Speech-to-Text
Mengubah ucapan menjadi teks menggunakan AI Google
Konversi audio menjadi transkripsi teks dan integrasikan pengenalan ucapan ke dalam aplikasi dengan API yang mudah digunakan.
Pelanggan baru juga mendapatkan kredit gratis senilai hingga $300 untuk mencoba Speech-to-Text dan produk Google Cloud lainnya.
Fitur
AI ucapan tingkat lanjut
Speech-to-Text dapat memanfaatkan Chirp 3, yakni model dasar Google Cloud untuk ucapan yang dilatih dengan data audio berdurasi jutaan jam dan miliaran kalimat teks. Hal ini berbeda dengan teknik pengenalan ucapan tradisional yang berfokus pada sejumlah besar data yang diawasi untuk bahasa tertentu. Teknik ini memberi pengguna pengenalan dan transkripsi yang lebih baik untuk aksen dan bahasa yang lebih sering diucapkan.
Dukungan untuk lebih dari 85 bahasa dan varian
Dibangun untuk basis pengguna global dengan dukungan bahasa yang ekstensif Transkripsikan data audio singkat, panjang, dan bahkan streaming. Speech-to-Text juga menawarkan deployment yang lebih akurat dan mencakup seluruh dunia untuk transkripsi dengan Chirp 3, model ucapan universal generasi berikutnya.
Chirp 3: Transkripsi dibuat menggunakan pelatihan yang diawasi secara mandiri dengan audio berdurasi jutaan jam dan 28 miliar kalimat teks yang mencakup lebih dari 100 bahasa.
Pengenalan ucapan saat streaming
Dapatkan hasil pengenalan ucapan real-time saat API memproses input audio yang di-streaming dari mikrofon aplikasi Anda atau dikirim dari file audio yang direkam sebelumnya (inline atau melalui Cloud Storage).
Transkripsi dan pengenalan ucapan yang didukung AI
Speech-to-Text menggunakan adaptasi model untuk meningkatkan akurasi kata yang sering digunakan, memperluas kosakata yang tersedia untuk transkripsi, dan meningkatkan transkripsi dari audio yang bising. Adaptasi model memungkinkan pengguna menyesuaikan Speech-to-Text untuk lebih sering mengenali kata atau frasa tertentu daripada opsi lain yang mungkin disarankan. Misalnya, Anda dapat membiaskan Speech-to-Text untuk mentranskripsikan "weather" daripada "whether".
Kepatuhan terhadap peraturan dan keamanan siap pakai
Speech-to-Text API v2 memberikan persyaratan keamanan dan peraturan tambahan secara langsung kepada pelanggan perusahaan dan bisnis. Residensi data memungkinkan pemanggilan model transkripsi melalui layanan yang sepenuhnya bersifat regional yang memanfaatkan region Google Cloud seperti Singapura dan Belgia. Log untuk pembuatan resource dan transkripsi tersedia dengan mudah di Konsol Google Cloud. Selain itu, Speech-to-Text API v2 menawarkan enkripsi tingkat perusahaan dengan kunci enkripsi yang dikelola pelanggan untuk semua resource serta transkripsi batch.
Adaptasi ucapan
Sesuaikan pengenalan ucapan untuk mentranskripsikan istilah khusus domain dan kata-kata langka dengan memberikan petunjuk dan meningkatkan akurasi transkripsi terhadap kata atau frasa tertentu. Konversi angka yang diucapkan menjadi alamat, tahun, mata uang, dan lainnya secara otomatis menggunakan class.
Speech-to-Text On-Prem
Miliki kontrol penuh atas infrastruktur Anda dan data ucapan yang dilindungi sambil memanfaatkan teknologi pengenalan ucapan Google di infrastruktur lokal, langsung di pusat data pribadi Anda. Hubungi bagian penjualan untuk memulai.
Pengenalan multisaluran
Speech-to-Text dapat mengenali saluran yang berbeda dalam situasi multisaluran (misalnya, konferensi video) dan menganotasi transkrip untuk mempertahankan urutan.
Penanganan kebisingan yang andal
Speech-to-Text dapat menangani audio bising dari berbagai lingkungan tanpa memerlukan peredam bising tambahan.
Model khusus domain
Pilih dari sejumlah model terlatih untuk kontrol suara dan panggilan telepon serta transkripsi video yang dioptimalkan untuk persyaratan kualitas khusus domain. Misalnya, model panggilan telepon kami yang canggih telah disesuaikan untuk audio yang berasal dari telepon, seperti panggilan telepon yang direkam pada frekuensi sampling 8 kHz.
Pemfilteran konten
Filter kata-kata tidak sopan membantu Anda mendeteksi konten yang tidak pantas atau tidak profesional dalam data audio Anda dan memfilter kata-kata tidak sopan dalam hasil teks.
Evaluasi transkripsi
Upload data suara Anda sendiri dan transkripsikan tanpa kode. Evaluasi kualitas dengan melakukan iterasi pada konfigurasi Anda.
Tanda baca otomatis (beta)
Speech-to-Text akan memberikan tanda baca dalam transkripsinya secara akurat, seperti dengan memberikan koma, tanda tanya, dan titik.
Diarisasi pembicara
Ketahui siapa yang berbicara dengan menerima prediksi otomatis terkait pembicara mana yang berbicara dalam percakapan.
Membandingkan model Chirp Speech-to-Text di API dan Agent Studio
| Produk | Apa ini | Paling cocok untuk | Fitur utama |
|---|---|---|---|
Chirp 3: Transkripsi di Platform Agen | Antarmuka pengguna grafis (GUI) berbasis web tanpa coding yang mudah digunakan. | Uji file audio dengan cepat, buat prototipe dengan cepat, buat transkripsi audio, upload audio atau rekaman langsung ke browser web. | -Peningkatan deteksi dan transkripsi multibahasa -Mendukung transkripsi dalam 85+ bahasa dan varian -Mendukung diarisasi pembicara dan adaptasi model -Pengenalan ucapan otomatis, mentranskripsikan audio menjadi teks -Deteksi dan transkripsi multibahasa |
Chirp 3: Transkripsi di Speech-to-Text V2 API | API yang merupakan model Speech-to-Text universal generasi berikutnya dari Google, yang menyatukan data dari berbagai bahasa. | Membangun aplikasi tingkat Perusahaan yang skalabel. Integrasi transkripsi yang mudah ke dalam software yang ada. | -Peningkatan deteksi dan transkripsi multibahasa -Mendukung transkripsi dalam 85+ bahasa dan varian -Mendukung diarisasi pembicara dan adaptasi model -Pengenalan ucapan otomatis, mentranskripsikan audio menjadi teks -Deteksi dan transkripsi multibahasa |
Chirp 3: Transkripsi di Platform Agen
Antarmuka pengguna grafis (GUI) berbasis web tanpa coding yang mudah digunakan.
Uji file audio dengan cepat, buat prototipe dengan cepat, buat transkripsi audio, upload audio atau rekaman langsung ke browser web.
-Peningkatan deteksi dan transkripsi multibahasa
-Mendukung transkripsi dalam 85+ bahasa dan varian
-Mendukung diarisasi pembicara dan adaptasi model
-Pengenalan ucapan otomatis, mentranskripsikan audio menjadi teks
-Deteksi dan transkripsi multibahasa
Chirp 3: Transkripsi di Speech-to-Text V2 API
API yang merupakan model Speech-to-Text universal generasi berikutnya dari Google, yang menyatukan data dari berbagai bahasa.
Membangun aplikasi tingkat Perusahaan yang skalabel.
Integrasi transkripsi yang mudah ke dalam software yang ada.
-Peningkatan deteksi dan transkripsi multibahasa
-Mendukung transkripsi dalam 85+ bahasa dan varian
-Mendukung diarisasi pembicara dan adaptasi model
-Pengenalan ucapan otomatis, mentranskripsikan audio menjadi teks
-Deteksi dan transkripsi multibahasa
Cara Kerjanya
Speech-to-Text memiliki tiga metode utama untuk melakukan pengenalan ucapan: sinkron, asinkron, dan streaming. Setiap metode menampilkan hasil teks berdasarkan perlu tidaknya transkripsi secara real time, berkala, atau pascapemrosesan. Sederhananya, Anda memasukkan data audio kemudian menerima respons berbasis teks.
Speech-to-Text memiliki tiga metode utama untuk melakukan pengenalan ucapan: sinkron, asinkron, dan streaming. Setiap metode menampilkan hasil teks berdasarkan perlu tidaknya transkripsi secara real time, berkala, atau pascapemrosesan. Sederhananya, Anda memasukkan data audio kemudian menerima respons berbasis teks.
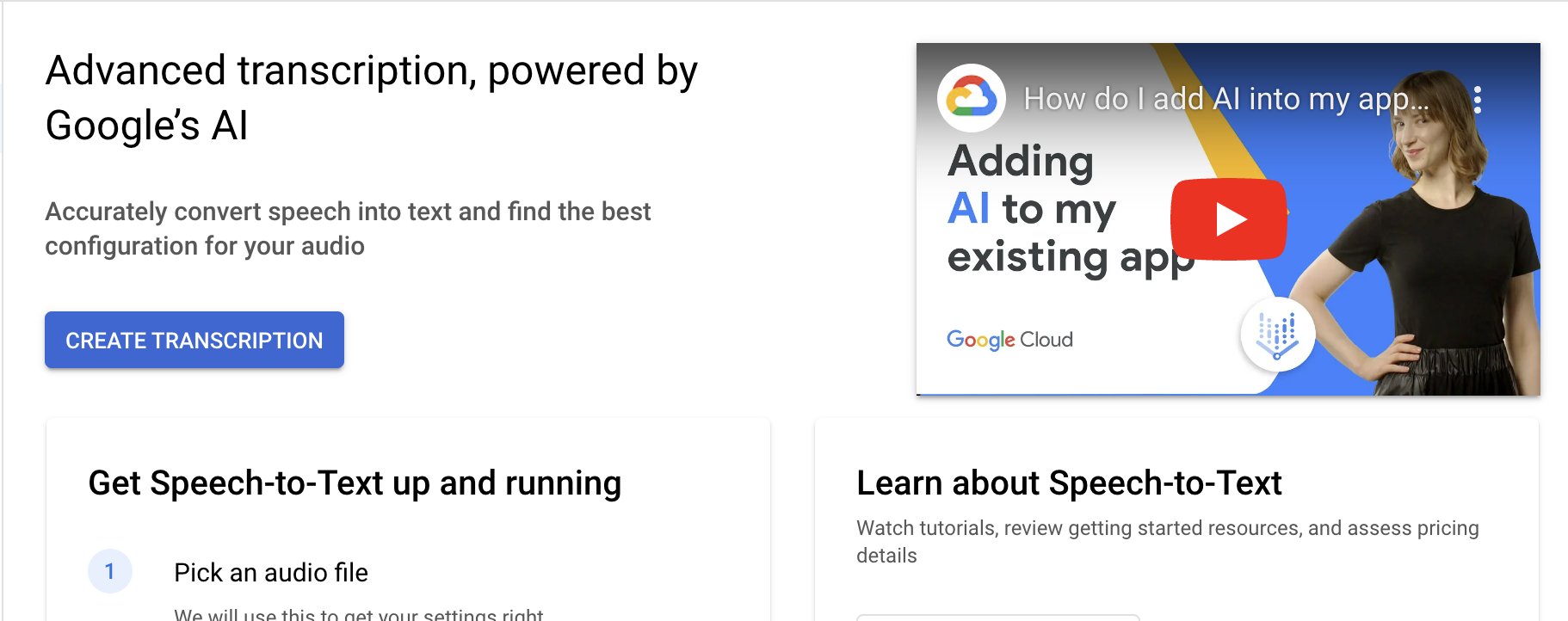
Demo
Menguji Speech-to-Text API
Buat transkripsi audio dengan cepat dari file yang diupload atau berbicara langsung ke mikrofon.
Mentranskripsikan audio
Membuat transkripsi audio
Membuat transkripsi audio
Tutorial, panduan memulai, dan lab
Membuat transkripsi audio
Membuat transkripsi audio
Membuat teks video menggunakan AI
Buat subtitel untuk video menggunakan AI
Buat subtitel untuk video menggunakan AI
Transkripsikan audio dan video Anda untuk menyertakan teks. Tambahkan subtitel ke konten yang ada atau secara real time ke konten streaming. Chirp 3: Transkripsi kami ideal untuk mengindeks atau memberi subtitel pada video dan/atau konten yang melibatkan banyak pembicara. Model ini menggunakan teknologi machine learning yang prinsipnya sama dengan pemberian teks video di YouTube.
Tutorial ini menunjukkan cara menggunakan layanan Google Cloud AI Speech-to-Text API dan Translation API untuk menambahkan subtitel ke video dan menyediakan subtitel lokal dalam bahasa lain.
Tutorial, panduan memulai, dan lab
Buat subtitel untuk video menggunakan AI
Buat subtitel untuk video menggunakan AI
Transkripsikan audio dan video Anda untuk menyertakan teks. Tambahkan subtitel ke konten yang ada atau secara real time ke konten streaming. Chirp 3: Transkripsi kami ideal untuk mengindeks atau memberi subtitel pada video dan/atau konten yang melibatkan banyak pembicara. Model ini menggunakan teknologi machine learning yang prinsipnya sama dengan pemberian teks video di YouTube.
Tutorial ini menunjukkan cara menggunakan layanan Google Cloud AI Speech-to-Text API dan Translation API untuk menambahkan subtitel ke video dan menyediakan subtitel lokal dalam bahasa lain.
Menambahkan Speech-to-Text ke aplikasi
Cara menambahkan Speech-to-Text ke aplikasi
Cara menambahkan Speech-to-Text ke aplikasi
Pelajari cara mengaktifkan Speech-to-Text untuk aplikasi Anda dengan cepat dan mudah menggunakan Google Cloud. Video ini membahas cara menambahkan AI ke aplikasi Anda tanpa memerlukan pengalaman model machine learning yang ekstensif. Dengan menggunakan Speech-to-Text API yang terlatih sebelumnya, Anda dapat mengaktifkan AI untuk aplikasi Anda dengan cepat dan mudah.
Tutorial, panduan memulai, dan lab
Cara menambahkan Speech-to-Text ke aplikasi
Cara menambahkan Speech-to-Text ke aplikasi
Pelajari cara mengaktifkan Speech-to-Text untuk aplikasi Anda dengan cepat dan mudah menggunakan Google Cloud. Video ini membahas cara menambahkan AI ke aplikasi Anda tanpa memerlukan pengalaman model machine learning yang ekstensif. Dengan menggunakan Speech-to-Text API yang terlatih sebelumnya, Anda dapat mengaktifkan AI untuk aplikasi Anda dengan cepat dan mudah.
Terjemahkan audio ke teks
Bahasa, ucapan, teks, dan terjemahan dengan Google Cloud API
Bahasa, ucapan, teks, dan terjemahan dengan Google Cloud API
Dalam kursus ini, Anda akan menggunakan Speech-to-Text API untuk mentranskripsikan file audio menjadi file teks, menerjemahkannya dengan Google Cloud Translation API, dan membuat ucapan sintetis dengan Natural Language AI.
Tutorial, panduan memulai, dan lab
Bahasa, ucapan, teks, dan terjemahan dengan Google Cloud API
Bahasa, ucapan, teks, dan terjemahan dengan Google Cloud API
Dalam kursus ini, Anda akan menggunakan Speech-to-Text API untuk mentranskripsikan file audio menjadi file teks, menerjemahkannya dengan Google Cloud Translation API, dan membuat ucapan sintetis dengan Natural Language AI.
Harga
| Cara kerja penetapan harga Speech-to-Text | Harga Speech-to-Text didasarkan pada versi API, saluran, metode batch, dan biaya layanan Google Cloud tambahan seperti penyimpanan. | |
|---|---|---|
| Versi API | Layanan dan kemampuan | Harga |
Speech-to-Text V2 API | V2 menawarkan residensi data untuk deployment Chirp 3 multi-region dan satu region. V2 menyertakan logging audit dan dukungan untuk kunci enkripsi yang dikelola pelanggan. | $0,016 per menit |
Lihat detail harga untuk Speech-to-Text.
Cara kerja penetapan harga Speech-to-Text
Harga Speech-to-Text didasarkan pada versi API, saluran, metode batch, dan biaya layanan Google Cloud tambahan seperti penyimpanan.
Speech-to-Text V2 API
V2 menawarkan residensi data untuk deployment Chirp 3 multi-region dan satu region. V2 menyertakan logging audit dan dukungan untuk kunci enkripsi yang dikelola pelanggan.
$0,016
per menit
Lihat detail harga untuk Speech-to-Text.











