Speech-to-Text
Transforme voz em texto com a IA do Google
Converta áudio em transcrições de texto e integre o reconhecimento de fala em aplicativos com APIs fáceis de usar.
Clientes novos também ganham até US$ 300 em créditos para testar a solução Speech-to-Text e outros produtos do Google Cloud.
Recursos
IA de fala avançada
A Speech-to-Text pode usar o Chirp, o modelo básico do Google Cloud para fala com milhões de horas de dados de áudio e bilhões de frases de texto.Isso contrasta com as técnicas tradicionais de reconhecimento de fala que se concentram em grandes quantidades de dados supervisionados específicos da linguagem. Essas técnicas melhoram o reconhecimento e a transcrição de idiomas e sotaques falados.
Suporte para mais de 85 idiomas e variantes
Crie uma base global de usuários com amplo suporte a idiomas. Transcreva dados de áudio curtos, longos e até mesmo com streaming. A Speech-to-Text também oferece aos usuários implantações mais precisas e ampliadas ao redor do mundo para transcrição com o Chirp 3, a próxima geração de modelos de fala universais.
Chirp 3: a transcrição foi desenvolvida usando treinamento autossupervisionado em milhões de horas de áudio e 28 bilhões de frases de texto em mais de 100 idiomas.
Streaming de reconhecimento de fala
Receba resultados do reconhecimento de fala em tempo real conforme a API processa a entrada de áudio transmitida com o microfone do seu aplicativo ou enviada em um arquivo de áudio pré-gravado (in-line ou com o Cloud Storage).
Reconhecimento de fala e transcrição com tecnologia de IA
O Speech-to-Text usa a adaptação de modelo para melhorar a precisão de palavras usadas com frequência, expandir o vocabulário disponível para transcrição e melhorar a transcrição de áudios barulhentos. A adaptação de modelos permite que os usuários personalizem a Speech-to-Text para reconhecer palavras ou frases específicas com mais frequência do que outras opções sugeridas. Por exemplo, é possível direcionar a conversão de voz em texto para a transcrição de "clima" em vez de "se".
Compliance regulamentar e de segurança pronta para uso
A API Speech-to-Text v2 oferece aos clientes empresariais e corporativos requisitos regulatórios e de segurança adicionais prontos para uso. A residência de dados possibilita a invocação de modelos de transcrição por meio de um serviço totalmente regionalizado que acessa regiões do Google Cloud, como Singapura e Bélgica. Os registros para geração e transcrição de recursos são disponibilizados facilmente no console do Google Cloud. Já a API Speech-to-Text v2 oferece criptografia de nível empresarial com chaves de criptografia gerenciadas pelo cliente para todos os recursos, além de transcrição em lote.
Adaptação de fala
Forneça dicas para personalizar o reconhecimento de fala e transcrever termos específicos de um domínio e palavras raras. Assim você também poderá melhorar a acurácia da sua transcrição de palavras ou frases específicas. Converta automaticamente números falados em endereços, anos, moedas e muito mais usando classes.
Speech-to-Text On-Prem
Tenha controle total sobre sua infraestrutura e dados de fala protegidos ao usar a tecnologia de reconhecimento de fala do Google no local diretamente nos seus data centers particulares. Entre em contato com a equipe de vendas para começar.
Reconhecimento de diversos canais
A Speech-to-Text pode reconhecer diferentes canais em uma situação com diversos locutores (como uma videoconferência) e anotar as transcrições para preservar a ordem.
Robustez de ruído
A Speech-to-Text é capaz de gerenciar áudios com ruídos de vários ambientes sem precisar de um cancelamento de ruído extra.
Modelos específicos do domínio
Escolha dentre uma variedade de modelos treinados para chamadas telefônicas, transcrição de vídeo e controle de voz otimizados para requisitos de qualidade de domínios específicos. Por exemplo, nosso modelo aprimorado de chamada telefônica é ajustado para áudios originados da telefonia, como ligações gravadas em uma taxa de amostragem de 8 khz.
Filtragem de conteúdo
O filtro de linguagem obscena ajuda você a detectar conteúdo inapropriado ou não profissional nos seus dados de áudio, além de remover palavras obscenas nos resultados em texto.
Avaliação de transcrição
Faça upload dos seus dados de voz, e eles serão transcritos sem códigos. Avalie a qualidade ao iterar na sua configuração.
Pontuação automática (Beta)
A Speech-to-Text pontua com precisão as transcrições, por exemplo, fornecendo vírgulas, pontos de interrogação e pontos.
Diarização de locutor
Saiba quem disse o quê com as previsões automáticas sobre quais locutores emitiram quais falas em uma conversa.
Comparar o modelo Chirp de Speech-to-Text na API e no Vertex AI Studio
| Produto | O que é | Ideal para | Principais recursos |
|---|---|---|---|
Chirp 3: transcrição na Vertex AI | Uma interface gráfica do usuário baseada na Web e sem código que é simples de usar. | Teste arquivos de áudio rapidamente, crie protótipos com agilidade, faça transcrições de áudio e envie áudios ou gravações diretamente para um navegador da Web. | - Detecção e transcrição de idiomas multilíngues aprimoradas - Compatível com transcrição em mais de 85 idiomas e variantes - Suporte para diarização de locutor e adaptação de modelo - Reconhecimento de fala automático, transcrevendo áudio em texto - Detecção e transcrição de idiomas multilíngues |
Chirp 3: transcrição na API Speech-to-Text V2 | Uma API que é a próxima geração do modelo universal de conversão de voz em texto do Google, unificando dados de vários idiomas. | Como criar aplicativos escalonáveis de nível empresarial. Fácil integração da transcrição ao software atual. | - Detecção e transcrição de idiomas multilíngues aprimoradas - Compatível com transcrição em mais de 85 idiomas e variantes - Suporte para diarização de locutor e adaptação de modelo - Reconhecimento de fala automático, transcrevendo áudio em texto - Detecção e transcrição de idiomas multilíngues |
Chirp 3: transcrição na Vertex AI
Uma interface gráfica do usuário baseada na Web e sem código que é simples de usar.
Teste arquivos de áudio rapidamente, crie protótipos com agilidade, faça transcrições de áudio e envie áudios ou gravações diretamente para um navegador da Web.
- Detecção e transcrição de idiomas multilíngues aprimoradas
- Compatível com transcrição em mais de 85 idiomas e variantes
- Suporte para diarização de locutor e adaptação de modelo
- Reconhecimento de fala automático, transcrevendo áudio em texto
- Detecção e transcrição de idiomas multilíngues
Chirp 3: transcrição na API Speech-to-Text V2
Uma API que é a próxima geração do modelo universal de conversão de voz em texto do Google, unificando dados de vários idiomas.
Como criar aplicativos escalonáveis de nível empresarial.
Fácil integração da transcrição ao software atual.
- Detecção e transcrição de idiomas multilíngues aprimoradas
- Compatível com transcrição em mais de 85 idiomas e variantes
- Suporte para diarização de locutor e adaptação de modelo
- Reconhecimento de fala automático, transcrevendo áudio em texto
- Detecção e transcrição de idiomas multilíngues
Como funciona
A Speech-to-Text tem três métodos principais para realizar o reconhecimento de fala: síncrono, assíncrono e streaming. Cada método retorna resultados de texto com base na necessidade da transcrição no pós-processamento, periodicamente ou em tempo real. Simplificando, você inserirá dados de áudio e receberá uma resposta em texto.
A Speech-to-Text tem três métodos principais para realizar o reconhecimento de fala: síncrono, assíncrono e streaming. Cada método retorna resultados de texto com base na necessidade da transcrição no pós-processamento, periodicamente ou em tempo real. Simplificando, você inserirá dados de áudio e receberá uma resposta em texto.
Demonstração
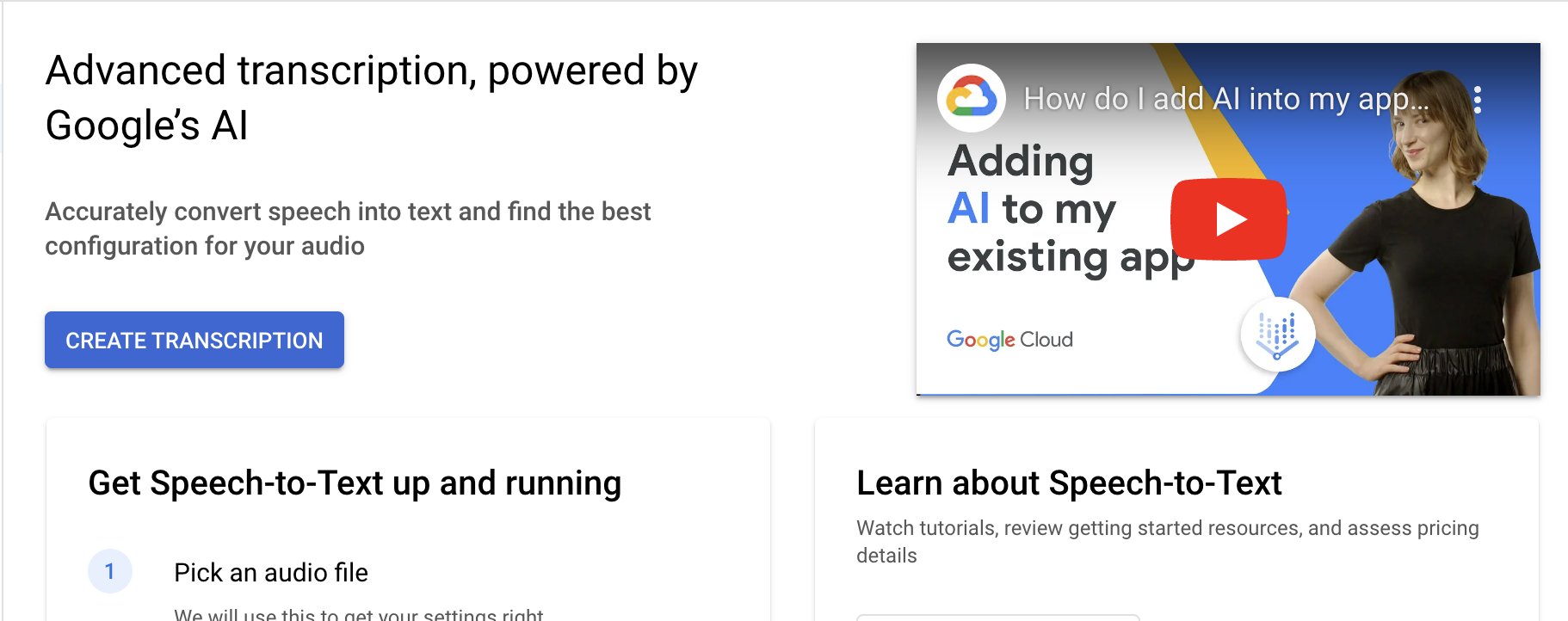
Testar a API Speech-to-Text
Crie rapidamente uma transcrição de áudio com um upload de arquivo ou falando diretamente em um microfone.
Usos comuns
Transcrever áudio
Criar uma transcrição de áudio
Criar uma transcrição de áudio
Tutoriais, guias de início rápido e laboratórios
Criar uma transcrição de áudio
Criar uma transcrição de áudio
Transcreva vídeos usando a IA
Criar legendas para vídeos usando a IA
Criar legendas para vídeos usando a IA
Transcreva seu áudio e vídeo para incluir legendas. Adicione legendas a conteúdos já existentes ou ao streaming em tempo real. Nosso Chirp 3: Transcrição é ideal para indexar ou legendar conteúdo de vídeo e/ou com diversos interlocutores. Além disso, ele usa uma tecnologia de aprendizado de máquina semelhante à do YouTube para legendas.
Neste tutorial, mostramos como usar as APIs Speech-to-Text e Translation dos serviços de IA do Google Cloud para adicionar legendas a vídeos e fornecer legendas localizadas em outros idiomas.
Tutoriais, guias de início rápido e laboratórios
Criar legendas para vídeos usando a IA
Criar legendas para vídeos usando a IA
Transcreva seu áudio e vídeo para incluir legendas. Adicione legendas a conteúdos já existentes ou ao streaming em tempo real. Nosso Chirp 3: Transcrição é ideal para indexar ou legendar conteúdo de vídeo e/ou com diversos interlocutores. Além disso, ele usa uma tecnologia de aprendizado de máquina semelhante à do YouTube para legendas.
Neste tutorial, mostramos como usar as APIs Speech-to-Text e Translation dos serviços de IA do Google Cloud para adicionar legendas a vídeos e fornecer legendas localizadas em outros idiomas.
Adicionar a Speech-to-Text a apps
Como adicionar a Speech-to-Text a apps
Como adicionar a Speech-to-Text a apps
Saiba como ativar a Speech-to-Text para seu aplicativo de maneira rápida e fácil com o Google Cloud. Este vídeo mostra como adicionar IA ao seu aplicativo sem ter muita experiência com modelos de machine learning. Com a API Speech-to-Text pré-treinada, é fácil e rápido ativar a IA para seu aplicativo.
Tutoriais, guias de início rápido e laboratórios
Como adicionar a Speech-to-Text a apps
Como adicionar a Speech-to-Text a apps
Saiba como ativar a Speech-to-Text para seu aplicativo de maneira rápida e fácil com o Google Cloud. Este vídeo mostra como adicionar IA ao seu aplicativo sem ter muita experiência com modelos de machine learning. Com a API Speech-to-Text pré-treinada, é fácil e rápido ativar a IA para seu aplicativo.
Traduzir áudio em texto
Linguagem, voz, texto e tradução com as APIs do Google Cloud
Linguagem, voz, texto e tradução com as APIs do Google Cloud
Neste curso, você vai usar a API Speech-to-Text para transcrever um arquivo de áudio em um arquivo de texto, traduzir com a API Google Cloud Translation e criar fala sintética com o Natural Language. IA.
Tutoriais, guias de início rápido e laboratórios
Linguagem, voz, texto e tradução com as APIs do Google Cloud
Linguagem, voz, texto e tradução com as APIs do Google Cloud
Neste curso, você vai usar a API Speech-to-Text para transcrever um arquivo de áudio em um arquivo de texto, traduzir com a API Google Cloud Translation e criar fala sintética com o Natural Language. IA.
Preços
| Como funcionam os preços da Speech-to-Text | Os preços da Speech-to-Text são baseados na versão da API, nos canais, nos métodos de lote e em qualquer custo extra de serviço do Google Cloud, como armazenamento. | |
|---|---|---|
| Versão da API | Serviço e capacidade | Preços |
API Speech-to-Text V2 | A V2 oferece residência de dados para implantações de região única e multirregional do Chirp 3. A V2 inclui registro de auditoria e suporte para chaves de criptografia gerenciadas pelo cliente. | $0,016 por minuto |
Confira os detalhes de preços da Speech-to-Text.
Como funcionam os preços da Speech-to-Text
Os preços da Speech-to-Text são baseados na versão da API, nos canais, nos métodos de lote e em qualquer custo extra de serviço do Google Cloud, como armazenamento.
API Speech-to-Text V2
A V2 oferece residência de dados para implantações de região única e multirregional do Chirp 3. A V2 inclui registro de auditoria e suporte para chaves de criptografia gerenciadas pelo cliente.
$0,016
por minuto
Confira os detalhes de preços da Speech-to-Text.











