Accelerate State of DevOps 2021
Che cosa separa i team software con le prestazioni più alte e più basse? Nel report del 2021, esaminiamo le pratiche che promuovono il successo della distribuzione del software e delle prestazioni operative, in modo da consentirti di confrontare la tua organizzazione con i team con prestazioni più elevate. Puoi quindi utilizzare le nostre scoperte per migliorare i risultati chiave, accelerare l'innovazione e distinguerti dalla massa.
Riepilogo esecutivo
Il report Accelerate State of DevOps di quest'anno del team DevOps Research and Assessment (DORA) di Google Cloud rappresenta sette anni di ricerche e dati da oltre 32.000 professionisti in tutto il mondo.
La nostra ricerca esamina le capacità e le pratiche che determinano le prestazioni di distribuzione del software, operative e organizzative. Avvalendoci di rigorose tecniche statistiche, cerchiamo di comprendere le pratiche che conducono all'eccellenza nella distribuzione di tecnologia e a potenti risultati aziendali. A questo scopo presentiamo insight basati sui dati e relativi ai modi più efficaci ed efficienti per sviluppare e distribuire tecnologia.
La nostra ricerca continua a mostrare che l'eccellenza nelle prestazioni di distribuzione del software e operative determina le prestazioni dell'organizzazione nelle trasformazioni della tecnologia. Per consentire ai team di confrontarsi con il settore, usiamo una cluster analysis per formare categorie di prestazioni significative, suddividendole in basse, medie, alte o elite. Dopo che i tuoi team si saranno fatti un'idea delle loro prestazioni attuali rispetto al settore, potrai usare i risultati della nostra analisi predittiva per applicarli a pratiche e capacità al fine di migliorare i risultati chiave e, in definitiva, il tuo posizionamento relativo. Quest'anno sottolineiamo l'importanza di centrare gli obiettivi di affidabilità, integrare la sicurezza nell'intera catena di fornitura del software, creare documentazione interna di qualità e sfruttare al massimo il potenziale offerto dal cloud. Esaminiamo anche la possibilità che una cultura del team positiva sia in grado di mitigare gli effetti del lavoro da remoto in conseguenza della pandemia di COVID-19.
Per apportare miglioramenti significativi, i team devono adottare una filosofia di miglioramento continuo. Usa i benchmark per misurare lo stato attuale, identificare i vincoli in base alle capacità esaminate dalla ricerca e sperimentare miglioramenti per alleviare i vincoli identificati. La sperimentazione porterà a una combinazione di vittorie e sconfitte, ma in entrambi gli scenari i team potranno adottare azioni significative in conseguenza delle lezioni apprese.
Risultati principali
Le organizzazioni con le prestazioni più alte stanno crescendo e continuano a innalzare il livello di riferimento.
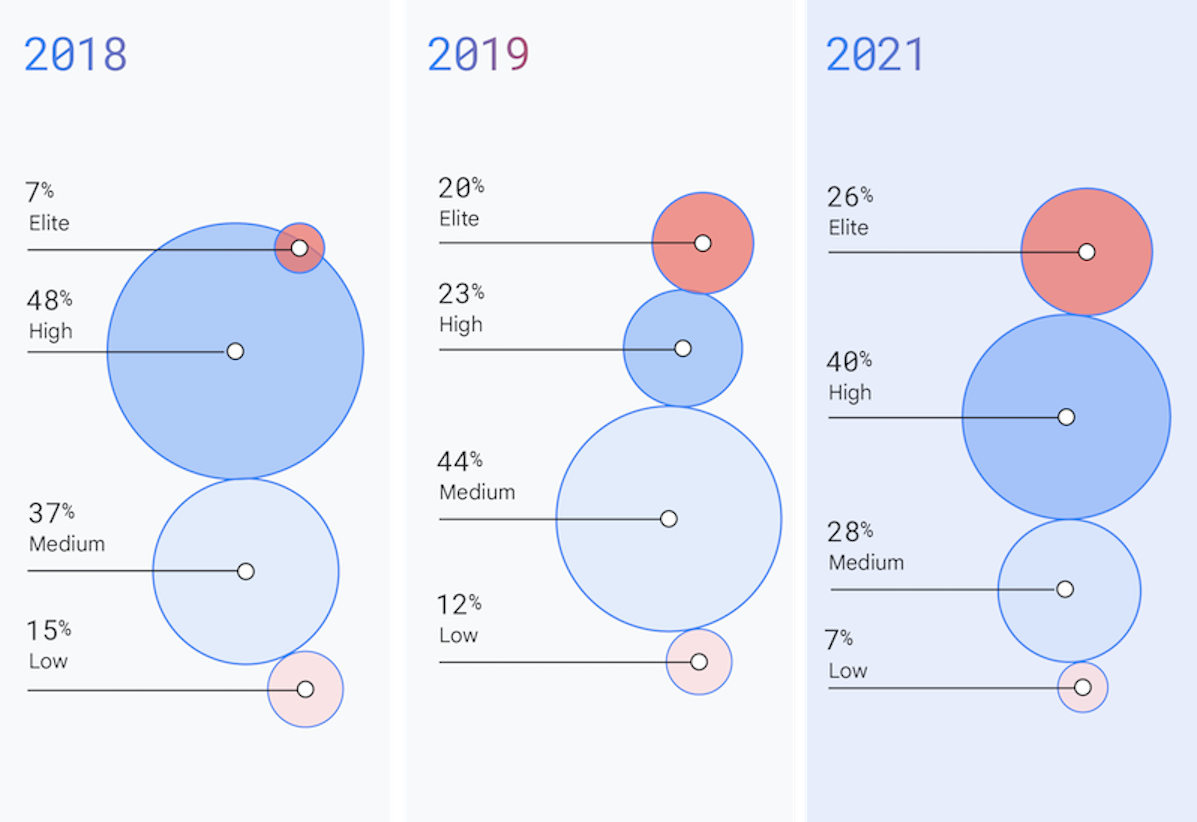
Le organizzazioni con prestazioni elite rappresentano ora il 26% dei team nel nostro studio e hanno ridotto i tempi di risposta per le modifiche alla produzione. Il settore continua ad accelerare e i team vedono in questo vantaggi significativi.
SRE e DevOps sono filosofie complementari.
I team che sfruttano le pratiche operative moderne illustrate dai nostri amici di Site Reliability Engineering (SRE) dichiarano prestazioni operative superiori. I team che danno priorità all'eccellenza sia operativa che nella distribuzione dichiarano le massime prestazioni dell'organizzazione.
Sempre più team stanno sfruttando il cloud e vedono i suoi significativi vantaggi.
I team continuano a trasferire i carichi di lavoro nel cloud e, tra loro, quanti sfruttano tutte e cinque le capacità del cloud vedono un aumento nelle prestazioni, sia di distribuzione del software e operative (SDO, Software Delivery and Operational), sia dell'organizzazione. Analogamente, l'adozione del multi-cloud è in aumento e consente ai team di sfruttare le capacità uniche di ciascun provider.
Una catena di fornitura del software sicura è fondamentale e migliora le prestazioni.
Dato il significativo aumento degli attacchi dannosi negli ultimi anni, le organizzazioni devono passare da pratiche reattive a misure proattive e diagnostiche. I team che integrano le pratiche di sicurezza nell'intera catena di fornitura ottengono una distribuzione del software rapida, affidabile e sicura.
Una buona documentazione è la base per il successo nell'implementazione delle capacità DevOps.
Per la prima volta, abbiamo misurato la qualità della documentazione interna e delle pratiche che contribuiscono a determinarla. I team con una documentazione di alta qualità sono maggiormente in grado di implementare le pratiche tecniche e hanno prestazioni complessivamente migliori.
Una cultura del team positiva mitiga il burnout in circostanze difficili.
La cultura del team fa una grande differenza nella sua capacità di fornire il software e raggiungere o superare gli obiettivi dell'organizzazione. I team inclusivi con una cultura generativa1,2 hanno sperimentato meno burnout durante la pandemia di COVID-19.
____________________________
1. Nella tipologia delle culture dell'organizzazione di Westrum, una cultura del team generativa si riferisce a team altamente cooperativi, che abbattono le barriere, prendono i fallimenti come spunto per l'indagine e condividono il rischio del processo decisionale.
2. Westrum, R. (2004). "A typology of organizational cultures." BMJ Quality & Safety, 13(suppl 2), ii22-ii27.
Come ci collochiamo?
Vuoi sapere dove si colloca il tuo team rispetto ad altri nel settore? Questa sezione include la più recente valutazione benchmark delle prestazioni DevOps.
Esaminiamo in che modo i team sviluppano, distribuiscono ed eseguono i sistemi software e suddividiamo quindi gli intervistati in quattro cluster di prestazioni: elite, alte, medie e basse. Confrontando le prestazioni del tuo team con quelle di ogni cluster potrai sapere dove ti collochi nel contesto dei risultati presentati in questo report.
Prestazioni di distribuzione del software e operative
Per soddisfare le esigenze di un settore in costante cambiamento, le organizzazioni devono distribuire ed eseguire il software in modo rapido e affidabile. Maggiore è la velocità con cui i tuoi team possono apportare modifiche al tuo software, minore sarà il tempo necessario a fornire valore ai tuoi clienti, eseguire esperimenti e ricevere feedback preziosi. Con sette anni di raccolta di dati e ricerca alle spalle, abbiamo sviluppato e convalidato quattro metriche che misurano le prestazioni di distribuzione del software. A partire dal 2018, abbiamo incluso una quinta metrica volta ad acquisire le capacità operative.
I team che eccellono in tutte e cinque le misure mostrano prestazioni dell'organizzazione eccezionali. Chiamiamo queste cinque misure prestazioni di distribuzione del software e operative (SDO, Software Delivery and Operational). Ricorda che queste metriche si concentrano sui risultati a livello di sistema, il che aiuta a evitare i comuni trabocchetti delle metriche per il software, come mettere le funzioni in competizione tra loro e realizzare ottimizzazioni locali a scapito dei risultati complessivi.
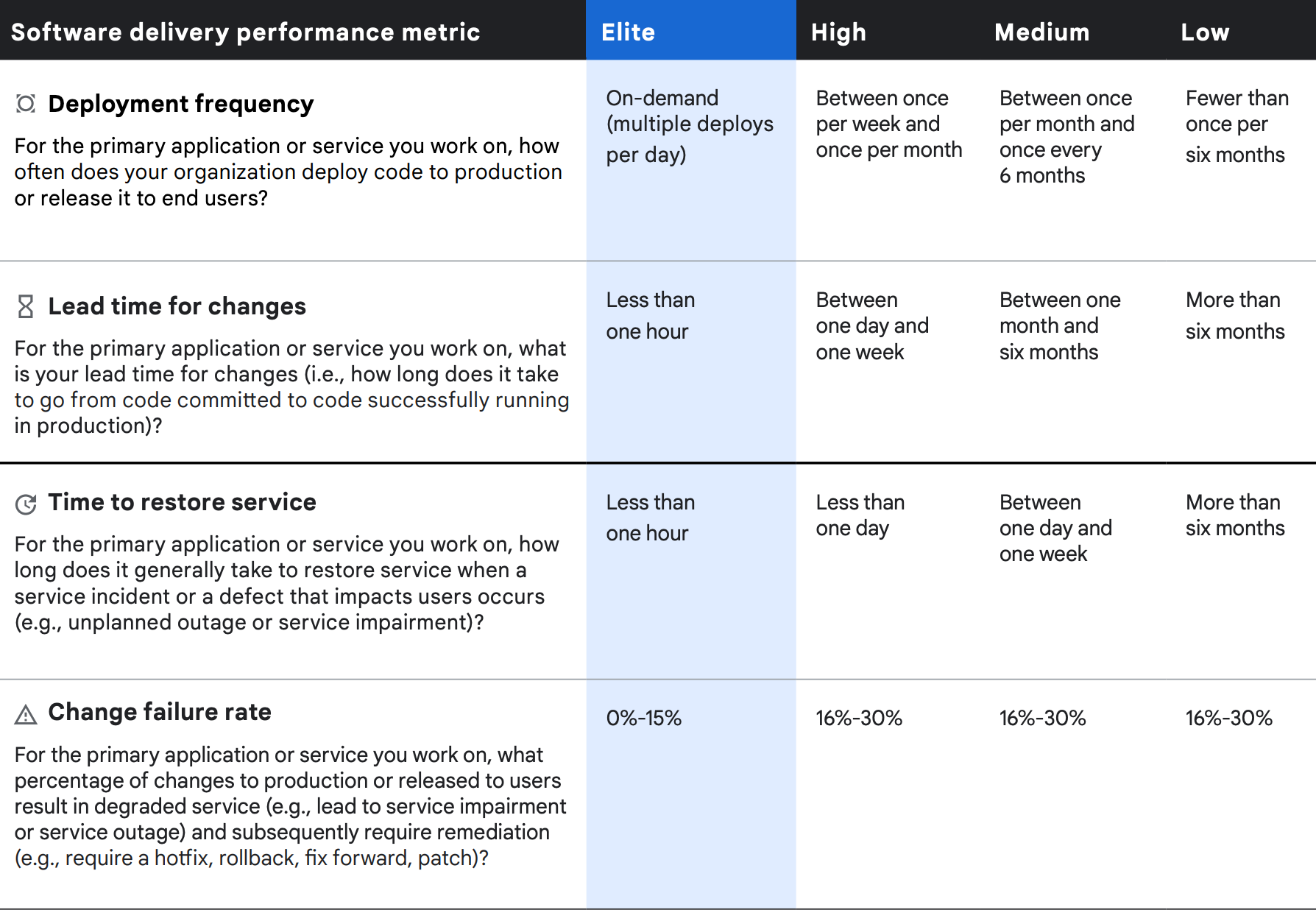
Quattro metriche delle prestazioni di distribuzione
Le quattro metriche delle prestazioni di distribuzione del software possono essere considerate in termini di velocità effettiva e stabilità. Misuriamo la velocità effettiva utilizzando il tempo di risposta delle modifiche al codice (ovvero il tempo dal commit del codice al rilascio in produzione) e la frequenza di deployment. Misuriamo la stabilità utilizzando il tempo per ripristinare un servizio dopo un incidente e il tasso di errore delle modifiche.
Anche in questo caso, la cluster analysis delle quattro metriche di distribuzione del software rivela quattro distinti profili di prestazioni, elite, alte, medie e basse, con differenze statisticamente significative nelle misure di velocità effettiva e stabilità. Come negli anni precedenti, le organizzazioni con le prestazioni più alte hanno risultati significativamente migliori per tutte e quattro le misure, mentre quelle con le prestazioni più basse sono significativamente peggiori in tutte le aree.
La quinta metrica: dalla disponibilità all'affidabilità
La quinta metrica rappresenta le prestazioni operative ed è una misura delle pratiche operative moderne. La metrica principale per le prestazioni operative è l'affidabilità, ovvero la misura in cui un team è in grado di mantenere le promesse e le affermazioni sul software di cui è responsabile. In passato, abbiamo misurato la disponibilità più che l'affidabilità; tuttavia, poiché la disponibilità è un obiettivo specifico di SRE; abbiamo esteso la nostra misura all'affidabilità in modo da offrire una rappresentazione più ampia di disponibilità, latenza, prestazioni e scalabilità. Nello specifico, abbiamo chiesto agli intervistati di valutare la loro capacità di raggiungere o superare gli obiettivi di affidabilità. Abbiamo rilevato che team con livelli di prestazioni di distribuzione diversi ottengono risultati migliori quando assegnano priorità anche alle prestazioni operative.
Come nei report precedenti, abbiamo confrontato le organizzazioni con prestazioni elite e basse per illustrare l'impatto delle capacità specifiche. Tuttavia, quest'anno abbiamo voluto prendere in considerazione l'impatto delle prestazioni operative. In tutte le categorie di prestazioni di distribuzione, da basse a elite, abbiamo visto che i team hanno ottenuto grandi benefici per una varietà di risultati assegnando priorità al raggiungimento o al superamento degli obiettivi di affidabilità.
Il settore continua ad accelerare
Ogni anno continuiamo a vedere come il settore si evolve e accelera la capacità di distribuire software in modo più rapido e con una maggiore stabilità. Per la prima volta, le organizzazioni con prestazioni alte o elite costituiscono i due terzi degli intervistati. Inoltre, le organizzazioni con prestazioni elite di quest'anno hanno di nuovo alzato il livello di riferimento, riducendo il tempo di risposta per le modifiche rispetto alle valutazioni precedenti (ad esempio, migliorando da meno di un giorno nel 2019 a meno di un'ora nel 2021). Inoltre, sempre per la prima volta, le organizzazioni con prestazioni elite hanno ridotto al minimo il tasso di errore delle modifiche rispetto agli anni precedenti, quando le categorie di prestazioni medie e alte erano state in grado di fare altrettanto.
Velocità effettiva e stabilità
Velocità effettiva
Frequenza di deployment
In linea con gli anni precedenti, il gruppo elite ha dichiarato di eseguire deployment on demand di routine, più volte al giorno. Per confronto, le organizzazioni con prestazioni basse hanno dichiarato di eseguire meno di un deployment ogni sei mesi (meno di due all'anno), il che segna di nuovo una riduzione delle prestazioni rispetto al 2019. Il numero di deployment annuali normalizzato va da 1.460 all'anno (calcolati come quattro deployment al giorno x 365 giorni) per le organizzazioni con le massime prestazioni a 1,5 deployment all'anno per quelle con le prestazioni più basse (media tra due deployment e un deployment). Questa analisi evidenzia come, approssimativamente, le organizzazioni con prestazioni elite eseguono il deployment del codice con una frequenza 973 volte maggiore rispetto a quelle con prestazioni basse.
Tempo di risposta per le modifiche
Con un miglioramento rispetto al 2019, le organizzazioni con prestazioni elite dichiarano tempi di risposta per le modifiche inferiori a un'ora, misurando questi tempi come l'intervallo che va dal commit del codice al suo corretto deployment in produzione. Si tratta di un aumento delle prestazioni rispetto al 2019, quando i nostri intervistati con le prestazioni più alte dichiaravano tempi di risposta inferiori a un giorno. A differenza delle organizzazioni con prestazioni elite, quelle con prestazioni basse richiedevano tempi di risposta superiori a sei mesi. Con tempi di risposta di un'ora per le organizzazioni con prestazioni elite (una stima conservativa orientata verso i valori più alti di "meno di un'ora") e di 6570 ore per le organizzazioni con prestazioni basse (calcolate assumendo la media di 8760 ore in un anno e 4380 ore in sei mesi), il gruppo elite ha tempi di risposta per le modifiche 6570 volte più rapidi rispetto al gruppo con prestazioni basse.
Stabilità
Tempo per ripristinare il servizio
Il gruppo elite ha dichiarato un tempo per ripristinare il servizio inferiore a un'ora, mentre il gruppo con prestazioni basse ha dichiarato più di sei mesi. Per questo calcolo abbiamo scelto intervalli di tempo conservativi: un'ora per le organizzazioni con prestazioni elite e la media di ore in un anno (8760) e in sei mesi (4380) per le organizzazioni con prestazioni basse. In base a questi numeri, le organizzazioni elite hanno un tempo per ripristinare il servizio 6570 volte più rapido rispetto a quelle con prestazioni basse. Le prestazioni del tempo per ripristinare il servizio sono rimaste invariate per il gruppo elite e sono aumentate per il gruppo con prestazioni basse rispetto al 2019.
Tasso di errore delle modifiche
Le organizzazioni con prestazioni elite hanno dichiarato un tasso di errore delle modifiche dello 0%–15%, mentre quelle con prestazioni basse hanno dichiarato un tasso del 16%–30%. La media tra questi due intervalli mostra un tasso di errore delle modifiche del 7,5% per il gruppo elite e del 23% per il gruppo con prestazioni basse. I tassi di errore delle modifiche del gruppo elite sono tre volte migliori rispetto a quelli del gruppo con prestazioni basse. Quest'anno, i tassi di errore delle modifiche sono rimasti invariati per il gruppo elite e sono migliorati per il gruppo con prestazioni basse rispetto al 2019, ma peggiorati per i gruppi intermedi.
Livello di prestazioni elite
Confrontando il gruppo elite con quello con prestazioni basse, troviamo che le organizzazioni con prestazioni elite hanno:
- Deployment del codice 973 volte più frequenti
- Tempi di risposta dal commit al deployment 6570 volte più rapidi
- Tasso di errore delle modifiche 3 volte inferiore (le modifiche hanno una probabilità di non riuscire inferiore di 1/3)
- Tempi di ripristino dagli incidenti 6570 volte più rapidi
Come migliorare?
Come migliorare le prestazioni SDO e dell'organizzazione? La nostra ricerca fornisce una guida basata su evidenze fattuali per aiutarti a concentrare gli sforzi sulle capacità che migliorano le prestazioni.
Il report di quest'anno ha esaminato l'impatto di cloud, pratiche SRE, sicurezza, pratiche tecniche e cultura. Nel corso di questa sezione introdurremo ognuna di queste capacità e ne evidenzieremo l'impatto su una varietà di risultati. Per chi ha dimestichezza con i modelli di ricerca State of DevOps di DORA, abbiamo creato una risorsa online che ospita il modello di quest'anno e tutti modelli precedenti.3
____________________________
3. https://devops-research.com/models.htm
____________________________
Cloud
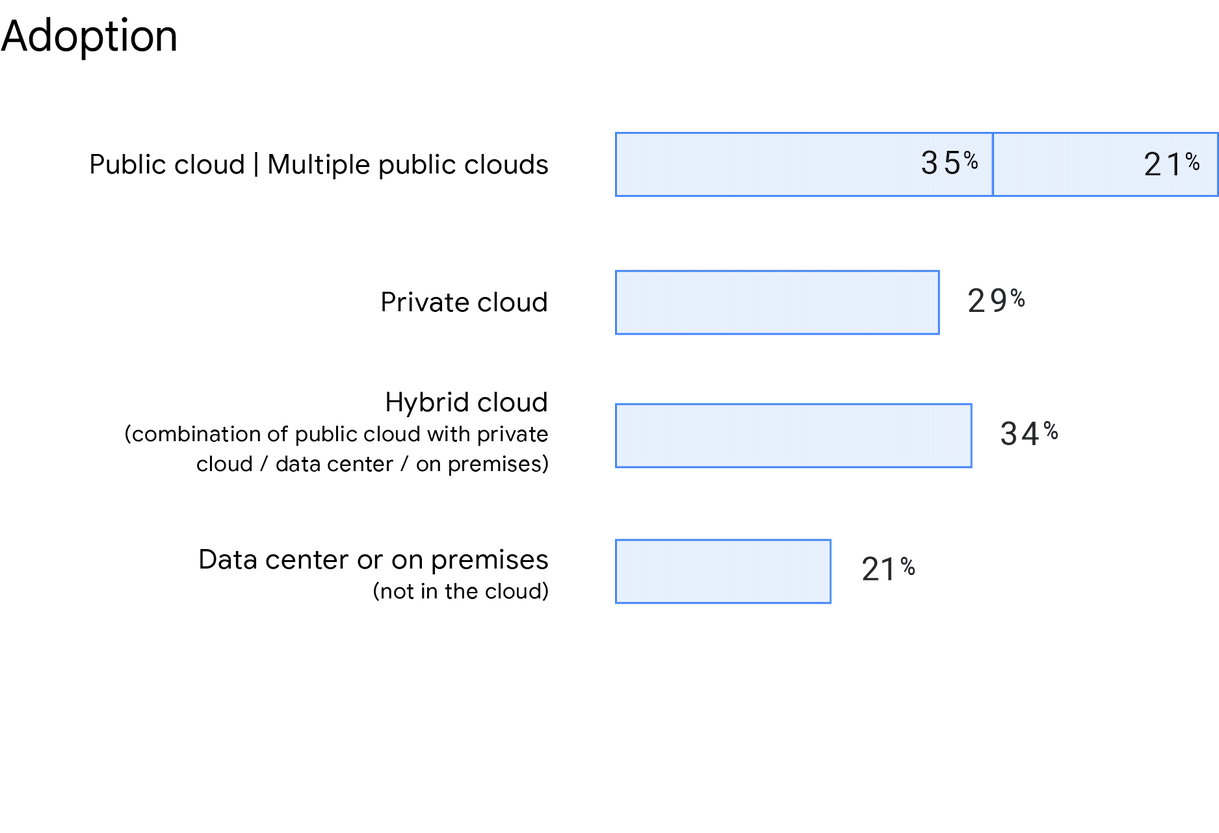
Confermando quanto evidenziato in Accelerate State of DevOps 2019, un numero crescente di organizzazioni sta scegliendo soluzioni cloud ibrido e multi-cloud. Nel nostro sondaggio, agli intervistati è stato chiesto dove fossero ospitati il loro servizio o la loro applicazione principali e abbiamo riscontrato un crescente utilizzo del cloud pubblico. Il 56% degli intervistati ha dichiarato di usare un cloud pubblico (e anche più cloud pubblici), con un aumento del 5% rispetto al 2019. Quest'anno abbiamo anche chiesto informazioni specifiche sull'uso del multi-cloud e il 21% degli intervistati ha dichiarato di eseguire il deployment in più cloud pubblici. Il 21% degli intervistati ha indicato di non utilizzare il cloud ma piuttosto un data center o una soluzione on-premise. Infine, il 34% degli intervistati ha dichiarato di utilizzare un cloud ibrido e il 29% un cloud privato.
Accelerare i risultati aziendali con cloud ibrido e multi-cloud
Quest'anno vediamo una crescita nell'uso del cloud ibrido e del multi-cloud, con un impatto significativo sui risultati che stanno a cuore alle aziende. Gli intervistati che usano il cloud ibrido o multi-cloud hanno dimostrato una probabilità 1,6 volte maggiore di superare gli obiettivi di prestazioni dell'organizzazione rispetto agli altri. Abbiamo anche visto dei notevoli effetti sulle prestazioni SDO, per cui gli utenti del cloud ibrido e multi-cloud hanno una probabilità 1,4 volte maggiore di eccellere in termini di frequenza di deployment, tempo di risposta per le modifiche, tempo per il ripristino, tasso di errore delle modifiche e affidabilità.
Perché il multi-cloud?
Analogamente alla nostra valutazione del 2018, abbiamo chiesto agli intervistati di esporre le loro motivazioni per l'utilizzo di più cloud provider pubblici. Anziché selezionare tutte le risposte pertinenti, quest'anno abbiamo chiesto agli intervistati di indicare il principale motivo per l'uso di più provider. Oltre un quarto (il 26%) degli intervistati ha addotto come motivo la possibilità di sfruttare i vantaggi unici offerti da ciascun cloud provider. Questo suggerisce che, quando gli intervistati selezionano un provider aggiuntivo, ne cercano uno che si differenzi dal provider attuale e offra alternative. Il secondo motivo più comune per il passaggio al multi-cloud è la disponibilità (22%). Non desta sorpresa il fatto che gli intervistati che hanno adottato più cloud provider abbiano mostrato una probabilità 1,5 volte maggiore di raggiungere o superare gli obiettivi di affidabilità.
Motivo principale per l'uso di più provider
Sfruttare i vantaggi unici di ciascun provider | 26% |
Disponibilità | 22% |
Ripristino di emergenza | 17% |
Aspetti legali e conformità | 13% |
Altro | 08% |
Tattica di negoziazione o requisito di approvvigionamento | 08% |
Mancanza di fiducia in un unico provider | 06% |
Sfruttare i vantaggi unici di ciascun provider
26%
Disponibilità
22%
Ripristino di emergenza
17%
Aspetti legali e conformità
13%
Altro
08%
Tattica di negoziazione o requisito di approvvigionamento
08%
Mancanza di fiducia in un unico provider
06%
Modifiche ai benchmark
L'implementazione dell'infrastruttura cloud è importante
Come in passato, vediamo che non tutti gli intervistati adottano il cloud nello stesso modo. Questo porta a una variabilità nell'efficacia dell'adozione del cloud nel favorire il conseguimento dei risultati aziendali. Abbiamo affrontato questa limitazione concentrandoci sulle caratteristiche essenziali del cloud computing, secondo la definizione del National Institute of Standards and Technology (NIST) e utilizzandole come guida. Basandoci sulla definizione di cloud computing del NIST, abbiamo esaminato l'impatto di pratiche essenziali sulle prestazioni SDO, anziché limitarci a esaminare soltanto l'impatto dell'adozione del cloud sulla distribuzione del software e l'operatività.
Per la terza volta abbiamo riscontrato che l'aspetto fondamentale è il modo in cui i team implementano i servizi cloud, non il semplice utilizzo di tecnologie cloud. Le organizzazioni con prestazioni elite hanno una probabilità 3,5 volte maggiore di aver soddisfatto tutte le caratteristiche essenziali del cloud definite dal NIST. Solo il 32% degli intervistati che avevano dichiarato di utilizzare l'infrastruttura cloud si è detto d'accordo o fortemente d'accordo con l'affermazione di soddisfare tutte e cinque le caratteristiche essenziali del cloud computing definite dal NIST, con un aumento del 3% rispetto al 2019. Nel complesso, l'uso delle caratteristiche del cloud computing definite dal NIST è aumentato del 14–19%, con l'aumento maggiore registrato nell'elasticità rapida.
Self-service on demand
I consumatori possono eseguire il provisioning di risorse di computing secondo necessità, automaticamente, senza che questo richieda alcuna interazione umana da parte del provider.
Il 73% degli intervistati ha utilizzato il self-service on demand, con un aumento del 16% rispetto al 2019.
Ampio accesso alla rete
Le capacità sono ampiamente disponibili e accessibili tramite client multipli, come telefoni cellulari, tablet, laptop e workstation.
Il 74% degli intervistati ha sfruttato l'ampio accesso alla rete, con un aumento del 14% rispetto al 2019.
Pooling di risorse
Le risorse del provider sono riunite in pool in un modello multi-tenant e le risorse fisiche e virtuali vengono assegnate e riassegnate dinamicamente on demand. In genere il cliente non ha un controllo diretto sulla località esatta delle risorse fornite, ma può specificarla a un livello di astrazione superiore, come paese, stato o data center.
Il 73% degli intervistati ha utilizzato il pooling di risorse, con un aumento del 15% rispetto al 2019.
Elasticità rapida
L'elasticità nel provisioning e nel rilascio delle risorse consente di fare rapidamente lo scale in o lo scale out in base alla domanda. Le capacità che il consumatore ha a disposizione per il provisioning appaiono illimitate e possono essere richieste in ogni quantità, in qualunque momento.
Il 77% degli intervistati ha utilizzato l'elasticità rapida, con un aumento del 18% rispetto al 2019.
Misurazione del servizio
I sistemi cloud controllano e ottimizzano automaticamente l'uso delle risorse sfruttando una capacità di misurazione a un livello di astrazione adeguato al tipo di servizio, come spazio di archiviazione, elaborazione, larghezza di banda e account utente attivi. L'uso delle risorse può essere monitorato, controllato e inserito in report per scopi di trasparenza.
Il 78% degli intervistati ha utilizzato la misurazione del servizio, con un aumento del 16% rispetto al 2019.
SRE e DevOps
Mentre la community DevOps stava emergendo in conferenze e conversazioni pubbliche, all'interno di Google: Site Reliability Engineering (SRE) si andava formando un movimento con una filosofia analoga. SRE e approcci simili, come la disciplina Production Engineering di Facebook, condividono molti degli obiettivi e delle tecniche che hanno spinto alla nascita di DevOps. Nel 2016, SRE si è affacciata sulla scena pubblica con la pubblicazione del primo libro4 dedicato alla Site Reliability Engineering. Il movimento da allora è cresciuto e conta oggi una community globale di professionisti SRE che collaborano alla definizione di pratiche per le operazioni tecniche.
Forse è inevitabile che sia sorta una certa confusione. Qual è la differenza tra SRE e DevOps? Devo scegliere tra le due? Quale è meglio? In realtà, non ci sono conflitti: SRE e DevOps sono altamente complementari e la nostra ricerca ne dimostra l'allineamento. SRE è una disciplina di apprendimento che assegna priorità alla comunicazione interfunzionale e alla sicurezza psicologica, gli stessi valori alla base della cultura generativa orientata alle prestazioni tipica dei team DevOps di livello elite. Partendo da questi principi fondanti, SRE offre tecniche pratiche, tra cui il framework di metriche per indicatori del livello del servizio/obiettivi del livello di servizio (SLI/SLO). Proprio come il framework Lean per i prodotti specifica come ottenere i cicli rapidi di feedback dei clienti supportati dalla nostra ricerca, il framework SRE offre la definizione di pratiche e strumentazioni in grado di migliorare la capacità di un team di mantenere in modo coerente le promesse fatte ai suoi utenti.
Nel 2021, abbiamo ampliato la nostra indagine sulle operazioni, espandendola dall'analisi della disponibilità del servizio alla categoria più generale dell'affidabilità. Il sondaggio di quest'anno ha introdotto diversi elementi ispirati dalle pratiche SRE, per valutare la misura in cui i team:
- Definiscono l'affidabilità in termini di comportamento rivolto verso l'utente
- Adottano il framework di metriche SLI/SLO per assegnare priorità al lavoro in base ai budget di errore
- Usano l'automazione per ridurre il lavoro manuale e gli avvisi che rallentano l'attività
- Definiscono protocolli e svolgono esercitazioni di preparazione a rispondere agli incidenti
- Integrano i principi di affidabilità nell'intero ciclo di vita di distribuzione del software (considerando l'affidabilità fin dalle prime fasi)
Nell'analisi dei risultati, abbiamo trovato riscontro del fatto che i team che eccellono in queste moderne pratiche operative hanno una probabilità 1,4 volte maggiore di dichiarare prestazioni SDO superiori e 1,8 volte maggiore di dichiarare migliori risultati aziendali.
Le pratiche SRE sono state adottate dalla maggioranza dei team nel nostro studio: il il 52% degli intervistati ha dichiarato di utilizzare queste pratiche in qualche misura, anche se la profondità con cui sono adottate varia sostanzialmente tra i team. I dati indicano che l'uso di questi metodi determina una maggiore affidabilità e prestazioni SDO complessivamente migliori: SRE favorisce il successo di DevOps.
Inoltre, abbiamo riscontrato che un modello di operatività basato sulla responsabilità condivisa, che si riflette nella misura in cui sviluppatori e operatori sono entrambi messi in condizione di contribuire all'affidabilità, è anch'esso un fattore che determina risultati migliori in termini di affidabilità.
Oltre a migliorare le misure oggettive delle prestazioni, SRE migliora anche l'esperienza di lavoro dei professionisti in ambito tecnico. Tipicamente, una persona sottoposta a un carico di attività operative pesante tenderà a sperimentare il burnout, ma SRE ha un effetto positivo. Abbiamo riscontrato che maggiore è l'uso di pratiche SRE in un team, minore è la probabilità di raggiungere il burnout dei suoi membri. SRE può inoltre aiutare a ottimizzare le risorse: i team che raggiungono gli obiettivi di affidabilità mediante l'applicazione di pratiche SRE dichiarano di dedicare più tempo a scrivere codice rispetto a quelli che non adottano SRE.
La nostra ricerca rivela che i team a qualsiasi livello di prestazioni SDO, da basse a elite, possono tutti ottenere vantaggi da un aumento dell'uso di pratiche SRE. Più sono buone le sue prestazioni, maggiore è la probabilità che un team adotti modalità operative moderne: il livello di prestazioni elite ha una probabilità 2,1 volte maggiore di dichiarare l'uso di pratiche SRE rispetto alle controparti con prestazioni basse. Anche i team che operano ai massimi livelli hanno comunque un margine di crescita: solo il 10% degli intervistati del gruppo elite ha dichiarato che i propri team hanno implementato completamente ogni pratica SRE che abbiamo esaminato. Man mano che le prestazioni SDO continuano ad avanzare nei vari settori, l'approccio di ogni team alle operazioni è un fattore critico per il miglioramento continuo di DevOps.
____________________________
4. Betsy Beyer et al., eds., Site Reliability Engineering (O'Reilly Media, 2016).
____________________________
Documentazione e sicurezza
Documentazione
Quest'anno abbiamo esaminato la qualità della documentazione interna, ovvero la documentazione (manuali, file README e anche commenti nel codice) per i servizi e le applicazioni su cui lavora il team. Abbiamo misurato la qualità della documentazione in base al grado in cui questa:
- Aiuta i lettori a raggiungere i propri obiettivi
- È accurata, aggiornata ed esauriente
- È ricercabile, ben organizzata e chiara5
La registrazione e l'accesso alle informazioni sui sistemi interni è un aspetto critico del lavoro tecnico di un team. Abbiamo rilevato che circa il 25% degli intervistati ha una documentazione di buona qualità e che l'impatto del lavoro di documentazione è chiaro: i team con una qualità della documentazione superiore hanno una probabilità 2,4 volte maggiore di raggiungere prestazioni di distribuzione del software e operative (SDO) migliori. I team con una buona documentazione distribuiscono il software in modo più rapido e affidabile rispetto a quelli con una documentazione carente. Non c'è bisogno di una documentazione perfetta. La nostra ricerca mostra che qualsiasi miglioramento della qualità della documentazione ha un impatto positivo e diretto sulle prestazioni.
L'ambiente tecnico odierno è caratterizzato da sistemi sempre più complessi, oltre che da esperti e ruoli specializzati per i diversi aspetti di questi sistemi. Dalla sicurezza ai test, la documentazione è un mezzo chiave per condividere conoscenze specialistiche e orientamenti sia tra questi sottogruppi specializzati all'interno di un team, sia con il team in senso più ampio.
Abbiamo riscontrato che la qualità della documentazione è un fattore che determina il successo dei team nell'implementazione delle pratiche tecniche. Queste a loro volta determinano il miglioramento delle capacità tecniche del sistema, tra cui osservabilità, test continuo e automazione del deployment. Abbiamo rilevato che i team con una documentazione di qualità hanno una probabilità:
- 3,8 volte maggiore di implementare pratiche di sicurezza
- 2,4 volte maggiore di raggiungere o superare gli obiettivi di affidabilità
- 3,5 volte maggiore di implementare le pratiche di Site Reliability Engineering (SRE)
- 2,5 volte maggiore di sfruttare appieno i vantaggi del cloud
Come migliorare la qualità della documentazione
Il lavoro tecnico comporta il reperimento e l'utilizzo di informazioni, ma una documentazione di qualità dipende dalle persone che scrivono e gestiscono i contenuti. Nel 2019, la nostra ricerca ha rilevato che l'accesso a fonti di informazioni interne ed esterne supporta la produttività. La ricerca di quest'anno porta questa indagine a un livello ulteriore ed esamina la qualità della documentazione accessibile e le pratiche che hanno un impatto su questa qualità.
La nostra ricerca mostra che le seguenti pratiche hanno un impatto positivo significativo sulla qualità della documentazione:
Documentare casi d'uso critici per prodotti e servizi. Gli aspetti di un sistema che vengono documentati sono importanti e i casi d'uso consentono ai lettori di applicare le informazioni e far funzionare i sistemi.
Creare linee guida chiare per l'aggiornamento e la modifica della documentazione esistente. Molto del lavoro di documentazione è gestire i contenuti esistenti. Quando i membri del team sanno come eseguire aggiornamenti o rimuovere informazioni imprecise od obsolete, il team può continuare a mantenere la qualità della documentazione man mano che il sistema cambia nel tempo.
Definire i proprietari. I team con una documentazione di qualità hanno maggiore probabilità di aver definito chiaramente la proprietà della documentazione. L'attribuzione della proprietà consente di stabilire responsabilità esplicite per la scrittura di nuovi contenuti e l'aggiornamento o la verifica delle modifiche ai contenuti esistenti. I team con una documentazione di qualità hanno maggiore probabilità di dichiarare di scrivere la documentazione per tutte le principali funzionalità delle applicazioni su cui lavorano e questa ampia copertura è favorita dalla definizione di una proprietà chiara.
Includere la documentazione nel processo di sviluppo del software. I team che hanno creato la documentazione e l'hanno aggiornata con le modifiche al sistema hanno una documentazione di qualità superiore. Come i test, la creazione e la gestione della documentazione è parte integrante di un processo di sviluppo del software con prestazioni elevate.
Riconoscere il lavoro di documentazione durante le revisioni delle prestazioni e le promozioni. Il riconoscimento è correlato alla qualità complessiva della documentazione. La scrittura e la gestione della documentazione è parte integrante del lavoro di progettazione del software e trattarla come tale ne migliora la qualità.
Tra le altre risorse che sono risultate un supporto a una documentazione di qualità:
- Formazione su come scrivere e gestire la documentazione
- Test automatici per esempi di codice o documentazione incompleta
- Linee guida, come guide di stile per la documentazione e guide alla scrittura per un pubblico globale
La documentazione è la base per il successo nell'implementazione delle capacità DevOps. Una documentazione di qualità superiore amplifica i risultati degli investimenti nelle singole capacità DevOps come sicurezza, affidabilità e sfruttamento di tutti i vantaggi del cloud. L'implementazione di pratiche a supporto di una documentazione di qualità si ripaga grazie al rafforzamento delle capacità tecniche e al miglioramento delle prestazioni SDO.
____________________________
5. Metriche di qualità determinate dalla ricerca esistente sulla documentazione tecnica, tra cui:
- Aghajani, E. et al. (2019). Software Documentation Issues Unveiled. Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering, 1199-1210. https://doi.org/10.1109/ICSE.2019.00122
- Plösch, R., Dautovic, A., & Saft, M. (2014). The Value of Software Documentation Quality. Proceedings of the International Conference on Quality Software, 333-342. https://doi.org/10.1109/QSIC.2014.22
- Zhi, J. et al. (2015). Cost benefits and quality of software development documentation: A systematic mapping. Journal of Systems and Software, 99(C), 175-198. https://doi.org/10.1016/j.jss.2014.09.042
____________________________
Sicurezza
[Anticipare] e integrare nell'intero ciclo
Oltre ai team tecnologici, la costante accelerazione ed evoluzione caratterizza anche la quantità e la complessità delle minacce per la sicurezza. Nel 2020, sono stati compromessi oltre 22 miliardi di record di informazioni personali riservate o dati aziendali, secondo il 2020 Threat Landscape Retrospective Report di Tenable.6 La sicurezza non può essere un'aggiunta successiva o il passaggio finale prima della distribuzione, deve essere integrata nell'intero processo di sviluppo del software.
Per una distribuzione sicura del software, le pratiche di sicurezza devono evolvere a una velocità maggiore rispetto alle tecniche adottate dagli utenti malintenzionati. Durante gli attacchi alla catena di fornitura software di SolarWinds e Codecov del 2020, gli hacker hanno compromesso il sistema di build di SolarWinds e lo script di caricamento bash di Codecov7 per introdursi di nascosto nell'infrastruttura di migliaia di clienti di queste aziende. Dato l'impatto diffuso di questi attacchi, il settore deve passare da un approccio preventivo a uno diagnostico, in cui i team software devono presupporre che i loro sistemi siano già compromessi e creare la sicurezza all'interno della propria catena di fornitura.
In linea con i report precedenti, abbiamo riscontrato l'eccellenza del gruppo elite nell'implementazione delle pratiche di sicurezza. Quest'anno, le organizzazioni con prestazioni di livello elite che hanno raggiunto o superato gli obiettivi di affidabilità avevano una probabilità doppia di aver integrato la sicurezza nel processo di sviluppo del software. Questo suggerisce che i team che hanno accelerato la distribuzione mantenendo gli standard di affidabilità hanno trovato un modo di integrare i controlli e le pratiche di sicurezza senza compromettere la velocità o l'affidabilità della loro distribuzione del software.
Oltre a mostrare prestazioni di distribuzione e operative elevate, i team che integrano le pratiche di sicurezza nell'intero processo di sviluppo hanno una probabilità 1,6 volte maggiore di raggiungere o superare gli obiettivi dell'organizzazione. I team di sviluppo che integrano la sicurezza portano un significativo valore alla propria azienda.
____________________________
6. https://www.tenable.com/cyber-exposure/2020-threat-landscape-retrospective
7. https://www.cybersecuritydive.com/news/codecov-breach-solarwinds-software-supply-chain/598950/
____________________________
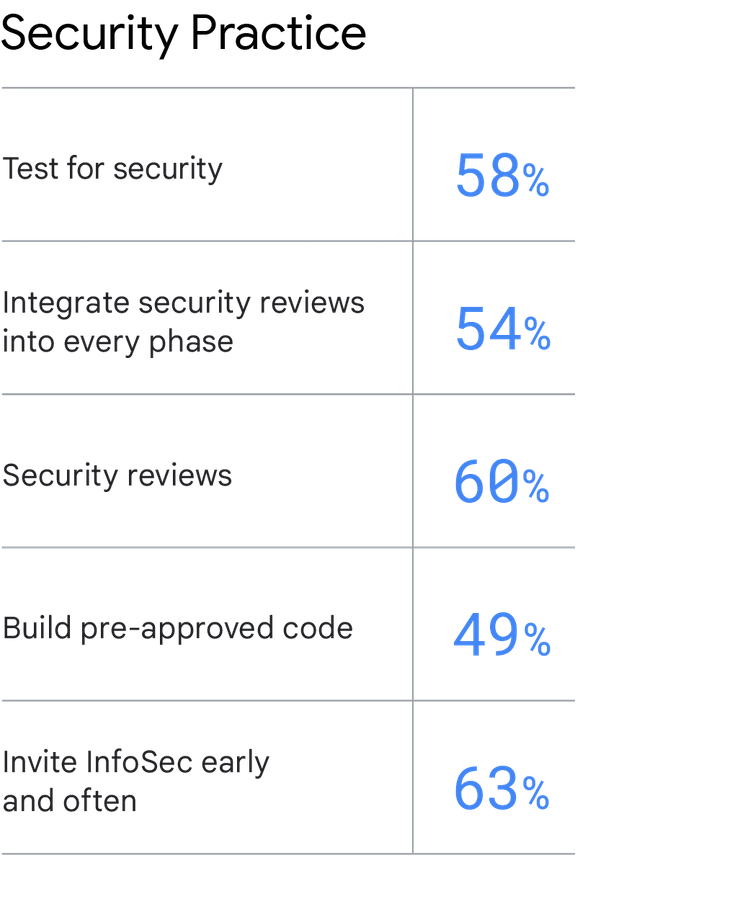
Come fare la cosa giusta
È facile sottolineare l'importanza della sicurezza e suggerire ai team di considerarla prioritaria, ma per farlo sono richiesti diversi cambiamenti rispetto ai metodi tradizionali di sicurezza delle informazioni. Puoi integrare la sicurezza, migliorare le prestazioni di distribuzione del software, operative e dell'organizzazione adottando le pratiche seguenti:
Testare la sicurezza. Testa i requisiti di sicurezza nell'ambito del processo di test automatizzato, comprese aree in cui è previsto l'uso di codice preapprovato.
Integrare le revisioni della sicurezza in ogni fase. Integra l'Information Security (InfoSec) nel lavoro di ogni giorno dell'intero ciclo di vita di distribuzione del software. In questo rientrano gli input del team InfoSec durante le fasi di progettazione e architettura dell'applicazione, la partecipazione a demo del software e l'offerta di feedback durante le demo.
Svolgere revisioni della sicurezza. Svolgere una revisione della sicurezza per tutte le funzionalità principali. Creare codice preapprovato. Fai creare al team InfoSec librerie, pacchetti, toolchain e processi preapprovati e facili da consumare, che sviluppatori e operatori IT utilizzeranno nel loro lavoro. Invitare InfoSec presto e spesso. Includi InfoSec nella pianificazione e in tutte le fasi successive dello sviluppo delle applicazioni, per consentire di individuare le debolezze legate alla sicurezza tempestivamente, dando tempo più che sufficiente per correggerle.
Creare codice preapprovato. Fai creare al team InfoSec librerie, pacchetti, toolchain e processi preapprovati e facili da consumare, che sviluppatori e operatori IT utilizzeranno nel loro lavoro.
Invitare InfoSec presto e spesso. Includi InfoSec nella pianificazione e in tutte le fasi successive dello sviluppo delle applicazioni, per consentire di individuare le debolezze legate alla sicurezza tempestivamente, dando tempo più che sufficiente per correggerle.
Come abbiamo notato in precedenza, una documentazione di alta qualità contribuisce al successo di varie capacità e la sicurezza non fa eccezione. Abbiamo rilevato che i team con una documentazione di alta qualità hanno una probabilità 3,8 volte maggiore di integrare la sicurezza nell'intero processo di sviluppo. Non tutti in un'organizzazione sono esperti di crittografia. Il modo migliore per condividere l'esperienza di quanti lo sono all'interno di un'organizzazione è la stesura di pratiche di sicurezza documentate.
Capacità tecniche DevOps
La nostra ricerca mostra che le organizzazioni che eseguono una trasformazione DevOps adottando la distribuzione continua hanno una maggiore probabilità di avere processi con qualità elevata, rischio ridotto e costi ottimizzati.
Nello specifico, abbiamo misurato le seguenti pratiche tecniche:
- Architettura a basso accoppiamento
- Sviluppo basato su trunk
- Test continui
- Integrazione continua
- Uso di tecnologie open source
- Pratiche di monitoraggio e osservabilità
- Gestione delle modifiche al database
- Automazione del deployment
Abbiamo riscontrato come, per quanto tutte queste pratiche contribuiscano a migliorare la distribuzione continua, l'architettura a basso accoppiamento e i test continui sono quelle con l'impatto maggiore. Ad esempio, quest'anno abbiamo rilevato che le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità tre volte maggiore di impiegare un'architettura a basso accoppiamento rispetto alle controparti con prestazioni basse.
Architettura a basso accoppiamento
La nostra ricerca continua a mostrare la possibilità di migliorare le prestazioni dell'IT impegnandosi a ridurre le dipendenze granulari tra servizi e team. Di fatto, questo è uno dei maggiori predittori del successo della distribuzione continua. L'uso di un'architettura a basso accoppiamento permette ai team di scalare, effettuare tentativi non riusciti, testare ed eseguire il deployment con operazioni indipendenti tra loro. I team possono procedere al proprio ritmo, lavorare in batch più piccoli, accumulare meno debito tecnico e recuperare più rapidamente in caso di mancata riuscita.
Test continuo e integrazione continua
Analogamente a quanto emerso negli anni passati, mostriamo che il test continuo è un forte predittore del successo della distribuzione continua. Le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità 3,7 volte maggiore di sfruttare il test continuo. Integrando test frequenti fin dalle prime fasi e nell'intero processo di distribuzione, con una collaborazione continua tra quanti eseguono i test e gli sviluppatori, i team possono eseguire l'iterazione e apportare modifiche al prodotto, al servizio o all'applicazione con più rapidità. Puoi usare questo loop di feedback per fornire valore ai tuoi clienti e allo stesso tempo integrare facilmente pratiche come il test automatico e l'integrazione continua.
L'integrazione continua migliora anche la distribuzione continua. Le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità 5,8 volte maggiore di sfruttare l'integrazione continua. Nell'integrazione continua, ogni commit attiva una build del software ed esegue una serie di test automatizzati che forniscono feedback nell'arco di pochi minuti. Con l'integrazione continua riduci il coordinamento manuale, spesso complesso, necessario per il successo dell'integrazione.
L'integrazione continua, secondo la definizione di Kent Beck e della community Extreme Programming, dove ha avuto origine, include anche la pratica dello sviluppo basato su trunk, di cui parleremo ora.7
Sviluppo basato su trunk
La nostra ricerca ha evidenziato una probabilità uniformemente maggiore che le organizzazioni con prestazioni elevate abbiano implementato lo sviluppo basato su trunk, in cui gli sviluppatori lavorano in piccoli batch e uniscono di frequente il lavoro svolto in un trunk condiviso. Di fatto, le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità 2,3 volte maggiore di utilizzare lo sviluppo basato su trunk. Le organizzazioni con prestazioni basse sono più propense a utilizzare rami di lunga durata e ritardarne l'unione.
I team dovrebbero unire il lavoro svolto almeno una volta al giorno, o più volte se possibile. Lo sviluppo basato su trunk è strettamente correlato all'integrazione continua, per cui dovresti implementare queste due pratiche tecniche contemporaneamente, perché il loro impatto è maggiore quando utilizzate insieme.
Automazione del deployment
In ambienti di lavoro ideali, i computer eseguono le attività ripetitive, mentre le persone si concentrano sulla risoluzione dei problemi. L'implementazione dell'automazione del deployment aiuta i tuoi team ad avvicinarsi a questo obiettivo.
Automatizzando il trasferimento del software dal test alla produzione riduci il tempo di risposta consentendo deployment più rapidi ed efficienti. Riduci inoltre la probabilità di errori di deployment, più comuni nei deployment manuali. Quando i tuoi team usano l'automazione del deployment, ricevono un feedback immediato che può aiutarti a migliorare il servizio o il prodotto in tempi molto più rapidi. Anche se non devi necessariamente implementare il test continuo, l'integrazione continua e l'automazione del deployment simultaneamente, avrai maggiore probabilità di vedere miglioramenti più sostanziali utilizzando le tre pratiche insieme.
Gestione delle modifiche al database
Il monitoraggio delle modifiche attraverso il controllo della versione è un aspetto cruciale della scrittura e della manutenzione del codice, oltre che della gestione dei database. Dalla nostra ricerca emerge che le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità 3,4 volte maggiore di applicare la gestione delle modifiche al database rispetto alle controparti con prestazioni basse. Inoltre, le chiavi per il successo nella gestione delle modifiche al database sono collaborazione, comunicazione e trasparenza tra tutti i team coinvolti. Anche se puoi scegliere tra gli approcci specifici da implementare, consigliamo di riunire i team ogni volta che sono richieste modifiche al database, perché le rivedano prima di procedere all'aggiornamento del database.
____________________________
8. Beck, K. (2000). Extreme programming explained: Embrace change. Addison-Wesley Professional
____________________________
Monitoraggio e osservabilità
Come negli anni precedenti, abbiamo riscontrato che le pratiche di monitoraggio e osservabilità supportano la distribuzione continua. Le organizzazioni di livello elite che hanno successo nel raggiungere i propri obiettivi di affidabilità hanno una probabilità 4,1 volte maggiore di avere soluzioni che incorporano l'osservabilità nell'integrità complessiva del sistema. Le pratiche di osservabilità offrono ai tuoi team una migliore comprensione dei sistemi, riducendo così il tempo necessario per identificare e risolvere i problemi. La nostra ricerca, inoltre, indica che i team con buone pratiche di osservabilità dedicano più tempo alla programmazione. Una possibile spiegazione per questo risultato consiste nel fatto che l'implementazione delle pratiche di osservabilità contribuisce a permettere agli sviluppatori di dedicare meno tempo a ricercare le cause dei problemi e tornare quindi a concentrarsi sulla programmazione.
Tecnologie open source
Molti sviluppatori sfruttano già tecnologie open source e la loro dimestichezza con questi strumenti è un punto di forza per l'organizzazione. Una debolezza principale delle tecnologie closed source è il limite che pongono alla capacità di trasferire conoscenze all'interno e all'esterno dell'organizzazione. Ad esempio, non puoi assumere qualcuno che abbia già dimestichezza con gli strumenti della tua organizzazione e gli sviluppatori non possono trasferire le conoscenze che hanno accumulato ad altre organizzazioni. Al contrario, la maggior parte delle tecnologie open source ha una community che le sostiene e in cui gli sviluppatori possono trovare assistenza. Le tecnologie open source sono più ampiamente accessibili, hanno costi relativamente bassi e sono più personalizzabili. Le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità 2,4 volte maggiore di sfruttare tecnologie open source. Consigliamo di passare a utilizzare più software open source man mano che implementi la tua trasformazione DevOps.
Per saperne di più sulle capacità tecniche DevOps, consulta le capacità DORA all'indirizzo https://cloud.google.com/devops/capabilities
COVID-19 e cultura
COVID-19
Quest'anno abbiamo esaminato i fattori che hanno influito sulle prestazioni dei team durante la pandemia di COVID-19. Nello specifico, la pandemia di COVID-19 ha avuto un impatto negativo sulle prestazioni di distribuzione del software e operative (SDO)? I team sperimentano più burnout come conseguenza? Infine, quali fattori sono promettenti per mitigare il burnout?
Innanzitutto, abbiamo cercato di comprendere l'impatto della pandemia sulle prestazioni di distribuzione e operative. Molte organizzazioni hanno dato priorità alla modernizzazione per adattarsi a cambiamenti sostanziali nel mercato, ad esempio il passaggio dagli acquisti di persona a quelli online. Nel capitolo "Come ci collochiamo?" abbiamo parlato di come le prestazioni nel settore del software abbiano registrato un'accelerazione significativa, ancora in corso. I team con le prestazioni migliori sono ora la maggioranza del nostro campione e quelli con prestazioni elite continuano ad alzare il livello di riferimento, con deployment più frequenti e tempi di risposta più brevi, tempi di ripristino più rapidi e migliori tassi di errore delle modifiche. Analogamente, uno studio dei ricercatori di GitHub ha mostrato un aumento nell'attività degli sviluppatori (ovvero push, richieste di pull, richieste di pull revisionate e problemi commentati per utente9) nell'arco del 2020. A quanto pare, il settore ha continuato ad accelerare nonostante la pandemia, piuttosto che come conseguenza, ma è degno di nota il fatto che non abbiamo registrato una tendenza negativa nelle prestazioni SDO durante questo periodo di enorme difficoltà.
La pandemia ha cambiato il nostro modo di lavorare e per molti anche il luogo di lavoro. Per questo motivo esaminiamo l'impatto del lavoro da remoto in conseguenza della pandemia. Abbiamo riscontrato che l'89% degli intervistati ha lavorato da casa a causa della pandemia. Solo il 20% ha dichiarato di aver già lavorato da casa prima dello scoppio della pandemia. Il passaggio a un ambiente di lavoro remoto ha avuto implicazioni significative per il modo di sviluppare il software, svolgere le attività aziendali e lavorare insieme. Per molti, il lavoro da casa ha precluso la capacità di entrare in contatto nelle conversazioni che nascono spontaneamente quando ci si incontra in corridoio o di collaborare di persona.
____________________________
9. https://octoverse.github.com/
____________________________
Cosa ha ridotto il burnout?
Nonostante questo, abbiamo riscontrato un fattore che ha avuto un grande effetto sul burnout dei team in conseguenza del lavoro da remoto: la loro cultura. I team con una cultura generativa, composti da persone che si sentivano incluse e parte del team, avevano una probabilità dimezzata di andare incontro al burnout durante la pandemia. Questo risultato ribadisce quanto sia importante dare priorità al team e alla cultura. I team con le prestazioni migliori sono preparati ad attraversare periodi più impegnativi, che esercitano pressione sia sul team che sui singoli individui.
Cultura
In senso lato, la cultura è l'inevitabile corrente sotterranea che permea le relazioni interpersonali in ogni organizzazione. È tutto ciò che influisce sul modo di pensare, percepire e comportarsi dei dipendenti nei confronti dell'organizzazione e dei loro pari. Tutte le organizzazioni hanno una loro cultura unica e i nostri risultati mostrano coerentemente che la cultura è uno dei principali fattori nelle prestazioni dell'organizzazione e dell'IT. Nello specifico, le nostre analisi indicano che una cultura generativa, misurata utilizzando la tipologia delle culture dell'organizzazione di Westrum, e il senso di appartenenza e inclusione delle persone all'interno dell'organizzazione sono fattori che determinano prestazioni di distribuzione del software e operative (SDO) superiori. Ad esempio, abbiamo riscontrato che le organizzazioni di livello elite che raggiungono i propri obiettivi di affidabilità hanno una probabilità 2,9 volte maggiore di avere una cultura del team generativa rispetto alle controparti con prestazioni basse. Analogamente, una cultura generativa è un fattore determinante per prestazioni dell'organizzazione superiori e minore frequenza di burnout dei dipendenti. In breve, la cultura è davvero importante. Fortunatamente, la cultura è fluida, sfaccettata e sempre in movimento, il che ti consente di modificarla.
Il successo nell'esecuzione di DevOps richiede che l'organizzazione abbia team che collaborano anche tra funzioni diverse. Nel 2018 abbiamo rilevato che i team con prestazioni alte avevano una probabilità doppia di sviluppare e distribuire software in un unico team interfunzionale. Questo ribadisce come la collaborazione e la cooperazione siano essenziali per il successo di qualsiasi organizzazione. Una domanda chiave è: quali fattori contribuiscono a creare un ambiente che incoraggi e celebri la collaborazione interfunzionale?
Nel corso degli anni, abbiamo provato a rendere tangibile il costrutto della cultura e a fornire alla community DevOps una migliore comprensione dell'impatto della cultura sulle prestazioni dell'organizzazione e dell'IT. Abbiamo iniziato questo percorso con una definizione operativa di cultura basata sulla tipologia delle culture dell'organizzazione di Westrum, che identifica tre tipi di organizzazioni: orientate al potere, orientate alle regole e orientate alle prestazioni. Abbiamo utilizzato questo framework nella nostra ricerca e rilevato che una cultura dell'organizzazione orientata alle prestazioni, che ottimizza il flusso delle informazioni, la fiducia, l'innovazione e la condivisione del rischio, è un fattore determinante per prestazioni SDO elevate.
Con l'evoluzione della nostra comprensione della cultura e di DevOps, abbiamo lavorato per espandere la definizione iniziale di cultura e includere altri fattori psico-sociali come la sicurezza psicologica. Le organizzazioni con prestazioni elevate hanno una maggiore probabilità di avere una cultura che incoraggia i dipendenti ad assumere rischi calcolati e moderati senza temere conseguenze negative.
Appartenenza e inclusione
Dato l'impatto uniformemente elevato della cultura sulle prestazioni, quest'anno abbiamo ampliato il nostro modello per esplorare se il senso di appartenenza e inclusione dei dipendenti contribuisce all'effetto benefico della cultura sulle prestazioni.
La ricerca psicologica ha mostrato che le persone sono intrinsecamente motivate a creare e mantenere relazioni solide e stabili con gli altri.10 Siamo motivati a sentirci connessi agli altri e a sentirci accettati nei vari gruppi di cui facciamo parte. Il senso di appartenenza porta con sé un'ampia varietà di risultati fisici e psicologici positivi. Ad esempio, la ricerca indica che il senso di appartenenza ha un impatto positivo sulla motivazione e porta a miglioramenti nel rendimento accademico.11
Una componente di questo senso di connessione è l'idea che le persone dovrebbero sentirsi a proprio agio portando sul lavoro ogni parte di sé e sapendo che le loro esperienze e i loro background sono valutati e apprezzati nella loro unicità.12 Concentrarsi sulla creazione di culture inclusive con un senso di appartenenza nell'organizzazione aiuta ad avere personale soddisfatto, diversificato e motivato.
I nostri risultati indicano che le organizzazioni orientate alle prestazioni che danno valore all'appartenenza e all'inclusione hanno una maggiore probabilità di avere livelli di burnout dei dipendenti più bassi rispetto alle organizzazioni con culture meno positive.
Alla luce delle prove che mostrano l'influsso dei fattori psico-sociali sulle prestazioni SDO e sui livelli di burnout tra i dipendenti, consigliamo di investire nell'affrontare le questioni legate alla cultura nell'ambito dell'impegno verso la trasformazione DevOps per realizzarla con successo.
____________________________
10. Baumeister & Leary, 1995. The need to belong: Desire for interpersonal attachments as a fundamental human motivation. Psychological Bulletin, 117(3), 497–529. https://doi.org/10.1037/0033-2909.117.3.497
11. Walton et al., 2012. Mere belonging: the power of social connections. Journal of Personality and Social Psychology, 102(3):513-32. https://doi.org/10.1037/a0025731
12. Mor Barak & Daya, 2014; Managing diversity: Toward a globally inclusive workplace. Sage. Shore, Cleveland, & Sanchez, 2018; Inclusive workplaces: A review and model, Human Resources Review. https://doi.org/10.1016/j.hrmr.2017.07.003
Chi ha partecipato al sondaggio?
Con sette anni di ricerca e oltre 32.000 risposte ai sondaggi tra i professionisti del settore, Accelerate State of DevOps 2021 presenta le pratiche di sviluppo software e DevOps con cui i team e le organizzazioni raggiungono il maggiore successo.
Quest'anno, 1200 professionisti di una varietà di settori in tutto il mondo hanno condiviso le loro esperienze per contribuire ad aumentare la nostra comprensione dei fattori che determinano prestazioni più elevate. Per riassumere, la rappresentazione di gruppi demografici e aziendali è rimasta notevolmente coerente.
Analogamente agli anni precedenti, abbiamo raccolto dati demografici per ogni partecipante al sondaggio. Le categorie includono genere, disabilità e gruppi sottorappresentati.
Informazioni demografiche e aziendali
Quest'anno abbiamo visto una rappresentazione coerente con i report precedenti nelle categorie delle informazioni aziendali, tra cui dimensioni dell'azienda, settore e area geografica. Di nuovo, oltre il 60% degli intervistati è composto da tecnici o manager e un terzo lavora nel settore tecnologico. Inoltre, vediamo rappresentati i settori dei servizi finanziari, retail e delle aziende industriali/di produzione.
____________________________
13. https://www.washingtongroup-disability.com/question-sets/wg-short-set-on-functioning-wg-ss/
____________________________
Dati demografici
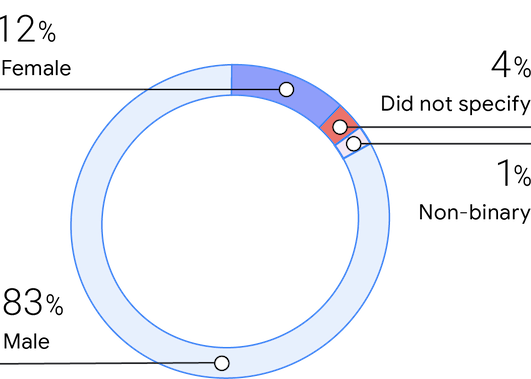
Genere
In linea con i sondaggi precedenti, il campione di quest'anno è composto da un 83% di uomini, un 12% di donne e un 1% non binario. Gli intervistati hanno dichiarato che le donne compongono circa il 25% dei loro team, un notevole aumento rispetto al 2019 (16%) e di nuovo allineato con il 2018 (25%).
Disabilità
La disabilità è identificata lungo sei dimensioni che seguono le linee guida del Washington Group Short Set.13 Questo è il terzo anno in cui poniamo domande sulla disabilità. La percentuale di persone con disabilità è rimasta stabile al 9% rispetto al nostro report del 2019.
Gruppi sottorappresentati
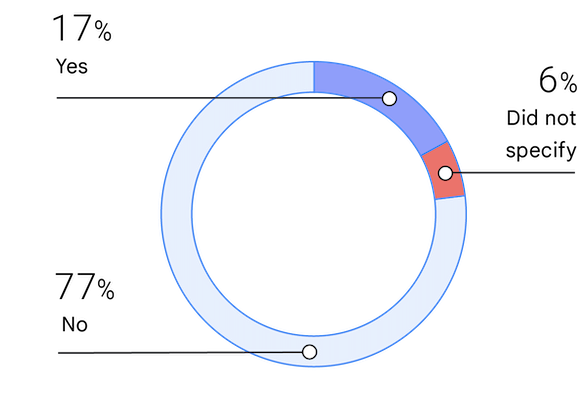
L'identificazione come appartenente a un gruppo sottorappresentato può far riferimento al gruppo etnico, al genere o a un'altra caratteristica. Questo è il quarto anno in cui abbiamo posto domande sui gruppi sottorappresentati. La percentuale di persone che si identificano come sottorappresentate è aumentata leggermente, dal 13,7% del 2019 al 17% del 2021.
Anni di esperienza
Gli intervistati nel sondaggio di quest'anno hanno una lunga esperienza, di almeno 16 anni per il 41%. Oltre l'85% degli intervistati ha almeno 6 anni di esperienza.
Informazioni aziendali
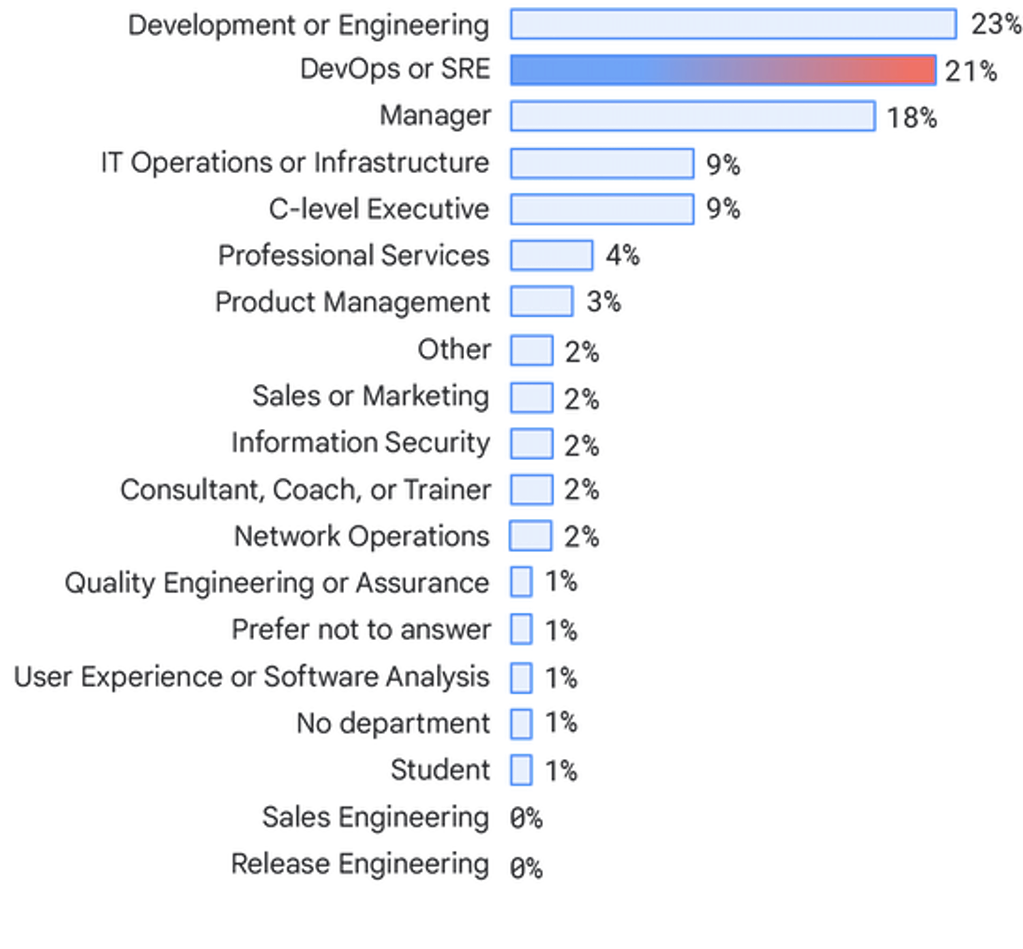
Reparti
Gli intervistati sono in maggioranza persone che lavorano in team di sviluppo o progettazione (23%), team DevOps o SRE (21%), manager (18%) e team delle operazioni IT o dell'infrastruttura (9%). Abbiamo visto una riduzione nella rappresentazione dei consulenti (dal 4% del 2019 al 2%) e un aumento dei dirigenti di livello C (dal 4% del 2019 al 9%).
Settore
Come nei report Accelerate State of DevOps precedenti, vediamo che la maggioranza degli intervistati lavora nel settore tecnologico, seguito da servizi finanziari, retail e altri.
Dipendenti
In linea con i report Accelerate State of DevOps precedenti, gli intervistati lavorano in organizzazioni di varie dimensioni. Il 22% degli intervistati lavora in aziende con oltre 10.000 dipendenti e il 7% in aziende con 5000–9999 dipendenti. Un altro 15% degli intervistati lavora in organizzazioni con 2000–4999 dipendenti. Abbiamo visto anche una buona rappresentazione di organizzazioni con 500–1999 dipendenti, al 13%, 100–499 dipendenti, al 15%, e infine 20–99 dipendenti, al 15%.
Dimensioni del team
Oltre la metà degli intervistati (62%) lavora in team con 10 o meno membri (il 28% in team con 6–10 membri, il 27% in team di 2–5, il 6% in team individuali). Un altro 19% lavora in team con 11–20 membri.
Aree geografiche
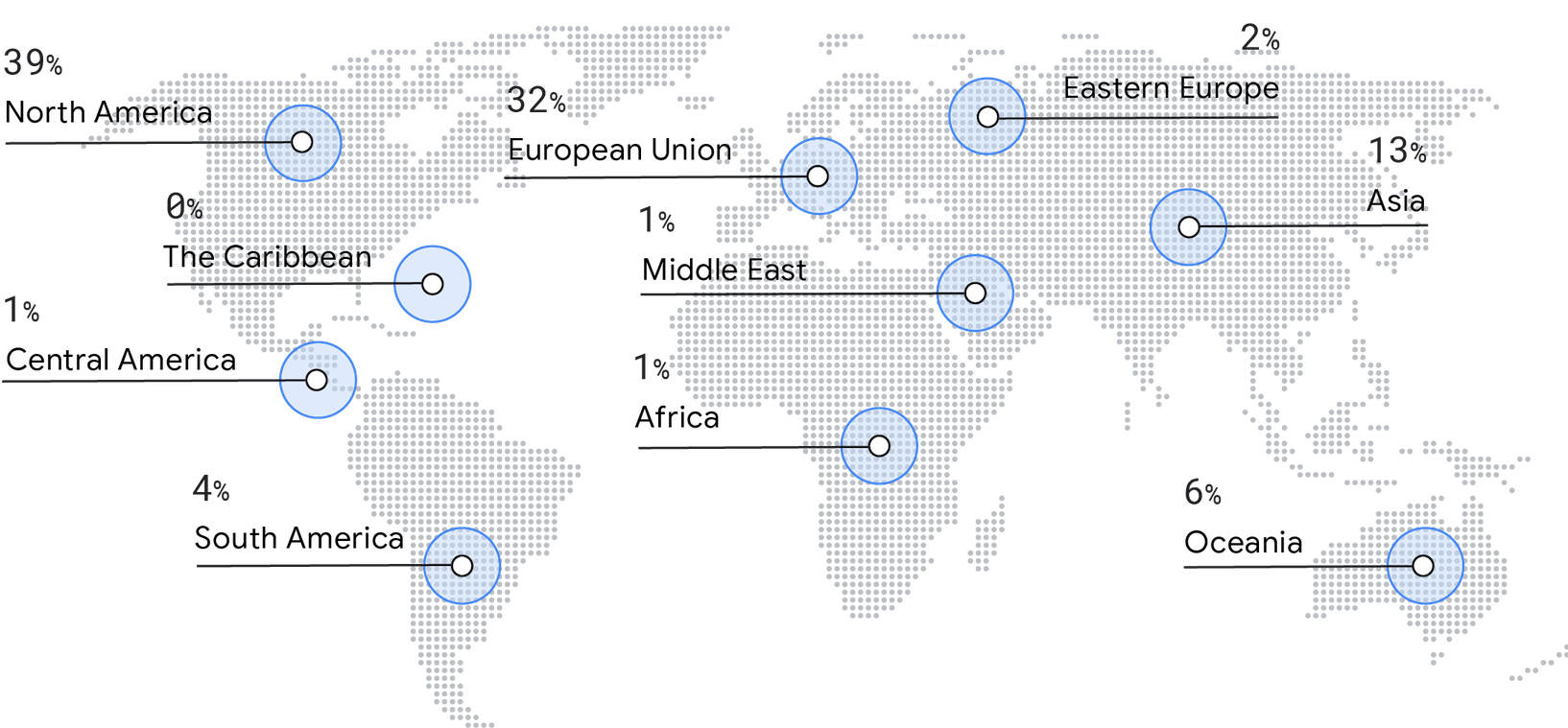
Il sondaggio di quest'anno ha visto una riduzione delle risposte dal Nord America (dal 50% del 2019 al 39% del 2021). Abbiamo visto invece un aumento nella rappresentazione di Europa (dal 29% del 2019 al 32% del 2021), Asia (dal 9% del 2019 al 13% del 2021), Oceania (dal 4% del 2019 al 6% del 2021) e Sud America (dal 2% del 2019 al 4% del 2021).
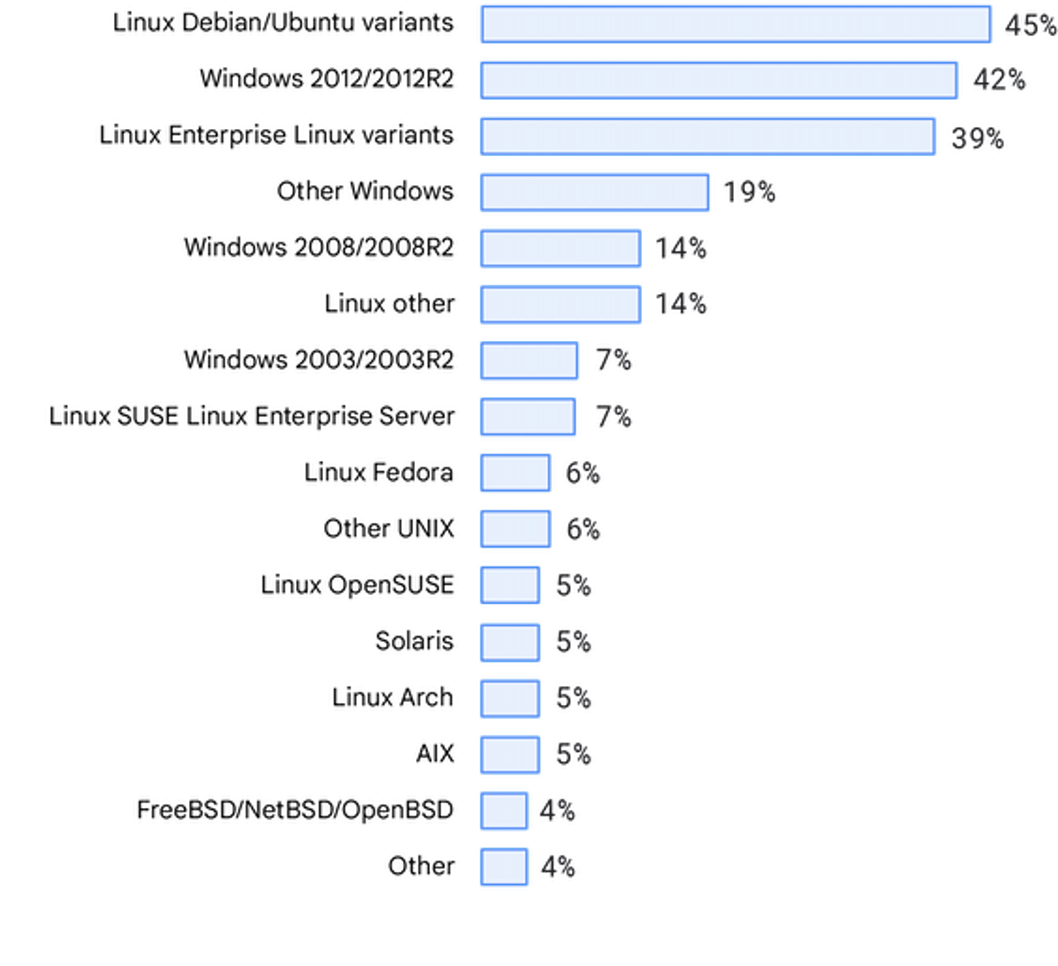
Sistemi operativi
Anche la distribuzione dei sistemi operativi è coerente con i report State of DevOps precedenti. Riconosciamo inoltre agli intervistati il merito di aver segnalato l'opportunità di aggiornare il nostro elenco di sistemi operativi e li ringraziamo per questo.
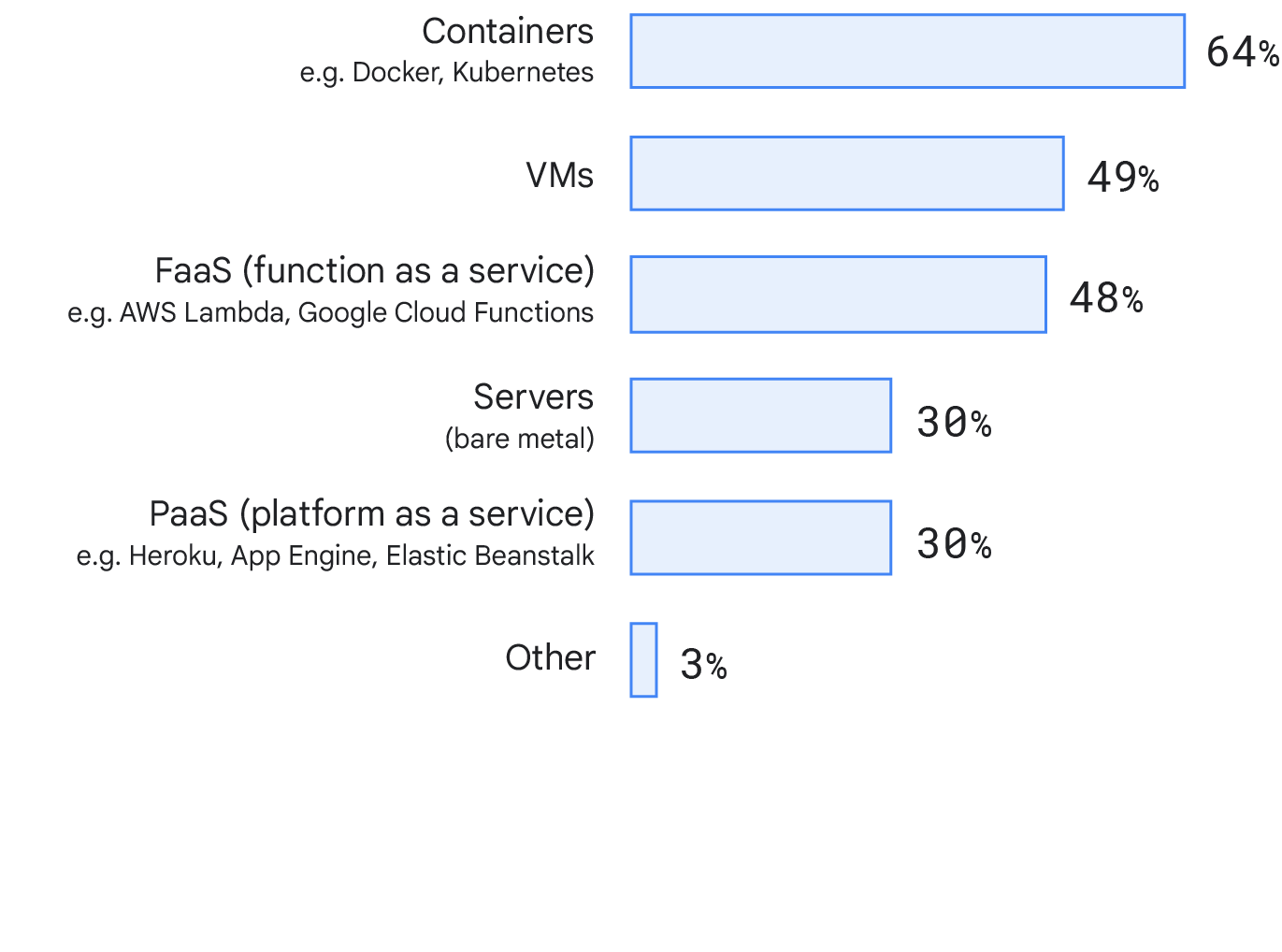
Destinazione di deployment
Quest'anno abbiamo esaminato dove gli intervistati eseguono il deployment del servizio o dell'applicazione principale su cui lavorano. Ha destato sorpresa il fatto che un'ampia parte degli intervistati utilizza i container (64%), mentre il 48% usa le macchine virtuali (VM). Questo può riflettere un cambiamento di orientamento nel settore verso tecnologie delle destinazioni di deployment più moderne. Abbiamo controllato se ci fossero differenze tra le varie dimensioni delle aziende e non abbiamo riscontrato differenze significative tra le destinazioni di deployment.
Considerazioni finali
Dopo sette anni di ricerca, vediamo i vantaggi che DevOps offre alle organizzazioni. Anno dopo anno, le organizzazioni continuano ad accelerare e migliorare.
I team che ne adottano i principi e le capacità possono distribuire il software in modo rapido e affidabile, fornendo al tempo stesso valore all'azienda. Quest'anno abbiamo esaminato gli effetti delle pratiche SRE, di una catena di fornitura software sicura e di una documentazione di qualità, oltre a riconsiderare la nostra esplorazione dello sfruttamento del cloud. Ogni area consente a persone e team di avere una maggiore efficacia. Ci concentriamo sull'importanza di strutturare soluzioni adatte per le persone che sfruttano queste capacità, anziché adattare le persone alla soluzione.
Ringraziamo tutti quanti hanno contribuito al sondaggio di quest'anno e speriamo che la nostra ricerca aiuti te e la tua organizzazione a creare team e software migliori, mantenendo al contempo l'equilibrio tra lavoro e vita privata.
Ringraziamenti
Il report di quest'anno è stato reso possibile da un'ampia famiglia di collaboratori appassionati. La progettazione, l'analisi, la scrittura, la modifica delle domande del sondaggio e la progettazione del report sono solo alcuni dei modi in cui i nostri colleghi ci hanno aiutato a portare a compimento questo grande impegno. Gli autori vogliono cogliere l'occasione per ringraziare tutte queste persone per il loro contributo e la loro guida al report di quest'anno. Tutti i riconoscimenti sono in ordine alfabetico.

Autori
Dustin Smith
Dustin Smith, specializzato in psicologia dei fattori umani e responsabile della ricerca sull'esperienza utente del personale in Google, ha lavorato al progetto DORA per tre anni. Negli ultimi sette anni, ha studiato l'influenza dei sistemi e degli ambienti circostanti sulle persone in una varietà di contesti: progettazione del software, giochi free-to-play, settore sanitario e militare. La sua ricerca in Google identifica le aree in cui gli sviluppatori di software possono sentirsi più contenti e produttivi durante lo sviluppo. Ha lavorato al progetto DORA per due anni. Dustin ha conseguito il PhD in psicologia dei fattori umani presso la Wichita State University.
Daniella Villalba
Daniella Villalba è una ricercatrice che si occupa di esperienza utente e si dedica al progetto DORA. Si concentra sulla comprensione dei fattori che rendono gli sviluppatori contenti e produttivi. Prima di entrare in Google, Daniella ha studiato i vantaggi dell'addestramento alla meditazione e i fattori psico-sociali che influiscono sulle esperienze degli studenti universitari, sulla memoria dei testimoni oculari e sulle false confessioni. Ha conseguito il PhD in psicologia sperimentale presso la Florida International University.
Michelle Irvine
Michelle Irvine lavora in Google come Technical Writer e si dedica a colmare il divario tra gli strumenti per sviluppatori e le persone che li usano. Prima di entrare in Google, ha lavorato nell'editoria per l'istruzione e come Technical Writer per un software di simulazione per la fisica. Michelle ha un BSc in fisica, oltre a un MA in retorica e design delle comunicazioni conseguito presso l'Università di Waterloo.
Dave Stanke
Dave Stanke lavora come Developer Relations Engineer in Google, dove consiglia ai clienti le pratiche per l'adozione di DevOps e SRE. Nell'arco della sua carriera ha ricoperto ogni genere di posizione, tra cui CTO di una startup, product manager, assistenza clienti, sviluppatore software, amministratore di sistema e graphic designer. Ha conseguito un MS in gestione della tecnologia presso la Columbia University.
Nathen Harvey
Nathen Harvey lavora come Developer Relations Engineer in Google e ha costruito la sua carriera sull'aiuto ai team nel realizzare il loro potenziale e al contempo allineare la tecnologia ai risultati aziendali. Nathen ha avuto il privilegio di lavorare con alcuni dei migliori team e delle migliori community open source, aiutandoli ad applicare principi e pratiche di DevOps e SRE. Nathen è coredattore e ha contribuito alla pubblicazione del libro "97 Things Every Cloud Engineer Should Know", O'Reilly 2020.
Metodologia
Progettazione della ricerca
Questo studio adotta un approccio intersezionale basato sulla teoria. Questo approccio basato sulla teoria è noto come inferenziale predittivo ed è uno dei più comuni nelle odierne ricerche in ambito aziendale e tecnologico. L'approccio inferenziale viene adottato quando non è possibile un approccio puramente sperimentale e sono preferibili esperimenti sul campo.
Popolazione target e campionamento
La popolazione target per questo sondaggio era costituita da professionisti e leader che lavorano direttamente, o in stretto contatto, con la tecnologia e le trasformazione, in particolare quanti hanno dimestichezza con DevOps. Abbiamo promosso il sondaggio tramite mailing list, promozioni online, un gruppo online, social media, oltre a chiedere di condividere il sondaggio con le proprie reti (il cosiddetto campionamento a valanga).
Creazione dei costrutti latenti
Abbiamo formulato ipotesi e costrutti utilizzando, dove possibile, costrutti convalidati in precedenza. Abbiamo sviluppato nuovi costrutti in base alla teoria, alle definizioni e agli input degli esperti. Abbiamo intrapreso ulteriori passaggi per chiarire l'intento, al fine di assicurare che i dati raccolti dal sondaggio avessero un'alta probabilità di essere affidabili e validi.14
Metodi di analisi statistica
Cluster analysis. Abbiamo utilizzato la cluster analysis per identificare i nostri profili di prestazioni di distribuzione del software in base a frequenza di deployment, tempo di risposta, tempo per ripristinare il servizio e tasso di errore delle modifiche. Abbiamo usato un'analisi delle classi latenti15 perché non avevamo motivi teorici o di settore per avere un numero predeterminato di cluster; inoltre, abbiamo utilizzato il criterio di informazione Bayesiano16 per determinare il numero di cluster ottimale.
Modello di misurazione. Prima di condurre l'analisi, abbiamo identificato i costrutti mediante un'analisi fattoriale esplorativa, con analisi delle componenti principali con rotazione Varimax.17 Abbiamo confermato i test statistici per validità e affidabilità convergente utilizzando la varianza media estratta (AVE), la correlazione, l'alpha di Cronbach,18 e l'attendibilità composita.
Modellazione di equazioni strutturali. Abbiamo testato i modelli di equazioni strutturali (SEM, Structural Equation Model) utilizzando l'analisi dei minimi quadrati parziali (PLS, Partial Least Squares), un SEM basato sulla correlazione.19
________________________
14. Churchill Jr, G. A. "A paradigm for developing better measures of marketing constructs", Journal of Marketing Research 16:1, (1979), 64–73.
15. Hagenaars, J. A., & McCutcheon, A. L. (Eds.). (2002). Applied latent class analysis. Cambridge University Press.
16. Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychological methods, 17(2), 228.
17. Straub, D., Boudreau, M. C., & Gefen, D. (2004). Validation guidelines for IS positivist research. Communications of the Association for Information systems, 13(1), 24.
18. Nunnally, J.C. Psychometric Theory. New York: McGraw-Hill, 1978
19. Hair Jr, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2021). "A primer on partial least squares structural equation modeling (PLS-SEM).", Sage publications
Per approfondire
Scopri di più sulle funzionalità DevOps su https://cloud.google.com/devops/capabilities
Trova risorse su Site Reliability Engineering (SRE) all'indirizzo
Esegui il controllo rapido DevOps:
https://www.devops-research.com/quickcheck.html
Esplora il programma di ricerca DevOps:
https://www.devops-research.com/research.html
Scopri l'Application Modernization Program di Google Cloud:
https://cloud.google.com/solutions/camp
Leggi il white paper "The ROI of DevOps Transformation: How to quantify the impact of your modernization initiatives":
https://cloud.google.com/resources/roi-of-devops-transformation-whitepaper
Consulta i report State of DevOps precedenti:
State of DevOps 2014: https://services.google.com/fh/files/misc/state-of-devops-2014.pdf
State of DevOps 2015: https://services.google.com/fh/files/misc/state-of-devops-2015.pdf
State of DevOps 2016: https://services.google.com/fh/files/misc/state-of-devops-2016.pdf
State of DevOps 2017: https://services.google.com/fh/files/misc/state-of-devops-2017.pdf
Accelerate State of DevOps 2018: https://services.google.com/fh/files/misc/state-of-devops-2018.pdf
Accelerate State of DevOps 2019:
https://services.google.com/fh/files/misc/state-of-devops-2019.pdf
Vuoi iniziare la trasformazione basata sui dati?
Scopri il nostro approccio alla creazione di un cloud di dati mirato all'ottimizzazione di velocità, scalabilità e sicurezza. Visualizza qui


















