
Managed Service untuk Apache Spark (sebelumnya dikenal sebagai Dataproc)
Cara baru untuk menjalankan Spark: Lebih mudah, cerdas, dan cepat
Jalankan workload Apache Spark dengan Serverless Spark tanpa pengoperasian atau cluster terkelola. Percepat pengembangan dengan alur kerja AI agentic dan tingkatkan performa dengan Lightning Engine.
Pelanggan baru mendapatkan kredit gratis senilai $300 untuk mencoba Managed Service untuk Apache Spark dan produk Google Cloud lainnya.
Apache Spark adalah merek dagang dari Apache Software Foundation.

Fitur
Performa terbaik di industri dengan Lightning Engine
Percepat workload ETL dan SQL berskala besar hingga 4,9x lebih cepat dibandingkan Apache Spark open source tanpa perubahan kode. Lightning Engine menggunakan mesin eksekusi vektor C++ native, caching cerdas, dan pengacakan kolom yang dioptimalkan. Kombinasikan hal ini dengan penyetelan otomatis Spark yang cerdas untuk menghilangkan biaya penyetelan manual, mengoptimalkan memori, dan mencegah error OOM secara otomatis.
*Kueri berasal dari TPC-DS standard dan TPC-H standard
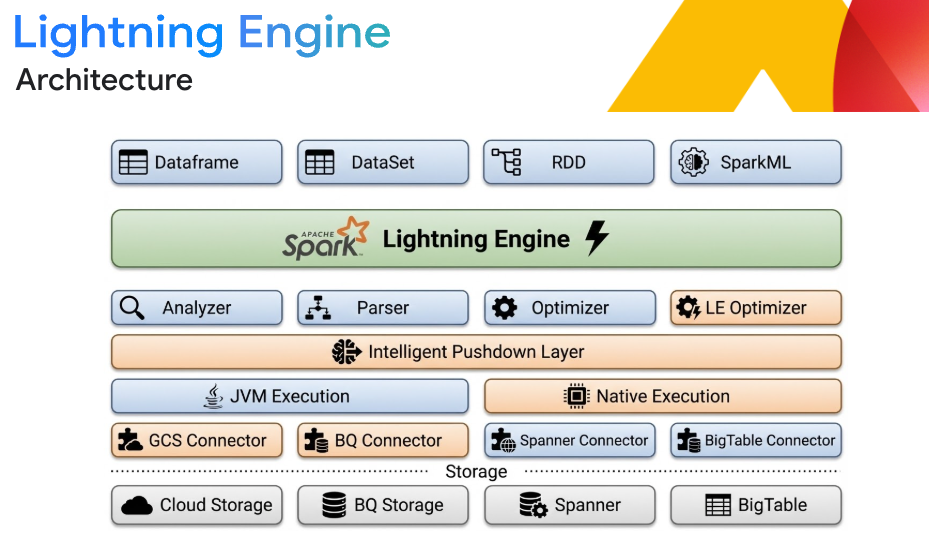
Interoperabilitas lakehouse yang fleksibel
Bangun arsitektur lakehouse terbuka yang menjamin independensi mesin. Memproses data dalam format terbuka seperti Apache Iceberg langsung dari Google Cloud Storage. Terintegrasi secara lancar dengan BigQuery dan Knowledge Catalog (sebelumnya dikenal sebagai Dataplex) untuk analisis dan tata kelola terpadu, yang memastikan interoperabilitas multi-engine yang sesungguhnya tanpa lapisan terjemahan.
Pengalaman developer yang didukung AI terpadu
Selesaikan backlog Anda dengan agen data yang mengambil tindakan, bukan hanya menjawab pertanyaan. Percepat alur kerja Anda menggunakan Gemini yang terintegrasi ke dalam ekstensi agentic VSCode untuk mempercepat produktivitas workload Spark dari pengembangan hingga produksi, atau gunakan IDE pilihan Anda. Manfaatkan Agen Data Engineering dan Agen Data Science untuk mengotomatiskan data wrangling, membangun pipeline dari bahasa alami, dan membuat kode PySpark. Mengatasi masalah tugas Spark yang bermasalah secara otomatis dengan Gemini Cloud Assist. Menggabungkan SQL dan Spark dalam satu notebook yang terpadu serta mengutamakan AI.
Siap untuk AI/ML perusahaan
Membangun dan mengoperasionalkan seluruh siklus proses machine learning Anda. Mempercepat inferensi dan pelatihan model dengan dukungan GPU, yang didukung oleh NVIDIA RAPIDS, dan Runtime ML yang telah dikonfigurasi sebelumnya untuk PyTorch dan XGBoost. Melakukan integrasi dengan ekosistem Google Cloud AI untuk mengorkestrasi MLOps end-to-end dan mengelola aset dengan integrasi Model Registry Gemini Enterprise Agent Platform.
Migrasi yang aman, skalabel, dan lancar
Integrasikan secara lancar dengan postur keamanan Anda menggunakan IAM, Kontrol Layanan VPC, dan Kerberos. Migrasikan workload Spark cloud dan lama dengan mudah menggunakan template dan alat Managed Service untuk Apache Spark. Workload lift-and-shift dengan dukungan untuk Spark 2.x hingga Spark 4.0 tanpa refaktorisasi kode langsung.
Efisiensi multi-tenant dan kontrol FinOps
Mengoptimalkan pemanfaatan resource dan menghemat biaya tidak ada aktivitas. Men-deploy cluster Spark multi-tenant yang memungkinkan hingga 800 pengguna berbagi resource komputasi sekaligus mempertahankan isolasi data dan lingkungan yang ketat. Kontrol tagihan Anda dengan kapabilitas penskalaan hingga nol, penagihan per detik, dan dukungan Spot VM untuk workload yang fleksibel.
Ekosistem open source dan fleksibel
Hindari ketergantungan pada vendor. Meskipun dioptimalkan untuk Apache Spark, cluster terkelola kami mendukung lebih dari 30 alat open source seperti Apache Hadoop, Flink, dan Trino. Terintegrasi secara lancar dengan orchestrator seperti Managed Service untuk Apache Airflow dan diperluas dengan Kubernetes dan Docker untuk fleksibilitas maksimum.
Opsi deployment
| Opsi deployment | Pilih antara kontrol cluster terkelola yang mendetail atau kemudahan tanpa pengoperasian dari pengalaman serverless untuk opsi terbaik bagi workload Anda. | ||
|---|---|---|---|
| Mode Deployment: | Penjelasan: | Cocok untuk: | Bayar Untuk: |
Serverless | Tugas Spark sebagai layanan. Managed Spark, infrastruktur terkelola | Pipeline baru, analisis interaktif, dan workload yang tidak terduga di mana model tanpa pengoperasian dan bayar per tugas lebih disukai. | Waktu proses tugas |
Cluster | Cluster Spark sebagai layanan. Managed Spark, infrastruktur Anda | Memigrasikan workload Spark atau OSS lama, menjalankan cluster persisten, atau memerlukan penyesuaian open source yang mendalam. | Waktu operasional cluster |
Opsi deployment
Pilih antara kontrol cluster terkelola yang mendetail atau kemudahan tanpa pengoperasian dari pengalaman serverless untuk opsi terbaik bagi workload Anda.
Serverless
Tugas Spark sebagai layanan.
Managed Spark, infrastruktur terkelola
Pipeline baru, analisis interaktif, dan workload yang tidak terduga di mana model tanpa pengoperasian dan bayar per tugas lebih disukai.
Waktu proses tugas
Cluster
Cluster Spark sebagai layanan.
Managed Spark, infrastruktur Anda
Memigrasikan workload Spark atau OSS lama, menjalankan cluster persisten, atau memerlukan penyesuaian open source yang mendalam.
Waktu operasional cluster
Cara Kerjanya
Mempermudah Spark dengan cluster terkelola atau serverless tanpa pengoperasian. Bekerja lebih cerdas dengan Gemini di IDE pilihan Anda, menggunakan AI agentic untuk mempercepat pengembangan PySpark. Jalankan tugas lebih cepat dengan Lightning Engine, sekaligus mempertahankan tata kelola terpadu di seluruh lakehouse terbuka Anda dengan Knowledge Catalog.
Mempermudah Spark dengan cluster terkelola atau serverless tanpa pengoperasian. Bekerja lebih cerdas dengan Gemini di IDE pilihan Anda, menggunakan AI agentic untuk mempercepat pengembangan PySpark. Jalankan tugas lebih cepat dengan Lightning Engine, sekaligus mempertahankan tata kelola terpadu di seluruh lakehouse terbuka Anda dengan Knowledge Catalog.
Data engineering dalam skala besar
Pipeline ETL otomatis
Pipeline ETL otomatis
Buat pipeline ETL Spark berbasis peristiwa yang tangguh dan otomatis diskalakan sesuai permintaan. Manfaatkan eksekusi serverless untuk workload yang tidak terduga atau cluster terkelola untuk tugas persisten. Gunakan template alur kerja untuk mengotomatiskan tugas pemrosesan data paling penting di tingkat produksi Anda dari awal hingga akhir.


Tutorial, panduan memulai, dan lab
Pipeline ETL otomatis
Pipeline ETL otomatis
Buat pipeline ETL Spark berbasis peristiwa yang tangguh dan otomatis diskalakan sesuai permintaan. Manfaatkan eksekusi serverless untuk workload yang tidak terduga atau cluster terkelola untuk tugas persisten. Gunakan template alur kerja untuk mengotomatiskan tugas pemrosesan data paling penting di tingkat produksi Anda dari awal hingga akhir.
Data science dan machine learning
Data science interaktif
Data science interaktif
Dukung data scientist untuk mengeksplorasi data dan melakukan iterasi pada model Spark ML. Padukan SQL dan Spark menggunakan Gemini dengan ekstensi agen VSCode atau IDE pilihan Anda, sehingga beralih dengan lancar dari eksplorasi data ke pembuatan model dengan PySpark menggunakan eksekusi serverless. Hubungkan GPU dengan satu perintah.


Tutorial, panduan memulai, dan lab
Data science interaktif
Data science interaktif
Dukung data scientist untuk mengeksplorasi data dan melakukan iterasi pada model Spark ML. Padukan SQL dan Spark menggunakan Gemini dengan ekstensi agen VSCode atau IDE pilihan Anda, sehingga beralih dengan lancar dari eksplorasi data ke pembuatan model dengan PySpark menggunakan eksekusi serverless. Hubungkan GPU dengan satu perintah.
Modernisasi lakehouse
Data lakehouse terbuka
Data lakehouse terbuka
Menggunakan Managed Service untuk Apache Spark sebagai mesin pemrosesan untuk data lakehouse modern Anda. Memproses data dalam format terbuka seperti Apache Iceberg langsung dari data lake Anda, sehingga menghilangkan data silo. Terintegrasi dengan BigQuery dan Lakehouse untuk Apache Iceberg untuk platform analisis multi-engine yang terpadu.
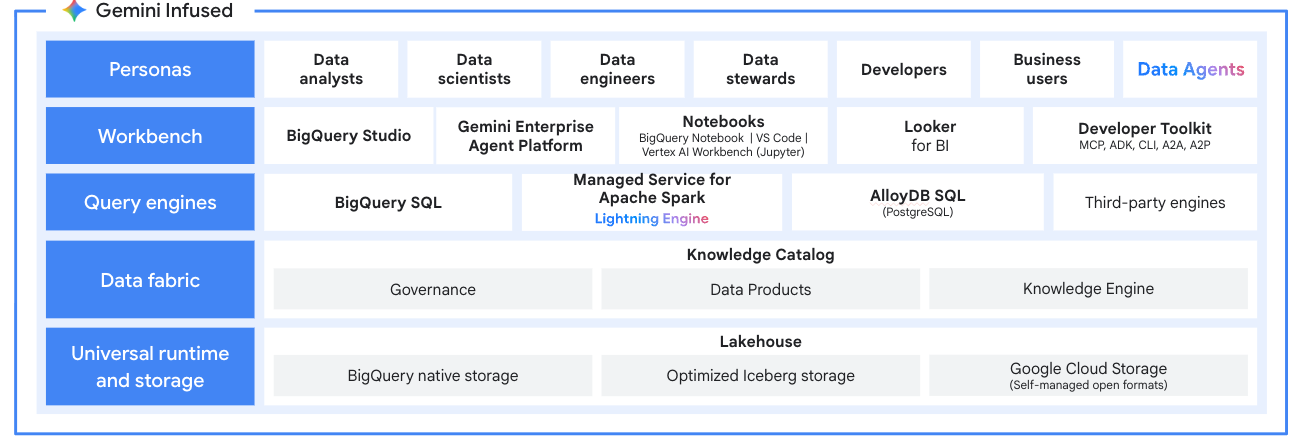

Tutorial, panduan memulai, dan lab
Data lakehouse terbuka
Data lakehouse terbuka
Menggunakan Managed Service untuk Apache Spark sebagai mesin pemrosesan untuk data lakehouse modern Anda. Memproses data dalam format terbuka seperti Apache Iceberg langsung dari data lake Anda, sehingga menghilangkan data silo. Terintegrasi dengan BigQuery dan Lakehouse untuk Apache Iceberg untuk platform analisis multi-engine yang terpadu.
Harga
| Cara kerja penetapan harga Managed Service untuk Apache Spark | Harga bergantung pada model deployment yang Anda pilih. Serverless ditagih per eksekusi tugas, sedangkan cluster ditagih untuk komputasi dan waktu operasional yang mendasarinya. | |
|---|---|---|
| Mode deployment: | Yang Anda bayarkan untuk: | Yang Anda bayar: |
Serverless | Hanya bayar sesuai dengan penggunaan Anda. Ditagih per detik untuk komputasi, GPU, dan penyimpanan shuffle. Penskalaan hingga nol memastikan Anda tidak pernah membayar kapasitas yang tidak digunakan. | Mulai dari $0,06 per DCU jam |
Paket premium dan akselerator: Akses Lightning Engine untuk performa hingga 4,9x lebih cepat atau hubungkan GPU NVIDIA untuk workload AI/ML. | Mulai dari $0,089 per DCU jam Paket premium serverless | |
Cluster | Bayar waktu operasional cluster. Ditagih untuk resource Compute Engine yang mendasarinya ditambah biaya pengelolaan tetap. Manfaatkan Spot VM dan zero-scale untuk mengoptimalkan biaya. | Mulai dari $0,01 per vCPU jam Biaya pengelolaan |
Add-on Lightning Engine: Hadirkan performa terobosan ke cluster Anda. Nikmati eksekusi hingga 4,9x lebih cepat dibandingkan Spark open source. | Mulai dari $0,0025 per vCPU jam | |
Pelajari lebih lanjut harga Managed Service untuk Apache Spark. Lihat semua detail penetapan harga.
Cara kerja penetapan harga Managed Service untuk Apache Spark
Harga bergantung pada model deployment yang Anda pilih. Serverless ditagih per eksekusi tugas, sedangkan cluster ditagih untuk komputasi dan waktu operasional yang mendasarinya.
Serverless
Hanya bayar sesuai dengan penggunaan Anda. Ditagih per detik untuk komputasi, GPU, dan penyimpanan shuffle. Penskalaan hingga nol memastikan Anda tidak pernah membayar kapasitas yang tidak digunakan.
Starting at
$0,06 per DCU jam
Paket premium dan akselerator:
Akses Lightning Engine untuk performa hingga 4,9x lebih cepat atau hubungkan GPU NVIDIA untuk workload AI/ML.
Starting at
$0,089 per DCU jam
Paket premium serverless
Cluster
Bayar waktu operasional cluster. Ditagih untuk resource Compute Engine yang mendasarinya ditambah biaya pengelolaan tetap. Manfaatkan Spot VM dan zero-scale untuk mengoptimalkan biaya.
Starting at
$0,01 per vCPU jam
Biaya pengelolaan
Add-on Lightning Engine:
Hadirkan performa terobosan ke cluster Anda. Nikmati eksekusi hingga 4,9x lebih cepat dibandingkan Spark open source.
Starting at
$0,0025 per vCPU jam
Pelajari lebih lanjut harga Managed Service untuk Apache Spark. Lihat semua detail penetapan harga.
Kasus Bisnis
Kisah sukses pelanggan

“Kami melihat beberapa pemeriksaan kualitas kami yang sebelumnya memerlukan waktu sekitar 11 jam kini dapat diselesaikan dalam hitungan menit.”
Michael Manos, Chief Technology Officer Dun & Bradstreet
Migrasi ke Google Cloud telah membantu Dun & Bradstreet meningkatkan kecepatan aliran data secara signifikan, mengurangi proses pemeriksaan kualitas dari hitungan jam menjadi menit, dan memangkas waktu yang dibutuhkan untuk memublikasikan data baru menjadi setengahnya. Fondasi data yang kuat ini juga memungkinkan Dun & Bradstreet memanfaatkan sepenuhnya ekosistem Google Cloud, termasuk teknologi data dan AI yang canggih.



Perbedaan Managed Service untuk Apache Spark
Produktivitas tanpa pengoperasian dengan opsi deployment yang fleksibel. Pilih eksekusi serverless atau cluster yang terkelola sepenuhnya untuk menghilangkan beban infrastruktur dan biaya penyesuaian manual.
Pengembangan AI agentic. Percepat alur kerja Anda dengan Gemini yang terintegrasi ke dalam ekstensi agentic VSCode atau dengan IDE pilihan Anda bersama dengan Agen Data yang mengotomatiskan coding PySpark, penyiapan data, dan pemecahan masalah tugas dalam notebook terpadu.
Performa terbaik di industri. Didukung oleh Lightning Engine. Percepat workload ETL dan data science Anda yang paling menuntut hingga 4,9x lipat, sehingga mengurangi total biaya kepemilikan Anda secara signifikan










Referensi tambahan:
FAQ
Apa yang terjadi pada Dataproc dan Serverless Spark?
Untuk menyederhanakan pengalaman Anda, kami telah memadukan Dataproc dan Google Cloud Serverless untuk Apache Spark dalam satu produk: Managed Service untuk Apache Spark. Anda mendapatkan kemampuan canggih yang sama persis, tetapi sekarang Anda cukup memilih model deployment yang diinginkan—serverless tanpa pengoperasian atau cluster yang terkelola sepenuhnya—dari satu antarmuka terpadu. Bandingkan kedua mode deployment secara lebih mendetail.
Kapan saya harus memilih cluster serverless versus cluster terkelola?
Pilih serverless jika Anda ingin berfokus sepenuhnya pada kode tanpa pengelolaan infrastruktur, yang cocok untuk pipeline baru dan analisis ad-hoc. Pilih cluster terkelola jika Anda memerlukan kontrol terperinci, memigrasikan workload Spark atau OSS cloud atau lama, atau memerlukan cluster persisten dengan beragam alat open source.
Apa itu Lightning Engine?
Lightning Engine adalah mesin eksekusi native Google Cloud yang sangat dioptimalkan. Dibangun dengan library C++, mesin ini mengoptimalkan setiap lapisan, mulai dari konektor penyimpanan throughput tinggi hingga caching cerdas. Mesin ini memberikan performa hingga 4,9x lebih baik daripada Spark standar dan 2x lipat harga-performa dibandingkan alternatif Spark berkecepatan tinggi terkemuka, yang terintegrasi dengan lancar ke dalam deployment serverless atau cluster Anda tanpa perubahan kode.
Apakah saya perlu menginstal library ML saya sendiri seperti PyTorch?
Tidak. Jika menjalankan workload AI/ML, Anda dapat menggunakan Runtime ML yang telah dikonfigurasi sebelumnya. Lingkungan ini dilengkapi dengan library umum seperti PyTorch, XGBoost, dan scikit-learn bawaan, serta driver GPU NVIDIA yang dioptimalkan, sehingga tidak perlu lagi melakukan penyiapan yang rumit.
Apakah Managed Service untuk Apache Spark sepenuhnya kompatibel dengan open source?
Ya. Kami menyediakan lingkungan Apache Spark yang 100% kompatibel dengan open source. Anda dapat menjalankan kode Spark yang ada tanpa modifikasi, sehingga memastikan portabilitas workload yang lengkap dan menghindari keterikatan vendor.
Bagaimana Gemini AI membantu pengembangan Spark?
AI Gemini dapat langsung diintegrasikan ke IDE pilihan Anda untuk bertindak sebagai kopilot AI Anda. Hal ini membantu Anda menulis dan men-debug kode PySpark dengan lebih cepat, sementara Gemini Cloud Assist memberikan analisis penyebab masalah otomatis dan rekomendasi pemecahan masalah untuk tugas yang gagal.
Dapatkah saya menggunakan layanan ini untuk membangun data lakehouse terbuka?
Tentu saja. Managed Service untuk Apache Spark adalah mesin pemrosesan inti untuk lakehouse terbuka Google Cloud. BigLake memungkinkan Anda memproses data dalam format terbuka seperti Apache Iceberg langsung dari Cloud Storage, yang terintegrasi secara lancar dengan BigQuery dan Knowledge Catalog untuk Apache Iceberg.
Bagaimana cara kerja tingkat harga Standard dan Premium?
Paket Standard dan Premium saat ini hanya berlaku untuk deployment serverless. Paket Standard cocok untuk batch processing dan ETL tujuan umum yang hemat biaya. Paket premium dirancang untuk workload Anda yang paling menuntut, sehingga meningkatkan performa 4,9x lipat dibandingkan Apache Spark open source dengan Lightning Engine dan menyediakan akses ke kapabilitas AI/ML yang dipercepat GPU.











