O que é um banco de dados relacional?
Um banco de dados relacional é um conjunto de informações que organiza dados em relações predefinidas, em que os dados são armazenados em uma ou mais tabelas (ou "relações") de colunas e linhas, facilitando a visualização e a compreensão de como diferentes estruturas de dados se relacionam. Os relacionamentos são uma conexão lógica entre diferentes tabelas, que se estabelecem com base na interação entre elas.
Saiba como os bancos de dados relacionais do Google Cloud Cloud SQL, Cloud Spanner e AlloyDB para PostgreSQL podem ajudar você a reduzir os custos operacionais e a ajudar na criação de aplicativos transformadores.
Tudo pronto para começar? Crie uma instância de teste gratuito de 90 dias do Cloud Spanner com 10 GB de armazenamento sem custos financeiros.
Banco de dados relacional definido
Um banco de dados relacional (RDB) é uma forma de estruturar informações em tabelas, linhas e colunas. Ao combinar tabelas, o RDB consegue estabelecer vinculações (ou relacionamentos) entre informações, o que facilita o entendimento e a geração de insights sobre a relação entre vários pontos de dados.
O modelo de banco de dados relacional
Desenvolvido por EF Codd, da IBM, na década de 1970, o modelo de banco de dados relacional permite que qualquer tabela seja relacionada a outra tabela usando um atributo comum. Em vez de usar estruturas hierárquicas para organizar dados, Codd propôs uma mudança para o uso de um modelo de dados em que eles são armazenados, acessados e relacionados em tabelas sem reorganizar as tabelas que os contêm.
Pense no banco de dados relacional como uma coleção de arquivos de planilha que ajuda empresas a organizar, gerenciar e relacionar dados. No modelo de banco de dados relacional, cada "planilha" é uma tabela que armazena informações, representadas por colunas (atributos) e linhas (registros ou tuplas).
Os atributos (colunas) especificam um tipo de dados, e cada registro (ou linha) contém o valor desse tipo específico. Todas as tabelas em um banco de dados relacional têm um atributo conhecido como chave primária, que é um identificador exclusivo de uma linha. Cada linha pode ser usada para criar uma relação entre tabelas diferentes usando uma chave externa, uma referência a uma chave primária de outra tabela atual.
Vamos ver como o modelo de banco de dados relacional funciona na prática:
Digamos que você tenha uma tabela Cliente e uma Pedido.
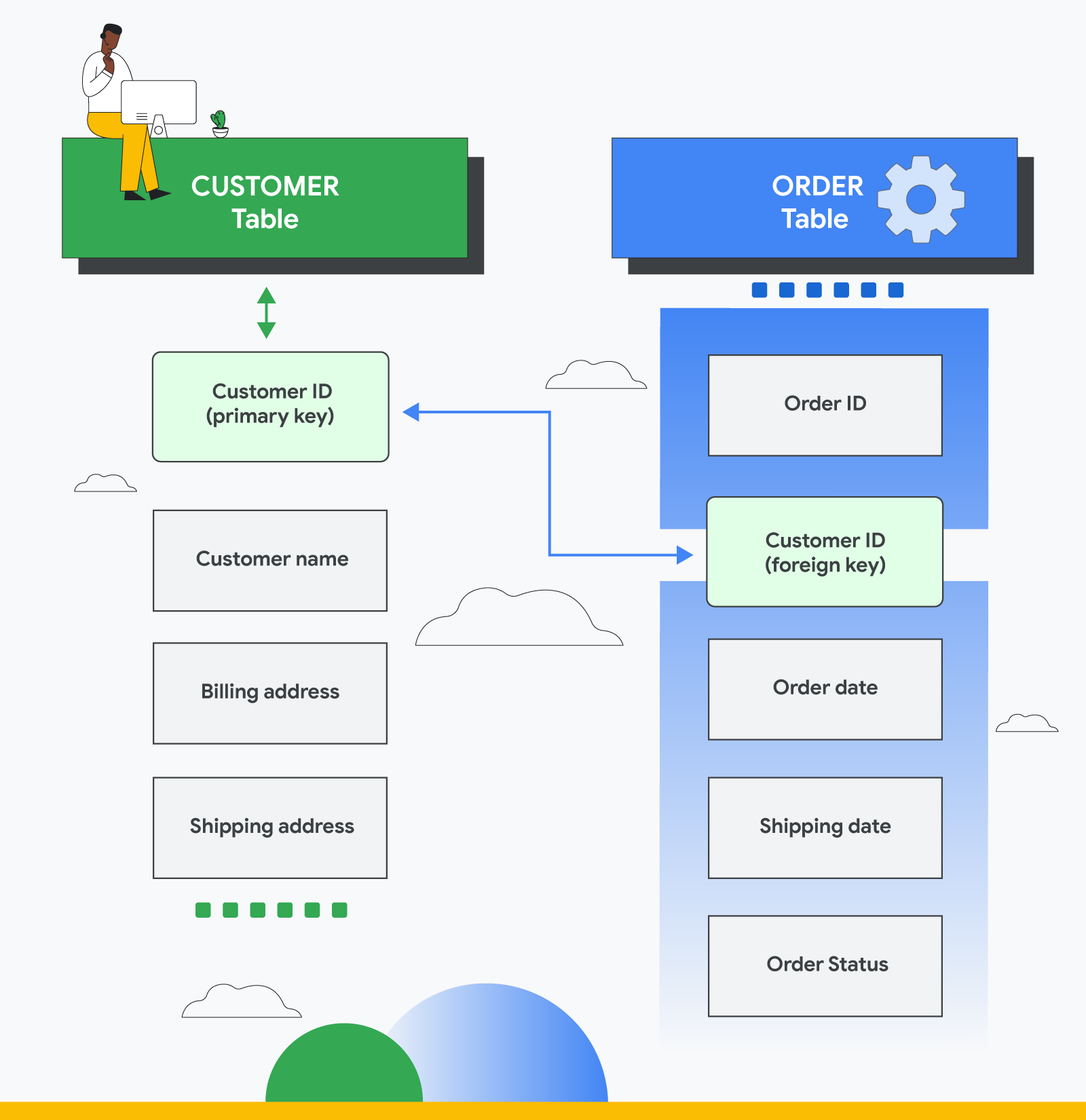
A tabela Customer contém dados sobre o cliente:
- ID de cliente (chave primária)
- Nome do cliente
- Endereço de faturamento
- Endereço de entrega
Na tabela Customer, o ID é uma chave primária que identifica exclusivamente o cliente no banco de dados relacional. Nenhum outro cliente teria o mesmo ID.
A tabela Order contém informações transacionais sobre um pedido:
- Código do pedido (chave primária)
- ID de cliente (chave externa)
- Data do pedido
- Data do envio
- Status do pedido
Aqui, a chave primária para identificar um pedido específico é o ID do pedido. Você pode conectar um cliente a um pedido usando uma chave externa para vincular o ID de cliente da tabela Cliente.
Agora, as duas tabelas estão relacionadas com base no ID de cliente compartilhado. Isso significa que você pode consultar as duas tabelas para criar relatórios formais ou usar os dados de outros aplicativos. Por exemplo, um gerente de agência de varejo pode gerar um relatório sobre todos os clientes que fizeram uma compra em uma data específica ou descobrir quais clientes tiveram pedidos com uma data de entrega atrasada na última mês.
A explicação acima tem como objetivo ser simples. No entanto, os bancos de dados relacionais também se destacam em mostrar relações muito complexas entre dados, permitindo que você faça referência a dados em mais tabelas, desde que os dados estejam em conformidade com o esquema relacional predefinido do banco de dados.
Como os dados são organizados como relacionamentos predefinidos, é possível consultá-los de maneira declarativa. Uma consulta declarativa é uma maneira de definir o que você quer extrair do sistema sem expressar como o sistema precisa calcular o resultado. Essa é a essência de um sistema relacional, e não outros sistemas.
Exemplos de bancos de dados relacionais
Agora que você já sabe como os bancos de dados relacionais funcionam, comece a aprender sobre os diversos sistemas de gerenciamento que usam esse modelo. Um sistema de gerenciamento de banco de dados relacional (RDBMS) é um programa usado para criar, atualizar e gerenciar bancos de dados relacionais. Alguns dos RDBMSs mais conhecidos incluem MySQL, PostgreSQL, MariaDB, Microsoft SQL Server e Oracle.
Os bancos de dados relacionais baseados na nuvem, como o Cloud SQL, Cloud Spanner e AlloyDB estão cada vez mais conhecidos, porque oferecem serviços gerenciados para manutenção de bancos de dados, aplicação de patch, gerenciamento de capacidade, provisionamento e suporte à infraestruturas.
Tudo pronto para começar? Crie uma instância de teste gratuito de 90 dias do Cloud Spanner com 10 GB de armazenamento sem custos financeiros.
Benefícios dos bancos de dados relacionais
A principal vantagem do modelo de banco de dados relacional é que ele oferece uma maneira intuitiva de representar dados e facilita o acesso a pontos de dados relacionados. Como resultado, os bancos de dados relacionais são usados com mais frequência por organizações que precisam gerenciar grandes quantidades de dados estruturados, desde o rastreamento de inventário até o processamento de dados transacionais para a geração de registros de aplicativos.
Há muitas outras vantagens em usar bancos de dados relacionais para gerenciar e armazenar seus dados, incluindo:
Flexibilidade
Flexibilidade
É fácil adicionar, atualizar ou excluir tabelas, relações e fazer outras alterações em dados sempre que necessário, sem alterar a estrutura geral do banco de dados ou afetar aplicativos existentes.
Conformidade com ACID
Conformidade com ACID
Os bancos de dados relacionais são compatíveis com o desempenho da ACID (atomicidade, consistência, isolamento e durabilidade) para garantir a validade dos dados independentemente de erros, falhas ou outros possíveis erros.
Facilidade de usar
Facilidade de usar
É fácil executar consultas complexas usando SQL. Com isso, até mesmo usuários não técnicos aprendam a interagir com o banco de dados.
Colaboração
Colaboração
Várias pessoas podem operar e acessar dados ao mesmo tempo. O bloqueio integrado impede o acesso simultâneo aos dados quando eles estão sendo atualizados.
Segurança integrada
Segurança integrada
A segurança baseada em papéis garante que o acesso aos dados seja limitado a usuários específicos.
Normalização do banco de dados
Normalização do banco de dados
Os bancos de dados relacionais usam uma técnica de design conhecida como normalização que reduz a redundância e melhora a integridade dos dados.
Bancos de dados relacionais versus não relacionais
A principal diferença entre bancos de dados relacionais e não relacionais (bancos de dados NoSQL) é a forma como os dados são armazenados e organizados. Os bancos de dados não relacionais não armazenam dados de maneira tabular baseada em regras. Em vez disso, eles armazenam dados como arquivos individuais e não conectados e podem ser usados para tipos de dados complexos e não estruturados, como documentos ou arquivos rich media.
Ao contrário dos bancos de dados relacionais, os bancos de dados NoSQL seguem um modelo de dados flexível, o que os torna ideais para armazenar dados que mudam com frequência ou para aplicativos que processam diversos tipos de dados.
Produtos e serviços relacionados
O Google Cloud oferece vários serviços de banco de dados relacional totalmente gerenciado, que foi criado para atender às necessidades da sua empresa, desde a desativação do seu data center local até a execução de aplicativos SaaS e a migração dos principais sistemas de negócios.
Nossas ofertas de banco de dados relacional oferecem mais opções para migrar cargas de trabalho para a nuvem. Dê maior flexibilidade e liberdade aos desenvolvedores, para que eles tenham mais tempo para se concentrar em criar os melhores apps possíveis.
 Cloud SQLServiço de banco de dados relacional totalmente gerenciado para MySQL, PostgreSQL e SQL Server.
Cloud SQLServiço de banco de dados relacional totalmente gerenciado para MySQL, PostgreSQL e SQL Server. Cloud SpannerBanco de dados relacional totalmente gerenciado com escala ilimitada, consistência forte e até 99,999% de disponibilidade.
Cloud SpannerBanco de dados relacional totalmente gerenciado com escala ilimitada, consistência forte e até 99,999% de disponibilidade. AlloyDBServiço de banco de dados totalmente compatível e compatível com PostgreSQL para suas cargas de trabalho empresariais mais exigentes de banco de dados.
AlloyDBServiço de banco de dados totalmente compatível e compatível com PostgreSQL para suas cargas de trabalho empresariais mais exigentes de banco de dados.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











