이 튜토리얼에서는 Cloud Scheduler 및 Cloud Run Functions를 사용하여 Cloud SQL 데이터베이스의 수동 백업을 예약하는 방법을 설명합니다.
이 튜토리얼을 완료하는 데 약 30분이 소요됩니다.
먼저 테스트 데이터베이스가 포함된 git 저장소를 클론하고 Cloud Storage 버킷에 이 데이터베이스를 저장하여 환경을 설정합니다.
그런 다음 PostgreSQL용 Cloud SQL 데이터베이스 인스턴스를 만들고 Cloud Storage 버킷에서 인스턴스로 테스트 데이터베이스를 가져옵니다.
환경이 설정된 후 Pub/Sub 주제에 예약된 날짜 및 시간에 백업 트리거 메시지를 게시하는 Cloud Scheduler 작업을 만듭니다. 메시지에는 Cloud SQL 인스턴스 이름과 프로젝트 ID에 대한 정보가 포함됩니다. 메시지는 Cloud Run 함수를 트리거합니다. 이 함수는 Cloud SQL Admin API를 사용하여 Cloud SQL에서 데이터베이스 백업을 시작합니다. 이 워크플로를 다이어그램으로 나타내면 다음과 같습니다.
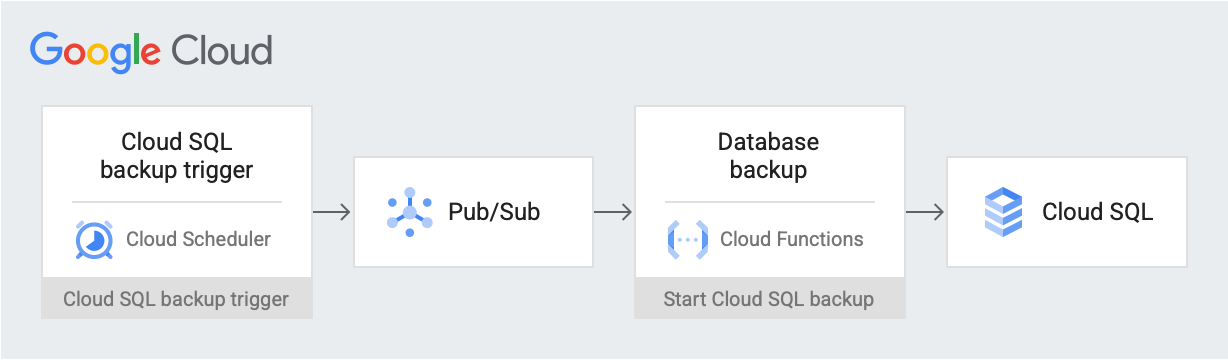
Google Cloud 구성요소
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
- Cloud Storage: Cloud SQL로 가져오는 테스트 데이터베이스를 저장합니다.
- Cloud SQL 인스턴스: 백업할 데이터베이스를 포함합니다.
- Cloud Scheduler: 정해진 일정에 따라 Pub/Sub 주제에 메시지를 게시합니다.
- Pub/Sub: Cloud Scheduler에서 전송한 메시지가 포함됩니다.
- Cloud Run 함수: Pub/Sub 주제를 구독하고 트리거되면 Cloud SQL 인스턴스에 API를 호출하여 백업을 시작합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Google Cloud 콘솔에서 API 페이지로 이동하여 다음 API를 사용 설정합니다.
- Cloud SQL Admin API
- Cloud Run Functions API
- Cloud Scheduler API
- Cloud Build API
- App Engine Admin API
이 튜토리얼의 나머지 부분에서는 Cloud Shell에서 모든 명령어를 실행합니다.
환경 설정하기
시작하려면 먼저 샘플 데이터가 있는 저장소를 클론합니다. 그런 후 환경을 구성하고 이 튜토리얼에 필요한 권한이 있는 커스텀 역할을 만듭니다.
Cloud Shell에서 이 튜토리얼의 모든 작업을 수행할 수 있습니다.
샘플 데이터가 있는 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/training-data-analyst.gittraining-data-analyst저장소의 데이터를 사용하여 가상 레코드가 있는 데이터베이스를 만듭니다.다음 환경 변수를 구성합니다.
export PROJECT_ID=`gcloud config get-value project` export DEMO="sql-backup-tutorial" export BUCKET_NAME=${USER}-PostgreSQL-$(date +%s) export SQL_INSTANCE="${DEMO}-sql" export GCF_NAME="${DEMO}-gcf" export PUBSUB_TOPIC="${DEMO}-topic" export SCHEDULER_JOB="${DEMO}-job" export SQL_ROLE="sqlBackupCreator" export STORAGE_ROLE="simpleStorageRole" export REGION="us-west2"이 튜토리얼에 필요한 권한만 있는 두 개의 커스텀 역할을 만듭니다.
gcloud iam roles create ${STORAGE_ROLE} --project ${PROJECT_ID} \ --title "Simple Storage role" \ --description "Grant permissions to view and create objects in Cloud Storage" \ --permissions "storage.objects.create,storage.objects.get"gcloud iam roles create ${SQL_ROLE} --project ${PROJECT_ID} \ --title "SQL Backup role" \ --description "Grant permissions to backup data from a Cloud SQL instance" \ --permissions "cloudsql.backupRuns.create"이러한 역할은 최소 권한의 원칙에 따라 Cloud Run 함수 및 Cloud SQL 서비스 계정의 액세스 범위를 줄입니다.
Cloud SQL 인스턴스 만들기
이 섹션에서는 Cloud Storage 버킷과 PostgreSQL용 Cloud SQL 인스턴스를 만듭니다. 그런 다음 테스트 데이터베이스를 Cloud Storage 버킷에 업로드하고 버킷의 해당 데이터베이스를 Cloud SQL 인스턴스로 가져옵니다.
Cloud Storage 버킷 만들기
gcloud CLI를 사용하여 Cloud Storage 버킷을 만듭니다.
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
Cloud SQL 인스턴스를 만들고 해당 서비스 계정에 대해 권한을 부여합니다.
다음으로 Cloud SQL 인스턴스를 만들고 서비스 계정에 백업 실행을 만들 수 있는 권한을 부여합니다.
PostgreSQL용 Cloud SQL 인스턴스를 만듭니다.
gcloud sql instances create ${SQL_INSTANCE} --database-version POSTGRES_13 --region ${REGION}이 작업을 완료하는 데 몇 분 정도 걸립니다.
Cloud SQL 인스턴스가 실행 중인지 확인합니다.
gcloud sql instances list --filter name=${SQL_INSTANCE}결과는 다음과 유사합니다.
NAME DATABASE_VERSION LOCATION TIER PRIMARY_ADDRESS PRIVATE_ADDRESS STATUS sql-backup-tutorial POSTGRES_13 us-west2-b db-n1-standard-1 x.x.x.x - RUNNABLE
Cloud SQL 서비스 계정에 단순 저장소 역할을 사용하여 Cloud Storage로 데이터를 내보낼 권한을 부여합니다.
export SQL_SA=(`gcloud sql instances describe ${SQL_INSTANCE} \ --project ${PROJECT_ID} \ --format "value(serviceAccountEmailAddress)"`) gcloud storage buckets add-iam-policy-binding gs://${BUCKET_NAME} \ --member=serviceAccount:${SQL_SA} \ --role=projects/${PROJECT_ID}/roles/${STORAGE_ROLE}
Cloud SQL 인스턴스에 샘플 데이터를 채웁니다.
이제 파일을 버킷에 업로드하고 샘플 데이터베이스를 만들고 채울 수 있습니다.
클론한 저장소로 이동합니다.
cd training-data-analyst/CPB100/lab3a/cloudsql디렉터리에 있는 파일을 새 버킷에 업로드합니다.
gcloud storage cp * gs://${BUCKET_NAME}샘플 데이터베이스를 만듭니다. '계속하시겠어요(Y/n)?' 메시지가 표시되면 Y(예)를 입력하여 계속 진행합니다.
gcloud sql import sql ${SQL_INSTANCE} gs://${BUCKET_NAME}/table_creation.sql --project ${PROJECT_ID}데이터베이스를 채웁니다. '계속하시겠어요(Y/n)?' 메시지가 표시되면 Y(예)를 입력하여 계속 진행합니다.
gcloud sql import csv ${SQL_INSTANCE} gs://${BUCKET_NAME}/accommodation.csv \ --database recommendation_spark \ --table Accommodationgcloud sql import csv ${SQL_INSTANCE} gs://${BUCKET_NAME}/rating.csv \ --database recommendation_spark \ --table Rating
주제, 함수, 스케줄러 작업 만들기
이 섹션에서는 커스텀 IAM 서비스 계정을 만들고 환경 설정에서 만든 커스텀 SQL 역할에 바인딩합니다. 그런 다음 Pub/Sub 주제 및 주제를 구독하는 Cloud Run 함수를 만들고 Cloud SQL Admin API를 사용하여 백업을 시작합니다. 마지막으로 Cloud Scheduler 작업을 만들어 Pub/Sub 주제에 주기적으로 메시지를 게시합니다.
Cloud Run 함수의 서비스 계정 만들기
첫 번째 단계는 커스텀 서비스 계정을 만들고 환경 설정에서 만든 커스텀 SQL 역할에 이를 결합하는 것입니다.
Cloud Run 함수에서 사용할 IAM 서비스 계정을 만듭니다.
gcloud iam service-accounts create ${GCF_NAME} \ --display-name "Service Account for GCF and SQL Admin API"Cloud Run 함수 서비스 계정에 커스텀 SQL 역할에 대한 액세스 권한을 부여합니다.
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${GCF_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="projects/${PROJECT_ID}/roles/${SQL_ROLE}"
Pub/Sub 주제 만들기
다음 단계에서는 Cloud SQL 데이터베이스와 상호작용하는 Cloud Run 함수를 트리거하기 위해 사용되는 Pub/Sub 주제를 만듭니다.
gcloud pubsub topics create ${PUBSUB_TOPIC}
Cloud Run 함수 만들기
다음으로 Cloud Run 함수를 만듭니다.
다음을 Cloud Shell에 붙여넣어
main.py파일을 만듭니다.cat <<EOF > main.py import base64 import logging import json from datetime import datetime from httplib2 import Http from googleapiclient import discovery from googleapiclient.errors import HttpError from oauth2client.client import GoogleCredentials def main(event, context): pubsub_message = json.loads(base64.b64decode(event['data']).decode('utf-8')) credentials = GoogleCredentials.get_application_default() service = discovery.build('sqladmin', 'v1beta4', http=credentials.authorize(Http()), cache_discovery=False) try: request = service.backupRuns().insert( project=pubsub_message['project'], instance=pubsub_message['instance'] ) response = request.execute() except HttpError as err: logging.error("Could NOT run backup. Reason: {}".format(err)) else: logging.info("Backup task status: {}".format(response)) EOF다음을 Cloud Shell에 붙여넣어
requirements.txt파일을 만듭니다.cat <<EOF > requirements.txt google-api-python-client Oauth2client EOF코드를 배포합니다.
gcloud functions deploy ${GCF_NAME} \ --trigger-topic ${PUBSUB_TOPIC} \ --runtime python37 \ --entry-point main \ --service-account ${GCF_NAME}@${PROJECT_ID}.iam.gserviceaccount.com
Cloud Scheduler 작업 만들기
마지막으로 Cloud Scheduler 작업을 만들어 데이터 백업 함수를 1시간마다 주기적으로 트리거합니다. Cloud Scheduler에서 App Engine 인스턴스를 배포에 사용합니다.
Cloud Scheduler 작업을 위한 App Engine 인스턴스를 만듭니다.
gcloud app create --region=${REGION}Cloud Scheduler 작업을 만듭니다.
gcloud scheduler jobs create pubsub ${SCHEDULER_JOB} \ --schedule "0 * * * *" \ --topic ${PUBSUB_TOPIC} \ --message-body '{"instance":'\"${SQL_INSTANCE}\"',"project":'\"${PROJECT_ID}\"'}' \ --time-zone 'America/Los_Angeles'
솔루션 테스트
마지막 단계는 솔루션을 테스트하는 것입니다. 먼저 Cloud Scheduler 작업을 실행합니다.
Cloud Scheduler 작업을 수동으로 실행하여 데이터베이스의 PostgreSQL 덤프를 트리거합니다.
gcloud scheduler jobs run ${SCHEDULER_JOB}PostgreSQL 인스턴스에서 수행된 작업을 나열하고
BACKUP_VOLUME유형의 작업이 있는지 확인합니다.gcloud sql operations list --instance ${SQL_INSTANCE} --limit 1출력에 완료된 백업 작업이 표시됩니다. 예를 들면 다음과 같습니다.
NAME TYPE START END ERROR STATUS 8b031f0b-9d66-47fc-ba21-67dc20193749 BACKUP_VOLUME 2020-02-06T21:55:22.240+00:00 2020-02-06T21:55:32.614+00:00 - DONE
삭제
다음 단계를 수행하여 이 튜토리얼에서 사용된 리소스에 대한 비용이 Google Cloud 계정에 청구되지 않도록 할 수 있습니다. 비용이 청구되지 않도록 하는 가장 쉬운 방법은 가이드에서 만든 프로젝트를 삭제하는 것입니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
전체 프로젝트를 삭제하지 않으려면 생성된 각 리소스를 삭제하세요. 이렇게 하려면 Google Cloud 콘솔에서 적절한 페이지로 이동하여 리소스를 선택하고 삭제합니다.
다음 단계
- Cloud Scheduler를 사용하여 컴퓨팅 인스턴스를 예약하는 방법 알아보기
- Cloud SQL 백업 자세히 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기