数据科学解决方案
统一的数据、分析和机器学习平台,助力 AI 工作流
将复杂性转移到统一的数据和 AI 平台上,减轻数据团队的负担。Google Cloud 提供全面的托管式服务套件和集成式工作流,让您可以轻松构建、管理和扩缩数据科学解决方案。
概览
什么是数据科学解决方案?
数据科学解决方案是一种全面的技术驱动型方法,利用机器学习、AI 和统计建模来解决复杂的业务难题并提高运营效率。这使得关注点从基本数据分析转向全生命周期企业执行,强调数据工程、预测建模和 MLOps 的核心流程,将原始数据转化为自动化的战略优势。
为什么选择 Google Cloud 进行数据科学工作?
提高业务速度与敏捷性,创造短期和长期价值。传统方法通常需要将 5-7 种单独的工具拼接在一起,而 Google Cloud 的数据科学平台基于单一多模态数据基础,可涵盖从数据注入到模型部署的整个生命周期,并确保统一治理。
适用于各种业务挑战的数据科学解决方案
无论您的目标是提高收入、降低成本还是管理风险,Google Cloud 都能提供相应的工具来将数据模型工业化,并让您将重心从局部实验转移到实际的 MLOps 流水线。

面向端到端数据科学工作流的统一平台
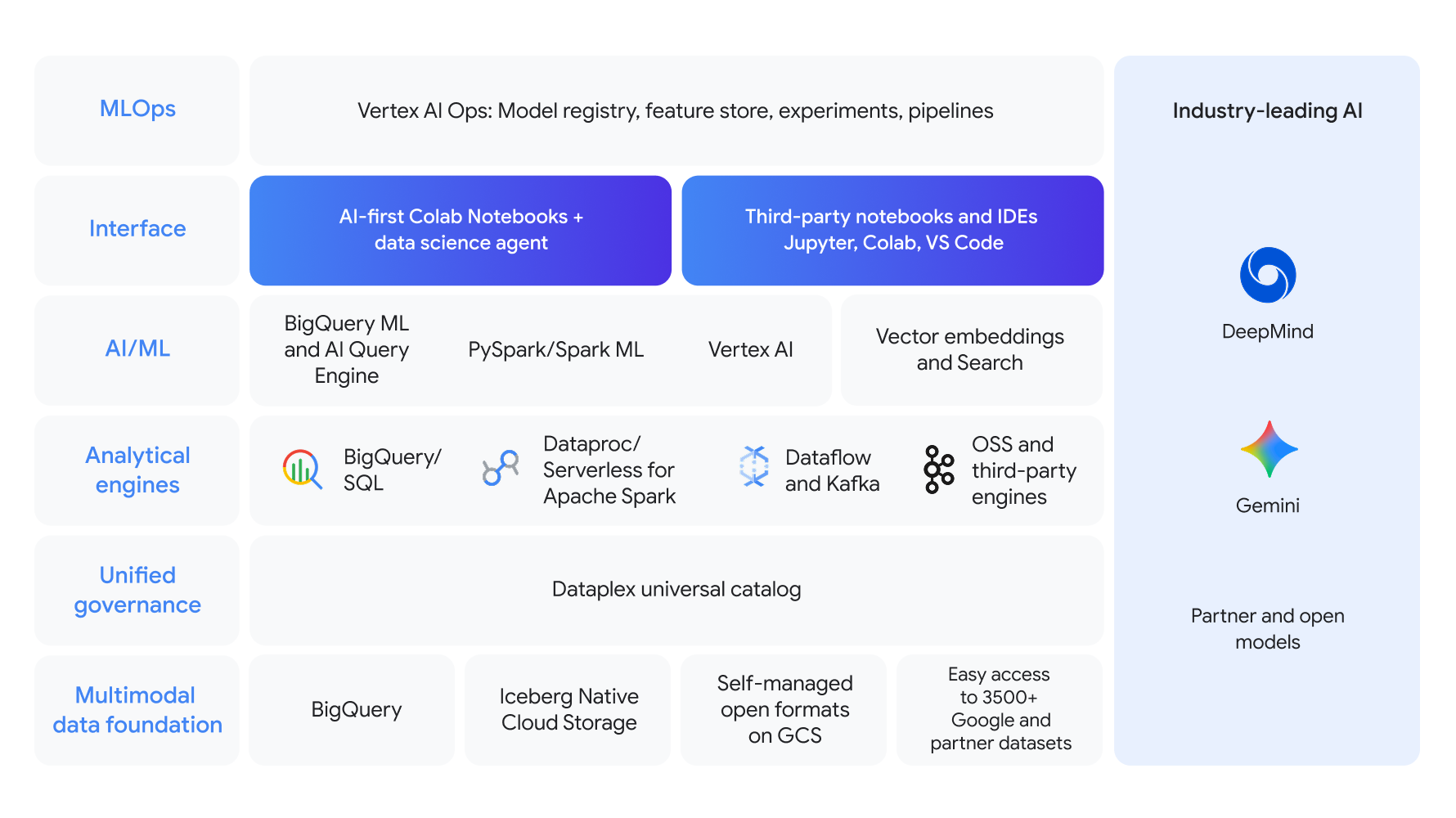
基于多模态数据基础构建,为整个数据科学和机器学习生命周期提供统一的解决方案,并确保统一治理
借助 BigQuery SQL 和 Apache Spark 等强大的分析引擎,然后使用 BigQuery ML 或 Gemini Enterprise Agent Platform 构建模型。借助 AI 优先的 Colab Enterprise 笔记本和强大的 MLOps,在行业领先 AI 技术的支持下简化开发流程。
方法指南
基于多模态数据基础构建,为整个数据科学和机器学习生命周期提供统一的解决方案,并确保统一治理
借助 BigQuery SQL 和 Apache Spark 等强大的分析引擎,然后使用 BigQuery ML 或 Gemini Enterprise Agent Platform 构建模型。借助 AI 优先的 Colab Enterprise 笔记本和强大的 MLOps,在行业领先 AI 技术的支持下简化开发流程。
以 AI 优先的笔记本为核心的集中式工作区
从一系列企业数据科学笔记本解决方案中进行选择
Colab Enterprise 提供安全、受管理的集成环境,可与 Gemini Enterprise Agent Platform 和 BigQuery 集成。Workbench 提供可自定义的 JupyterLab 实例,而 Cloud Workstations 支持完整的 IDE。扩展程序还可以将自托管工具直接连接到 Google Cloud 服务。

方法指南
从一系列企业数据科学笔记本解决方案中进行选择
Colab Enterprise 提供安全、受管理的集成环境,可与 Gemini Enterprise Agent Platform 和 BigQuery 集成。Workbench 提供可自定义的 JupyterLab 实例,而 Cloud Workstations 支持完整的 IDE。扩展程序还可以将自托管工具直接连接到 Google Cloud 服务。


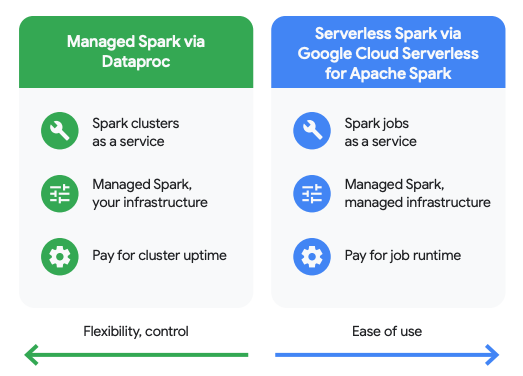
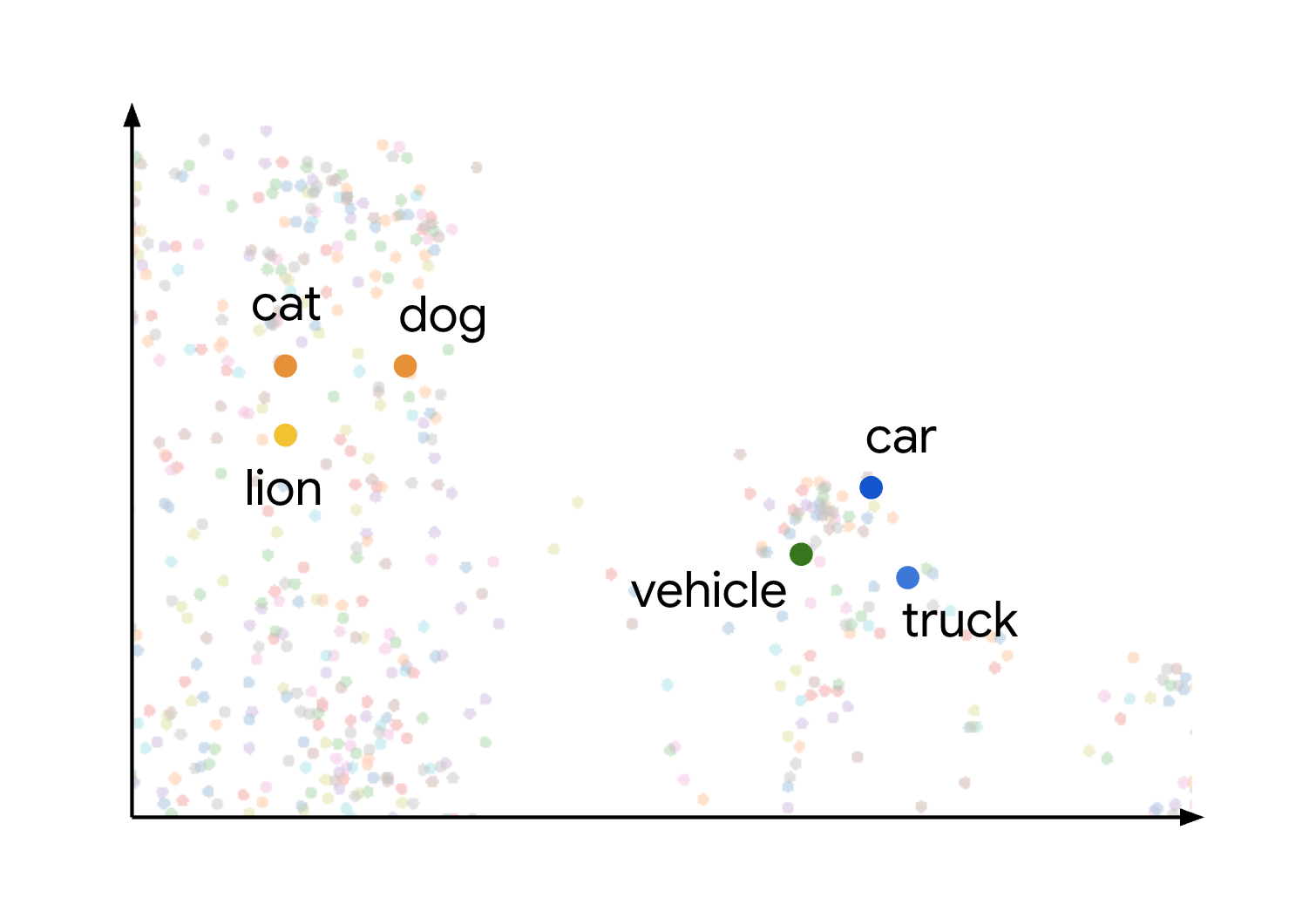
使用多个引擎灵活处理数据
方法指南
借助适用于 Python 的 BigQuery DataFrames 扩展数据科学工作
偏好 Python 原生库吗?
BigQuery DataFrames 提供类 pandas 的 API,可将 Python 代码转换为优化后的 SQL,并在 BigQuery 引擎上执行。因此,您可灵活选用合适的工具来完成对应的作业(无论是 SQL、PySpark,还是 pandas 风格的 DataFrame),同时始终基于相同的底层数据进行操作

方法指南
偏好 Python 原生库吗?
BigQuery DataFrames 提供类 pandas 的 API,可将 Python 代码转换为优化后的 SQL,并在 BigQuery 引擎上执行。因此,您可灵活选用合适的工具来完成对应的作业(无论是 SQL、PySpark,还是 pandas 风格的 DataFrame),同时始终基于相同的底层数据进行操作
构建、训练、调优和运行机器学习模型
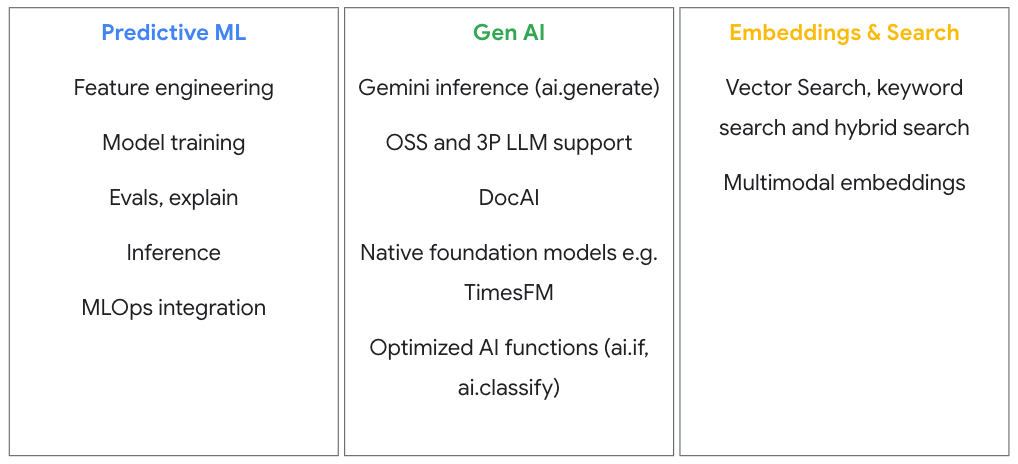
借助集成式 MLOps,让模型快速走向生产。
BigQuery 与 Gemini Enterprise Agent Platform 深度集成,简化 MLOps
将特征集中管理于 Gemini Enterprise Agent Platform Feature Store,避免训练-应用偏差与重复工作。使用 AutoML 自动构建表格数据模型。所有模型(无论来自 BigQuery ML 还是 Gemini Enterprise Agent Platform),都会自动注册到该平台的 Model Registry。之后,您可轻松完成版本管理、评估与部署,在单一平台上构建无缝的端到端生命周期。

方法指南
BigQuery 与 Gemini Enterprise Agent Platform 深度集成,简化 MLOps
将特征集中管理于 Gemini Enterprise Agent Platform Feature Store,避免训练-应用偏差与重复工作。使用 AutoML 自动构建表格数据模型。所有模型(无论来自 BigQuery ML 还是 Gemini Enterprise Agent Platform),都会自动注册到该平台的 Model Registry。之后,您可轻松完成版本管理、评估与部署,在单一平台上构建无缝的端到端生命周期。
业务用例
以成效为导向的成功




查看更多





专为数据科学团队中的每个角色打造
专为数据科学团队中的每个角色打造
常见问题解答
面向数据科学家和机器学习工程师
重点介绍 Colab Enterprise 笔记本的开发者体验、对 PyTorch 和 TensorFlow 等框架的支持,以及 BigQuery DataFrames。团队可以在项目之间共享笔记本、数据连接和计算资源,使 Google Cloud 成为真正的协作式数据科学平台。
面向数据和分析领导者
最大限度地提高投资回报率和治理水平。统一的平台可减少工具泛滥和供应商成本,并内置治理功能。无需单独的 MLOps 团队模型即可从笔记本用于生产用途,直接支持 3 倍/4 倍/10 倍的性能统计数据。
面向数据工程师和架构师
集成和灵活性可带来优势。支持开源兼容性(Apache Spark、Airflow 和 Kafka)和基于一个数据副本进行多引擎处理,确保框架不会受制于特定供应商。











