
Foundations for TPU development
Build with your preferred framework and diagnostic tools to drive peak performance
 Learn about TPU architectureTensor Processing Units (TPUs) are Application-Specific Integrated Circuits (ASICs) designed by Google to accelerate machine learning workloads. Google Cloud makes TPUs available as a scalable resource.Tutorial
Learn about TPU architectureTensor Processing Units (TPUs) are Application-Specific Integrated Circuits (ASICs) designed by Google to accelerate machine learning workloads. Google Cloud makes TPUs available as a scalable resource.Tutorial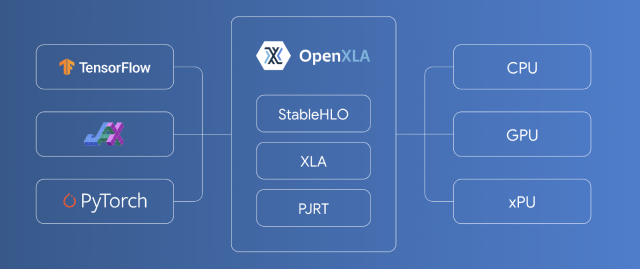 Understanding XLAXLA (Accelerated Linear Algebra) is a machine learning (ML) compiler that optimizes linear algebra, providing improvements in execution speed and memory usage.Guide
Understanding XLAXLA (Accelerated Linear Algebra) is a machine learning (ML) compiler that optimizes linear algebra, providing improvements in execution speed and memory usage.Guide

Accelerate production inference on TPUs
Deploy high-throughput, low-latency workloads using vLLM and optimized TPU serving stacks
 Optimizing Qwen 3.5-397B MoE on IronwoodThis technical report details how we systematically applied a global optimization playbook to Qwen 3.5 MoE on Ironwood TPUs.Blog
Optimizing Qwen 3.5-397B MoE on IronwoodThis technical report details how we systematically applied a global optimization playbook to Qwen 3.5 MoE on Ironwood TPUs.Blog Gemma 4 is now available on vLLM TPUvLLM introduces support & community recipes for Gemma 4, with Day 0 support on Google TPUs.Guide
Gemma 4 is now available on vLLM TPUvLLM introduces support & community recipes for Gemma 4, with Day 0 support on Google TPUs.Guide Inference Recipes for TPUGet recipes to run the latest open weight models on Ironwood with vLLM, including Qwen3 and GPT-OSS.Code
Inference Recipes for TPUGet recipes to run the latest open weight models on Ironwood with vLLM, including Qwen3 and GPT-OSS.Code
 vLLM for LLM inferenceLearn the essential skills to design and implement efficient AI inference solutions using Google Cloud's specialized hardware and popular open-source frameworks.Course
vLLM for LLM inferenceLearn the essential skills to design and implement efficient AI inference solutions using Google Cloud's specialized hardware and popular open-source frameworks.Course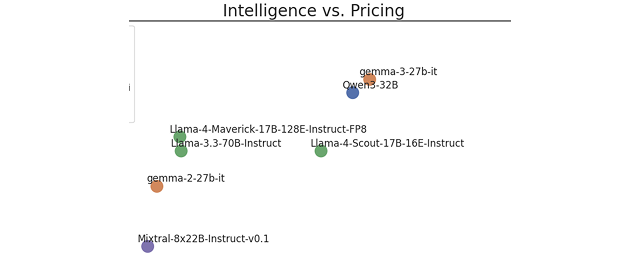 Explore benchmarking data with Inference QuickstartA hands-on guide to the Google Inference Quickstart (GIQ) recommender API to help you explore performance and pricing metrics for serving open-source Large Language Models (LLMs) on Google Kubernetes Engine (GKE).Notebook
Explore benchmarking data with Inference QuickstartA hands-on guide to the Google Inference Quickstart (GIQ) recommender API to help you explore performance and pricing metrics for serving open-source Large Language Models (LLMs) on Google Kubernetes Engine (GKE).Notebook

Scale model pre-training on TPUs
Achieve higher training throughput using JAX, PyTorch, and Keras on TPUs
 Elastic training with MaxTextWhat happens when one machine dies in the middle of a multi-node training run? In this article we'll explore a possible answer, called elastic training, using the JAX AI stack (MaxText and Pathway) and on Cloud TPUs.Blog
Elastic training with MaxTextWhat happens when one machine dies in the middle of a multi-node training run? In this article we'll explore a possible answer, called elastic training, using the JAX AI stack (MaxText and Pathway) and on Cloud TPUs.Blog Build an LLM with JAXBuild a GPT-2 style language model with 20 million parameters from scratch using JAX, the open-source library behind Google’s Gemini, Veo, and Nano Banana models.Course
Build an LLM with JAXBuild a GPT-2 style language model with 20 million parameters from scratch using JAX, the open-source library behind Google’s Gemini, Veo, and Nano Banana models.Course How to scale your modelTraining LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models.ebook
How to scale your modelTraining LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models.ebook
 A developer’s guide to training with Ironwood TPUsThis technical overview explores the specific methods and tools within the JAX and MaxText ecosystems designed to refine training efficiency and reach peak performance on Ironwood hardware.Guide
A developer’s guide to training with Ironwood TPUsThis technical overview explores the specific methods and tools within the JAX and MaxText ecosystems designed to refine training efficiency and reach peak performance on Ironwood hardware.Guide Inside the optimization of FP8 training on IronwoodGoogle’s Ironwood chips are our first TPUs to support 8-bit floating point precision, helping to accelerate AI training and inference by reducing memory usage and increasing throughput.Blog
Inside the optimization of FP8 training on IronwoodGoogle’s Ironwood chips are our first TPUs to support 8-bit floating point precision, helping to accelerate AI training and inference by reducing memory usage and increasing throughput.Blog MaxTextHigh performance, highly scalable, open-source LLM library and reference implementation written in pure Python/JAX and targeting Google Cloud TPUs and GPUs for training.Tutorial
MaxTextHigh performance, highly scalable, open-source LLM library and reference implementation written in pure Python/JAX and targeting Google Cloud TPUs and GPUs for training.Tutorial
Optimize post-training on TPUs
Efficiently customize and align open models for high-performance serving and deployment
 Scaling Agentic RL with TunixTunix is built to maximize TPU throughput, keep environments modular, and make multi-turn training efficiency fully transparent. Here is how it works under the hood.Blog
Scaling Agentic RL with TunixTunix is built to maximize TPU throughput, keep environments modular, and make multi-turn training efficiency fully transparent. Here is how it works under the hood.Blog Running PyTorch Natively on TPUs at Google ScaleTorchTPU enables developers to migrate existing PyTorch workloads to TPU with minimal code changes.Blog
Running PyTorch Natively on TPUs at Google ScaleTorchTPU enables developers to migrate existing PyTorch workloads to TPU with minimal code changes.Blog





Profile and debug TPU workloads
Uncover bottlenecks and optimize your model’s execution
 Deep Kernel profiling with XProfIntroducing the Kernel Profiling suite in XProf—a low-level hardware debugging suite engineered specifically for Pallas kernel authoring and optimization on Google TPUs.Blog
Deep Kernel profiling with XProfIntroducing the Kernel Profiling suite in XProf—a low-level hardware debugging suite engineered specifically for Pallas kernel authoring and optimization on Google TPUs.Blog Advanced TPU optimization with XProfIntroducing three advanced capabilities designed to provide instruction-level insights: Continuous Profiling Snapshots, the Utilization Viewer, and LLO Bundle Visualization.Blog
Advanced TPU optimization with XProfIntroducing three advanced capabilities designed to provide instruction-level insights: Continuous Profiling Snapshots, the Utilization Viewer, and LLO Bundle Visualization.Blog


Secure and scale TPU workloads
Design secure, high-performance network architectures for your AI workloads
 Evolving Google’s data center networks for the AI eraHow Google created an end-to-end, vertically integrated AI technology stack that comprises everything from chips to systems, to platforms and application and agentic ecosystems.Blog
Evolving Google’s data center networks for the AI eraHow Google created an end-to-end, vertically integrated AI technology stack that comprises everything from chips to systems, to platforms and application and agentic ecosystems.Blog Data encryption for AI WorkloadsLearn about additional ways to encrypt your data when using Cloud Storage along with TPUs for AI workloads.Guide
Data encryption for AI WorkloadsLearn about additional ways to encrypt your data when using Cloud Storage along with TPUs for AI workloads.Guide Using VPC service controlsGet hands-on tips, guidance on how to set up a service perimeter using VPC Service Controls in the Google Cloud console.Guide
Using VPC service controlsGet hands-on tips, guidance on how to set up a service perimeter using VPC Service Controls in the Google Cloud console.Guide
Community contributions
Resources and code samples from our developer community
 Legal domain adaptation of Gemma with TunixA Tunix-based workflow for adapting Gemma to handle Indian legal domain specifications.Guide
Legal domain adaptation of Gemma with TunixA Tunix-based workflow for adapting Gemma to handle Indian legal domain specifications.Guide Fine-tuning Gemma 3 to speak Gen ZAn implementation showing how to push a fine-tuning job using a single @kinetic.run() decorator.Guide
Fine-tuning Gemma 3 to speak Gen ZAn implementation showing how to push a fine-tuning job using a single @kinetic.run() decorator.Guide Tuning Pallas from scratchA practical walkthrough on writing, profiling, and auto-tuning custom TPU kernels.Guide
Tuning Pallas from scratchA practical walkthrough on writing, profiling, and auto-tuning custom TPU kernels.Guide

TPU developer resources
Explore official documentation, workload recipes, and the latest technical updates for Cloud TPUs


















