이 페이지에서는 Dataflow 파이프라인을 개발할 때 사용할 권장사항을 간략하게 설명합니다. 이러한 권장사항을 사용하면 다음과 같은 이점이 있습니다.
- 파이프라인 관측 가능성 및 성능 향상
- 개발자 생산성 향상
- 파이프라인 테스트 가능성 향상
이 페이지의 Apache Beam 코드 예시에서는 Java를 사용하지만 이 내용은 Apache Beam Java, Python, Go SDK에 적용됩니다.
고려해야 할 사항
파이프라인을 설계할 때는 다음 질문을 고려하세요.
- 파이프라인의 입력 데이터는 어디에 저장되나요? 입력 데이터 세트가 얼마나 많이 있나요?
- 데이터는 어떤 모양인가요?
- 데이터로 무엇을 하려고 하나요?
- 파이프라인의 출력 데이터는 어디로 전송되어야 하나요?
- Dataflow 작업에서 Assured Workloads를 사용하나요?
템플릿 사용
파이프라인 개발을 가속화하려면 가능한 경우 Apache Beam 코드를 작성하여 파이프라인을 빌드하는 대신 Dataflow 템플릿을 사용합니다. 템플릿에는 다음과 같은 이점이 있습니다.
- 템플릿을 재사용할 수 있습니다.
- 템플릿을 사용하면 특정 파이프라인 매개변수를 변경하여 각 작업을 맞춤설정할 수 있습니다.
- 권한을 제공하는 모든 사용자가 템플릿을 사용하여 파이프라인을 배포할 수 있습니다. 예를 들어 개발자는 템플릿에서 작업을 만들 수 있으며, 조직의 데이터 과학자는 나중에 해당 템플릿을 배포할 수 있습니다.
Google 제공 템플릿을 사용하거나 자체 템플릿을 만들 수 있습니다. 일부 Google 제공 템플릿을 사용하면 커스텀 로직을 파이프라인 단계로 추가할 수 있습니다. 예를 들어 BigQuery에 대한 Pub/Sub 템플릿은 Cloud Storage에 저장된 JavaScript 사용자 정의 함수(UDF)를 실행하기 위한 매개변수를 제공합니다.
Google이 제공하는 템플릿은 Apache License 2.0에 따른 오픈소스이므로 새 파이프라인의 기초로 사용할 수 있습니다. 템플릿은 코드 예시로도 유용합니다. GitHub 저장소에서 템플릿 코드를 봅니다.
Assured Workloads
Assured Workloads를 사용하면 Google Cloud 고객을 위한 보안 및 규정 준수 요구사항을 적용할 수 있습니다. 예를 들어 주권 제어가 포함된 EU 리전 및 지원은 EU 기반 고객을 위해 데이터 상주 및 데이터 주권 보장을 적용하는 데 도움이 됩니다. 이러한 기능을 제공하기 위해 일부 Dataflow 기능은 제한되거나 한도가 적용됩니다. Dataflow에 Assured Workloads를 사용할 경우 파이프라인이 액세스하는 모든 리소스가 조직의 Assured Workloads 프로젝트 또는 폴더에 있어야 합니다. 이러한 리소스는 다음과 같습니다.
- Cloud Storage 버킷
- BigQuery 데이터 세트
- Pub/Sub 주제 및 구독
- Firestore 데이터 세트
- I/O 커넥터
Dataflow에서는 2024년 3월 7일 이후에 생성된 스트리밍 작업의 경우 모든 사용자 데이터가 CMEK로 암호화됩니다.
2024년 3월 7일 이전에 생성된 스트리밍 작업의 경우 윈도잉, 그룹화, 조인과 같은 키 기반 작업에 사용되는 데이터 키는 CMEK 암호화로 보호되지 않습니다. 작업에 이 암호화를 사용 설정하려면 작업을 드레이닝하거나 취소한 후 다시 시작합니다. 자세한 내용은 파이프라인 상태 아티팩트 암호화를 참조하세요.
파이프라인 간 데이터 공유
Dataflow에는 파이프라인 간에 데이터를 공유하거나 컨텍스트를 처리하기 위한 파이프라인 간 통신 메커니즘은 없습니다. Cloud Storage 같은 내구성 있는 스토리지나 App Engine 같은 메모리 내 캐시를 사용하여 파이프라인 인스턴스 간에 데이터를 공유할 수 있습니다.
작업 예약
다음과 같은 방법으로 파이프라인 실행을 자동화할 수 있습니다.
- Cloud Scheduler를 사용합니다.
- Cloud Composer 워크플로에서 여러 Google Cloud 연산자 중 하나인 Apache Airflow Dataflow 연산자를 사용합니다.
- Compute Engine에서 커스텀(크론) 작업 프로세스를 실행합니다.
파이프라인 코드 작성 권장사항
다음 섹션에서는 Apache Beam 코드를 작성하여 파이프라인을 만들 때 사용할 수 있는 권장사항을 제공합니다.
Apache Beam 코드 구조화
파이프라인을 만들려면 일반 ParDo 병렬 처리 Apache Beam 변환을 사용하는 것이 일반적입니다.
ParDo 변환을 적용하면 DoFn 객체 형식으로 코드를 제공합니다. DoFn은 분산 처리 함수를 정의하는 Apache Beam SDK 클래스입니다.
DoFn 코드를 작고 독립적인 항목으로 생각할 수 있습니다. 많은 인스턴스가 각 머신이 다른 머신에 대해 알지 못하는 상태에서 서로 다른 머신에서 실행 중일 수 있습니다. 따라서 DoFn 요소의 병렬 및 분산 특성에 이상적인 순수 함수를 만드는 것이 좋습니다.
순수 함수에는 다음과 같은 특성이 있습니다.
- 순수 함수는 숨겨진 상태나 외부 상태에 의존하지 않습니다.
- 관찰 가능한 부작용이 없습니다.
- 확정적입니다.
순수 함수 모델은 완전히 엄격하지는 않습니다. 코드가 Dataflow 서비스에서 보장되지 않는 항목에 의존하지 않으면 상태 정보나 외부 초기화 데이터가 DoFn 및 기타 함수 객체에 유효할 수 있습니다.
ParDo 변환을 구조화하고 DoFn 요소를 만들 때 다음 가이드라인을 고려하세요.
- 단 한 번 처리를 사용하는 경우 Dataflow 서비스는 입력
PCollection의 모든 요소가DoFn인스턴스에 의해 정확히 한 번만 처리되도록 보장합니다. - Dataflow 서비스는
DoFn이 호출되는 횟수를 보장하지 않습니다. - Dataflow 서비스는 분산된 요소가 그룹화되는 방식을 정확하게 보장하지 않습니다. 어떤 요소가 함께 처리되는지 보장하지 않습니다(있는 경우).
- Dataflow 서비스는 파이프라인을 통해 생성된
DoFn인스턴스의 정확한 수를 보장하지 않습니다. - Dataflow 서비스는 내결함성이 있으며 작업자에게 문제가 발생하면 코드를 여러 번 재시도할 수 있습니다.
- Dataflow 서비스에서 코드의 백업 사본을 만들 수 있습니다. 코드가 이름이 고유하지 않은 임시 파일을 사용하거나 만드는 경우와 같은 수동 부작용과 관련된 문제가 발생할 수 있습니다.
- Dataflow 서비스는
DoFn인스턴스별 요소 처리를 직렬화합니다. 코드에는 스레드 안전성이 엄격하게 요구되지 않지만, 여러DoFn인스턴스 사이에 공유되는 상태는 스레드 안전성을 가져야 합니다.
재사용 가능한 변환 라이브러리 만들기
Apache Beam 프로그래밍 모델을 사용하면 변환을 재사용할 수 있습니다. 공통 변환의 공유 라이브러리를 만들면 서로 다른 팀별로 재사용성, 테스트 가능성, 코드 소유권을 개선할 수 있습니다.
다음 두 가지 자바 코드 예시를 살펴보겠습니다. 이 두 코드 모두 결제 이벤트를 읽습니다. 두 파이프라인이 동일한 처리를 수행한다고 가정하면 나머지 처리 단계에서 공유 라이브러리를 통해 동일한 변환을 사용할 수 있습니다.
첫 번째 예시는 제한되지 않은 Pub/Sub 소스에서 가져온 것입니다.
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
두 번째 예시는 제한된 관계형 데이터베이스 소스에서 가져온 것입니다.
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
코드 재사용성 권장 사항을 구현하는 방법은 프로그래밍 언어 및 빌드 도구에 따라 다릅니다. 예를 들어 Maven을 사용하는 경우 변환 코드를 자체 모듈로 분리할 수 있습니다. 그러면 다음 코드 예시와 같이 다양한 파이프라인의 대규모 다중 모듈 프로젝트에 모듈을 하위 모듈로 포함할 수 있습니다.
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
자세한 내용은 다음 Apache Beam 문서 페이지를 참조하세요.
- Apache Beam 변환을 위한 사용자 코드 작성 요구사항
PTransform스타일 가이드: 재사용 가능한 새로운PTransform컬렉션 작성자를 위한 스타일 가이드
오류 처리에 데드 레터 큐 사용
파이프라인에서 요소를 처리할 수 없는 경우도 있습니다. 데이터 문제가 일반적인 원인입니다. 예를 들어 잘못된 형식의 JSON을 포함하는 요소로 인해 파싱 오류가 발생할 수 있습니다.
DoFn.ProcessElement 메서드 내에서 예외를 포착하고 오류를 로깅하고 요소를 삭제할 수 있지만 이 방법을 사용하면 데이터가 손실되고 나중에 수동 처리 또는 문제 해결을 위해 데이터를 검사할 수 없게 됩니다.
대신 데드 레터 큐(처리되지 않은 메시지 큐)라는 패턴을 사용하세요.
DoFn.ProcessElement 메서드의 예외를 포착하고 오류를 로깅합니다. 실패한 요소를 삭제하는 대신 브랜치 출력을 사용하여 실패한 요소를 별도의 PCollection 객체에 씁니다. 그런 다음 이러한 요소는 별도의 변환으로 나중에 검사하고 처리할 수 있도록 데이터 싱크에 작성될 수 있습니다.
다음 Java 코드 예시는 데드 레터 큐 패턴을 구현하는 방법을 보여줍니다.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Cloud Monitoring을 사용하여 파이프라인의 데드 레터 큐에 다른 모니터링 및 알림 정책을 적용하세요. 예를 들어 데드 레터 변환으로 처리되는 요소의 수와 크기를 시각화하고 특정 임곗값 조건이 충족되면 트리거되도록 구성할 수 있습니다.
스키마 변형 처리
실패한 요소를 별도의 PCollection 객체에 기록하는 데드 레터 패턴을 사용하여 유효하기는 하지만 예기치 않은 스키마가 있는 데이터를 처리할 수 있습니다.
경우에 따라 변형된 스키마를 유효한 요소로 반영하는 요소를 자동으로 처리해야 하는 경우도 있습니다. 예를 들어 요소의 스키마가 새 필드 추가와 같은 변형을 반영하는 경우 데이터 싱크의 스키마를 조정하여 변경을 수용할 수 있습니다.
자동 스키마 변경은 데드 레터 패턴에서 사용하는 분기 출력 방식을 사용합니다. 그러나 이 경우에는 추가적인 스키마가 발생할 때마다 대상 스키마를 변경하는 변환을 트리거합니다. 이 방식의 예시는 Google Cloud 블로그의 Square Enix를 사용하여 스트리밍 파이프라인에서 JSON 스키마 변경을 처리하는 방법을 참조하세요.
데이터 세트 조인 방법 결정
데이터 세트 조인은 데이터 파이프라인의 일반적인 사용 사례입니다. 부차 입력 또는 CoGroupByKey 변환을 사용하여 파이프라인에서 조인을 수행할 수 있습니다.
유형마다 장점과 단점이 있습니다.
부차 입력은 데이터 보강 및 키 입력 조회와 같은 일반적인 데이터 처리 문제를 유연하게 해결할 수 있는 방법을 제공합니다. PCollection 객체와 달리 부차 입력은 변경 가능하며 런타임에서 확인할 수 있습니다. 예를 들어 부차 입력의 값은 파이프라인의 다른 분기에서 계산하거나 원격 서비스를 호출하여 확인할 수 있습니다.
Dataflow는 데이터를 공유 디스크와 유사한 영구 스토리지로 유지하여 부차 입력을 지원합니다. 이 구성을 통해 모든 작업자가 완전한 부차 입력을 사용할 수 있습니다.
그러나 부차 입력 크기는 매우 커서 작업자 메모리에 맞지 않을 수 있습니다. 작업자가 영구 스토리지에서 지속적으로 읽기를 해야 하는 경우 큰 부차 입력에서 읽으면 성능 문제가 발생할 수 있습니다.
CoGroupByKey 변환은 공통 키가 있는 여러 PCollection 객체 및 그룹 요소를 병합(평면화)하는 핵심 Apache Beam 변환입니다. 각 작업자가 전체 부차 입력 데이터를 사용할 수 있게 하는 부차 입력과 달리 CoGroupByKey는 Shuffle(그룹화) 작업을 수행하여 작업자 간에 데이터를 분산합니다. 따라서 CoGroupByKey는 조인하려는 PCollection 객체가 매우 크고 작업자 메모리에 맞지 않는 경우에 적합합니다.
다음 안내에 따라 부차 입력 또는 CoGroupByKey 사용 여부를 결정하세요.
- 조인하는
PCollection객체 중 하나가 다른 객체보다 지나치게 작고, 작은PCollection객체가 작업자 메모리에 적합한 경우 부차 입력을 사용합니다. 부차 입력을 완전히 메모리에 캐시하면 요소를 빠르고 효율적으로 가져올 수 있습니다. - 파이프라인에 여러 번 조인해야 하는
PCollection객체가 있는 경우 부차 입력을 사용합니다. 여러CoGroupByKey변환을 사용하는 대신 여러ParDo변환에서 재사용할 수 있는 단일 부차 입력을 만듭니다. - 작업자 메모리를 크게 초과하는
PCollection객체의 상당 부분을 가져와야 하는 경우CoGroupByKey를 사용합니다.
자세한 내용은 Dataflow의 메모리 부족 오류 문제 해결을 참조하세요.
요소당 비용이 많이 드는 작업 최소화
DoFn 인스턴스는 0개 이상의 요소로 구성된 원자적 작업 단위인 번들이라는 요소 배치를 처리합니다. 그런 다음 모든 요소에 대해 실행되는
DoFn.ProcessElement
메서드에 의해 개별 요소가 처리됩니다. 모든 요소에 대해 DoFn.ProcessElement 메서드가 호출되므로, 해당 메서드에 의해 호출되는 시간이 많이 걸리거나 계산 비용이 많이 드는 작업은 그 메서드에 의해 처리되는 모든 요소에 대해 실행됩니다.
요소의 배치에 대해 딱 한 번 비용이 많이 드는 작업을 수행해야 하는 경우 DoFn.ProcessElement 요소 대신 DoFn.Setup 메서드 또는 DoFn.StartBundle 메서드에 이러한 작업을 포함합니다. 포함되는 작업의 예시는 다음과 같습니다.
DoFn인스턴스 동작의 일부를 제어하는 구성 파일을 파싱합니다.DoFn.Setup메서드를 사용하여DoFn인스턴스가 초기화되는 경우 이 작업을 한 번만 호출하세요.번들의 모든 요소를 단일 네트워크 연결을 통해 전송해야 하는 경우와 같이 번들의 모든 요소에서 재사용해야 하는 단기 클라이언트를 인스턴스화합니다.
DoFn.StartBundle메서드를 사용하여 번들당 한 번 이 작업을 호출합니다.
배치 크기 및 외부 서비스에 대한 동시 호출 제한
외부 서비스를 호출할 때 GroupIntoBatches 변환을 사용하여 호출당 오버헤드를 줄일 수 있습니다. 이 변환은 지정된 크기의 요소 배치를 만듭니다.
일괄 처리는 요소를 개별이 아닌 페이로드 하나로 외부 서비스로 보냅니다.
일괄 처리와 함께 적합한 키를 선택하여 수신 데이터를 파티션으로 나누는 방식으로 외부 서비스의 최대 병렬(동시) 호출 수를 제한할 수 있습니다. 파티션 수에 따라 최대 동시 로드가 결정됩니다. 예를 들어 모든 요소에 같은 키가 제공되는 경우 외부 서비스를 호출할 수 있는 다운스트림 변환은 동시에 실행되지 않습니다.
요소의 키를 생성하는 데 다음 방법 중 하나를 사용해 보세요.
- 사용자 ID와 같은 데이터 키로 사용할 데이터 세트의 속성을 선택합니다.
- 데이터 키를 생성하여 고정된 수의 파티션에 요소를 무작위로 분할합니다. 여기에서 가능한 키 값의 수가 파티션 수를 결정합니다. 동시에 로드할 수 있도록 충분한 파티션을 만들어야 합니다.
각 파티션에는
GroupIntoBatches변환을 위한 요소가 충분히 있어야 유용할 수 있습니다.
다음 Java 코드 예시는 10개의 파티션에 요소를 무작위로 분할하는 방법을 보여줍니다.
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
융합한 단계로 인한 성능 문제 파악
Dataflow는 파이프라인을 구성하는 데 사용한 변환 및 데이터를 기반으로 파이프라인을 나타내는 단계의 그래프를 빌드합니다. 이 그래프가 파이프라인 실행 그래프입니다.
파이프라인을 배포하면 Dataflow가 파이프라인의 실행 그래프를 수정하여 성능을 개선할 수 있습니다. 예를 들어 Dataflow는 파이프라인에서 모든 중간 PCollection 객체를 작성할 때의 성능과 비용 영향을 피하기 위해 일부 작업을 함께 융합하는데 이것을 융합 최적화라고 부릅니다.
경우에 따라 Dataflow는 파이프라인에서 작업을 융합하는 최적의 방법을 잘못 결정하여 사용 가능한 모든 작업자를 사용하는 사용자 작업의 기능이 제한될 수 있습니다. 이러한 경우 작업이 융합되지 않게 할 수 있습니다.
다음 예제 Apache Beam 코드를 살펴봅시다. GenerateSequence 변환은 작은 제한된 PCollection 객체를 생성하며, 이것은 두 개의 다운스트림 ParDo 변환에 의해 추가로 처리됩니다.
Find Primes Less-than-N 변환은 계산 비용이 많이 들고 큰 수의 경우에는 느리게 실행될 가능성이 있습니다. 반대로 Increment Number 변환은 빠르게 완료될 가능성이 높습니다.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
다음 다이어그램은 Dataflow 모니터링 인터페이스에서 파이프라인의 그래픽 표현을 보여줍니다.
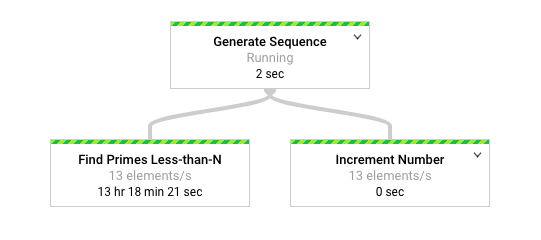
Dataflow 모니터링 인터페이스에서는 두 변환 모두에 동일하게 느린 처리 속도(특히 초당 13개 요소)가 발생함을 보여줍니다. Increment Number 변환은 요소를 빠르게 처리할 것으로 예상할 수 있지만 대신 Find Primes Less-than-N과 동일한 처리 속도에 연결되어 있는 것으로 보입니다.
Dataflow에서 단계들을 단일 단계로 융합한 바람에 독립적으로 실행되지 않기 때문입니다. gcloud dataflow jobs describe 명령어를 사용하여 자세한 정보를 확인할 수 있습니다.
gcloud dataflow jobs describe --full job-id --format json
결과 출력에서 융합된 단계는 ComponentTransform 배열의 ExecutionStageSummary 객체에 설명됩니다.
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
이 시나리오에서는 Find Primes Less-than-N 변환이 느린 단계이므로 해당 단계 이전에 융합을 중단하는 것이 적절한 전략입니다. 단계의 융합을 푸는 한 가지 방법은 다음 Java 코드 예시에 표시된 대로 이 단계 앞에 GroupByKey 변환을 삽입하여 그룹을 해제하는 것입니다.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
이러한 융합 해제 단계를 재사용 가능한 복합 변환에 결합할 수도 있습니다.
단계 융합을 해제한 후 파이프라인을 실행하면 Increment Number가 몇 초 만에 완료되며 더 오래 실행되는 Find Primes Less-than-N 변환은 별도의 단계에서 실행됩니다.
이 예시에서는 단계 융합을 해제하기 위한 그룹 및 그룹 해제 작업을 적용합니다.
다른 상황에서는 다른 방법을 사용할 수 있습니다. 이 경우 GenerateSequence 변환의 연속된 출력이 제공되면 중복 출력을 처리하는 것은 문제가 되지 않습니다.
중복 키가 있는 KV 객체는 그룹(GroupByKey) 변환 및 그룹 해제(Keys) 변환에서 하나의 키로 중복 삭제됩니다. 그룹 및 그룹 해제 작업 후 중복을 유지하려면 다음 단계를 수행하여 키-값 쌍을 만듭니다.
- 임의의 키와 원래 입력을 값으로 사용합니다.
- 임의의 키를 사용하여 그룹화합니다.
- 각 키의 값을 출력으로 내보냅니다.
Reshuffle 변환을 사용하여 주변 변환 융합을 방지할 수도 있습니다. 그러나 Reshuffle 변환의 부작용은 다양한 Apache Beam 실행기에 포팅할 수 없습니다.
동시 로드 및 융합 최적화에 대한 자세한 내용은 파이프라인 수명 주기를 참조하세요.
Apache Beam 측정항목을 사용하여 파이프라인 통계 수집
Apache Beam 측정항목은 실행 중인 파이프라인의 속성을 보고할 수 있는 측정항목을 생성하는 유틸리티 클래스입니다. Cloud Monitoring을 사용하면 Apache Beam 측정항목을 Cloud Monitoring 커스텀 측정항목으로 사용할 수 있습니다.
다음 예시에서는 DoFn 서브클래스에 사용되는 Apache Beam Counter 측정항목을 보여줍니다.
예시 코드에서는 두 개의 카운터를 사용합니다. 한 카운터는 JSON 파싱 오류(malformedCounter)를 추적하고 다른 카운터는 JSON 메시지가 유효하지만 빈 페이로드(emptyCounter)를 포함하는지 추적합니다. Cloud Monitoring에서 커스텀 측정항목 이름은 custom.googleapis.com/dataflow/malformedJson 및 custom.googleapis.com/dataflow/emptyPayload입니다. 커스텀 측정항목을 사용하여 Cloud Monitoring에서 시각화 및 알림 정책을 만들 수 있습니다.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
자세히 알아보기
다음 페이지에서는 파이프라인 구조화 방법, 데이터에 적용할 변환을 선택하는 방법, 파이프라인의 입력 및 출력 방식을 선택할 때 고려해야 할 사항을 자세히 설명합니다.
사용자 코드 빌드에 대한 자세한 내용은 사용자 제공 함수에 대한 요구사항을 참조하세요.