
Foundations for TPU development
Build with your preferred framework and diagnostic tools to drive peak performance
 Learn about TPU architectureTensor Processing Units (TPUs) are application specific integrated circuits (ASICs) designed by Google to accelerate machine learning workloads. Google Cloud makes TPUs available as a scalable resource.Tutorial
Learn about TPU architectureTensor Processing Units (TPUs) are application specific integrated circuits (ASICs) designed by Google to accelerate machine learning workloads. Google Cloud makes TPUs available as a scalable resource.Tutorial Set up your Cloud TPU environmentAn end-to-end checklist for getting started with TPUs on Google Cloud.Tutorial
Set up your Cloud TPU environmentAn end-to-end checklist for getting started with TPUs on Google Cloud.Tutorial A developer's guide to debugging JAX on TPUsA practical guide to debugging and profiling techniques for JAX on Cloud TPUs.Blog
A developer's guide to debugging JAX on TPUsA practical guide to debugging and profiling techniques for JAX on Cloud TPUs.Blog


Accelerate production inference on TPUs
Deploy high-throughput, low-latency workloads using vLLM and optimized TPU serving stacks
 Serve Qwen3-Coder with vLLM on Ironwood TPUIn this guide, we show how to serve Qwen3-Coder-480B-A35B-Instruct-FP8-Dynamic on Ironwood (TPU7x).Guide
Serve Qwen3-Coder with vLLM on Ironwood TPUIn this guide, we show how to serve Qwen3-Coder-480B-A35B-Instruct-FP8-Dynamic on Ironwood (TPU7x).Guide Inference on TPULearn the essential skills to design and implement efficient AI inference solutions using Google Cloud's specialized hardware and popular open-source frameworks.Course
Inference on TPULearn the essential skills to design and implement efficient AI inference solutions using Google Cloud's specialized hardware and popular open-source frameworks.Course

Scale model pre-training on TPUs
Achieve higher training throughput using JAX, PyTorch, and Keras on TPUs
 How to scale your modelTraining LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models.eBook
How to scale your modelTraining LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models.eBook MaxTextHigh performance, highly scalable, open-source LLM library and reference implementation written in pure Python/JAX and targeting Google Cloud TPUs and GPUs for training.Tutorial
MaxTextHigh performance, highly scalable, open-source LLM library and reference implementation written in pure Python/JAX and targeting Google Cloud TPUs and GPUs for training.Tutorial Getting started with Metrax,A hands-on guide for Metrax, a powerful and flexible metrics library for JAX.Notebook
Getting started with Metrax,A hands-on guide for Metrax, a powerful and flexible metrics library for JAX.Notebook
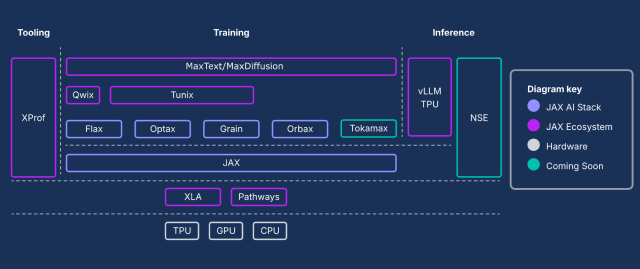 Building production AI on Google Cloud TPUs with JAXAn overview of the JAX AI Stack — a robust, end-to-end platform based on JAX, the core numerical library, into an industrial-grade solution for machine learning at any scale.Blog
Building production AI on Google Cloud TPUs with JAXAn overview of the JAX AI Stack — a robust, end-to-end platform based on JAX, the core numerical library, into an industrial-grade solution for machine learning at any scale.Blog Mastering the JAX AI stackDive into high-performance machine learning with this comprehensive video series on the JAX AI stack, centered on the developer-friendly Flax NNX library.
Mastering the JAX AI stackDive into high-performance machine learning with this comprehensive video series on the JAX AI stack, centered on the developer-friendly Flax NNX library.Beginner
Video Playlist
Optimize post-training on TPUs
Efficiently customize and align open models for high-performance serving and deployment




TPU developer resources
Explore official documentation, workload recipes, and the latest technical updates for Cloud TPUs











