Accelerate State of DevOps 2021
¿Qué diferencia a los equipos de software de mayor y menor rendimiento? En el informe de 2021, examinamos las prácticas que impulsan la entrega de software y el rendimiento operativo exitosos para que puedas comparar tu organización con las entidades de mejor rendimiento. Luego, puedes usar nuestros hallazgos para mejorar los resultados clave, acelerar la innovación y alejarte del paquete.
Resumen ejecutivo
El informe Accelerate State of DevOps del equipo de investigación y evaluación de DevOps (DORA) de Google Cloud representa siete años de investigación y datos de más de 32,000 profesionales de todo el mundo.
Nuestra investigación examina las capacidades y prácticas que impulsan la entrega de software, las operaciones y el rendimiento de la organización. Cuando aprovechamos técnicas estadísticas rigurosas, buscamos comprender las prácticas que llevan a la excelencia en tecnología y a resultados comerciales potentes. Para ello, presentamos estadísticas basadas en datos sobre las formas más eficaces y eficientes de desarrollar y entregar tecnología.
Nuestra investigación sigue demostrando que la excelencia en la entrega de software y el rendimiento operativo impulsan el rendimiento organizacional en las transformaciones tecnológicas. A fin de permitir que los equipos se comparen con la industria, usamos un análisis de clúster para crear categorías de rendimiento significativas (como rendimiento bajo, medio, alto o de élite). Una vez que los equipos tengan una idea de su rendimiento actual en relación con la industria, puedes usar los hallazgos de nuestro análisis predictivo para orientar prácticas y capacidades a fin de mejorar los resultados clave y, finalmente, la relación posición. Este año, destacamos la importancia de cumplir los objetivos de confiabilidad, integrando la seguridad en toda la cadena de suministro de software, creando documentación interna de calidad y aprovechando al máximo la nube. También exploramos si una cultura de equipo positiva puede mitigar los efectos de trabajar de forma remota como resultado de la pandemia del COVID-19.
Para realizar mejoras significativas, los equipos deben adoptar una filosofía de mejora continua. Usa las comparativas a fin de medir tu estado actual, identificar restricciones en función de las capacidades que estudia la investigación y experimentar con mejoras para aliviar dichas restricciones. En la experimentación habrá una combinación de victorias y fracasos, pero en ambas situaciones los equipos pueden tomar medidas importantes como resultado de las lecciones aprendidas.
Hallazgos clave
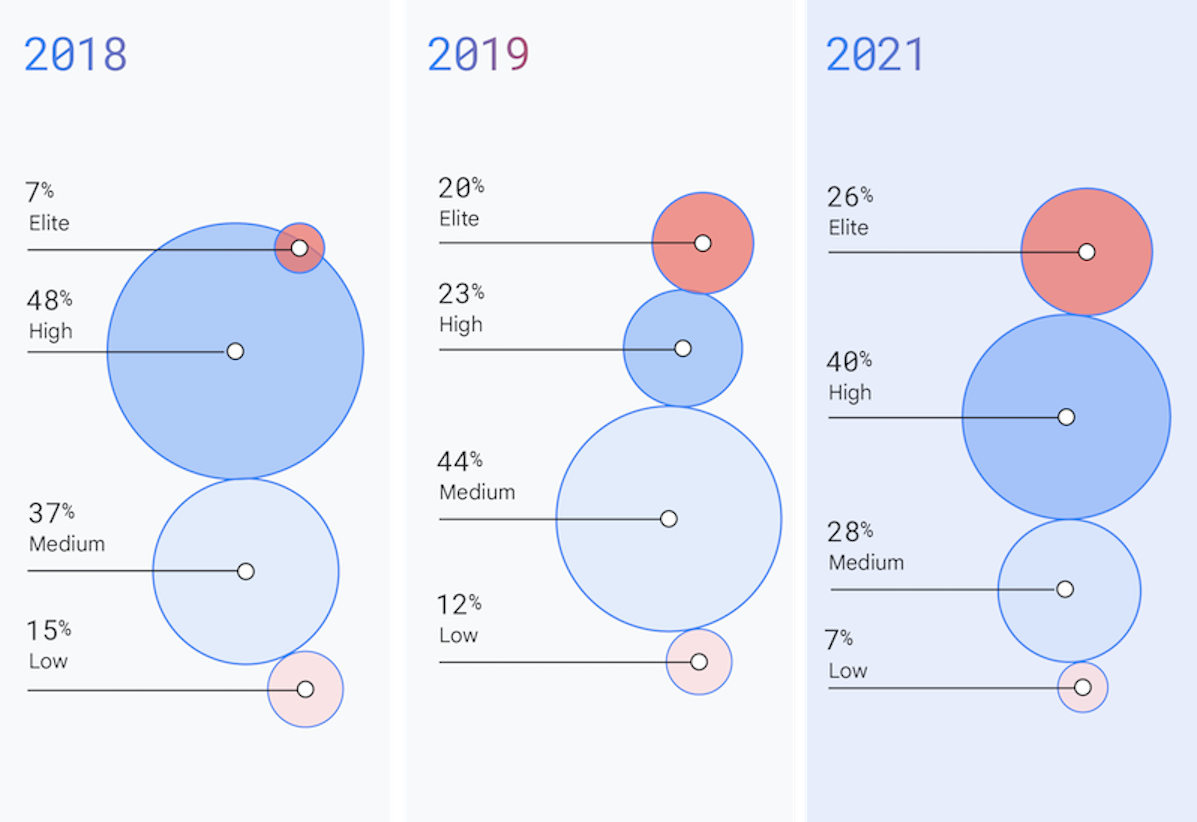
Los elementos con mejor rendimiento están creciendo y continúan elevando los estándares.
Las organizaciones con rendimiento de élite ahora representan el 26% de los equipos de nuestro estudio y disminuyeron los plazos de entrega de los cambios en la producción. La industria sigue acelerando, y los equipos obtienen beneficios significativos.
SRE y DevOps son filosofías complementarias.
Los equipos que aprovechan las prácticas operativas modernas descritas en nuestros amigos de ingeniería de confiabilidad de sitios (SRE) informan un mayor rendimiento operativo. Los equipos que priorizan la entrega y la excelencia operativa informan el rendimiento organizacional más alto.
Más equipos aprovechan la nube y obtienen beneficios significativos.
Los equipos continúan migrando cargas de trabajo a la nube y las que aprovechan las cinco capacidades de la nube observan aumentos en la entrega de software, el rendimiento operativo (SDO) y el rendimiento de la organización. La adopción de múltiples nubes también está en ascenso para que los equipos puedan aprovechar las capacidades únicas de cada proveedor.
Una cadena de suministro de software segura es esencial y mejora el rendimiento.
Debido al aumento significativo de ataques maliciosos en los últimos años, las organizaciones deben pasar de las prácticas reactivas a las medidas proactivas y de diagnóstico. Los equipos que integran las prácticas de seguridad en toda la cadena de suministro de software entregan software de forma rápida, confiable y segura.
La buena documentación es la base para implementar correctamente funciones de DevOps
Por primera vez, medimos la calidad de la documentación interna y las prácticas que contribuyen a esta calidad. Los equipos con documentación de alta calidad pueden implementar prácticas técnicas y tener un mejor rendimiento en general.
Una cultura de equipo positiva mitiga el agotamiento durante circunstancias desafiantes
La cultura de equipo marca una gran diferencia en la capacidad de un equipo para ofrecer software y cumplir o superar sus objetivos organizacionales. Los equipos inclusivos con una cultura generativa1,2 experimentaron menos agotamiento durante la pandemia del COVID-19.
____________________________
1. Desde la cultura de la organización tipográfica de Westrum, una cultura de equipo generativa hace referencia a los equipos que son altamente cooperativos, dividen los sistemas aislados, dejan que el fracaso genere consultas y compartan el riesgo de tomar decisiones.
2. Westrum, R. (2004). “A typology of organizational cultures.” BMJ Quality & Safety, 13(suppl 2), ii22-ii27.
¿Cómo calificamos comparativamente?
¿Te interesa saber cómo se compara tu equipo con otros del sector? En esta sección, se incluye la evaluación comparativa más reciente del rendimiento de DevOps.
Examinamos cómo los equipos desarrollan, entregan y operan los sistemas de software, y luego segmentamos a los encuestados en cuatro clústeres de rendimiento: rendimiento de élite, alto, medio y bajo. Si comparas el rendimiento de tu equipo con el de cada clúster, puedes ver dónde te encuentras en el contexto de los resultados que se describen en este informe.
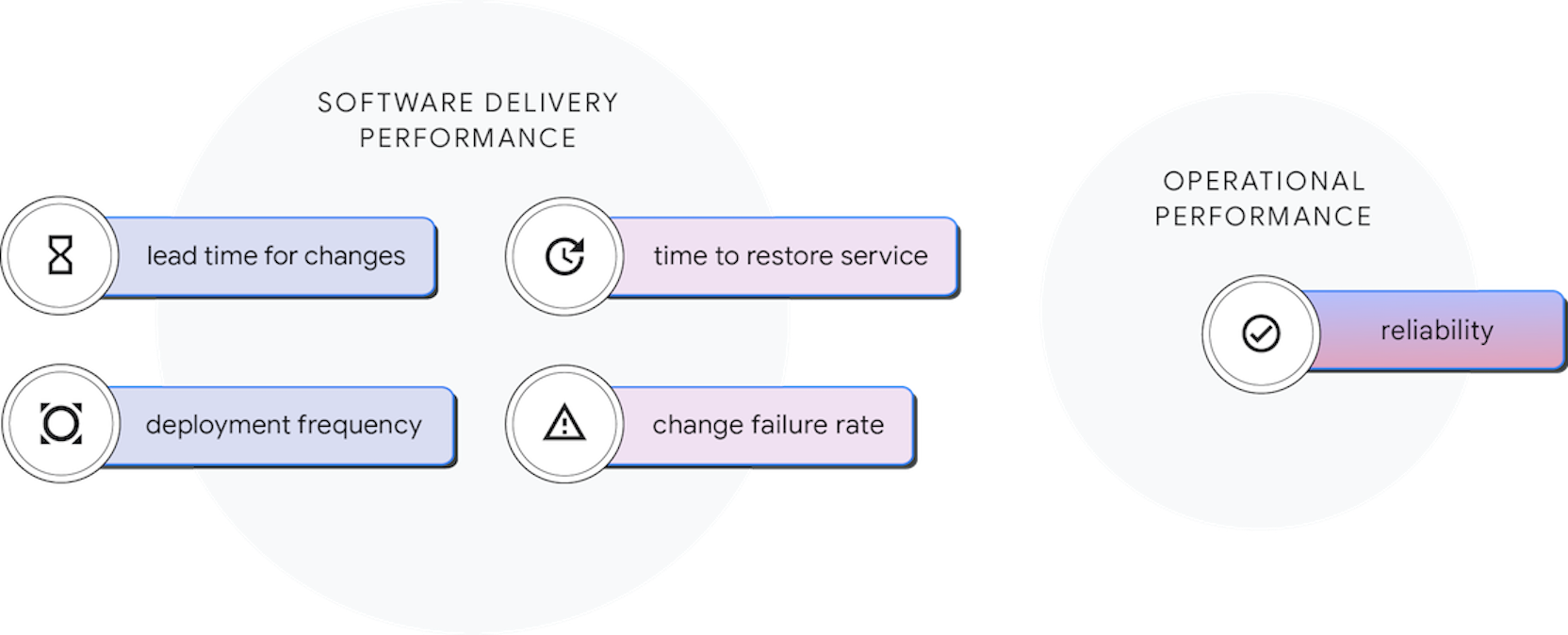
Entrega de software y rendimiento operativo
Para satisfacer las demandas de una industria en constante cambio, las organizaciones deben ofrecer y operar software con rapidez y confiabilidad. Cuanto más rápido los equipos puedan realizar cambios en el software, más rápido podrás generar valor para tus clientes, realizar experimentos y recibir comentarios valiosos. Con siete años de investigación y recopilación de datos, desarrollamos y validamos cuatro métricas que miden el rendimiento de la entrega de software. Desde 2018, incluimos una quinta métrica para capturar las capacidades operativas.
Los equipos que se destacan en las cinco mediciones tienen un rendimiento organizativo extraordinario. Llamamos a estas cinco medidas rendimiento de la entrega de software y operativo (software delivery and operational, SDO). Ten en cuenta que estas métricas se enfocan en los resultados a nivel del sistema, lo que ayuda a evitar los problemas comunes de las métricas de software, como la comparación entre funciones y las optimizaciones locales a costa de los resultados generales.
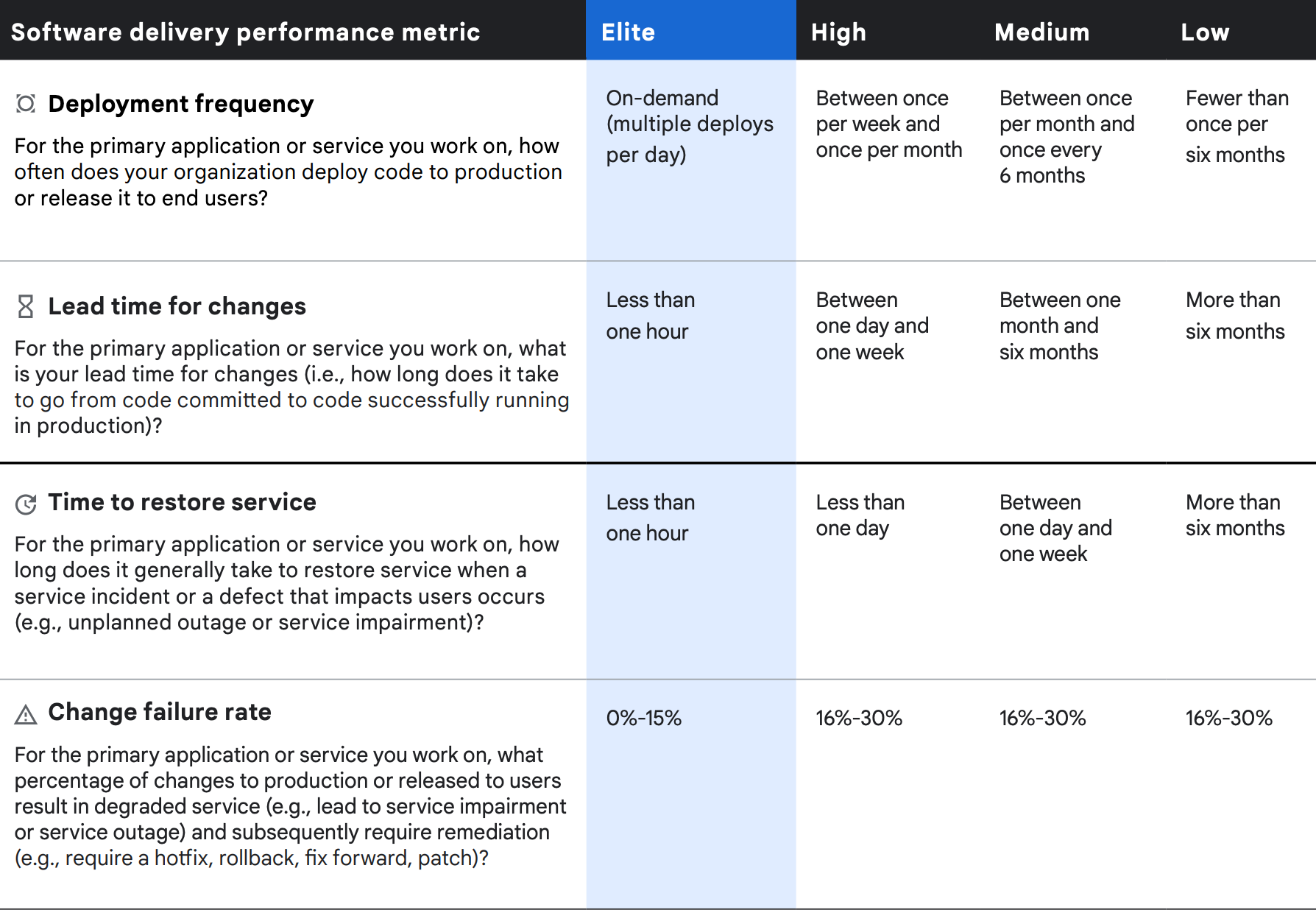
Cuatro métricas del rendimiento de la entrega
Se pueden considerar cuatro métricas de rendimiento de la entrega de software en términos de capacidad de procesamiento y estabilidad. Medimos la capacidad de procesamiento con el plazo de entrega de los cambios de código (es decir, el tiempo desde la confirmación de código hasta el lanzamiento en producción) y la frecuencia de implementación. Medimos la estabilidad con el tiempo de restablecimiento del servicio después de un incidente y la tasa de errores de cambio.
Una vez más, el análisis de clústeres de las cuatro métricas de entrega de software revela cuatro perfiles de rendimiento distintos: de élite, alto, medio y bajo, con diferencias estadísticamente significativas en la capacidad de procesamiento y las medidas de estabilidad entre ellas. Al igual que en años anteriores, nuestros equipos con el mejor rendimiento tienen un rendimiento significativamente mejor en las cuatro medidas, y aquellos con un rendimiento bajo funcionan mucho mejor en todas las áreas.
La quinta métrica: de la disponibilidad a la confiabilidad
La quinta métrica representa el rendimiento operativo y es una medida de las prácticas operativas modernas. La métrica principal para el rendimiento operativo es la confiabilidad, que es el grado en el que un equipo puede mantener promesas y aserciones sobre el software que operan. Históricamente, medimos la disponibilidad en lugar de la confiabilidad, pero, como la disponibilidad es un enfoque específico de la ingeniería de confiabilidad, expandimos nuestra medición a la confiabilidad para que la disponibilidad, la latencia, el rendimiento y la escalabilidad tienen una representación más amplia. En concreto, le pedimos a los encuestados que calificaran su capacidad para cumplir o superar sus objetivos de confiabilidad. Descubrimos que los equipos con diferentes grados de rendimiento de entrega obtienen mejores resultados cuando también priorizan el rendimiento operativo.
Al igual que los informes anteriores, comparamos los equipos de rendimiento de élite con los de bajo rendimiento para ilustrar el impacto de funciones específicas. Sin embargo, este año tratamos de tener en cuenta el impacto del rendimiento operativo. En todas las categorías de rendimiento de la entrega (de rendimiento bajo a rendimiento de élite), observamos grandes beneficios en múltiples resultados para los equipos que priorizaron el cumplimiento o la superación de sus objetivos de confiabilidad.
La industria sigue acelerando
Todos los años, vemos que la industria evoluciona y acelera la capacidad de entrega de software con mayor velocidad y mayor estabilidad. Por primera vez, dos tercios de las organizaciones que respondieron fueron organizaciones de rendimiento alto y de élite. Además, las empresas con un rendimiento de élite de este año aumentaron nuevamente las expectativas, ya que disminuyeron los plazos de entrega de los cambios en comparación con las evaluaciones anteriores (por ejemplo, si pasaron de menos de un día en 2019 a menos de una hora en 2021). Además, por primera vez, solo las organizaciones de rendimiento de élite minimizaron su tasa de errores de cambio en comparación con años anteriores en los que los equipos de rendimiento medio y alto pudieron hacer lo mismo.
Capacidad de procesamiento y estabilidad
Capacidad de procesamiento
Frecuencia de implementación
De manera coherente con los años anteriores, el grupo de élite informó que se implementa a pedido y que realiza varias implementaciones por día. En comparación, los equipos de bajo rendimiento informaron que habían realizado implementaciones menos de una vez cada seis meses (menos de dos por año), lo que nuevamente supone una disminución del rendimiento en comparación con 2019. Los números de las implementaciones anuales normalizadas van de 1,460 implementaciones al año (se calculan como cuatro implementaciones por día x 365 días) para los elementos con mejor rendimiento a 1.5 implementaciones por año para las de bajo rendimiento (el promedio de dos implementaciones y una implementación). Este análisis indica que los equipos de rendimiento de élite implementan código 973 veces más a menudo que los equipos de bajo rendimiento.
Plazo de entrega de los cambios
Una mejora en comparación con 2019 es que los equipos de rendimiento de élite informan un plazo de entrega de menos de una hora, midiendo el cambio en el plazo de entrega como el tiempo transcurrido entre la confirmación del código y su implementación correcta en producción. Se trata de un aumento en el rendimiento en comparación con 2019, cuando los usuarios con más rendimiento informaron cambios en los plazos de entrega de menos de un día. A diferencia de las empresas de rendimiento de élite, las de bajo rendimiento necesitaron plazos de entrega de más de seis meses. Con plazos de entrega de una hora para las empresas con rendimiento de élite (una estimación conservadora en el extremo superior de "menos de una hora") y de 6,570 horas para las de bajo rendimiento (calculada a partir de un promedio de 8,760 horas por año y 4,380 horas en seis meses), el grupo de élite tiene plazos de entrega para los cambios 6,570 veces más rápidos que las empresas de bajo rendimiento.
Estabilidad
Tiempo de restablecimiento del servicio
El grupo de élite informó un tiempo para restablecer el servicio de menos de una hora, mientras que el de bajo rendimiento informó más de seis meses. Para este cálculo, elegimos intervalos de tiempo conservadores: una hora para los equipos de alto rendimiento y una media de un año (8,760 horas) y seis meses (4,380 horas) para los equipos de bajo rendimiento. Según estas cifras, las organizaciones de élite tienen un tiempo de restablecimiento del servicio 6,570 veces más rápido que las de bajo rendimiento. El tiempo de restablecimiento del servicio se mantuvo igual para las organizaciones de rendimiento de élite y aumentó para las de rendimiento bajo en comparación con 2019.
Tasa de errores de cambio
Las empresas con rendimiento de élite informaron una tasa de errores de cambio del 0% al 15%, mientras que las que tienen un rendimiento bajo informaron tasas de errores de cambio del 16% al 30%. La media entre estos dos rangos muestra una tasa de errores de cambio del 7.5% para las organizaciones de rendimiento de élite y del 23% para las de bajo rendimiento. Las tasas de fallo de los cambios en las organizaciones de rendimiento de élite son tres veces más altas que en las organizaciones de bajo rendimiento. Este año, las tasas de errores de cambio se mantuvieron iguales para las organizaciones de rendimiento de élite y mejoraron para las de bajo rendimiento en comparación con 2019, pero empeoraron para los grupos intermedios.
Organizaciones de rendimiento de élite
Si comparamos el grupo de élite con el de rendimiento más bajo, descubrimos que el de élite las siguientes ventajas:
- Implementaciones de código 973 veces más frecuentes
- Tiempo de entrega 6,570 veces más rápido desde la confirmación hasta la implementación
- Tasa de errores de cambio 3 veces menor (la probabilidad de que los cambios fallen es un 1/3 menor)
- Tiempo de recuperación de incidentes 6,570 veces más rápido
¿Cómo podemos mejorar?
¿Cómo se puede mejorar el rendimiento de la SDO y de la organización? Nuestra investigación proporciona orientación basada en evidencia para ayudarte a enfocarte en las capacidades que impulsan el rendimiento.
En el informe de este año, se analizó el impacto de la nube, las prácticas de SRE, la seguridad, las prácticas técnicas y la cultura. En esta sección, presentamos cada una de estas capacidades y notamos su impacto en diversos resultados. Para quienes están familiarizados con los modelos de investigación de State of DevOps de DORA, creamos un recurso en línea que aloja el modelo de este año y todos los modelos anteriores.3
____________________________
3. https://devops-research.com/models.htm
____________________________
Translation
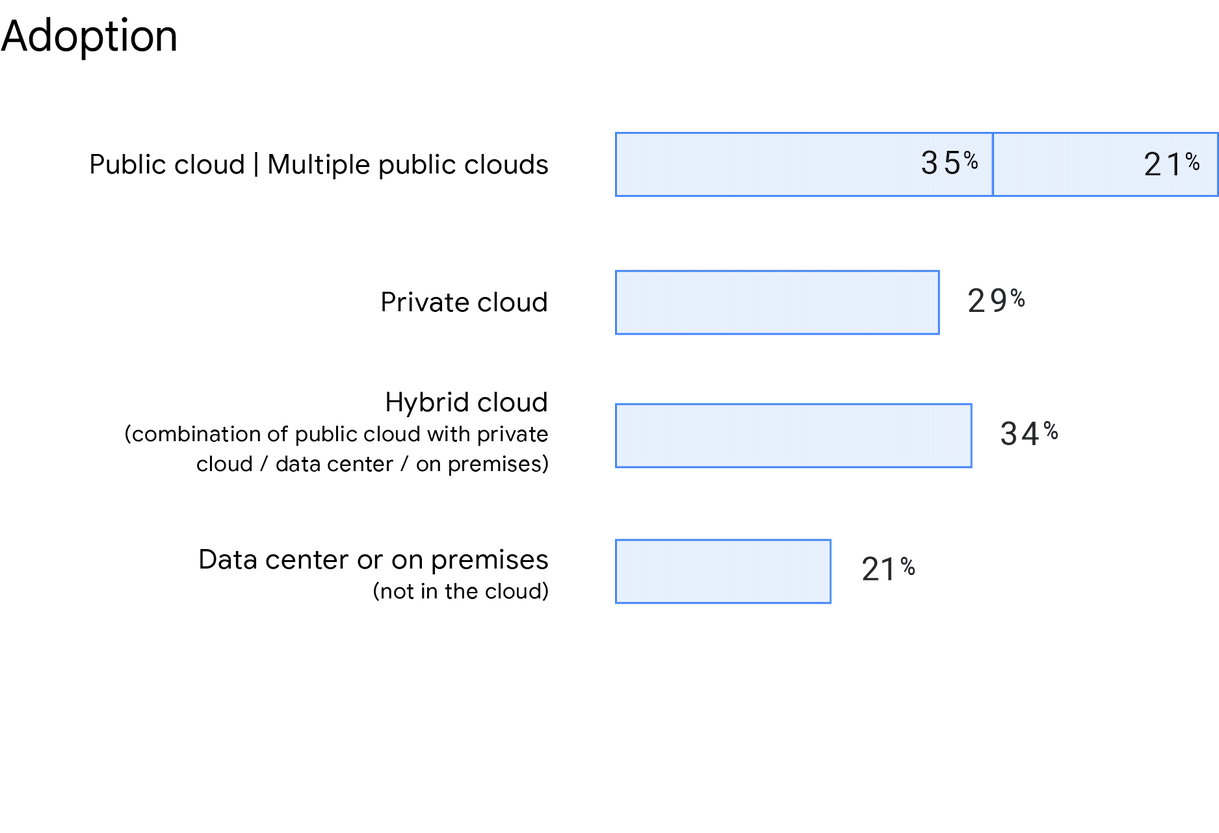
De manera coherente con Accelerate State of DevOps 2019, cada vez más organizaciones eligen soluciones de nubes híbridas y múltiples. En nuestra encuesta, se les preguntó a los encuestados dónde estaba alojado su servicio o aplicación principal, y el uso de la nube pública está en ascenso. El 56% de los encuestados indicó que usa una nube pública (incluidas varias nubes públicas), un aumento del 5% respecto de 2019. Este año, también preguntamos específicamente sobre el uso de múltiples nubes, y el 21% de los encuestados informó su implementación en múltiples nubes públicas. El 21% de los encuestados indicó que no usaba la nube y, en su lugar, utilizó un centro de datos o una solución local. Por último, el 34% de los encuestados informó que usa una nube híbrida y el 29% usa una nube privada.
Aceleración de los resultados empresariales con nubes híbridas y múltiples
Este año, observamos un crecimiento en el uso de nubes híbridas y múltiples, con un impacto significativo en los resultados que les interesan a las empresas. Los encuestados que usan nubes híbridas o múltiples tuvieron 1.6 veces más probabilidades de superar sus objetivos de rendimiento de la organización que aquellos que no lo hicieron. También observamos efectos fuertes en la SDO: los usuarios de nubes híbridas y múltiples tienen 1.4 veces más probabilidades de destacarse en términos de frecuencia de implementación, plazos de entrega de los cambios, tiempo de recuperación, tasa de errores de cambio y confiabilidad.
¿Por qué usar múltiples nubes?
De manera similar a nuestra evaluación de 2018, les pedimos a los encuestados que informaran sus motivos para aprovechar varios proveedores de servicios en la nube pública. En lugar de seleccionar todas las opciones que correspondan, este año pedimos a los encuestados que informaran su motivo principal para usar varios proveedores. Más de un cuarto (26%) de las organizaciones que participaron del estudio lo hacían para aprovechar los beneficios únicos de cada proveedor de servicios en la nube. Esto sugiere que, cuando los encuestados seleccionan un proveedor adicional, buscan una diferenciación entre su proveedor actual y las alternativas. La segunda razón más común para comenzar a utilizar múltiples nubes fue la disponibilidad (22%). Como era de esperarse, es 1.5 veces más probable que los encuestados que adoptaron varios proveedores de servicios en la nube cumplan o superen sus objetivos de confiabilidad.
Motivo principal por el que se usan varios proveedores
Aprovechar los beneficios únicos de cada proveedor | 26% |
Disponibilidad | 22% |
Recuperación ante desastres | 17% |
Cumplimiento legal | 13% |
Otro | 8% |
Táctica de negociación o requisito de adquisición | 8% |
Falta de confianza en un proveedor | 6% |
Aprovechar los beneficios únicos de cada proveedor
26%
Disponibilidad
22%
Recuperación ante desastres
17%
Cumplimiento legal
13%
Otro
8%
Táctica de negociación o requisito de adquisición
8%
Falta de confianza en un proveedor
6%
Cambios de comparativas
Cómo implementar la infraestructura de nube es importante
Históricamente, descubrimos que no todos los encuestados adoptan la nube de la misma manera. Esto genera variaciones en la eficacia de la adopción de la nube para generar resultados comerciales. A fin de abordar esta limitación, nos enfocamos en las características esenciales de la computación en la nube (según la define el Instituto Nacional de Estándares y Tecnología [NIST]) y las usamos como guía. Con la definición de Computación en la nube del NIST, investigamos el impacto de las prácticas esenciales en el rendimiento de la SDO y no solo la investigación del impacto de la adopción de la nube en la SDO.
Por tercera vez, descubrimos que lo que realmente importa es cómo los equipos implementan sus servicios en la nube, no solo que estén usando tecnologías de nube. Las empresas con un rendimiento de élite tenían 3.5 veces más probabilidades de cumplir con todas las características esenciales de la nube de NIST. Solo el 32% de los encuestados que indicaron que estaban usando la infraestructura de nube estuvieron de acuerdo o muy de acuerdo con que cumplían con las cinco características esenciales de la computación en la nube que definió el NIST, lo que representa un aumento del 3% con respecto a 2019. En general, el uso de las características de NIST de la computación en la nube aumentó de un 14% a un 19% y la elasticidad rápida fue la que mostró el mayor aumento.
Autoservicio a pedido
Los consumidores pueden aprovisionar los recursos de procesamiento según sea necesario, automáticamente, sin que se requiera ninguna interacción humana por parte del proveedor.
El 73% de los encuestados utilizaba el autoservicio a pedido, un aumento del 16% con respecto a 2019.
Acceso amplio a la red
Las funciones están disponibles de forma general y se puede acceder a ellas mediante varios clientes, como teléfonos celulares, tablets, laptops y estaciones de trabajo.
El 74% de los encuestados utilizó el acceso amplio a la red, lo que representa un aumento del 14% con respecto a 2019.
Agrupación de recursos
Los recursos del proveedor se agrupan en un modelo de múltiples usuarios, con recursos físicos y virtuales asignados de forma dinámica y reasignados a pedido. Por lo general, el cliente no tiene control directo sobre la ubicación exacta de los recursos proporcionados, pero puede especificar la ubicación en un nivel más alto de abstracción, como país, estado o centro de datos.
El 73% de los encuestados utilizó la agrupación de recursos, un aumento del 15% en comparación con 2019.
Elasticidad rápida
Las funciones se pueden aprovisionar de manera elástica y se lanzan para escalar rápidamente hacia afuera o hacia adentro con la demanda. Las capacidades del consumidor disponibles para el aprovisionamiento parecerían ser ilimitadas y se pueden asignar en cualquier cantidad y en cualquier momento.
El 77% de los encuestados utilizaron la elasticidad rápida, lo que implica un aumento del 18% con respecto a 2019.
Servicio medido
Los sistemas en la nube controlan y optimizan automáticamente el uso de recursos mediante la capacidad de medición en un nivel de abstracción adecuado para el tipo de servicio, como almacenamiento, procesamiento, ancho de banda y cuentas de usuario activas. El uso de los recursos se puede supervisar, controlar y notificar para que sea transparente.
El 78% de los encuestados utilizó el servicio medido, lo que implica un aumento del 16% respecto de 2019.
SRE y DevOps
Mientras la comunidad de DevOps surgía en las conferencias y conversaciones públicas, se formaba un movimiento similar en Google: ingeniería de confiabilidad de sitios (SRE). La SRE y otros enfoques similares, como la disciplina de ingeniería de producción de Facebook, adoptan muchos de los mismos objetivos y técnicas que motivan a DevOps. En 2016, la SRE se unió oficialmente al discurso público cuando se publicó el primer libro4 sobre ingeniería de confiabilidad de sitios. El movimiento creció desde entonces y, en la actualidad, una comunidad global de profesionales de SRE colabora en prácticas para operaciones técnicas.
Quizás inevitablemente, surgió la confusión. ¿Cuál es la diferencia entre SRE y DevOps? ¿Debo elegir una de las dos? ¿Cuál es mejor? En realidad, no hay conflicto. La SRE y DevOps son muy complementarias, y nuestra investigación demuestra su alineación. SRE es una disciplina de aprendizaje que prioriza la comunicación multifuncional y la seguridad psicológica, los mismos valores que resultan fundamentales para la cultura generativa orientada al rendimiento, típica de los equipos de DevOps de élite. A partir de sus principios fundamentales, la SRE proporciona técnicas prácticas, incluido el marco de trabajo de las métricas del indicador de nivel de servicio/objetivo de nivel de servicio (SLI/SLO). Así como el marco de trabajo de productos lean especifica cómo alcanzar los ciclos de comentarios de clientes rápidos respaldados por nuestra investigación, el marco de trabajo de SRE ofrece definición sobre prácticas y herramientas que pueden mejorar la capacidad de un equipo para mantener de forma coherente promesa a los usuarios.
En 2021, ampliamos nuestra consulta a las operaciones y ampliamos la experiencia de análisis de la disponibilidad de servicios a la categoría de confiabilidad más general. En la encuesta de este año, se agregaron varios elementos inspirados en las prácticas de SRE para evaluar el grado en el que los equipos hacen lo siguiente:
- Definir la confiabilidad en términos del comportamiento del usuario
- Usar el framework de métricas de SLI/SLO para priorizar el trabajo según los porcentajes de error aceptable
- Usar la automatización para reducir el trabajo manual y las alertas disruptivas
- Definir protocolos y simulacros de preparación para la respuesta ante incidentes
- Incorporar principios de confiabilidad a lo largo del ciclo de vida de la entrega de software (“desplazamiento a la izquierda en la confiabilidad”)
En el análisis de los resultados, descubrimos que los equipos que se destacan en estas prácticas operacionales modernas tienen 1.4 veces más probabilidades de informar un mejor rendimiento de la SDO y 1.8 veces más probabilidades de informar mejores resultados comerciales.
La mayoría de los equipos en nuestro estudio adoptaron las prácticas de SRE: el 52% de los encuestados informó el uso de estas prácticas en cierta medida, aunque la profundidad de la adopción varía sustancialmente entre los equipos. Los datos indican que el uso de estos métodos predice una mayor confiabilidad y un mayor rendimiento general de la SDO: la SRE impulsa el éxito de DevOps.
Además, descubrimos que un modelo de operaciones de responsabilidad compartida, que se refleja en el grado en que los desarrolladores y operadores están autorizados de forma conjunta para contribuir a la confiabilidad, también predice mejores resultados de confiabilidad.
Además de mejorar las medidas objetivas de rendimiento, la SRE mejora la experiencia laboral de los profesionales técnicos. Por lo general, las personas con una gran cantidad de tareas de operación son propensas al agotamiento, pero la SRE tiene un efecto positivo. Descubrimos que, cuanto más use un equipo las prácticas de SRE, menos probabilidades habrá de que sus miembros experimenten el agotamiento. La SRE también puede ayudar a optimizar los recursos: los equipos que cumplen sus objetivos de confiabilidad mediante la aplicación de las prácticas de SRE informan que dedican más tiempo a escribir código que los equipos que no practican la SRE.
Nuestra investigación revela que los equipos en cualquier nivel de rendimiento de SDO, desde el más bajo hasta la élite, probablemente perciban beneficios de un mayor uso de las prácticas de SRE. Cuanto mejor sea el rendimiento de un equipo, mayor es la probabilidad de que usen modos de operación modernos: los equipos de rendimiento de élite tienen un 210% más de probabilidades de informar el uso de prácticas de SRE equivalentes de bajo rendimiento. Sin embargo, incluso los equipos que operan en los niveles más altos pueden crecer: solo el 10% de los encuestados de élite indicaron que implementaron por completo todas las prácticas de SRE que investigamos. A medida que el rendimiento de la SDO sigue avanzando en las industrias, el enfoque de cada equipo con respecto a las operaciones es un impulsor fundamental de la mejora continua de DevOps.
____________________________
4. Betsy Beyer et al., eds., Site Reliability Engineering (O’Reilly Media, 2016).
____________________________
Documentación y seguridad
Documentación
Este año, vimos la calidad de la documentación interna (como manuales, documentos README o incluso comentarios de código) para los servicios y las aplicaciones en los que trabaja un equipo. Medimos la calidad de la documentación según la medida en la que se cumplen los siguientes requisitos:
- Ayuda a los lectores a lograr sus objetivos.
- Es preciso, está actualizado y es integral.
- Es fácil de encontrar, está bien organizado y es claro.5
Registrar y acceder a la información sobre los sistemas internos es una parte fundamental del trabajo técnico del equipo. Descubrimos que alrededor del 25% de los encuestados tienen documentación de buena calidad, y el impacto de este trabajo de documentación es claro: los equipos con documentos de mejor calidad tienen 2.4 veces más probabilidades de ver un mejor rendimiento de entrega de software y operaciones (SDO) Los equipos con una buena documentación entregan software de forma más rápida y confiable que aquellos con documentación deficiente. No es necesario que la documentación sea perfecta. Nuestra investigación demuestra que cualquier mejora en la calidad de la documentación tiene un impacto positivo y directo en el rendimiento.
El entorno tecnológico actual tiene sistemas cada vez más complejos, así como expertos y funciones especializadas para diferentes aspectos de estos sistemas. Desde la seguridad hasta las pruebas, la documentación es una forma clave de compartir conocimientos especializados y orientación tanto entre estos subequipos especializados como con el equipo en general.
Descubrimos que la calidad de la documentación predice el éxito de los equipos en la implementación de prácticas técnicas. A su vez, estas prácticas predicen las mejoras en las capacidades técnicas del sistema, como la observabilidad, las pruebas continuas y la automatización de implementaciones. Descubrimos que los equipos con documentación de calidad tienen las siguientes características:
- 3.8 veces más probabilidades de implementar prácticas de seguridad
- 2.4 veces más probabilidades de cumplir o superar sus objetivos de confiabilidad
- 3.5 veces más probabilidades de implementar prácticas de ingeniería de confiabilidad de sitios (SRE)
- 2.5 veces más probabilidades de aprovechar la nube al máximo
Cómo mejorar la calidad de la documentación
El trabajo técnico implica encontrar y usar información, pero la documentación de calidad se basa en que las personas escriban y mantengan el contenido. En 2019, nuestras investigaciones demostraron que el acceso a fuentes de información internas y externas respalda la productividad. La investigación de este año da un paso más allá para analizar la calidad de la documentación a la que se accede y las prácticas que afectan esa calidad.
Nuestra investigación muestra que las siguientes prácticas tienen un impacto positivo en la calidad de la documentación:
Documenta los casos de uso críticos para tus productos y servicios. Lo que documentas sobre un sistema es importante, y los casos de uso permiten que los lectores pongan la información y tus sistemas en funcionamiento.
Crea lineamientos claros para actualizar y editar documentación existente. Gran parte del trabajo de documentación es mantener el contenido existente. Cuando los miembros del equipo saben cómo realizar actualizaciones o quitar información imprecisa o desactualizada, el equipo puede mantener la calidad de la documentación, aunque el sistema cambie con el tiempo.
Define los propietarios Es más probable que los equipos con documentación de calidad definan claramente la propiedad de la documentación. La propiedad permite responsabilidades explícitas para escribir contenido nuevo y actualizar o verificar el contenido existente. Es más probable que los equipos con documentación de calidad indiquen que la documentación está escrita para todas las funciones principales de las aplicaciones en las que trabajan, y una propiedad clara ayuda a crear esta amplia cobertura.
Incluye la documentación como parte del proceso de desarrollo de software. Los equipos que crearon documentación y la actualizaron a medida que el sistema cambió tenían documentación de mejor calidad. Al igual que las pruebas, la creación y el mantenimiento de la documentación es una parte integral de un proceso de desarrollo de software de alto rendimiento.
Reconoce el trabajo de documentación a la hora de realizar evaluaciones de desempeño y dar ascensos. El reconocimiento se correlaciona con la calidad general de la documentación. Escribir y mantener la documentación es una parte central del trabajo de ingeniería de software, y tratarla como tal mejora su calidad.
Estos son algunos recursos que respaldan la calidad de la documentación:
- Capacitación sobre cómo escribir y mantener la documentación
- Pruebas automáticas para muestras de código o documentación incompleta
- Lineamientos, como guías de estilo de documentación y guías de escritura para un público global
La documentación es fundamental para implementar correctamente las capacidades de DevOps. La documentación de mayor calidad amplía los resultados de las inversiones en capacidades individuales de DevOps, como la seguridad, la confiabilidad y el aprovechamiento total de la nube. Implementar prácticas para respaldar la documentación de calidad da como resultado capacidades más sólidas en términos técnicos y un mejor rendimiento de SDO.
____________________________
5. Métricas de calidad que se basan en investigaciones existentes sobre documentación técnica, como las siguientes:
— Aghajani, E. et al. (2019). Software Documentation Issues Unveiled. Actas de la cuadragésimo primera Conferencia Internacional de Ingeniería de Software, 2019, de IEEE/ACM, 1199-1210. https://doi.org/10.1109/ICSE.2019.00122
— Plösch, R., Dautovic, A., y Saft, M. (2014). The Value of Software Documentation Quality. Actas de la Conferencia Internacional sobre Software de Calidad, 333-342. https://doi.org/10.1109/QSIC.2014.22
— Zhi, J. et al. (2015). Cost benefits and quality of software development documentation: A systematic mapping. Journal of Systems and Software, 99(C), 175-198. https://doi.org/10.1016/j.jss.2014.09.042
____________________________
Seguridad
[Desplazamiento a la izquierda] e integración en todo el proceso
A medida que los equipos de tecnología continúan acelerando y evolucionando, también lo hacen la cantidad y la sofisticación de las amenazas de seguridad. En 2020, se expusieron más de 22,000 millones de registros de información personal o datos empresariales confidenciales, según el Informe retrospectivo sobre el panorama de amenazas de 2020 de Tenable.6 La seguridad no puede ser algo secundario ni un último paso antes de la entrega; debe estar integrada en todo el proceso de desarrollo de software.
Para entregar software de manera segura, las prácticas de seguridad deben evolucionar más rápido que las técnicas que usan las entidades maliciosas. Durante los ataques de la cadena de suministro de software de SolarWinds y Codecov, en 2020, los hackers vulneraron el sistema de compilación de SolarWinds y la secuencia de comandos de carga de bash de Codecov7 a fin de incorporarse en la infraestructura de miles de clientes de esas empresas. Debido al impacto generalizado de estos ataques, la industria debe pasar de un enfoque preventivo a uno de diagnóstico, en el que los equipos de software deben suponer que sus sistemas ya están en peligro e incorporar la seguridad en su cadena de suministro.
De manera coherente con los informes anteriores, descubrimos que las organizaciones con rendimiento de élite se destacan en la implementación de prácticas de seguridad. Este año, las empresas con rendimiento de élite que cumplieron o superaron sus objetivos de confiabilidad tenían el doble de probabilidades de integrar la seguridad en su proceso de desarrollo de software. Esto sugiere que los equipos que aceleraron la entrega mientras mantenían sus estándares de confiabilidad encontraron una forma de integrar las verificaciones y prácticas de seguridad sin sacrificar su capacidad de entregar software con rapidez o confiabilidad.
Además de presentar un alto rendimiento en la entrega y las operaciones, los equipos que integran las prácticas de seguridad en todos sus procesos de desarrollo tienen 1.6 veces más probabilidades de cumplir o superar sus objetivos organizacionales. Los equipos de desarrollo que adoptan la seguridad ven valor significativo generado para la empresa.
____________________________
6. https://www.tenable.com/cyber-exposure/2020-threat-landscape-retrospective
7. https://www.cybersecuritydive.com/news/codecov-breach-solarwinds-software-supply-chain/598950/
____________________________
Cómo obtener los resultados correctos
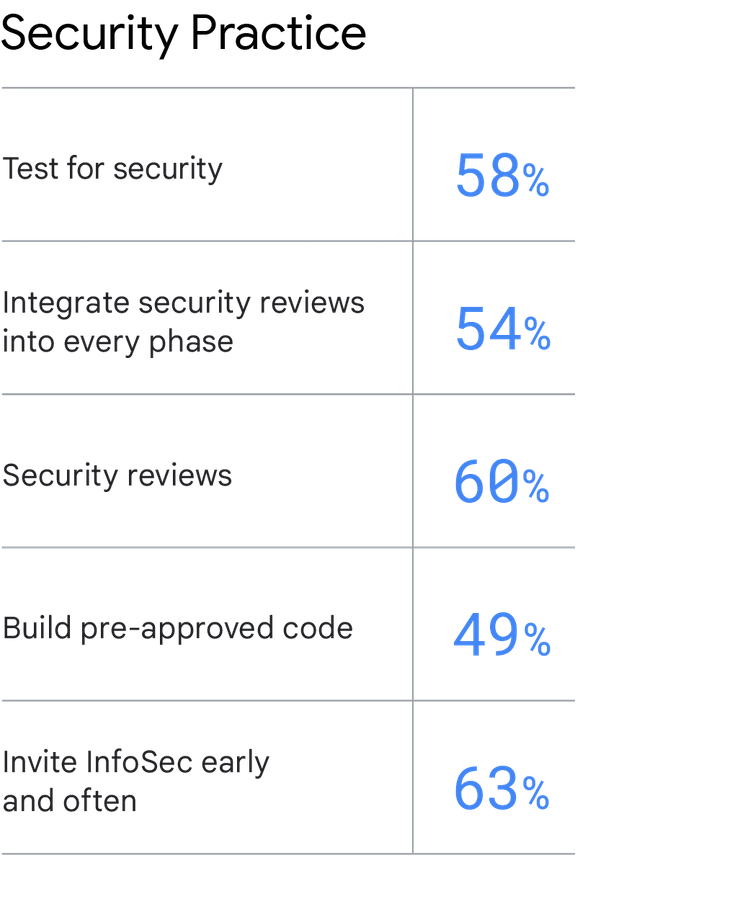
Es fácil hacer hincapié en la importancia de la seguridad y sugerir que los equipos deben priorizarla, pero para hacerlo, se requieren varios cambios de los métodos tradicionales de seguridad de la información. Aprovecha las siguientes prácticas para integrar la seguridad, mejorar la entrega de software y el rendimiento operativo, y mejorar el rendimiento de la organización:
Prueba la seguridad. Prueba los requisitos de seguridad como parte del proceso de prueba automatizado, incluidas las áreas en las que se debe usar el código aprobado con anterioridad.
Integra la revisión de seguridad en todas las fases. Integra la seguridad de la información (InfoSec) en el trabajo diario de todo el ciclo de vida de la entrega de software. Esto incluye que el equipo de InfoSec participe durante las fases de diseño y arquitectura de la aplicación, asista a demostraciones de software y proporcione comentarios durante las demostraciones.
Revisiones de seguridad. Realiza una revisión de seguridad de todas las funciones principales. Compila el código aprobado con anterioridad. Haz que el equipo de InfoSec compile bibliotecas, paquetes, cadenas de herramientas y procesos aprobados con anterioridad y que sean fáciles de usar para que los desarrolladores y operadores de TI los usen en su trabajo. Invita a InfoSec con anticipación y frecuencia. Incluye InfoSec durante la planificación y todas las fases posteriores del desarrollo de aplicaciones para que puedan detectar las debilidades relacionadas con la seguridad antes, lo que le da al equipo tiempo suficiente para solucionarlos.
Compila el código aprobado con anterioridad. Haz que el equipo de InfoSec compile bibliotecas, paquetes, cadenas de herramientas y procesos aprobados con anterioridad y que sean fáciles de usar para que los desarrolladores y operadores de TI los usen en su trabajo.
Invita a InfoSec con anticipación y frecuencia. Incluye InfoSec durante la planificación y todas las fases posteriores del desarrollo de aplicaciones para que puedan detectar las debilidades relacionadas con la seguridad antes, lo que le da al equipo tiempo suficiente para solucionarlos.
Como ya mencionamos, la documentación de alta calidad impulsa el éxito de una variedad de capacidades, y la seguridad no es la excepción. Descubrimos que los equipos con documentación de alta calidad tenían 3.8 veces más probabilidades de integrar la seguridad en todo su proceso de desarrollo. No todos los miembros de una organización tienen experiencia en criptografía. La experiencia de quienes lo hacen se comparte mejor en una organización mediante prácticas de seguridad documentadas.
Capacidades técnicas de DevOps
Nuestra investigación demuestra que las organizaciones que se someten a una transformación de DevOps adoptando la entrega continua tienen más probabilidades de tener procesos rentables, de alta calidad y bajo riesgo.
Específicamente, medimos las siguientes prácticas técnicas:
- Arquitectura con acoplamiento bajo
- Desarrollo basado en troncales
- Pruebas continuas
- Integración continua
- Uso de tecnologías de código abierto
- Prácticas de supervisión y observabilidad
- Administración de cambios en bases de datos
- Automatización de la implementación
Descubrimos que, si bien todas estas prácticas mejoran la entrega continua, la arquitectura con acoplamiento bajo y las pruebas continuas tienen el mayor impacto. Por ejemplo, este año descubrimos que las organizaciones con rendimiento de élite que cumplen sus objetivos de confiabilidad tienen tres veces más probabilidades de usar una arquitectura con acoplamiento bajo que sus equivalentes de bajo rendimiento.
Arquitectura con acoplamiento bajo
Nuestra investigación continúa demostrando que puedes mejorar el rendimiento de TI si trabajas para reducir las dependencias detalladas entre servicios y equipos. De hecho, este es uno de los predictores más fuertes de una entrega continua exitosa. Con una arquitectura con acoplamiento bajo, los equipos pueden escalar, fallar, realizar pruebas e implementar de forma independiente. Los equipos pueden moverse a su propio ritmo, trabajar en lotes más pequeños, acumular menos deudas técnicas y recuperarse más rápido de las fallas.
Integración continua y pruebas continuas
De manera similar a nuestros hallazgos de años anteriores, mostramos que las pruebas continuas son un predictor sólido de la entrega continua exitosa. Las empresas con un rendimiento de élite que cumplen sus objetivos de confiabilidad tienen 3.7 veces más probabilidades de aprovechar las pruebas continuas. Mediante la incorporación de pruebas tempranas y frecuentes durante el proceso de entrega, con verificadores que trabajan junto con los desarrolladores, los equipos pueden iterar y realizar cambios en su producto, servicio o aplicación con mayor rapidez. Puedes usar este ciclo de reacción para entregar valor a tus clientes y, a la vez, incorporar con facilidad prácticas como las pruebas automatizadas y la integración continua.
La integración continua también mejora la entrega continua. Las empresas con un rendimiento de élite que cumplen sus objetivos de confiabilidad tienen un 580% más de probabilidades de aprovechar la integración continua. En la integración continua, cada confirmación activa una compilación del software y ejecuta una serie de pruebas automatizadas que proporcionan comentarios en pocos minutos. Con la integración continua, se disminuye la coordinación manual y, a menudo, compleja, que se necesita para una integración exitosa.
La integración continua, como la define Kent Beck y la comunidad de programación extrema, donde se originó, también incluye la práctica del desarrollo basado en troncos y que se analiza a continuación.7
Desarrollo basado en troncales
Nuestra investigación demostró constantemente que las organizaciones de alto rendimiento tienen más probabilidades de implementar el desarrollo basado en troncos, en el que los desarrolladores trabajan en lotes pequeños y combinan su trabajo en un tronco compartido con frecuencia. De hecho, las organizaciones con un rendimiento de élite que cumplen sus objetivos de confiabilidad tienen 2.3 veces más probabilidades de usar el desarrollo basado en troncos. Las que tienen un rendimiento bajo tienen más probabilidades de usar ramas de larga duración y retrasar la combinación.
Es recomendable que los equipos combinen su trabajo al menos una vez al día (y es mejor que lo hagan varias veces al día). El desarrollo basado en troncos está estrechamente relacionado con la integración continua, por lo que debes implementar estas dos prácticas técnicas al mismo tiempo, ya que tienen más impacto cuando se usan en conjunto.
Automatización de la implementación
En entornos de trabajo ideales, las computadoras realizan tareas repetitivas mientras las personas se enfocan en resolver problemas. Implementar la automatización de implementaciones ayuda a tus equipos a acercarse a este objetivo.
Cuando trasladas el software de la prueba a la producción de forma automática, disminuyes el plazo de entrega gracias a que permite implementaciones más rápidas y eficientes. Además, reduces la probabilidad de errores de implementación, que son más comunes en las implementaciones manuales. Cuando tus equipos usan la automatización de implementaciones, reciben comentarios inmediatos, que pueden ayudarte a mejorar el servicio o producto a una velocidad mucho más rápida. Si bien no es necesario implementar simultáneamente las pruebas continuas, la integración continua y las implementaciones automáticas, es probable que observes mejoras mayores cuando usando estas tres prácticas juntas.
Administración de cambios en la base de datos
El seguimiento de los cambios a través del control de versión es una parte fundamental de la escritura y el mantenimiento del código, y para la administración de las bases de datos. Nuestra investigación demostró que las organizaciones de rendimiento de élite que cumplen con sus objetivos de confiabilidad tienen 3.4 veces más probabilidades de ejercer la administración de cambios en la base de datos en comparación con sus contrapartes de bajo rendimiento. Además, las claves para una administración exitosa de cambios en la base de datos son la colaboración, la comunicación y la transparencia en todos los equipos relevantes. Si bien puedes elegir entre diferentes enfoques específicos, te recomendamos que, cuando necesites realizar cambios en tu base de datos, los equipos se reúnan y revisen los cambios antes de actualizar la base de datos.
____________________________
8. Beck, K. (2000). Extreme programming explained: Embrace change. Addison-Wesley Professional
____________________________
Supervisión y observabilidad
Al igual que con años anteriores, descubrimos que las prácticas de supervisión y observabilidad admiten la entrega continua. Las organizaciones de rendimiento de élite que cumplen correctamente con sus objetivos de confiabilidad tienen 4.1 veces más probabilidades de tener soluciones que incorporen la observabilidad del estado general del sistema. Las prácticas de observabilidad brindan a tus equipos un mejor entendimiento de tus sistemas, lo que disminuye el tiempo que se tarda en identificar y solucionar problemas. Nuestra investigación también indica que los equipos con buenas prácticas de observabilidad pasan más tiempo programando. Una explicación posible de este hallazgo es que la implementación de las prácticas de observabilidad ayuda a que los desarrolladores dediquen menos tiempo a buscar causas de problemas y más tiempo a la solución de problemas y la programación.
Tecnologías de código abierto
Muchos desarrolladores ya aprovechan las tecnologías de código abierto, y su conocimiento de estas herramientas es una fortaleza para la organización. Una debilidad principal de las tecnologías de código cerrado es que limitan tu habilidad para transferir conocimientos hacia y desde la organización. Por ejemplo, no puedes contratar a alguien que ya esté familiarizado con las herramientas de tu organización y los desarrolladores no pueden transferir el conocimiento que acumularon a otras organizaciones. Por el contrario, la mayoría de las tecnologías de código abierto cuentan con una comunidad que los desarrolladores pueden usar para recibir asistencia. Las tecnologías de código abierto son más accesibles y personalizables, y tienen un costo relativamente bajo. Las empresas con un rendimiento de élite que cumplen sus objetivos de confiabilidad tienen 2.4 veces más probabilidades de aprovechar tecnologías de código abierto. Te recomendamos que comiences a usar más software de código abierto a medida que implementes la transformación de DevOps.
Para obtener más información sobre las capacidades técnicas de DevOps, consulta las capacidades de DORA en https://cloud.google.com/devops/capabilities.
COVID-19 y cultura
COVID-19
Este año, investigamos los factores que influyeron en el rendimiento de los equipos durante la pandemia del COVID‐19. Específicamente, ¿la pandemia del COVID‐19 afectó de forma negativa la entrega de software y el rendimiento operativo (SDO)? ¿Los equipos experimentan más agotamiento como resultado? Por último, ¿qué factores prometen mitigar el agotamiento?
En primer lugar, buscamos comprender el impacto que la pandemia tuvo en la entrega y el rendimiento operativo. Muchas organizaciones priorizaron la modernización para adaptarse a los cambios drásticos en el mercado (por ejemplo, el cambio de comprar de forma presencial a en línea). En el capítulo “¿Cómo calificamos comparativamente?”, analizamos cómo el rendimiento en la industria de software se aceleró considerablemente y continúa acelerándose. Los equipos con un rendimiento más alto ahora son la mayor parte de nuestro ejemplo, y los equipos de élite continúan elevando los estándares, implementando con más frecuencia y con tiempos de entrega más cortos, tiempos de recuperación más rápidos y mejores tasas de errores de cambio. De manera similar, un estudio de GitHub demostró un aumento en la actividad de los desarrolladores (es decir, envíos, solicitudes de extracción, solicitudes de extracción revisadas y problemas con comentarios por usuario9) hasta el año 2020. Sin duda, la industria siguió acelerándose a pesar de la pandemia (no debido a ella), pero es importante destacar que no observamos una tendencia a la baja en el rendimiento de la SDO durante este período terrible.
La pandemia cambió la forma en que trabajamos y, para muchos, cambió el lugar donde trabajamos. Por este motivo, analizamos el impacto del trabajo remoto como resultado de la pandemia. Descubrimos que el 89% de los encuestados trabajaron desde casa debido a la pandemia. Solo el 20% informó haber trabajado desde su casa antes de la pandemia. El cambio a un entorno de trabajo remoto tuvo consecuencias significativas en la forma en que desarrollamos software, administramos negocios y trabajamos en conjunto. Para muchas personas, trabajar desde casa impidió la posibilidad de colaborar en persona o conectarse mediante conversaciones espontáneas en un pasillo.
____________________________
9. https://octoverse.github.com/
____________________________
¿Qué redujo el agotamiento?
A pesar de esto, encontramos un factor que tuvo un gran impacto en el hecho de que un equipo tuviera o no problemas de agotamiento como resultado del trabajo remoto: la cultura. Los equipos con una cultura de equipo generativa, compuesta por personas que se sentían incluidas y que pertenecían a su equipo, tenían la mitad de probabilidades de experimentar agotamiento durante la pandemia. Este hallazgo refuerza la importancia de priorizar el equipo y la cultura. Los equipos que obtienen mejores resultados están preparados para afrontar períodos más complejos que ejerzan presión tanto sobre el equipo como sobre los individuos.
Cultura
En términos generales, la cultura es el factor de fondo interpersonal más importante en todas las organizaciones. Es todo lo que influye en las formas de pensar, sentir y actuar de los empleados en relación con la organización y con sus pares. Todas las organizaciones tienen su propia cultura única, y nuestros hallazgos demuestran que la cultura es uno de los principales impulsores del rendimiento organizacional y de TI. En concreto, nuestros análisis indican que una cultura generativa, medida con la tipología de culturas de organización de Westrum, y el sentido de pertenencia e inclusión de las personas en la organización, predice un mayor rendimiento en la entrega de software y las operaciones (SDO). Por ejemplo, descubrimos que las organizaciones con rendimiento de élite que cumplen sus objetivos de confiabilidad tienen 2.9 veces más probabilidades de tener una cultura de equipo generativa que sus contrapartes de bajo rendimiento. Del mismo modo, una cultura generativa predice un rendimiento organizacional más alto y tasas más bajas de agotamiento para los empleados. En resumen, la cultura es realmente importante. Afortunadamente, la cultura es fluida y multifacética, y siempre se encuentra en cambio constante, lo que la convierte en algo que puedes cambiar.
La ejecución exitosa de DevOps requiere que tu organización tenga equipos que trabajen de forma colaborativa y multifuncional. En 2018, descubrimos que los equipos de alto rendimiento tenían el doble de probabilidades de desarrollar y entregar software en un solo equipo multifuncional. Esto refuerza que la colaboración y la cooperación son fundamentales para el éxito de cualquier organización. Una pregunta clave es: ¿qué factores contribuyen a crear un entorno que fomenta y celebra la colaboración multifuncional?
Con los años, intentamos hacer que la construcción de la cultura sea tangible y proporcionar a la comunidad de DevOps una mejor comprensión del impacto de la cultura en el rendimiento organizativo y de TI. Comenzamos este viaje definiendo operativamente la cultura con la tipología de cultura organizacional de Westrum. Identificó tres tipos de organizaciones: orientadas al poder, orientadas a las reglas y orientadas al rendimiento. Usamos este marco de trabajo en nuestra propia investigación y descubrimos que una cultura organizacional orientada al rendimiento que optimiza el flujo de información, la confianza, la innovación y el uso compartido de riesgos predice el alto rendimiento de SDO.
A medida que evolucionamos nuestra comprensión de la cultura y de DevOps, trabajamos para ampliar nuestra definición inicial de cultura a fin de incluir otros factores psicosociales, como la seguridad psicológica. Las organizaciones de alto rendimiento son más propensas a tener una cultura que incentive a los empleados a tomar riesgos calculados y moderados sin temor a consecuencias negativas.
Pertenencia e inclusión
Dado el impacto coherentemente sólido de la cultura sobre el rendimiento, este año expandimos nuestro modelo para explorar si el sentido de pertenencia e inclusión de los empleados contribuye al efecto beneficioso de la cultura en el rendimiento.
Las investigaciones psicológicas han demostrado que las personas tienen una motivación inherente de formar y mantener relaciones sólidas y estables con los demás.10 Tenemos la motivación de conectarnos con otros y sentirnos aceptados en los distintos grupos que habitamos. Los sentimientos de pertenencia conducen a una amplia gama de resultados físicos y psicológicos favorables. Por ejemplo, las investigaciones indican que los sentimientos de pertenencia tienen un impacto positivo y motivan a un logro académico.11
Un componente de este sentido de conexión es la idea de que las personas deben sentirse cómodas trabajando en equipo y que se valoran y celebran sus experiencias y trasfondos únicos.12 Enfocarse en crear culturas inclusivas de pertenencia en organizaciones ayuda a crear un personal próspero, diverso y motivado.
Nuestros resultados indican que las organizaciones orientadas al rendimiento que valoran la inclusión y la pertenencia tienen más probabilidades de tener niveles de agotamiento más bajos en los empleados en comparación con las organizaciones con culturas organizacionales menos positivas.
Dada la evidencia que muestra cómo los factores psicosociales afectan el rendimiento de la SDO y los niveles de agotamiento entre los empleados, te recomendamos que, si buscas atravesar una transformación exitosa de DevOps, inviertas en abordar los problemas relacionados con la cultura como parte de tus iniciativas de transformación.
____________________________
10. Baumeister & Leary, 1995. The need to belong: Desire for interpersonal attachments as a fundamental human motivation. Psychological Bulletin, 117(3), 497–529. https://doi.org/10.1037/0033-2909.117.3.497
11. Walton et al., alrededor del 2012. Mere belonging: the power of social connections. Journal of Personality and Social Psychology, 102(3):513-32. https://doi.org/10.1037/a0025731
12. Mor Barak y Daya, 2014; Managing diversity: Toward a globally inclusive workplace. Sage. Shore, Cleveland, & Sanchez, 2018; Inclusive workplaces: A review and model, Human Resources Review. https://doi.org/10.1016/j.hrmr.2017.07.003
¿Quién respondió la encuesta?
Con siete años de investigación y más de 32,000 respuestas a encuestas realizadas por profesionales de la industria, el programa Accelerate State of DevOps 2021 presenta las prácticas de desarrollo de software y DevOps que hacen que los equipos y las organizaciones tengan más éxito.
Este año, 1,200 profesionales de una variedad de industrias de todo el mundo compartieron sus experiencias para ayudarnos a comprender los factores que impulsan un mayor rendimiento. Para resumir, la representación en las medidas demográficas y organizativas se mantuvo muy coherente.
Al igual que en años anteriores, recopilamos la información demográfica de cada encuestado. Las categorías incluyen género, discapacidad y grupos poco representados.
Datos demográficos y firmográficos
Este año, observamos una representación coherente con los informes anteriores en categorías organizativas, como el tamaño de la empresa, la industria y la región. Una vez más, más del 60% de los encuestados trabaja como ingenieros o administradores, y un tercio trabaja en la industria tecnológica. Además, observamos la representación de empresas de los sectores de servicios financieros, venta minorista, industria y fabricación.
____________________________
13. https://www.washingtongroup-disability.com/question-sets/wg-short-set-on-functioning-wg-ss/
____________________________
Sectores demográficos
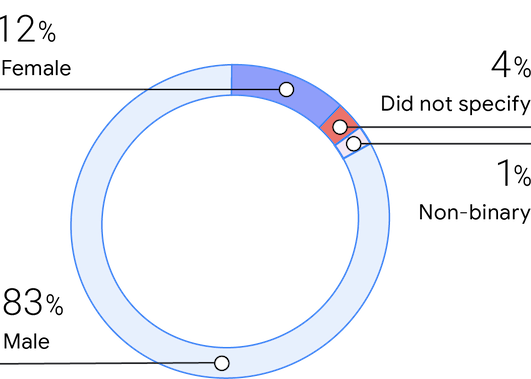
Género
De manera coherente con las encuestas anteriores, la muestra de este año incluye un 83% de hombres, un 12% de mujeres y un 1% de personas no binarias. Los encuestados afirmaron que las mujeres conforman alrededor del 25% de sus equipos, lo que representa un gran aumento con respecto a 2019 (16%) y una vuelta a los valores de 2018 (25%).
Discapacidad
La discapacidad se identifica en seis dimensiones según las indicaciones de la Lista breve de preguntas sobre discapacidad del Washington Group.13 Este es el tercer año que preguntamos sobre la discapacidad. El porcentaje de personas con discapacidad fue coherente con nuestro informe de 2019, con un 9%.
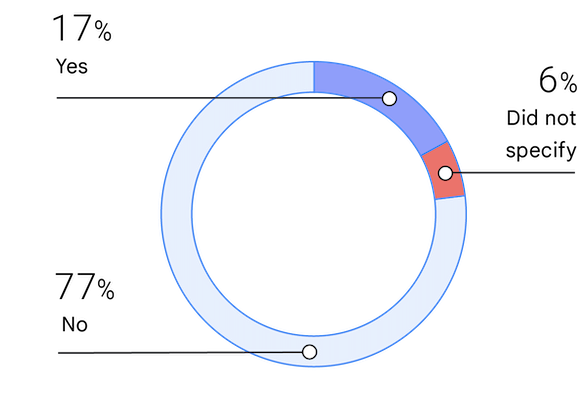
Grupos subrepresentados
La identificación como miembro de un grupo poco representado puede referirse al origen étnico, el género o alguna otra característica. Este es el cuarto año que preguntamos sobre la subrepresentación. El porcentaje de personas que se identifican como poco representadas aumentó un poco del 13,7% en 2019 al 17% en 2021.
Años de experiencia
Las personas que respondieron la encuesta de este año tienen mucha experiencia, y el 41% tiene al menos 16 años de experiencia. Más del 85% de los encuestados tenían al menos 6 años de experiencia.
Datos organizativos
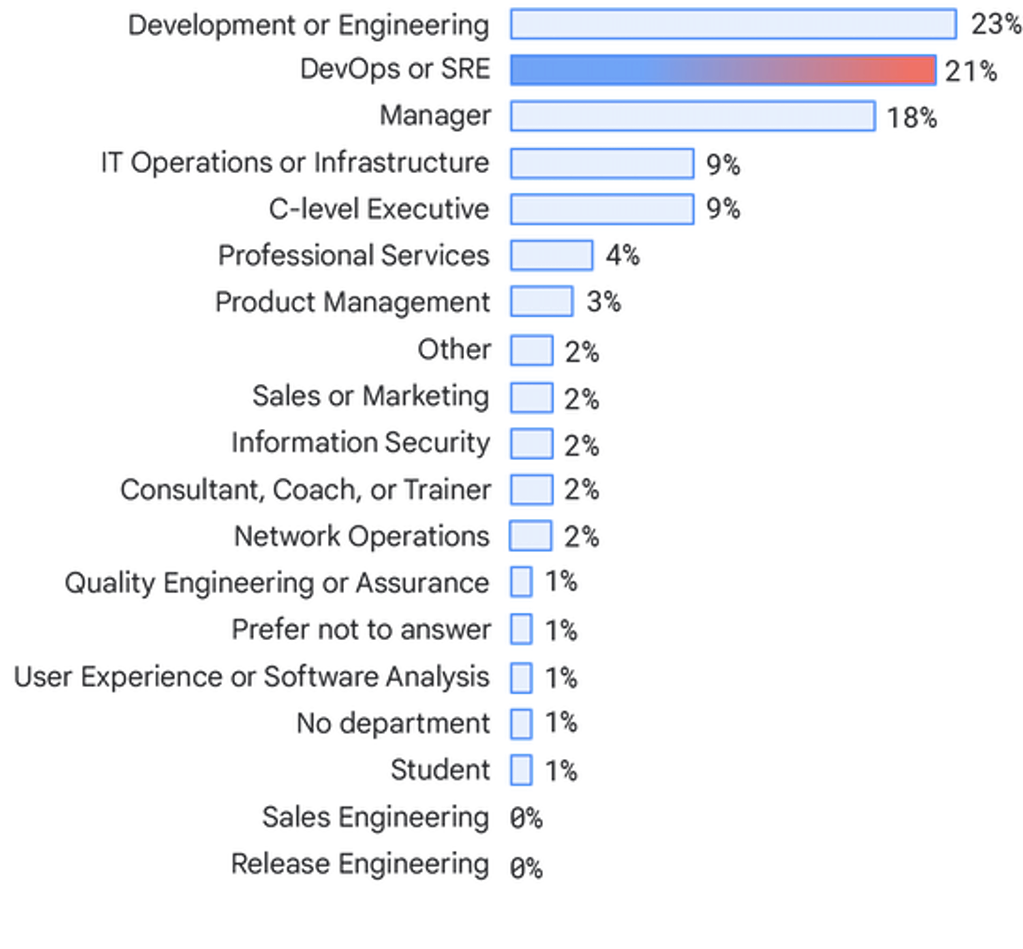
Departamentos
En general, las personas que responden trabajan en equipos de desarrollo o ingeniería (23%), equipos de DevOps o SRE (21%), gerencia (18%) y operaciones de TI o equipos de infraestructura (9%). Obtuvimos una disminución de la representación de los consultores (del 4% en 2019 al 2%) y un aumento en los ejecutivos de nivel directivo (del 4% en 2019 al 9%).
Sector
Al igual que en los informes anteriores de Accelerate State of DevOps, observamos que la mayoría de los encuestados trabajan en el sector de tecnología, seguido del de servicios financieros, venta minorista y otros.
Empleados
De manera coherente con los informes anteriores de Accelerate State of DevOps, los encuestados provienen de una variedad de tamaños de organización. El 22% de los encuestados se encuentra en empresas con más de 10,000 empleados y el 7% en empresas con entre 5,000 y 9,999 empleados. Otro 15% de los encuestados está en organizaciones con entre 2,000 y 4,999 empleados. También observamos una representación justa de los encuestados de organizaciones con entre 500 y 1,999 empleados (13%), entre 100 y 499 empleados (15%) y, finalmente, entre 20 y 99 empleados (15%).
Tamaño del equipo
Más de la mitad de los encuestados (el 62%) trabaja en equipos con 10 miembros o menos (el 28% para los equipos de 6 a 10 años, el 27% para equipos de 2 y 5 años y el 6% para equipos de una sola persona). Otro 19% trabaja en equipos con 11 a 20 miembros.
Regiones
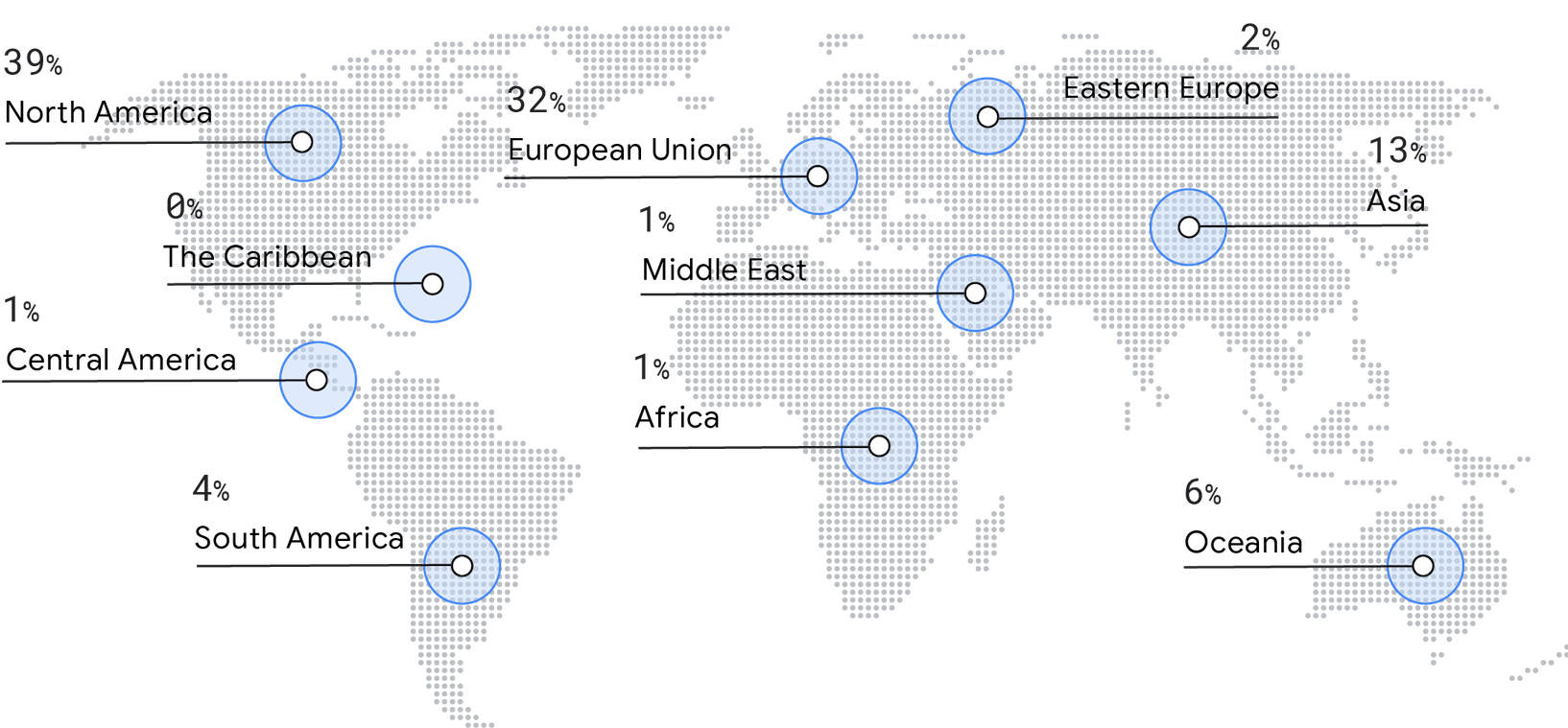
La encuesta de este año registró una disminución en la cantidad de respuestas de Norteamérica (el 50% en 2019 y el 39% en 2021). En cambio, observamos un aumento en la representación de Europa (del 29% en 2019 al 32% en 2021), Asia (del 9% en 2019 al 13% en 2021), Oceanía (del 4% en 2019 al 6% en 2021) y América del Sur (del 2% en 2019 al 4% en 2021).
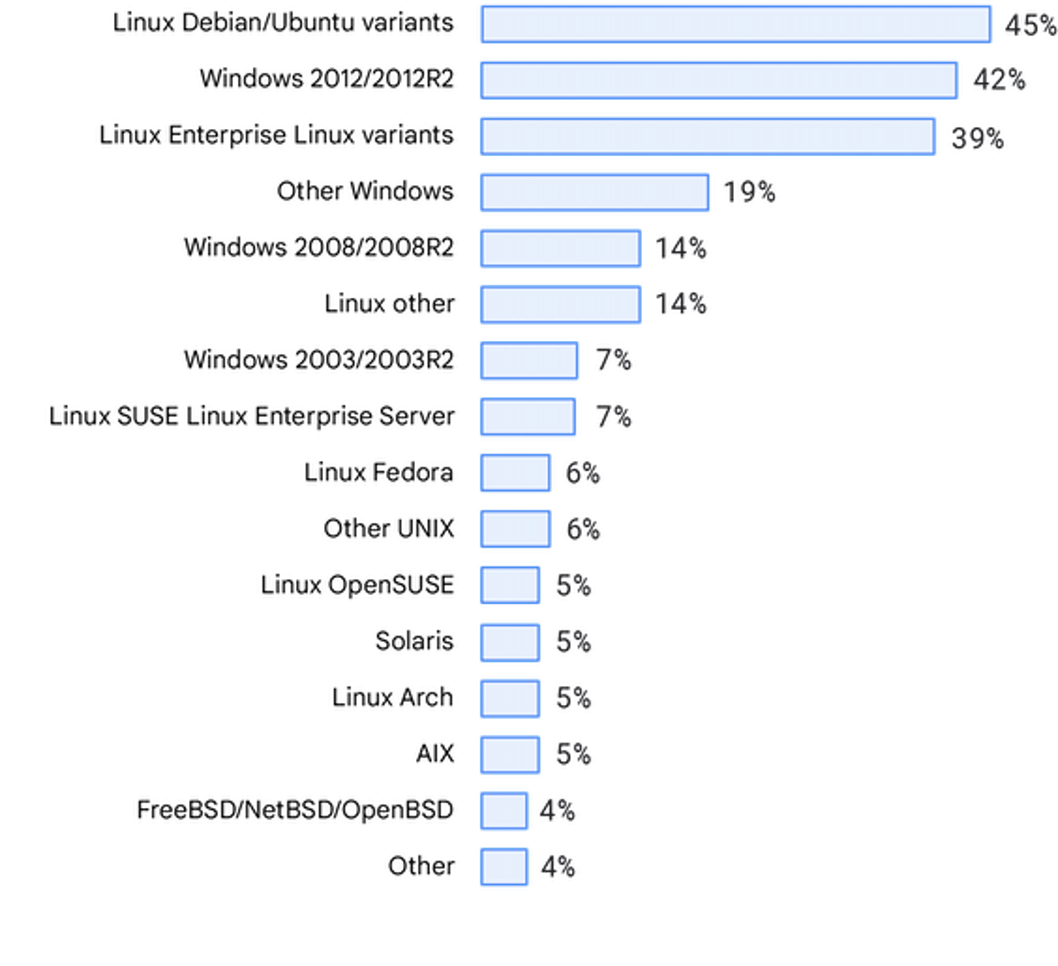
Sistemas operativos
La distribución de los sistemas operativos también fue coherente con los informes anteriores de State of DevOps. También reconocemos y agradecemos a los encuestados que nos ayudaron a llamar la atención sobre el hecho de que nuestra lista de sistemas operativos necesita actualizarse.
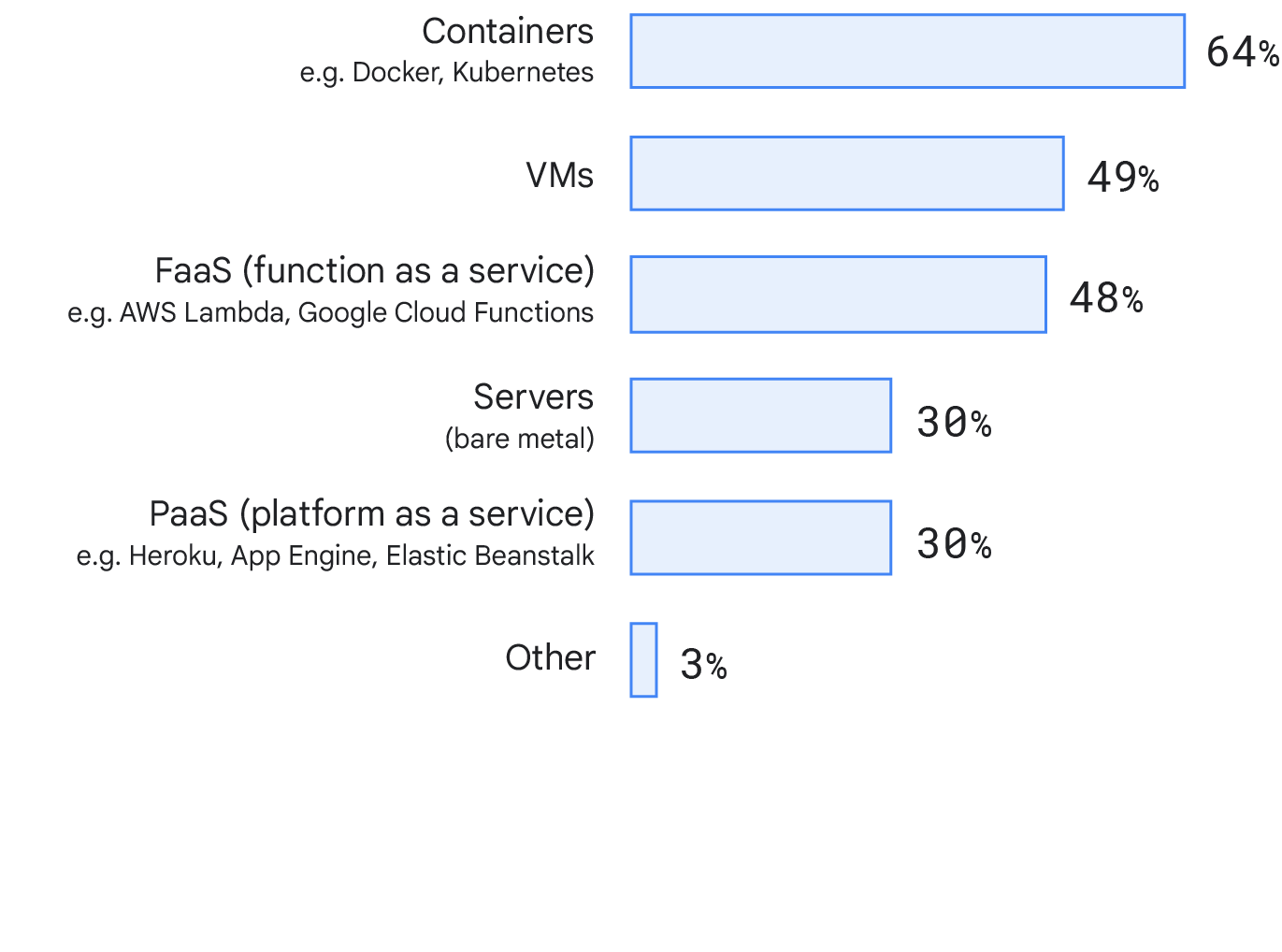
Destino de implementación
Este año, analizamos dónde se implementa el servicio o la aplicación principal en los que los encuestados trabajan. Para nuestra sorpresa, una gran proporción de los encuestados usa contenedores (el 64%), y el 48% usa máquinas virtuales (VMs). Esto podría reflejar un cambio en la industria hacia tecnologías de destino de implementación más modernas. Verificamos las diferencias entre los diferentes tamaños de empresas y no encontramos diferencias significativas entre los objetivos de implementación.
Reflexiones finales
Después de siete años de investigación, seguimos viendo los beneficios que DevOps brinda a las organizaciones. Cada año, las organizaciones continúan acelerando y mejorando.
Los equipos que adoptan sus principios y capacidades pueden entregar software con rapidez y confiabilidad, al mismo tiempo que generan valor directamente para la empresa. Este año, investigamos los efectos de las prácticas de SRE, una cadena de suministro segura de software y la documentación de calidad, y repasamos nuestra exploración de la posibilidad de aprovechar la nube. Cada área permite que las personas y los equipos sean más eficaces. Nos enfocamos en la importancia de estructurar soluciones que se adapten a las personas que usan estas capacidades, en lugar de intentar que las personas se adapten a la solución.
Agradecemos a todas las personas que participaron en la encuesta de este año, y esperamos que nuestra investigación los ayude a ti y a tu organización a crear mejores equipos y mejor software, al mismo tiempo que mantienen el equilibrio entre la vida laboral y personal.
Agradecimientos
Este informe fue posible gracias a una gran familia de colaboradores apasionados. El diseño de las preguntas de la encuesta, el análisis, la redacción, la edición y el diseño del informe son solo algunas de las formas en las que nuestros colegas nos ayudaron a llevar a cabo este gran esfuerzo. Los autores desean agradecer a todas estas personas por sus aportes y orientación en el informe de este año. Todos los agradecimientos se muestran en orden alfabético.

Autores
Dustin Smith
Dustin Smith es un psicólogo de factores humanos y gerente de investigación de la experiencia del usuario que forman parte del personal en Google. Trabaja en el proyecto DORA desde hace tres años. Durante los últimos siete años, ha estudiado cómo las personas se ven afectadas por los sistemas y entornos que las rodean en una variedad de contextos: ingeniería de software, videojuegos gratis, cuidado de la salud y ejército. En su investigación en Google, se identifican áreas en las que los desarrolladores de software pueden sentirse más felices y productivos durante el desarrollo. Ha trabajado en el proyecto DORA durante dos años. Dustin recibió su doctorado en psicología de factores humanos en la Universidad Estatal de Wichita.
Daniella Villalba
Daniella Villalba es investigadora de la experiencia del usuario dedicada al proyecto DORA. Se enfoca en comprender qué factores favorecen la satisfacción y productividad de los desarrolladores. Antes de Google, Daniella estudió los beneficios de la capacitación en meditación, los factores psicosociales que afectan las experiencias de los alumnos universitarios, la memoria de los testigos presenciales y las confesiones falsas. Obtuvo un doctorado en psicología experimental de Florida State University.
Michelle Irvine
Michelle Irvine es una escritora técnica de Google, donde trabaja para cerrar la brecha entre las herramientas para desarrolladores y las personas que las usan. Antes de Google, trabajó en edición educativa y como redactora técnica de software de simulación de física. Michelle tiene una licenciatura en física y una maestría en diseño de comunicación y retórica de la University of Waterloo.
Dave Stanke
Dave Stanke es ingeniero de relaciones con desarrolladores en Google, donde asesora a los clientes sobre prácticas para adoptar DevOps y SRE. Durante su carrera, ocupó una serie de cargos muy variada, que incluye los de director de tecnología para startups, gerente de producto, agente de asistencia al cliente, desarrollador de software, administrador de sistemas y diseñador gráfico. Tiene una maestría en administración de tecnología de Columbia University.
Nathen Harvey
Nathen Harvey es ingeniero de relaciones con desarrolladores en Google y desarrolló su carrera sobre la base de ayudar a los equipos a alcanzar su potencial mientras alinean la tecnología con los resultados comerciales. Nathen tuvo el privilegio de trabajar con algunos de los mejores equipos y comunidades de código abierto para ayudarlos a aplicar los principios y las prácticas de DevOps y SRE. Nathen coeditó y contribuyó a la publicación de “97 Things All Cloud Engineer Should Know” (97 cosas que todo ingeniero de la nube debe saber), O'Reilly, 2020.
Metodología
Diseño de la investigación
Este estudio emplea un diseño transversal basado en teoría. Este diseño basado en teoría se conoce como predictivo inferencial y es uno de los tipos más comunes que se realizan en la investigación empresarial y tecnológica en la actualidad. El diseño inferencial se usa cuando no es posible usar un diseño puramente experimental y se prefieren los experimentos de campo.
Población objetivo y muestreo
La población objetivo de esta encuesta eran profesionales y líderes que trabajaban en la tecnología y las transformaciones, o en campos estrechamente relacionados, y, sobre todo, profesionales con conocimientos de DevOps. La encuesta se promocionó mediante listas de direcciones de correo electrónico, promociones en línea, un panel en línea y redes sociales, y pedimos a las personas que compartieran la encuesta con sus redes (es decir, muestreo de bola de nieve).
Creación de construcciones latentes
Formulamos nuestras hipótesis y construcciones con construcciones validadas con anterioridad siempre que fuera posible. Desarrollamos construcciones nuevas basadas en teoría, definiciones y aportes de expertos. Luego, tomamos medidas adicionales para aclarar la intención a fin de garantizar que los datos recopilados en la encuesta tuvieran una alta probabilidad de ser confiables y válidos.14
Métodos de análisis estadístico
Análisis de clústeres: Usamos el análisis de clústeres para identificar nuestros perfiles de rendimiento de entrega de software según la frecuencia de implementación, el plazo de entrega, el tiempo de restablecimiento del servicio y la tasa de errores de cambio. Usamos un análisis de clases latentes15 porque no había razones teóricas ni industriales para tener una cantidad predeterminada de clústeres, y usamos el criterio de información bayesiano 16 para determinar la cantidad óptima de clústeres.
Modelo de medición: Antes de realizar el análisis, identificamos construcciones mediante el uso de un análisis de factores exploratorio con un análisis de componentes principales mediante la rotación Varimax.17 Confirmamos las estadísticas pruebas de confiabilidad y convergencia convergentes y diferentes mediante la correlación de varianza media extraída (AVE), el alfa de Cronbach18 y la confiabilidad compuesta.
Modelados de ecuación estructural: Probamos los modelos de ecuación estructural (SEM) con el análisis de los mínimos cuadrados parciales (PLS), que es un SEM basado en la correlación.19
________________________
14. Churchill Jr, G. A. “A paradigm for developing better measures of marketing constructs”, Journal of Marketing Research 16:1, (1979), 64–73.
15. Hagenaars, J. A., t McCutcheon, A. L. (Eds.). (2002). Applied latent class analysis. Cambridge University Press.
16. Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychological methods, 17(2), 228.
17. Straub, D., Boudreau, M. C., y Gefen, D. (2004). Validation guidelines for IS positivist research (Lineamientos de validación para la investigación positivista de IS). Communications of the Association for Information systems, 13(1), 24.
18. Nunnally, J.C. Psychometric Theory. New York: McGraw-Hill, 1978
19. Hair Jr, J. F., Hult, G. T. M. Ringle, C. M. y Sarstedt, M. (2021). “A primer on partial least squares structural equation modeling (PLS-SEM)”. Sage publications
Lecturas adicionales
Obtén más información sobre las capacidades de DevOps en https://cloud.google.com/devops/capabilities
Encuentra recursos sobre la ingeniería de confiabilidad de sitios (SRE) en
Realiza la Verificación rápida de DevOps:
https://www.devops-research.com/quickcheck.html
Explora el programa de investigación de DevOps:
https://www.devops-research.com/research.html
Descubre el programa de modernización de aplicaciones de Google Cloud:
https://cloud.google.com/solutions/camp
Lee el informe “The ROI of DevOps Transformation: How to quantify the impact of your modernization initiatives”:
https://cloud.google.com/resources/roi-of-devops-transformation-whitepaper
Consulta los informes State of DevOps anteriores:
State of DevOps 2014: https://services.google.com/fh/files/misc/state-of-devops-2014.pdf
State of DevOps 2015: https://services.google.com/fh/files/misc/state-of-devops-2015.pdf
State of DevOps 2016: https://services.google.com/fh/files/misc/state-of-devops-2016.pdf
State of DevOps 2017: https://services.google.com/fh/files/misc/state-of-devops-2017.pdf
Accelerate State of DevOps 2018: https://services.google.com/fh/files/misc/state-of-devops-2018.pdf
Accelerate State of DevOps 2019:
https://services.google.com/fh/files/misc/state-of-devops-2019.pdf
¿Todo listo para comenzar la transformación basada en datos?
Explora nuestro enfoque para compilar una nube de datos que optimice la velocidad, el escalamiento y la seguridad. Ver aquí











