이 페이지에서는 Dataflow에서 메모리 부족(OOM) 오류를 찾고 해결하는 방법을 설명합니다.
메모리 부족 오류 찾기
파이프라인의 메모리가 부족한지 확인하려면 다음 방법 중 하나를 사용합니다.
- 작업 세부정보 페이지의 로그 창에서 진단 탭을 확인합니다. 이 탭에는 메모리 문제와 관련된 오류 및 오류 발생 빈도가 표시됩니다.
- Dataflow 모니터링 인터페이스에서 메모리 사용률 차트를 사용하여 작업자 메모리 용량 및 사용량을 모니터링합니다.
- 작업 세부정보 페이지의 로그 창에서 작업자 로그를 선택하여 작업자 로그에서 메모리 부족 오류를 확인합니다.
메모리 부족 오류가 시스템 로그에 표시될 수도 있습니다. 이를 보려면 로그 탐색기로 이동하여 다음 쿼리를 사용하세요.
resource.type="dataflow_step" resource.labels.job_id="JOB_ID" "out of memory" OR "OutOfMemory" OR "Shutting down JVM"JOB_ID를 작업 ID로 바꿉니다.
Java 작업의 경우 Java 메모리 모니터는 주기적으로 가비지 컬렉션 측정항목을 보고합니다. 가비지 컬렉션에 사용되는 CPU 시간 비율이 장시간 기준점 50%를 초과하면 SDK 하네스가 실패합니다. 다음 예시와 유사한 오류가 표시될 수 있습니다.
Shutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = ...이 오류는 물리적 메모리를 계속 사용할 수 있는 경우에도 발생할 수 있으며 일반적으로 파이프라인의 메모리 사용량이 비효율적임을 나타냅니다. 이 문제를 해결하려면 파이프라인을 최적화하세요.
Java 메모리 모니터는
MemoryMonitorOptions인터페이스로 구성됩니다.
작업의 메모리 사용량이 높거나 메모리 부족 오류가 발생하면 이 페이지의 권장사항을 따라 메모리 사용량을 최적화하거나 사용 가능한 메모리 양을 늘리세요.
메모리 부족 오류 해결
Dataflow 파이프라인을 변경하면 메모리 오류를 해결하거나 메모리 사용량을 줄일 수 있습니다. 가능한 변경 사항은 다음과 같습니다.
아래 다이어그램은 이 페이지에서 설명하는 Dataflow 문제 해결 워크플로를 보여줍니다.
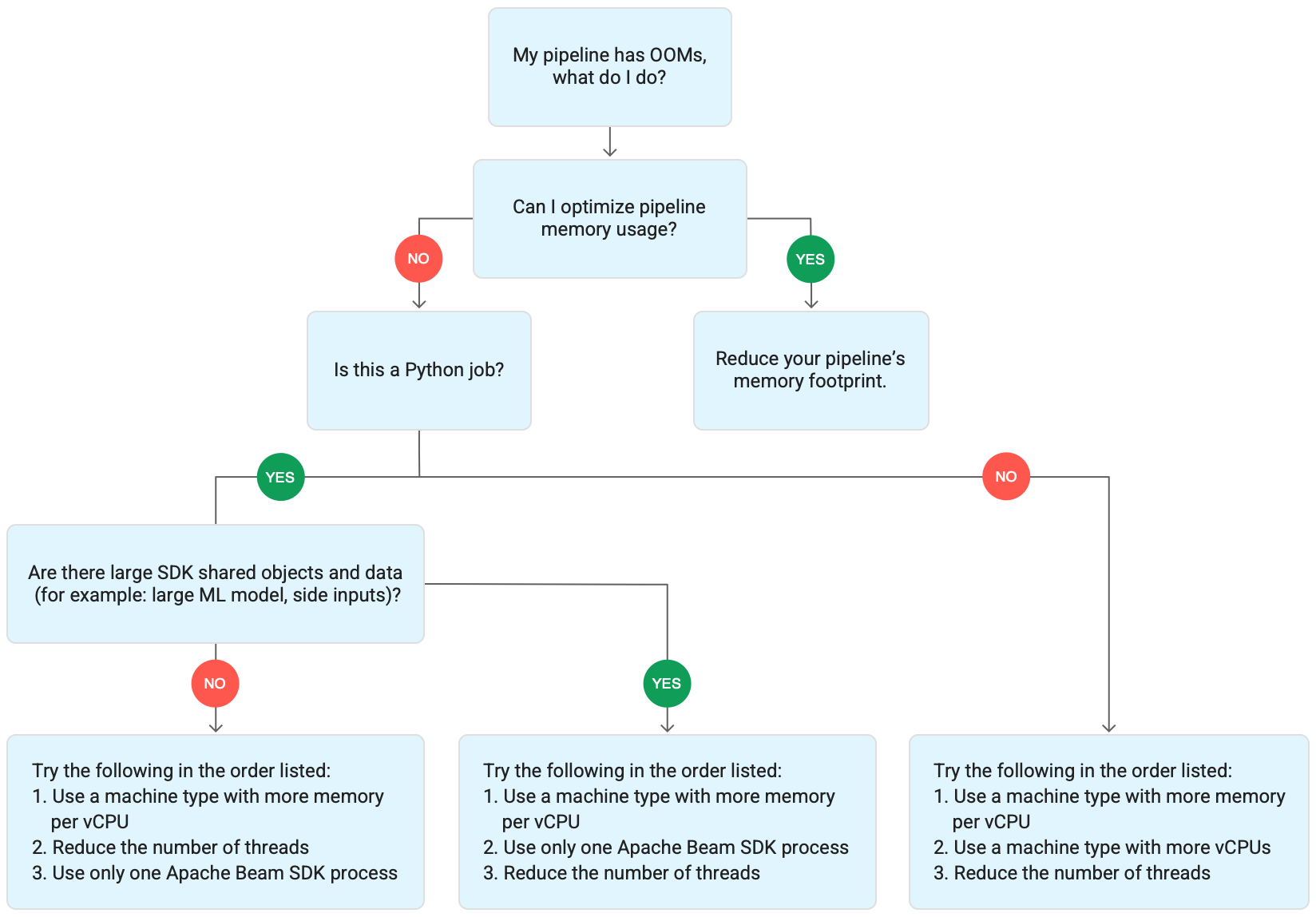
다음과 같은 완화 방법을 시도해 보세요.
- 가능하면 파이프라인을 최적화하여 메모리 사용량을 줄이세요.
- 작업이 일괄 작업인 경우 다음 단계를 나열된 순서대로 시도해 보세요.
- vCPU당 메모리가 더 많은 머신 유형을 사용합니다.
- 스레드 수를 작업자당 vCPU 수보다 적게 줄입니다.
- vCPU당 메모리가 더 많은 커스텀 머신 유형을 사용합니다.
- 작업이 Python을 사용하는 스트리밍 작업인 경우 스레드 수를 12 미만으로 줄입니다.
- 작업이 Java 또는 Go를 사용하는 스트리밍 작업인 경우 다음을 시도해 보세요.
- Runner v2 작업의 경우 스레드 수를 500개 미만으로 줄이거나 Runner v2를 사용하지 않는 작업의 경우 300개 미만으로 줄입니다.
- 메모리가 더 많은 머신 유형을 사용합니다.
파이프라인 최적화
여러 파이프라인 작업으로 인해 메모리 부족 오류가 발생할 수 있습니다. 이 섹션에서는 파이프라인의 메모리 사용량을 줄이는 옵션을 제공합니다. 가장 많은 메모리를 사용하는 파이프라인 단계를 식별하려면 Cloud Profiler를 사용하여 파이프라인 성능을 모니터링합니다.
다음 권장사항을 사용하여 파이프라인을 최적화할 수 있습니다.
- 파일 읽기에 Apache Beam 기본 제공 I/O 커넥터 사용
GroupByKeyPTransform을 사용할 때 작업 재설계- 외부 소스에서 인그레스 데이터 줄이기
- 스레드 간 객체 공유
- 메모리 효율적인 요소 표현 사용
- 부차 입력 크기 줄이기
- Apache Beam 분할 가능 DoFn 사용
파일 읽기에 Apache Beam 기본 제공 I/O 커넥터 사용
DoFn 안에 큰 파일을 열지 마세요. 파일을 읽으려면 Apache Beam의 기본 제공 I/O 커넥터를 사용합니다.
DoFn에서 열린 파일은 메모리에 들어가야 합니다. 여러 DoFn 인스턴스가 동시에 실행되므로 DoFn에서 열린 대용량 파일로 인해 메모리 부족 오류가 발생할 수 있습니다.
GroupByKey PTransform을 사용할 때 작업 재설계
Dataflow에서 GroupByKey PTransform을 사용하면 키 및 기간별 결과 값이 단일 스레드에서 처리됩니다. 이 데이터는 Dataflow 백엔드 서비스에서 작업자에게 스트림으로 전달되므로 작업자 메모리에 맞을 필요가 없습니다. 그러나 값이 메모리에 수집되면 처리 로직으로 인해 메모리 부족 오류가 발생할 수 있습니다.
예를 들어 윈도우 데이터가 포함된 키가 있고 목록과 같은 메모리 내 객체에 키 값을 추가하는 경우 메모리 부족 오류가 발생할 수 있습니다. 이 시나리오에서는 작업자에 모든 객체를 보관할 수 있는 충분한 메모리 용량이 없을 수 있습니다.
GroupByKey PTransform에 대한 자세한 내용은 Apache Beam Python GroupByKey 및 Java GroupByKey 문서를 참조하세요.
다음 목록에는 GroupByKey PTransform을 사용할 때 메모리 소비를 최소화하도록 파이프라인을 설계하기 위한 제안 사항이 포함되어 있습니다.
- 키 및 기간별로 데이터 양을 줄이려면 값이 여러 개인 키(핫키라고도 함)를 사용하지 마세요.
- 기간별로 수집되는 데이터의 양을 줄이려면 더 작은 기간을 사용합니다.
- 기간에서 키 값을 사용하여 숫자를 계산하는 경우
Combine변환을 사용합니다. 값을 수집한 후 단일DoFn인스턴스에서 계산하지 마세요. - 처리하기 전에 값 또는 중복을 필터링하세요. 자세한 내용은 Python
Filter및 JavaFilter변환 문서를 참조하세요.
외부 소스에서 인그레스 데이터 줄이기
데이터 보강을 위해 외부 API 또는 데이터베이스를 호출하는 경우 반환되는 데이터는 작업자 메모리에 들어가야 합니다.
호출을 일괄 처리하는 경우 GroupIntoBatches 변환을 사용하는 것이 좋습니다.
메모리 부족 오류가 발생하면 배치 크기를 줄입니다. 일괄 그룹화에 대한 자세한 내용은 Python GroupIntoBatches 및 Java GroupIntoBatches 변환 문서를 참조하세요.
스레드 간 객체 공유
DoFn 인스턴스 간에 인메모리 데이터 객체를 공유하면 공간 및 액세스 효율성이 향상될 수 있습니다. Setup, StartBundle, Process, FinishBundle, Teardown을 포함하여 DoFn의 모든 메서드에서 생성된 데이터 객체는 각 DoFn에 대해 호출됩니다. Dataflow에서 각 작업자에는 여러 DoFn 인스턴스가 있을 수 있습니다. 더 효율적인 메모리 사용량을 위해 데이터 객체를 싱글톤으로 전달하여 여러 DoFn에서 공유합니다. 자세한 내용은 DoFn에서 캐시 재사용 블로그 게시물을 참조하세요.
메모리 효율적인 요소 표현 사용
메모리를 더 적게 사용하는 PCollection 요소에 표현을 사용할 수 있는지 평가합니다. 파이프라인에서 Coder를 사용할 때는 인코딩 뿐만 아니라 디코딩된 PCollection 요소 표현도 고려해야 합니다. 희소 행렬은 이 유형의 최적화로 이점을 얻을 수 있습니다.
부차 입력 크기 줄이기
DoFn이 부차 입력을 사용하는 경우 부차 입력의 크기를 줄입니다. 요소 컬렉션인 부차 입력의 경우 AsList와 같이 전체 부차 입력을 동시에 구체화하는 뷰 대신 AsIterable 또는 AsMultimap과 같은 반복 가능한 뷰를 사용하는 것이 좋습니다.
스레드 수 줄이기
DoFn 인스턴스를 실행하는 최대 스레드 수를 줄여 스레드당 사용 가능한 메모리를 늘릴 수 있습니다. 이 변경으로 동시 로드가 줄어들지만 각 DoFn에 더 많은 메모리를 사용할 수 있습니다.
다음 표는 Dataflow에서 만드는 기본 스레드 수를 보여줍니다.
| 작업 유형 | Python SDK | Java/Go SDK |
|---|---|---|
| 일괄 | vCPU당 스레드 1개 | vCPU당 스레드 1개 |
| Runner v2로 스트리밍 | vCPU당 스레드 12개 | 작업자 VM당 스레드 500개 |
| Runner v2를 사용하지 않고 스트리밍 | vCPU당 스레드 12개 | 작업자 VM당 스레드 300개 |
Apache Beam SDK 스레드 수를 줄이려면 다음 파이프라인 옵션을 설정하세요.
자바
--numberOfWorkerHarnessThreads 파이프라인 옵션을 사용합니다.
Python
--number_of_worker_harness_threads 파이프라인 옵션을 사용합니다.
Go
--number_of_worker_harness_threads 파이프라인 옵션을 사용합니다.
일괄 작업의 경우 값을 vCPU 수보다 작은 수로 설정합니다.
스트리밍 작업의 경우 기본값의 절반으로 값을 줄이는 것부터 시작하세요. 이 단계로 문제가 완화되지 않으면 각 단계에서 결과를 관찰하면서 값을 계속 절반으로 줄입니다. 예를 들어 Python을 사용하는 경우 값 6, 3, 1을 사용해 보세요.
vCPU당 메모리가 더 많은 머신 유형 사용
vCPU당 메모리가 더 많은 작업자를 선택하려면 다음 방법 중 하나를 사용합니다.
- 범용 머신 계열에서 높은 메모리 머신 유형을 사용합니다. 높은 메모리 머신 유형은 표준 머신 유형보다 vCPU당 메모리가 높습니다. vCPU 수가 동일하게 유지되므로 높은 메모리 머신 유형을 사용하면 각 작업자에 사용 가능한 메모리와 스레드당 사용 가능한 메모리가 증가합니다. 따라서 높은 메모리 머신 유형을 사용하는 것이 vCPU당 메모리가 더 많은 작업자를 선택하는 비용 효율적인 방법이 될 수 있습니다.
- vCPU 수와 메모리 양을 지정할 때 유연성을 높이기 위해 커스텀 머신 유형을 사용할 수 있습니다. 커스텀 머신 유형을 사용하면 메모리를 256MB 단위로 늘릴 수 있습니다. 이러한 머신 유형은 표준 머신 유형과 다른 방식으로 가격이 책정됩니다.
- 일부 머신 계열에서는 확장 메모리 커스텀 머신 유형을 사용할 수 있습니다. 확장 메모리를 사용하면 vCPU당 메모리 비율이 높아지며, 비용이 더 높습니다.
작업자 유형을 설정하려면 다음 파이프라인 옵션을 사용하세요. 자세한 내용은 파이프라인 옵션 설정 및 파이프라인 옵션을 참조하세요.
자바
--workerMachineType 파이프라인 옵션을 사용합니다.
Python
--machine_type 파이프라인 옵션을 사용합니다.
Go
--worker_machine_type 파이프라인 옵션을 사용합니다.
Apache Beam SDK 프로세스 하나만 사용
Runner v2를 사용하는 Python 스트리밍 파이프라인과 Python 파이프라인의 경우 Dataflow가 작업자당 Apache Beam SDK 프로세스를 하나만 시작하도록 할 수 있습니다. 이 옵션을 시도하기 전에 먼저 다른 방법을 사용하여 문제를 해결해 보세요. 컨테이너화된 Python 프로세스 하나만 시작하도록 Dataflow 작업자 VM을 구성하려면 다음 파이프라인 옵션을 사용합니다.
--experiments=no_use_multiple_sdk_containers
이 구성을 사용하면 Python 파이프라인이 작업자당 하나의 Apache Beam SDK 프로세스를 만듭니다. 이 구성은 각 Apache Beam SDK 프로세스에 대해 공유 객체 및 데이터가 여러 번 복제되지 않도록 방지합니다. 하지만 작업자에서 사용할 수 있는 컴퓨팅 리소스의 효율적인 사용이 제한됩니다.
Apache Beam SDK 프로세스 수를 1개로 줄이더라도 작업자에서 시작된 총 스레드 수가 줄어들지 않을 수 있습니다. 또한 단일 Apache Beam SDK 프로세스에 모든 스레드가 있으면 처리 속도가 느리거나 파이프라인이 중단될 수 있습니다. 따라서 이 페이지의 스레드 수 줄이기 섹션에 설명된 대로 스레드 수를 줄여야 할 수도 있습니다.
vCPU가 한 개뿐인 머신 유형을 사용하여 작업자가 하나의 Apache Beam SDK 프로세스만 사용하도록 강제할 수도 있습니다.
Dataflow 메모리 사용량 이해하기
메모리 부족 오류를 해결하려면 Dataflow 파이프라인이 메모리를 사용하는 방법을 이해하는 것이 좋습니다.
Dataflow가 파이프라인을 실행할 때 작업자라고 하는 여러 Compute Engine 가상 머신(VM)에 처리가 분산됩니다.
작업자는 Dataflow 서비스에서 작업 항목을 처리하고 Apache Beam SDK 프로세스에 작업 항목을 위임합니다. Apache Beam SDK 프로세스는 DoFn의 인스턴스를 만듭니다. DoFn은 분산 처리 함수를 정의하는 Apache Beam SDK 클래스입니다.
Dataflow는 각 작업자에서 여러 스레드를 실행하고 각 작업자의 메모리가 모든 스레드에 공유됩니다. 스레드는 더 큰 프로세스 내에서 실행되는 단일 실행 가능 태스크입니다. 기본 스레드 수는 여러 요소에 따라 다르며 일괄 작업과 스트리밍 작업에 따라 달라집니다.
파이프라인에 작업자에서 사용할 수 있는 기본 메모리 양보다 많은 메모리가 필요한 경우 메모리 부족 오류가 발생할 수 있습니다.
Dataflow 파이프라인은 주로 3가지 방식으로 작업자 메모리를 사용합니다.
작업자 작업 메모리
Dataflow 작업자에는 운영체제 및 시스템 프로세스에 대한 메모리가 필요합니다. 작업자 메모리 사용량은 일반적으로 1GB 이하입니다. 사용량은 일반적으로 1GB 미만입니다.
- 작업자의 다양한 프로세스에서는 파이프라인이 정상적으로 작동하는지 확인하기 위해 메모리를 사용합니다. 이러한 각 프로세스는 작업에 소량의 메모리를 예약할 수 있습니다.
- 파이프라인에서 Streaming Engine을 사용하지 않는 경우 추가 작업자 프로세스는 메모리를 사용합니다.
SDK 프로세스 메모리
Apache Beam SDK 프로세스는 프로세스 내에서 스레드 간 공유되는 객체와 데이터를 만들 수 있습니다. 이 페이지에서는 이를 SDK 공유 객체 및 데이터라고 합니다. 이러한 SDK 공유 객체 및 데이터의 메모리 사용량을 SDK 프로세스 메모리라고 합니다. 다음 목록에는 SDK 공유 객체 및 데이터의 예시가 나와 있습니다.
- 부 입력
- 머신러닝 모델
- 인메모리 싱글톤 객체
apache_beam.utils.shared모듈로 생성된 Python 객체- Cloud Storage 또는 BigQuery와 같은 외부 소스에서 로드된 데이터
Streaming Engine을 사용하지 않는 스트리밍 작업은 부차 입력을 메모리에 저장합니다. Java 및 Go 파이프라인의 경우 각 작업자에는 부차 입력 복사본이 하나씩 있습니다. Python 파이프라인의 경우 각 Apache Beam SDK 프로세스에는 부차 입력의 복사본이 있습니다.
Streaming Engine을 사용하는 스트리밍 작업의 부차 입력 크기 제한은 80MB입니다. 부차 입력은 작업자 메모리 외부에 저장됩니다.
SDK 공유 객체 및 데이터의 메모리 사용량은 Apache Beam SDK 프로세스 수에 따라 선형적으로 증가합니다. Java 및 Go 파이프라인에서는 작업자당 하나의 Apache Beam SDK 프로세스가 시작됩니다. Python 파이프라인에서는 vCPU당 하나의 Apache Beam SDK 프로세스가 시작됩니다. SDK 공유 객체 및 데이터는 동일한 Apache Beam SDK 프로세스 내에서 여러 스레드 간에 재사용됩니다.
DoFn 메모리 사용량
DoFn은 분산 처리 함수를 정의하는 Apache Beam SDK 클래스입니다.
각 작업자는 동시 DoFn 인스턴스를 실행할 수 있습니다. 각 스레드는 DoFn 인스턴스 하나를 실행합니다. 총 메모리 사용량을 평가하거나, 작업 세트 크기를 계산하거나, 애플리케이션이 계속 작동하는 데 필요한 메모리 양을 계산하는 것이 유용할 수 있습니다. 예를 들어 개별 DoFn이 최대 5MB의 메모리를 사용하고 작업자가 300개의 스레드를 사용하는 경우 DoFn 메모리 사용량이 1.5GB 또는 메모리의 바이트 수에 스레드 수를 곱한 값만큼 최대치를 기록할 수 있습니다. 작업자가 메모리를 사용하는 방법에 따라 메모리 사용량이 급증하면 작업자의 메모리가 부족해질 수 있습니다.
DoFn Dataflow가 만드는 인스턴스 수를 추정하기 어렵습니다. 이러한 숫자는 SDK, 머신 유형 등의 여러 요소에 따라 달라집니다. 또한 DoFn은 여러 스레드에서 연속으로 사용할 수 있습니다.
Dataflow 서비스는 DoFn이 호출되는 횟수를 보장하지 않으며, 파이프라인을 통해 생성된 정확한 DoFn 인스턴스 수를 보장하지 않습니다.
그러나 다음 표에서는 예상되는 동시 로드 개수 수준에 대한 정보를 바탕으로 DoFn 인스턴스 수의 상한값을 추정할 수 있습니다.
Beam Python SDK
| 일괄 | Streaming Engine을 사용하지 않고 스트리밍 | 스트리밍 엔진 | |
|---|---|---|---|
| 동시 로드 |
vCPU당 프로세스 1개 프로세스당 스레드 1개 vCPU당 스레드 1개
|
vCPU당 프로세스 1개 프로세스당 스레드 12개 vCPU당 스레드 12개 |
vCPU당 프로세스 1개 프로세스당 스레드 12개 vCPU당 스레드 12개
|
최대 동시 DoFn 인스턴스 수(모든 값은 언제든지 변경될 수 있음) |
스레드당 DoFn 1개 vCPU당
|
스레드당 DoFn 1개 vCPU당
|
스레드당 DoFn 1개 vCPU당
|
Beam Java/Go SDK
| 일괄 | Runner v2가 없는 Streaming Appliance 및 Streaming Engine | Runner v2가 있는 Streaming Engine | |
|---|---|---|---|
| 동시 로드 |
작업자 VM당 프로세스 1개 vCPU당 스레드 1개
|
작업자 VM당 프로세스 1개 프로세스당 스레드 300개 작업자 VM당 스레드 300개
|
작업자 VM당 프로세스 1개 프로세스당 스레드 500개 작업자 VM당 스레드 500개
|
최대 동시 DoFn 인스턴스 수(모든 값은 언제든지 변경될 수 있음) |
스레드당 DoFn 1개 vCPU당
|
스레드당 DoFn 1개
작업자 VM당
|
스레드당 DoFn 1개
작업자 VM당
|
예를 들어 n1-standard-2 Dataflow 작업자와 함께 Python SDK를 사용하는 경우 다음이 적용됩니다.
- 일괄 작업: Dataflow는 vCPU당 하나의 프로세스(이 경우 2개)를 실행합니다. 각 프로세스는 하나의 스레드를 사용하고 각 스레드는 하나의
DoFn인스턴스를 만듭니다. - Streaming Engine을 사용한 스트리밍 작업: Dataflow는 vCPU당 하나의 프로세스(총 2개)를 시작합니다. 그러나 각 프로세스는 최대 12개의 스레드를 생성할 수 있으며, 각 스레드에는 자체 DoFn 인스턴스가 있습니다.
복잡한 파이프라인을 설계할 때는 DoFn 수명 주기를 이해하는 것이 중요합니다.
DoFn 함수가 직렬화 가능한지 확인하고, 함수 내에서 직접 요소 인수를 수정해서는 안 됩니다.
다국어 파이프라인이 있고 작업자에서 Apache Beam SDK가 2개 이상 실행 중인 경우 작업자는 가능한 한 가장 낮은 수준의 프로세스당 스레드 동시 로드를 사용합니다.
Java, Go, Python 차이점
Java, Go, Python은 프로세스와 메모리를 다르게 관리합니다. 따라서 메모리 부족 오류 문제를 해결할 때 취해야 하는 접근 방식은 파이프라인이 Java, Go 또는 Python을 사용하는지 여부에 따라 다릅니다.
Java 및 Go 파이프라인
Java 및 Go 파이프라인에서는 다음 사항이 적용됩니다.
- 각 작업자는 하나의 Apache Beam SDK 프로세스를 시작합니다.
- 부차 입력 및 캐시와 같은 SDK 공유 객체 및 데이터는 작업자의 모든 스레드에서 공유됩니다.
- 일반적으로 SDK 공유 객체와 데이터에서 사용하는 메모리는 작업자의 vCPU 수에 따라 확장되지 않습니다.
Python 파이프라인
Python 파이프라인에서는 다음 사항이 적용됩니다.
- 각 작업자는 vCPU당 하나의 Apache Beam SDK 프로세스를 시작합니다.
- 부차 입력 및 캐시와 같은 SDK 공유 객체 및 데이터는 각 Apache Beam SDK 프로세스 내의 모든 스레드에서 공유됩니다.
- 작업자의 총 스레드 수는 vCPU 수에 따라 선형적으로 확장됩니다. 따라서 SDK 공유 객체 및 데이터에서 사용되는 메모리는 vCPU 수에 따라 선형적으로 증가합니다.
- 작업을 수행하는 스레드가 프로세스 전체에 분산됩니다. 새 작업 단위는 작업 항목이 없는 프로세스 또는 현재 가장 적은 작업 항목이 할당된 프로세스에 할당됩니다.