Accelerate State of DevOps 2021:
Was unterscheidet leistungsstarke und leistungsschwache Softwareteams? Im Jahresbericht 2021 untersuchen wir die Praktiken, die zu einer erfolgreichen Softwarebereitstellung und zur operativen Leistung beitragen, damit Sie Ihr Unternehmen mit den Elite-Performern vergleichen können. Mit den Erkenntnissen können Sie dann die wichtigsten Ergebnisse verbessern, Innovationen beschleunigen und sich von der Masse abheben.
Kurze Zusammenfassung
Der diesjährige Bericht „Accelerate State of DevOps“ des DevOps Research and Assessment-Teams (DORA) bei Google Cloud umfasst 7 Jahre Forschungsarbeit und Daten von mehr als 32.000 Fachleuten weltweit.
In unserer Recherche gehen wir auf die Fähigkeiten und Best Practices für Softwarebereitstellung, operative und organisatorische Leistung ein. Durch die Verwendung strenger statistischer Techniken versuchen wir, die Best Practices zu verstehen, die zu einer hervorragenden Technologiebereitstellung und hervorragenden Geschäftsergebnissen führen. Dazu präsentieren wir datengestützte Informationen über die effektivsten und effizientesten Methoden zur Entwicklung und Bereitstellung von Technologie.
Unsere Studie zeigt, dass eine optimale Softwarebereitstellung und reibungslose operative Abläufe die Unternehmensleistung mit Bezug auf technologische Transformationen verbessern. Damit Teams sich mit der Branche vergleichen können, verwenden wir eine Clusteranalyse, um aussagekräftige Leistungskategorien zu erstellen (z. B. Niedrig-, Mittel-, Hoch- oder Elite-Performer). Nachdem Ihre Teams eine Vorstellung von der aktuellen Leistung im Vergleich zur Branche erhalten haben, können Sie die Ergebnisse unserer Vorhersageanalyse nutzen, um Prozesse und Funktionen zur Verbesserung der wichtigsten Ergebnisse und letztendlich Ihrer relativen Position einzusetzen. In diesem Jahr machen wir insbesondere deutlich, wie wichtig es ist, die Zuverlässigkeitsziele zu erfüllen, die Sicherheit über die gesamte Softwarelieferkette hinweg zu schaffen, eine hochwertige interne Dokumentation zu erstellen und die Cloud optimal zu nutzen. Wir untersuchen auch, ob eine positive Teamkultur die Auswirkungen der Covid-19-Pandemie auf die Arbeit aus der Ferne abmildern kann.
Damit Verbesserungen auch sinnvoll sind, müssen Teams eine Philosophie der kontinuierlichen Verbesserung verfolgen. Mithilfe von Benchmarks können Sie messen, wo Sie aktuell stehen, und auf Basis der untersuchten Funktionen etwaige Einschränkungen ermitteln. Außerdem können Sie so testweise Verbesserungen vornehmen, um diese Einschränkungen zu beseitigen. Dieser Testprozess wird von Erfolgen und Misserfolgen geprägt sein, aber in beiden Fällen können Ihre Teams dann sinnvolle Maßnahmen ergreifen, da sie dadurch hilfreiche Erkenntnisse gewonnen haben.
Die wichtigsten Erkenntnisse
Die Hoch-Performer wachsen weiter und setzen neue Maßstäbe.
Elite-Performer machen jetzt 26 % der Teams in unserer Studie aus und haben ihre Vorlaufzeiten für Änderungen in der Produktion verkürzt. Die Branche wächst kontinuierlich und ihre Teams profitieren davon.
SRE und DevOps ergänzen die Strategie.
Teams, die moderne operative Praktiken unserer Freunde im Site Reliability Engineering (SRE) nutzen, melden eine höhere operative Leistung. Teams, die sowohl Bereitstellung als auch operative Exzellenz priorisieren, melden die höchste organisatorische Leistung.
Weitere Teams nutzen die Cloud und sehen erhebliche Vorteile.
Teams verschieben weiterhin Arbeitslasten in die Cloud und diejenigen, die alle fünf Funktionen der Cloud nutzen, verzeichnen eine Zunahme der Leistung von Softwarebereitstellungs- und Betriebsabläufen sowie der Unternehmensleistung. Immer mehr Unternehmen setzen auch auf Multi-Cloud, sodass Teams die einzigartigen Funktionen verschiedener Anbieter nutzen können.
Eine sichere Softwarelieferkette ist unerlässlich und verbessert die Unternehmensleistung.
Aufgrund der deutlichen Zunahme bösartiger Angriffe in den letzten Jahren müssen Organisationen von reaktiven Praktiken zu proaktiven und diagnostischen Maßnahmen wechseln. Teams, die Sicherheitspraktiken in ihrer gesamten Softwarelieferkette einbinden, stellen Software schnell, zuverlässig und sicher bereit.
Eine lückenlose Dokumentation ist die Grundlage für das erfolgreiche Implementieren von DevOps-Funktionen.
Zum ersten Mal haben wir die Qualität der internen Dokumentation und der Praktiken gemessen, die zu dieser Qualität beitragen. Teams mit hochwertiger Dokumentation können technische Verfahren besser implementieren und insgesamt eine bessere Leistung erzielen.
Eine positive Teamkultur beugt bei herausfordernden Umständen einem Burnout vor.
Die Teamkultur wirkt sich stark darauf aus, ob ein Team Software bereitstellen und die organisatorischen Ziele erreichen oder sogar übertreffen kann. Inklusive Teams mit generativer1,2, Kultur erlebten während der Coronakrise seltener einen Burnout.
____________________________
1. Nach Westrums Typologie der Organisationskultur bezieht sich eine generative Teamkultur auf Teams, die stark kooperieren, Silos aufbrechen, Misserfolge zu Untersuchungen führen lassen und das Risiko der Entscheidungsfindung teilen.
2. Westrum, R. (2004). „A typology of organizational cultures“. BMJ Quality & Safety, 13(suppl 2), ii22-ii27.
Wie schneiden wir im Vergleich ab?
Möchten Sie wissen, wie Ihr Team im Vergleich zu den Teams anderer Unternehmen der Branche abschneidet? Dieser Abschnitt enthält die neueste Benchmarkbewertung der DevOps-Leistung diverser Firmen.
Wir untersuchen, wie Teams Softwaresysteme entwickeln, bereitstellen und betreiben. Anschließend teilen wir die Teilnehmer in vier Leistungscluster auf: Elite, hohe, mittlere und geringe Leistung. Durch einen Vergleich der Leistung Ihres Teams mit der Leistung der einzelnen Cluster können Sie sehen, wo Sie sich im Kontext der Ergebnisse in diesem Bericht befinden.
Softwarebereitstellungsleistung und operative Leistung
Um den Anforderungen einer sich ständig ändernden Branche gerecht zu werden, müssen Unternehmen Software schnell und zuverlässig bereitstellen und betreiben. Je schneller Ihre Teams an der Software Änderungen vornehmen können, desto schneller können Sie Ihren Kundinnen und Kunden einen Mehrwert bieten, Tests durchführen und so wertvolles Feedback erhalten. Mit sieben Jahren der Datenerfassung und Forschung haben wir vier Messwerte entwickelt und validiert, die die Leistung der Softwarebereitstellung messen. Seit 2018 haben wir einen fünften Messwert hinzugefügt, um Betriebsfunktionen zu erfassen.
Teams, die bei allen fünf Messwerten gut abschneiden, weisen auch eine außergewöhnlich hohe Unternehmensleistung auf. Wir fassen diese fünf Messwerte unter dem Begriff Softwarebereitstellungs- und operative Leistung (Software Delivery and Operational Performance, SDO) zusammen. Bei diesen Messwerten liegt der Schwerpunkt auf Systemergebnissen. Dadurch werden häufige Fehler von Softwaremesswerten vermieden, z. B. Aufgabenbereiche gegeneinander auszuspielen und lokale Optimierungen auf Kosten der Gesamtergebnisse vorzunehmen.
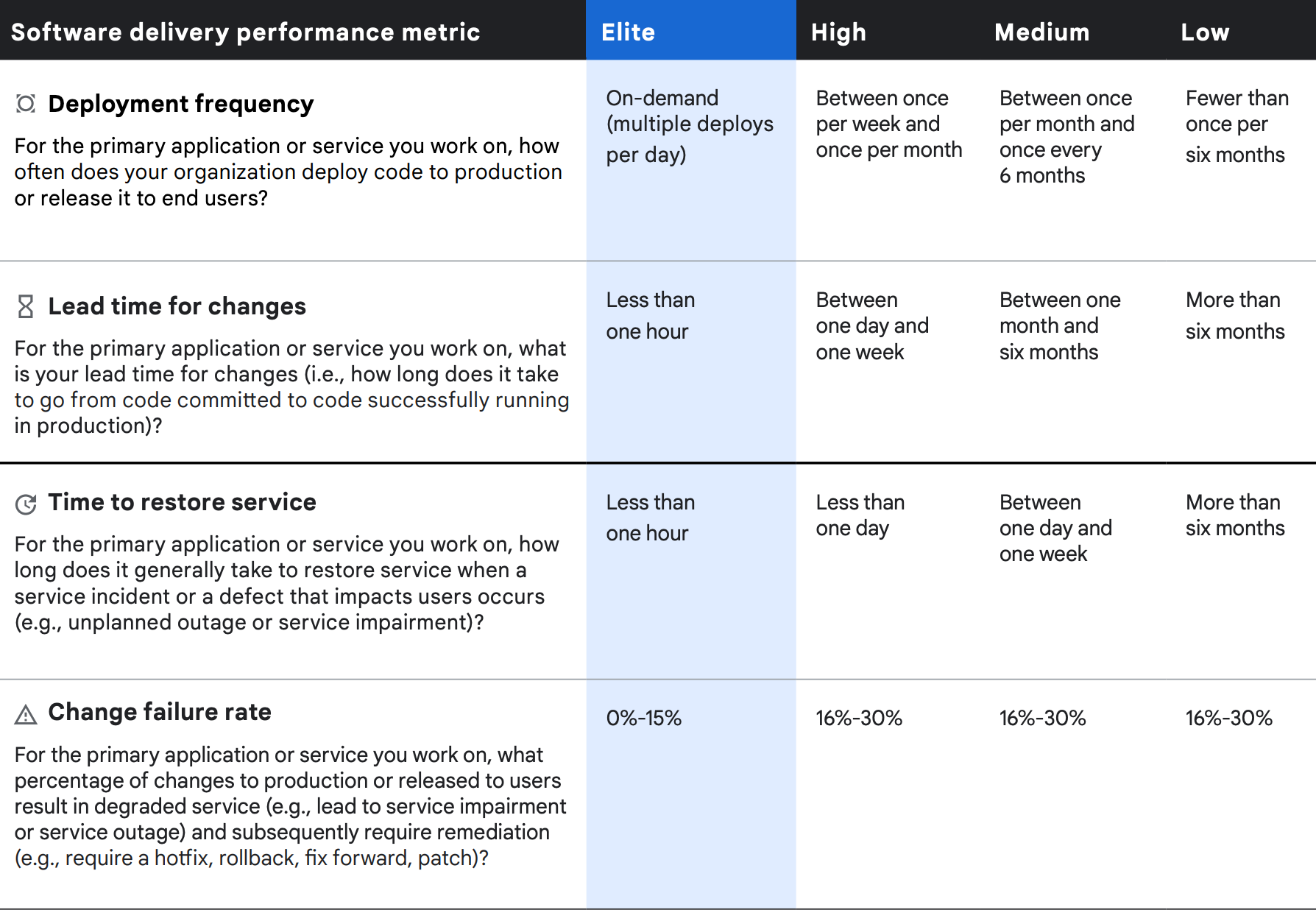
Vier Messwerte zur Auslieferungsleistung
Die vier Messwerte der Softwarebereitstellungsleistung lassen sich in Durchsatz und Stabilität ausdrücken. Der Durchsatz wird anhand der Vorlaufzeit von Codeänderungen (also der Zeit vom Code-Commit bis zum Release in der Produktion) und der Bereitstellungshäufigkeit gemessen. Wir messen die Stabilität anhand der benötigten Zeit bis zur Dienstwiederherstellung nach einem Vorfall und anhand der Änderungsfehlerquote.
Wie bereits erwähnt, zeigt die Clusteranalyse der vier Messwerte für die Softwarebereitstellung vier verschiedene Leistungsprofile auf – Elite, Hoch, Mittel und Niedrig – und statistisch signifikante Unterschiede zwischen ihnen im Durchsatz und bei den Stabilitätsmessungen. Wie in den Vorjahren sind unsere leistungsstärksten Ergebnisse hinsichtlich aller vier Messungen deutlich besser, während leistungsschwache Kampagnen in allen Bereichen deutlich schlechter abschneiden.
Der fünfte Messwert: von der Verfügbarkeit bis zur Zuverlässigkeit
Der fünfte Messwert steht für die operative Leistung und ist ein Maß für moderne betriebliche Verfahren. Der wichtigste Messwert für die betriebliche Leistung ist die Zuverlässigkeit. Dies ist das Ausmaß, in dem ein Team Versprechen und Annahmen über die verwendete Software einhalten kann. In der Vergangenheit wurde eher die Verfügbarkeit als die Zuverlässigkeit gemessen. Verfügbarkeit ist jedoch ein bestimmter Fokus beim Reliability Engineering, sodass wir unsere Messung auf Zuverlässigkeit ausgeweitet haben. Dadurch sind Verfügbarkeit, Latenz, Leistung und Skalierbarkeit breiter vertreten. Konkret haben wir die Teilnehmenden gebeten, zu bewerten, wie gut sie in der Lage sind, ihre Zuverlässigkeitsziele zu erreichen bzw. zu übertreffen. Wir haben festgestellt, dass Teams mit unterschiedlicher Bereitstellungsleistung bessere Ergebnisse erzielen, wenn sie gleichzeitig die operative Leistung priorisieren.
Wie in den bisherigen Berichten haben wir die Spitzenleistungen mit denen mit geringer Leistung verglichen, um die Auswirkungen bestimmter Funktionen zu veranschaulichen. Dieses Jahr haben wir aber versucht, die Auswirkungen der betrieblichen Leistung zu berücksichtigen. In allen Kategorien (z. B. der Spitzenleistung) bei der Bereitstellung sahen wir erhebliche Vorteile für mehrere Ergebnisse, wenn Teams ihre Ziele priorisieren oder übertreffen.
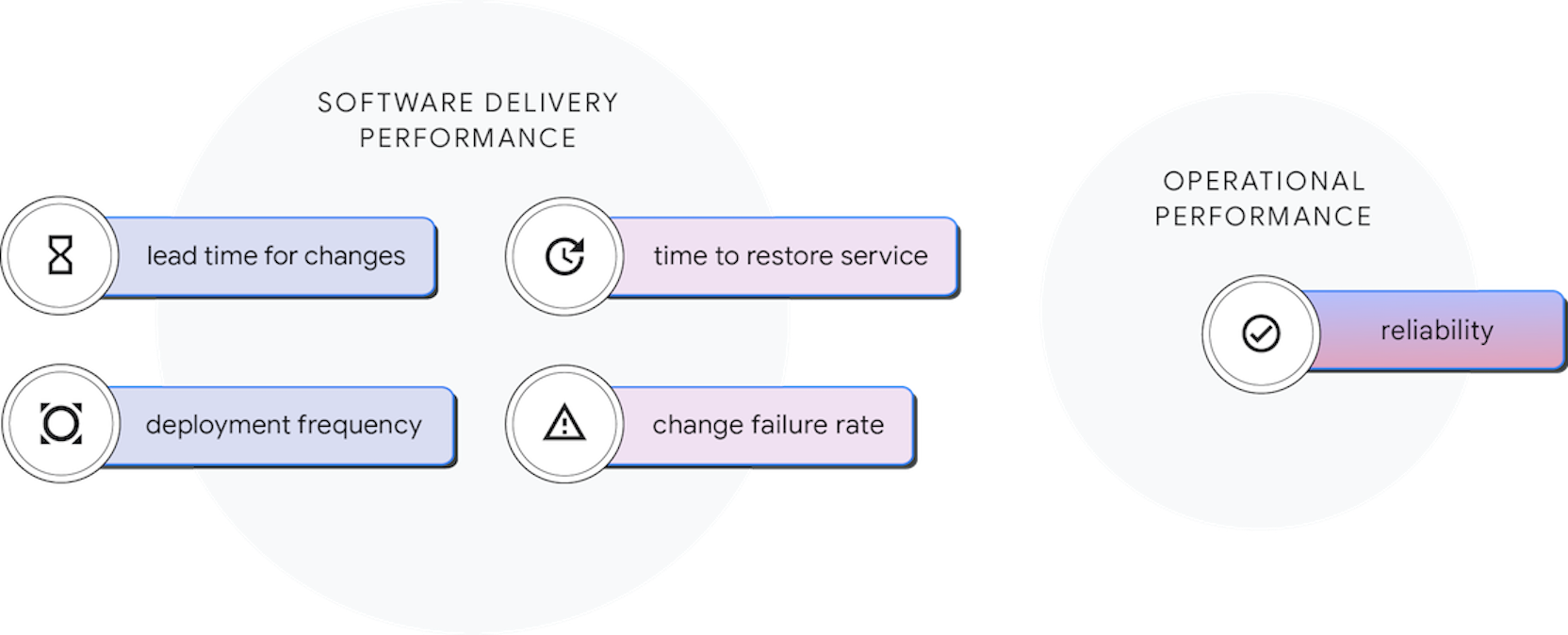
Die Branche wächst kontinuierlich
Wir beobachten weiterhin jedes Jahr, wie die Branche die Möglichkeit beschleunigt, Software schneller und stabiler bereitzustellen. Zum ersten Mal machen unsere Hoch- und Elite-Performer zwei Drittel der Teilnehmer aus. Darüber hinaus haben die diesjährigen Elite-Performer noch einmal höhere Maßstäbe gesetzt und die Vorlaufzeit für Änderungen im Vergleich zu vorherigen Bewertungen gesenkt, z. B. von weniger als einem Tag im Jahr 2019 auf weniger als eine Stunde im Jahr 2021. Außerdem haben erstmals nur Elite-Performer ihre Änderungsfehlerquote im Vergleich zu den Vorjahren minimiert, in denen mittlere und hohe Performer das auch konnten.
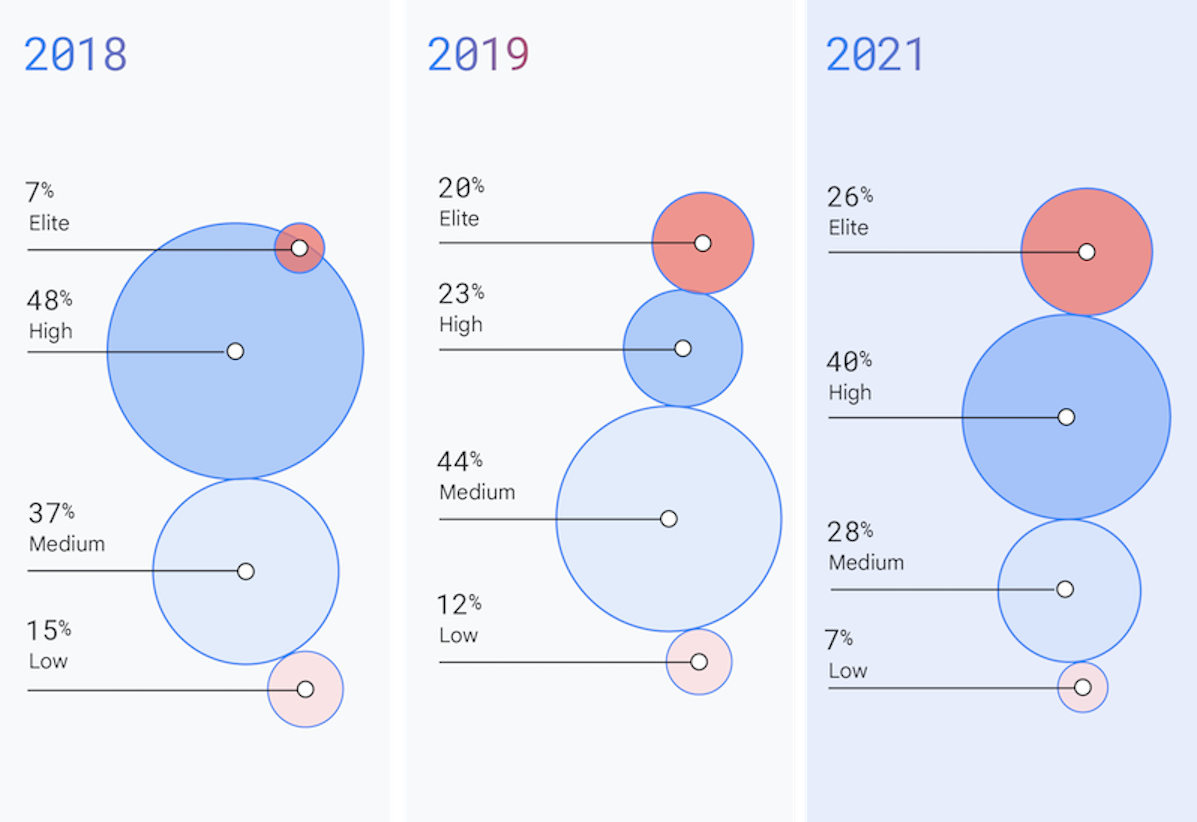
Durchsatz und Stabilität
Durchsatz
Bereitstellungshäufigkeit
In den letzten Jahren berichtete die Elite-Gruppe darüber, dass sie bei Bedarf regelmäßig bereitstellt und pro Tag mehrere Bereitstellungen ausführt. Im Vergleich dazu konnten Niedrig-Performer weniger als einmal pro sechs Monate (weniger als zwei pro Jahr) bereitstellen, was im Vergleich zu 2019 ein weiterer Rückgang der Leistung ist. Die normalisierten jährlichen Bereitstellungszahlen reichen von 1.460 Bereitstellungen pro Jahr (berechnet als vier Bereitstellungen pro Tag × 365 Tage) für die Hoch-Performer bis 1,5 Bereitstellungen pro Jahr für Niedrig-Performer (durchschnittlich zwei Bereitstellungen und eine Bereitstellung). Diese Analyse zeigt, dass Elite-Performer Code 973-mal häufiger bereitstellen als Niedrig-Performer.
Vorlaufzeit für Änderungen
Das ist eine Verbesserung gegenüber 2019. Die Elite-Performer melden eine Vorlaufzeit von weniger als einer Stunde, wobei die Vorlaufzeit als die Zeit von der Übergabe des Codes bis zu seiner erfolgreichen Bereitstellung in der Produktion gemessen wird. Das ist eine Leistungssteigerung im Vergleich zu 2019, als unsere leistungsstärksten Performer Änderungen von Vorlaufzeiten von weniger als einem Tag gemeldet haben. Im Gegensatz zu unseren Elite-Performern brauchten Niedrig-Performer Vorlaufzeiten von mehr als sechs Monate. Mit Vorlaufzeiten von einer Stunde für Elite-Performer (konservative Schätzung am oberen Ende von „weniger als einer Stunde“) und 6.570 Stunden für Niedrig-Performer – berechnet aus dem Durchschnitt von 8.760 Stunden pro Jahr und 4.380 Stunden über 6 Monate – hat die Elite-Gruppe sich 6.570-mal schneller geändert als die Niedrig-Performer.
Stability
Zeit bis zur Dienstwiederherstellung
Die Elite-Gruppe meldete eine Zeit von weniger als einer Stunde bis zur Wiederherstellung des Dienstes, während die Niedrig-Performer von mehr als sechs Monaten berichteten. Für diese Berechnung haben wir konservative Zeiträume ausgewählt: eine Stunde für Hoch-Performer und den Durchschnitt von einem Jahr (8.760 Stunden) und von sechs Monaten (4.380 Stunden) für Niedrig-Performer. Aufgrund dieser Zahlen haben Elite-Performer 6.570-mal schneller Zeit zur Wiederherstellung eines Dienstes als Niedrig-Performer. Die Zeit zur Wiederherstellung der Dienstleistung blieb für Elite-Performer gleich und stieg im Vergleich zu 2019 für Niedrig-Performer.
Änderungsfehlerquote
Elite-Performer meldeten eine Änderungsfehlerquote zwischen 0 % und 15 %, während Niedrig-Performer eine Änderungsfehlerquote von 16 % bis 30 % melden. Der Mittelwert zwischen diesen beiden Bereichen zeigt eine Änderungsfehlerquote von 7,5 % bei Elite-Performern und 23 % bei Niedrig-Performern. Änderungsfehlerquoten sind für Elite-Performer dreimal besser als solche für Niedrig-Performer. In diesem Jahr blieben die Änderungsfehlerquoten für Elite-Performer gleich und verbesserten sich im Vergleich zu 2019 für Niedrig-Performer. Für Gruppen dazwischen hat sich jedoch der Wert verschlechtert.
Elite-Performer
Wenn wir die Elite-Gruppe mit den Niedrig-Performern vergleichen, haben wir festgestellt, dass Elite-Performer:
- 973-mal häufigere Codebereitstellungen haben
- 6570-mal schnellere Vorlaufzeit vom Commit bis zur Bereitstellung haben
- 3-mal geringere Änderungsfehlerquote (Änderungen sind um 1/3 weniger fehlerwahrscheinlich)
- 6570-mal schnellere Wiederherstellung nach Vorfällen
Wie verbessern wir uns?
Wie verbessern wir die Leistung der SDO und die Unternehmensleistung? Unsere Forschung bietet evidenzbasierte Orientierungshilfen, die Ihnen dabei helfen, sich auf die Möglichkeiten zu konzentrieren, die zur Leistungssteigerung beitragen.
Im diesjährigen Bericht wurden die Auswirkungen von Cloud, SRE-Verfahren, Sicherheit, technischen Praktiken und Kultur untersucht. In diesem Abschnitt stellen wir jede dieser Funktionen vor und erläutern, wie sie sich auf verschiedene Ergebnisse auswirken. Für diejenigen, die mit den State of DevOps-Forschungsmodellen von DORA vertraut sind, haben wir eine Onlineressource erstellt, die das diesjährige Modell und alle früheren Modelle hostet.3
____________________________
3. https://devops-research.com/models.htm
____________________________
Cloud
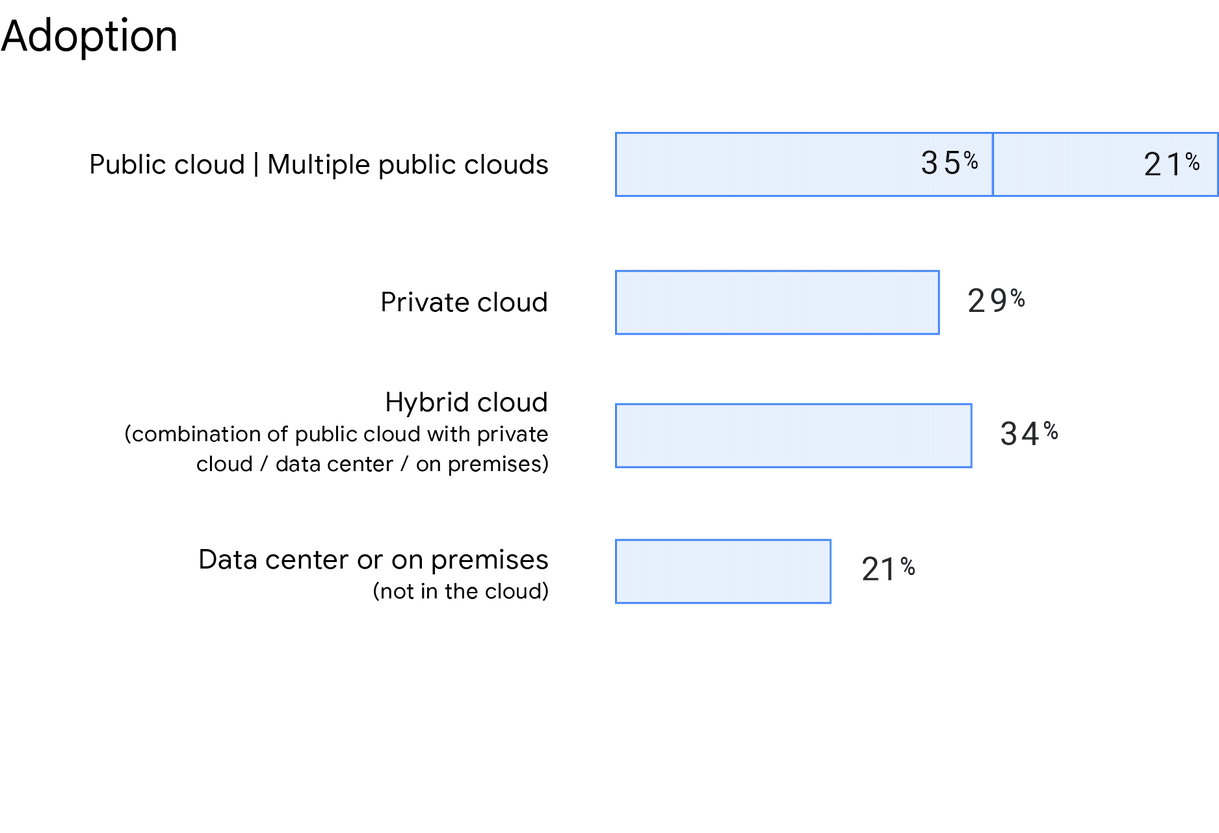
Immer mehr Unternehmen entscheiden sich gemäß Accelerate State of DevOps 2019 für Multi-Cloud- und Hybrid-Cloud-Lösungen. In unserer Umfrage wurden die Teilnehmer gefragt, wo ihr Hauptdienst oder ihre primäre Anwendung gehostet wurde. Die Nutzung der öffentlichen Cloud steigt an. 56 % der Befragten gaben an, dass sie eine öffentliche Cloud (einschließlich mehrerer öffentlicher Clouds) verwenden. Das ist eine Steigerung von 5 % im Vergleich zu 2019. In diesem Jahr haben wir uns auch speziell über die Multi-Cloud-Nutzung informiert. 21 % der Teilnehmerinnen und Teilnehmer gaben an, dass sie in mehreren öffentlichen Clouds bereitgestellt haben. 21 % der Befragten sagten, dass sie die Cloud nicht nutzen, und haben stattdessen ein Rechenzentrum oder eine lokale Lösung verwendet. 34 % der Teilnehmer berichten von der Nutzung einer Hybrid-Cloud und 29 % von einer privaten Cloud.
Geschäftsergebnisse mit Hybrid- und Multi-Cloud beschleunigen
Dieses Jahr verzeichnen wir ein Wachstum beim Einsatz von Hybrid- und Multi-Cloud-Umgebungen, was sich in erheblichem Maße auf die Ergebnisse auswirkt, die Unternehmen wichtig sind. Bei Teilnehmern, die Hybrid- oder Multi-Cloud-Umgebungen nutzen, ist die Wahrscheinlichkeit, dass sie ihre Unternehmensleistungsziele übertreffen, 1,6-mal höher als bei denen, die dies nicht tun. Auch gibt es deutliche Auswirkungen auf die SDO: Nutzer von Hybrid- und Multi-Cloud-Umgebungen haben eine 1,4-mal höhere Wahrscheinlichkeit, in puncto Bereitstellungshäufigkeit, Vorlaufzeit für Änderungen, Zeit zur Wiederherstellung, Änderungsfehlerquote und Zuverlässigkeit eine Top-Leistung zu erzielen.
Warum Multi-Cloud?
Ähnlich wie bei unserer Bewertung im Jahr 2018 haben wir die Teilnehmer gebeten, ihre Gründe für die Nutzung mehrerer Anbieter öffentlicher Clouds zu melden. Statt alle zutreffenden Antworten auszuwählen, haben wir die Teilnehmer in diesem Jahr gebeten, ihren Hauptgrund für die Verwendung mehrerer Anbieter zu melden. Mehr als ein Viertel der 26 % der Teilnehmer haben dabei die Vorteile der einzelnen Cloud-Anbieter genutzt. Wenn dadurch die Teilnehmer einen zusätzlichen Anbieter auswählen, müssen sie zwischen ihrem aktuellen und dem anderen Anbieter unterscheiden. Der zweithäufigste Grund für den Wechsel zu Multi-Cloud war die Verfügbarkeit (22 %). Kein Wunder, dass Teilnehmer, die mehrere Cloud-Anbieter nutzen, die Zuverlässigkeitsziele 1,5-mal eher erreichen oder übertreffen.
Hauptgrund für die Verwendung mehrerer Anbieter
Individuelle Vorteile für jeden Anbieter nutzen | 26 % |
Verfügbarkeit | 22 % |
Notfallwiederherstellung | 17 % |
Einhaltung gesetzlicher Vorschriften | 13 % |
Sonstiges | 08 % |
Verhandlungstaktik oder Beschaffungsanforderung | 08 % |
Mangelndes Vertrauen in einen Anbieter | 06 % |
Individuelle Vorteile für jeden Anbieter nutzen
26 %
Verfügbarkeit
22 %
Notfallwiederherstellung
17 %
Einhaltung gesetzlicher Vorschriften
13 %
Sonstiges
08 %
Verhandlungstaktik oder Beschaffungsanforderung
08 %
Mangelndes Vertrauen in einen Anbieter
06 %
Änderungen an den Benchmarks
Wie Sie die Cloud-Infrastruktur implementieren
In der Vergangenheit haben wir festgestellt, dass nicht alle Befragten die Cloud auf die gleiche Weise einführen. Dies führt zu Unterschieden darin, wie effektiv die Cloud-Einführung für bessere Geschäftsergebnisse ist. Wir werden dieser Einschränkung gerecht, indem wir uns auf die wesentlichen Merkmale des Cloud-Computings – wie sie vom National Institute of Standards and Technology (NIST) definiert wurden – konzentriert haben. Anhand der NIST Definition of Cloud Computing haben wir die Auswirkungen wesentlicher Praktiken auf die SDO-Leistung und nicht nur die Auswirkungen der Cloud-Einführung auf SDO untersucht.
Zum dritten Mal stellen wir fest, dass es wirklich darauf ankommt, wie Teams ihre Cloud-Services implementieren, und nicht nur darauf, dass sie Cloud-Technologien nutzen. Bei Elite-Performern war die Wahrscheinlichkeit, dass sie alle wichtigen NIST-Cloud-Eigenschaften erfüllen, 3,5-mal höher. Nur 32 % der Befragten, die angaben, dass sie die Cloud-Infrastruktur nutzen, stimmten zu oder stimmen stark zu, dass sie alle fünf wichtigen Merkmale des Cloud-Computings von NIST erfüllten – ein Anstieg von 3 % im Vergleich zu 2019. Insgesamt hat die Nutzung der NIST-Eigenschaften von Cloud-Computing um 14-19 % zugenommen. Die schnelle Elastizität zeigte dabei den größten Anstieg.
Selfservice on demand
Nutzer können Computing-Ressourcen nach Bedarf automatisch und ohne menschliche Interaktionen des Anbieters bereitstellen.
73 % der Teilnehmerinnen und Teilnehmer haben On-Demand-Selfservice verwendet. Das ist ein Anstieg von 16 % gegenüber 2019.
Erweiterter Netzwerkzugriff
Die Funktionen sind allgemein verfügbar und können über mehrere Clients wie Smartphones, Tablets, Laptops und Workstations aufgerufen werden.
74 % der Befragten haben umfassenden Netzwerkzugriff verwendet, eine Steigerung um 14 % gegenüber 2019.
Ressourcen-Pooling
Anbieterressourcen werden in einem mehrmandantenfähigen Modell bereitgestellt, wobei physische und virtuelle Ressourcen dynamisch zugewiesen und bei Bedarf neu zugewiesen werden. Der Kunde hat in der Regel keine direkte Kontrolle über den genauen Standort der bereitgestellten Ressourcen, kann jedoch den Standort auf einer höheren Abstraktionsebene angeben, z. B. Land, Bundesland oder Rechenzentrum.
73 % der Befragten haben das Pooling genutzt, 15 % mehr als 2019.
Schnelle Elastizität
Ressourcen können elastisch und schnell nach Bedarf bereitgestellt (hochskaliert) und freigegeben (herunterskaliert) werden. So hat es den Anschein, dass sie unbegrenzt sind und jederzeit in beliebiger Menge in Anspruch genommen werden können.
77 % der Befragten verwendeten eine schnelle Elastizität, 18 % mehr als 2019.
Gemessener Dienst
Cloud-Systeme steuern und optimieren die Ressourcennutzung automatisch. Dabei wird eine Metering-Funktion auf einer Ebene der Abstraktionsstufe verwendet, die dem Diensttyp entspricht, z. B. Speicher, Verarbeitung, Bandbreite und aktive Nutzerkonten. Die Ressourcennutzung kann mit dem Ziel der Transparenz überwacht, gesteuert und gemeldet werden.
78 % der Befragten haben den gemessenen Dienst verwendet, eine Steigerung um 16 % gegenüber 2019.
SRE und DevOps
Während die DevOps-Community auf öffentlichen Konferenzen und Diskussionen aufkam, entstand innerhalb von Google eine gleichgesinnte Bewegung: Site Reliability Engineering (SRE). SRE und ähnliche Ansätze wie die Facebook-Produktionstechnik nutzen viele der gleichen Ziele und Techniken, die für DevOps motivierend sind. Im Jahr 2016 kam SRE offiziell in die öffentliche Diskussion, als das erste Buch4 zum Thema Site Reliability Engineering veröffentlicht wurde. Die Bewegung ist seither gewachsen und heute arbeitet eine globale Community von SRE-Experten zusammen an Praktiken für technische Vorgänge.
Natürlich kam es natürlich zu Verwirrung. Was ist der Unterschied zwischen SRE und DevOps? Muss ich eine der beiden Optionen auswählen? Welche wäre besser? In der Praxis gibt es hier keinen Konflikt. SRE und DevOps sind komplementär. Unsere Forschung zeigt die Abstimmung. SRE ist eine Lerndisziplin, bei der die funktionsübergreifende Kommunikation und die psychologische Sicherheit im Mittelpunkt stehen. Dies sind die Werte, die den Kern der leistungsorientierten generativen Kultur bilden, die für Elite-DevOps-Teams typisch ist. SRE basiert auf seinen Kernprinzipien und bietet praktische Techniken, einschließlich des SLI-/SLO-Messwertframeworks (Service Level Indicator/Service Level Objective). Genau wie mit dem schlanken Produkt-Framework angegeben wird, wie die schnellen Kundenfeedback-Zyklen, die durch unsere Forschung unterstützt werden, erreicht werden können, gibt das SRE-Framework Definitionen für Praktiken und Tools vor, die die Teamfähigkeit kontinuierlich verbessern können, Versprechungen ihren Nutzern gegenüber einzuhalten.
2021 haben wir unsere Untersuchung auf den Betrieb ausgeweitet und sie von der Analyse der Dienstverfügbarkeit auf die allgemeinere Kategorie der Zuverlässigkeit erweitert. In der diesjährigen Umfrage wurden mehrere von SRE-Verfahren inspirierte Artikel eingeführt, um zu beurteilen, inwieweit Teams:
- Zuverlässigkeit beim nutzerbezogenen Verhalten festlegen
- SLI-/SLO-Messwertframework zur Priorisierung von Aufgaben nach Fehlerbudgets einsetzen
- Automatisierung nutzen, um manuelle Arbeit und störende Warnmeldungen zu reduzieren
- Protokolle und Übungsdurchläufe zur Vorbereitung auf Zwischenfälle definieren
- Zuverlässigkeitsprinzipien während des gesamten Softwarebereitstellungszyklus einbinden („Verschiebung zum Verbessern der Zuverlässigkeit“)
Die Analyse der Ergebnisse ergab, dass Teams, die mit diesen modernen operativen Praktiken Erfolg haben, 1,4-mal eher eine höhere SDO-Leistung und 1,8-mal eher bessere Geschäftsergebnisse melden.
SRE-Praktiken wurden von einer Mehrheit der Teams in unserer Studie angewendet: 52 % der Teilnehmerinnen und Teilnehmer sagten, dass sie diese Methoden in gewissem Umfang genutzt haben, auch wenn die Intensität der Akzeptanz zwischen den Teams stark variiert. Die Daten zeigen, dass die Verwendung dieser Methoden eine höhere Zuverlässigkeit und eine höhere Gesamtleistung der SDO prognostiziert: SRE steigert den DevOps-Erfolg.
Darüber hinaus haben wir herausgefunden, dass ein gemeinsames Verantwortungsmodell, das die Vorgänge widerspiegelt, mit denen Entwickler und Betreiber gemeinsam zuverlässig zusammenarbeiten können, auch bessere Zuverlässigkeitsergebnisse vorhersagt.
SRE verbessert nicht nur objektive Leistungskennzahlen, sondern auch die Arbeit der technischen Fachkräfte. In der Regel sind Personen mit einer hohen Anzahl von Vorgängen anfällig für Burnout, aber SRE hat einen positiven Effekt. Je mehr Teams SRE-Praktiken einsetzen, desto unwahrscheinlicher ist ein Burnout. SRE kann auch zur Optimierung von Ressourcen beitragen. Teams, die ihre Zuverlässigkeitsziele über die Anwendung von SRE-Verfahren erreichen, berichten, dass sie mehr Zeit für das Schreiben von Code haben als Teams, die SRE nicht anwenden.
Unsere Untersuchungen haben ergeben, dass die Teams bei SDO-Leistungen – von niedrig bis Elite – wahrscheinlich von der zunehmenden Nutzung der SRE-Praktiken profitieren können. Je besser die Leistung eines Teams ist, desto größer ist die Wahrscheinlichkeit, dass es moderne Betriebsarten verwendet: Bei den Elite-Performer ist es 2,1-mal wahrscheinlicher, dass sie SRE-Verfahren einsetzen, als bei den Niedrig-Performern. Aber selbst Teams, die auf den höchsten Ebenen arbeiten, haben Wachstumspotenzial: Nur 10 % der Befragten der Elite-Performer gaben an, dass ihre Teams alle von uns untersuchten SRE-Verfahren vollständig umgesetzt haben. Da die Leistung der SDO in allen Branchen immer weiter vorangeht, ist der Ansatz jedes Teams für den Betrieb ein entscheidender Faktor für die laufende Verbesserung von DevOps.
____________________________
4. Betsy Beyer et al., Eds., Site Reliability Engineering (O'Reilly Media, 2016).
____________________________
Dokumentation und Sicherheit
Dokumentation
In diesem Jahr haben wir uns mit der Qualität der internen Dokumentation befasst, d. h. Dokumentationen wie Handbücher, README-Dateien und sogar Codekommentare – für die Dienste und Anwendungen, mit denen ein Team beschäftigt ist. Wir haben die Qualität der Dokumentation danach gemessen, wie stark Folgendes auf die Dokumentation zutrifft:
- Hilft Lesern, ihre Ziele zu erreichen
- Ist präzise, aktuell und umfassend
- Sie ist leicht zu finden, gut organisiert und klar.5
Das Aufzeichnen und Zugreifen auf Informationen über interne Systeme ist ein wichtiger Teil der technischen Arbeit eines Teams. Wir haben festgestellt, dass etwa 25 % der Teilnehmer hochwertige Dokumentationen haben. Die Auswirkungen dieser Dokumentation sind deutlich: Teams mit höherer Dokumentation haben mit 2,4-facher Wahrscheinlichkeit eine bessere SDO-Leistung (Softwarebereitstellung und Betrieb). Teams mit guter Dokumentation liefern Software schneller und zuverlässiger als Teams mit schlechter Dokumentation. Die Dokumentation muss nicht perfekt sein. Unsere Studien haben gezeigt, dass jede Verbesserung der Dokumentationsqualität einen positiven und direkten Einfluss auf die Leistung hat.
In der heutigen Technologieumgebung gibt es zunehmend komplexere Systeme sowie Experten und spezielle Rollen für verschiedene Aspekte dieser Systeme. Ob Sicherheit oder Test – die Dokumentation ist entscheidend, um Fachwissen und Anleitungen zwischen diesen speziellen untergeordneten Teams und dem gesamten Team zur Verfügung zu stellen.
Wir haben festgestellt, dass die Dokumentationsqualität den Erfolg der Teams bei der Implementierung technischer Praktiken voraussagt. Dadurch werden wiederum technische Verbesserungen des Systems vorhergesagt, z. B. Beobachtbarkeit, kontinuierliche Tests und Bereitstellungsautomatisierung. Unsere Erfahrung zeigt, dass Teams mit hochwertiger Dokumentation …
- mit einer 3,8-mal höheren Wahrscheinlichkeit Sicherheitsmaßnahmen implementieren
- mit einer 2,4-mal höheren Wahrscheinlichkeit die Zuverlässigkeitsziele erreichen oder übertreffen
- mit einer 3,5-mal höheren Wahrscheinlichkeit Site Reliability Engineering (SRE) implementieren
- mit einer 2,5-mal höheren Wahrscheinlichkeit die Cloud vollständig nutzen
Dokumentationsqualität verbessern
Technische Arbeit erfordert die Suche und Verwendung von Informationen, aber die Qualität der Dokumentation hängt davon ab, wer die Inhalte verfasst und verwaltet. Unsere Studie im Jahr 2019 hat gezeigt, dass der Zugriff auf interne und externe Informationsquellen die Produktivität unterstützt. Die diesjährige Studie geht noch einen Schritt weiter und untersucht die Qualität der aufgerufenen Dokumentation, auf die zugegriffen wird, sowie die Praktiken, die die Dokumentationsqualität beeinflussen.
Unsere Forschung zeigt, dass die folgenden Praktiken einen erheblichen positiven Einfluss auf die Dokumentationsqualität haben:
Dokumentieren kritischer Anwendungsfälle für Ihre Produkte und Dienstleistungen. Was Sie über ein System dokumentieren, ist wichtig. In Anwendungsfällen können Ihre Leser die Informationen und Ihre Systeme problemlos einsetzen.
Erstellen klarer Richtlinien zum Aktualisieren und Bearbeiten vorhandener Dokumentationen. Ein Großteil der Dokumentationsarbeit erfordert die Pflege vorhandener Inhalte. Wenn Teammitglieder wissen, wie sie Updates vornehmen oder ungenaue oder veraltete Informationen entfernen, kann das Team die Dokumentationsqualität aufrechterhalten, auch wenn sich das System mit der Zeit ändert.
Festlegen von Inhabern. Teams mit einer guten Dokumentation haben eher eine klar definierte Inhaberschaft. Die Inhaberschaft ermöglicht ausdrückliche Verantwortung für das Schreiben neuer Inhalte und das Aktualisieren oder Überprüfen von Änderungen an vorhandenen Inhalten. In den Teams, die eine hochwertige Dokumentation haben, ist die Wahrscheinlichkeit höher, dass für alle wichtigen Features der Anwendungen, an denen sie arbeiten, Dokumentation geschrieben wird. Eine klare Inhaberschaft hilft, diese umfassende Abdeckung zu erreichen.
Einbeziehen der Dokumentation als Teil der Softwareentwicklung. Teams, die Dokumentationen erstellt und aktualisiert haben, als sich das System geändert hat, haben eine höhere Qualität der Dokumentation. Wie das Testen ist das Erstellen und Verwalten von Dokumentationen ein wesentlicher Bestandteil eines leistungsstarken Softwareentwicklungsprozesses.
Anerkennen der Dokumentationsarbeit während Leistungsüberprüfungen und Werbeaktionen. Anerkennung korreliert mit der allgemeinen Dokumentationsqualität. Das Schreiben und Verwalten von Dokumentationen ist ein wesentlicher Bestandteil der Softwareentwicklung. Wird sie so behandelt, wird die Qualität verbessert.
Weitere Ressourcen, die die Qualitätsdokumentation unterstützen:
- Training zum Schreiben und Verwalten von Dokumenten
- Automatisierte Tests für Codebeispiele oder unvollständige Dokumentationen
- Richtlinien, wie z. B. Dokumentationsleitfäden und Leitfäden für das Schreiben für ein globales Publikum
Dokumentation ist die Grundlage für das erfolgreiche Implementieren von DevOps-Funktionen. Eine höherwertige Dokumentation verstärkt die Ergebnisse von Investitionen in einzelne DevOps-Funktionen wie Sicherheit, Zuverlässigkeit und vollständige Nutzung der Cloud. Die Implementierung von Verfahren zur Unterstützung der hochwertigen Dokumentation zahlt sich durch bessere technische Funktionen und höhere SDO-Leistung aus.
____________________________
5. Qualitätsmesswerte anhand bestehender Forschungsergebnisse zu technischen Dokumentationen, z. B.:
— Aghajani, E. et al. (2019). Software Documentation Issues Unveiled. Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering, 1199-1210. https://doi.org/10.1109/ICSE.2019.00122
— Plösch, R. Dautovic, A. und Saft, M. (2014). The Value of Software Documentation Quality. Proceedings of the International Conference on Quality Software, 333-342. https://doi.org/10.1109/QSIC.2014.22
— Zhi, J. et al. (2015). Cost benefits and quality of software development documentation: A systematic mapping. Journal of Systems and Software, 99(C), 175-198. https://doi.org/10.1016/j.jss.2014.09.042
____________________________
Sicherheit
[Shift Left] und durchgehend einbinden
So wie sich die Technologieteams immer schneller und weiter entwickeln, so wächst auch die Anzahl und Komplexität der Sicherheitsbedrohungen. Laut Tenables 2020 Threat Landscape Retrospective Report wurden im Jahr 2020 mehr als 22 Milliarden Datensätze mit vertraulichen persönlichen Informationen oder Geschäftsdaten offengelegt.6 Sicherheit kann kein nachträglicher Gedanke oder der letzte Schritt vor der Übermittlung sein, sie muss in den gesamten Softwareentwicklungsprozess integriert werden.
Für eine sichere Bereitstellung von Software müssen sich Sicherheitsmaßnahmen schneller weiterentwickeln als die von böswilligen Akteuren genutzten Verfahren. Während der Angriffe auf die SolarWinds- und Codecov-Softwarelieferkette 2020 wurden Hacker das Build-System von SolarWinds und das Bash-Uploader-Skript für Codecov manipuliert7, um sich heimlich in die Infrastruktur Tausender Kunden dieser Unternehmen einzubetten. Aufgrund der weitreichenden Auswirkungen dieser Angriffe muss die Branche von einem präventiven Ansatz auf einen Diagnoseansatz wechseln. Dabei müssen Softwareteams davon ausgehen, dass ihre Systeme bereits gehackt wurden, und Sicherheit in ihre Lieferkette einbinden.
In Übereinstimmung mit früheren Berichten haben wir herausgefunden, dass Elite-Performer hervorragende Sicherheitsmaßnahmen umsetzen. In diesem Jahr war die Wahrscheinlichkeit, dass Elite-Performer, die ihre Zuverlässigkeitsziele erreicht oder übertroffen hatten und die Sicherheit in ihren Softwareentwicklungsprozess integriert ist, doppelt so hoch. Dies zeigt, dass Teams, die ihre Auslieferung beschleunigt und gleichzeitig ihre Zuverlässigkeitsstandards beibehalten haben, eine Möglichkeit gefunden haben, Sicherheitsprüfungen und -verfahren zu integrieren, ohne ihre Fähigkeit zu gefährden, Software schnell oder zuverlässig auszuliefern.
Teams, die Sicherheitspraktiken in ihren Entwicklungsprozess integrieren, weisen nicht nur eine hohe Bereitstellungs- und Betriebsleistung auf, sondern haben auch eine 1,6-mal höhere Wahrscheinlichkeit, ihre Unternehmensziele zu erreichen oder zu übertreffen. Entwicklungsteams, die Sicherheit einbeziehen, sehen einen erheblichen Mehrwert für das Unternehmen.
____________________________
6. https://www.tenable.com/cyber-exposure/2020-threat-landscape-retrospective
7. https://www.cybersecuritydive.com/news/codecov-breach-solarwinds-software-supply-chain/598950/
____________________________
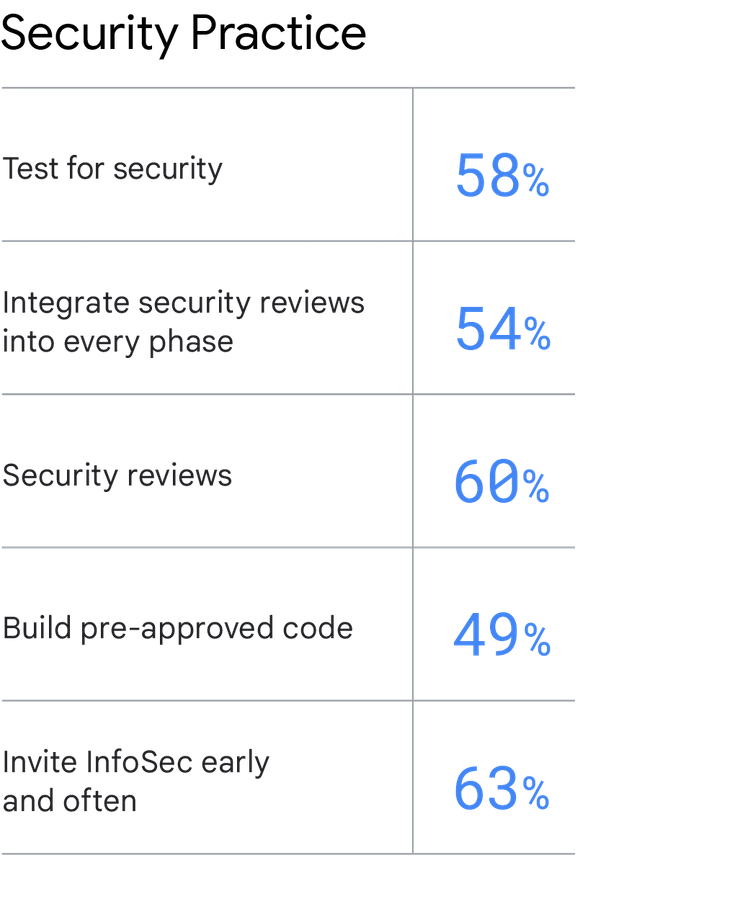
So gehts:
Die Wichtigkeit der Sicherheit lässt sich leicht betonen und die Empfehlung vorbringen, dass Teams sie als Priorität haben sollten. Dafür sind jedoch einige Änderungen gegenüber den traditionellen Sicherheitsmethoden erforderlich. Mit den folgenden Best Practices können Sie Sicherheit einbinden, die Softwarebereitstellung und die operative Leistung optimieren sowie die Unternehmensleistung verbessern:
Sicherheit testen. Testen Sie Sicherheitsanforderungen im Rahmen der automatisierten Tests, auch Bereiche, in denen vorab genehmigter Code verwendet werden sollte.
Sicherheitsprüfung in jede Phase einbinden. Binden Sie die Datensicherheit (InfoSec) in die tägliche Arbeit des gesamten Softwarebereitstellungslebenszyklus ein. Dazu gehört beispielsweise, dass das InfoSec-Team während der Design- und Architekturphasen der Anwendung Input liefert, an Software-Demos teilnimmt und während der Demos Feedback gibt.
Sicherheitsüberprüfungen. Führen Sie eine Sicherheitsüberprüfung für alle Hauptfunktionen aus. Erstellen Sie vorab genehmigten Code. Lassen Sie das InfoSec-Team vorab genehmigte, einfach zu verwendende Bibliotheken, Pakete, Toolchains und Prozesse für Entwickler und IT-Mitarbeiter erstellen. InfoSec frühzeitig und oft einladen. Beziehen Sie InfoSec während der Planung und allen darauffolgenden Phasen der Anwendungsentwicklung ein, damit sie sicherheitsrelevante Schwachstellen frühzeitig erkennen können, sodass dem Team genügend Zeit zur Behebung bleibt.
Erstellen Sie vorab genehmigten Code. Lassen Sie das InfoSec-Team vorab genehmigte, einfach zu verwendende Bibliotheken, Pakete, Toolchains und Prozesse für Entwickler und IT-Mitarbeiter erstellen.
InfoSec frühzeitig und oft einladen. Beziehen Sie InfoSec während der Planung und allen darauffolgenden Phasen der Anwendungsentwicklung ein, damit sie sicherheitsrelevante Schwachstellen frühzeitig erkennen können, sodass dem Team genügend Zeit zur Behebung bleibt.
Wie bereits erwähnt, sind hochwertige Dokumentationen der Schlüssel zum Erfolg einer Vielzahl von Funktionen, und natürlich auch Sicherheit. Teams mit einer hochwertigen Dokumentation haben eine 3,8-mal höhere Wahrscheinlichkeit, dass sie Sicherheit während des gesamten Entwicklungsprozesses einbinden. Nicht alle Personen in einer Organisation haben Erfahrung mit Kryptografie. Das Fachwissen derjenigen, die am besten arbeiten, wird in einem Unternehmen am besten durch dokumentierte Sicherheitsmaßnahmen geteilt.
Technische DevOps-Ressourcen
Unsere Studien haben gezeigt, dass Organisationen, die eine DevOps-Transformation durch die Einführung von Continuous Delivery durchlaufen, eher Prozesse mit hoher Qualität, niedrigen Risiken und Kosteneffizienz haben.
Insbesondere haben wir die folgenden technischen Praktiken gemessen:
- Lose gekoppelte Architektur
- Entwicklung nach Baumschema
- Kontinuierliche Tests
- Continuous Integration
- Nutzung von Open-Source-Technologien
- Verfahren für Monitoring und Beobachtbarkeit
- Verwaltung von Datenbankänderungen
- Automatisierung der Bereitstellung
Wir haben festgestellt, dass zwar all diese Verfahren die Continuous Delivery verbessern, eine lose gekoppelte Architektur und kontinuierliche Tests jedoch die größten Auswirkungen haben. In diesem Jahr haben wir zum Beispiel festgestellt, dass Elite-Performer, die ihre Zuverlässigkeitsziele erreichen, dreimal häufiger eine lose gekoppelte Architektur verwenden als die Niedrig-Performer.
Lose gekoppelte Architektur
Unsere Untersuchungen haben gezeigt, dass Sie die IT-Leistung verbessern können, indem Sie detaillierte Abhängigkeiten zwischen Diensten und Teams reduzieren. Das ist tatsächlich eine der stärksten Vorhersagen für eine erfolgreiche Continuous Delivery. Mithilfe einer lose gekoppelten Architektur können Teams unabhängig voneinander skalieren, fehlschlagen, testen und bereitstellen. Teams können in ihrem eigenen Tempo arbeiten, in kleineren Batches arbeiten, weniger technische Schulden haben und Fehler schneller beheben.
Kontinuierliche Tests und Continuous Integration
Ähnlich wie in den Ergebnissen der letzten Jahre zeigen wir, dass kontinuierliche Tests eine gute Vorhersage für erfolgreiche Continuous Delivery sind. Elite-Performer, die ihre Zuverlässigkeitsziele erreichen, verwenden 3,7-mal häufiger kontinuierliche Tests. Durch die schnelle und häufige Einbindung von Tests während des Bereitstellungsprozesses, bei denen Tester während der gesamten Zusammenarbeit zusammenarbeiten, können Teams ihre Produkte, Dienstleistungen oder Anwendungen schneller iterieren und ändern. Mithilfe dieser Feedback Loop können Sie Ihren Kunden einen Mehrwert bieten und gleichzeitig Verfahren wie automatische Tests und Continuous Integration einbeziehen.
Durch die Continuous Integration wird auch die Continuous Delivery verbessert. Elite-Performer, die ihre Zuverlässigkeitsziele erreichen, nutzen mit 5,8-mal höherer Wahrscheinlichkeit Continuous Integration. Bei der Continuous Integration löst jeder Commit einen Build der Software aus und führt eine Reihe automatisierter Tests aus, die in wenigen Minuten Feedback geben. Durch die Continuous Integration verringern Sie die manuelle und häufig komplexe Koordination einer erfolgreichen Einbindung.
Continuous Integration, wie sie von Kent Beck und der Extreme Programming-Community, je nachdem, wo sie entstanden ist, definiert wurde, umfasst auch die Verfahren der Entwicklung nach Baumschema, die als Nächstes besprochen werden.7
Entwicklung nach Baumschema
Unsere Untersuchungen haben gezeigt, dass Organisationen mit hoher Leistung eher auf die Entwicklung nach einem Baumschema implementiert haben. Dabei arbeiten Entwickler in kleinen Batches zusammen und führen ihre Arbeit häufig in einem gemeinsam genutzten Baumschema zusammen. Tatsächlich ist es bei Elite-Performern, die ihre Zuverlässigkeitsziele erreichen, 2,3-mal wahrscheinlicher, dass sie die Entwicklung nach einem Baumschema verwenden. Nutzer mit geringer Leistung verwenden eher langlebige Zweige und verzögern das Zusammenführen.
Die Teams sollten ihre Arbeit mindestens einmal am Tag zusammenführen, wenn möglich mehrmals am Tag. Die Entwicklung nach einem Baumschema steht in engem Zusammenhang mit der Continuous Integration. Sie sollten also diese beiden technischen Verfahren gleichzeitig implementieren, da sie mehr Auswirkungen haben, wenn Sie sie zusammen verwenden.
Bereitstellungsautomatisierung
Im Idealfall werden im Computer die wiederholten Aufgaben ausgeführt, während sich die Menschen auf das Lösen von Problemen konzentrieren. Durch die Implementierung von Bereitstellungsautomatisierung können Ihre Teams sich diesem Ziel nähern.
Wenn Sie Software automatisiert vom Testen in die Produktion verschieben, reduzieren Sie die Vorlaufzeit, da Sie schnellere und effizientere Bereitstellungen ermöglichen. Außerdem verringern Sie die Wahrscheinlichkeit von Bereitstellungsfehlern, die bei manuellen Bereitstellungen häufiger auftreten. Wenn Ihre Teams die Bereitstellungsautomatisierung verwenden, erhalten sie sofort Feedback, mit dem Sie Ihren Dienst oder Ihr Produkt deutlich schneller verbessern können. Sie müssen zwar nicht gleichzeitig kontinuierliche Tests, Continuous Integration und automatisierte Bereitstellungen implementieren, die Verknüpfung dieser drei Funktionen wirken sich aber wahrscheinlich positiv auf die Verbesserungen aus.
Änderungsmanagement für Datenbanken
Das Tracking von Änderungen durch die Versionsverwaltung ist ein wichtiger Teil des Schreibens und Verwaltens von Code und für die Verwaltung von Datenbanken. Unsere Studie hat gezeigt, dass Elite-Performer, die ihre Zuverlässigkeitsziele erreichen, mit 3,4-mal höherer Wahrscheinlichkeit Datenbankänderungsmanagement ausüben als ihre Pendants mit geringer Leistung. Darüber hinaus sind die Zusammenarbeit, Kommunikation und Transparenz in allen relevanten Teams der Schlüssel zum erfolgreichen Datenbankänderungsmanagement. Sie haben zwar die Möglichkeit, zwischen bestimmten Implementierungsmethoden zu wählen. Wir empfehlen aber, dass Sie immer dann, wenn Sie Änderungen an Ihrer Datenbank vornehmen müssen, die Teams zusammen informieren und die Änderungen vor der Aktualisierung der Datenbank überprüfen.
____________________________
8. Beck, K. (2000). Extreme programming explained: Embrace change. Addison-Wesley Professional
____________________________
Monitoring und Beobachtbarkeit
Wie in den letzten Jahren haben wir festgestellt, dass das Monitoring und die Beobachtbarkeit von Praktiken die Continuous Delivery unterstützen. Elite-Performer, die ihre Zuverlässigkeitsziele erfolgreich erreichen, haben mit 4,1-mal höherer Wahrscheinlichkeit Lösungen, die die Beobachtbarkeit in den Gesamtsystemzustand einfließen lassen. Mithilfe von Beobachtbarkeitspraktiken erhalten Ihre Teams ein besseres Verständnis für Ihre Systeme. Dadurch wird die Zeit zum Erkennen und Beheben von Problemen reduziert. Unsere Studien haben auch gezeigt, dass Teams, die gut beobachtbar sind, mehr Zeit mit Programmieren verbringen. Eine mögliche Erklärung für dieses Ergebnis ist, dass die Implementierung von Beobachtbarkeitspraktiken dazu beiträgt, die Zeit der Entwickler von der Suche nach Ursachen für Probleme zur Fehlerbehebung zu verringern und schließlich wieder für die Codierung freigeben.
Open-Source-Technologien
Viele Entwickler nutzen bereits Open-Source-Technologien und ihre Vertrautheit mit diesen Tools ist eine Stärke für das Unternehmen. Eine wichtige Schwäche von Closed-Source-Technologien besteht darin, dass Ihre Möglichkeiten der Informationsübermittlung in und außerhalb der Organisation eingeschränkt sind. Es ist beispielsweise nicht möglich, jemanden einzustellen, der bereits mit den Tools Ihrer Organisation vertraut ist. Entwickler können dieses Wissen auch nicht an andere Organisationen übertragen. Im Gegensatz dazu haben die meisten Open-Source-Technologien eine Community um sich herum, die Entwickler für den Support nutzen können. Open-Source-Technologien sind zugänglicher, relativ kostengünstig und anpassbar. Elite-Performer, die ihre Zuverlässigkeitsziele erreichen, verwenden mit 2,4-mal höherer Wahrscheinlichkeit Open-Source-Technologien. Wir empfehlen Ihnen, bei der Implementierung Ihrer DevOps-Transformation auf mehr Open-Source-Software umzustellen.
Weitere Informationen zu technischen DevOps-Ressourcen finden Sie unter DORA-Funktionen unter https://cloud.google.com/devops/capabilities
COVID-19 und Kultur
COVID-19
In diesem Jahr haben wir die Faktoren untersucht, die die Leistung der Teams während der Coronakrise beeinflusst haben. Hat sich die Pandemie negativ auf die Softwarebereitstellung und den Betrieb ausgewirkt? Haben die Teams aufgrund von Corona mehr Burnouts? Welche Faktoren sind mildernd für einen Burn-out?
Zuerst wollten wir verstehen, wie sich die Pandemie auf die Übermittlungs- und Betriebsleistung auswirkt. Viele Organisationen priorisieren Modernisierungen, um auf dramatische Marktveränderungen zu reagieren (z. B. der Wechsel vom Präsenzkauf zum Onlinekauf). Im Abschnitt „Wie vergleichen wir?“ Kapitel erfahren Sie, wie sich die Leistung in der Softwarebranche erheblich beschleunigt hat und sich weiter beschleunigt. Leistungsstarke Teams machen jetzt den Großteil unserer Stichprobe aus und Elite-Performer setzen die Messlatte weiter hoch, wodurch sie häufiger mit kürzeren Vorlaufzeiten, schnelleren Wiederherstellungszeiten und besserer Änderungsausfallrate ausgestattet werden. Ebenso hat eine Studie durch GitHub-Forscher eine Zunahme der Entwickleraktivität (Push-, Pull-, überprüfte und kommentierte Probleme pro Nutzer9) im Jahr 2020 festgestellt. Man kann sagen, dass die Branche trotz und nicht wegen der Pandemie weiter voranschreitet, aber es ist bemerkenswert, dass der SDO-Erfolg in dieser düsteren Zeit nicht abgenommen hat.
Durch die Pandemie hat sich unser Arbeitsalltag verändert – und viele haben auch ihren Arbeitsort verändert. Aus diesem Grund betrachten wir die Auswirkungen der Arbeit im Homeoffice aufgrund der Pandemie. 89 % der Befragten haben aufgrund der Pandemie im Homeoffice gearbeitet. Nur 20 % gaben an, vor der Pandemie jemals zuvor im Homeoffice gearbeitet zu haben. Der Wechsel zu einer Arbeitsumgebung im Homeoffice hatte erhebliche Auswirkungen auf die Entwicklung von Software, die Geschäftsabläufe und die Zusammenarbeit. Viele haben im Homeoffice keine Möglichkeit mehr, sich durch spontane Gespräche im Flur oder in persönlicher Zusammenarbeit auszutauschen.
____________________________
9. https://octoverse.github.com/
____________________________
Was reduzierte Burnout?
Trotzdem haben wir festgestellt, dass ein Faktor erhebliche Auswirkungen darauf hatte, ob ein Team wegen der Arbeit im Homeoffice Probleme hatte: Kultur. Bei Teams mit einer generativen Teamkultur, deren Mitglieder sich inkludiert und als Teil ihres Teams fühlten, war die Wahrscheinlichkeit eines Burnouts während der Pandemie halbiert. Dieses Ergebnis unterstreicht, wie wichtig die Priorisierung von Teams und Kultur ist. Bessere Teams sind besser gerüstet für herausfordernde Zeiträume, die sowohl das Team als auch einzelne Personen unter Druck setzen.
Kultur
Einfach ausgedrückt: Die Kultur ist der unausweichliche Unterton, der zwischen den einzelnen Personen in einer Organisation vorherrscht. Es hängt von verschiedenen Faktoren ab, wie sich Mitarbeiter in ihrem Unternehmen verhalten, wie sie denken, sich fühlen und sich gegenseitig behandeln. Alle Organisationen haben ihre eigene Kultur, und unsere Erkenntnisse zeigen, dass diese Kultur zu den Haupttreibern einer organisatorischen und IT-Leistung beiträgt. Unsere Analysen deuten darauf hin, dass eine generative Kultur (gemessen an der Westrums-Organisationskulturtypologie) und ein Gefühl der Zugehörigkeit und Inklusion in der Organisation eine höhere SDO-Leistung (Softwarebereitstellung und Betrieb) voraussagt. Wir haben beispielsweise festgestellt, dass Elite-Performer, die ihre Zuverlässigkeitsziele erreichen, mit einer 2,9-mal höheren Wahrscheinlichkeit eine generative Teamkultur haben als ihre Pendants mit geringer Leistung. Gleichermaßen prognostiziert eine generative Kultur eine höhere organisatorische Leistung und niedrigere Zahlen für das Burnout von Mitarbeitern. Kurz gesagt: Kultur ist wirklich wichtig. Glücklicherweise ist Kultur fließend, vielseitig und immer im Wandel. Deshalb ist es etwas, das Sie ändern können.
Für die erfolgreiche Ausführung von DevOps müssen in Ihrem Unternehmen Teams funktionsübergreifend zusammenarbeiten. Im Jahr 2018 stellten wir fest, dass leistungsstarke Teams Software mit doppelt so hoher Wahrscheinlichkeit als funktionsübergreifendes Team entwickeln und ausliefern. Das zeigt, dass Zusammenarbeit für den Erfolg einer Organisation von größter Bedeutung ist. Eine wichtige Frage ist: Welche Faktoren tragen dazu bei, eine Umgebung zu schaffen, die die funktionsübergreifende Zusammenarbeit fördert und feiert?
Im Laufe der Jahre haben wir versucht, das Konstrukt der Kultur greifbarer zu machen und der DevOps-Community mehr darüber zu vermitteln, wie sich die Kultur auf die organisatorische und IT-Leistung auswirkt. Den Anfang machten wir mit einer operativen Definition der Kultur anhand der Typologie der Organisationskultur von Westrum. Er identifizierte drei Arten von Organisationen: macht-, regel- und leistungsorientiert. Wir haben dieses Framework in unserer eigenen Studie genutzt und festgestellt, dass eine leistungsorientierte Organisationskultur, die den Informationsfluss, das Vertrauen, die Innovation und die Risikoteilung optimiert, eine hohe SDO-Leistung voraussagt.
Während wir uns der Kultur und DevOps widmen, haben wir unsere ursprüngliche Definition der Kultur um weitere psychosoziale Faktoren wie die psychische Sicherheit erweitert. Organisationen mit hoher Leistung haben eine höhere Wahrscheinlichkeit, eine Unternehmenskultur zu haben, die Mitarbeiter dazu ermutigt, berechnete und mäßige Risiken einzugehen, ohne negative Auswirkungen zu fürchten.
Zugehörigkeit und Inklusion
Angesichts der konsistent starken Auswirkungen auf die Leistung haben wir dieses Jahr unser Modell erweitert, um herauszufinden, ob das Gefühl der Zugehörigkeit und Inklusion der Mitarbeiter zum positiven Einfluss der Kultur auf die Leistung beiträgt.
Psychologische Forschung hat gezeigt, dass die Menschen dazu angeregt sind, starke und stabile Beziehungen zu anderen aufzubauen und zu pflegen.10 Wir fühlen uns motiviert, mit anderen verbunden zu sein und uns in den verschiedenen Gruppen, deren Mitglieder wir sind, akzeptiert zu fühlen. Das Gefühl der Zugehörigkeit führt zu einer Vielzahl von positiven physischen und psychologischen Ergebnissen. Studien haben beispielsweise gezeigt, dass das Gefühl der Zugehörigkeit zu mehr positiver Motivation führt und die akademische Leistung verbessert.11
Ein Teil dieses Gefühls der Verbundenheit ist die Vorstellung, dass Menschen sich wohl fühlen sollten, wenn sie das Beste aus sich herausholen können und dass ihre Erfahrungen und ihr Hintergrund wertvoll sind und wertgeschätzt werden.12 Wenn Sie sich auf die Schaffung einer inklusiven Kultur der Zugehörigkeit innerhalb der Organisationen konzentrieren, können Sie eine florierende, vielfältige und motivierte Belegschaft aufbauen.
Unsere Ergebnisse zeigen, dass leistungsorientierte Organisationen, die Zugehörigkeit und Inklusion wertschätzen, im Vergleich zu Unternehmen mit einer weniger positiven Organisationskultur eher ein geringeres Maß an Burnout bei ihren Mitarbeitern aufweisen.
Da dies zeigt, wie sich psychosoziale Faktoren auf die Leistung der SDO und die Burnouts bei den Mitarbeitern auswirken, empfehlen wir, dass Sie, wenn Sie eine erfolgreiche DevOps-Transformation anstreben, in die Bewältigung kulturbezogener Probleme als Teil Ihrer Transformationsbemühungen investieren.
____________________________
10. Baumeister und Leary, 1995. The need to belong: Desire for interpersonal attachments as a fundamental human motivation. Psychological Bulletin, 117(3), 497–529. https://doi.org/10.1037/0033-2909.117.3.497
11. Walton et al., 2012. Mere belonging: the power of social connections. Journal of Personality and Social Psychology, 102(3):513-32. https://doi.org/10.1037/a0025731
12. Mor Barak & Daya, 2014; Managing diversity: Toward a globally inclusive workplace. Sage. Shore, Cleveland, & Sanchez, 2018; Inclusive workplaces: A review and model, Human Resources Review. https://doi.org/10.1016/j.hrmr.2017.07.003
Wer hat an der Umfrage teilgenommen?
Accelerate State of DevOps 2021 deckt sieben Jahre Forschung und mehr als 32.000 Umfrageantworten von Branchenexperten auf und zeigt die Softwareentwicklung und DevOps-Praktiken, die Teams und Organisationen zum Erfolg verhelfen.
1.200 Berufstätige in einer Vielzahl von Branchen rund um den Globus haben ihre Erfahrungen mit uns geteilt, damit wir die Faktoren, die die Leistung steigern können, besser verstehen. Zusammenfassend lässt sich sagen, dass die Repräsentation über alle demografischen und firmenbezogenen Größenwerte hinweg bemerkenswert stabil geblieben ist.
Ähnlich wie in den vergangenen Jahren haben wir für alle Teilnehmenden der Befragung demografische Informationen erfasst. Die Kategorien umfassen Geschlecht, Behinderungen und unterrepräsentierte Gruppen.
Demografische und firmenbezogene Merkmale
In diesem Jahr deckt sich die Repräsentation mit der früherer Berichte, was firmenbezogene Kategorien wie Unternehmensgröße, Branche und Region betrifft. Wieder arbeiten mehr als 60 % der befragten Personen als Entwickelnde oder im Management und ein Drittel arbeitet in der Technologiebranche. Außerdem sind Branchen wie die Finanzdienstleistungsbranche, der Einzelhandel und Industrie/Fertigung vertreten.
____________________________
13. https://www.washingtongroup-disability.com/question-sets/wg-short-set-on-functioning-wg-ss/
____________________________
Demografie
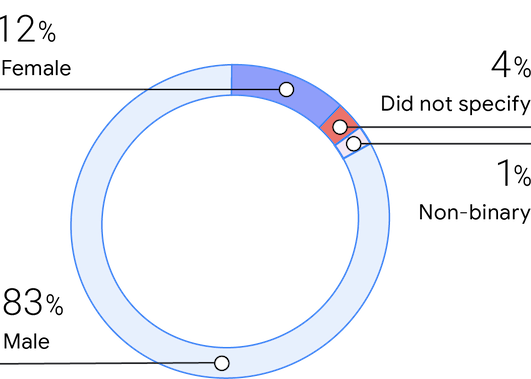
Geschlecht
Gemäß den vorherigen Umfragen besteht die diesjährige Stichprobe aus 83 % Männer, 12 % Frauen und 1 % nicht binär. Die Teilnehmerinnen und Teilnehmer sagten, dass Frauen etwa 25 % ihrer Teams ausmachen, was einen großen Anstieg von 2019 (16 %) und wieder mit 2018 (25 %) übereinstimmt.
Behinderungen
Behinderungen werden anhand von sechs Dimensionen dargestellt, die den Leitlinien des Washington Group Short Sets entsprechen.13 Dies ist das dritte Jahr, in dem wir nach Behinderungen gefragt haben. Der Prozentsatz der Menschen mit Behinderungen entspricht dem Prozentsatz unseres Berichtes aus dem Jahr 2019 (9 %).
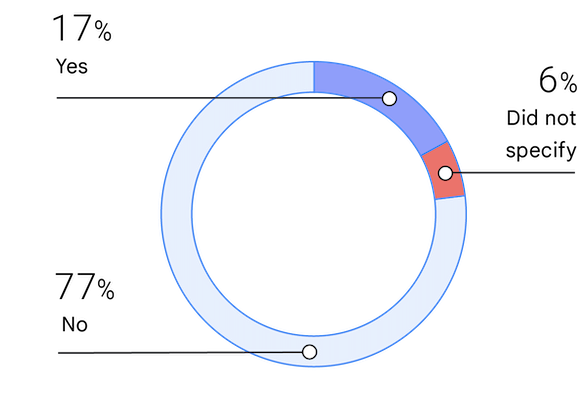
Unterrepräsentierte Gruppen
Eine Person kann aufgrund ihrer ethnischen Herkunft, ihres Geschlechts oder einer anderen Eigenschaft einer unterrepräsentierten Gruppe angehören. Dies ist das vierte Jahr, in dem wir nach Unterrepräsentation gefragt haben. Der Prozentsatz der Personen, die sich als Teil einer unterrepräsentierten Gruppe einstufen, ist leicht gestiegen: von 13,7 % im Jahr 2019 auf 17 % im Jahr 2021.
Erfahrung in Jahren
Die Teilnehmer der diesjährigen Umfrage sind sehr erfahren. 41 % haben mindestens 16 Jahre Erfahrung. Mehr als 85 % unserer Teilnehmer hatten mindestens 6 Jahre Erfahrung.
Firmenbezogene Merkmale
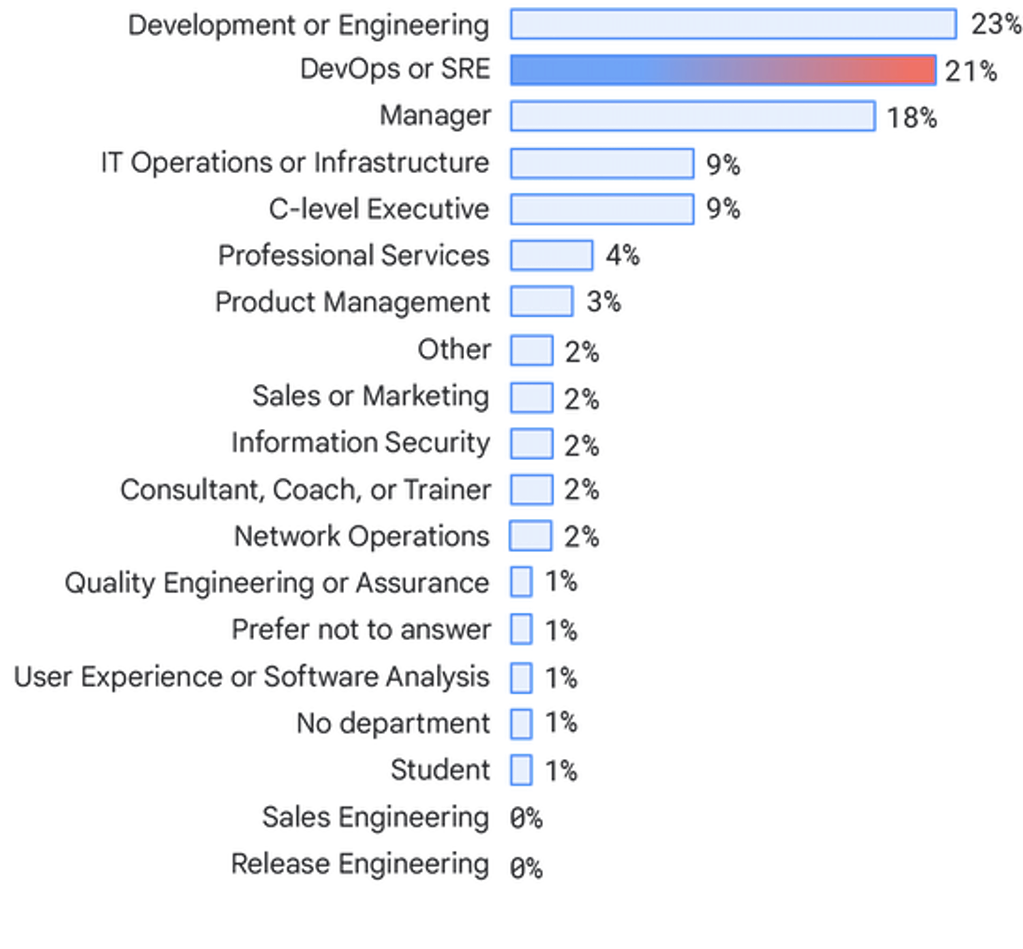
Abteilungen
Bei den Befragten handelt es sich im Wesentlichen um Einzelpersonen, die in Entwicklungs- oder Engineering-Teams (23 %), DevOps- oder SRE-Teams (21 %), als Manager (18 %) und IT-Ops- oder Infrastrukturteams (9 %) arbeiten. Die Zahl der Berater ist im Jahr 2019 um 4 % auf 2 % gesunken und die Anzahl der Führungskräfte der Führungsebene ist um 4 % auf 9 % gestiegen.
Branche
Wie schon in früheren „Accelerate State of DevOps“-Berichten gezeigt, arbeiten die meisten Teilnehmer in der Technologiebranche, gefolgt von Finanzdienstleistungen, Einzelhandel und weiteren.
Mitarbeiter
Entsprechend den Ergebnissen der früheren „Accelerate State of DevOps“-Berichte kommen die Teilnehmer aus unterschiedlichen Organisationsgrößen zusammen. 22 % der Teilnehmenden stammen aus Unternehmen mit mehr als 10.000 Mitarbeitenden, 7 % aus Unternehmen mit 5.000 bis 9.999 Mitarbeitenden. Weitere 15 % der Befragten arbeiten in Organisationen mit 2.000 bis 4.999 Mitarbeitern. Außerdem liegt die Teilnehmerzahl von Organisationen mit 500 bis 1.999 Mitarbeitern bei 13 %, mit 100 bis 499 Mitarbeitern bei 15 % und mit 20 bis 99 Mitarbeitern mit bei 15 %.
Teamgröße
Mehr als die Hälfte der Befragten (62 %) arbeitet in Teams aus zehn oder weniger Mitgliedern (28 % mit 6–10 Personen, 27 % mit 2–5 und 6 % als Ein-Mann-Teams). 19 % arbeiten in Teams mit 11 bis 20 Mitgliedern.
Regionen
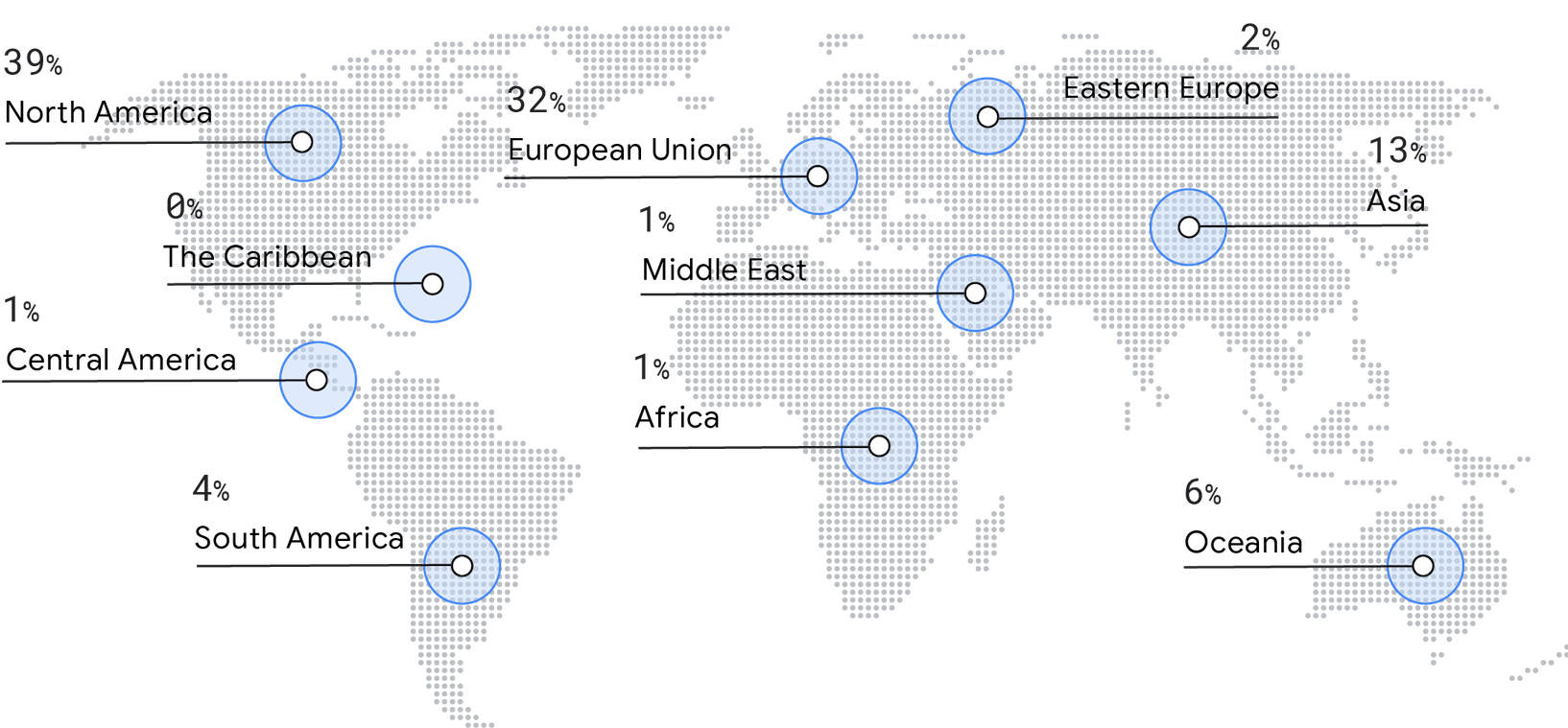
Bei der diesjährigen Umfrage gab es einen Rückgang der Antworten aus Nordamerika (50 % im Jahr 2019 auf 39 % im Jahr 2021). Stattdessen verzeichneten wir einen Anstieg der Repräsentation in Europa (29 % im Jahr 2019 auf 32 % im Jahr 2021), Asien (9 % im Jahr 2019 auf 13 % im Jahr 2021), Ozeanien (4 % im Jahr 2019 bis 6 % (2021) und Südamerika (2 % im Jahr 2019 bis 4 % im Jahr 2021).
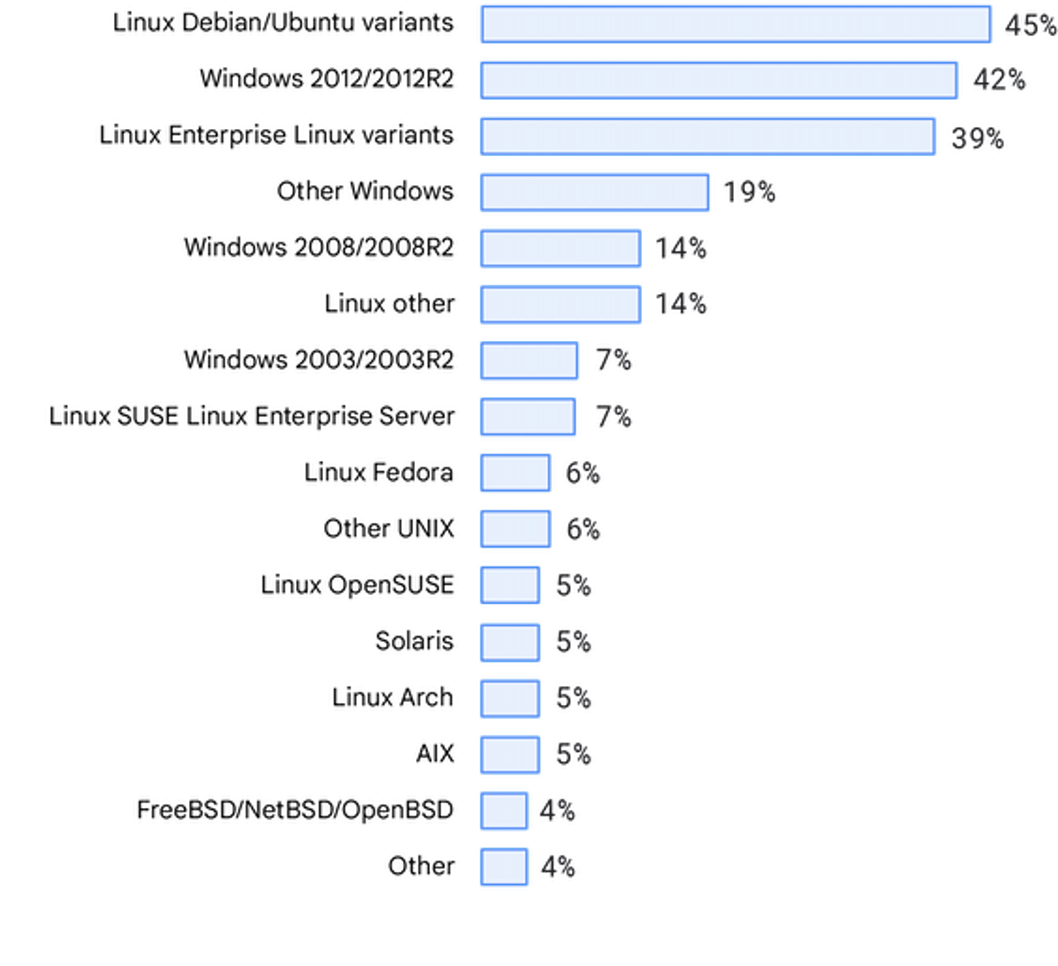
Betriebssysteme
Die Verteilung der Betriebssysteme entsprach auch den vorherigen „State of DevOps“-Berichten. Außerdem würdigen und danken wir den Teilnehmern, die uns darauf hingewiesen haben, dass unsere Liste der Betriebssysteme eine Aktualisierung brauchen könnte.
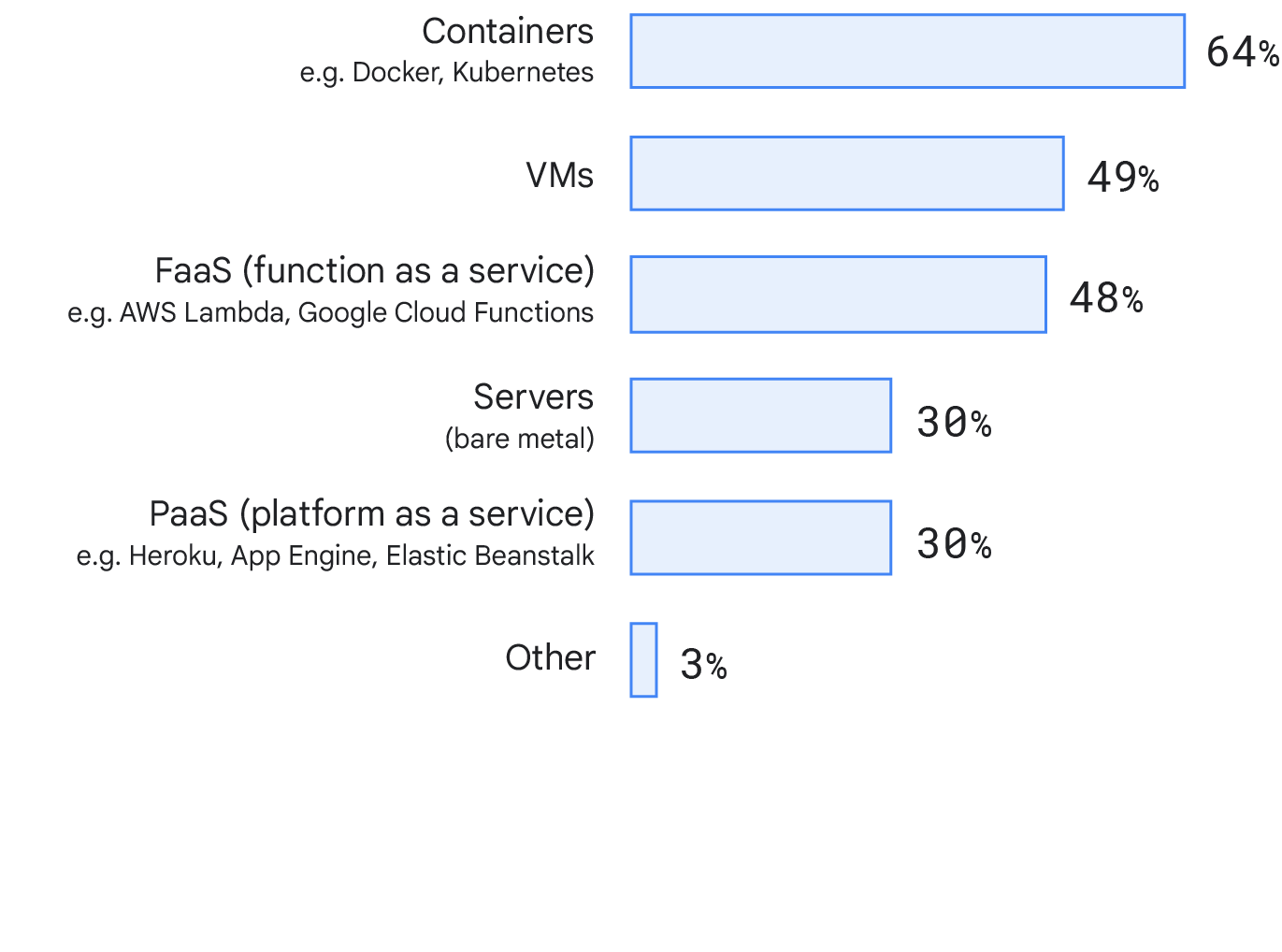
Bereitstellungsziel
In diesem Jahr haben wir uns angesehen, wo die Teilnehmer den primären Dienst oder die primäre Anwendung bereitstellen, an der sie arbeiten. Überraschenderweise nutzen 64 % der Befragten, also ein Großteil, Container, 48 % verwenden virtuelle Maschinen (VMs). Dies kann sich in einer stärkeren Verlagerung der Branche in Richtung moderner Deployment-Zieltechnologien widerspiegeln. Wir haben Unterschiede zwischen verschiedenen Unternehmensgrößen überprüft und keine wesentlichen Unterschiede zwischen Deployment-Zielen festgestellt.
Schlussgedanken
Nach sieben Jahren Forschung können wir weiterhin die Vorteile von DevOps für Organisationen beobachten. Unternehmen werden von Jahr zu Jahr schneller und besser.
Teams, die ihre Grundsätze und Fähigkeiten einhalten, können Software schnell und zuverlässig bereitstellen und gleichzeitig den Nutzen für das Unternehmen steigern. In diesem Jahr haben wir uns die Auswirkungen von SRE-Praktiken, einer sicheren Softwarelieferkette und Qualitätsdokumentation angesehen und einen Blick auf die Nutzung der Cloud geworfen. Jeder Bereich ermöglicht eine höhere Effizienz von Personen und Teams. Wir konzentrieren uns auf die Wichtigkeit, Lösungen zu strukturieren, die zu den Mitarbeitern passen, die diese Möglichkeiten nutzen, und nicht die Nutzer an die Lösung anzupassen.
Wir möchten allen danken, die an der diesjährigen Umfrage teilgenommen haben. Wir hoffen, dass unsere Forschung Ihnen und Ihrer Organisation dabei hilft, bessere Teams und bessere Software zu entwickeln und gleichzeitig die Work-Life-Balance zu wahren.
Danksagungen
Der diesjährige Bericht wurde von einer großen Familie engagierter Beitragender ermöglicht. Das Entwerfen der Fragen, das Durchführen von Analysen, das Schreiben und Bearbeiten von Text und das Strukturieren des Berichts sind nur einige der Arten, auf die unsere Kolleginnen und Kollegen uns bei der Umsetzung dieses großen Projekts geholfen haben. Die Autoren möchten all diesen Personen für ihre Beiträge und ihre Hilfe für den diesjährigen Bericht danken. Unsere Danksagungen sind alphabetisch aufgeführt.

Autoren
Dustin Smith
Dustin Smith ist ein Psychologe und Forschungsleiter im Bereich Nutzererfahrung bei Google und er arbeitet seit drei Jahren am DORA-Projekt. In den letzten sieben Jahren erforscht er, wie Menschen von den Systemen und Umgebungen in ihrem Umfeld in einer Vielzahl von Zusammenhängen betroffen sind: Softwareentwicklung, kostenlose Spiele, Gesundheitswesen und Militär. In seinen Forschungsergebnissen bei Google identifiziert er Bereiche, in denen Softwareentwickler während der Entwicklung glücklicher und produktiver sein können. Er arbeitet seit zwei Jahren am DORA-Projekt. Dustin hat seinen Doktortitel in Human Factors Psychology von der Wichita State University.
Daniela Villalba
Daniella Villalba ist Forscherin im Bereich Nutzererfahrung für das DORA-Projekt. Sie konzentriert sich darauf, die Faktoren zu ermitteln, die Entwickelnde glücklich und produktiv machen. Vor ihrer Zeit bei Google untersuchte Daniella Villalba die Vorteile von Meditationstraining, die psychosozialen Faktoren, die sich darauf auswirken, welche Erfahrungen Studierende machen, Erinnerungen von Augenzeuginnen und -zeugen und falsche Geständnisse. Sie hat einen Doktortitel in Experimental Psychology von der Florida International University.
Michelle Irvine
Michelle Irvine ist technische Autorin bei Google und arbeitet daran, die Lücke zwischen Entwicklertools und ihren Nutzern zu schließen. Vor ihrer Tätigkeit bei Google arbeitete sie im Bildungsbereich und als technische Autorin von physischer Simulationssoftware. Michelle hat einen Bachelor in Physik sowie einen MA im Rhetorik- und Kommunikationsdesign der Universität von Waterloo.
Dave Stanke
Dave Stanke ist Developer Relations Engineer bei Google und unterstützt Kunden bei der Einführung von DevOps und SRE. Während seiner beruflichen Laufbahn hat er in allen möglichen Bereichen gearbeitet, darunter als CTO eines Start-ups, als Produktmanager, im Kundensupport, als Softwareentwickler, Systemadministrator und Grafikdesigner. Er hat einen Master of Science-Abschluss in Technology Management von der Columbia University.
Nathen Harvey
Nathen Harvey ist Developer Relations Engineer bei Google und verbringt sein Arbeitsleben damit, Teams dabei zu helfen, ihr Potenzial voll auszuschöpfen und gleichzeitig ihre Technologien so auszuwählen, dass sie auf die Geschäftsergebnisse abgestimmt sind. Er hatte das Privileg, mit einigen der besten Teams und Open-Source-Communitys zusammenzuarbeiten und sie beim Anwenden der Prinzipien und Best Practices von DevOps und SRE zu unterstützen. Nathen Harvey hat außerdem gemeinsam mit einer Kollegin 97 Things Every Cloud Engineer Should Know, O'Reilly 2020 redigiert und war auch am Schreiben der Texte beteiligt.
Methodik
Forschungsdesign
In dieser Studie wird ein branchenübergreifendes, theoretisches Design verwendet. Dieses theoretische Design wird als abgeleitete Vorhersage bezeichnet und ist heute eine der am häufigsten in der Geschäfts- und Technologieforschung durchgeführten Typen. Abgeleitetes Design wird verwendet, wenn ein rein experimentelles Design nicht möglich ist und Feldtests bevorzugt werden.
Zielgruppe und Stichprobenerhebung
Die Zielgruppe Umfrage bestand aus Fachleuten und Führungskräften, die in den Bereichen Technologien und Transformationen arbeiten - oder in naheliegenden Bereichen - und insbesondere aus Personen, die mit DevOps vertraut sind. Wir haben die Umfrage über E-Mail-Listen, Online-Promotions, einem Online-Panel, soziale Medien und die Umfrageteilnehmer gebeten, sie mit ihren Netzwerken (Schneeballauswahl) zu teilen.
Latente Konstrukte erstellen
Wir haben unsere Hypothesen und Konstrukte so oft wie möglich mit zuvor validierten Konstrukten formuliert. Wir haben auf Grundlage von Theorien, Definitionen und Fachwissen neue Konstrukte entwickelt. Anschließend haben wir zusätzliche Maßnahmen ergriffen, um die Absicht der Befragung klarzustellen, damit die darin erhobenen Daten eine hohe Wahrscheinlichkeit aufweisen, dass sie verlässlich und gültig sind.14
Methoden der statistischen Analyse
Clusteranalyse. Wir haben die Clusteranalyse verwendet, um unsere Leistungsprofile für die Softwarebereitstellung anhand der Bereitstellungshäufigkeit, der Vorlaufzeit, der Zeit zur Wiederherstellung des Dienstes und der Änderungsfehlerquote zu identifizieren. Wir haben eine latente Klassenanalyse verwendet15, weil wir keine branchenbezogenen oder theoretischen Gründe für eine bestimmte Anzahl von Clustern hatten. Daher haben wir das bayessche Informationskriterium16 genutzt, um die optimale Anzahl von Clustern zu bestimmen.
Messmodell Vor der Analyse haben wir Konstrukte mithilfe der explorativen Faktoranalyse mit der Hauptkomponentenanalyse mithilfe von varimax-Rotation identifiziert.17 Wir bestätigten statistische Tests zur konvergenten und divergenten Validität und Reliabilität unter Verwendung der durchschnittlich extrahierten Varianz (AVE), der Korrelation, von Cronbachs Alpha18 und der zusammengesetzten Reliabilität.
Strukturelle Gleichungsmodellierung. Wir haben die strukturierten Gleichungsmodelle (SEM) mithilfe von Partial Least Squares (PLS) analysiert, einem korrelierten SEM.19
________________________
14. Churchill Jr, G. A. „A paradigm for developing better measures of marketing constructs“, Journal of Marketing Research 16:1, (1979), 64–73.
15. Hagenaars, J. A. & McCutcheon, A. L. (Hrsg.) (2002). Applied latent class analysis. Cambridge University Press.
16. Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychological methods, 17(2), 228.
17. Straub, D. Boudreau, M. C. & Gefen, D. (2004). Validation guidelines for IS positivist research. Communications of the Association for Information systems, 13(1), 24.
18. Nunnally, J.C. Psychometric Theory. New York: McGraw-Hill, 1978
19. Hair Jr, J. #f1 Hult, G. T. M., Ringle, C. M., & Sarstedt, M. 2021: „A primer on partial least squares structural equation modeling (PLS-SEM).“ Sage publications
Weitere Informationen
Weitere Informationen zu DevOps-Ressourcen finden Sie unter https://cloud.google.com/devops/capabilities
Ressourcen zum Site Reliability Engineering (SRE) finden Sie unter
Machen Sie den DevOps-Schnelltest:
https://www.devops-research.com/quickcheck.html
DevOps-Forschungsprogramm entdecken:
https://www.devops-research.com/research.html
Informationen zum Google Cloud Application Modernization Program:
https://cloud.google.com/solutions/camp
Whitepaper „The ROI of DevOps Transformation: How to quantifying the impact of your modernization initiatives“:
https://cloud.google.com/resources/roi-of-devops-transformation-whitepaper
Vorherige State of DevOps Berichte:
State of DevOps 2014: https://services.google.com/fh/files/misc/state-of-devops-2014.pdf
State of DevOps 2015: https://services.google.com/fh/files/misc/state-of-devops-2015.pdf
State of DevOps 2016: https://services.google.com/fh/files/misc/state-of-devops-2016.pdf
State of DevOps 2017: https://services.google.com/fh/files/misc/state-of-devops-2017.pdf
Accelerate State of DevOps 2018: https://services.google.com/fh/files/misc/state-of-devops-2018.pdf
Accelerate State of DevOps 2019:
https://services.google.com/fh/files/misc/state-of-devops-2019.pdf
Sind Sie bereit für die datenbasierte Transformation?
Lernen Sie unseren Ansatz zum Erstellen einer Daten-Cloud kennen, die Geschwindigkeit, Skalierung und Sicherheit optimiert. Hier ansehen.


















