Cluster Director
Orchestrazione dell'AI per cluster Kubernetes e Slurm
Configura, esegui il deployment e gestisci facilmente cluster AI o HPC. Ottieni i vantaggi dell'automazione dell'infrastruttura gestita senza limitare il tuo controllo.

Funzionalità
Un servizio di infrastruttura gestito per Slurm e Kubernetes
Puoi accedere alle funzionalità di Cluster Director in due modi:
- Direttamente tramite il control plane, l'API o la CLI per i job che utilizzano Slurm o orchestratori personalizzati. Questo ambiente unificato si integra anche con Google Kubernetes Engine (GKE), offrendoti un'unica e potente interfaccia per creare e supervisionare sia i cluster Slurm che Kubernetes.
- All'interno di GKE o Compute Engine. In questi contesti, puoi accedere alle funzionalità di Cluster Director mentre lavori da un ambiente familiare.
Pianificazione dei job semplificata
Cluster Director fornisce la pianificazione dei job a tolleranza di errore e altamente scalabile pronta all'uso. Il nodo controller viene gestito per te. Puoi configurare facilmente i nodi di accesso per il tuo cluster, inclusi il tipo di macchina, l'immagine di origine e la dimensione del disco di avvio.
Gestione intuitiva dei cluster
Utilizza il control plane per creare, aggiornare ed eliminare facilmente il tuo cluster. Inoltre, semplifica la rete consentendoti di eseguire il deployment dei cluster su una rete VPC nuova e appositamente creata o su una rete esistente. Per l'archiviazione, puoi creare e collegare una nuova istanza Filestore o Google Cloud Managed Lustre oppure connetterti a un bucket Cloud Storage esistente.
Posizionamento consapevole della topologia
Per massimizzare le prestazioni, Cluster Director è profondamente integrato con la topologia di rete di Google. Ciò garantisce che le VM all'interno di un cluster siano posizionate in stretta prossimità fisica, riducendo la latenza di rete, fondamentale per i workload di addestramento distribuiti altamente sincronizzati.
Visibilità e approfondimenti completi
La dashboard di osservabilità integrata di Cluster Director offre una visione chiara dell'integrità, dell'utilizzo e delle prestazioni del cluster, in modo da poter comprendere rapidamente il comportamento del sistema e diagnosticare i problemi in un unico posto. La dashboard è progettata per scalare facilmente a decine di migliaia di VM.
Esecuzioni di addestramento senza interruzioni
Ottieni un'affidabilità di base richiedendo un Bill of Health ("Rapporto sullo stato di salute"), oltre a funzionalità aggiuntive come il checkpointing a 3 livelli e i controlli di manutenzione avanzati per massimizzare l'efficienza dell'addestramento.
Come funziona
Gli utenti dell'infrastruttura di AI possono passare settimane a risolvere problemi di configurazione prima di poter eseguire il deployment, ma non deve essere per forza così. Scopri cosa ti aspetta come utente di Cluster Director per la prima volta, dalla preparazione di un ambiente al deployment, alla trasformazione delle interruzioni in eventi gestiti.
Gli utenti dell'infrastruttura di AI possono passare settimane a risolvere problemi di configurazione prima di poter eseguire il deployment, ma non deve essere per forza così. Scopri cosa ti aspetta come utente di Cluster Director per la prima volta, dalla preparazione di un ambiente al deployment, alla trasformazione delle interruzioni in eventi gestiti.

Qualificazione e preparazione pre-deployment
Progetta una base affidabile e ad alte prestazioni
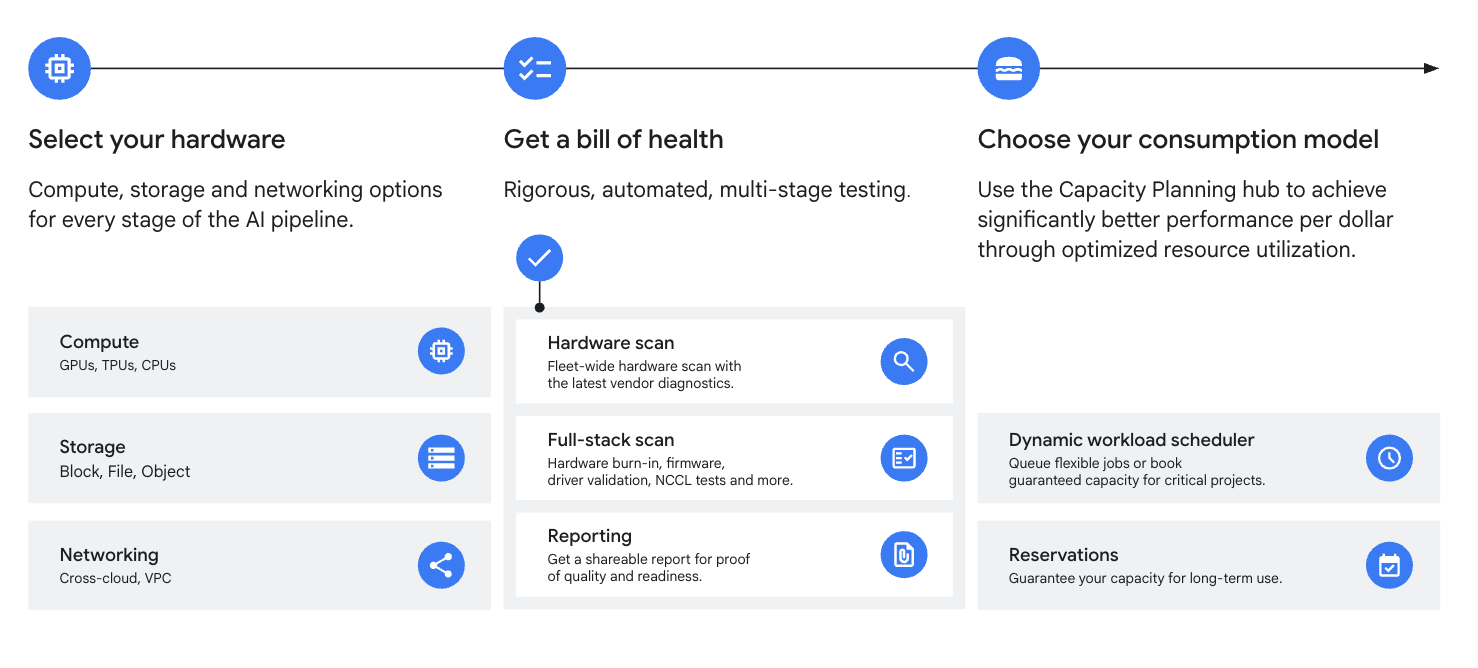
Prima di avviare un cluster, devi assicurarti che gli acceleratori siano performanti e affidabili fin da subito. Cluster Director fornisce un posizionamento intelligente e consapevole della topologia per le TPU e le GPU.
Ogni componente di calcolo, rete e archiviazione viene convalidato attraverso un rigoroso processo di qualificazione in più fasi, documentato in un dettagliato Bill of Health ("Rapporto sullo stato di salute") che fornisce la prova definitiva di qualità e idoneità.
Risorse per l'apprendimento
Progetta una base affidabile e ad alte prestazioni
Prima di avviare un cluster, devi assicurarti che gli acceleratori siano performanti e affidabili fin da subito. Cluster Director fornisce un posizionamento intelligente e consapevole della topologia per le TPU e le GPU.
Ogni componente di calcolo, rete e archiviazione viene convalidato attraverso un rigoroso processo di qualificazione in più fasi, documentato in un dettagliato Bill of Health ("Rapporto sullo stato di salute") che fornisce la prova definitiva di qualità e idoneità.
Esegui il deployment del cluster
Esegui il deployment del cluster in pochi minuti, non giorni
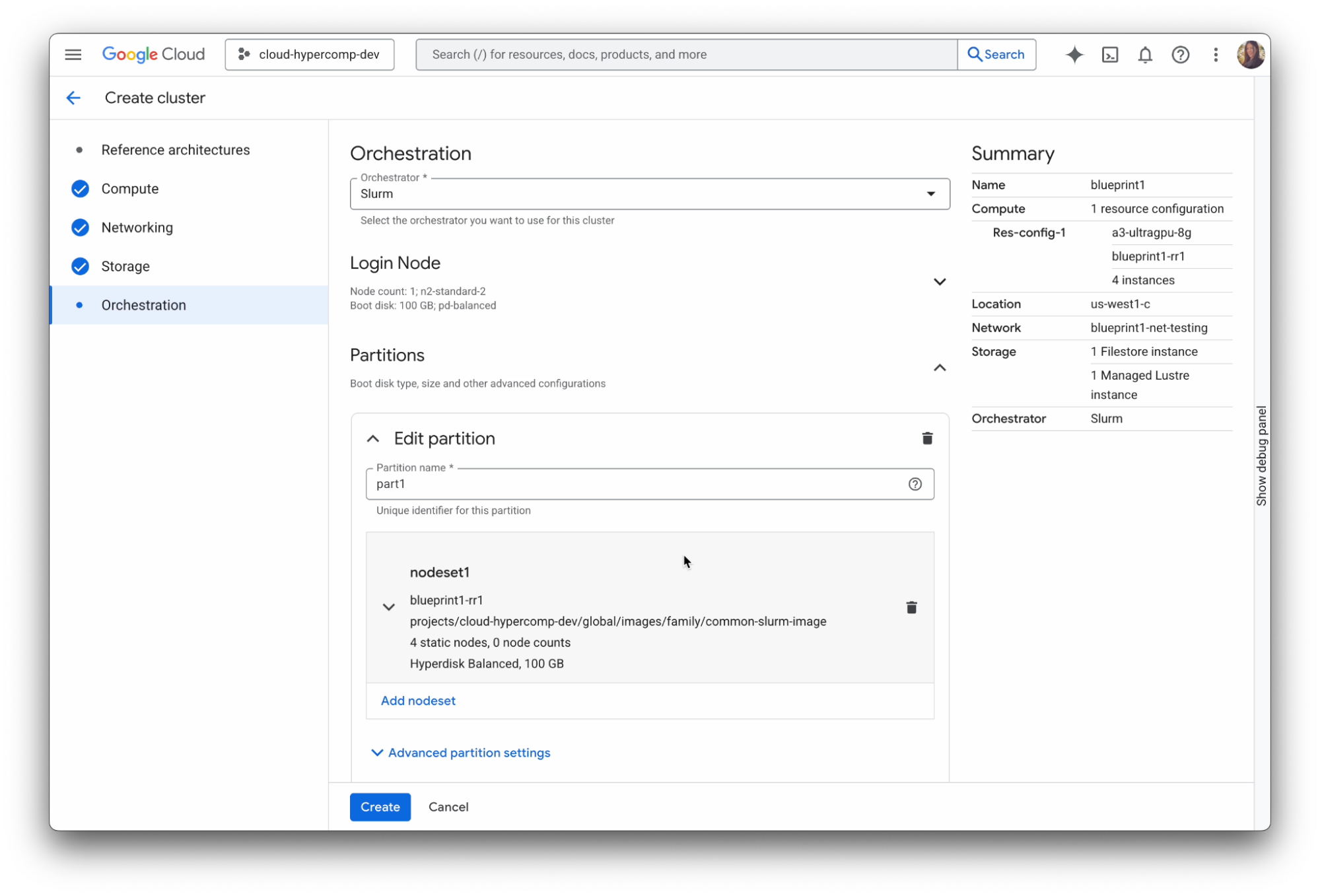
Rimuovi la complessità della configurazione di un cluster GKE o Slurm. Inizia con architetture di riferimento convalidate, scegli le risorse di acceleratore e archiviazione e lascia che Cluster Director faccia il resto.
Esegui il deployment di un ambiente completamente ottimizzato su qualsiasi scala con le best practice di Google per prestazioni e topologia integrate, riducendo drasticamente i tempi di deployment.
Risorse per l'apprendimento
Esegui il deployment del cluster in pochi minuti, non giorni
Rimuovi la complessità della configurazione di un cluster GKE o Slurm. Inizia con architetture di riferimento convalidate, scegli le risorse di acceleratore e archiviazione e lascia che Cluster Director faccia il resto.
Esegui il deployment di un ambiente completamente ottimizzato su qualsiasi scala con le best practice di Google per prestazioni e topologia integrate, riducendo drasticamente i tempi di deployment.
Gestisci il tuo cluster
Gestione e osservabilità dei cluster
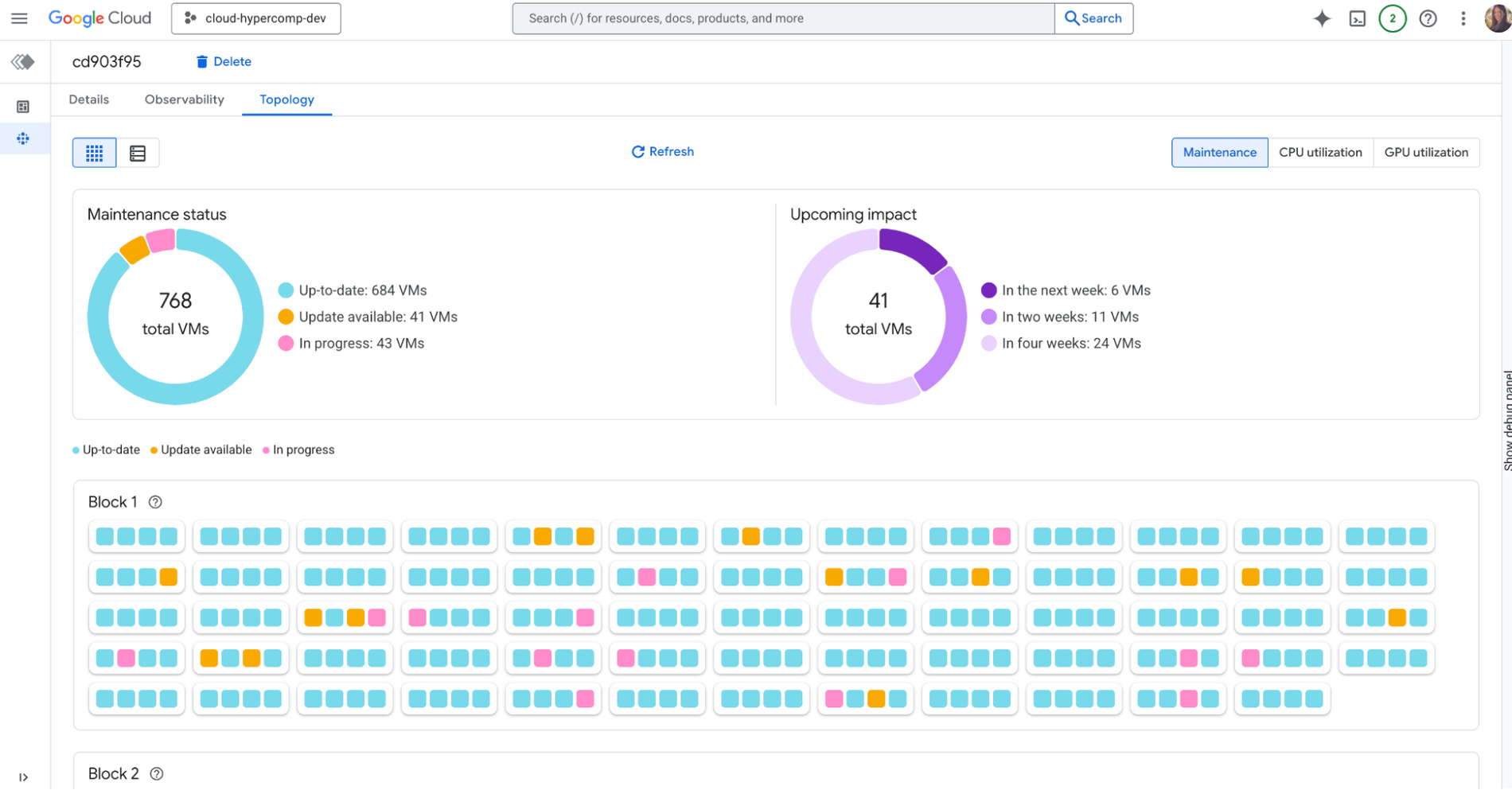
Colma il divario tra l'infrastruttura non elaborata e l'esecuzione di un job con una singola console per il tuo cluster Slurm. Ottieni una vista della topologia dell'integrità e dell'utilizzo del cluster.
Quando sorgono problemi, utilizza l'osservabilità incentrata sul job per correlare istantaneamente le metriche del full stack con un singolo ID job, trasformando ore di congetture in pochi clic e identificando rapidamente la causa principale di eventuali rallentamenti.
Risorse per l'apprendimento
Gestione e osservabilità dei cluster
Colma il divario tra l'infrastruttura non elaborata e l'esecuzione di un job con una singola console per il tuo cluster Slurm. Ottieni una vista della topologia dell'integrità e dell'utilizzo del cluster.
Quando sorgono problemi, utilizza l'osservabilità incentrata sul job per correlare istantaneamente le metriche del full stack con un singolo ID job, trasformando ore di congetture in pochi clic e identificando rapidamente la causa principale di eventuali rallentamenti.
Rileva i problemi hardware
Funzionalità di autoriparazione
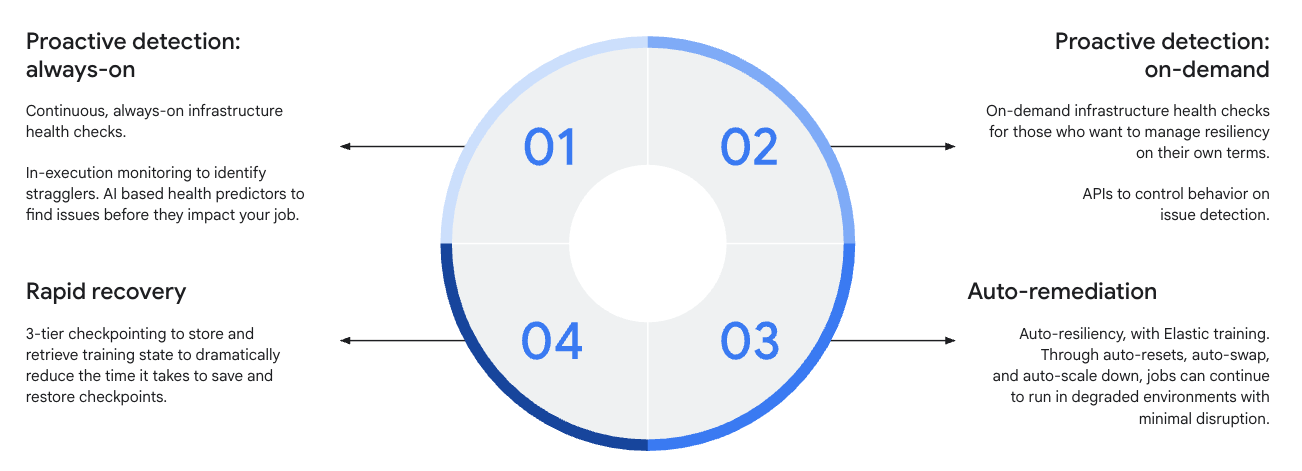
Puoi utilizzare Cluster Director per rilevare, risolvere e recuperare in modo proattivo i problemi dell'infrastruttura.
Ad esempio, ottieni controlli di integrità sempre attivi, rilevamento di elementi in ritardo e un predittore di integrità AI per identificare in modo proattivo i problemi.
Risorse per l'apprendimento
Funzionalità di autoriparazione
Puoi utilizzare Cluster Director per rilevare, risolvere e recuperare in modo proattivo i problemi dell'infrastruttura.
Ad esempio, ottieni controlli di integrità sempre attivi, rilevamento di elementi in ritardo e un predittore di integrità AI per identificare in modo proattivo i problemi.
Prezzi
| Come funzionano i prezzi di Cluster Director | L'utilizzo di Cluster Director non comporta costi aggiuntivi. Paghi solo le risorse Google Cloud sottostanti utilizzate dai tuoi cluster, come calcolo, archiviazione e rete. | |
|---|---|---|
| Servizi | Descrizione | Prezzo (USD) |
Inizia senza costi | I nuovi utenti ricevono 300 $ di crediti di prova gratuita da utilizzare entro 90 giorni. | Senza costi |
Il livello senza costi di Compute Engine offre un'istanza VM e2-micro, fino a 30 GB di spazio di archiviazione Standard Persistent Disk e fino a 1 GB di trasferimenti di dati in uscita al mese. | Senza costi | |
Istanze VM, archiviazione e networking | Per ulteriori informazioni, consulta la pagina relativa ai prezzi di Compute Engine. Paghi solo per i servizi che utilizzi. Nessun pagamento anticipato. Nessun costo di recesso. I prezzi variano in base al prodotto e all'utilizzo. | A partire da $ 0,01 (e2-micro, pagamento a consumo) |
Come funzionano i prezzi di Cluster Director
L'utilizzo di Cluster Director non comporta costi aggiuntivi. Paghi solo le risorse Google Cloud sottostanti utilizzate dai tuoi cluster, come calcolo, archiviazione e rete.
Inizia senza costi
I nuovi utenti ricevono 300 $ di crediti di prova gratuita da utilizzare entro 90 giorni.
Senza costi
Il livello senza costi di Compute Engine offre un'istanza VM e2-micro, fino a 30 GB di spazio di archiviazione Standard Persistent Disk e fino a 1 GB di trasferimenti di dati in uscita al mese.
Senza costi
Istanze VM, archiviazione e networking
Per ulteriori informazioni, consulta la pagina relativa ai prezzi di Compute Engine.
Paghi solo per i servizi che utilizzi. Nessun pagamento anticipato. Nessun costo di recesso. I prezzi variano in base al prodotto e all'utilizzo.
Starting at
$ 0,01
(e2-micro, pagamento a consumo)


















