SQL-Instanzpreise können Sie sich weiter informieren und die geeignete Region auswählen. Neben den regulären Kosten für die Instanz fallen für ein regionenübergreifendes Replikat Gebühren für regionenübergreifende Datenübertragung für Replikationslogs an, die von der primären Instanz an die Replikatinstanz gesendet werden, wie unter Preise für ausgehenden Netzwerktraffic beschrieben.
Kurzreferenz für Cloud SQL-Lesereplikate
| Thema | Diskussion |
|---|---|
| Sicherungen | Sie können keine Sicherungen auf dem Replikat konfigurieren. |
| Kerne und Arbeitsspeicher | Für Lesereplikate kann eine andere Anzahl von Kernen und Arbeitsspeicher verwendet werden als für die primäre Instanz. |
| Primäre Instanz löschen | Bevor Sie eine primäre Instanz löschen können, müssen Sie alle zugehörigen Lesereplikate auf eigenständige Instanzen hochstufen oder die Lesereplikate löschen. |
| Replikat löschen | Wenn Sie ein Replikat löschen, hat dies keine Auswirkungen auf den Status der primären Instanz. |
| Write-Ahead-Logging deaktivieren | Bevor Sie Write-Ahead-Logs für eine primäre Instanz deaktivieren können, müssen Sie alle ihre Lesereplikate hochstufen oder löschen. |
| Failover | Eine primäre Instanz kann nur dann ein Failover auf ein Replikat ausführen, wenn das Replikat ein DR-Replikat ist. Lesereplikate können während eines Ausfalls keinen Failover ausführen. |
| Hochverfügbarkeit | Mit Lesereplikaten können Sie Hochverfügbarkeit für die Replikate aktivieren. |
| Load-Balancing | Cloud SQL unterstützt kein Load-Balancing zwischen Replikaten. Sie können Load-Balancing für Ihre Cloud SQL-Instanz implementieren. You can also use connection pooling to distribute queries across replicas with your load balancing setup for better performance. |
| Wartungsfenster | Lesereplikate teilen sich Wartungsfenster mit der primären Instanz. Für die Replikate gelten die Wartungseinstellungen für die primäre Instanz, einschließlich des Wartungsfensters, der Neuplanung und des Zeitraums für den Wartungsausschluss. Während der Wartung aktualisiert Cloud SQL zuerst alle Lesereplikate, bevor die primäre Instanz aktualisiert wird. |
| Mehrere Lesereplikate | Cloud SQL unterstützt kaskadierende Replikate. Sie können also bis zu zehn Replikate für eine einzige primäre Instanz erstellen und Replikate bis zu vier Ebenen verketten, einschließlich der primären. |
| Private IP-Adresse | Wenn Sie eine Verbindung zu einem Replikat über eine private IP-Adresse herstellen, müssen Sie keine zusätzliche private VPC-Verbindung für das Replikat erstellen, da diese von der primären Instanz übernommen wird. |
| Primäre Instanz wiederherstellen | Sie können die primäre Instanz eines Replikats nicht wiederherstellen, solange das Replikat vorhanden ist. Bevor Sie eine Instanz aus einer Sicherung wiederherstellen oder darauf eine Wiederherstellung zu einem bestimmten Zeitpunkt durchführen, müssen Sie alle zugehörigen Replikate hochstufen oder löschen. |
| Einstellungen | Die Einstellungen der primären Instanz werden an das Replikat weitergegeben, einschließlich des Passworts für den Postgres-Nutzer und der Änderungen an der Nutzertabelle. |
| Replikat anhalten | Der Befehl stop ist bei Replikaten nicht verfügbar. Sie können restart, delete oder disable replication verwenden, aber Sie können sie nicht wie eine primäre Instanz anhalten. |
| Replikatupgrade | Upgrades können bei Lesereplikaten jederzeit Betriebsunterbrechungen verursachen. |
| Nutzertabellen | Sie können keine Änderungen am Replikat vornehmen. Alle Nutzeränderungen müssen auf der primären Instanz durchgeführt werden. |
Nächste Schritte
- Informationen zur Erstellung eines Lesereplikats
- Informationen zum Konfigurieren von Instanzen für Hochverfügbarkeit