En esta página, se muestra cómo activar un archivo compartido NFS como un volumen en Cloud Run. Puedes usar cualquier servidor NFS, incluido tu propio servidor NFS alojado de forma local o en una VM de Compute Engine. Si aún no tienes un servidor NFS, te recomendamos Filestore, que es una oferta de NFS completamente administrada de Google Cloud.
Si quieres usar sistemas de archivos de red NBD, 9P, CIFS/Samba y Ceph, consulta cómo usar los sistemas de archivos de red NBD, 9P, CIFS/Samba y Ceph.
Activar el archivo compartido NFS como un volumen en Cloud Run presenta el archivo compartido como archivos en el sistema de archivos del contenedor. Después de activar el uso compartido de archivos como un volumen, puedes acceder a él como si fuera un directorio en tu sistema de archivos local, mediante las operaciones y bibliotecas del sistema de archivos de tu lenguaje de programación.
Rutas no permitidas
Cloud Run no te permite activar un volumen en /dev,
/proc y /sys, ni en sus subdirectorios.
Limitaciones
Para escribir en un volumen NFS, el contenedor debe ejecutarse como raíz. Si el contenedor solo lee desde el sistema de archivos, puede ejecutarse como cualquier usuario.
Cloud Run no admite el bloqueo de NFS. Los volúmenes NFS se activan de forma automática en modo sin bloqueo.
Antes de comenzar
Para activar un servidor NFS como volumen en Cloud Run, asegúrate de tener lo siguiente:
- Una red de VPC en la que se ejecuta el servidor NFS o la instancia de Filestore.
- Un servidor NFS que se ejecuta en una red de VPC, con el servicio de Cloud Run conectado a esa red de VPC. Si aún no tienes un servidor NFS, crea uno mediante la creación de una instancia de Filestore.
- Tu servicio de Cloud Run está conectado a la red de VPC en la que se ejecuta tu servidor NFS. Para obtener el mejor rendimiento, usa VPC directa en lugar de conectores de VPC.
- Si usas un proyecto existente, asegúrate de que la configuración de firewall de VPC permita que Cloud Run acceda al servidor NFS. (Si comienzas desde un proyecto nuevo, esto es así de forma predeterminada). Si usas Filestore como tu servidor NFS, sigue la documentación de Filestore para crear una regla de salida de firewall a fin de permitir que Cloud Run llegue a Filestore.
Activa un volumen de NFS
Puedes activar varios servidores NFS, instancias de Filestore y otros tipos de volúmenes en diferentes rutas de activación.
Si usas varios contenedores, primero especifica los volúmenes y, luego, especifica las activaciones de volúmenes de cada contenedor.
Console
En la consola de Google Cloud ve a Cloud Run:
Haz clic en Implementar contenedor y selecciona Servicio para configurar un servicio nuevo. Si quieres configurar un servicio existente, haz clic en el servicio y, luego, en implementar y editar la nueva revisión.
Si configuras un servicio nuevo, completa la página de configuración del servicio inicial como desees y haz clic en Contenedores, volúmenes, Herramientas de redes y seguridad para expandir la página de configuración del servicio.
Haz clic en la pestaña Volúmenes.
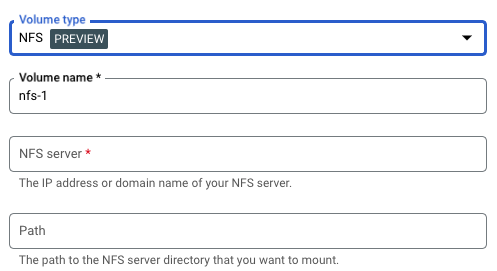
- En Volúmenes, haz lo siguiente:
- Haz clic en Agregar volumen.
- En el menú desplegable Tipo de volumen, selecciona NFS como el tipo de volumen.
- En el campo Nombre del volumen, ingresa el nombre que deseas usar para el volumen.
- En el campo Servidor NFS, ingresa el nombre o la ubicación de dominio (en el formato
IP_ADDRESS) del archivo compartido NFS. - En el campo Ruta de acceso, ingresa la ruta al directorio del servidor NFS que deseas activar.
- Haz clic en Listo.
- Haz clic en la pestaña Contenedor y, luego, expande el contenedor en el que activas el volumen para editar el contenedor.
- Haz clic en la pestaña Activaciones de volúmenes.
- Haz clic en Volumen de activación.
- Selecciona el volumen de NFS en el menú.
- Especifica la ruta en la que deseas activar el volumen.
- Haz clic en Volumen de activación.
- En Volúmenes, haz lo siguiente:
Haz clic en Crear o Implementar.
gcloud
Para agregar un volumen y activarlo, sigue estos pasos:
gcloud run services update SERVICE \ --add-volume=name=VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH \ --add-volume-mount=volume=VOLUME_NAME,mount-path=MOUNT_PATH
Reemplaza lo siguiente:
- SERVICE por el nombre de tu servicio
- VOLUME_NAME por el nombre que deseas darle al volumen.
- IP_ADDRESS por la ubicación del archivo NFS compartido.
- NFS_PATH con la ruta de acceso al archivo NFS compartido que comienza con una barra diagonal, por ejemplo,
/example-directory. - MOUNT_PATH por la ruta de acceso relativa en la que activarás el volumen, por ejemplo,
/mnt/my-volume. - VOLUME_NAME por el nombre que quieras para el volumen. El valor VOLUME_NAME se usa para asignar el volumen a la activación de volúmenes.
Para activar el volumen como un volumen de solo lectura, sigue estos pasos:
--add-volume=name=VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH,readonly=true
Si usas varios contenedores, primero especifica los volúmenes y, luego, especifica las activaciones de volúmenes de cada contenedor:
gcloud run services update SERVICE \ --add-volume=name VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH \ --container CONTAINER_1 \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH \ --container CONTAINER_2 \ --add-volume-mount volume= VOLUME_NAME,mount-path=MOUNT_PATH2
YAML
Si creas un servicio nuevo, omite este paso. Si actualizas un servicio existente, descarga su configuración de YAML:
gcloud run services describe SERVICE --format export > service.yaml
Actualiza MOUNT_PATH, VOLUME_NAME, IP_ADDRESS y NFS_PATHsegún sea necesario. Si tienes varias activaciones de volúmenes, tendrás varios de estos atributos.
apiVersion: run.googleapis.com/v1 kind: Service metadata: name: SERVICE spec: template: metadata: annotations: run.googleapis.com/execution-environment: gen2 spec: containers: - image: IMAGE_URL volumeMounts: - name: VOLUME_NAME mountPath: MOUNT_PATH volumes: - name: VOLUME_NAME nfs: server: IP_ADDRESS path: NFS_PATH readOnly: IS_READ_ONLY
Reemplazar
- SERVICE por el nombre del servicio de Cloud Run
- MOUNT_PATH por la ruta de acceso relativa en la que activarás el volumen, por ejemplo,
/mnt/my-volume. - VOLUME_NAME por el nombre que quieras para el volumen. El valor VOLUME_NAME se usa para asignar el volumen a la activación de volúmenes.
- IP_ADDRESS por la dirección del archivo NFS compartido.
- NFS_PATH: Es la ruta de acceso al archivo NFS compartido que comienza con una barra diagonal, por ejemplo,
/example-directory. - IS_READ_ONLY por
Truepara que el volumen sea de solo lectura oFalsepara permitir escrituras.
Crea o actualiza el servicio con el siguiente comando:
gcloud run services replace service.yaml
Leer y escribir en un volumen
Si usas la función de activación de volúmenes de Cloud Run, accedes a un volumen activado con las mismas bibliotecas en tu lenguaje de programación que usas para leer y escribir archivos en tu sistema de archivos local.
Esto es muy útil si usas un contenedor existente que espera que los datos se almacenen en el sistema de archivos local y usa operaciones regulares del sistema de archivos para acceder a él.
En los siguientes fragmentos, se supone una activación de volumen con una mountPath configurada como /mnt/my-volume.
Nodejs
Usa el módulo del sistema de archivos para crear un archivo nuevo o agregarlo a uno existente en el volumen, /mnt/my-volume:
var fs = require('fs');
fs.appendFileSync('/mnt/my-volume/sample-logfile.txt', 'Hello logs!', { flag: 'a+' });Python
Escribe en un archivo mantenido en el volumen, /mnt/my-volume:
f = open("/mnt/my-volume/sample-logfile.txt", "a")Go
Usa el paquete os para crear un archivo nuevo mantenido en el volumen, /mnt/my-volume
f, err := os.Create("/mnt/my-volume/sample-logfile.txt")Java
Usa la clase Java.io.File para crear un archivo de registro en el volumen, /mnt/my-volume:
import java.io.File;
File f = new File("/mnt/my-volume/sample-logfile.txt");Solución de problemas de NFS
Si tienes problemas, verifica lo siguiente:
- Tu servicio de Cloud Run está conectado a la red de VPC en la que está en el servidor NFS.
- No hay reglas de firewall que impidan que Cloud Run llegue al servidor NFS.
- Si el contenedor escribe en el servidor NFS, asegúrate de que se ejecute como raíz.
Tiempo de inicio del contenedor y activaciones de volúmenes de NFS
El uso de activaciones de volumen NFS puede aumentar ligeramente el tiempo de inicio en frío de tu contenedor de Cloud Run, ya que la activación de volumen se inicia antes de iniciar los contenedores. El contenedor se iniciará solo si NFS se activa correctamente.
Ten en cuenta que NFS activa un volumen correctamente solo después de establecer una conexión con el servidor y recuperar un identificador de archivo. Cualquier retraso en la red puede afectar el tiempo de inicio del contenedor. Si Cloud Run no puede establecer una conexión con el servidor, el servicio de Cloud Run no se iniciará. Además, si NFS tarda más de 30 segundos en activarse, el servicio de Cloud Run no se iniciará porque tiene un tiempo de espera total de 30 segundos para realizar todas las activaciones.
Características de rendimiento de NFS
Si creas más de un volumen NFS, todos se activarán en paralelo.
Debido a que NFS es un sistema de archivos de red, está sujeto a límites de ancho de banda, y el acceso al sistema de archivos puede verse afectado por un ancho de banda limitado.
Cuando escribes en tu volumen NFS, la operación se almacena en la memoria de Cloud Run hasta que se borran los datos. Los datos se borran en las siguientes circunstancias:
- Tu aplicación borra los datos de archivos de forma explícita con sync(2), msync(2) o fsync(3).
- Tu aplicación cierra un archivo con close(2).
- La presión de la memoria obliga a recuperar los recursos de memoria del sistema.
Para obtener más información, consulta la documentación de Linux sobre NFS.