Accelerate State of DevOps 2021
¿Qué diferencia a los equipos de software de mayor y menor rendimiento? En el informe del 2021, analizamos las prácticas que hacen que el envío de software y el rendimiento operativo sean todo un éxito, para que puedas comparar tu organización con la de los equipos con rendimiento de élite. Puedes utilizar esa información para mejorar los resultados clave, fomentar la innovación y desmarcarte de la competencia.
Resumen ejecutivo
El informe "Accelerate State of DevOps" de este año del equipo de investigación y evaluación de DevOps (DORA) de Google Cloud representa siete años de investigaciones y datos de más de 32.000 profesionales de todo el mundo.
En nuestro estudio, se analizan las capacidades y las prácticas que mejoran el rendimiento operativo, organizativo y del envío de software. Utilizamos técnicas estadísticas rigurosas para tratar de comprender las prácticas que generan excelencia en la implementación de tecnología y resultados de negocio excepcionales. Con este fin, ofrecemos información valiosa basada en datos sobre las formas más eficaces y eficientes de desarrollar y suministrar tecnología.
Nuestra investigación sigue demostrando que la excelencia en el envío de software y el rendimiento operativo impulsa el rendimiento organizativo en las transformaciones tecnológicas. Para que los equipos puedan compararse con el resto del sector, usamos un análisis de clústeres para crear categorías de rendimiento significativas (por ejemplo, bajo, medio, alto o élite). Una vez que tus equipos se hayan hecho una idea de su rendimiento actual en relación con el sector, puedes usar los hallazgos de nuestro análisis predictivo para orientar prácticas y capacidades que permitan mejorar los resultados clave y, con el tiempo, tu posición relativa. Este año destacamos la importancia de cumplir los objetivos de fiabilidad, integrar la seguridad en toda la cadena de suministro de software, crear documentación interna de calidad y aprovechar al máximo la nube. También investigamos si una cultura de equipo positiva puede mitigar los efectos del teletrabajo debido a la pandemia del COVID‐19.
Para lograr mejoras significativas, los equipos deben adoptar una filosofía de mejora continua. Usar los puntos de referencia para medir tu estado actual, identificar las restricciones según las funciones investigadas por el estudio y experimentar con mejoras para reducir dichas restricciones. La experimentación implica una combinación de victorias y fracasos, pero, en ambos casos, los equipos pueden adoptar medidas significativas como resultado de las lecciones aprendidas.
Principales conclusiones
Las empresas con mejor rendimiento están creciendo y siguen subiendo el listón.
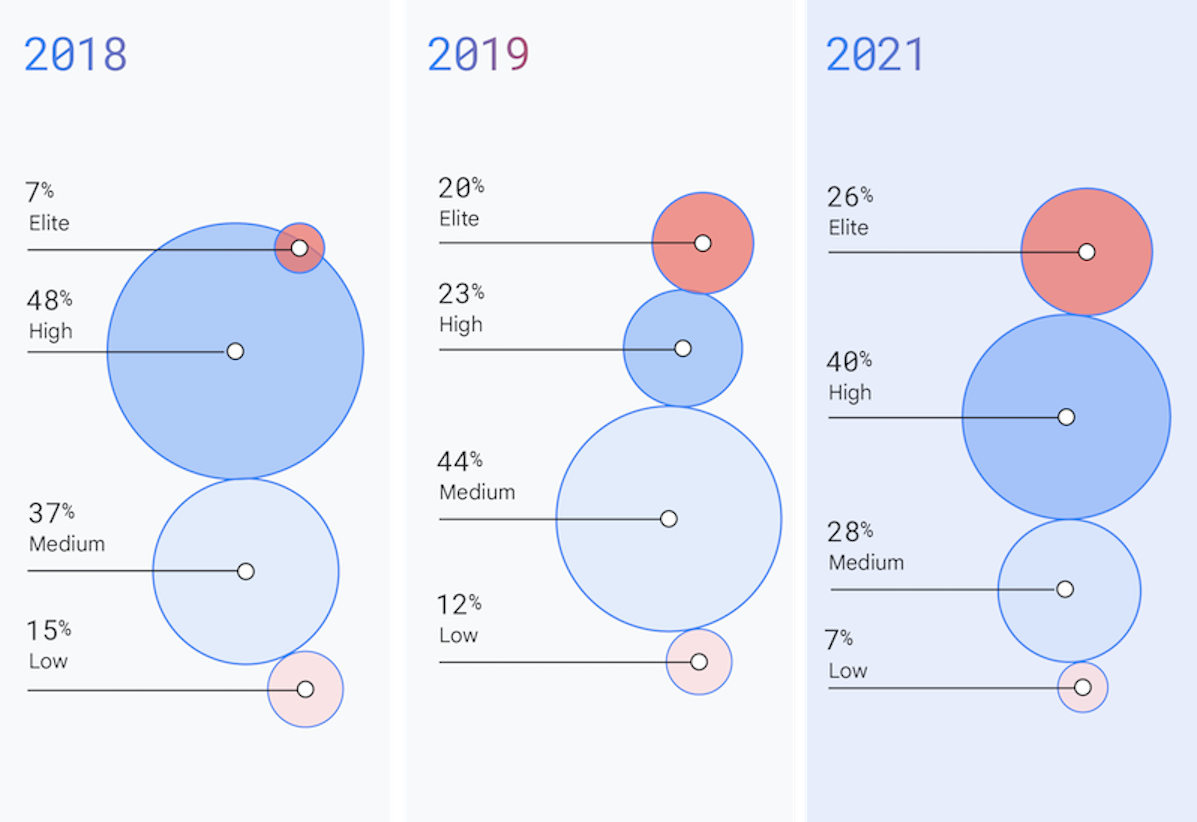
Los equipos de élite son actualmente el 26 % de los equipos de nuestro estudio, y han reducido los plazos de entrega de los cambios en la fase de producción. El sector sigue acelerando, y los equipos consiguen ventajas significativas al hacerlo.
SRE y DevOps son filosofías complementarias
Los equipos que aprovechan las prácticas operativas modernas que describen nuestros amigos de Site Reliability Engineering (SRE) afirman obtener un rendimiento operativo más alto. Los equipos que dan prioridad a la entrega y a la excelencia operativa consiguen los mejores resultados organizativos.
Cada vez más equipos aprovechan la nube para disfrutar de ventajas significativas.
Los equipos siguen transfiriendo cargas de trabajo a la nube, y los que aprovechan las cinco capacidades de la nube consiguen un aumento del rendimiento de envío de software y de operaciones (SDO), así como del rendimiento organizativo. Además, la adopción de entornos multinube está en auge para que los equipos puedan aprovechar las funciones únicas de cada proveedor.
Una cadena de suministro de software segura es esencial e impulsa el rendimiento.
A raíz del considerable aumento de los ataques maliciosos en los últimos años, las organizaciones deben sustituir las prácticas reactivas por medidas proactivas y de diagnóstico. Los equipos que integran prácticas de seguridad en toda su cadena de suministro suministran software de manera rápida, fiable y segura.
Una buena documentación es esencial para implementar funciones de DevOps.
Por primera vez, medimos la calidad de la documentación interna y las prácticas que contribuyen a conseguir esta calidad. Los equipos que cuentan con documentación de alta calidad son más eficientes a la hora de implementar prácticas técnicas y lograr un mejor rendimiento.
Una cultura de equipo positiva ayuda a hacer frente a la fatiga en situaciones difíciles.
La cultura de equipo marca una gran diferencia en la capacidad de un equipo de suministrar software y cumplir o superar sus objetivos organizativos. Los equipos inclusivos con una cultura generativa1,2 experimentaron menos agotamiento durante la pandemia del COVID-19.
____________________________
1. En la cultura organizativa de la tipología de Westrum, una cultura de equipo generativa hace referencia a los equipos que son muy cooperativos, que eliminan los silos, que convierten los fallos en oportunidades y que comparten el riesgo de tomar decisiones.
2. Westrum, R. (2004). "A typology of organizational cultures." BMJ Quality & Safety, 13(suppl 2), ii22-ii27.
¿Cómo lo estamos haciendo?
¿Tienes curiosidad por comparar tu equipo con el del resto de profesionales del sector? En esta sección se incluye la evaluación comparativa más reciente del rendimiento de DevOps.
Examinamos cómo los equipos desarrollan, entregan y operan los sistemas de software y, a continuación, segmentan a los encuestados en cuatro grupos de rendimiento: élite, alto, medio y bajo. Al comparar el rendimiento de tu equipo con el de cada grupo, puedes ver en qué punto te encuentras en el contexto de los resultados contenidos en este informe.
Rendimiento del envío de software y rendimiento operativo
Para satisfacer las necesidades de un sector en constante evolución, las organizaciones deben entregar y operar software de forma rápida y fiable. Cuanto más rápido puedan cambiar el software los equipos, antes podrás ofrecer valor a los clientes, realizar experimentos y recibir comentarios valiosos. Durante siete años de recopilación e investigación de datos, hemos desarrollado y validado cuatro métricas que miden el rendimiento del envío de software. Desde el 2018, hemos incluido una quinta métrica para registrar las funciones operativas.
Los equipos que destacan en las cinco métricas presentan un rendimiento organizativo excepcional. Estas cinco métricas se denominan rendimiento del envío de software y operaciones (SDO). Ten en cuenta que estas métricas se centran en los resultados a nivel del sistema, lo que ayuda a evitar los errores habituales de las métricas de software, como enfrentar funciones entre sí y hacer optimizaciones locales en detrimento de los resultados generales.
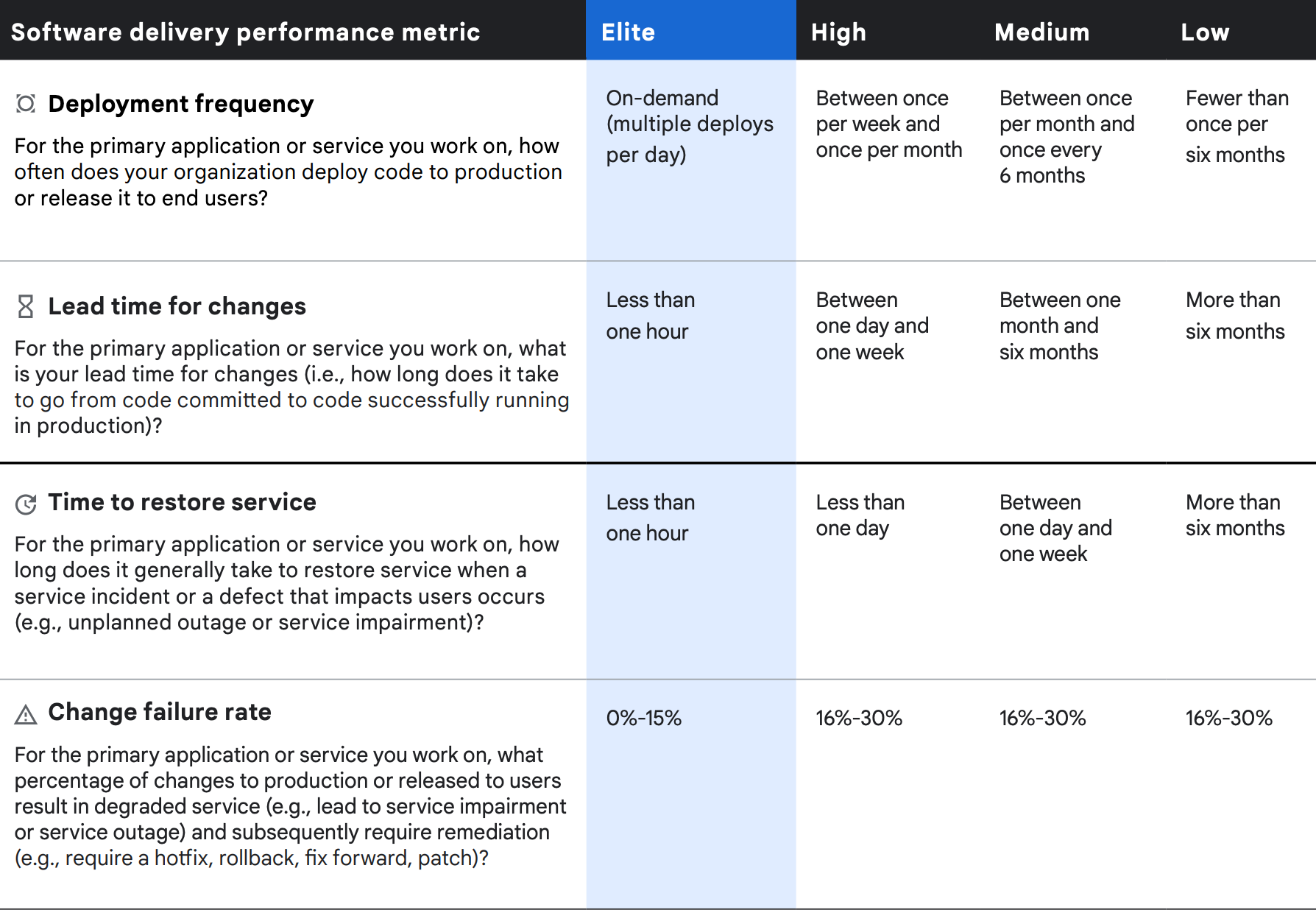
Cuatro métricas de rendimiento de la entrega
En términos de rendimiento y estabilidad, se pueden considerar cuatro métricas de rendimiento del envío de software. Medimos el rendimiento mediante el tiempo de entrega de los cambios de código (es decir, el tiempo que transcurre desde la confirmación del código hasta la publicación en producción) y la frecuencia de despliegue. Medimos la estabilidad usando el tiempo para restaurar un servicio después de un incidente y la tasa de fallos de cambios.
De nuevo, el análisis de clústeres de las cuatro métricas de envío de software muestra cuatro perfiles de rendimiento distintos (élite, alto, medio y bajo), con diferencias estadísticamente significativas en las medidas de rendimiento y estabilidad entre ellos. Como en años anteriores, las organizaciones con el máximo rendimiento tienen resultados considerablemente mejores en las cuatro medidas, y las organizaciones con bajo rendimiento presentan resultados peores en todas las áreas.
La quinta métrica: desde la disponibilidad hasta la fiabilidad
La quinta métrica representa el rendimiento operativo y mide las prácticas operativas modernas. La métrica principal de rendimiento operativo es la fiabilidad, que es el grado en el que un equipo puede mantener sus promesas y declaraciones acerca del software que opera. Históricamente, hemos medido la disponibilidad en lugar de la fiabilidad; sin embargo, dado que la disponibilidad es un enfoque específico de la ingeniería de fiabilidad, hemos ampliado nuestra medición a la fiabilidad de forma que la disponibilidad, la latencia, el rendimiento y la escalabilidad tengan una mayor representación. En concreto, pedimos a los encuestados que evaluaran su capacidad para cumplir o superar sus objetivos de fiabilidad. Hemos observado que los equipos con diversos grados de rendimiento de entrega obtienen mejores resultados cuando también priorizan el rendimiento operativo.
Al igual que en informes anteriores, hemos comparado los equipos de élite con los de bajo rendimiento para ilustrar el impacto de funciones concretas. No obstante, este año queríamos tener en cuenta el impacto de los resultados operativos. En todas las categorías de rendimiento de entrega (de bajo a élite), los equipos que dieron prioridad a los objetivos de fiabilidad o los superaron obtuvieron grandes resultados en varios resultados.
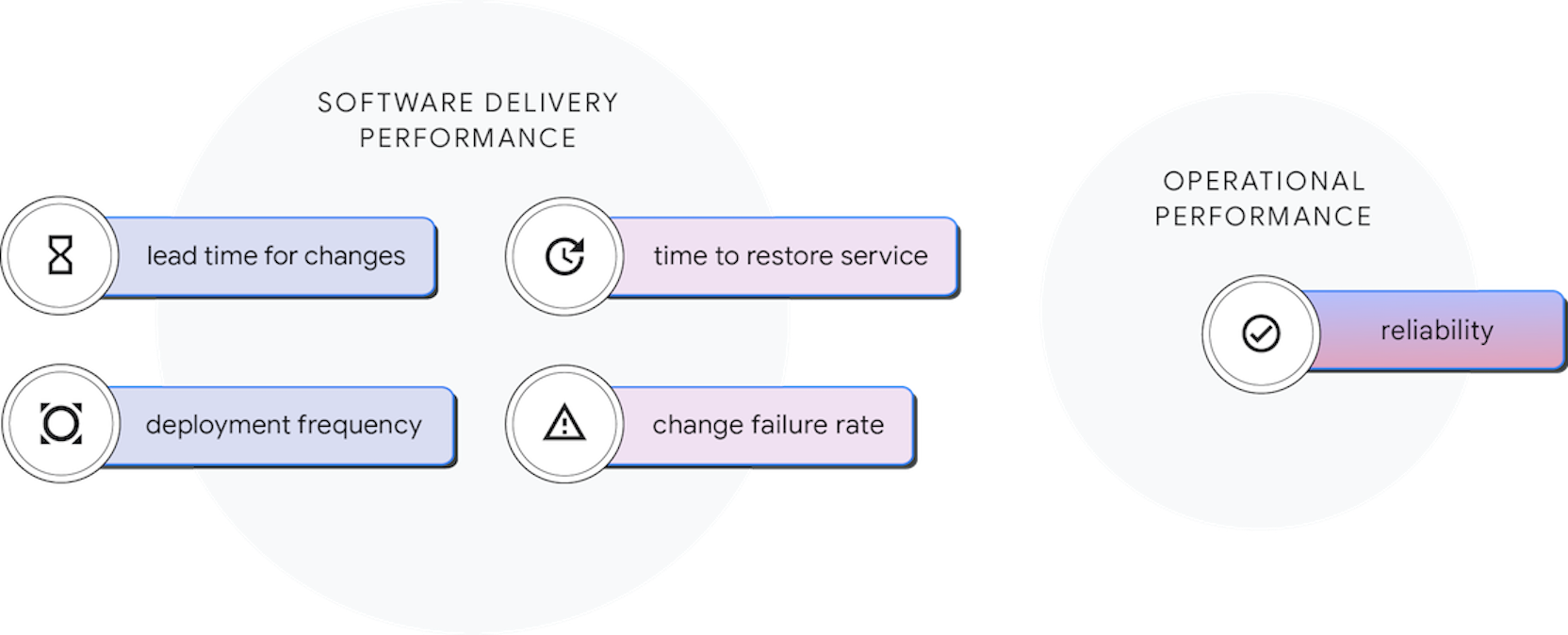
El sector sigue acelerando
Cada año seguimos viendo cómo evoluciona el sector y aceleramos la capacidad de suministrar software con más velocidad y mejor estabilidad. Por primera vez, las empresas de rendimiento alto y élite son dos tercios de las encuestadas. Además, los equipos con rendimiento de élite de este año han vuelto a subir el listón, disminuyendo su plazo de entrega de los cambios en comparación con las evaluaciones anteriores (por ejemplo, han pasado de menos de un día en el 2019 a menos de una hora en el 2021). Además, por primera vez, solo los equipos con rendimiento de élite han minimizado su tasa de errores de cambio en comparación con años anteriores, cuando los equipos de rendimiento alto y medio podían hacer lo mismo.
Rendimiento y estabilidad
Rendimiento
Frecuencia de despliegue
Al igual que todos los años, el grupo de élite afirmó que suele desplegar bajo demanda y hacer varios despliegues al día. En cambio, los equipos de bajo rendimiento indicaron que habían hecho despliegues menos de una vez cada seis meses (menos de dos al año), lo que supone, de nuevo, una disminución en el rendimiento en comparación con el año 2019. Las cifras de despliegue anuales normalizadas oscilan entre los 1460 despliegues al año (calculados como 4 despliegues al día por 365 días) para los equipos con el máximo rendimiento y 1,5 despliegues al año para los equipos de bajo rendimiento (media de dos despliegues y un despliegue). Este análisis calcula que los equipos con un rendimiento de élite despliegan código 973 veces más a menudo que los que tienen un rendimiento bajo.
Plazo de entrega de los cambios
Desde el 2019, los equipos con un rendimiento de élite afirman que los plazos de entrega de los cambios son inferiores a una hora; el plazo de entrega del cambio se mide como el tiempo que pasa desde que se confirma el código hasta que se implementa correctamente en la fase de producción. Esto supone un aumento del rendimiento en comparación con el 2019, en el que los equipos con mayor rendimiento tenían plazos de entrega de cambios inferiores a un día. A diferencia de los equipos con rendimiento de élite, los que tenían un rendimiento bajo necesitaban plazos de entrega superiores a los seis meses. Con plazos de entrega de una hora para los equipos con rendimiento de élite (una estimación conservadora en el extremo más alto de "menos de una hora") y 6570 horas para los equipos de bajo rendimiento, calculados tomando la media de 8760 horas por año y 4380 horas en 6 meses, el grupo de élite tiene plazos de entrega de cambios 6570 veces más rápidos que los equipos de bajo rendimiento.
Estabilidad
Tiempo para restaurar el servicio
El grupo con rendimiento de élite presentó un tiempo para restaurar el servicio inferior a una hora, mientras que los que equipos de bajo rendimiento registraron más de seis meses. Para hacer este cálculo, hemos elegido períodos conservadores: una hora para los equipos de alto rendimiento, y una media de un año (8760 horas) y seis meses (4380 horas) para los que de bajo rendimiento. Basándose en estas cifras, los equipos con rendimiento de élite presentan un tiempo para restaurar el servicio 6570 veces más rápido que los que tienen un rendimiento bajo. El rendimiento del tiempo para restaurar el servicio no varió en los equipos con rendimiento de élite y, en comparación con el 2019, aumentó el de los equipos de bajo rendimiento.
Índice de fallos por cambios
Los equipos con rendimiento de élite presentaron un porcentaje de fallos en los cambios de entre un 0 y un 15 %, mientras que los de rendimiento bajo experimentaron tasas de fallos de cambios del 16 al 30 %. La media entre estos dos intervalos muestra una tasa de fallos de cambios del 7,5 % en los equipos con rendimiento de élite y del 23 % en los de bajo rendimiento. La tasa de fallos de cambios de los equipos con rendimiento de élite es tres veces mejor que la de los equipos de bajo rendimiento. Este año, las tasas de fallos de cambios no variaron para los equipos con rendimiento de élite, y mejoraron para las de bajo rendimiento en comparación con el 2019, pero empeoraron para los grupos intermedios.
Máximo rendimiento
Al comparar el grupo con rendimiento de élite con el de bajo rendimiento, observamos que el de élite presenta:
- Despliegues de código 973 veces más frecuentes
- Un plazo de entrega 6570 veces más rápido desde la confirmación hasta el despliegue
- Tasa de fallos de cambios 3 veces menor (los cambios tienen 1/3 menos de probabilidades de fallar)
- Un tiempo de recuperación frente a incidentes 6570 veces más rápido
¿Cómo podemos mejorar?
¿Cómo podemos mejorar el rendimiento de SDO y organizativo? Nuestra investigación proporciona orientación basada en pruebas para ayudarte a centrarte en las funciones que impulsan el rendimiento.
En el informe de este año, hemos examinado el impacto de la nube, las prácticas de SRE, la seguridad, las prácticas técnicas y la cultura. En esta sección, presentamos cada una de estas funciones y observamos su impacto en una serie de resultados. Para los que ya conoces los modelos de investigación del estado de DevOps de DORA, hemos creado un recurso online que contiene el modelo de este año y todos los modelos anteriores.3
____________________________
3. https://devops-research.com/models.htm
____________________________
Cloud
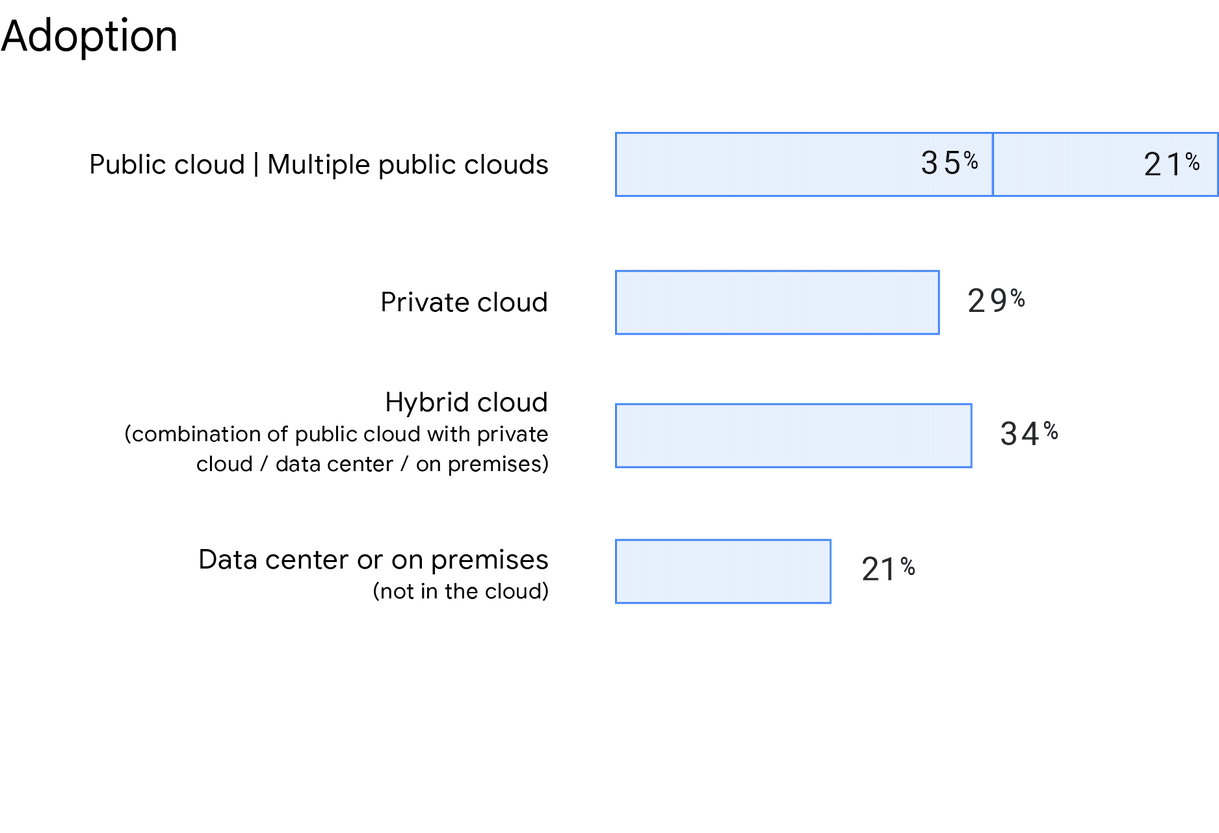
De acuerdo con Accelerate State of DevOps 2019, cada vez son más las organizaciones que eligen soluciones de nube híbrida y multinube. En nuestra encuesta, se preguntó a los encuestados dónde se alojaba su aplicación o servicio principal, y el uso de la nube pública va en aumento. El 56 % de los encuestados indicaron haber utilizado una nube pública (incluidas varias nubes públicas), lo que supone un aumento del 5 % con respecto al 2019. Este año también preguntamos específicamente sobre el uso de la multinube, y el 21 % de los encuestados afirmaron que estaban desplegando a varias nubes públicas. El 21 % de los encuestados indicaron que no utilizaban la nube y, en su lugar, usaban un centro de datos o una solución on-premise. Por último, el 34 % de los encuestados afirma que usa una nube híbrida y el 29 % que utiliza una nube privada.
Acelerar los resultados empresariales con entornos híbridos y multinube
Este año, observamos un aumento del uso de entornos híbridos y multinube, y un impacto significativo en los resultados que interesan a las empresas. Los encuestados que usan entornos híbridos o multinube tienen 1,6 veces más probabilidades de superar sus objetivos de rendimiento organizativos que los que no los usan. También observamos importantes efectos en las SDO, ya que los usuarios de entornos híbridos y multinube tienen 1,4 veces más probabilidades de obtener excelentes resultados en cuanto a frecuencia de despliegue, plazo de entrega de los cambios, tiempo de recuperación, tasa de fallos y fiabilidad.
Ventajas de los entornos multinube
Al igual que hicimos con la evaluación del 2018, pedimos a los encuestados que explicaran sus motivos para usar varios proveedores de nube pública. En lugar de seleccionar todas las opciones que correspondan, este año pedimos a los encuestados que indicaran su principal motivo para usar varios proveedores. Más de un cuarto de los encuestados (26 %) lo hizo para aprovechar las ventajas únicas de cada proveedor de servicios en la nube. Esto indica que, cuando los encuestados seleccionan un proveedor adicional, buscan la diferenciación entre su proveedor actual y las alternativas. La segunda causa más habitual de pasarse a la nube multinube era la disponibilidad (22 %). No es de extrañar que los encuestados que han adoptado varios proveedores de nube tengan 1,5 veces más probabilidades de cumplir o superar sus objetivos de fiabilidad.
Principal motivo para utilizar varios proveedores
Aprovechar las ventajas únicas que ofrece cada proveedor | 26 % |
Disponibilidad | 22 % |
Recuperación tras fallos | 17 % |
Cumplimiento de los requisitos legales | 13 % |
Otro | 8 % |
Requisito de táctica o aprovisionamiento de negociación | 8 % |
Falta de confianza en un proveedor | 6 % |
Aprovechar las ventajas únicas que ofrece cada proveedor
26 %
Disponibilidad
22 %
Recuperación tras fallos
17 %
Cumplimiento de los requisitos legales
13 %
Otro
8 %
Requisito de táctica o aprovisionamiento de negociación
8 %
Falta de confianza en un proveedor
6 %
Cambios en las comparativas
La forma de implementar la infraestructura en la nube es importante
Tradicionalmente, hemos observado que no todos los encuestados adoptan la nube de la misma forma. Esto conlleva diferencias en cuanto a la eficacia de la adopción de la nube a la hora de mejorar los resultados empresariales. Hemos abordado esta limitación centrándonos en las características esenciales del cloud computing, tal como las define el National Institute of Standards and Technology (NIST), y utilizando dicha información como guía. Usando la definición del cloud computing realizada por NIST, investigamos el impacto de las prácticas esenciales en el rendimiento de SDO, en lugar de solo investigar el impacto de la adopción de la nube en SDO.
Por tercera vez, confirmamos que lo realmente importante es cómo implementan los equipos sus servicios en la nube, no solo que usen tecnologías de la nube. Los equipos con rendimiento de élite tenían 3,5 veces más probabilidades de haber cumplido todas las características esenciales de la nube del NIST. Solo el 32 % de los encuestados que afirmaron que estaban utilizando la infraestructura en la nube estaban de acuerdo o completamente de acuerdo con que cumplieron las cinco características esenciales del cloud computing definidas por el NIST, lo que supone un aumento del 3 % con respecto al 2019. En general, el uso de las características del cloud computing del NIST ha aumentado entre un 14 % y un 19 %; la elasticidad rápida presenta el mayor incremento.
Autoservicio bajo demanda
Los consumidores pueden aprovisionar los recursos de computación según sea necesario de forma automática y sin intervención humana por parte del proveedor.
El 73 % de los encuestados usaba el autoservicio bajo demanda, lo que supone un aumento del 16 % con respecto al 2019.
Amplio acceso a la red
Hay muchas funciones disponibles a las que se puede acceder a través de varios clientes, como teléfonos móviles, tablets, portátiles y estaciones de trabajo.
El 74 % de los encuestados usaba un amplio acceso a la red, lo que supone un aumento del 14 % respecto al 2019.
Agrupamiento de recursos
Los recursos de los proveedores se agrupan en un modelo de varios clientes, con recursos físicos y virtuales que se asignan y se vuelven a asignar dinámicamente bajo demanda. Por lo general, el cliente no tiene control directo sobre la ubicación exacta de los recursos proporcionados, pero puede especificarla en un nivel superior de abstracción, como el país, la provincia o estado, o el centro de datos.
El 73 % de los encuestados usaba agrupamiento de recursos, lo que supone un aumento del 15 % respecto al 2019.
Elasticidad rápida
Las funciones se pueden aprovisionar y liberar de forma elástica para escalarse rápidamente hacia dentro o hacia fuera con la demanda. Las funciones de los consumidores disponibles para el aprovisionamiento parecen ser ilimitadas y pueden usarse en cualquier cantidad y momento.
El 77 % de los encuestados usaba la elasticidad rápida, un 18 % más con respecto al 2019.
Servicio medido
Los sistemas en la nube controlan y optimizan de forma automática el uso de los recursos mediante una capacidad de medición en un nivel de abstracción adecuado para el tipo de servicio, como almacenamiento, procesamiento, ancho de banda y cuentas de usuario activas. El uso de recursos se puede monitorizar, controlar y evaluar para garantizar la transparencia.
El 78 % de los encuestados usaba el servicio medido, lo que supone un aumento del 16 % con respecto al 2019.
SRE y DevOps
A medida que la comunidad de DevOps emergía en conferencias y conversaciones públicas, se formó un movimiento de mentalidad similar dentro de Google: Site Reliability Engineering (SRE). SRE y métodos similares, como la disciplina de ingeniería de producción de Facebook, adoptan muchas de las mismas metas y técnicas que motivan el desarrollo de DevOps. En el 2016, SRE se unió oficialmente al discurso público cuando se publicó el primer libro4 sobre Site Reliability Engineering. El movimiento ha crecido desde entonces, y actualmente una comunidad mundial de profesionales de SRE colabora en prácticas para operaciones técnicas.
Quizá inevitablemente, surgió la confusión. ¿Qué diferencia hay entre SRE y DevOps? ¿Tengo que elegir uno u otro? ¿Cuál es mejor? En realidad, no hay ningún conflicto. SRE y DevOps son totalmente complementarios, y nuestro estudio demuestra que están en sintonía. SRE es una disciplina de aprendizaje que da prioridad a la comunicación multifuncional y a la seguridad psicológica, los mismos valores que se encuentran en el núcleo de la cultura generativa orientada al rendimiento, típica de los equipos de DevOps de élite. Además de sus principios fundamentales, SRE ofrece técnicas prácticas, como el framework de métricas de indicadores de nivel de servicio/objetivos de nivel de servicio (SLI/SLO). Del mismo modo que el framework de productos optimizado especifica cómo alcanzar los rápidos ciclos de comentarios de los clientes que desentrañados por nuestra investigación, el framework SRE ofrece definición de prácticas y herramientas que pueden mejorar la capacidad de un equipo para mantener siempre las promesas a sus usuarios.
En el 2021, ampliamos nuestra consulta a operaciones y pasamos de un análisis de la disponibilidad del servicio a la categoría más general de la fiabilidad. En la encuesta de este año, se han introducido varios elementos inspirados en prácticas de SRE para evaluar en qué medida los equipos:
- Definen la fiabilidad en cuanto al comportamiento de cara al usuario
- Usan el framework de métricas SLI/SLO para priorizar el trabajo según los presupuestos de errores
- Usan la automatización para reducir las tareas manuales y las alertas molestas
- Definen protocolos y simulacros de preparación para la respuesta a incidentes
- Incorporan principios de fiabilidad a lo largo del ciclo de vida del envío de software ("shift-left en fiabilidad")
Al analizar los resultados, hemos observado que los equipos que destacan en las prácticas operativas modernas tienen 1,4 veces más probabilidades de registrar un rendimiento de SDO mayor y 1,8 veces más probabilidades de presentar mejores resultados empresariales.
La mayoría de los equipos de nuestro estudio han adoptado las prácticas de SRE: el 52 % de los encuestados usaba estas prácticas en cierta medida, aunque la medida de la adopción varía. sustancialmente entre equipos. Los datos indican que el uso de estos métodos predice una mayor fiabilidad y un mayor rendimiento general de SDO: SRE impulsa el éxito de DevOps.
Además, hemos descubierto que un modelo de responsabilidad compartida de las operaciones, reflejado en el grado en que los desarrolladores y operadores están capacitados para contribuir a la fiabilidad, también ofrece mejores resultados de fiabilidad.
Además de mejorar las medidas objetivas de rendimiento, SRE mejora la experiencia de trabajo de los profesionales técnicos. Por lo general, las personas con grandes cargas de trabajo son propensas a agotarse, pero SRE tiene un efecto positivo. Asimismo, descubrimos que, cuanto más se utilizan las prácticas SRE, menos probabilidades hay de que sus miembros se agoten. SRE también puede ayudar a optimizar los recursos: los equipos que cumplen sus objetivos de fiabilidad mediante la aplicación de prácticas SRE afirman que dedican más tiempo a escribir código que los equipos que no lo hacen.
Según nuestros estudios, los equipos a cualquier nivel del rendimiento SDO, de bajo a élite, obtienen ventajas con el aumento del uso de las prácticas SRE. Cuanto mejor sea el rendimiento de un equipo, mayor será la probabilidad de que use métodos modernos de operaciones: los equipos con un rendimiento de élite tienen 2,1 veces más de probabilidades de usar las prácticas SRE que un equipo de bajo rendimiento. No obstante, incluso los equipos que trabajan a los niveles más altos tienen margen de crecimiento: solo el 10 % de los encuestados con rendimiento de élite indicaron que sus equipos han implementado todas las prácticas SRE que investigamos. A medida que el rendimiento SDO en distintos sectores sigue progresando, el enfoque de cada equipo en las operaciones es un elemento clave de la continua mejora de DevOps.
____________________________
4. Betsy Beyer et al., eds., Site Reliability Engineering (O’Reilly Media, 2016).
____________________________
Documentación y seguridad
Documentación
Este año, hemos analizado la calidad de la documentación interna, que es documentación (como manuales, archivos informativos e incluso comentarios de código) sobre los servicios y aplicaciones con los que trabaja un equipo. Hemos medido la calidad de la documentación por el grado en que dicha documentación:
- Ayuda a los lectores a cumplir sus objetivos
- Es precisa, está actualizada y es exhaustiva
- Se puede encontrar, está bien organizada y es clara5
Grabar y acceder a información sobre sistemas internos es una parte fundamental del trabajo técnico de un equipo. Hemos observado que aproximadamente el 25 % de los encuestados tiene documentación de buena calidad y que el impacto de este tipo de documentos es claro: los equipos con documentación de mayor calidad tienen 2,4 veces más probabilidades de disfrutar de un mejor rendimiento de envío de software y operaciones (SDO). Los equipos con buena documentación suministran software más rápido y con mayor fiabilidad que los equipos con una documentación deficiente. La documentación no tiene por qué ser perfecta. Nuestros estudios demuestran que cualquier mejora en la calidad de la documentación tiene un impacto directo y positivo en el rendimiento.
En la actualidad, el entorno tecnológico tiene sistemas cada vez más complejos, así como expertos y roles especializados para diferentes aspectos de estos sistemas. Desde la seguridad hasta las pruebas, la documentación es una forma clave de compartir conocimientos y directrices especializados tanto entre estos equipos especializados como con el resto de la organización.
Hemos observado que, con la calidad de la documentación, se puede predecir el éxito de los equipos a la hora de implementar prácticas técnicas. A su vez, estas prácticas predicen mejoras en las funciones técnicas del sistema, como la observabilidad, las pruebas continuas y la automatización del despliegue. Hemos observado que los equipos con documentación de calidad:
- Tienen 3,8 veces más probabilidades de implementar prácticas de seguridad
- Tienen 2,4 veces más probabilidades de cumplir o superar sus objetivos de fiabilidad
- Tienen 3,5 veces más probabilidades de implementar prácticas de Site Reliability Engineering (SRE)
- Tienen 2,5 veces más probabilidades de aprovechar la nube por completo
Cómo mejorar la calidad de la documentación
Las tareas técnicas implican buscar y usar información, pero la documentación de calidad depende de las personas que redactan y mantienen el contenido. En el 2019, descubrimos que el acceso a fuentes de información internas y externas fomenta la productividad. El estudio de este año lleva la investigación un paso más allá para evaluar la calidad de la documentación a la que se accede, así como sobre las prácticas que influyen en la calidad de esta documentación.
Nuestros estudios demuestran que las siguientes prácticas tienen un impacto positivo significativo en la calidad de la documentación:
Documenta casos prácticos importantes de tus productos y servicios. Lo que documentes sobre un sistema es importante, y los casos prácticos permiten que los lectores utilicen la información y los sistemas.
Crea directrices claras para actualizar y editar la documentación disponible. Gran parte del trabajo de documentación consiste en mantener el contenido disponible. Cuando los miembros del equipo saben cómo hacer actualizaciones o eliminar información imprecisa u obsoleta, el equipo puede mantener la calidad de la documentación aunque el sistema evolucione con el tiempo.
Define propietarios. Los equipos que cuentan con documentación de calidad tienen más probabilidades de definir claramente la propiedad de la documentación. La propiedad permite contar con responsabilidades explícitas para escribir contenido nuevo y para actualizar o verificar cambios en el contenido actual. Los equipos con documentación de calidad tienen más probabilidades de afirmar que se redacta documentación para todas las funciones principales de las aplicaciones en las que trabajan, y una propiedad clara ayuda a crear esta amplia cobertura.
Incluye documentación como parte del proceso de desarrollo del software. Los equipos que han creado documentación y la han actualizado a medida que el sistema ha cambiado, tienen documentación de mayor calidad. Al igual que las pruebas, la creación y el mantenimiento de documentación son una parte fundamental de un proceso de desarrollo de software que ofrece un rendimiento óptimo.
Otorga reconocimiento al trabajo de documentación durante las revisiones de rendimiento y los ascensos. El reconocimiento se correlaciona con la calidad general de la documentación. Redactar y mantener la documentación es una parte fundamental del trabajo de ingeniería de software y, por tanto, tratar estos procesos como tal mejora la calidad general.
Otros recursos que hemos encontrado para fomentar la documentación de calidad son los siguientes:
- Formación sobre cómo redactar y mantener documentación
- Pruebas automatizadas de códigos de ejemplo o documentación incompleta
- Directrices, como guías de estilo de documentación y guías de redacción para una audiencia global
La documentación es fundamental para implementar correctamente las funciones de DevOps. Cuanto mayor sea la calidad de la documentación, mejores serán los resultados de las inversiones en funciones individuales de DevOps, como la seguridad, la fiabilidad y el aprovechamiento íntegro de la nube. Implementar prácticas que fomenten la calidad de la documentación merece la pena, ya que esto ofrece capacidades técnicas más sólidas y un mayor rendimiento de SDO.
____________________________
5. Métricas de calidad basadas en los estudios de documentación técnica disponibles, como los siguientes:
— Aghajani, E. et al. (2019). Software Documentation Issues Unveiled. Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering, 1199-1210. https://doi.org/10.1109/ICSE.2019.00122
— Plösch, R., Dautovic, A., & Saft, M. (2014). The Value of Software Documentation Quality. Proceedings of the International Conference on Quality Software, 333-342. https://doi.org/10.1109/QSIC.2014.22
— Zhi, J. et al. (2015). Cost benefits and quality of software development documentation: A systematic mapping. Journal of Systems and Software, 99(C), 175-198. https://doi.org/10.1016/j.jss.2014.09.042
____________________________
Seguridad
[Shift left] e integración en todos los procesos
A medida que los equipos tecnológicos siguen avanzando y evolucionando, también lo hace la cantidad y el nivel de sofisticación de las amenazas para la seguridad. En el 2020, más de 22.000 millones de registros de información personal confidencial o datos empresariales quedaron expuestos a accesos no autorizados, según el informe Threat Landscape Retrospective del 2020 de Tenable.6 La seguridad no puede ser un elemento secundario o el último paso antes de la entrega: se debe integrar en todo el proceso de desarrollo del software.
Para proporcionar software de forma segura, las prácticas de seguridad deben evolucionar más rápido que las técnicas que usan las personas malintencionadas. Durante los ataques del 2020 a la cadena de suministro de software de SolarWinds y Codecov, los piratas informáticos pusieron en riesgo el sistema de compilación de SolarWinds y la secuencia de comandos de subida de bash de Codecov7 para infiltrarse en la infraestructura de miles de clientes de esas empresas. Debido al impacto generalizado de estos ataques, el sector debe pasar de un enfoque preventivo a un enfoque diagnóstico, en el que los equipos de software deben dar por hecho que sus sistemas ya están en riesgo e incorporar la seguridad en su cadena de suministro.
Al igual que en informes anteriores, hemos observado que los equipos con rendimiento de élite tienen resultados excelentes a la hora de implementar prácticas de seguridad. Este año, los equipos con rendimiento de élite que lograron o superaron sus objetivos de fiabilidad tenían el doble de probabilidades de tener la seguridad integrada en su proceso de desarrollo de software. Esto sugiere que los equipos que han acelerado la entrega y mantienen sus estándares de fiabilidad han encontrado una forma de integrar las comprobaciones y las prácticas de seguridad sin poner en riesgo su capacidad para distribuir software de manera rápida o fiable.
Además de lograr un alto rendimiento operativo y de entrega, los equipos que integran prácticas de seguridad en todo su proceso de desarrollo tienen 1,6 veces más probabilidades de alcanzar o superar sus objetivos organizativos. Los equipos de desarrollo que adoptan la estrategia de seguridad aportan un valor significativo a la empresa.
____________________________
6. https://www.tenable.com/cyber-exposure/2020-threat-landscape-retrospective
7. https://www.cybersecuritydive.com/news/codecov-breach-solarwinds-software-supply-chain/598950/
____________________________
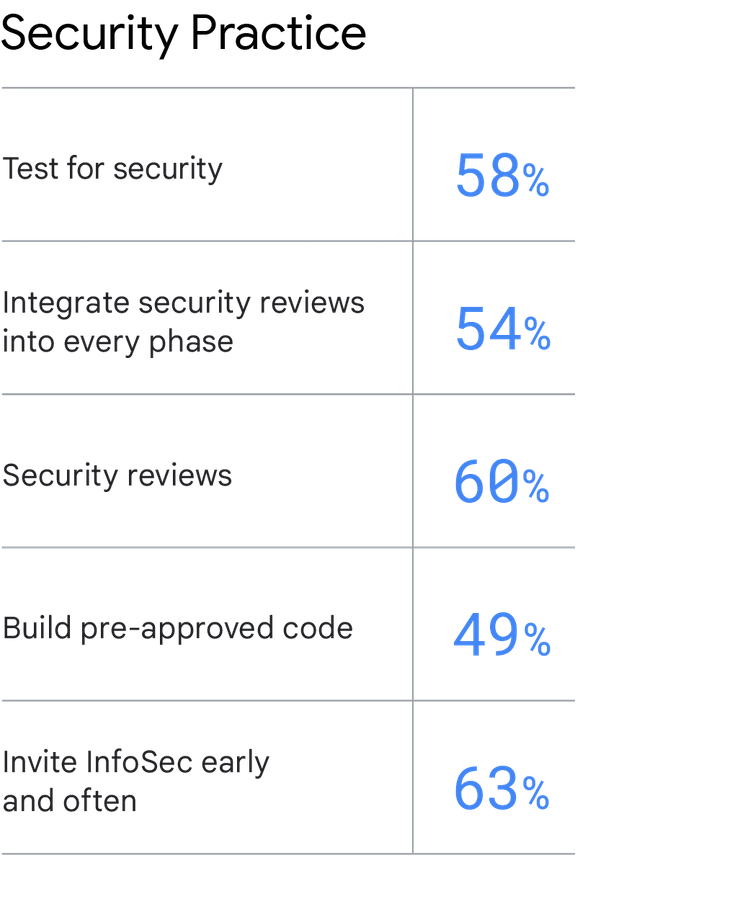
Cómo tomas las medidas correctas
Es fácil hacer hincapié en la importancia de la seguridad y sugerir que los equipos tienen que darle prioridad. Sin embargo, para ponerlo en práctica, se requieren diversos cambios con respecto a los métodos tradicionales de seguridad de la información. Puedes integrar la seguridad, mejorar el envío de software y el rendimiento operativo, así como mejorar el rendimiento organizativo, aplicando estas prácticas:
Prueba la seguridad. Prueba los requisitos de seguridad como parte del proceso automatizado de pruebas, incluidas las áreas en las que se debe usar código preaprobado.
Integra la revisión de seguridad en todas las fases. Integra la seguridad de la información (InfoSec) en el trabajo diario de todo el ciclo de vida del envío de software. Por ejemplo, el equipo de InfoSec debe aportar información durante las fases de diseño y arquitectura de la aplicación, asistir a demostraciones de software y proporcionar comentarios durante las demostraciones.
Revisiones de seguridad. Haz una revisión de seguridad de todas las funciones principales. Crea código preaprobado. Haz que el equipo de InfoSec cree bibliotecas, paquetes, cadenas de herramientas y procesos preaprobados y sencillos para que los desarrolladores y los operadores de TI los utilicen en su trabajo. Invita a InfoSec cuanto antes y a menudo. Incluye a InfoSec durante la planificación y todas las fases posteriores del desarrollo de aplicaciones para identificar rápidamente las debilidades relacionadas con la seguridad. De este modo, el equipo tendrá tiempo suficiente para solucionarlas.
Crea código preaprobado. Haz que el equipo de InfoSec cree bibliotecas, paquetes, cadenas de herramientas y procesos preaprobados y sencillos para que los desarrolladores y los operadores de TI los utilicen en su trabajo.
Invita a InfoSec cuanto antes y a menudo. Incluye a InfoSec durante la planificación y todas las fases posteriores del desarrollo de aplicaciones para identificar rápidamente las debilidades relacionadas con la seguridad. De este modo, el equipo tendrá tiempo suficiente para solucionarlas.
Como hemos mencionado antes, una documentación de alta calidad permite alcanzar el éxito de diversas áreas, y la seguridad no es ninguna excepción. Hemos observado que los equipos con documentación de alta calidad tienen 3,8 veces más probabilidades de integrar la seguridad en su proceso de desarrollo. No todos los miembros de una organización tienen conocimientos sobre criptografía. La experiencia de los expertos en la materia se comparte mejor en las organizaciones mediante prácticas de seguridad documentadas.
Funciones técnicas de DevOps
Según nuestros estudios, las organizaciones que experimentan una transformación de DevOps mediante la adopción de la entrega continua tienen más probabilidades de tener procesos de alta calidad, con bajo riesgo y rentables.
En concreto, medimos las siguientes prácticas técnicas:
- Arquitectura con bajo acoplamiento
- Desarrollo basado en troncales
- Pruebas continuas
- Integración continua
- Uso de tecnologías de código abierto
- Prácticas de monitorización y observabilidad
- Gestión de los cambios en bases de datos
- Automatización de despliegues
Hemos observado que, aunque todas estas prácticas mejoran la entrega continua, la arquitectura con bajo acoplamiento y las pruebas continuas tienen el mayor impacto. Por ejemplo, este año descubrimos que los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen tres veces más probabilidades de emplear una arquitectura con bajo acoplamiento que los equipos de bajo rendimiento.
Arquitectura con bajo acoplamiento
Nuestra investigación sigue demostrando que puedes mejorar el rendimiento de TI esforzándote por reducir las dependencias pormenorizadas entre los servicios y los equipos. De hecho, este es uno de los principales factores que determinan que la entrega continua será un éxito. Gracias a una arquitectura con bajo acoplamiento, los equipos pueden escalar, probar y desplegar de forma independiente. Los equipos pueden avanzar a su propio ritmo, trabajar en lotes más pequeños, acumular menos deuda técnica y recuperarse más rápido si se produce un fallo.
Pruebas continuas e integración continua
Al igual que en los resultados de años anteriores, hemos observado que la prueba continua es un factor importante para predecir el éxito de la entrega continua. Los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen 3,7 veces más probabilidades de aprovechar las pruebas continuas. Al incorporar pruebas tempranas y frecuentes a lo largo del proceso de entrega, con los responsables de pruebas trabajando codo con codo con los desarrolladores, los equipos pueden iterar y hacer cambios en sus productos, servicios o aplicaciones más rápidamente. Puedes usar este bucle de retroalimentación para ofrecer valor a tus clientes a la vez que incorporas fácilmente prácticas como las pruebas automatizadas y la integración continua.
Además, la integración continua mejora la entrega continua. Los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen 5,8 veces más probabilidades de aprovechar la integración continua. En la integración continua, cada confirmación activa una compilación del software y ejecuta una serie de pruebas automatizadas que proporcionan información en unos minutos. Gracias a la integración continua, disminuye la coordinación manual y, a menudo, compleja, que se necesita para lograr una integración correcta.
La integración continua, tal como la definen Kent Beck y la comunidad Extreme Programming, donde se originó, también incluye la práctica del desarrollo basado en troncales, que se explica a continuación.7
Desarrollo basado en troncales
Según nuestra investigación, las organizaciones de alto rendimiento tienen más probabilidades de implementar el desarrollo basado en troncales, con el que los desarrolladores trabajan en pequeños lotes y fusionan su trabajo en un troncal compartido con frecuencia. De hecho, los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen 2,3 veces más probabilidades de utilizar el desarrollo basado en troncales. Los equipos de bajo rendimiento tienen más probabilidades de utilizar ramas de larga duración y retrasar la fusión.
Los equipos deben fusionar su trabajo al menos una vez al día, o varias veces al día si es posible. El desarrollo basado en troncales está estrechamente relacionado con la integración continua, por lo que deberías implementar estas dos prácticas técnicas simultáneamente, ya que tienen un mayor impacto cuando se usan juntas.
Automatización de despliegues
En entornos de trabajo ideales, los ordenadores llevan a cabo tareas repetitivas mientras los humanos se centran en resolver problemas. Si implementas la automatización de los despliegues, tus equipos estarán más cerca de conseguir este objetivo.
Al pasar el software de la fase de prueba a la producción de manera automatizada, reduces el tiempo de entrega, ya que los despliegues son más rápidos y eficientes. Además, se reduce la probabilidad de que se produzcan errores de despliegue, que son más habituales en los despliegues manuales. Cuando tus equipos usan la automatización de despliegues, reciben información inmediata, lo que puede ayudarte a mejorar tu servicio o producto a una velocidad muy superior. Aunque no es preciso implementar las pruebas de forma continua, la integración continua y los despliegues automatizados a la vez, es probable que consigas mejoras superiores si combinas estas tres prácticas.
Gestión de cambios en las bases de datos
El seguimiento de cambios mediante el control de versiones es una parte fundamental de la escritura y el mantenimiento del código, así como de la gestión de bases de datos. Según nuestros estudios, los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen 3,4 veces más probabilidades de aplicar la gestión de cambios en sus bases de datos que los de bajo rendimiento. Además, la clave del éxito de la gestión de cambios en bases de datos es la colaboración, la comunicación y la transparencia entre todos los equipos implicados. Aunque puedes elegir entre diferentes estrategias de implementación, te recomendamos que, cada vez que tengas que hacer cambios en la base de datos, los equipos se reúnan para revisar los cambios antes de actualizar la base de datos.
____________________________
8. Beck, K. (2000). Extreme programming explained: Embrace change. Addison-Wesley Professional
____________________________
Monitorización y observabilidad
Al igual que en años anteriores, hemos observado que las prácticas de monitorización y observabilidad permiten llevar a cabo una entrega continua. Los equipos con rendimiento de élite que cumplen correctamente sus objetivos de fiabilidad tienen 4,1 veces más probabilidades de tener soluciones que incorporan la observabilidad en el estado general del sistema. Las prácticas de observabilidad permiten a tus equipos entender mejor tus sistemas, lo que reduce el tiempo necesario para identificar problemas y solucionarlos. Además, nuestros estudios indican que los equipos con buenas prácticas de observabilidad pasan más tiempo programando. Una posible explicación de estos resultados es que la implementación de prácticas de observabilidad permite a los desarrolladores dejar de buscar posibles causas de problemas y, en su lugar, dedicarse a programar.
Tecnologías de código abierto
Muchos desarrolladores ya aprovechan las tecnologías de código abierto, y su familiaridad con estas herramientas es un factor clave para la organización. Una de las principales desventajas de las tecnologías de fuente cerrada es que limitan la capacidad de transferir información dentro y fuera de la organización. Por ejemplo, no puedes contratar a alguien que ya conozca las herramientas de tu organización, y los desarrolladores no pueden transferir la información que han acumulado a otras organizaciones. Por otro lado, la mayoría de las tecnologías de código abierto cuentan con una comunidad que los desarrolladores pueden utilizar para ofrecer asistencia. Las tecnologías de código abierto son más accesibles, relativamente asequibles y personalizables. Los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen 2,4 veces más probabilidades de utilizar tecnologías de código abierto. Te recomendamos que empieces a usar más software de código abierto cuando implementes tu transformación de DevOps.
Para obtener más información sobre las capacidades técnicas de DevOps, consulta las funciones de DORA en https://cloud.google.com/devops/capabilities
COVID-19 y la cultura
COVID-19
Este año hemos analizado los factores que han influido en el rendimiento de los equipos durante la pandemia del COVID‐19. En concreto, ¿la pandemia del COVID‐19 ha afectado negativamente al rendimiento del envío de software y operaciones (SDO)? ¿Los equipos se agotan más como consecuencia? Por último, ¿qué factores parecen prometedores para reducir el agotamiento?
En primer lugar, nuestro objetivo era comprender cómo afectaba la pandemia al rendimiento de envío y operaciones. Muchas organizaciones han dado prioridad a la modernización para adaptarse a cambios drásticos del mercado (por ejemplo, el cambio de la compra en persona a la compra online). En el apartado "¿Cómo lo estamos haciendo?" explicamos cómo el rendimiento del sector del software se ha acelerado considerablemente y sigue acelerándose. Actualmente, los equipos de alto rendimiento forman la mayor parte de nuestro muestreo, y los equipos con rendimiento de élite siguen subiendo el listón, desplegando con más frecuencia, con menores plazos de entrega, con tiempos de recuperación más rápidos y con mejores tasas de fallos de cambios. De un modo similar, en un estudio de investigadores de GitHub, se observó un aumento en la actividad de los desarrolladores (es decir, envíos, solicitudes de extracción, solicitudes de extracción revisadas y comentarios publicados por usuario9) durante el año 2020. El sector ha seguido acelerándose a pesar de la pandemia, no debido a ella. Sin embargo, cabe destacar que no se observó una tendencia a la baja en el rendimiento de SDO durante este periodo de urgencia.
La pandemia ha cambiado nuestra forma de trabajar y, para muchos, también ha cambiado el lugar de trabajo. Por esta razón, tenemos en cuenta el impacto del trabajo remoto como consecuencia de la pandemia. Hemos observado que el 89 % de los encuestados ha trabajado desde casa debido a la pandemia. Solo el 20 % afirmó haber trabajado desde casa alguna vez antes de la pandemia. Cambiar a un entorno de trabajo remoto ha tenido implicaciones significativas en la forma en que desarrollamos el software, gestionamos el negocio y trabajamos juntos. Para muchos, el trabajo desde casa supuso un obstáculo para la conexión mediante conversaciones improvisadas en el pasillo o la colaboración en persona.
____________________________
9. https://octoverse.github.com/
____________________________
¿Qué supuso una reducción del agotamiento?
A pesar de esto, descubrimos un factor que tenía un gran impacto en el hecho de si un equipo tenía problemas de agotamiento a causa del teletrabajo: la cultura. Los equipos que tienen una cultura de equipo generativa, formados por personas que se sentían incluidas y que pertenecían a su equipo, tenían la mitad de probabilidades de sufrir agotamiento durante la pandemia.. Este resultado refuerza la importancia de dar prioridad a los equipos y la cultura. Los equipos que obtienen mejores resultados están más preparados para superar los periodos más difíciles que generan presión tanto al equipo como a las personas.
Cultura
En términos generales, la cultura es la parte interpersonal ineludible de todas las organizaciones. Es decir, cualquier cosa que influya en la forma en que los empleados piensan, se sienten y se comportan con respecto a la organización y los demás. Todas las organizaciones tienen su propia cultura única, y nuestros hallazgos demuestran que la cultura es uno de los factores que más impulsan el rendimiento organizativo y de TI. Concretamente, nuestros análisis indican que una cultura generadora, que se mide mediante la tipología de la cultura organizativa de Westrum, y el sentido de pertenencia e inclusión de las personas dentro de la organización, se traducen en un mayor rendimiento de envío de software y operaciones (SDO). Por ejemplo, observamos que los equipos con rendimiento de élite que cumplen sus objetivos de fiabilidad tienen 2,9 veces más probabilidades de tener una cultura de equipo generativa que los que tienen un rendimiento bajo. Del mismo modo, con una cultura generativa cabe esperar un mayor rendimiento organizativo y una tasa más baja de agotamiento de los empleados. En resumen, la cultura es muy importante. Afortunadamente, la cultura es fluida y polifacética, y siempre está en movimiento, por lo que es algo que puedes cambiar.
Para que DevOps sea un éxito, tu organización debe tener equipos que colaboren entre sí y de forma multifuncional. En el 2018, descubrimos que los equipos de alto rendimiento tenían el doble de probabilidades de desarrollar y enviar software en un solo equipo multifuncional. Esto refuerza que la colaboración y la cooperación son fundamentales para el éxito de cualquier organización. Una pregunta clave es: ¿qué factores contribuyen a crear un entorno que fomente y celebre la colaboración multifuncional?
A lo largo de los años, hemos intentado lograr que la estructura de la cultura sea tangible y ofrecer a la comunidad de DevOps una mejor comprensión del impacto de la cultura en el rendimiento organizativo y de TI. Iniciamos este proceso creando una definición operativa de la cultura a partir de la tipología de la cultura organizativa de Westrum, que identificó tres tipos de organizaciones: orientadas al poder, a las reglas y al rendimiento. Hemos utilizado este framework en nuestra investigación y hemos observado que una cultura organizativa orientada al rendimiento que optimice el flujo de información, la confianza, la innovación y el intercambio de riesgos presenta grandes probabilidades de alto rendimiento de SDO.
A medida que evoluciona nuestra comprensión sobre la cultura y DevOps, nos esforzamos por ampliar nuestra definición inicial de cultura para incluir otros factores psicosociales, como la seguridad psicológica. Las organizaciones con un alto rendimiento tienen más probabilidad de tener una cultura que anime a los empleados a asumir riesgos calculados y moderados sin miedo a consecuencias negativas.
Pertenencia e inclusión
Dado el enorme impacto que la cultura tiene en el rendimiento, este año hemos ampliado nuestro modelo para examinar si el sentido de pertenencia e inclusión de los empleados contribuye al efecto beneficioso de la cultura en el rendimiento.
Según diversos estudios psicológicos, las personas están motivadas de forma innata para forjar y mantener relaciones sólidas y estables con otras personas.10 Estamos motivados a sentirnos conectados con otras personas y a sentirnos aceptados dentro de los grupos en los que participamos. Los sentimientos de pertenencia dan lugar a una amplia variedad de resultados físicos y psicológicos favorables. Por ejemplo, un estudio indica que el sentimiento de pertenencia influye positivamente en la motivación y en la mejora de los logros académicos.11
Un componente de esta sensación de conexión es la idea de que las personas se sienten cómodas al llevar darlo todo en el trabajo, y que sus experiencias y contextos únicos son valorados y reconocidos.12 Centrarse en crear culturas inclusivas que pertenezcan a otras organizaciones ayuda a construir una plantilla en crecimiento, diversa y motivada.
Nuestros resultados indican que las organizaciones orientadas al rendimiento que valoran la pertenencia y la inclusión tienen más probabilidades de tener niveles inferiores de agotamiento de empleados que las organizaciones con culturas menos positivas.
Debido a las pruebas que demuestran cómo los factores psicosociales afectan al rendimiento de SDO y a los niveles de agotamiento entre los empleados, recomendamos que, si quieres llevar a cabo una transformación de DevOps con éxito, debes invertir en abordar problemas relacionados con la cultura como parte del proceso de transformación.
____________________________
10. Baumeister & Leary, 1995. The need to belong: Desire for interpersonal attachments as a fundamental human motivation. Psychological Bulletin, 117(3), 497–529. https://doi.org/10.1037/0033-2909.117.3.497
11. Walton et al., 2012. Mere belonging: the power of social connections. Journal of Personality and Social Psychology, 102(3):513-32. https://doi.org/10.1037/a0025731
12. Mor Barak & Daya, 2014; Managing diversity: Toward a globally inclusive workplace. Sage. Shore, Cleveland, & Sanchez, 2018; Inclusive workplaces: A review and model, Human Resources Review. https://doi.org/10.1016/j.hrmr.2017.07.003
¿Quién ha completado la encuesta?
Con siete años de investigación y más de 32.000 respuestas de profesionales del sector, en el informe Accelerate State of DevOps 2021 se muestran las prácticas de desarrollo de software y DevOps que hacen que los equipos y organizaciones tengan más éxito.
Este año, más de 1200 profesionales de diversos sectores de todo el mundo compartieron sus experiencias para ayudarnos a conocer mejor los factores que mejoran el rendimiento. En resumen, la representación de estadísticas demográficas y emporiográficas ha variado poquísimo.
Al igual que en años anteriores, hemos recopilado información demográfica de cada encuestado. Entre las categorías se incluyen las de sexo, discapacidad y grupos con poca representación.
Datos demográficos y organizativos
Este año, observamos una representación coherente con informes anteriores en cuanto a las categorías emporiográficas, como el tamaño, el sector y la zona de la empresa. De hecho, más del 60 % de los encuestados trabajan como ingenieros o supervisores, y una tercera parte trabaja en el sector tecnológico. Además, hay representación de los sectores de servicios financieros, minoristas y de empresas industriales y de fabricación.
____________________________
13. https://www.washingtongroup-disability.com/question-sets/wg-short-set-on-functioning-wg-ss/
____________________________
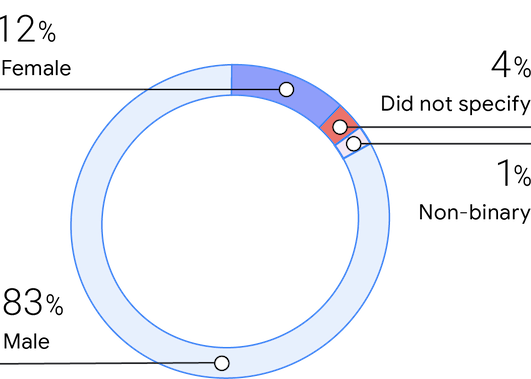
Datos demográficos
Sexo
Al igual que en encuestas anteriores, la muestra de este año está formada por un 83 % de hombres, un 12 % de mujeres y un 1 % de género no binario. Los encuestados afirmaron que las mujeres constituyen aproximadamente el 25 % de sus equipos, lo que supone un gran aumento desde el 2019 (16 %) y, de nuevo, un valor estable con respecto al 2018 (25 %).
Discapacidad
La discapacidad se identifica con seis dimensiones que siguen las directrices del Washington Group Short Set.13 Este es el tercer año en el que preguntamos sobre la discapacidad. El porcentaje de personas con discapacidades se mantuvo estable con respecto a nuestro informe del 2019 (un 9 %).
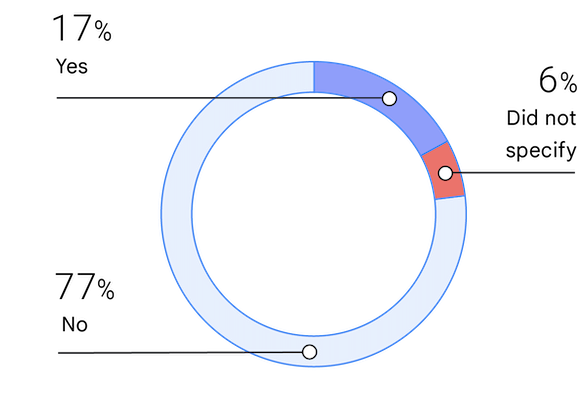
Grupos infrarrepresentados
Identificarse como miembro de un grupo infrarrepresentado puede hacer referencia a la raza, sexo u otra característica. Este es el cuarto año que hemos preguntado sobre la infrarrepresentación. El porcentaje de personas que se identifican como pertenecientes a un grupo infrarrepresentado ha aumentado ligeramente, del 13,7 % en el 2019 al 17 % en el 2021.
Años de experiencia
Los participantes en la encuesta de este año cuentan con una gran experiencia: un 41 % de ellos tiene al menos 16 años de experiencia. Más del 85 % de los encuestados tenía al menos 6 años de experiencia.
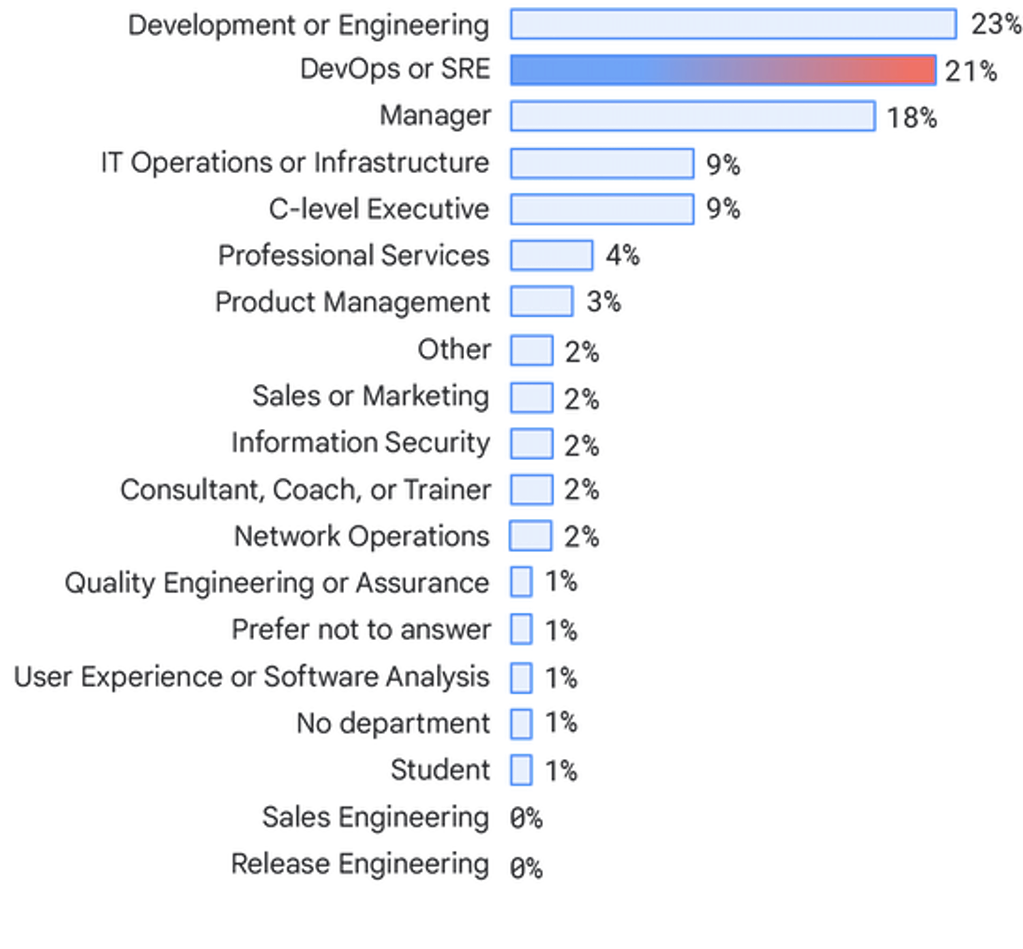
Datos firmográficos
Departamentos
Los encuestados consisten principalmente en personas que trabajan en equipos de desarrollo o ingeniería (23 %), equipos de DevOps o SRE (21 %), gestores (18 %) y equipos de operaciones o infraestructuras de TI (9 %). Hemos observado una disminución de la representación por parte de los consultores (de un 4 % en el 2019 a un 2 %), así como un aumento de los directivos de alto nivel (de un 4 % en el 2019 a un 9 %).
Sector
Al igual que en los informes anteriores de Accelerate State of DevOps, vemos que la mayoría de los encuestados trabajan en el sector tecnológico, seguido de los servicios financieros, el comercio minorista y otros sectores.
Empleados
Al igual que los informes anteriores de Accelerate State of DevOps, los encuestados proceden de organizaciones de diversos tamaños. El 22 % de los encuestados trabaja en empresas con más de 10.000 empleados, y el 7 %, en empresas con entre 5000 y 9999 empleados. Otro 15 % de los encuestados trabaja en organizaciones con entre 2000 y 4999 empleados. También observamos una representación equitativa de los encuestados de organizaciones con entre 500 y 1999 empleados (un 13 %), entre 100 y 499 empleados (un 15 %) y, por último, entre 20 y 99 empleados (un 15 %).
Tamaño del equipo
Más de la mitad de los encuestados (62 %) trabajan en equipos con 10 miembros o menos (28 % en equipos de 6-10 miembros, 27 % en equipos de 2-5 miembros y 6 % en equipos de una persona). Otro 19 % trabaja en equipos de entre 11 y 20 miembros.
Regiones
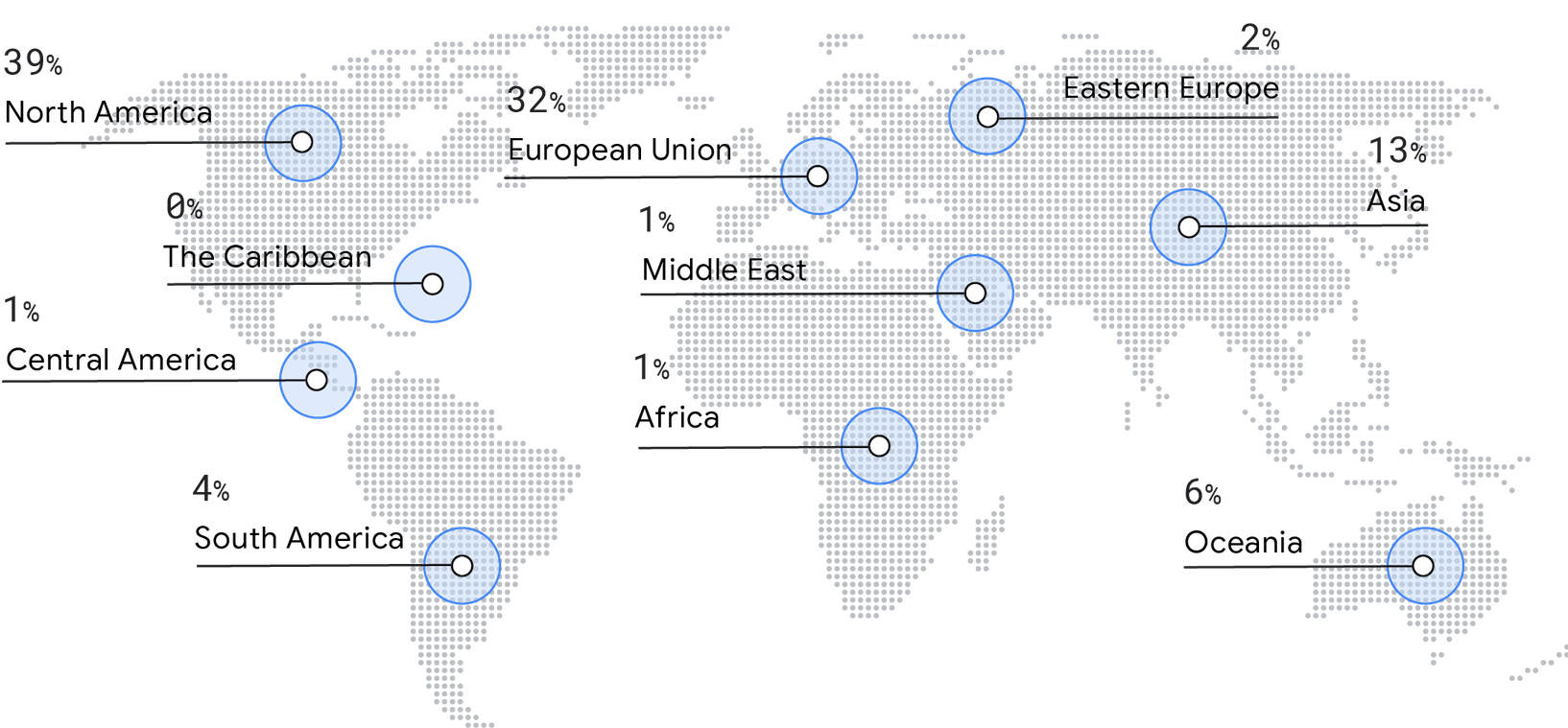
La encuesta de este año experimentó una disminución de las respuestas desde Norteamérica (del 50 % en el 2019 al 39 % en el 2021). En su lugar, hemos observado un aumento de la representación en Europa (del 29 % en el 2019 al 32 % en el 2021), Asia (del 9 % en el 2019 al 13 % en el 2021), Oceanía (del 4 % en el 2019 al 6 % en el 2021) y Sudamérica (del 2 % en el 2019 al 4 % en el 2021).
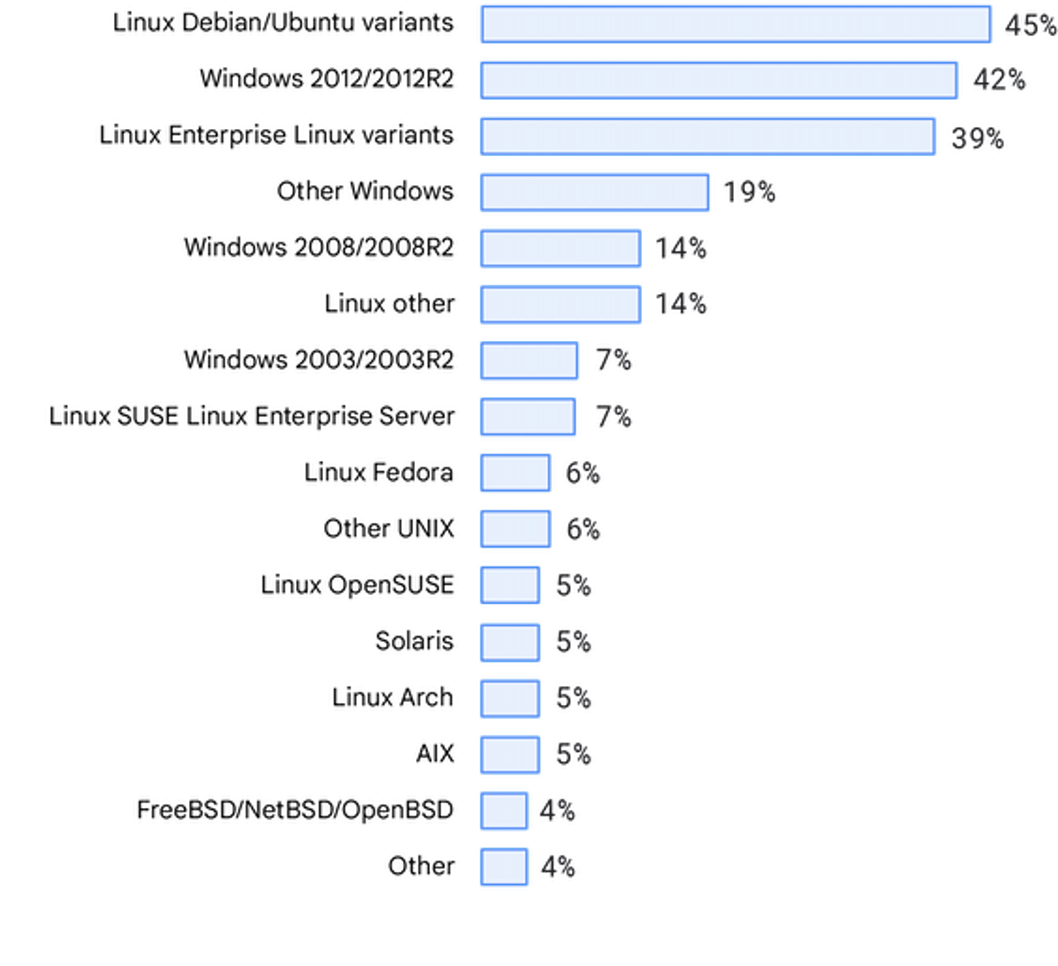
Sistemas operativos
La distribución de los sistemas operativos también estaba correlacionada con los informes State of DevOps anteriores. Además, queremos dar las gracias a los encuestados que nos dijeron que nuestra lista de sistemas operativos necesitaba una actualización.
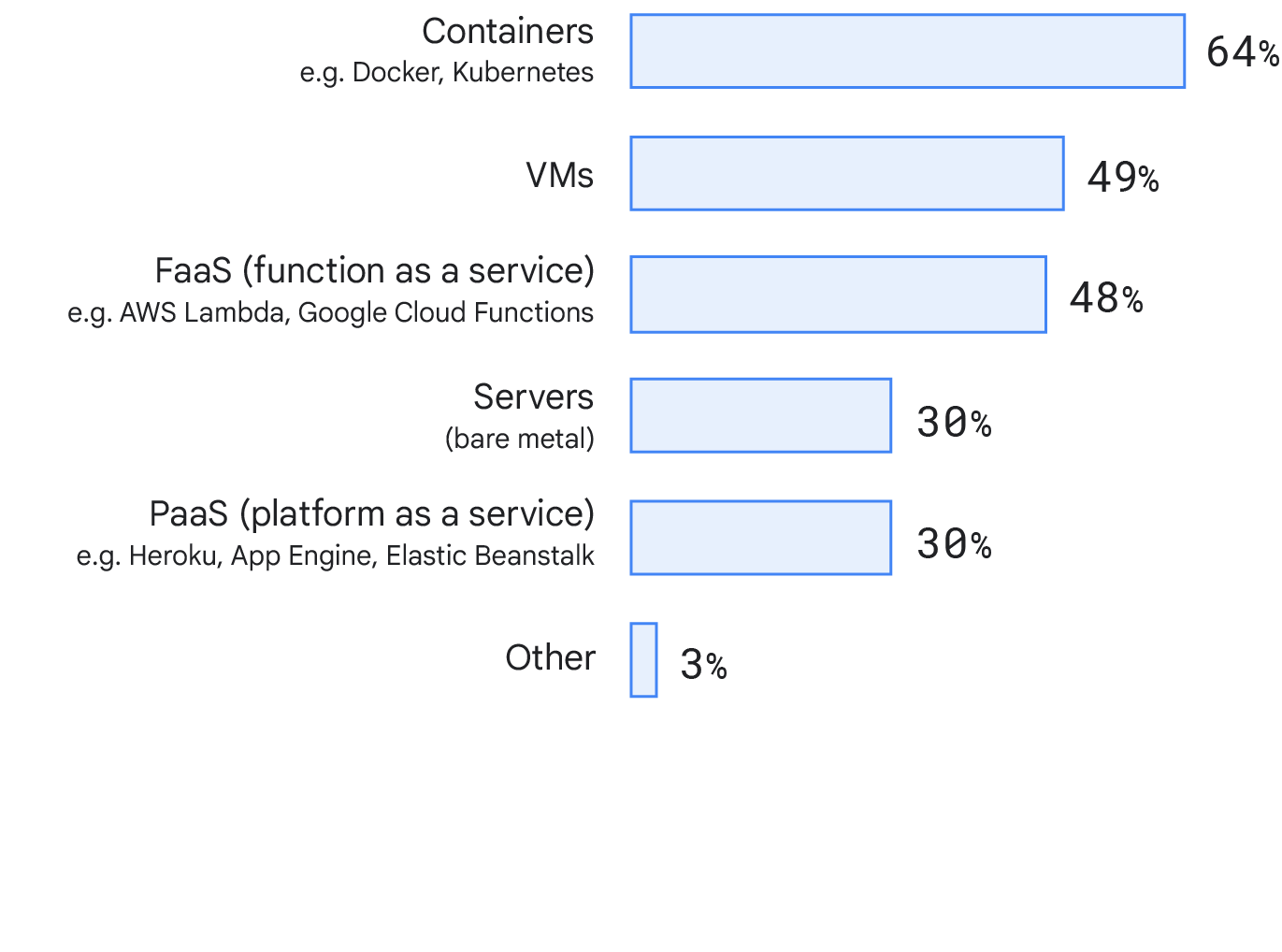
Destino de despliegue
Este año hemos analizado los lugares desde los que los encuestados despliegan el servicio o la aplicación principal en los que trabajan. Por sorpresa, una gran parte de los encuestados utiliza contenedores (64 %), y el 48 % usa máquinas virtuales. Esto podría reflejar un cambio en el sector hacia el desarrollo de tecnologías de destino de despliegue más modernas. Hemos comprobado las diferencias entre los distintos tamaños de empresa y no hemos observado ninguna diferencia significativa entre los destinos de despliegue.
Reflexiones finales
Después de siete años de investigación, seguimos observando las ventajas que aporta DevOps a las organizaciones. Las organizaciones interanuales siguen acelerándose y mejorando.
Los equipos que son conscientes de sus principios y funciones pueden ofrecer software de forma rápida y fiable, al mismo tiempo que aportan valor directamente a la empresa. Este año hemos analizado los efectos de las prácticas SRE, una cadena de suministro de software segura y la documentación de calidad, y hemos vuelto a examinar nuestra oportunidad de sacar partido a la nube. Cada área permite a las personas y a los equipos ser más eficientes. Nos centramos en la importancia de estructurar soluciones que se adapten a las personas que aprovechan esas prestaciones, en lugar de adaptar las personas a la solución.
Damos las gracias a todos los que han contribuido a la encuesta de este año. Esperamos que nuestra investigación os ayude a ti y a tu organización a crear mejores equipos y mejores software, al mismo tiempo que mantenéis una buena conciliación de vida laboral y personal.
Agradecimientos
El informe de este año ha sido posible gracias a una gran familia de colaboradores apasionados. El diseño, análisis, redacción y revisión de las preguntas de la encuesta, así como el diseño del informe, son solo algunas de las formas en las que nuestros compañeros han ayudado a llevar a cabo esta gran labor. Los autores quieren dar las gracias a todas estas personas por sus contribuciones y asesoramiento en el informe de este año. Todos los apellidos aparecen por orden alfabético.

Autores
Dustin Smith
Dustin Smith es psicólogo de los factores humanos y director de investigación de la experiencia del usuario de Google, y ha trabajado en el proyecto DORA durante tres años. Durante los últimos siete años, ha estudiado cómo se ven afectadas las personas por los sistemas y los entornos en distintos contextos: ingeniería de software, videojuegos gratuitos, sanidad y sector militar. Su trabajo en Google identifica áreas en las que los desarrolladores de software pueden sentirse más satisfechos y productivos durante el desarrollo. Lleva dos años trabajando en el proyecto DORA. Dustin recibió su doctorado en Psicología de los Factores Humanos en la Wichita State University.
Daniella Villalba
Daniella Villalba es investigadora de la experiencia de usuario y se entrega por completo al proyecto DORA. Se centra en identificar los factores que hacen que los desarrolladores estén satisfechos y sean productivos. Antes de trabajar en Google, Daniella estudió las ventajas de la formación en meditación, los factores psicosociales que afectan a las experiencias de los estudiantes universitarios, la memoria de los testigos y las confesiones falsas. Tiene un doctorado en Psicología Experimental por la Universidad Internacional de Florida.
Michelle Irvine
Michelle Irvine es una escritora técnica de Google, donde trabaja para tender puentes entre las herramientas para desarrolladores y las personas que las usan. Antes de llegar a Google, trabajó en el ámbito de la edición para centros educativos y como redactora técnica de software de simulación física. Michelle se licenció en Física y tiene un máster en Retórica y Diseño de Comunicación por la Universidad de Waterloo.
Dave Stanke
Dave Stanke es ingeniero de relaciones con los desarrolladores en Google. Asesora a los clientes sobre las prácticas recomendadas para adoptar DevOps y SRE. A lo largo de su carrera ha ocupado todo tipo de puestos, como el de director de tecnología en una empresa emergente, responsable de producto, servicio de asistencia, desarrollador de software, administrador de sistemas y diseñador gráfico. Tiene un máster en Gestión Tecnológica por la Universidad de Columbia.
Nathen Harvey
Nathen Harvey es ingeniero de relaciones con los desarrolladores en Google. A lo largo de su carrera, ha ayudado a desatar el potencial de diversos equipos y a adaptar la tecnología a los resultados empresariales. Ha tenido el privilegio de trabajar con algunos de los mejores equipos y comunidades de software libre, ayudándoles a aplicar los principios y las prácticas de DevOps y SRE. Nathen correvisó y contribuyó a la publicación de "97 Things Every Cloud Engineer Should Know", O'Reilly 2020.
Metodología
Diseño de investigación
Este estudio utiliza un diseño transversal basado en teoría. Este diseño basado en teoría se conoce como "predictivo inferencial" y es uno de los tipos más comunes llevados a cabo en la investigación empresarial y tecnológica. El diseño inferencial se usa cuando no es posible realizar un diseño totalmente experimental, y se recomienda realizar experimentos de campo.
Población objetivo y muestreo
Nuestra población objetivo de esta encuesta eran profesionales y líderes que trabajan en el sector de la tecnología y las transformaciones, o bien en ámbitos estrechamente relacionados, sobre todo los que estaban familiarizados con DevOps. Promocionamos la encuesta mediante listas de correo electrónico, promociones online, un panel online y redes sociales, y pedimos a los usuarios que compartieran la encuesta con sus redes (es decir, muestreo de bola de nieve).
Crear estructuras latentes
Formulamos nuestras hipótesis y conceptos a partir de ideas previamente validadas siempre que nos fue posible. Desarrollamos nuevos conceptos basados en la teoría, definiciones y la opinión de expertos. A continuación, tomamos medidas adicionales para aclarar nuestra intención de asegurarnos de que los datos recopilados en la encuesta tuvieran una alta probabilidad de ser fiables y válidos.14
Métodos de análisis estadístico
Análisis de clústeres Usamos el análisis de clústeres para identificar nuestros perfiles de rendimiento de envío de software en función de la frecuencia de despliegue, el plazo de entrega, el tiempo para restaurar el servicio y la tasa de fallos de cambios. Utilizamos un análisis de clase latente15 porque no teníamos ningún motivo teórico o del sector para tener un número predeterminado de clústeres, y usamos el criterio de información bayesiana 16 para determinar el número óptimo de clústeres.
Modelo de medición. Antes de llevar a cabo los análisis, identificamos construcciones que usaban el análisis de factores exploratorios con el análisis de componentes principales mediante la rotación varimax.17 Confirmamos las pruebas estadísticas para la validez y fiabilidad convergentes y divergentes mediante la varianza media extraída (AVE), la correlación, el valor alfa de Cronbach18 y la fiabilidad compuesta.
Modelización de ecuaciones estructurales. Probamos los modelos de ecuaciones estructurales (SEM) mediante el análisis de cuadrados parciales mínimos (PLS), que es un método SEM basado en la correlación.19
________________________
14. Churchill Jr, G. A. "A paradigm for developing better measures of marketing constructs", Journal of Marketing Research 16:1, (1979), 64–73.
15. Hagenaars, J. A., & McCutcheon, A. L. (Eds.). (2002). Applied latent class analysis. Cambridge University Press.
16. Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychological methods, 17(2), 228.
17. Straub, D., Boudreau, M. C., & Gefen, D. (2004). Validation guidelines for IS positivist research. Communications of the Association for Information systems, 13(1), 24.
18. Nunnally, J.C. Psychometric Theory. New York: McGraw-Hill, 1978
19. Hair Jr, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2021). “A primer on partial least squares structural equation modeling (PLS-SEM).” Sage publications
Más información
Obtén más información sobre las funciones de DevOps en https://cloud.google.com/devops/capacidhttps://cloud.google.com/devops/capabilities
Explora recursos sobre Site Reliability Engineering (SRE) en
Completa la encuesta breve de DevOps:
https://www.devops-research.com/quickcheck.html
Examina el programa de investigación de DevOps:
https://www.devops-research.com/research.html
Descubre el programa de modernización de aplicaciones de Google Cloud:
https://cloud.google.com/solutions/camp
Lee el informe "The ROI of DevOps Transformation: cómo cuantificar el impacto de las iniciativas de modernización":
https://cloud.google.com/resources/roi-of-devops-transformation-whitepaper
Consulta los informes anteriores de State of DevOps:
State of DevOps 2014: https://services.google.com/fh/files/misc/state-of-devops-2014.pdf
State of DevOps 2015: https://services.google.com/fh/files/misc/state-of-devops-2015.pdf
State of DevOps 2016: https://services.google.com/fh/files/misc/state-of-devops-2016.pdf
State of DevOps 2017: https://services.google.com/fh/files/misc/state-of-devops-2017.pdf
Accelerate State of DevOps 2018: https://services.google.com/fh/files/misc/state-of-devops-2018.pdf
Accelerate State of DevOps 2019:
https://services.google.com/fh/files/misc/state-of-devops-2019.pdf
¿Todo listo para iniciar la transformación basada en datos?
Infórmate sobre nuestro modelo de nube de datos, que optimizará la velocidad, la escalabilidad y la seguridad. Ver aquí


















